이번에 읽은 논문은 universal multimodal retrieval, 줄여서 UMR 이라는 태스크를 다루는 논문입니다. 지금까지도 UMR 에 대한 페이퍼가 계속 나오고 있는데요.
이 논문의 핵심은, 좋은 universal retriever를 만들기 위해서는 단순히 모델 구조만 바꾸는 것이 아니라, 어떤 retrieval setting을 다룰 것인지, 어떤 데이터를 어떻게 구성할 것인지, 그리고 부족한 fused-modal 데이터를 어떻게 보강할 것인지가 중요하다는 점입니다.

- Venue: CVPR 2025
- Authors: Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, Min Zhang
- Affiliation: Hong Kong Polytechnic University, Alibaba Group, Soochow University
- Title: Bridging Modalities: Improving Universal Multimodal Retrieval by Multimodal Large Language Models
0. Background
#UMR (Universal Multimodal Retrieval) 의 등장
이 논문을 이해하려면 먼저 Universal Multimodal Retrieval (UMR) 이 무엇인지부터 설명하겠습니다
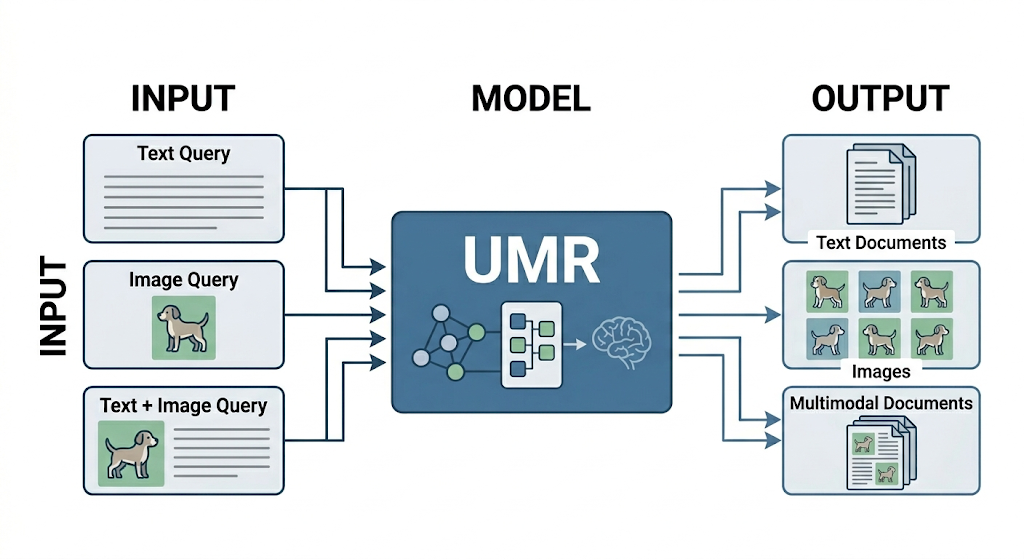
기존 retrieval 연구들은 주로 text-to-text나 text-to-image처럼 하나의 고정된 검색 설정을 다루는 경우가 많았습니다. 하지만 실제 환경에서는 query와 candidate가 꼭 하나의 modality로만 주어지지 않습니다. 텍스트로 이미지를 찾을 수도 있고, 이미지로 텍스트 문서를 찾을 수도 있으며, 텍스트와 이미지가 함께 포함된 입력으로 또 다른 복합 후보를 검색해야 하는 경우도 존재하죠.
결국 실제 retrieval은 생각보다 훨씬 더 멀티모달적이며, 이러한 다양한 상황을 하나의 unified retriever로 처리하려는 필요가 커지고 있습니다. 그리고 이런 태스크를 Universal Multimodal Retrieval (UMR) 라고 합니다.
# UMR setting
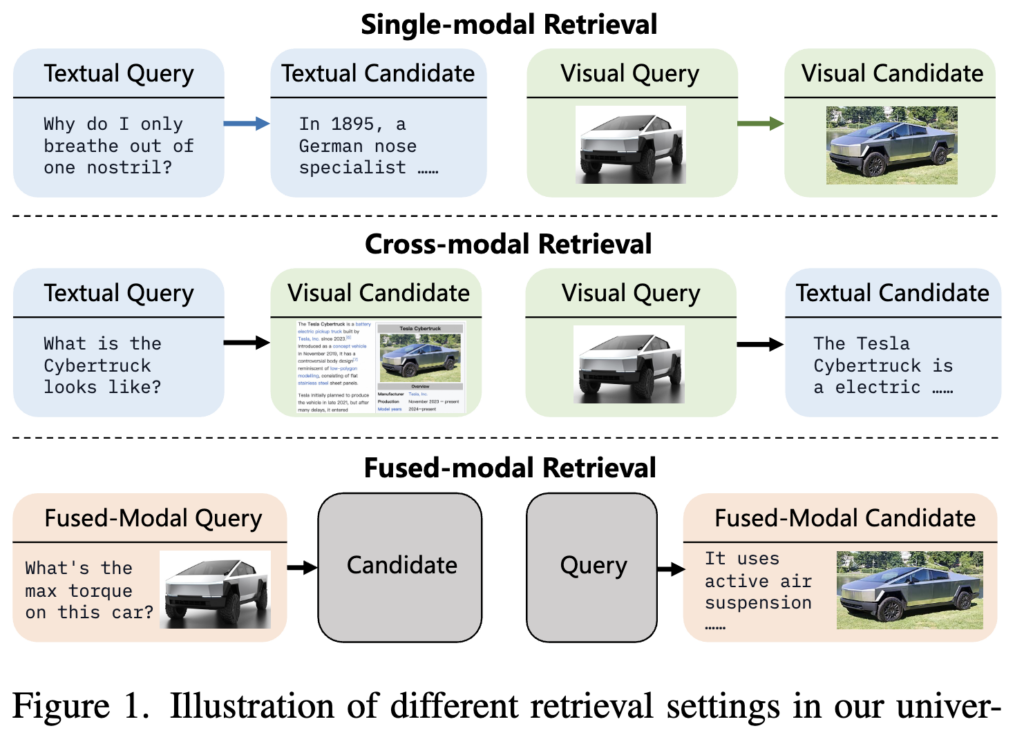
저자들은 UMR을 크게 세 가지로 구분하였습니다. 상단 그림과 이 세 가지 retrieval setting을 예시와 함께 보시죠
첫째, text-to-text나 image-to-image처럼 같은 modality끼리 찾는 single-modal retrieval,
둘째, text-to-image나 image-to-text처럼 modality가 서로 다른 cross-modal retrieval,
셋째, 이미지와 텍스트가 함께 포함된 query나 candidate를 다루는 fused-modal retrieval입니다.
이 분류는 단순한 태스크 소개가 아니라 이후 데이터 구성과 실험 해석의 기준으로 사용되었습니다.
즉, 이 논문은 단순히 멀티모달 retrieval 성능을 높이는 이야기가 아니라, 어떤 retrieval setting까지 포괄해야 truly universal하다고 볼 수 있는지를 먼저 정의하고 시작하는 논문이라고 볼 수 있죠!
1. Introduction
# 기존 연구 흐름
UMR 자체는 새로운 문제처럼 보일 수 있지만, 사실 이와 비슷한 방향의 기존 연구들은 이미 존재했습니다.

