Latent World Models기반 월드 모델의 계보를 잇는 모델이자, 최근 DreamderV4까지 나온 논문의 시초인 dreamer를 리뷰해봤습니다. 재밌게 읽어주시면 감사하겠습니다.
먼저, Dreamer를 읽을 때 강화학습, 월드 모델, 잠재 공간, 부분 관측 마르코프 결정 과정(POMDP) 같은 개념이 한번에 한번에 등장해서 머리가 복잡해질 때가 있습니다. 근데 막상 핵심 질문은 엄청 간단한데요.
에이전트가 실제 환경에서 계속 부딪혀 보지 않고 , 자기 머릿속에서 미래를 상상하며 더 똑똑하게 배울 수 있는가?
라는 질문이 바로 dreamer의 핵심질문 입니다. dreamer는 이 질문에 yes를 했고, 이를 픽셀 공간이 아니라 압축된 latet space에서 상상해야한다!까지 연결한 논문이라고 생각하시면 됩니다.
그럼 본격적으로 시작하겠습니다.
Background
해당 파트에서는 리뷰를 이해하기 위해서 알아햐하는 것들을 살짝 정리해보겠습니다.
- 강화학습
강화학습이 뭘까요? 강화학습은 행동을 해보고 , 그 결과로 받은 보상(reward)을 바탕으로 더 좋은 행동 규칙을 배우는 방법을 말합니다. 게임으로 리뷰하면 화면을 보고 버튼을 누르고, 점수를 얻으며, 점수를 많이 주는 플레이 방식을 익히는 과정과 같습니다.

강화학습의 기본 목표는 누적 보상의 기대값을 크게 만들도록 하는 것이 목표입니다.
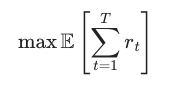
여기서 $r_t$는 $t$ 시점의 reward을 의미하고, 이렇게 설정한 이유는 에이전트는 당장 눈앞의 보상뿐만 아니라 앞으로 계속 받을 보상까지 함께 고려해야 하기 때문입니다.
2. POMDP
dreamder에서는 강화학습에서 흔히 등장하는 MDP가 아닌 PODMP를 설정하는 부분이 나옵니다. 그러면 POMDP가 뭘까요? PODMP는 부분 관측 마르코프 결정 과정으로 visaul cotrol을 POMDP로 설정하였습니다. 이유는 에이전트가 환경의 실제 상태(state)를 보지 못하고, 카메라 이미지 같은 관측만 보기 때문인데요.
예를 들어서, 로봇 팔의 사진 한 장만 보고는 그 팔이 지금 얼마나 빠르게 움직이는지 완전히 알기는 어렵습니다. 그래서 현재 관측만으로 진짜 다 알 수 없는 상황이 생깁니다. 이게 바로 POMDP 입니다.
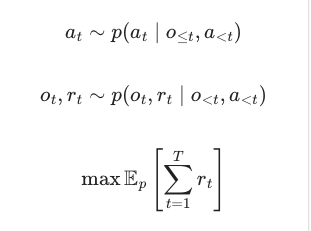
여기서 o_t 는 관측, a_t는 행동 r_t는 보상을 의미합니다. 핵심은 에이전트가 이미지 이력과 행동 이력을 바탕으로 미래 보상을 크게 만드는 행동을 골라야 한다는 것입니다.
- World model
그럼 월드 모델이 뭘까요? 요즘에 다들 월드 모델에 대해서 언급을 많이 하는데, 월들 모델은 한마디로 세상이 어떻게 변하는지에 대한 내부 시뮬레이터라고 말할 수 있습니다. 사람으로 비유하면, “내가 지금 오른쪽으로 뛰면 공이 저쪽으로 갈 것 같다”라고 머릿속으로 미리 그려보는 능력과 비슷한 것이죠.
Introduction
Dreamer 이전 모델 기반 방법론들은 보통 world model, 즉, 세상을 예측하는 내부 모델을 배운 다음에 그 안에서 얻은 상상된 보상을 크게 만드는 방향으로 행동을 정합니다. 이때 한쪽은 미리 정책 신경망을 학습하는 방식이고, 다른 한쪽은 행동할 때마다 여러 선택지를 즉석에서 계산하는 online planning 방식을 주로 사용합니다. 그런데 이런 방식은 보통 정해진 짧은 미래까지만 보고 판단했기 때문에 멀리 있는 큰 보상보다 눈앞의 작은 보상만 따라가는 근시안적인 행동을 하기가 매우 쉽습니다.
