안녕하세요. 이번 논문 리뷰는 DP나 Flow Matching policy같은 generative IL policy가 runtime에서 task failure를 일으킬 때, 이를 failure data 없이 사전에 예측하는 방법론인 FIPER(Failure Prediction at Runtime)입니다. 즉 policy steering을 하기 전 선제적으로 run-time failure detection 을 수행하는 논문이라고 보시면 될 것 같습니다.
논문 정보
- 저자:
- Ralf Römer*¹, Adrian Kobras*¹, Luca Worbis¹, Angela P. Schoellig¹·²·³
- 1: TU Munich, Learning Systems and Robotics Lab, MIRMI
- 2: Robotics Institute Germany, 3: Munich Center for Machine Learning
- 링크: https://arxiv.org/abs/2510.09459
- 프로젝트페이지: https://tum-lsy.github.io/fiper_website
교신저자이신 Angela P. Schoellig 교수님은 learning-based control, safe RL, autonomous systems 분야에서 저명한 연구자이신 것 같습니다. 제가 언젠가 세미나 때 말씀드린 Safety filtering, policy steering 쪽으로 최근 연구가 많은 CMU Intent Lab (교신저자 : Andrea Bajcsy) 과 살짝은 비슷한 행보를 걷고 있는 것 같아서 유의깊게 살펴보는 중입니다.
Introduction
Generative IL Policy의 Failure 문제
Diffusion Policy, Flow Matching 등 generative model 기반 IL은 복잡한 long-horizon manipulation task에서 인상적인 성능을 보여왔지만, 여전히 로봇이 deploy 할 시에 unpredictable하고 unsafe하게 task failure가 발생할 수 있었습니다. 특히 이 failure의 원인에는 크게 2가지가 있을 수 있는데요. Distribution shift 와 Compounding error 입니다. Distribution shift는 학습 때 보지 못한 환경 변화로 인한 unexpected visual/state shift 를 의미하고, Compounding error 는 action prediction에서의 누적되는 오차라고 보시면 됩니다. 그래서 인간 중심의 안전이 중요한 환경에서 로봇을 배치하기 위해서는 deploy 시점에서 이런 failure를 조기에 예측하는 것이 필수적이라고 할 수 있습니다.
기존 Failure Detection 의 어려움
근데 문제는 이 조기에 failure prediction을 한다는 것이 일반적인 classification 문제로는 다루기가 어렵다고 저자들은 주장하는데요. 여기에 2가지 이유를 듭니다.
먼저 Failure data 수집의 비실용성 문제가 있습니다. 다시 말하면 anomaly detection task 컨셉이랑 동일하다고 보시면 되겠는데요. closed-loop operation에서 발생 가능한 failure mode의 범위가 너무 광범위해서 comprehensive labeled data를 만드는 것이 사실상 불가능하고, 애초에 failure를 의도적으로 유발해서 데이터 취득하는 것 자체가 데이터 취득 시 마다 위험한 상황을 만들게 한다는 것입니다.
기존 failure detection/prediction 접근들의 한계
그리고 다음은 기존 OOD detector 기반의 근복적 한계가 있습니다. 기존의 단순 OOD detector는 모든 새로운 상황에 trigger해서 false alarm일 때가 많다고 합니다. 또는 실제로는 학습된 policy가 일부 OOD 환경에 대해 적응해서 generalize 가능한데, 이를 구분하지 못하는 상황도 펼쳐지게 됩니다. 이외에도 VLM 기반의 모니터링은 전제가 에러가 이미 발생한 후에야 반응할 수 있기에, 일어날 실패를 예측해서 선제 조치를 못하게 된다는 매우 큰 한계가 생기게 됩니다.
저자의 빡침포인트 및 연구 철학 제안
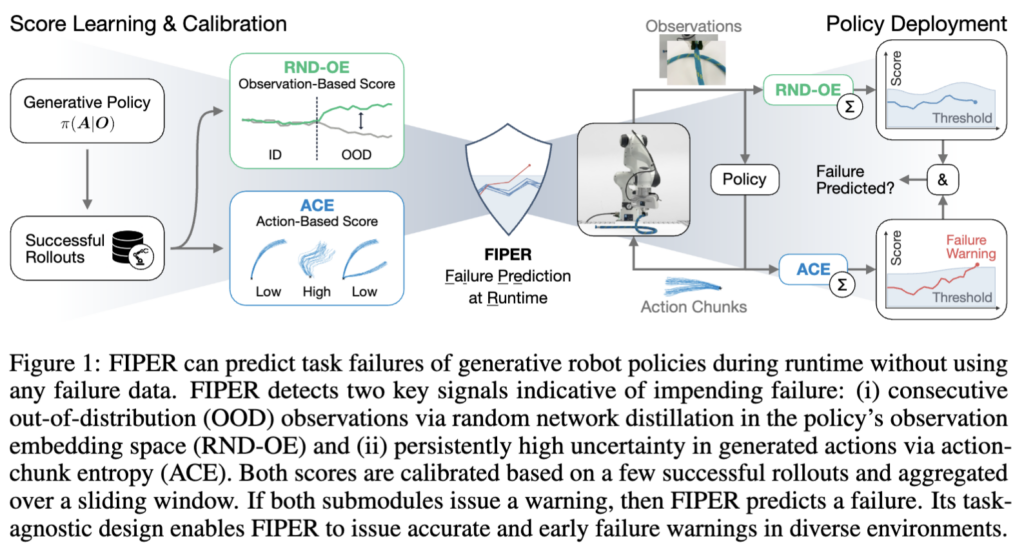
이제 여기서 저자들은 빡이 칩니다. “왜 observation 정보랑 action 정보를 따로따로만 보고 failure detection을 하는거임? 그리고 왜 에러가 이미 발생한 다음에야 failure라고 판단하는거임 선제적으로 판단해야지.. 그리고 실패 데이터없이 anomaly detection하듯이 failure detection 하면 안됨?” 까지가 결국 이 연구의 핵심철학인 것 같습니다.
이래서 저자들이 본 논문의 방법론인 FIPER(Failure Prediction at Runtime)를 제안을 합니다. 실제로 실패하는 경우를 생각해봤을 때, 저자들의 통찰로는 (i) 성공적인 실행 중 예상되는 패턴에서 관측치가 연속적으로 벗어나는 것과 (ii) 정책에 의해 생성된 확률적 행동에서 높은 불확실성이 생기는 경우. 이 둘을 실패의 핵심요소라고 생각했다고 합니다.