대표적으로 *CLIP 계열 기반 방법들은 이미지와 텍스트를 각각 인코딩한 뒤, 이를 fusion하거나 score를 결합하는 방식으로 multimodal retrieval을 수행해 왔습니다. 이런 방법들은 기본적으로 text-image alignment가 잘 되어 있기 때문에 cross-modal retrieval에서는 꽤 강한 성능을 보여주었습니다. 하지만 이미지와 텍스트가 동시에 포함된 fused-modal retrieval까지 자연스럽게 잘 다루는 데에는 한계가 있었습니다.
*[ECCV 2024] UniIR : Training and Benchmarking Universal Multimodal Information Retrievers
또 **text embedding model에 visual plugin을 붙이는 방식 역시 multimodal capability를 확장하는 데에는 효과적이었지만, retrieval setting 전반을 모두 유연하게 포괄한다고 보기는 어려웠습니다.
**[ACL 2024] MARVEL: Unlocking the Multi-Modal Capability of Dense Retrieval via Visual Module Plugin
이후에는 MLLM을 embedding model처럼 활용하려는 방향도 등장했습니다. 그중 ***E5-V가 바로 그 대표적인 논문인데요. 이 모델은 MLLM을 multimodal embedding model로 바꾸어 사용하면서도, 학습 자체는 text pair만으로 진행했음에도 의외로 다양한 modality로 잘 전이되는 결과를 보였습니다. 즉, E5-V에서는 이미 MLLM이 가진 multimodal understanding capability만으로도 어느 정도 universal embedding이 가능하다는 가능성을 보여준 셈이죠.
***[Arvix 2024] E5-V: Universal Embeddings with Multimodal Large Language Models
(제가 이 페이퍼의 경우 리뷰를 했어서 링크 걸어두겠습니다 ^-^ 리뷰 바로가기 (EV-5) )
# 저자들의 아이디어
저자들은 여기서 더 나아간 의문을 가졌습니다. “text-only training만으로도 어느 정도 된다면, multimodal data를 더 다양하게 섞어서 학습하면 더 좋아질 수 있지 않을까?” 특히 기존 방법들은 visual document retrieval을 충분히 다루지 못했고, fused-modal data도 매우 부족했기 때문에, MLLM의 retrieval 잠재력을 끝까지 끌어냈다고 보기 어렵다고 생각했습니다.
# What is VD(Visual Documents)?

여기서 visual document (VD) 라는 개념도 중요하다고 합니다. 먼저 VD는 visual document 로 단순한 자연 이미지가 아니라, 문서 스크린샷이나 text-rich image를 의미합니다. 기존처럼 문서를 단순 OCR text로 변환해서 다루는 대신, 문서 screenshot 자체를 retrieval 대상에 포함해야 한다고 주장하였습니다.
왜냐하면 문서에는 텍스트만 있는 것이 아니라, 레이아웃, 표, 그림, 수식, 시각 단서 같은 정보가 함께 들어 있기 때문이죠. 이런 정보는 plain text로 바꾸는 과정에서 손실될 수 있으므로, visual document retrieval을 UMR의 일부로 포함하는 것이 더 현실적인 설정이라는 것이죠. 이 논문이 기존 UMR 연구들과 차별화되는 지점 중 하나도 바로 이 부분이라고 볼 수 있을 것 같습니다
이러한 내용을 바탕으로 저자들은 두 가지 문제에 집중했습니다.
첫째, UMR에 가장 적합한 학습 데이터 구성은 무엇인가?
둘째, 가장 부족한 fused-modal 데이터를 어떻게 대규모로 확보할 것인가?
그리고 이 질문에 답하기 위해 GME라는 MLLM 기반 retriever와, fused-modal data synthesis pipeline, 그리고 이를 종합적으로 평가하기 위한 UMRB benchmark를 함께 제안합니다. 이제 더 자세한 내용에 대해 다뤄보겠습니다
2. Method
저자들은 먼저 UMR에 어떤 학습 데이터가 필요한가를 따져보고, 그 과정에서 드러난 병목인 fused-modal 데이터 부족 문제를 해결한 뒤, 그 위에서 MLLM 기반 retriever인 GME를 학습시키는 구조를 제안하였습니다
2.1 What training data is best for UMR?
가장 먼저 저자들은 UMR을 잘하려면 어떤 종류의 학습 데이터가 가장 좋을 지에 대해 알아보았습니다. MLLM이 원래 multimodal input을 처리할 수 있다고 해서, 아무 데이터로나 학습하면 바로 universal retriever가 되는 것은 아니기 때문이죠. 특히 UMR은 single-modal, cross-modal, fused-modal retrieval이 모두 섞여 있는 문제이기 때문에, 어떤 modality 조합의 데이터를 얼마나 넣느냐가 성능에 꽤 직접적인 영향을 줄 수 있습니다.
# 학습 데이터 구성에 따른 성능 비교
이를 보기 위해 저자들은 학습 데이터를 네 가지로 나누었습니다.
1. T → T, I → I 같은 single-modal 데이터
2. T → I 와 T → VD 같은 cross-modal 데이터
3. IT → IT 형태의 fused-modal 데이터
4. 이 세 가지를 고르게 섞은 mixed data입니다.
이렇게 같은 GME 구조를 두고, 오직 학습 데이터 타입만 바꾼 ablation을 수행하였습니다.
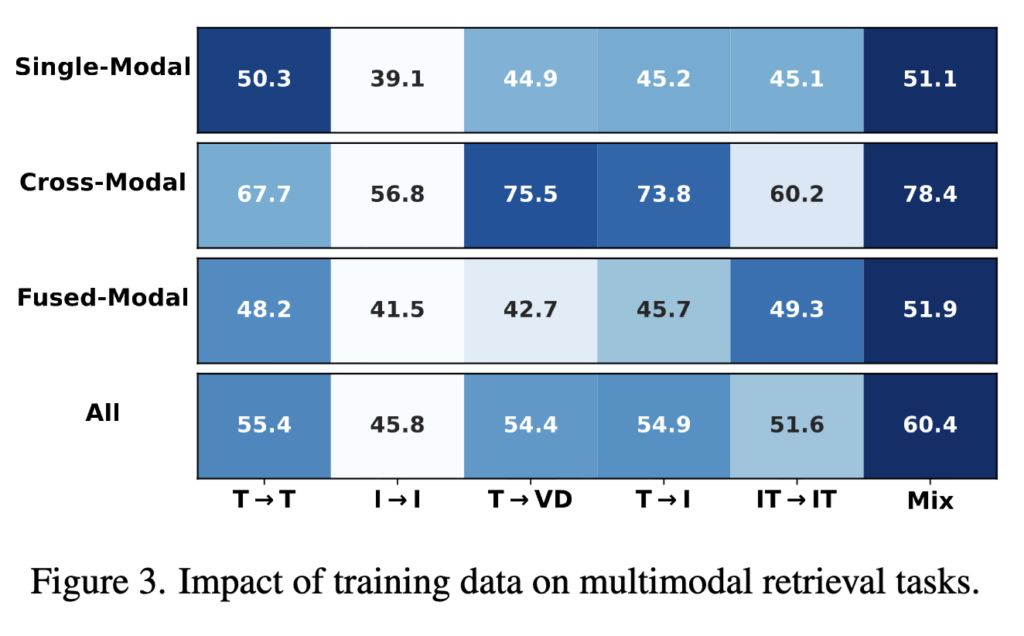
상단 Figure 3이 바로 그 결과입니다. 가로축은 학습 데이터를, 세로축은 평가 유형을 의미합니다. 그리고 같은 행 안에서 색이 진할수록 그 평가 유형에서 더 좋은 성능이라는 뜻입니다. 예를 들어 single-modal retrieval 행에서는 T → T와 Mix 쪽이 상대적으로 더 진하고, cross-modal retrieval 행에서는 T → VD, T → I, 그리고 Mix가 더 진하게 표시됩니다.
