Abstract
Vocabulary-free fine-grained image recognition은 사람이 사전에 정의한 라벨 집합이 없어도, 동일한 meta-class 내부에서 시각적으로 유사한 세부 카테고리를 구분하는 것을 목표로 합니다. 기존 연구들은 사전에 정의된 어휘 리스트가 있거나, 복잡한 파이프라인과 휴리스틱한 설계에 의존하여 오류가 누적된다는 한계가 있습니다. 해당 논문의 저자들은 LLMs이 시각-언어 정보를 이해하고, 문제를 분해하며, latent 지식을 찾고, 스스로 오류를 수정하는 능력을 갖추고 있기 때문에 효과적으로 이러한 문제를 해결할 수 있다고 보았고, FiNDR(Fine-grained Name Discovery via Reasoning)이라는 새로운 프레임워크를 제안합니다. 핵심 아이디어는 정답 class 이름이 없어도 모델이 스스로 적절한 이름을 생성하고 이를 활용하여 분류를 수행하는 것으로, 3단계로 동작합니다. (1) reasoning 능력을 갖춘 LLM으로 각 이미지에 대한 설명적인 후보 라벨들을 생성한 뒤, (2) VLM이 후보 이름을 검증하고 순위를 매겨 일관성 있는 class 집합을 구성합니다. 마지막으로 (3) 검증된 이름들을 기반으로 lightweight multimodal classifier를 학습하거나 구성하여 추론 단계에 활용합니다. 이러한 파이프라인에 사람이 정의한 분류체계가 없어도 모델이 자동으로 fine-grained category space를 구성하게 됩니다. 저자들은 실험을 통해 vocabulary-free 세팅에서 SOTA를 달성하였으며, 사람이 사전에 정의한 GT class를 사용하는 zero-shot baseline 보다도 더 좋은 성능을 달성하였다고 합니다. 이를 통해, 사람이 정의한 vocabulary가 성능의 upper bound라는 기존의 가정을 반박하였습니다. 또한 다양한 실험 결과를 통해 reasoning-augmented LMM 기반 open-world fine-grained recognition의 가능성을 시사하였습니다.
Introduction
Fine-grained image classification은 미세한 특징을 활용하여 유사한 카테고리르 구분하는 것을 목표로 합니다. 기존 연구들은 대부분 전문가가 사전에 정의한 방대한 크기의 vocabulary에 의존합니다. 그러나 특정 도메인 카테고리에 대한 사전 지식이 불완전하거나 전혀 존재하지 않는 경우가 존재할 수 있으며, 이러한 의존성에 의해 open-world 환경으로의 일반화 능력이 제한됩니다. 이러한 이유로 미리 정의된 categorical vocabulary 없이 이미지를 분류하는 vocabulary-free fine-grained recognition 연구가 떠오르고 있다고 합니다.
vocabulary-free 방법론은 크게 clustering 기반 방식, predefined vocabulary를 사용하는 zero-shot 방식, VLM이나 LLM을 활용한 dinamic vocabulary discovery 방식 3가지로 구분됩니다. clustering 기반의 방식은 시각적 특징에만 의존하므로 실제 물체의 이름이 필요한 상황에는 활용이 어렵습니다. zero-shot 기반의 방식은 일반화 능력이 우수하지만, 여전히 한정된 vocabulary에 의존하므로, label이 없거나 노이즈가 많은 경우에는 어려움을 겪게 됩니다. 이를 해결하기 위해 dynamic vocabulary discovery 기반의 방식이 제안되었으며, 이는 unlabeled image를 활용하여 잠재적인 class를 발견하는 방식입니다. 그러나 이러한 방식은 복잡한 low-data 상황을 가정하며, 여러 단계를 거쳐야하므로 오류가 누적되는 문제가 발생할 수 있다고 합니다. 또한, LLM이 생성하는 attribute가 이미지에 특화되어있지 않아 intra-class diversity나 이미지 변화가 존재하는 경우 신뢰성이 떨어지는 문제가 발생합니다.