그래서 (i)은 정책의 관측치 임베딩 공간에서 랜덤 네트워크 증류 RND(Random Network Distillation, Burda et al., ICLR 2019)를 활용하여 측정하고, (ii)는 관측치 조건 하의 action chunk 분포의 엔트로피에 기반하여 측정하는 것을 제안하게 됩니다. 최종적으로는 conformal prediction(CP), 만들어낸 score에 대한 calibration, 즉 통계적 보정기법을 적용하는 것으로 failure detection을 위한 threshold를 구성하게 됩니다. 이 threshold가지고 실시간으로 최종적인 관측치 점수 + 행동 기반 불확실성 점수 둘 다 고려해서 failure detection하는 셈입니다. 컨셉은 단순합니다.
Related Work
OOD detector 혹은 Failure detection 관련 기존 연구들인데요. 논문에서 언급하던 단점 위주로 몇개만 짧게 씩만 설명하겠습니다.
- FAIL-Detect(Xu et al.)는 observation embedding의 flow matching likelihood를 사용하지만 observation-only 로만 failure signal을 만들기에 action distribution에서의 warning sign을 놓치는 문제가 있습니다.
- Sentinel(Agia et al.)의 STAC score는 연속 action chunk 간 temporal consistency를 측정하지만, multimodal action distribution에서 mode switching을 high uncertainty로 오인하는 문제가 있습니다.
- ReDiffuser(He et al.)는 RND 기반으로 action reliability를 측정하지만 state-based policy에 맞춰져 있어 high-dimensional visual input 처리가 어려움이 있습니다.
- Diff-Dagger(Lee et al.)는 diffusion policy의 loss를 failure indicator로 쓰지만 flow matching 등 다른 generative model 아키텍쳐엔 직접 적용 불가한 문제가 있습니다.
- AHA(Duan et al.) 같은 경우는 로봇의 실패행동 데이터를 가지고 VLM fine-tuning해서 failure detection하는 거라고 보시면 되고, 그래서인지 inference가 느리고, 무겁고, 에러가 이미 발생한 후에야 alarm을 주기 때문에실패를 예측한다는 능력자체는 없습니다.
이 기존 방법론들은 다들 결론적으로 observation-only 또는 action-only로 보거나, failure-mode label을 만들어야지만 가능하거나, failure detection 자체가 너무 늦게 alert를 준다는 한계가 있습니다.
Methods
FIPER 는 아주 직관적으로, figure1에서 보신 것처럼, RND-OE, ACE라는 각각의 서브 모듈로 이루어집니다. 그리고 인트로에서 말했듯이, failure data없이 failure detection을 runtime에 선제적으로 하는 것이 목표입니다.
Problem Setup
역시 여타 논문들처럼 로봇 시스템을 MDP로 모델링합니다. Policy timestep t마다 generative IL policy \pi(A|O)가 observation history O_t에 conditioned된 action chunk A_t = (a_{t|t}, ..., a_{t+H-1|t})를 생성하고, 이 중 처음 h개만 실행 후 re-planning합니다. 이제 이거 가지고 현재까지의 trajectory \tau_{:t}를 입력받아, 남은 timestep에서 task를 완수할 수 있을지를 예측하는 failure predictor F(\tau_{:t}) \in \{0, 1\}를 설계하고, F(\tau_{:t}) = 1이면 failure를 predict하고 detection time t를 기록하는 것이 태스크의 최종 목표입니다.
4.1 Detecting OOD Observations via Random Network Distillation (RND-OE)
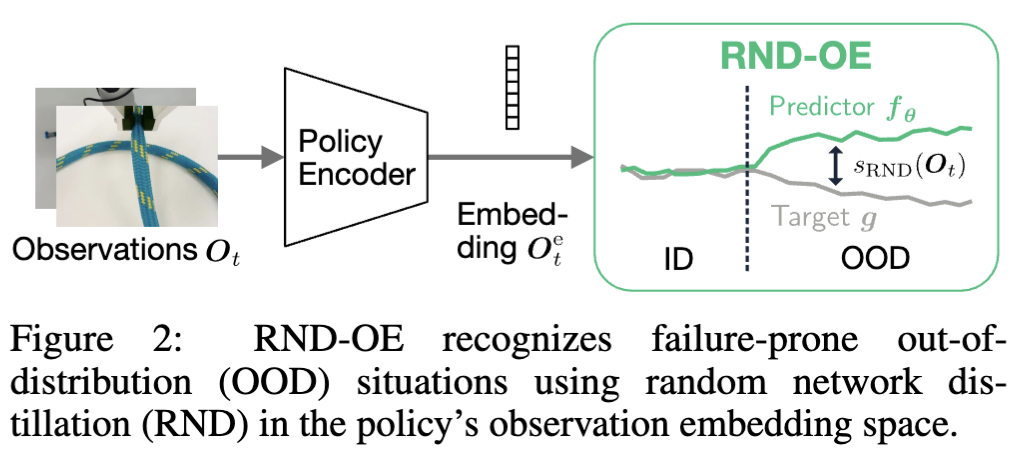
첫 번째, observation이 학습 분포에서 벗어났는지를 판단하는 RND-OE(RND Observation Embedding)입니다.
Random Network Distillation , RND(Burda et al., ICLR 2019)를 활용합니다.
RND는 원래 RL에서 sparse reward 문제 때문에 exploration 용도로 제안된 방법론입니다.
일단 Target 네트워크(g), Predictor 네트워크 (f) 를 각각 둡니다. g는 무작위로 초기화되고 매개변수가 고정된 네트워크여서 obs 입력이 주어지면 출력이 결정론적이고 일관적이라는 설정이 있고, f는 g랑 동일 아키텍쳐인데, 경사하강법으로 g의 출력을 예측하게끔 학습하면서 그 둘 간의 출력 MSE를 최소화하는 그 loss를 exploration의 signal로 활용하게 만드는 컨셉을 제안했었습니다.