또한, 기존 연구들은 모델이 완벽하지 않을 수 있다는 이유로, 상상 모델이 조금이라도 틀리면 잘못 배울까봐, 미분 정보를 이용해 고치기 보다는 많은 행동을 그냥 시험해보는 경우가 많았습니다. 지금 생각해보면 이런 시기가 있었단 말이야? 싶을 정도로 오차가 많은 시기였던것 같습니다.
논문의 저자가 말하길, 똑똑한 에이전트는 똑같은 상황을 다시 만나지 않아도 과거 경험을 바탕으로 새 상황에 적응할 수 있어야 합니다. 이를 위해서는 단순히 보상만 많이 받은 행동을 외우는 것이 아니라, 세상이 어떻게 움직이는 지에 대한 내부 이해, 즉, world modle이 필요합니다.
그리고 이미지를 드대로 들고 미래를 상상하는 것은 너무 무겁고 비효율적인데요. 이미지의 핵십만 뽑아낸 작은 latent space 안에서 미래를 상상하면 적은 비용으로도 효율적으로 미래를 상상할 수 있게됩니다. 계산이 가벼워지고 많은 미래 경로를 빠르게 그리고 동시에 상상할 수 있게 되죠.
그래서 본 논문의 저자는 위의 통찰을 기반으로 Dreamer를 제안하였습니다. Dreamer는 먼저 과거 경험으로부터 world model을 배우고, 그 다음 모델의 latent space 안에서 미래를 상상하면서 행동을 학습합니다. 여기서 중요한 구조가 actor-critic입니다. actor는 지금 어떤 행동을 할까를 정하는 역할이고, critic은 그 행동을 앞으로 얼마나 하면 좋을까를 점수로 매기는 역할이라고 생각하시면 됩니다. Dreamer는 이 둘을 이미지 공간이 아니라 latent space 안에서 학습함으로서 실제 환경에서 계속 부딪혀 보기 전에 내부 모델 안에서 먼저 많이 연습하게 합니다.

Dreamer의 핵심은 짧게 상상하더라도 길게 행동할 수 있게 만든다는 점인데요. 상상은 몇 단계 앞까지 하더라도 그 뒤의 먼 미래는 value model이 대신 점수처럼 요약해 주기 때문에 에이전트가 눈앞의 보상만 따라가지 않게 하도록 합니다. Figure 1에서 이에 대한 구조를 살짝 확인할 수 있는데요. 과거 경험 데이터에서 latent dynamcs를 배우고, 그 안에서 vaue와 action을 latne imagination으로 학습하는 흐름을 확인할 수 있습니다.
본 논문의 contribution을 정리해보겠습니다.
- latent imagination만으로 long-horizon behavior를 학습하는 방법을 제시했다는 점
- Dreamer를 기존 representation 방법들과 결합해 20개의 visual control task에 적용했고, 같은 하이퍼파라미터를 사용하면서도 기존의 model-based와 model-free 방법들보다 적은 데이터로 더 빨리 배우고, 최종 성능에서도 더 좋은 결과를 냄
Method
Dreamer의 전체 흐름은 Figure 3, Algorithm 1로 요약해서 볼 수 있는데요.
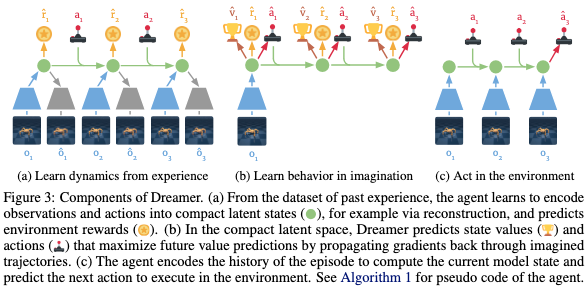

이 구조를 말로 풀이 하면 다음과 같습니다.
