안녕하세요. 이번에 리뷰로 가져온 논문은 CVPR 2026 Highlight로 선정된 STRNet: Visual Navigation with Spatio-Temporal Representation through Dynamic Graph Aggregation라는 논문입니다.
NoMaD, ViNT, NaviBridger 같은 기존 연구들이 주로 diffusion policy, action prediction head, subgoal selection 같은 downstream policy 설계에 집중했다면, STRNet은 그 앞단의 visual representation 자체를 좀더 좋게 만들기 위해 집중한 연구라고 보시면 좋을 것 같습니다. 기존 방식들의 문제점을 지적하는 부분이 공감이 가서 해당 논문을 읽게되었고 읽다보니 개인적으로 해당 방식의 방법론의 구조적인 참신함보다는 CNN 기반 방법론 위에서 이것저것 성능을 올리기 위해 이런식으로도 접근해 볼 수 도있구나 정도로 느끼면서 읽었던 것 같습니다. 바로 리뷰 시작하도록 하겠습니다.
Introduction
기존 visual navigation 모델들은 observation sequence와 goal image를 입력으로 받아 action을 예측하지만 중간에서 단순히 temporal pooling이나 average pooling에 의존하는 경우가 많습니다. 이러면 navigation에 중요한 공간 구조와 같은 문, 벽, 복도, 장애물의 관계나, 시간에 따른 변화 정보(motion, progress cue)가 약해질 수 있는 문제가 있습니다. 그래서 여기서 저자들은 STRNet은 visual navigation에서 중요한 것은 단순히 좋은 policy head가 아니라, navigation에 필요한 spatial-temporal representation을 encoder 단계에서 잘 만드는 것이라고 주장합니다.

위 Figure 1은 이 문제를 직관적으로 보여주는 시각화 그림인데 STRNet과 NoMaD의 feature embedding t-SNE 비교 그림입니다. 마지막에 action policy head에 들어가기 전에 생성된 context vector를 각각 NoMaD, STRNet에서 뽑아서 고차원 벡터를 2D 평면에서 시각화 한 결과라고 보시면 좋을 것 같습니다.
NoMaD의 temporal pooling feature는 temporal distance가 다른 점들과 살짝 뒤섞여 있는 반면, STRNet은 goal까지의 temporal distance에 따라 feature가 더 잘 분리되는 모습을 보입니다.
특히 차이가 나는지점은 왼쪽 오른쪽 덩어리가 분리가 됬는지 안되었는지를 보았을 때 확실히 STRNet이 거리에 따른 구분가능한 representation을 더 잘 만든다는 것을 확인할 수 있습니다. 결국 여기서 저자가 하고 싶은 말은 좋은 navigation policy를 만들려면 action head만 중요한 것이 아니라 현재 state가 goal과 얼마나 가까운지 구분 가능한 representation을 만들어야 한다는 점인 것 같습니다.
저자가 논문에서 언급하는 기여는 아래와 그대로 같습니다.
- 우리는 visual navigation에서 weak feature representation 즉 빈약한 특징 표현 문제가 충분히 탐구되지 않은 도전 과제임을 지적하고 decision-making stage 이전에 spatial reasoning과 temporal reasoning을 강화하도록 설계된 structured feature fusion framework를 제안한다.
- 우리는 spatial understanding을 향상시키기 위한 graph-based spatial aggregation module과, hybrid temporal shift와 multi-resolution contrast를 결합한 lightweight temporal fusion module을 제안한다. 이를 통해 compact하면서도 expressive한 spatio-temporal representation을 생성한다.
- simulation 및 real-world navigation task에서 수행한 광범위한 실험을 통해, STRNet이 기존 baseline들을 크게 능가함을 보인다. 특히 NoMaD와 비교했을 때 평균 success rate를 최대 70%까지 향상시키며, 제안한 representation의 효과성과 robustness를 입증한다.
spatial reasoning과 temporal reasoning을 강화하도록 설계된 structured feature fusion framework를 제안한 것이 가장 핵심이다라고 보시면 좋을 것 같습니다. 자세한 내용은 Method에서 다루도록 하겠습니다.