저자들은 최근 뛰어난 일반화 능력과 추론 능력을 갖춘 LMM(large multi-modal model)을 vocabulary-free fine-grained setting에 적용하고자 하였습니다. 따라서 reasoning 기법을 통해 강화된 최신 LMM의 방대한 지식을 통해 카테고리에 대한 사전 지식이 없는 완전 자동화된 vocabulary-free fine-grained recognition 시스템 구축을 연구하였습니다. 먼저 reasoning이 가능한 LMM이 unlabeled 이미지에 대해 descriptive candidate class name을 생성한 뒤, 성능이 뛰어나 VLM이 이 candidates를 필터링하고 순위를 매겨 최종 category list를 만들어냅니다. 마지막으로 생성된 class name들을 활용하여 효율적인 VLM 기반의 mulit-modal classifier를 구성하고 추론 단계에 활용합니다. 이러한 자동화된 방식은 foundation 모델의 풍부한 지식을 활용하면서, VLM을 검증에 사용하므로써 고정된 vocabulary나 사람이 설계한 사전지식이 없어도 open-world 시나리오에서 동작 가능하도록 합니다.
저자들은 다양한 fine-grained 벤치마크에 대한 실험을 통해 제안한 방식이 vocabulary-free setting에서 SOTA를 달성함을 보였으며, 특히 GT class name을 vocabulary로 사용하는 zero-shot classification 방식보다 더 좋은 성능을 보인다는 실험 결과를 통해, 기존의 upper bound로 간주되던 사람의 설계보다 더 효과적인 방식이 있다는 가능성을 시사하였습니다. 또한 고품질의 응답을 유도하기 위한 프롬프트 디자인 방식과 추론 전략을 분석하였으며, open-source LMM도 closed-source 모델과 경쟁 가능함을 실험적으로 보였다고 합니다.
해당 논문의 contribution을 정리하면
- 처음으로 reasoning-aubmented LMM 방식을 vocabulary-free fine-grained visual recognition 에 적용
- 완전 자동화된 새로운 프레임워크(FiNDR, Fine-grained Name Discovery via Reasoning)를 제안하였으며, 사전 지식과 사전에 정의된 vocabulary를 사용하는 방식보다 18.8% 이상 성능이 개선된 SOTA 달성
- 저자들이 제안한 FiNDR 방식이 “upper bound”로 여겨지던 인간이 정의한 GT class name을 사용하는 zero-shot classifier보다 더 뛰어난 성능을 달성하였으며, 이러한 발견을 통해 사람이 설계한 vocabulary의 우월성에 대한 의문 제기
- 다양한 public/private LMM에 대한 프롬프트 디자인 및 reasoning 전략을 심층 분석하여, open-source 모델이 proprietary 모델 수준의 성능을 달성할 수 있는 가이드 제공
Method
Problem Formulation
해당 논문은 vocabulary-free 세팅에서 fine-grained visual recognition를 목표로 합니다. 잠재적인 class를 발견하기 위해 매우 적은 수의 N개의 unlabeled image로 구성된 초기 discovery set \mathcal{D}_{disc}=\{x_i\}^N_{i=1} ⊂ \mathbb{R}^{H⨉W⨉C}을 가정합니다. 이때 중요한 것은, 사전 정의된 class tag나 attribute 메타데이터 등의 정보를 사용하지 않는다는 것 입니다.
평가단계에서는 query 이미지 x \in \mathcal{D}_{test}에 대해 semantic label \mathcal{c} \in \mathcal{C}을 할당해야하며, vocabulary \mathcal{C}는 사전에 알려져 있지 않습니다.
즉, mahcal{D}_{disc}에 존재하는 시각적 정보만을 활용하여 그럴듯한 label list \mathcal{C}를 유도해야 하며, 각 query instance에 대하여 가장 적절한 이름을 매핑하는 function f:\mathcal{D}_{test} → \mathcal{C}을 정의해야 합니다.