결과를 보면 특정 retrieval type에 맞는 데이터로만 학습한 모델은 그 setting에서는 강합니다. 예를 들어 T → T 데이터로 학습한 모델은 single-modal 에 강하고, T → VD, T → I 같은 데이터로 학습한 경우 cross-modal retrieval에 강하죠. 하지만 이렇게 특정 modality에 치우친 데이터만으로는 전체 UMR setting을 고르게 커버하지 못합니다.
반면 여러 modality 조합을 균형 있게 섞은 mixed setting은 모든 retrieval setting에서 가장 안정적인 평균 성능을 보였습니다. 결국 저자들이 여기서 보여주고 싶은 것은, UMR에서는 학습 데이터의 modality diversity가 곧 universality로 이어진다는 점입니다.
다시 말하면, universality는 모델 구조만으로 얻어지는 것이 아니라 training data diversity와도 깊게 연결되어 있죠
2.2 The bottleneck: fused-modal data is scarce
그럼 이제 학습 데이터로 Balanced mixture가 좋다는 점은 알겠는데, 실제로는 여기서 곧바로 문제가 생깁니다. 바로 데이터의 부족 문제입니다.
# Single/Cross vs Fused modal

실제로, single-modal이나 cross-modal 데이터는 비교적 풍부합니다. 예를 들어 text retrieval 쪽에는 MSMARCO 같은 데이터가 있고, image-text 쪽에는 LAION이나 Docmatix 같은 대규모 데이터가 존재하죠. 그런데 정작 mixed training에서 꼭 필요한 fused-modal 데이터는 양도 적고 도메인도 제한적입니다. 논문에서도 EVQA, INFOSEEK, CIRR 등을 예로 들며, fused-modal 데이터가 없는건 아니지만 전체 규모가 작고 다양성도 충분하지 않다고 합니다.
이게 왜 중요하냐면, fused-modal retrieval은 단순히 텍스트와 이미지를 따로 잘 이해하는 것과는 조금 다르기 때문입니다. query나 candidate 안에서 text와 image가 함께 의미를 만들어내는 구조이기 때문에, 이런 조합형 입력을 학습해본 경험이 부족하면 모델이 해당 setting에서 충분히 강해지기 어렵습니다. 다시 말해, mixed training이 좋다는 결론은 얻었지만, 그 mixed training을 실제로 가능하게 만드는 핵심인 fused-modal data가 가장 부족한 상황인 것이죠.
2.3 Fused-modal data synthesis
이 문제를 해결하기 위해 저자들은 fused-modal data synthesis pipeline을 제안하였습니다.
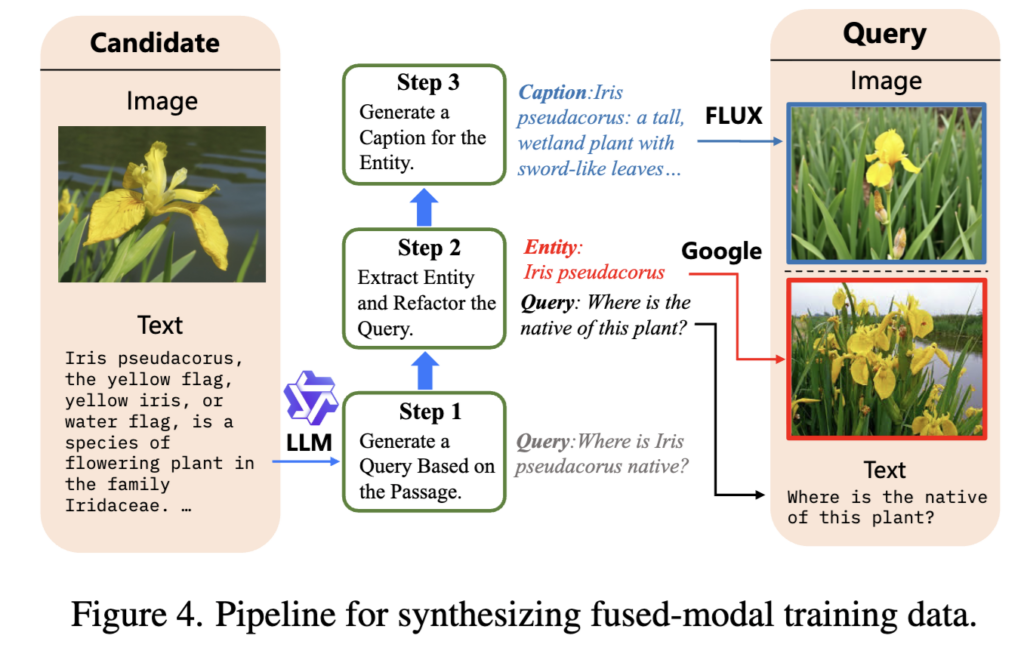
전체 파이프라인은 상단 Figure 4에서 확인할 수 있습니다.
1. Dataset (상단 그림에서는 왼쪽 Candidate에 해당)
먼저 Wikipedia paragraph처럼 이미지와 텍스트가 함께 포함된 candidate를 준비합니다.
2. Doc2Query generation (상단 그림에서는 step 1에 해당)
이후 이 candidate의 text passage를 보고 LLM이 자연스러운 query를 생성합니다.
3. Entity Extraction and Query Rewrite (상단 그림에서는 step 2에 해당)
2단계에서 생성한 query에서 핵심 entity를 추출한 뒤, 그 entity를 참조하도록 query를 다시 작성합니다.
예를 들어 “Where is Iris pseudacorus native?” 같은 query에서 핵심 entity인 Iris pseudacorus 를 추출한뒤, “Where is the native of this plant?”처럼 바꾸는 식이죠! 그러면 query가 단순 텍스트 query가 아니라, 이미지가 함께 주어졌을 때 더 잘 이해되는 fused-modal query가 될 수 있다고 합니다
4. Image Retrieval and Generation (상단 그림에서는 step 3에 해당)
그다음에는 아까 뽑은 entity에 대응하는 이미지를 붙입니다. 방법은 두 가지입니다.
하나는 Google image search를 통해 entity에 맞는 이미지를 찾아서 가져오는 것이고,
다른 하나는 entity와 passage를 기반으로 caption을 만든 뒤 FLUX 같은 text-to-image 모델로 이미지를 생성하는 것입니다.
5. Data Filtering
마지막으로 noisy sample을 줄이기 위해 filtering을 수행합니다. 특히 Google 검색 기반 이미지의 경우 noise가 더 많기 때문에, CLIP relevance score를 이용해 낮은 품질의 image-caption pair를 걸러냈다고 합니다.