Method
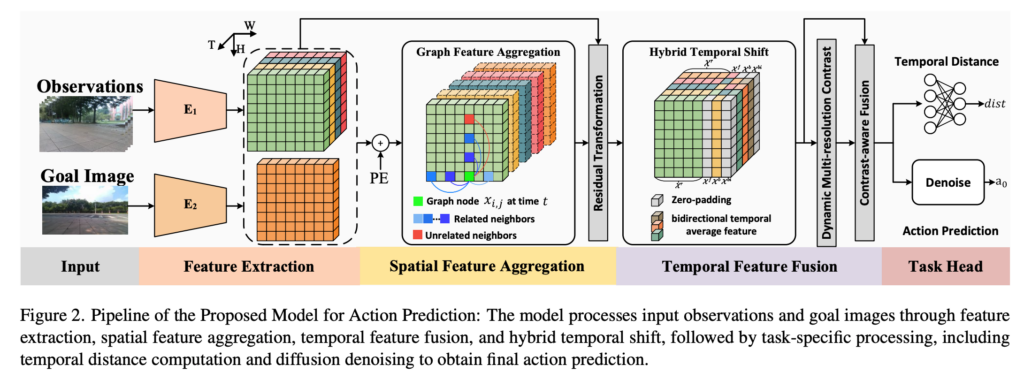
위는 STRNet의 전체 파이프라인입니다. 마찬가지로 input output 관점에서 전체구조를 보면 NoMaD와는 동일합니다. 큰 흐름을 간단하게 설명드리면 Observation sequence(5프레임) 와 goal image가 feature encoder를 통과한 뒤, spatial feature aggregation, temporal feature fusion, task head를 거쳐 action과 temporal distance를 예측하는 구조라고 보시면 좋을 것 같습니다.
입력 이미지는 과거 observation sequence(5 프레임)와 goal image입니다.
\mathcal{O} = {I_t}_{t=T-p}^{T}, \quad I_g
여기서 \mathcal{O}는 과거 관측 이미지들의 sequence이고, I_g는 goal image입니다. 모델은 이 입력을 바탕으로 action a와 temporal distance \tau를 예측합니다. \pi(\mathcal{O}, I_g) \rightarrow (a, \tau) STRNet도 NoMaD와 동일하게 goal까지 얼마나 남았는지도 같이 예측하는 구조이고 이 temporal distance는 long-range navigation에서 subgoal selection할 떄 중요하게 쓰입니다.
Spatial Feature Aggregation
STRNet의 첫 번째 핵심 모듈은 Spatial Feature Aggregation입니다. 기존 CNN이나 Transformer는 이미지를 grid 또는 sequence로 처리하고 CNN같은 경우에는 average pooling을 하거나, ViT 같은 경우네는 CLS토큰 만 쓰는 경우가 많습니다. navigation 환경에서는 문, 벽, 복도, 장애물과 같은 지역적인 spatial한 정보도 중요합니다. 그래서 저자들은 CNN 기반 방법론에서 Vision GNN의 아이디어를 차용해서 image feature를 graph로 보고, 각 image region을 node로 해석하여 Spatial 한 정보를 모델이 이해할 수 있도록 프레임워크를 설계하고자 합니다.