이게 deep ensemble과 MC dropout 같은 좀 나이브한 기존 uncertainty quantification 방법론을 능가하면서 OOD detection 성능을 보이는 uncertainty quantification으로 의미가 생겼다고 합니다. 그래서 저자들도 여기서 영감을 받아서 써먹었습니다. policy encoder 단에서 나온 embedding에 RND를 적용하니까 이론적으로 자기들이 이미 본 ID 에 대한 상황이면 서로 비슷한 값을 내뱉기에 loss값이 작을 터이고, 보지 못한 OOD 상황인 경우에는 둘 간에 loss 값이 커지면서 OOD를 판단할 하나의 score를 뽑게 되는 셈이었습니다. loss는 다음과 같습니다.
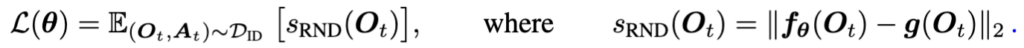
모델 구조는 RND를 따라서 다음과 같이 간단합니다.
- Target network g(\cdot): 랜덤 초기화 후 freeze (4 FC layers)
- Predictor network f_\theta(\cdot): 성공 rollout 데이터로 target을 맞추도록 학습 (6 FC layers로 target보다 layer 두 개를 더 쌓았다고 합니다.)
- 이 때, 둘 다 policy의 vision encoder h(\cdot)는 freeze하고 활용하는 구조입니다.
결국엔 Policy의 embedding space에서 RND를 적용해서 anomaly를 감지하기에 policy 성능에 실제로 영향을 주는 OOD만 잡아낼 수 있다는 장점이 있습니다. Raw image에서의 irrelevant한 visual noise는 신경안쓰고 filtering하는 효과를 주는 셈이죠. 그리고 앞서 말했듯이 pretrained encoder를 재활용하기에, 소수의 calibration rollout만으로도 RND 학습이 가능하다는 이점이 있습니다.
논문 Appendix C.6에서는 raw observation image 기반 RND도 실험했지만 embedding space 기반이 성능이 유의미했다고 합니다. e2e로 학습된 vision encoder가 task-irrelevant detail을 자연스럽게 필터링하기 때문에, real-world task에서의 visual noise로 인한 FPR을 줄일 수 있다는 분석이 있었습니다.
그리고 이 RND-OE는 단일 timestep의 OOD detection이 아니라, 크기 W_o인 sliding window로 score를 aggregation하는 형태를 취합니다.
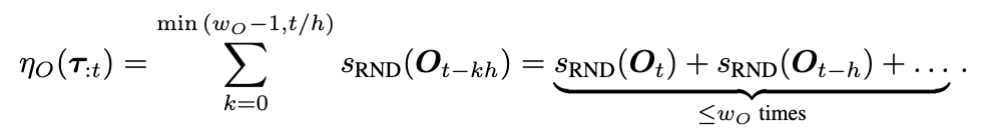
이게 중요한 이유가, 최근 대규모 데이터로 학습된 IL policy들은 brief/mild OOD에는 어느 정도 generalize할 수 있지만, 연속적인 OOD observation은 compounding error를 유발해서 회복이 어렵기 때문입니다. 단발성 OOD는 무시하고, 지속적인 OOD만 failure 신호로 잡겠다는 어떻게보면 compounding error 에 집중한 게 이 window 기반 aggregation 설계인 것 같습니다.
그리고 최종적으로 이 OOD score는 threshold를 넘으면 observation-based failure predictor로써 발동하게 됩니다.
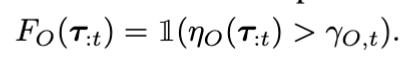
4.2 Detecting High Action Uncertainty via Action-Chunk Entropy (ACE)
두 번째, policy가 생성하는 action의 uncertainty를 측정하는 ACE(Action-Chunk Entropy)입니다. 이게 사실상 저자들의 핵심 철학인데요.
앞서서 관측정보에 대한 OOD 상황을 score화 시킬수는 있어지만, 진정한 failure detection은 미래 시스템 변화에 선제적으로 반응해야하고, 그러려면 미래 시스템 자체가 policy에 의해 생성된 action으로부터 영향을 받기 때문에, 저자들은 이 decision making system이라는 관점에서 intent를 반영한 uncertainty를 설계한다면 이 action uncertainty를 설계하는 것이라고 생각했다고 합니다. 근데 여기서 소제목을 보시면 Entropy가 나오게 되는데, Variance기반의 uncertainty가 아닌 Entropy기반의 uncertainty 설계가 바로 핵심입니다.
아래 Figure 3을 보시죠.
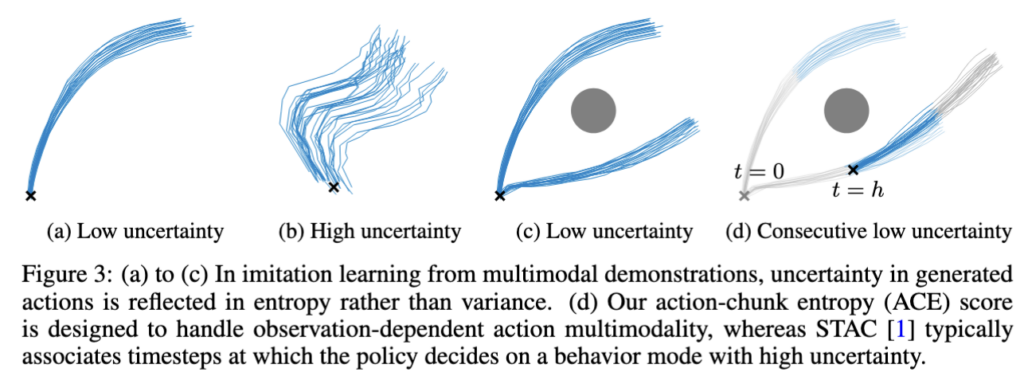
우선 ACT, DP에서의 intro에서부터 자주 나오던 얘기가 있습니다. demo data로 학습된 VA는 action multimodality를 포함한다는 것인데. 예를 들어 물체를 위에서 잡을지 옆에서 잡을지, 어떤 물체를 먼저 집을지 등 여러 valid한 action mode가 생길 수 있습니다. 기존 연구들에 따르면 보통 이 multimodality란 건 obs에 dependent하고 unknown 성향을 가진다고 하는데, 동일한 obs에 대해 여러 행동을 생성할 가능성이 있다보니까, 그 생성된 행동의 분산만 측정하는 것 자체는 uncertainty라는 거에 대한 정보를 만들기 어려운 요소라고 합니다.