- 먼저 실제 환경에서 데이터를 모으면,
- 그 데이터로 월드 모델을 학습합니다.
- 실제 데이터로부터 기반한 latent state로부터 미래를 상상하고요.
- 상상한 미래 위에서 행동 모델과 가치 모델을 학습합니다.
- 학습된 행동 모데을 실제 환경에서 실행해서 데이터를 더 모읍니다.
이 다섯단계가 계속 반복되는 형태로 본 Dreamer가 흘러갑니다.
POMDP
Dreamer는 이미지 기반 제어를 POMDP로 두는데요. 현실의 진짜 상태는 직접 보이지 않고, 이미지와 보상만 들어오기 때문입니다. 현재 이미지 한장 만으로는 부족한 정보를 latent state가 과거를 요약해서 보충해야 하기 때문입니다.
Latent dynamics 모델
Dremer의 월드 모델은 세 부분으로 나누는데요.
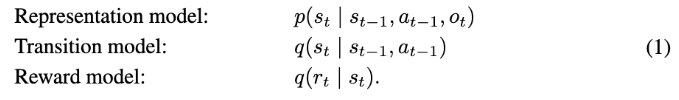
세 식은 각각의 뜻을 가집니다.
- representation model은 현재 관측 $o_t$와 직전 latent state 및 행동을 보고 현재 latent state $s_t$를 만듭니다.
- transition model은 관측을 다시 보지 않고도, 현재 latent state와 행동으로 다음 latent state를 예측합니다.
- reward model은 latent state가 얼마나 좋은지, rewrd가 얼마일지를 예측합니다.
논문에서는 현실에서 데이터를 생성하는 분포를 주로 p로, 상상을 가능하는 하는 근사 분포를 주로 q로 표기하는데요. 여기에서 핵심은 Dreamer는 이미지 자체를 상상하지 않고 latent state만 상상한다는 것입니다. 이 때문에 메모리를 적게 쓰고, 많은 미래 궤적을 빠르게 계산할 수 있다는 것…!
Action model, Value model
Dreamer는 Actor-critic 구조를 latent space에서 학습하는데요.
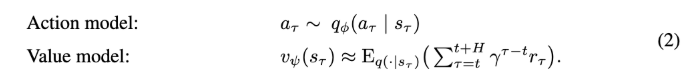
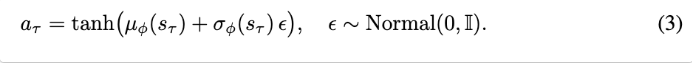
value estimation
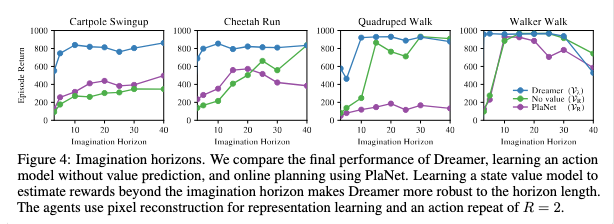
Dreamer에서는 상상 지평 H까지만 직접 상상하고 그 이후로는 가치 모델로 이어 붙인다는 것이 핵심 아이디어인데요. 이때 3가지 value estimation 중 하나를 사용합니다.
- 단순 누적보상 $V_R$
이 방식은 상상 지평 안의 보상만 더하는 단순한 방법인데요. 지평 밖의 보상은 완전히 무시하는 거죠.
2. k-step 부트스트랩 값 $V^k_N$
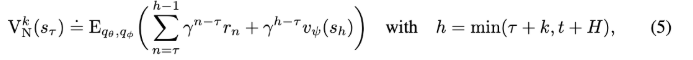
3. Dreamer가 실제로 쓰는 $V_{\lambda}$
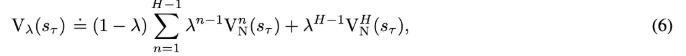
Objective
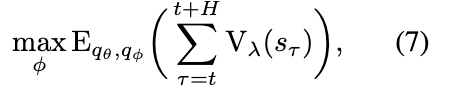
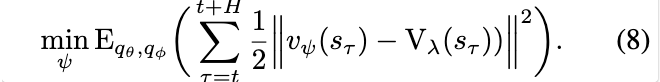
representation learning
논문에서는 3가지 방식으로 representation learning 방식 중 하나를 사용하는데요.