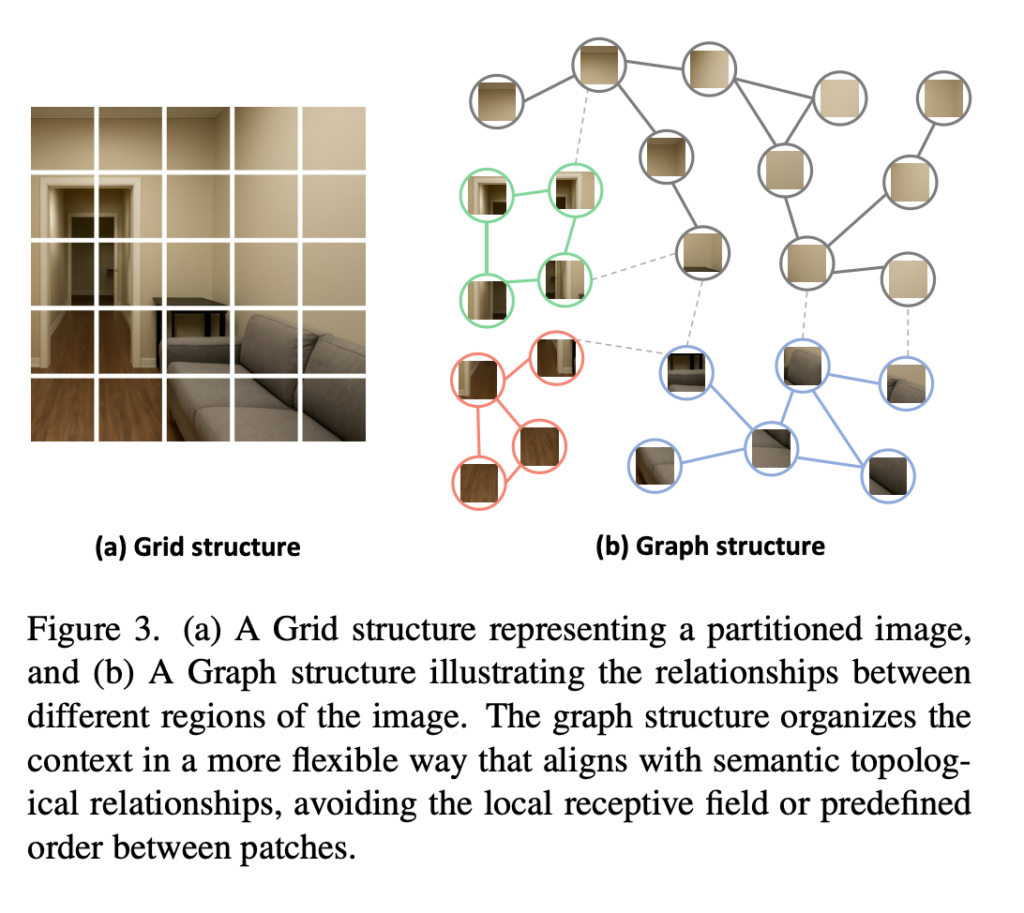
저자들은 이미지를 단순 grid로 보는 것보다 graph 구조로 region 간 관계를 보는 것이 navigation에 더 적합할 수 있다고 주장합니다.
Dynamic Axial Graph Construction
저자들은 피쳐맵의 각 위치 grid latex[/latex]의 feature를 노드 x_{i,j}라고 정의를 하고 STRNet은 여기서 각 노드들의 인접 노드들간 feature와 비교하여 노드 간 edge weight를 계산합니다. 여기서
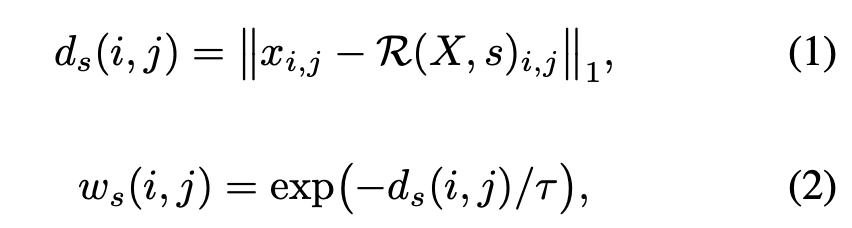
여기서 \mathcal{R}(X,s)는 feature map을 stride s만큼 shift한 것이고, d_s(i,j)는 원래 feature와 shift된 feature 사이의 차이라고 보시면 될 것 같습니다. (피쳐맵을 s칸씩 옆으로 민 버전과 원래 피쳐맵끼리 뺌)
그리고 여기서 살짝 좀 아쉬운 부분은 shift를 상하좌우에 대해서만 진행을 하기 때문에 결국엔 노드들간의 그래프 연결이 좌우 상하 에 해당하는 노드들끼리에 대해서만 적용되는것이고 멀리있는 대각선 노드는 아무런 교류가 불가한 상태라는 점 입니다.
다시 돌아와서 이 노드간 차이가 작으면 두 region이 유사하다는 뜻이고 차이가 크면 서로 다른 구조를 보고 있다라고 보시면 좋을 것 같습니다.