# 이렇게 생성한 데이터 예시
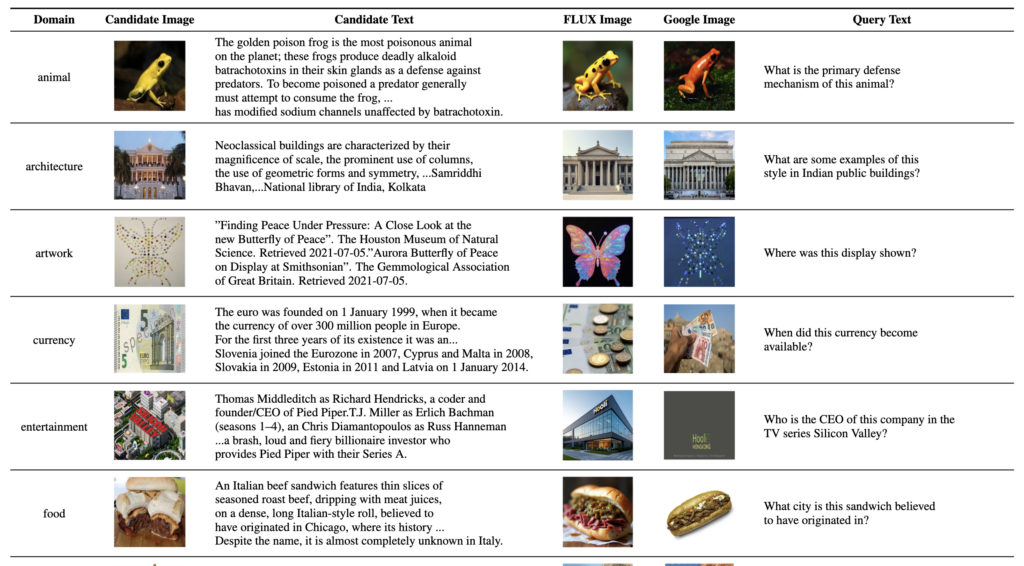
이렇게 해서 저자들은 약 31만 개의 Wikipedia 기반 multimodal candidate에서, 최종적으로 113만 개 이상의 fused-modal pair를 생성하고, filtering 이후에도 약 110만 개를 유지했다합니다. 다시말해, 이 합성 파이프라인은 단순히 보조 데이터를 조금 만드는 수준이 아니라, 부족했던 fused-modal training signal을 대규모로 보충하는 역할을 할 수 있었습니다
2.4 UMRB: evaluation-side benchmark construction
저자들은 학습 쪽에서 synthetic fused-modal data를 보강하는 데서 멈추지 않고, 평가 쪽에서도 기존 세팅의 한계를 보완하려고 합니다. 이를 위해 UMRB(Universal Multimodal Retrieval Benchmark) 를 제안했죠. 이 부분이 중요한 이유는, 앞에서 training-side에서는 fused-modal 데이터를 새로 보강했다면, evaluation-side에서는 universal하다고 부를 수 있는지를 평가하는 벤치마크를 제안했기 때문입니다.
# UMRB 구성
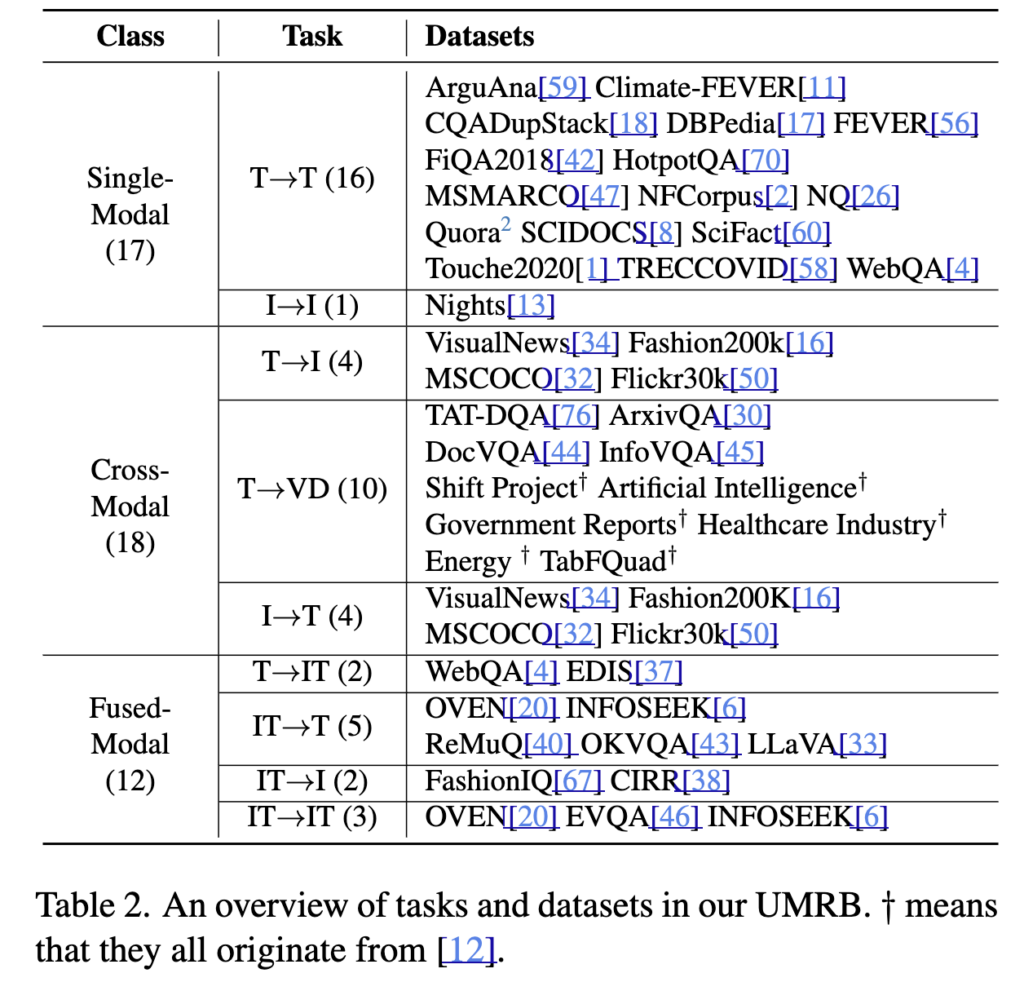
UMRB는 총 47개의 retrieval dataset으로 구성되며, single-modal, cross-modal, fused-modal retrieval을 모두 포함합니다. 구체적으로는 text-to-text, image-to-image 같은 same-modality retrieval뿐 아니라, text-to-image, image-to-text, 그리고 text-to-visual-document retrieval까지 포함합니다. 여기에 더해 text+image가 함께 들어가는 fused-modal retrieval도 포함되어 있어, 이름 그대로 UMR의 여러 하위 설정을 폭넓게 평가할 수 있습니다
세미나 발표에서 어떻게 구현되어 있고, 어떻게 평가하는지에 대한 질문이 있었는데요. 이에 대해 이해하기 쉽게, 쿼리와 타깃 text/image 구성은 아래 예시에 넣어두었습니다.