- reward prediction만으로 학습하기
가장 단순한 방식으로 미래 보상만 잘 맞히도록 latent state를 학습하는 것입니다. 근데 뒤에서는 언급하지만 가장 성능이 안 좋은 방식이라고 합니다… - fixcel reconstruction
Dreamer 직전 논문인 PlaNet에서 사용했던 방식인데요. 실제 실험 성능이 가장 높게 나온 방식 중에 하나입니다. 간단히 설명하면 다음과 같습니다. PlaNet의 월드 모델은 다음 4가지 요소를 두는데요.
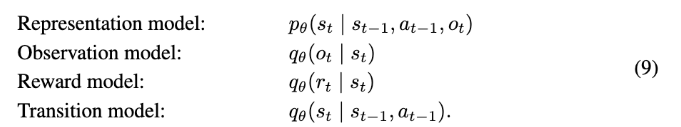
그리고 Objective는 다음과 같습니다.
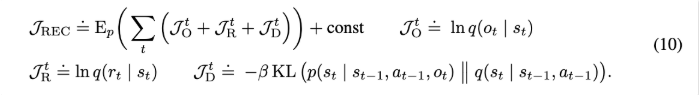
각 항의 의미를 간단히 살펴보면 다음과 같습니다.
- $J^t_O$는 latent state가 현재 이미지를 잘 설명해야함을 의미하고
- $J^t_R$는 latent state가 보상을 잘 설명해야함을 의미합니다.
- $J^t_D$는 현재 이미지를 너무 과하게 베끼지 말고, 전이 모델을 예측한 상태가 너무 멀이지지 말라는 규제항입니다.
논문에서는 전이 모델을 RSSM으로 image encoder를 CNN, image decoder를 transposed CNN으로 사용했다고 합니다.
- Contrastive estimation
해당 방식은 픽셀을 직접 맞히는 대신에 이 이미지가 latent state가 잘 설명하는가를 학습하는 방식을 말하는데요. 이때 관측 모델이 대신 상태 모델을 둡니다.
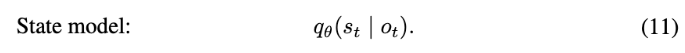
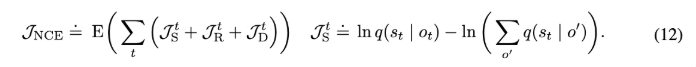
Experiments

실험 데이터셋으로는 DeepMind Control Suite의 Visual Control 20개 task를 사용했다고 합니다. Figure2를 통해 그 예시를 확인하실 수 있으며, Cup, Acrobot, Hopper, Walker와 같은 task가 있는 것을 확인하실 수 있습니다. 해당 task는 contact dynamics, sparse rewards, degrees of freedom 등을 포함한다고 하네요. 딱 월드 모델에 적합한 데이터셋이네요.
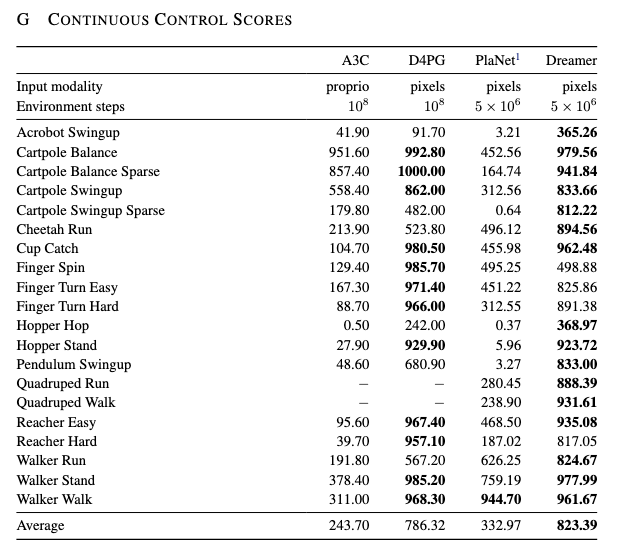
1. 우선, Dreamer가 모든 task에서 무조건 최고는 아니라는 것입니다. 예를 들어서, Finger Spin, Hopper Stand, Walker Stand 같은 task에서 D4PG가 더 높은 것을 볼 수 있는데, Dreamer는 모든 task를 압도적으로 다 이기 방법론!이라기 보다는 평균적으로 매우 강하고 특히 장기 과제에서 매우 뛰어난 방법론이다라고 생각해주시면 좋을 것 같습니다.