그리고 두 번째 수식의 w_s(i,j)는 edge weight입니다. 식 자체가 feature 차이가 작을수록 [/latex]w_s[/latex]가 커지고, feature 차이가 클수록 w_s가 작아지는 구조라고 보시면 좋을 것 같습니다.
결국 이미지 안에서 서로 관련 있는 region은 강하게 연결하고 관련이 약한 region은 약하게 연결해서 spatial context를 구성하게끔 설계했다고 보시면 좋을 것 같습니다.
Multi-scale Contrast Enhancement
그리고 위에서 잠깐 stride s를 언급했는 STRNet은 한 가지 scale만 보지 않고 여러 stride에서 feature contrast를 계산합니다.
\Delta_i = \frac{ \sum_s w_s^i \cdot \left(\mathcal{R}(\tilde{X},s)_i - \tilde{X}\right)}{\sum_s w_s^i + \varepsilon}
일단 위 수식은 horizontal direction(상하 이웃)에서 여러 shift scale을 사용해 contrastive residual을 계산하는 과정을 나타내는 수식입니다. 결국 여러 horizontal shift에서 얻은 feature 차이들의 가중합 평균을 나타내는 식이라고 보시면 좋을 것 같습니다. 여기서 vertical directional shift같은 경우는 [/latex]\Delta_j[/latex] 로 나타내게 되고 [/latex]\Delta = \max(\Delta_i, \Delta_j)[/latex] 는 여러 scale에 걸쳐서 가장 두드러지는 structural contrast를 골라서 쓴다고 합니다. 상하 방향과 좌우 방향 중에서 좀더 중요한 구조적 변화가 있는 것을 쓰겠다라고 보시면 좋을 것 같습니다.
그리고 이후 최종 spatial aggregation은 아래와 같이 표현되게 됩니다.Shortcode
여기서 \mathcal{P}는 positional encoding, \mathcal{A}는 graph-based aggregation, \mathcal{T}는 residual transformation입니다. 원래 image feature에 위치 정보를 더하고 graph aggregation으로 spatial relation을 반영하한뒤에 residual transformation을 통해 navigation에 더 적합한 spatial feature를 만들게끔 설계했다고 합니다.
Temporal Feature Fusion
Spatial aggregation이 한 frame 안의 구조를 보는 모듈이면 temporal fusion은 여러 frame 사이의 변화를 보는 모듈이라고 보시면 좋을 것 같습니다. 저자는 해당 모듈안에서도 3가지로 쪼개놨는데 먼저 Hybrid Temporal Shift Module에 대해서 설명드리도록 하겠습니다. 일단 저자들은은 비디오 연구쪽 TSM(temporal shift module)에서 영감을 받아 channel 일부를 시간축으로 shift합니다. 그림에서 보이는 것 처럼 Feature channel의 일부를 시간축으로 앞뒤 frame으로 살짝 이동 시켜서 temporal 정보를 섞습니다.
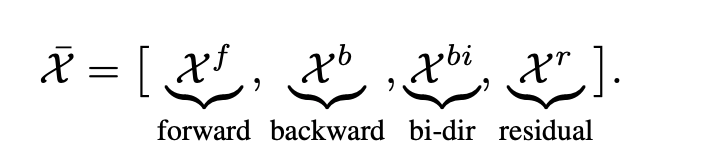
자세하게는 위처럼 feature channel을 네 그룹으로 나눕니다. forward shift, backward shift, bidirectional average, residual channel이고 시간축 shift는 아래와 같습니다.
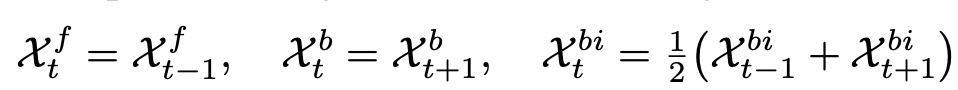
위같은 경우는 현재 frame feature에 이전 frame 정보, 다음 frame 정보, 양방향 평균 정보를 일부 섞어주는 것인데 비율은 forward : backward : bidirectional : residual = p : p : p : 1-3p 입니다. 이후 shifted feature는 lightweight 3D convolution을 거쳐 fusion됩니다.