Fine-grained Name Discovery via Reasoning(FiNDR)
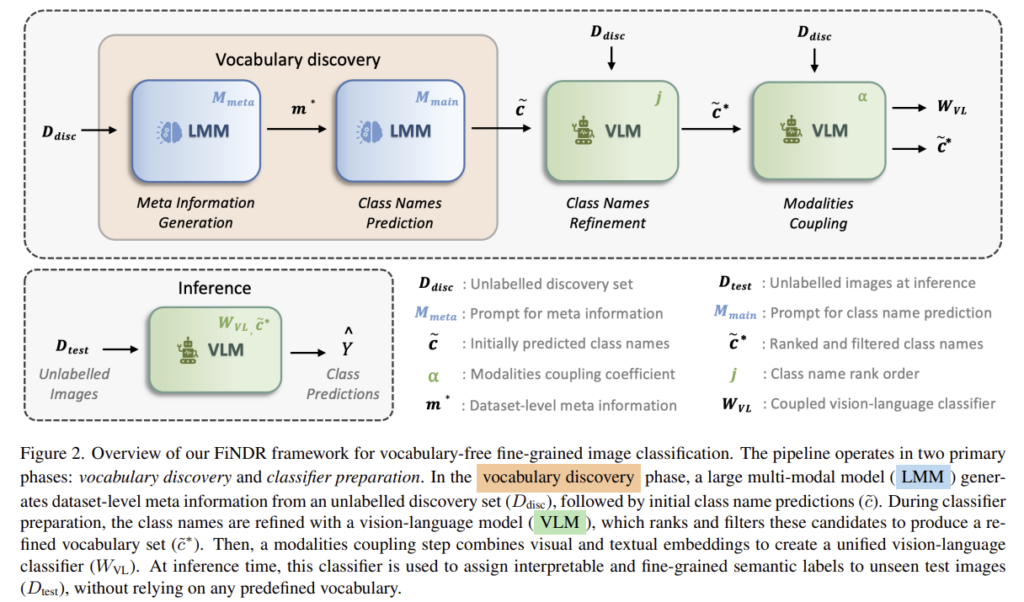
1. Vocabulary Discovery via Reasoning
먼저, 고품질의 class name 예측을 위해, reasoning에 특화된 LMM에서 효과적이라고 알려져있는 CoT 방식을 적용합니다. 구체적으로 mahcal{D}_{disc}에 포함된 이미지 x_i에 대해 LMM은 순차적으로 2단계의 질의를 통해 이미지 속 객체에 대한 메타 정보를 예측한 뒤, 해당 객체의 class name 후보를 생성합니다. 이 두가지 단계에 대한 프롬프트를 \mathcal{M}_{meta}와 \mathcal{M}_{main}으로 정의합니다.
구체적으로, 먼저 discovery set에서 무작위로 샘플링한 3개의 이미지 집합 \mathcal{S}=\{x_a,x_b,x_c\}를 입력으로 사용하여 dataset-level 메타 정보 m^{\star}=\mathcal{M}_{meta}(\mathcal{S}) = (c^{meta},u^{type},e^{expert})를 얻습니다. 여기서 (c^{meta},u^{type},e^{expert})는 순서대로 “이 데이터셋이 어떤 상위 카테고리인지”, “어떤 수준 단위로 세분화해야 하는지”, “어떤 전문가 관점이 필요한지”를 의미합니다.
이후 각 이미지는 메타 정보 m^{\star}와 함께 동일한 모델에 입력되어 두번째 프롬프트 \mathcal{M}_{main}을 통해 unique fine-grained label \tilde{c}_i = \mathcal{M}_{main}(x_i,m^{\star})을 생성합니다. \tilde{c}_i는 초기 class name 후보 집합 \tilde{\mathcal{C}}에 속하며, 모든 raw prediction \tilde{c}_i에 대해서는 후처리를 통해 사용할 수 없는 출력은 제거하여 사용합니다. 후처리 과정은 단어에 대하여 정규화를 적용하고 문법적으로 손상되거나 지나치게 일반적인 이름을 제거하는 작업을 거치게 되며, 정제된 라벨이 최종 induced vocabulary \tilde{\mathcal{C}}를 구성합니다.