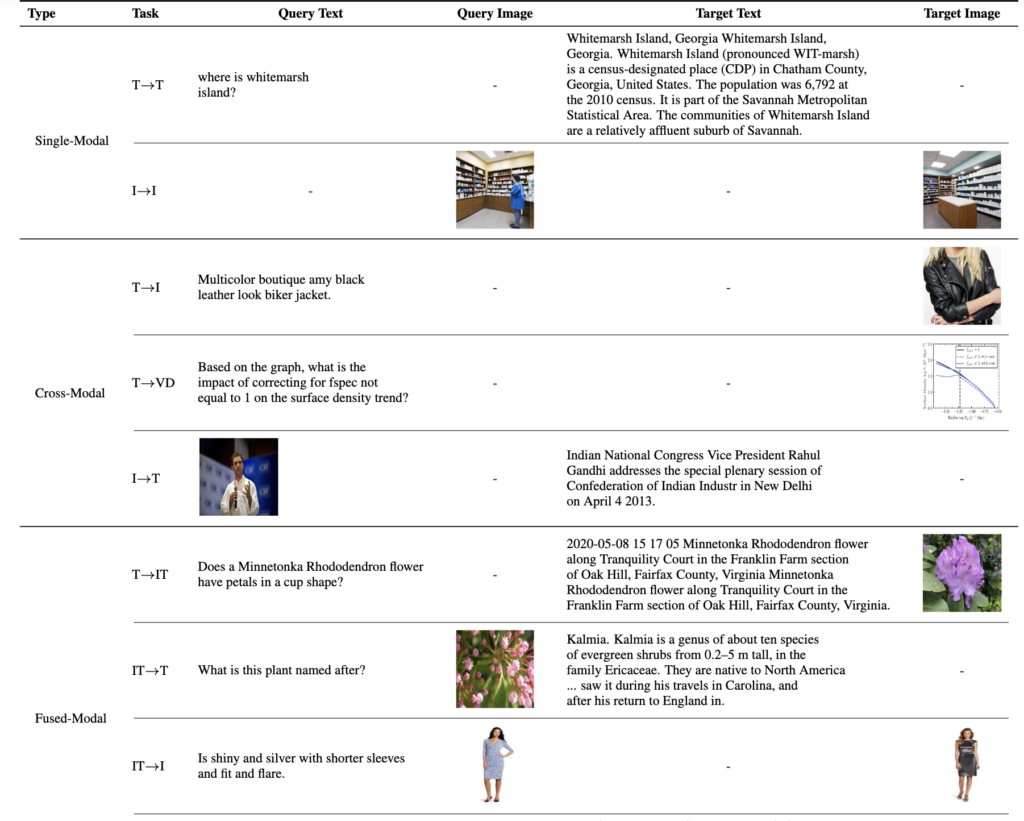
여기서 중요한 점은 T→VD, 즉 text-to-visual-document retrieval을 포함했다는 점입니다. 기존 UMR 연구들은 자연 이미지 retrieval 위주로 평가하는 경우가 많았는데, 저자들은 실제 RAG 환경이나 문서 검색 환경에서는 문서가 plain text가 아니라 screenshot 형태로 존재하는 경우도 많다고 보고, visual document retrieval까지 universal retrieval의 일부로 포함시켰다고 합니다.
2.5 GME: General Multimodal Embedder
자 이제 학습데이터와 평가데이터 구성 설명을 마쳤으니, 모델 설명 차례네요. 저자가 제안하는 GME 라는 Retrieval 모델 설명하겠습니다
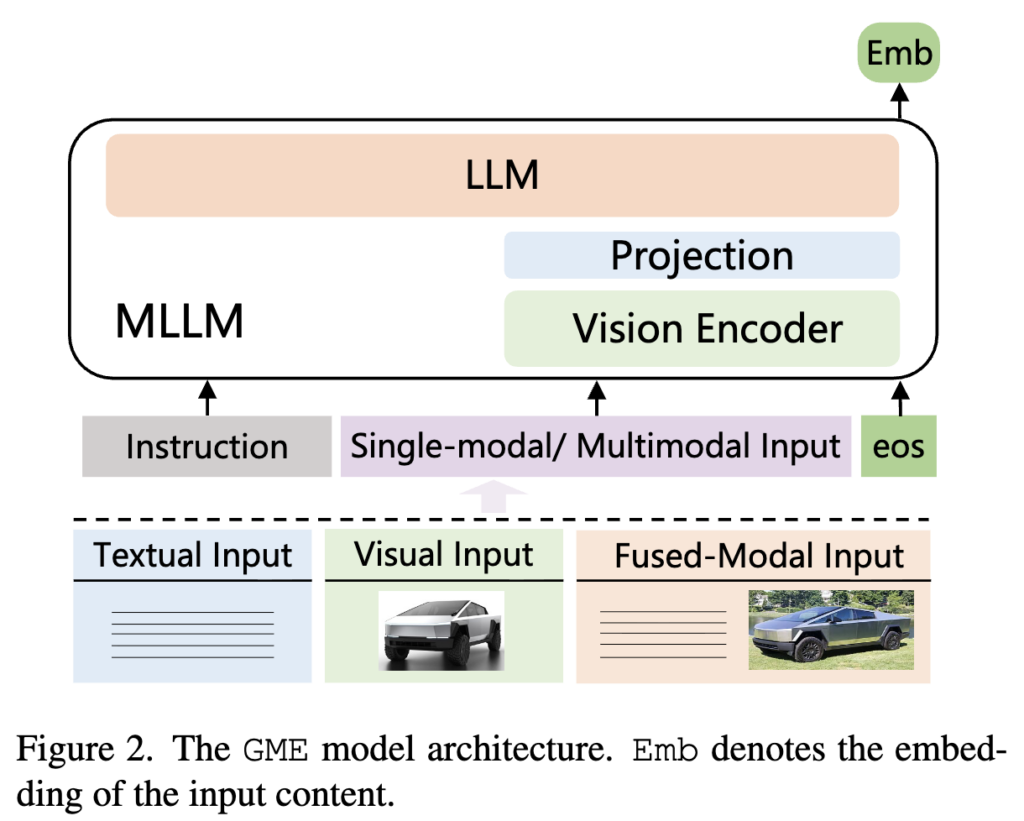
GME의 구조 자체는 생각보다 복잡하지 않습니다. 상단 Figure 2를 보면, 저자들은 Qwen2-VL 계열의 MLLM을 backbone으로 사용하고, text, image, 그리고 text-image가 함께 포함된 fused-modal input까지 모두 하나의 encoder로 처리합니다. query와 candidate는 동일한 encoder를 공유하고, 입력 하나당 embedding 하나를 출력합니다. 즉, 생성 목적의 MLLM을 retrieval embedding model로 fine-tuning해서 dense retriever처럼 사용하는 구조인 것이죠
여기서 중요한 점은 embedding을 만드는 방식이 꽤 단순하다는 것입니다. 저자들은 복잡한 pooling head를 두기보다, 마지막 token의 hidden state, 즉 EOS 위치의 표현을 그대로 embedding으로 사용합니다. 이는 입력 modality가 무엇이든 최종 출력은 하나의 dense embedding으로 통일되기 때문에, 서로 다른 modality 간 비교도 같은 embedding space에서 가능해집니다.