이걸 이제 저자들은 multimodality란 게 discrete한 성격을 가지는 것 같다고 판단하고, 성공적인 작업 완료를 위해서는 생성된 각 행동이 obs가 의존된 모드 중 하나에 명확히 대응해야 된다고 생각하면서 분산이 아닌, 정보이론에 입각한 entropy관점으로 접근을 하게 됩니다.
위의 (a), (b), (c) 그림을 각각 보면 multimodality 관점에서 uncetainty, variance, entropy 간의 관계를 생각해볼 수 있는데요.
- (a) uni mode의 tight한 distribution: 낮은 uncertainty → variance 낮음, entropy 낮음
- (b) multi mode 사이에서 diffuse한 distribution: 높은 uncertainty → variance 높음, entropy 높음
- (c) 2개의 tight mode가 잘 분리된 distribution: 낮은 uncertainty → variance 높음, entropy는 낮음
여기서 (c)가 핵심입니다. Policy가 “위에서 잡기” 또는 “옆에서 잡기” 두 mode를 명확하게 구분하고 있으면, 각 mode 내에서는 확신이 높은 것이고 이건 failure가 아니라고 할 수 있습니다. 하지만 분포 기반 접근(기존의 STAC 방법론)은 이걸 high uncertainty로 오인하는 경우가 생기게 된다고 합니다. 그에 반해 Entropy는 각 mode의 sharpness를 측정하기에 이 문제를 피할 수 있다는 게 저자들의 핵심 주장입니다.
마지막으로 (d)를 보면, STAC의 temporal consistency는 policy가 mode를 결정하는 순간(t=0 → t=h로 넘어갈 때 다른 mode 선택)에서 발산의 정도를 높게 잘못 감지하는 반면, ACE는 각 timestep에서 독립적으로 mode sharpness를 측정하므로 이 문제가 발생하지 않는다고 주장합니다.
이론적으로 policy network가 생성할 action 분포의 sharpness 정도는,
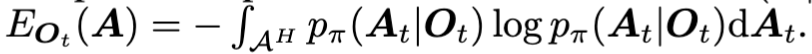
요런 수식으로 entropy로써 정량화될 수 있다고 하는데, 이게 DP나 Flow matching 기반이 policy에 대해 likelihood
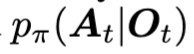
가 알려져 있지 않기에, E_{O_t}(A)를 근사하는 방식을 취해야한다고 합니다.
이 때,
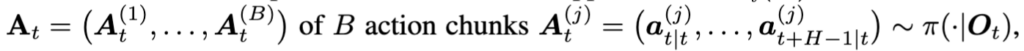
각 시간 t에서 B개의 action chunk를 샘플링하고 action chunk 전체의 joint entropy를 추정해서 직접적으로 E_{O_t}(A)를 근사하려면 action chunk 길이인 H값이 커짐에 따라, \mathcal{A}^H 공간의 연산이 exponential하게 많아져서 그만큼 많은 B batch값이 필요한 문제가 생깁니다.
근데 이제 저자들은 runtime failure detection을 목표로 하기에 계산 효율성을 위해서, 예측 시간 단계 t부터 t+H-1까지를 별도로 처리하여 계산 복잡도를 줄이고 ACE 점수를 정의하게 됩니다. timestep별로 따로 계산하면 각 timestep의 action들이 서로 가깝게 위치하므로 bin 수가 크게 줄어 B가 작아도 충분한 추정이 가능하기 때문입니다.
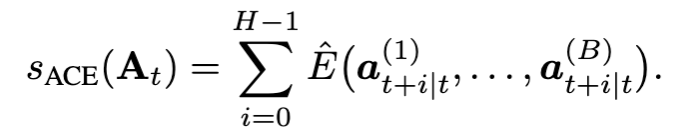
그래서 최종적으로는 위 식처럼, Action chunk 내 각 timestep i별로 Dimension-wise binning 이란 것을 sampled action을 binning해서 쪼개고, 여기서 확률 계산해서 entropy 추정 -> 전체 chunk에 대해 합산의 형태로 이루어지게 됩니다.
Dimension-wise binning 이란 건 다음과 같이 이루어집니다.
- Calibration dataset에서 각 action dimension d의 전체 range R_d를 offline으로 계산
- Cell size는 \alpha R_d (\alpha \in (0,1) : cell size factor)
- 각 timestep i, dimension d에 대해 B개의 sampled action을 binning하여 확률 p_c^i = n_c^i / B 계산
- Entropy: \hat{E} = -\sum_{c} p_c^i \log_2 p_c^i
최종적인 값은 아래처럼 또 window sliding 기반으로 aggregation해서 구해지게 돼서 compounding error를 또 고려한 설계가 되고, 단기간의 높은 불확실성이 아닌, 지속적인 행동 불확실성을 포착하게 되는 효과를 가진다고 합니다.
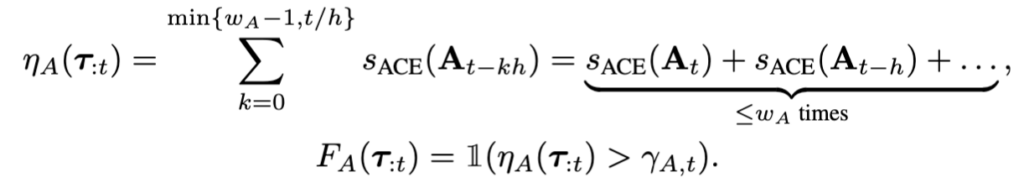
마지막으로 Cartesian space에서 계산한다는 점도 중요한데, joint velocity나 angle이 아니라 end-effector position 기준으로 계산함으로써 task-relevant하고 interpretable한 uncertainty를 측정합니다. 즉 policy가 end-effector를 어디로 보내야 할지 모르겠어하는 정도를 직접적으로 측정하는 것이죠. 논문에서는 6D pose 등 다른 representation도 시도했지만 성능 개선이 없었다고 하고, 또한 locomotion이나 navigation에도 fk를 통해 Cartesian space로 변환하면 적용 가능한 방법론이라고 어필합니다.