2. Class Name Refinement
앞서 구성된 라벨 집합 \tilde{\mathcal{C}}가 그럴싸하더라도, 일부의 경우 데이터 셋 이미지를 제대로 대표하지 못할 수 있습니다. 이를 해결하기 위해 저자들은 CLIP과 같은 vision-language encoder를 추가로 사용하여 \tilde{\mathcal{C}}의 text embedding과 \mathcal{D}_{disc}에서 추출한 visual feature를 비교하므로써, 텍스트와 이미지를 정렬합니다. 모든 후보 라벨 \mathcal{c} \in \tilde{\mathcal{C}}에 대한 텍스트 embedding \mathbf{t}_c와 모든 이미지 embedding \mathbf{v}_i \in \mathcal{D}_{disc} 사이의 평균 cosine similarity를 계산하여 visual relevance score 를 계산합니다.
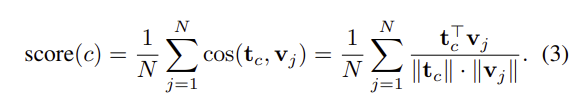
이 score를 기준으로 후보의 랭킹을 정한 뒤, 가장 높은 점수를 가진 항목들만 남겨 refined vocabulary \tilde{\mathcal{C}}*⊆\tilde{\mathcal{C}}를 구합니다. 이러한 필터링을 통해 라벨의 semantic space를 데이터 셋의 visual 정보와 잘 일치하는 이름들로 제한하였다고 합니다.
3. Vision-Language Modalities Coupling
다음으로, 저자들은 텍스트 정보만으로 모호함이 존재하므로, 시각적 정보를 텍스트 embedding과 결합하여 동일 카테고리에 속하는 이미지들에 정보를 보완하고자 하였습니다. 저자들은 이 과정이 사람의 개입 없이 자동 생성된 라벨만을 사용된다는 점을 강조합니다.
구체적으로. 먼저 refined vocabulary \tilde{\mathcal{C}}*에 대한 text embedding을 통해 text classifier를 생성합니다. 여기에 시각 정보를 결합하기 위해, discovery image에 대하여 가장 높은 cosine similarity가 할당된 pseudo labeled sample 집합 \mathcal{U}_c를 구성하며, 이때 너무 적은 수의 샘플로 인한 다양성 문제를 완화하기 위해 random crop과 horizontal filp을 포함하는 간단한 augmentation을 K=10 번 적용하여 평균을 구한 visual classifier \mathbf{v}_c를 구합니다.
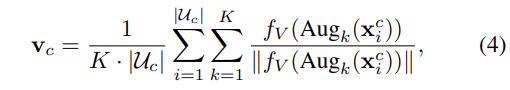
마지막으로, text representation과 visual representation을 결합하여 최종 vision-language classifier를 만듭지막으로, text representation과 visual representation을 결합하여 최종 vision-language classifier를 만듭니다. (알파값은 결합 계수로 실험시에는 0.7로 설정하였다고 합니다.)
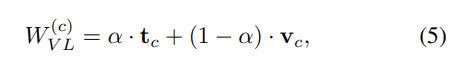
이를 통해 두 모달리티의 상호보완적 장점을 활용하여 잘못 추정된 textual class name에서 발생할 수 있는 문제를 완화하고자 하였다고 합니다.
4. Inference
마지막으로 테스트시에는, unseen 이미지 x \in \mathcal{D}_{test}에 대해 visual embedding을 추출한 뒤, refined label \tilde{\mathcal{C}}*에 대한 모든 프로토타입 W_{VL}과 비교하여 클래스를 할당합니다.
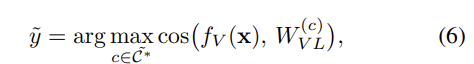
여기서 cosine metric은 이미지임베딩과 각 vision-language class representation 사이의 정렬 정도를 측정하며, 최종 예측 결과가 사람이 읽을 수 있는 semantic name이라는 점에서 해석 가능성과 실제 환경에 적용이 용이하도록 한다는 점을 어필합니다.
이러한 과정을 통해 저자들은 사전 정의된 vocabulary나 학습, 감독 없이도 자동화된 fine-grained visual recognition이 가능하다는 점을 강조합니다.