2.5.1 Training objective
학습은 contrastive learning 기반으로 이루어집니다. 각 샘플은 query q, positive candidate c^+, 그리고 여러 개의 negative candidate로 구성됩니다. 이때 q와 c는 텍스트일 수도 있고, 이미지일 수도 있고, image-text pair일 수도 있겠죠? 즉 retrieval setting에 따라 입력 modality는 달라지지만, 모두 같은 방식으로 embedding되고 같은 shared space 안에서 비교됩니다
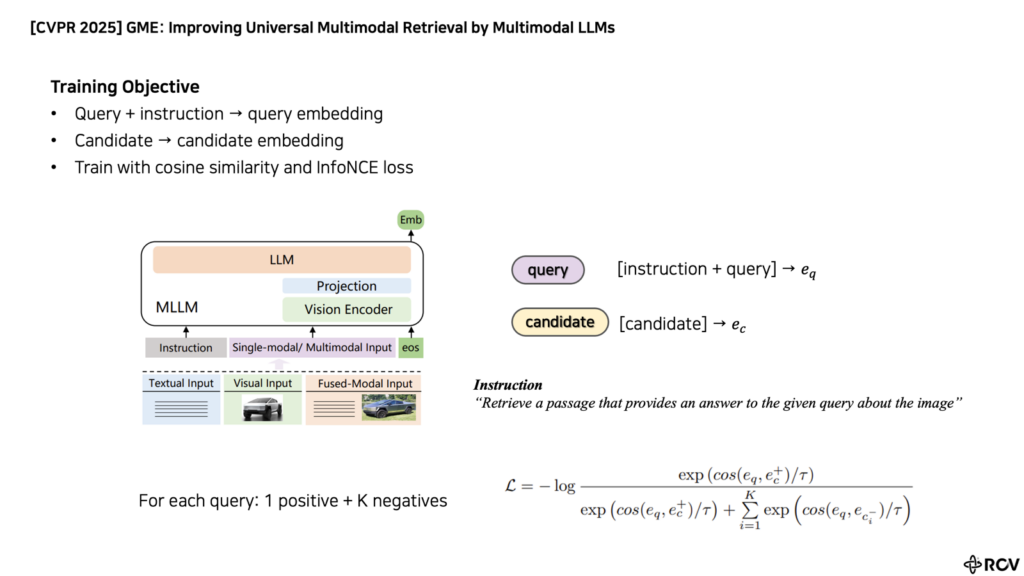
Loss는 다들 아시는 InfoNCE loss를 사용해 학습합니다. 여기서 한 가지 특징은 query에 task-specific instruction을 함께 넣는다는 점입니다. 예를 들어 “주어진 이미지에 대한 질문에 답을 제공하는 passage를 찾아라” 같은 instruction을 query 앞에 붙여, 모델이 단순 내용 이해가 아니라 retrieval 목적에 맞는 representation을 형성하도록 유도하였다고 하네요.
2.5.2 Hard negative mining
학습 과정에서 추가적인 기법이 들어가는데, 바로 Hard Negative Mining 입니다. (모달리티 간 디테일한 정렬이 중요하긴 했나 보네요)
retrieval에서는 random negative만으로 학습하면 너무 쉬운 오답만 보게 되어, 실제로 헷갈리는 후보를 잘 구분하지 못하는 경우가 많죠. 이를 보완하기 위해 저자들은 2-stage 전략을 사용하였습니다.
먼저 random negative로 초기 모델 M_1을 학습하고, 그 모델로 각 query에 대한 top-K candidate를 retrieval합니다. 그리고 그중 정답이 아닌 상위 결과들만 hard negative로 골라, 다시 이어서 학습합니다.
이 기법은 사실 이미 흔히 알려져있긴 하지만, UMR 자체가 modality도 다양하고 retrieval setting도 복잡하기 때문에, 단순한 negative보다 실제로 헷갈릴 만한 multimodal candidate를 학습 중에 충분히 보여주는 것이 더 중요해서 잘 워킹했다고 하네요. 뒤쪽 ablation에서도 hard negative를 제거했을 때 성능이 감소하는 것으로 나타난 것을 알 수 있었다고 합니다.
3. Experiments
앞선 Method에서 보았듯이, 이 논문은 단순히 GME라는 모델 구조를 제안하는 데서 끝나지 않습니다. 다양한 modality 조합의 학습 데이터가 UMR에 도움이 되는지, 그리고 그렇게 학습한 MLLM 기반 retriever가 실제로 universal한 embedding space를 형성하는지를 실험을 통해 보였습니다.
3.1 Experimental Setup
저자들은 앞선 분석을 바탕으로, 최종 학습에는 약 800만 개 규모의 데이터를 사용합니다.
single-modal
MSMARCO, NQ, HotpotQA, TriviaQA, SQuAD, FEVER, AllNLI 등 Text-to-Text retrieval 데이터를,
image-to-image를 위해서는 ImageNet에서 같은 class 이미지를 positive로 묶어 사용합니다.
cross-modal
LAION, MSCOCO, Docmatix
fused-modal
저자들이 직접 생성한 110만 개 수준의 synthetic data와 기존 M-BEIR training data가 함께 사용
최종 학습 데이터는 single-modal, cross-modal, fused-modal을 모두 포함하는 mixture로 구성됩니다.
Backbone: Qwen2-VL 2B와 7B 두 가지.
Fine-Tuning: LoRA 기반, 각 query마다 8개의 negative sample을 사용.
평가 데이터셋: UMRB
text retrieval, image retrieval, visual document retrieval, fused-modal retrieval까지 모두 포함한 평균 성능을 비교
3.2 Main Results
핵심 결과는 아래 Table 3에서 확인해보겠습니다
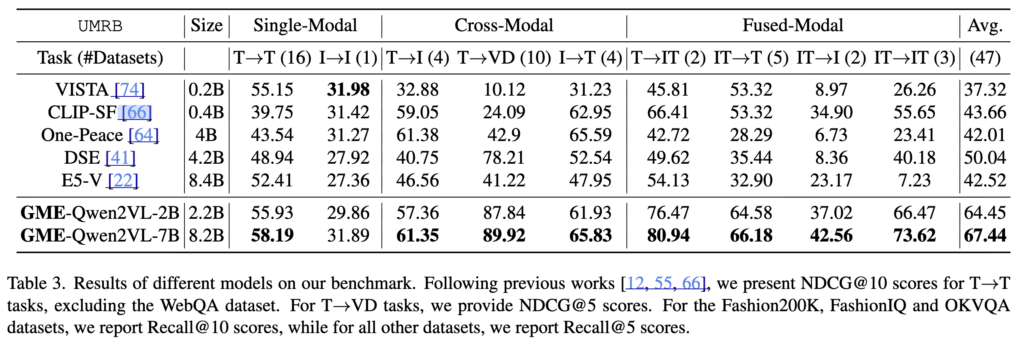
전체적으로 보면 GME-Qwen2VL-2B만으로도 기존 대표 UMR 모델인 VISTA를 크게 앞서고, 더 큰 7B 모델은 평균 성능 67.44로 가장 높은 성능을 보였습니다. 즉, MLLM backbone 위에 multimodal mixture training을 얹은 것만으로도 유의미한 결과를 가져온다는 걸 보여줍니다
저자들이 강조하는 부분은 T→VD, 즉 text-to-visual-document retrieval 성능입니다. GME 7B는 이 항목에서 89.92를 기록하는데, 이는 visual document retrieval 특화 모델인 DSE보다도 높은 수치라고 합니다. 보통 universal model은 여러 task를 한꺼번에 다루는 대신 특정 task에서는 specialized model보다 약할 것이라고 예상하기 쉬운데, 여기서는 오히려 문서 retrieval 같은 세부 task에서도 매우 강한 성능을 보여준다는 점이 의미있는 것 같습니다
또 하나 언급한건 E5-V인데, E5-V는 text-dominated task에서는 꽤 강한 성능을 보이지만, 전체 UMR 평균에서는 GME보다 낮습니다. 저자들은 이를 두고, text-only training만으로는 multimodal universality를 충분히 끌어내기 어렵다고 합니다
마지막으로 fused-modal retrieval 쪽에서도 GME는 전반적으로 강한 결과를 보입니다. 이는 앞서 synthetic fused-modal data를 대규모로 보강한 것이 단순한 부수 요소가 아니라, 실제로 모델의 universality를 끌어올리는 데 기여했음을 간접적으로 보여주는 결과이기도 합니다.