4.3 Observation- AND Action-Based Failure Prediction with FIPE
최종 failure predictor는 두 submodule의 논리합 구조인데요. 그냥 AND게이트입니다.
F(\tau_{:t}) = F_O(\tau_{:t}) \wedge F_A(\tau_{:t}) = \mathbb{1}(\eta_O(\tau_{:t}) > \gamma_{O,t} \wedge \eta_A(\tau_{:t}) > \gamma_{A,t})- OOD observation이지만 action uncertainty가 낮다 → policy가 generalize하고 있다 → failure은 아님
- Action uncertainty가 높지만 observation은 ID다 → 데모 데이터의 aleatoric uncertainty (suboptimality, diversity) 때문 → failure은 아님
- OOD observation + 높은 action uncertainty가 동시에 지속 -> failure 임
이런 논리로 접근됐는데, 나름 합리적인 AND게이트 설계인 것 같습니다.
Conformal Prediction으로 Threshold Calibration
마지막으로 두 서브모듈에 대한 Threshold \gamma_{O,t}, \gamma_{A,t}는 실패데이터없이 M개의 성공 rollout으로 구성된 calibration dataset \mathcal{D}_c를 사용해 통계적 기법인 CP(Conformal Prediction) 기반으로 calibration합니다. 특히 시간에 따라 변하는 임계값으로 처음에는 관대하게, 나중에는 엄격하게 threshold를 반영합니다.
논문에서 설명하기는 3가지 이론이 활용될 수 있다고 하는데, 그 중 저자들은 One-sided CP band 라는 기법을 활용했습니다.
One-sided CP band (Diquigiovanni et al.)은 calibration data를 두 partition으로 disjoint해서 time-varying mean \mu(t)과 bandwidth b(t)(\delta)를 계산하는 형태였습니다. 수식으로는 \gamma_t = \mu(t) + k^s \cdot s(t) 형태인데, 전체 rollout에 대한 FPR bound 를 이론적으로 보장한다고 합니다.
최종 score가 AND 결합이므로 F = F_O \wedge F_A에서, P(F=1) \leq P(F_A=1) \leq \delta로 개별 predictor의 통계적 보장이 FIPER 전체로 그대로 전이될 수 있다고도 언급합니다.
여기서 Remark 라면서 밝히는 부분이 있는데, 엄밀하게는 RND-OE 학습 데이터 \mathcal{D}_{\text{ID}}와 calibration 데이터 \mathcal{D}_c가 disjoint(분리?)해야 하지만, 실험에서는 같은 데이터를 사용해도 잘 작동했다고 합니다.
Experiments
Baseline
설명이 좀 복잡시러워서 gpt랑 얘기해보면서 표로 한번 정리했습니다. 교모하게 저자들이 baseline 대비 연구철학을 잘 잡은 것 같다는 생각이 들었습니다.
| 방법론 | 핵심 접근 | 한계 |
|---|---|---|
| PCA-kmeans(Liu et al., CoRL 2024) | Observation embedding의 PCA + k-means clustering, nearest centroid distance로 OOD 판별 | OOD와 failure 구분 못함 (TNR 0.24) |
| logpZO / FAIL-Detect(Xu et al., RSS 2025) | Observation embedding의 flow matching 기반 likelihood 추정 | Observation-only, action warning sign 놓침, single-timestep이라 false alarm 많음 |
| STAC / Sentinel(Agia et al., CoRL 2024) | 연속 action chunk 간 temporal consistency (MMD 기반) + VLM 모니터링 | Multimodal action에서 mode switching을 uncertainty로 오인, cumulative score로 detection 늦음 |
| RND-A(He et al., ICML 2024) | Action trajectory에 대한 RND 기반 confidence score | State-based policy 대상, visual input 처리 어려움 |
| Diff-Dagger(Lee et al., ICRA 2025) | Diffusion policy의 loss를 failure indicator로 활용 | Flow matching 등 다른 generative model에 직접 적용 불가 |
| Multi-task VWM(Liu et al., CoRL 2024) | Visual world model의 image embedding에서 failure detector 학습 | Failure example 필요 |
아래는 더 구분하기 쉽게 ✅, ❌ 도 체크해보라 해봤습니다.
| 특성 | PCA-kmeans | FAIL-Detect | Sentinel | RND-A | FIPER |
|---|---|---|---|---|---|
| Observation 기반 | ✅ | ✅ | ❌ | ❌ | ✅ |
| Action 기반 | ❌ | ❌ | ✅ | ✅ | ✅ |
| Failure data 불필요 | ✅ | ✅ | ✅ | ✅ | ✅ |
| OOD vs Failure 구분 | ❌ | △ | △ | △ | ✅ |
| score의 이론적 보장(CP) | ❌ | ❌ | ❌ | ❌ | ✅ |
| Generative model agnostic | △ | △ | △ | ❌ | ✅ |
실험 설계
실험 구성은 3 sim + 2 real 환경의 실험구성이고, 최대한 여러 embodiment/multimodality 를 고려한 것 같습니다. 이것도 글로 쓰다가 좀 복잡시러워서 gpt보고 표로 정리해달라고 시켰습니다.
| 환경 | 타입 | Generative Model | Backbone | Action Dim | OOD 유발 방법 | 특징 |
|---|---|---|---|---|---|---|
| SORTING | Sim (Franka) | Flow Matching | ACT (Transformer) | 2 | 블록 크기, 타겟 위치 변경 | 2개 블록 → 색상 맞는 박스 |
| STACKING | Sim (Franka) | Flow Matching | ACT (Transformer) | 8 | 블록 크기, 타겟 위치 변경 | 강한 action multimodality (6가지 순서) |
| PUSHT | Sim (Planar) | DDPM | U-Net | 2 | T자 물체 크기/형태 변경 | 접근 방향의 multimodality |
| PRETZEL | Real (Franka) | DDPM | U-Net | 5 | 줄 초기 위치, 축 회전 | 줄의 anisotropic 물성에 의한 OOD |
| PUSHCHAIR | Real (Mobile) | DDPM | U-Net | 3 | 의자 초기 자세 변경 | 의자 회전에 의한 failure |
Evaluation Metric
저자들은 TWA (Timestep-Wise Accuracy)이란 metric을 새로 제안하는데, 기존 accuracy 부류 metric과 DT(Detection Time) metric의 한계를 지적합니다.