Experiments
Datasets
저자들은 vocabulary-free 세팅에서 5가지의 대표적인 fine-grained visual recognition 벤치마크 CUB-200 (Birds-200), Stanford Cars (Cars-196), Stanford Dogs (Dogs-120), Oxford Flowers (Flowers-102), Oxford Pets (Pets-37)를 사용합니다. 평가 프로토콜은 기존 연구들을 따르며, low-resource 시나리오를 모사하기 위해 discovery set에서 클래스당 unlabeled image 수를 3개로 제한하고, 랜덤하게 샘플링하도록 합니다. 각 test set은 그대로 평가에 사용하였으며, discovery set과 test set의 교집합이 존재하지 않도록 하였다고 합니다.
Evaluation Metrics
vocabulary-free 세팅에서는 모델이 생성한 label 집합에 GT 라벨과 정확히 대응이 되지 않을 수 있으므로, 이러한 상황에도 성능을 평가하기 위한 상호보완적인 평가지표를 사용한다고 합니다. cACC(clustering accuracy)와 sACC(semantic accuracy)로, cACC는 예측된 label이 정확한지와 무관하게, 동일 클래스들이 얼마나 잘 묶여있는지 평가하는 것이며, sACC는 라벨의 의미론적 퀄리티를 평가합니다. sACC는 frozen language model을 이용하여 예측된 class name와 GT category 사이의 semantic relevance를 측정하며, 완전 동일한 이름이 아니더라도, 의미론적으로 유사할 경우 높은 점수를 부여하는 방식이라 합니다. 즉, cACC는 시각적 일관성을 평가하고, sACC는 언어적 연관성을 평가하는 방식입니다.
Comparison with SOTA
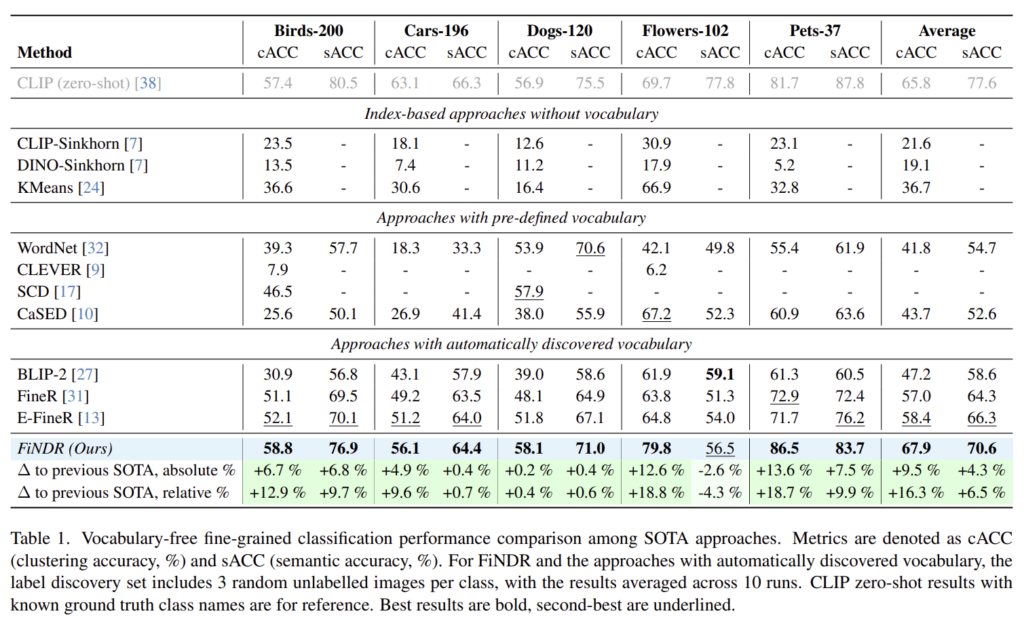
Table 1은 5가지 벤치마크에 대한 성능을 나타낸 것으로, unsupervised clustering(KMeans, Sinkhorn variants), retrieval 기반 방식(WordNet, CaSED), VQA(BLIP-2) 방식, open-vocabulary 방식(FineR, E-FineR)을 함께 비교합니다. 실험 결과, FiNDR는 모든 데이터 셋에서 평균적으로 기존 방식들을 능가하였으며, cACC와 sACC 두 지표 모두 우수한 성능을 보여주었습니다. 이를 통해 FiNDR 방식의 성능을 입증하였으며, 특히 CUB-200과, Dogs-120처럼 미세한 구분이 필요한 데이터셋에서 FiNDR 의 성능 향상이 두드려지는 결과를 보였다고 합니다. 이러한 결과는 FiNDR가 시각적 유사성을 포착할 뿐만 아니라, semantic relationship도 고려한 fine-grained label을 생성할 수 있음을 의미합니다.