3.3 Are the produced embeddings modality-universal?
모델이 만든 embedding space가 실제로도 modality-universal한지 시각적으로 확인해보았습니다. 이를 위해 EVQA에서 샘플을 뽑아 text, image, text+image 입력의 embedding을 t-SNE로 확인해보았는데요.

결과를 보면 CLIP의 경우 modality별로 embedding이 비교적 분리되어 보였다고 합니다. 즉 텍스트는 텍스트끼리, 이미지는 이미지끼리 따로 뭉치는 경향이 강하죠.
반면 GME는 서로 다른 modality의 입력이더라도 의미가 비슷하면 같은 semantic cluster 안에 더 가깝게 모입니다. 저자들은 이를 두고 GME가 modality-separated representation이 아니라, 의미 중심의 modality-universal representation을 형성한다고 해석하…네요..허허 그치만 semantic 한 정보가 모여있는걸 이것만으로 확인했다고 보긴 조금…. 어렵지않나……. 싶긴 하네요
3.4 Synthetic data ablation
저자들이 직접 만든 synthetic fused-modal data가 정말 도움이 되는지도 따로 확인하는 실험을 수행했습니다.
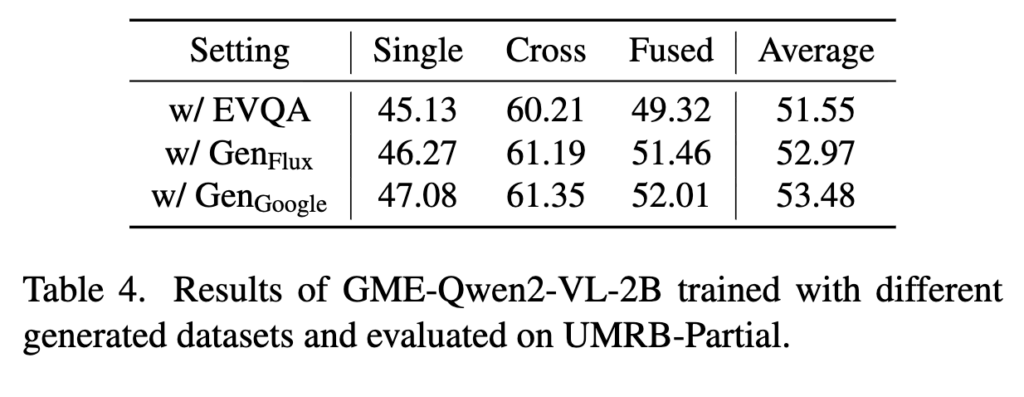
Table 4에서는 세 가지 조건을 비교하는데, 하나는 기존 EVQA 데이터만 사용한 경우이고, 나머지 둘은 저자들이 합성한 데이터입니다. 하나는 Google image search 기반 이미지(GenGoogle), 다른 하나는 FLUX로 생성한 이미지(GenFlux)를 사용한 것입니다.
결과를 보면 두 synthetic dataset 모두 EVQA 원본만 사용한 경우보다 더 높은 평균 성능을 보였습니다. 이는 저자들이 만든 합성 데이터가 단순히 양만 늘린 noisy data가 아니라, 실제로 retrieval training에 유효한 학습 신호를 제공하고 있음을 의미하죠.
또한 GenGoogle이 GenFlux보다 아주 약간 좋기는 하지만 차이는 크지는 않습니다. 이를 통해, 꼭 외부 이미지 검색에 의존하지 않더라도 생성형 모델 기반 이미지로도 충분히 경쟁력 있는 fused-modal training data를 만들 수 있음을 시사하는 결과였다고 합니다
3.5 Scaling law and ablation study
학습 데이터를 제안한다면, 데이터 양에 따른 성능 변화 폭도 보통 비교하는 것 같습니다 (Scaling law 검증을 위해서 같아요)
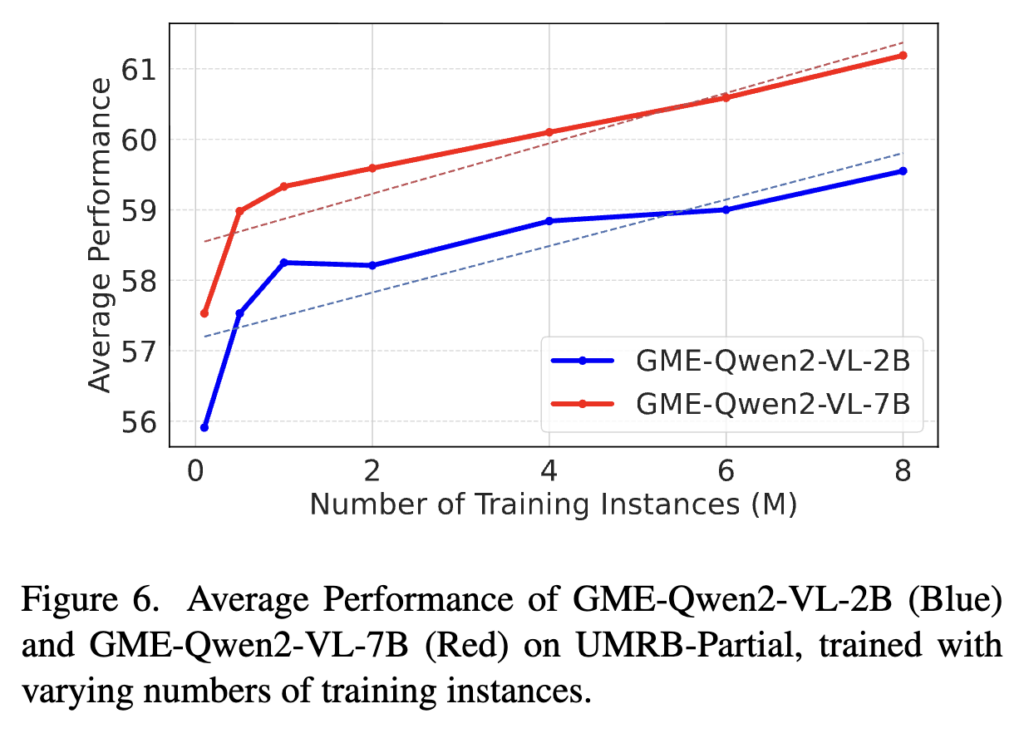
저자들도 Figure 6에서는 학습 데이터 양이 늘어날수록 성능이 어떻게 변하는지 결과를 제시하였습니다. 2B와 7B 모델 모두에서, training step이 증가할수록 UMRB-Partial 성능이 비교적 선형적으로 올라가는 모습을 보였죠.