기존 accuracy 부류 metric은 다음과 같습니다. 뭐 결국 confusion matrix 기반 metric인데요.
- TPR (True Positive Rate): 실제 실패 중에서 “실패다”라고 맞춘 비율 (놓치지 않는 능력)
- TNR (True Negative Rate): 실제 성공 중에서 “성공이다”라고 맞춘 비율 (오탐 없는 능력)
- Balanced Accuracy: (TPR + TNR) / 2. 실패와 성공의 개수가 다를 때(불균형 데이터) 공정한 평가를 위해 사용함.
반면 DT metric은 실패라고 처음 인식한 시점 / 전체 시간 입니다. 이건 얼마나 일찍 알아채냐에 대한 metric인데요.
이 두 부류 모두 한계가 있는 게, Accuracy만 보면 마지막 timestep에서 판단해도 높은 accuracy 일 때면 prediction이 아닌 detection이 되어 버리고, DT만 보면 모든 rollout을 즉시 Fail 판정하면 DT=0 이기에 의미가 없어진다는 문제가 생깁니다. 저자들은 이를 지적하면서 이 둘을 다음과 같은 single scalar로 통합하는 TWA를 제안하게 됩니다.
\text{TWA} = \frac{\sum_i (1 - t_i/T) + \text{\#TN}}{\text{\#P} + \text{\#N}}즉 정확하면서도 빨리 예측할수록 높은 점수를 받는 metric을 만들었습니다. 꽤 합리적인 metric design이라고 생각됩니다.
이후 Calibration에는 simulation 환경에서 M=50, real-world에서 M=10개의 성공 rollout만 사용합니다. 결과는 1-\delta \in \{0.9, 0.91, ..., 0.99\}에 대해 평균을 냈고, window size w와 threshold type은 TWA 기준으로 best를 선택하는 실험을 진행하게 됩니다.
1. 제안 Score의 OOD vs Failure 구분 능력
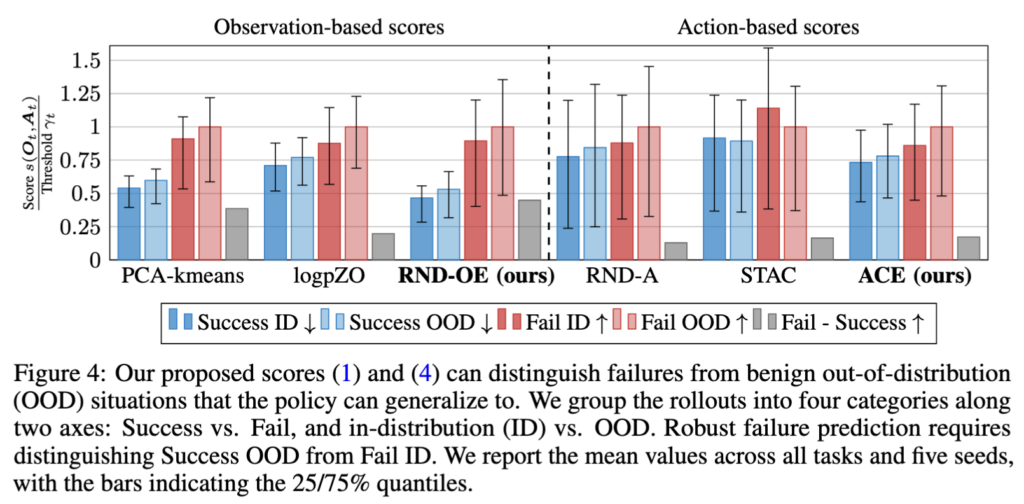
이 실험이 FIPER의 핵심 가치를 가장 잘 보여주는 것 같습니다. 일단 prediction Rollout을 4가지 카테고리인 Success ID, Success OOD, Fail ID, Fail OOD 로 나눕니다. 핵심은 Success OOD와 Fail ID를 얼마나 잘 구분하느냐인데요. 이 Figure 4의 결과를 보면, 우선 좌측 세 부류의 Observation-based scores 에서는 저자들이 제안한 RND-OE가 PCA-kmeans, logpZO보다 Success OOD와 Fail ID 사이의 gap이 더 큰 모습을 보입니다. 그리고 우측 세 부류의 Action-based scores를 보면, 저자들이 제안한 ACE가 RND-A, STAC보다 Success OOD와 Fail ID 사이의 gap이 더 큰 모습을 보입니다. 전반적으로는 action-based score에서의 Fail-Success gap이 observation-based보다 작은 경향성이 생겼는데, 저자들은 이게 failure를 action output만으로 잡는 게 observation보다 어렵다는 것을 시사한다고 합니다. 이로써 observation과 action을 결합해야 하는 이유를 실험적으로 어필하고 싶었던 것 같습니다.