저자들은 이러한 성능 향상의 핵심 원인으로 reasoning 능력을 강조합니다. 기존 SOTA 방식들이 사전에 정의된 vocabulary나 여러 단계의 파이프라인에 의존한 것과 달리, FiNDR는 이미지에 대한 직접적 reasoning과 visual feature 기반의 동적 label 생성을 수행합니다. 따라서 단순 clustering보다 더 정확하고 의미론적으로 부합하는 label을 부여할 수 있었다고 설명합니다.
한편, Flowers-120에 대해 sACC 향상폭은 +2.5%로 상대적으로 작았는데, 이는 FiNDR가 시각적으로 정확하지만 GT 라벨과 완전히 일치하지 않는 이름을 생성하는 경우가 있었기 때문이라고 분석하였습니다.
Analysis and Discussion
1. Vocabulary Quality

Figure 1은 사전에 정해진 vocabulary 없이 생성된 class name의 품질을 평가하기 위해 Oxford Pets 데이터 셋에서 FiNDR와 기존 SOTA 방법론인 FineR에 대한 정성적 결과를 비교한 것 입니다. 저자들은 예측된 라벨은 similarity score 기준으로 정렬되며 상위 3개와 하위 3개에 대한 예측 및 분석을 진행하였습니다.
상위 예측 결과 FiNDR는 일관되게 예측을 잘 하였으며, semantic precision이 높은 라벨을 생성하였으나. FineR(왼쪽)의 경우 부분적으로만 맞는 라벨을 생성하기도 하는 것을 확인할 수 있습니다. FineR는 “English Cocker Spaniel” 대신 “American Cocker Spaniel”을 예측하는 경우가 존재하며, FiNDR는 “Egyptian Mau”나 “Staffordshire Bull Terrier”와 같이 정확한 종을 안정적으로 식별하였습니다.
하위 예측 결과 분석또한 FineR는 “Possible Cat Breeds”처럼 지나치게 일반적이거나, 흰 털의 개를 “Golden Retriever”로 잘못 분류하는 등 문제가 발생하였으며, 저자들은 이 원인을 여러 단계의 오차가 누적되었기 때문이라고 보았습니다. 반면, FiNDR는 confidence가 낮은 경우에도 의미론적으로 그럴듯한 예측을 만들어내었습니다.
이러한 분석을 통해 저자들은 FiNDR가 의미론적으로 정확성이 높은 fine-grained label 생성이 가능하다는 점을 어필하였으며 의미론적 정보 뿐만 아니라 시각적 단서도 결합하므로써 상위 및 하위 예측에서 모두 개선이 이루어졌음을 보였습니다.
2. Label Semantics
저자들은 다음으로 cACC와 sACC 사이의 discrepancy를 설명합니다. FiNDR는 뛰어난 cACC를 통해 시각적으로는 구분을 잘 하고있음을 보였으나, sACC는 비교적 제한적인 개선이 이루어졌습니다. 이에 대해 저자들은 FiNDR가 라벨을 정확하게 예측하였음에도 dataset의 GT 라벨과는 정확히 일치하지 않는 경우가 있기 때문이라고 분석하였습니다. 이는 GT 라벨의 경우 학명(Helianthus Annuus)이나 다른 지역 naming(Mercedes Sprinter)을 사용하는 경우가 있기 때문으로, 유효한 여러 이름을 고려하지 못하기 때문입니다. 따라서 저자들은 현재의 semantic evaluation metric은 실제 semantic quality를 과소평가할 수 있다는 점을 지적하고, 추후 fixed naming 뿐만 아니라 다양한 정답 가능성을 허용하는 평가 방식이 필요하다고 주장합니다.