이를 통해 아직 더 학습하면 더 좋아질 여지가 있다고 합니다. 즉, 현재 결과도 좋지만 데이터 규모와 학습 시간 측면에서 아직 ceiling에 도달한 것은 아니라는 뜻이죠.
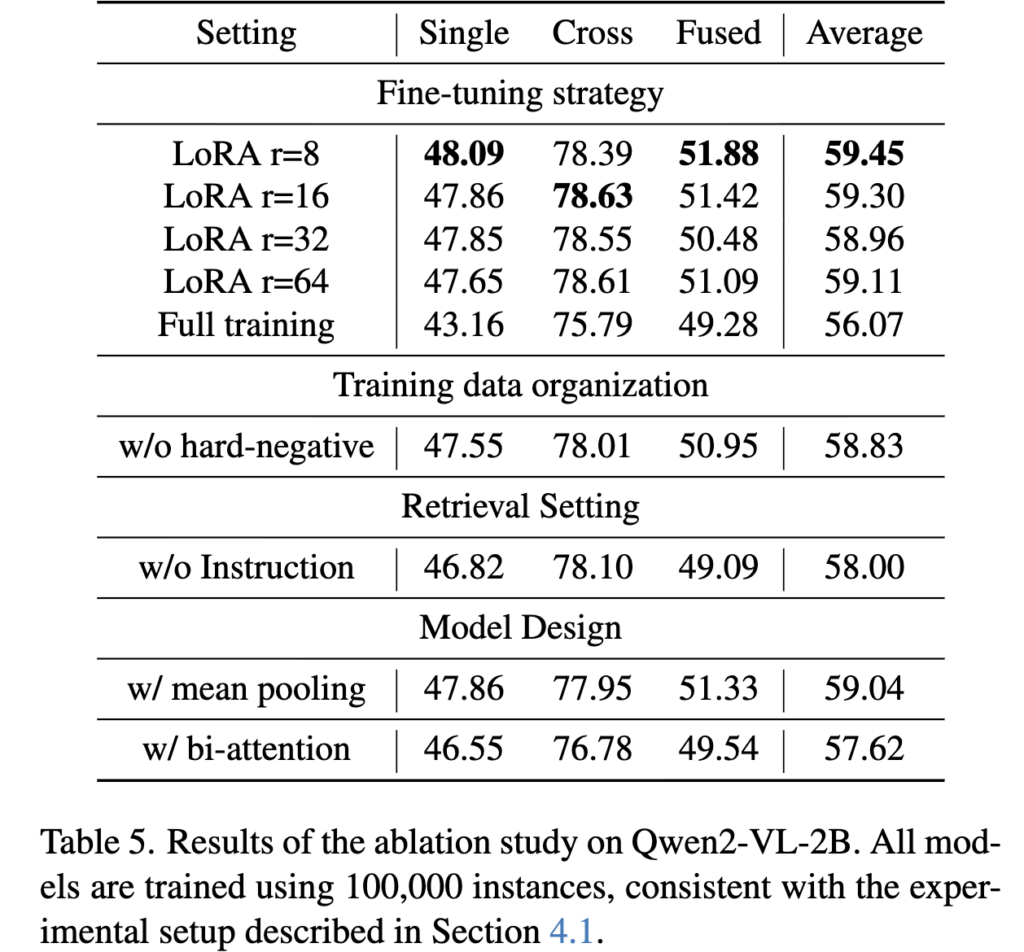
마지막으로 Table 5 ablation study입니다.
먼저 fine-tuning strategy를 비교했을 때는 LoRA rank 8이 가장 좋은 성능을 보였고, rank를 더 키우거나 full fine-tuning을 하는 것이 오히려 더 낫지는 않았습니다.
또한 hard negative를 제거하면 성능이 떨어지고, retrieval instruction을 빼도 성능이 감소합니다. mean pooling이나 bi-attention 같은 더 복잡한 설정 역시 final model보다 좋지 않았습니다.
저자들은 이를 통해, 복잡한 설계가 항상 더 좋은 것은 아니며, 오히려 EOS-based embedding, causal attention, retrieval instruction, hard negatives 같은 비교적 단순하지만 retrieval에 맞는 설계가 더 효과적이라고 언급하네요
4. Conclusion
이 논문은 어찌보면 GME라는 MLLM 기반 retrieval model을 제안한 논문처럼 보이지만..
제 생각에 더 중요한 메세지는 UMR이라는 문제를 어떻게 정의하고, 어떤 데이터로 학습시키며, 무엇으로 평가할 것인가를 꽤 체계적으로 정리했다는 점에 있다고 생각합니다.
특히 visual document retrieval까지 포함해 범위를 확장했다는 점이 실용적인 검색 관점에서는 중요한 포인트가 맞다고 설득되기도 했죠
물론 아쉬운 점도 있습니다. 우선 이 논문에서 말하는 ‘universal’은 어디까지나 text, image, text-rich image 범위에 한정되어 있고, video나 audio, multi-image interleaving 같은 더 넓은 multimodal setting까지 포함하는 것은 아니라는 점입니다.
평가 역시 영어 데이터 중심으로 이루어져 있어, 다국어 환경에서의 일반화 가능성은 아직 열려 있습니다. synthetic query 역시 실제 사용자 질의와는 다를 수 있기 때문에, 합성 데이터가 real-world query distribution을 얼마나 잘 반영하는지도 추가로 봐야할 것 같긴 합니다
안녕하세요 좋은리뷰 감사합니다.
VD에 대해 질문이 있습니다. universal retriever 외에도 해당 데이터 형식을 다룰 방법이 있을것 같습니다.
혹시 universal retriever를 이용했을 때, 각 데이터를 따로 다루는것보다 속도/연산 리소스 측면에서 이득이 언급되거나 비교된 내용이 있었는지 궁금합니다
감사합니다.
좋은 댓글 감사합니다.
우선 VD를 universal retriever로 해야하나? 라는 질문에 대해서는 말씀처럼 VD는 전용 document retriever나 OCR 기반 파이프라인 등 별도의 방식으로도 다룰 수는 있습니다. 그치만 이 논문은 그런 전용 모델 대비 효율성을 직접 비교하기보다는, text·image·VD를 하나의 unified retriever로 함께 다룰 수 있다는 범용성 측면에 더 초점을 둔 것 같습니다.
그런 관점에서 “속도/연산 리소스”에 대한 질문을 주신 것 같은데요. Appendix까지 봤지만, 이 논문은 universal retriever와 modality별 전용 retriever를 속도나 연산 자원 측면에서 직접 비교한 실험은 제시하진 않네요
그러니까 unified retriever가 usability와 scalability 측면에서 더 적합하다곤 하지만, 이는 아직까진 개념적 장점에 가깝고 latency나 inference cost를 정량 비교한 결과는 없습니다. 아무래도 연구가 충분히 성숙하게 진행되지 않아서 그런게 아닐까 싶네요 좋은 질문 감사합니다