2. Baseline 비교
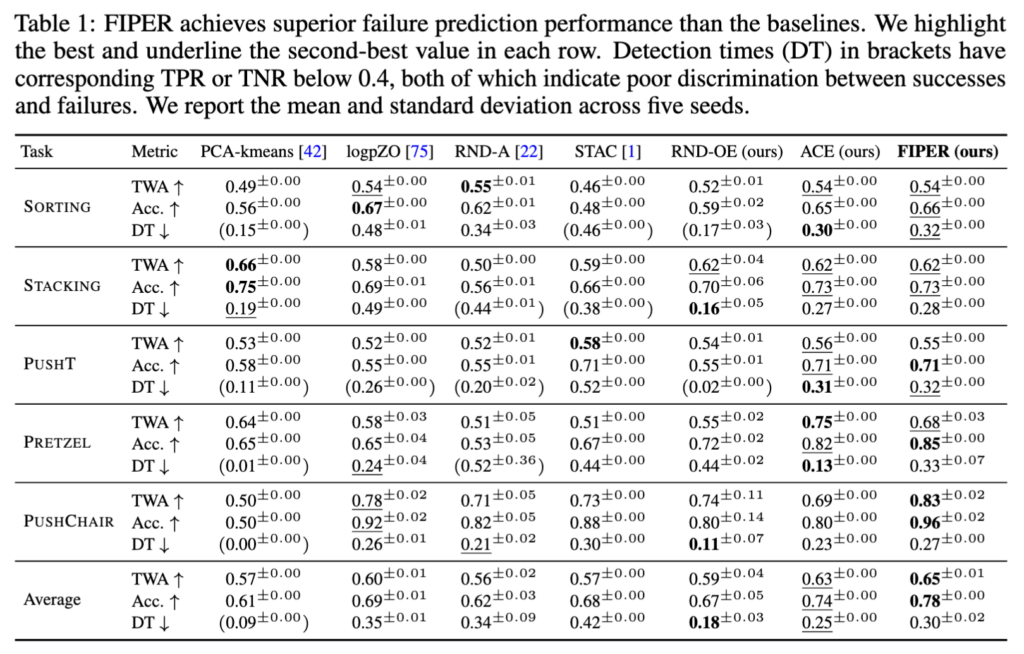
Table 1은 baseline 대비 전체 성능 비교인데, FIPER가 average TWA 0.65, Accuracy 0.78, TPR 0.92로 대부분의 baseline을 준수하게 넘는 모습을 보입니다. 근데 살짝 찝찝하기도 하네요. 아예 막 높은 모습은 아닙니다. 그래도 FIPER가 DT에 있어서는 전반적으로 PCA-kmeans를 제외하면 그렇게 느리지 않은 모습을 보여주네요. runtime failure prediction 관점에서는 어필이 많이 된 듯해보이고, 저자들의 각 sub모듈들은 AND 결합의 필요성으로써 성능이 어필된 듯 합니다.
3. AND 결합의 효과
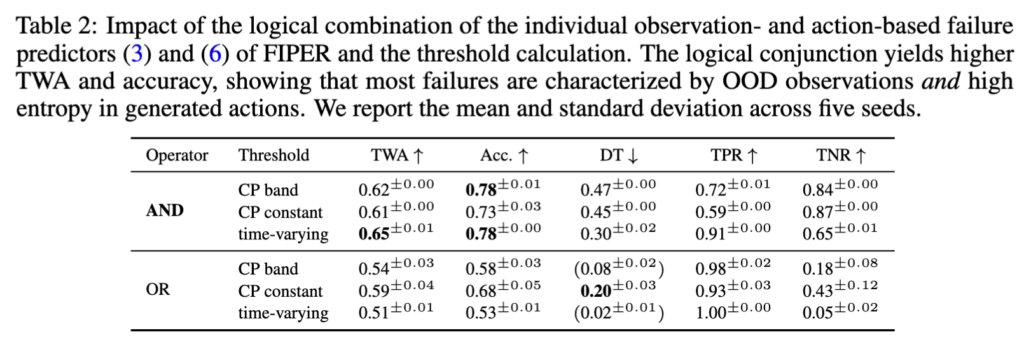
AND가 OR 대비 TNR(실제 성공을 성공이라고 예측)은 엄청 개선하면서 TPR(실제 실패를 실패라고 예측)은 많이 잃지 않는 준수한 성능을 보입니다. CP-based threshold(band, constant)는 높은 TNR을 달성하지만 DT가 늦어지는 경향이 있는데, 저자들은 이를 failure prediction보다는 failure detection에 더 적합하다고 분석했습니다. Time-varying threshold는 가장 높은 TWA를 보여서 prediction 관점에서는 이 방식의 threshold 지정이 best인 것 같습니다. 그 동안 나이브한 CP기반의 threshold 설정만 알고 있었는데, 시계열 도메인의 uncertainty 다 보니 확실히 time-varying mean을 반영하는 게 유의미한 것 같습니다.
4. Sliding Window Aggregation의 효과
기존 방법들과의 비교가 인상적입니다:
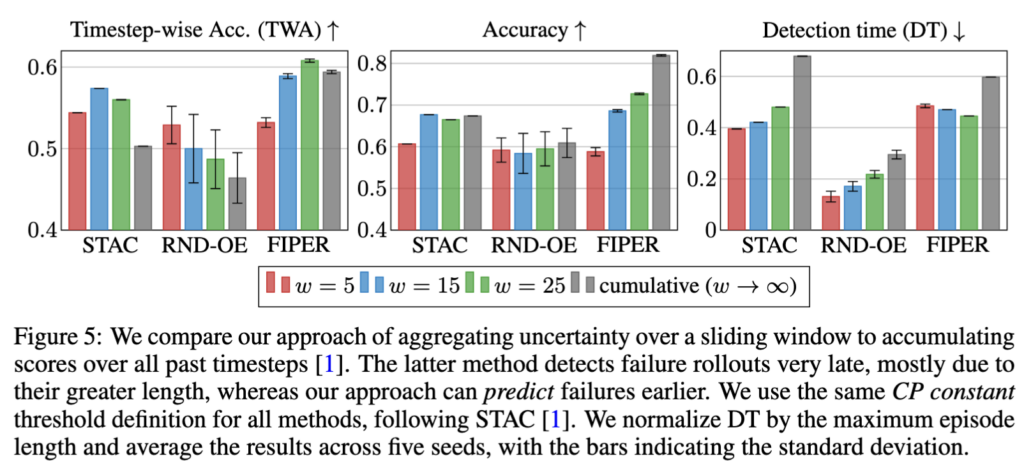
Cumulative score 관점 (Sentinel 방식, Figure 5)
- 일단 FIPER에 대해 Cumulative 방식이 accuracy가 올라가지만 DT가 매우 늦어지는 경향이 보였습니다. 반면 sliding window 기반으로 aggregating하는 방식은 확실히 DT가 낮고 TWA, accuracy도 가장 좋은 경향성을 보여줍니다.
- 이에 대한 저자들의 분석이 좀 있었는데, 이 실험 결과로 미루어보아 cumulative가 failure를 잡는 게 아니라 failure rollout이 더 길기 때문에 자연스럽게 누적 score가 높아지는 것만 포착하는 것이라고 합니다. 즉 failure “prediction”이 아니라 length “detection”에 가까운 형태를 보이는 것이라고 언급합니다.