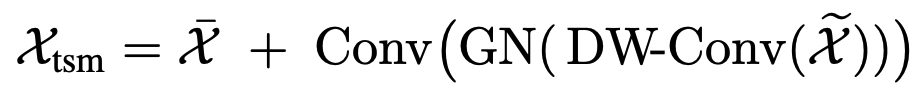
마찬가지로 여기도 residual connection이 있는데 저자들은 원래 feature의 정보를 계속 유지하면서 temporal shift로 얻은 motion-aware 정보를 더해주도록 하고자 설계한 것 같습니다.
이런 Hybrid temporal shift만으로는 다양한 scale의 motion 변화를 충분히 잡기 어렵다고 합니다. 그래서 저자들은은Dynamic multi-resolution contrast를 추가설계를 하였습니다. 먼저 temporal feature를 여러 scale로 pooling하고, circular roll을 적용한 뒤 원래 feature와 차이를 계산합니다. (앞서 설명한 shift랑 동일 피쳐맵을 shift 하고 짤리면 앞으로 가져옴)
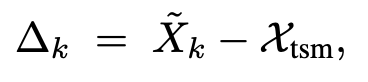
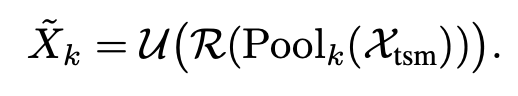
여기서 \mathrm{Pool}_k는 scale k에서 feature를 다운 샘플링하는 것이고 \mathcal{R}은 circular roll, \mathcal{U}는 다시 원래 크기로 업샘플링하는 연산입니다. 저자의 의도는 feature를 여러 해상도에서 일부러 어긋나게 만든 뒤 원래 feature와 비교해서 변화가 큰 영역을 찾도록 하는 것 같습니다. 뭔가 optical flow를 직접 쓰는 것은 아니지만 좀 coarse feature-level에서 motion cue를 얻고자 하는 설계인 것 같습니다.
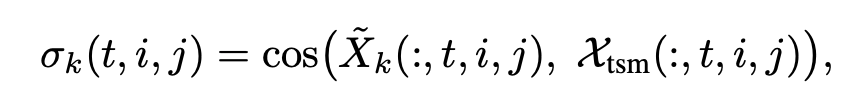
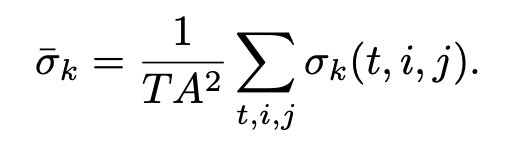
그리고 나서 해당 scale에서의 평균 similarity를 계산하고
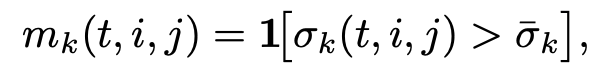
그 다음 평균 similarity보다 큰 위치만 유지하는 hard binary mask를 만듭니다. 그리고 이 mask는 아래 식에서 residual \Delta_k를 filtering하는 데 사용되게 됩니다.
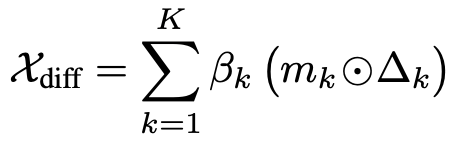
여기서 선택된 residual들은 learnable scale coefficient \beta_k(여기서 β는 scale별 learnable weight임)에 곱해지고 모든 scale에 대해 합산됩니다.(scale에서 얻은 temporal contrast를 learnable한 가중치로 합침) 결과적으로 여기서 얻어지는 {X}_{\text{diff}}는이는 중요한 temporal change는 강조되고 관련 없는 region은 억제된 feature라고 합니다.
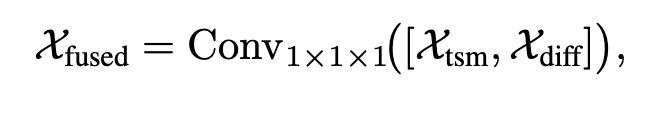
마지막으로 원래 temporal feature와 difference feature를 concat한 뒤 fusion하게 됩니다. 여기까지가 결국 STRNet의 최종 spatio-temporal representation입니다.