2. Dreamer의 진짜 강점은 sample efficiency인데요 Figure 6을 보면서 말씀드려보겠습니다.
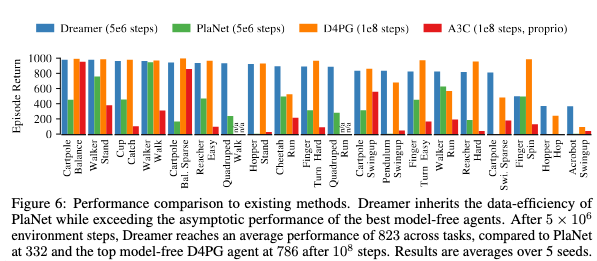
Dreamer의 경우, 평균 823점에 5×10^6 step 이라면, Planet은 평균 333점에 5×10^6 step을 가집니다. 점수가 엄청나게 차이가 나죠? D4PG의 경우 점수가 그렇게까지 차이가 나지 않은 786점을 가지지만 step은 10^8로 엄청나게 차이가 납니다. 즉, Dreamer가 훨~씬 적은 model-free baseline을 가진다라고 말할 수 있습니다.
이렇게 Dreamer를 다뤄봤습니다. 갑자기 월드 모델을 읽어봐서 뭐지 싶으셨던 분들이 있을거 같은데 가끔 월드모델로 돌아오도록 하겠습니다. 점점 최신 모델로 돌아올테니^^ 기대해주세요~! 감사합니다
주연님 좋은 리뷰 감사합니다.
‘Dreamer의 핵심은 짧게 상상하더라도 길게 행동할 수 있게 만든다는 점’ 이라고 하셨는데, sample efficiency 실험이 이에 해당한다고 보면 될까요?
또한, ‘latent state로부터 미래를 상상’하는 것이라 하였는데, action을 만들어내는 policy와 latent state에 대한 평가가 이루어지는 value 모델이 모두 학습이 되는 것인 지 궁금합니다.
알고리즘 1의 마지막이, 학습된 행동 모델을 실제 환경에 실행하여 데이터를 모은다고 하셨는데, 즉, Dreamer는 대략적인 policy를 학습한 뒤, 데이터를 수집하고 이를 real-world에서 수행하여 조정하는 것으로 이해하면 될까요?
마지막으로, 해당 방법론이 long-horizion에서 학습하는 방식을 제시하였다고 하셨는데, 실험의 어떤 task들이 long-horizion으로 보아야 하는 지 궁금합니다. 모든 task가 long-horizion일까요?
안녕하세요. 질문 감사합니다.
1. 해당 점을 직접적으로 보여주는 실험은 Figure 4라고 생각하시면 되는데요. Figure 6의 sample efficiency는 그 구조가 실제로 어떤 성능 이득을 내는지 보여주는 실험 결과라고 보시면 될 것 같습니다.
2. 네. 둘다 학습됩니다. 논문에서 latent space 안에서 action model이랑 value model을 함께 두고 실제로 알고리즘 1에서 업데이트합니다.
3. 월드 모델 학습 -> 잠재 상상으로 행동이랑 가치 학습 -> 실제 환경에서 새 데이터 수집 -> 다시 학습을 반복하는 순환 루프를 그린다고 보시면 되겠습니다.
4. 본 논문에서 말하길 20개의 task에서 모든 task가 logn-horizon하지는 않았다고 합니다. walker domain 같은 경우는 비교적 reative task에 가깝다고 했는데요. 모든 과제가 동일한 정도의 강기 의존성을 가지는 것은 아니고 어떤 task는 짧은 반응만으로는 꽤 풀리지만 어떤 task는 먼 미래까지 고려해야 풀리는거는 사실 task by task여서 task를 보고 결정해야하는 것 같습니다.
감사합니다.