Ablation study
1. Prompt Design
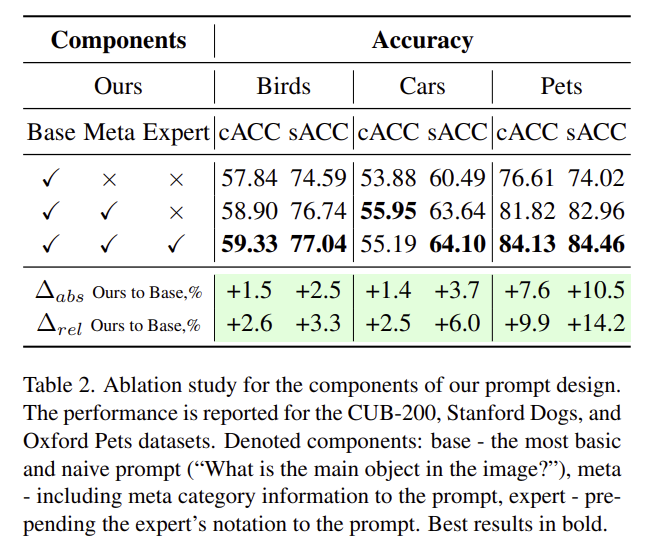
저자들은 prompt 설계시 서로 다른 구성요소들이 vocabulary-free classification에 어떤 영향을 미치는 지 분석하기 위한 ablation study를 수행합니다. 순차적으로 프롬프트를 실험하였으며, Base는 단순히 “what is the main object in the image?”와 같은 직관적인 형태의 질문을 사용하는 방식, Meta는 Base 프롬프트에 추가로 meta-category 정보를 보완한 형태, Expert는 메인 질의 전에 “You are an {expert} in the {field}”와 같은 컨셉을 추가한 방식입니다.
실험 결과, meta-category 정보를 통합하는 것 만으로도 성능이 일관되게 개선되었으며, 어떤 도메인인지를 명시함으로써 더욱 성능이 개선되었음을 보였습니다. 이를 통해 프롬프트에 단서가 포함될수록 성능이 개선되었으며, 특히 어떤 도메인인지를 명시하는 expert annotation을 통해 fine-grained classification에서 성능이 개선된다는 점을 강조하였습니다.
2. Explicit vs. Internal Reasoning
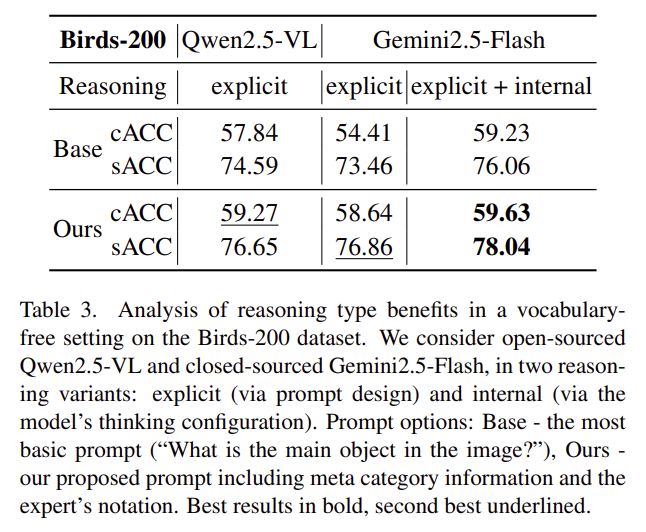
저자들은 추가로 reasoning 전략에 대하여 비교합니다. Explicit reasoning은 단계적 추론 과정을 프롬프트를 통해 “step-by-step”과 같이 명시적으로 제공하는 방식이며, Internal reasoning은 내부에 내장된 추론 방식을 이용하는 것으로, 주로 proprietary LMM에 존재하므로 접근성과 확장성 측면에 한계가 있는 방식입니다.
저자들은 Table 3의 CUB-200에 대한 실험 결과를 통해 explicit reasoning 만으로도 공개 open-source LMM의 성능을 크게 개선시킬 수 있으며, proprietary model과 유사한 성능을 달성할 수 있음을 보였습니다.