Loss
STRNet은 action prediction과 temporal distance estimation을 함께 학습하고 Action prediction은 diffusion policy 방식입니다.
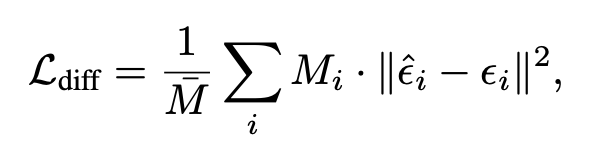
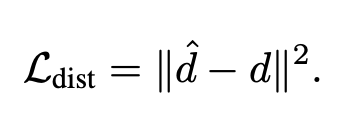
여기서 \epsilon_i는 실제로 추가된 noise이고, \hat{\epsilon}_i는 모델이 예측한 noise이고 Temporal distance loss는 단순 MSE입니다. 여기서 \hat{d}는 모델이 예측한 temporal distance이고 옆에가 gt distance입니다.
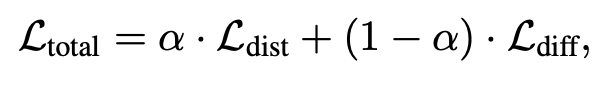
Experiments
실험은 indoor, outdoor simulation과 real-world 환경에서 진행했다고 하고 학습에는 RECON, SCAND, GoStanford, SACSoN을 합친 데이터 셋을 사용합니다.
평가 metric은 Path Length(성공한 task에서 평균 이동 거리), Collision(trial당 평균 충돌 횟수), Success Rate, SPL(성공률과 path efficiency를 함께 보는 지표)입니다.
Simulation Results
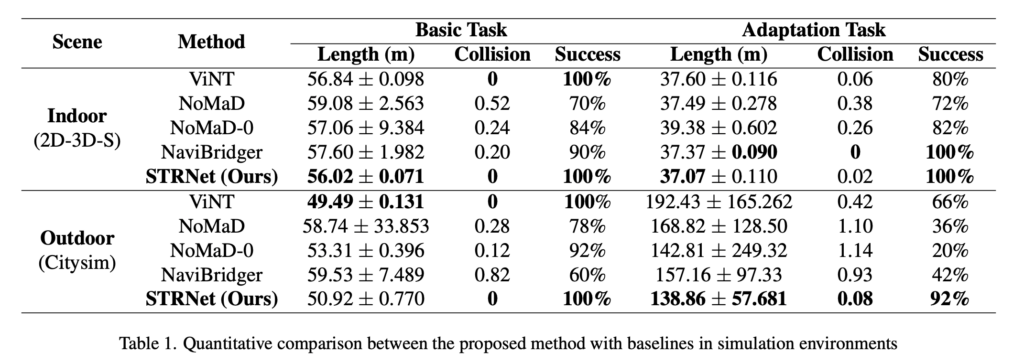
Table 1에서 STRNet은 indoor 2D-3D-S와 outdoor Citysim 모두 좋은 성능을 보입니다. STRNet이 시뮬 환경인 이런 adaptation setting에서도 상공률이 높은 결과를 보이고 신기한건 NoMaD-0이 NoMaD보다 좋은 결과를 보입니다. NoMaD-0은 temporal history를 사용하지 않는 상황인데 그런데 이 모델이 vanilla NoMaD보다 좋다는 말은 저자가 분석으로는 기존 NoMaD의 temporal fusion이 오히려 feature를 흐리게 한 결과라고 분석합니다.
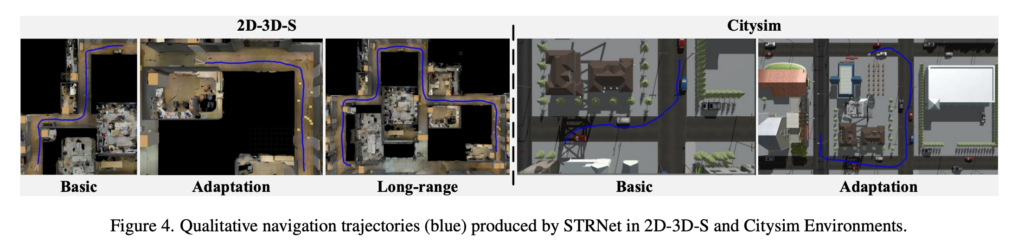
위는 2D-3D-S와 Citysim에서 STRNet이 생성한 trajectory 정성결과 입니다.