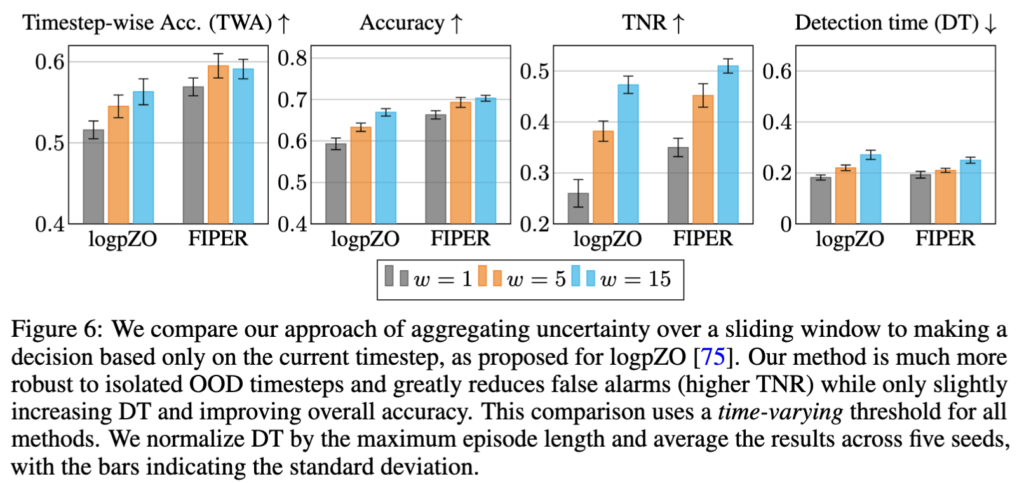
Single-timestep 관점 (FAIL-Detect 방식, Figure 6)
- 이제 single-timestep 관점인데, 비교대상인 logpZO의 경우 단발성 OOD에 너무 민감해서 거의 모든 rollout을 Fail로 판정하는 경향성을 보입니다. 이는 logpZO 가 flow-matching 아키텍쳐 내에서 Observation-only 한 failure signal만 뱉기 때문이고, 이때 action warning sign 놓치면서 single-timestep이라 false alarm 을 많이 뱉게 되는 경향을 보이게 됩니다. 즉 Observation embedding의 flow matching 기반 likelihood 추정으로는 failure signal로 만들기가 쉽지 않다는 방증인 것 같습니다.
그리고 마지막으로 Sliding window의 변화 관점에서 장점을 파악할 수 있었는데, 최근 몇 timestep의 trend만 보므로 early prediction이 가능하면서도 단발성 noise에는 robust한 장점이 있다고 합니다. 또한 저자들의 실험에서 최적 window size는 method와 threshold type에 따라 다르지만, 대체로 w=15~50 범위에서 좋은 TWA를 보인다고 합니다.
논문에서 conclusion 쯤에 large-scale VLA로의 확장에 대한 future work를 언급을 했었는데, VA/VLA 쪽에서 생각보다 architecture agnostic한 방법론이 될 수도 있겠단 생각이 듭니다. 전반적으로 수식이 많고 큰 틀의 맥락은 쉬웠지만 세세한 수식을 이해하기는 좀 오래걸렸는데요. table1의 실험이 약간 찝찝한 경향성을 보이긴 하지만, 전반적인 논리구조는 탄탄한 모습을 보였습니다. 특히 metric이나 threshold선정을 위한 CP의 time-varying한 수식 접근은 제가 잘 활용해먹으면 좋을 것 같습니다. 이상 리뷰 마치겠습니다. 감사합니다.
재찬님 좋은 리뷰 감사합니다.
저자들은 실패를 예측해서 선제적으로 인지하고자 하였고, 4.2절이 이에 해당하는 방법론으로 이해하였습니다. 저자들은 “2개의 tight mode가 잘 분리된 distribution”으로 해당 방법론을 설계하였다고 이해하였는데, 분리된 distribution들은 특정 time-step의 결과들이 되는 것으로 이해하면 될까요? 또한, Figure 3의 (c)와 (d)의 중간에 있는 회색 점은 어떤 것을 의미하는 것인지 궁금합니다.
마지막으로, 저자들은 해석 가능하도록 end-effector position을 이용하였다고 하셨는데, joint velocity 및 angle을 이용하는 방식도 가동 범위나 이런 물리적 정보든 어떤 정보로서 유의미하지 않을까 합니다. 그런 관점에서 end-effector의 위치를 해석하는 게 행동의 uncertianty 관점에서 가장 중요한 요소인지 재찬님의 의견이 궁금합니다.
안녕하세요 승현님, 좋은 질문 감사합니다.
1. 맞습니다. ACE는 각 timestep 자체의 엔트로피만 보고 sharpness(생성될 수 있는 액션 모드가 얼마나 뾰족한지)를 독립적으로 측정하는데, 이 때 한 시점의 샘플들로부터 엔트로피를 추정하여 합산하는 방식입니다. 그래서 Figure 3에서 논문의 주장 핵심은 기존 방법론이 “두 청크의 겹치는 분포 간 divergence”을 비교해 temporal inconsistency를 잡으려다 정상적인 모드 전환 순간에도 큰 divergence를 기록해 오탐을 유발할 수 있다는 점이 문제라고 지적하는 반면, ACE는 각 timestep 자체의 엔트로피만 보기 때문에 t에서 t+h로 모드가 바뀌어도 각 시점의 엔트로피가 자체가 낮다면 오탐을 일으키지 않는다고 주장한 것으로 이해해주시면 됩니다.
2. 음 회색점은 사실 논문에 명시되어 있지 않아서 저도 유추하면서 이해할 수 밖에 없었는데, 아마 피해야하는 장애물이 놓인 상황을 묘사한 것 같습니다.
3. 작업이 비교적 단순하다면(singularity를 크게 고려하지 않아도 된다면..?) 저자들이 제안한 것처럼 cartesian space에서 EEF trajectory에 대한 불확실성이 좀 더 직관적이고 task‑relevant하겠지만, 만약에 연구가 추후 발전되어 contact가 중요한 작업이나, 장애물 회피 등의 더 역동적인 동작에서는 joint space에서의 uncertainty 가 더 유의미할 것 같긴합니다. 특히 승현님이 말씀해주신대로 joint velocity나 torque 정보까지 저희가 접근할 수 있다면 더 그럴 것 같습니다.