GRScenes Results
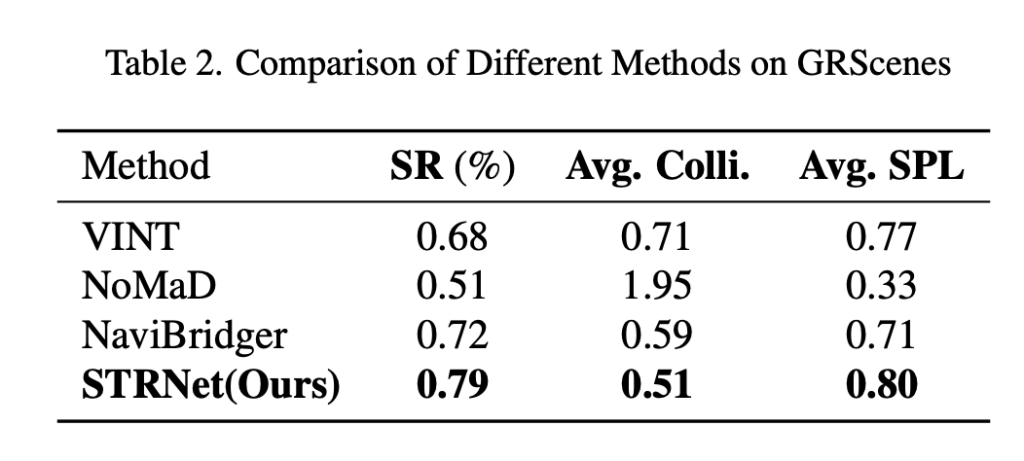
GRScenes는 cluttered indoor scene을 포함한 high-fidelity simulation dataset이라고 합니다. 여기서도 좋은 성능을 보입니다.

Figure 5는 NoMaD가 실패하는 4 가지 경우라고 합니다.
- poor representation으로 인한 suboptimal behavior
- 잘못된 scene understanding으로 인한 hesitation
- motion direction 오류와 erratic trajectory
- 장애물 인식 실패로 인한 collision
저자는 policy head가 문제가 아니라 action head에 들어가기 전의 representation이 이미 spatial-temporal 정보를 충분히 담지 못하면 navigation failure가 발생할 수 있다는 점을 주장합니다.
Real-world Evaluation

실제 robot 실험은 Diablo wheeled-leg robot과 Azure Kinect RGB input으로 평가했다고 합니다.
Figure 6에서는 curve, curb cut, cluttered sidewalk 상황에서 NoMaD와 STRNet의 traj 결과을 비교를 보여줍니다. NoMaD에 비해 STRNet은 더 smooth하고 drivable corridor에 맞는 trajectory를 예측하는 모습을 보였다 정도에서 끝냈는데 real world 평가는 달랑 정성결과 이것만 보여주고 없네요 허허
Ablation Study
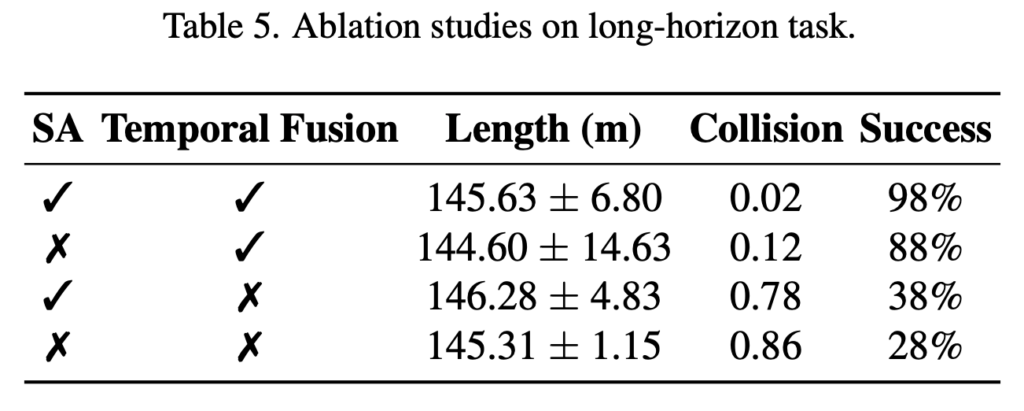
여기서 temporal fusion 제거하면 성능하락폭이 많이 큰 것을 확인할 수 있습니다. hybrid temporal shift만 썼을 때, multi-resolution contrast만 썼을 때, graph aggregation의 scale을 바꿨을 때 성능이 어떻게 변하는지까지 보여주지는 않았습니다.
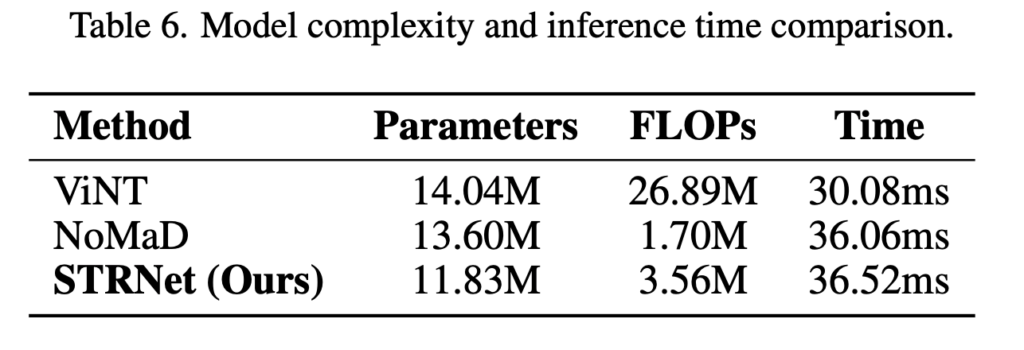
STRNet은 가장 빠른 모델은 아니지만 실시간 navigation에 사용할 수 있는 수준의 계산량을 유지하면서 representation 성능을 높였다라고 저자들은 주장합니다. 그래도 이제 슬슬 Navigation의 단순한 아키텍쳐를 지적하고 이를 겨냥해서 다양한 방식으로 해결하고자하는 논문들이 점점 많이 나오고 있는 것 같습니다. 저도 빨리 빨리 연구를 진행해야겠다라는 생각이 드네요. 이만 리뷰 마치도록 하겠습니다. 감사합니다.
리뷰 잘 읽었습니다. 읽다가 궁금한 점이 생겨 댓글 남깁니다!
Spatial graph construction에서 상하좌우 shift 기반으로 edge weight를 계산한다고 설명해주셨는데, 이 경우 대각선 방향이나 더 멀리 떨어진 region 간 관계는 직접적으로 반영되지 않는 것 같다고 이해했는데요. 혹시 논문에서 이런 연결 범위의 한계나, stride/scale을 키워서 보완하는 방식에 대한 언급이 있었는지 궁금하네요!
안녕하세요 주영님 좋은 댓글 감사합니다.
일단 상하자우 방향에 대해서는 stride를 K,2K.. 이런식으로 여러개 사용해서 더 멀리 떨어진 region까지 비교합니다. 다만 논문에서 대각선 방향에 대해서는 직접적으로 다루는 부분은 없어서 이 부분은 따로 보완하는 방식에 대한 저자의 언급은 따로 없었습니다!
감사합니다.
리뷰 감삼다 질문하나 남깁니다..
CNN 기반으로 Spatial Feature를 엮어내는 방식인거같은데요 . DINOv2 같은 백본으로 사용해 Feature를 뽑는 것과 비교했을 때, Graph Aggregation 아키텍처가 파라미터나 성능 측면에서 리포팅한거는 없겠죠…?
안녕하세요 우진님 좋은 댓글 감사합니다.
일단 방법론 자체가 CNN을 타깃으로한 느낌이 강해서 따로 DINO로 백본을 교체해서 한 실험은 하지 않은 것으로 보입니다. 감사합니다~!