Abstract
최근 로봇 조작에서 imitation learning을 활용한 연구들이 성공을 이루고 있으나, 제한적인 데이터 다양성으로 인해 기하학적 변형에는 제약이 있습니다. 해당 논문은 3D 생성 모델과 VFMs를 활용한 AffordGen 프레임워크를 제안하여 이러한 문제를 극복하고자 하였습니다. 대규모 3D mesh 전반에 keypoint들의 의미론적 대응을 관계를 이용하여 새로운 조작 trajectory를 생성하는 방식으로, 이렇게 생성된 대규모 affordance-aware 데이터 셋을 이용하여 강인한 closed-loop visuomotor policy를 학습합니다. 시뮬레이션과 real-world에서 실험을 진행하였으며, AffordGen으로 학습된 policy가 높은 성공률을 달성하며 새로운 물체에도 zero-shot 일반화가 가능함을 실험적으로 보였습니다. 또한, 로봇 학습에서 데이터 효율성도 크게 향상시켰음을 어필합니다.
Introduction
Visuomotor Imitation Learning은 로봇 조작에서 좋은 성능을 보여주고 있으나, 대규모의 고품질 demonstration 데이터 수집의 비용과, 학습 과정에 보지 못한 물체와 시나리오에 일반화가 어렵다는 문제로 인해 다양한 real-world 응용에 적용이 어렵습니다.
최근 DemoGen과 같이 하나의 시연 데이터로 수백개의 trajectories를 생성하여 데이터 효율을 크게 개선하고자 하는 시도가 있었으나, 여전히 단일 물체 인스턴스로 한정되며, translation 변화에 집중하여 orientation 변화에는 어려움을 보였다고 합니다. Robo-ABC와 DenseMather와 같은 affordance 기반의 방법론들은 의미론적 대응 관계를 통해 unseen 물체로 affordance 지식을 전이하고자 하는 시도가 있었습니다. 그러나 이러한 방식들은 affordance point를 찾고 planning으로 궤적을 생성하는 방식입니다. 즉, execution은 미리 계산된 trajectory를 따르므로, 실제 로봇 조작 중에 변화에 반응하지 못합니다.
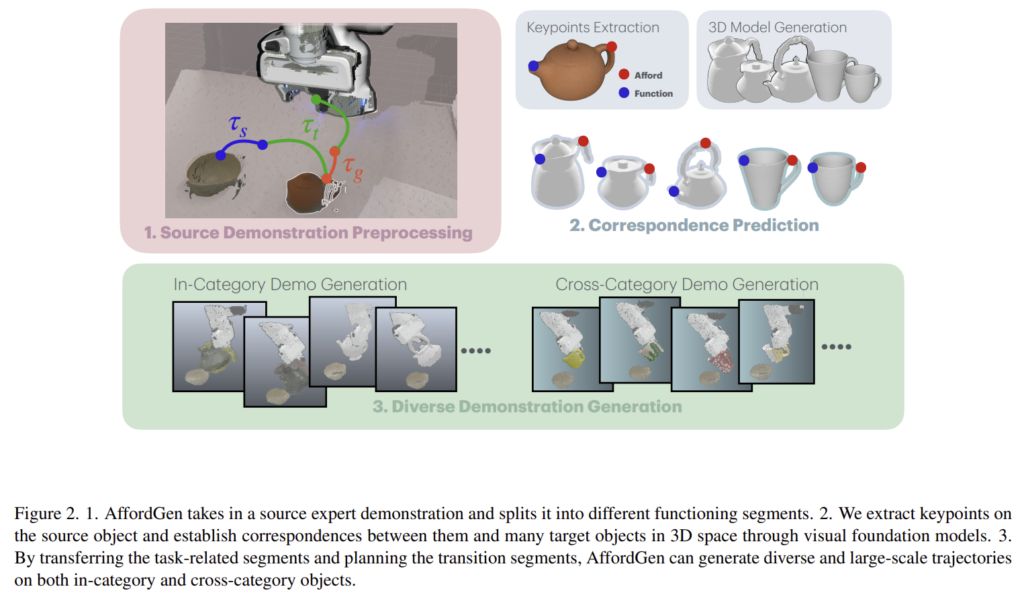
AffordGen은 affordance를 planning에 사용하지 않고, policy learning을 위한 학습 데이터 생성 시의 사전 지식으로 사용합니다. AffordGen은 서로 다른 카테고리의 unseen 물체에도 적용 가능한 학습 데이터를 생성하며, 소수의 사람 시연 영상에서 시작하여, 물체의 keypoint와 대규모 unseen 3D 모델 사이의 대응 관계를 구축합니다. 이후, DemoGen과 비슷하게 다양한 trajectories를 합성하며,새로운 물체 인스턴스와 완전한 6D 공간 관계까지 포함한다는 차별점이 있습니다.
저자들은 시뮬레이션과 real-world 환경에서 모두 AffordGen의 뛰어난 성능을 입증하였으며, 베이스라인 대비 평균 24.1%(시뮬레이션)와 24.3%(real-world)의 성능 개선을 달성하였습니다. 또한, 1개의 시연 영상만으로도 수백개의 서로 다른 mesh에 대해 수천개의 의미있는 trajectory를 생성할 수 있었다고 합니다. AffordGen은 seen과 unseen 물체에 대해 모두 성능 개선을 이루었으며, 나아가 동일한 조작 유형에 대해 완전 다른 물체라도 학습 데이터를 생성할 수 있도록 하였다고 합니다.
해당 논문의 contribution을 정리하면
- affordance를 활용하여 다양한 유의미한 demonstraction을 합성하는 새로운 프레임워크 AffordGen 제안
- AffordGen이 최소한의 인간 시연 데이터를 새로운 물체 카테고리의 수천개의 trajectory로 확장할 수 있음을 보였으며, 이를 통해 기존 데이터 증강 기법의 의미론적·기하학적 한계 극복
- 광범위한 실험을 통해 AffordGen으로 학습된 policy가 unseen 물체에 유의미한 zero-shot 일반화 성능을 달성함을 보였으며, 이를 통해 새로운 데이터 효율적인 학습 패러다임을 제시함
Methodology
Problem Forumulation
먼저, 저자들은 로봇 작업을 3단계로 분해합니다. \Omega=\{\Omega_G,\Omega_S,\Omega_T\} 순서대로 그리퍼를 닫아 물체를 잡는 grasp stage, 잡은 물체를 이용하여 조작 과제를 수행하는 skill stage, 두 단계를 충돌 없이 연결하는 transition stage를 의미합니다. time step t에서 로봇은 현재 시점의 visual observation o^e_t(저자들은 3D 공간 상의 정보와 새로운 데이터 생성을 위해 AffordGen의 입력으로 point cloud 형태를 사용하였다고 합니다.)와 로봇 자체의 관측 정보 o^s_t를 입력으로 받고, 이에 대응되는 행동 a_t를 출력합니다.
AffordGen은 주어진 조작 과제에서 조작되는 물체의 형태의 크기가 달라지더라도, trajectory에 포함된 의미론적 정보는 유지된다는 점으로부터 출발합니다. 이후 해당 논문은 (1) 원본 demonstration의 grasp stage와 skill stage에서 의미론적 정보를 추출하는 방법, (2) 추출된 정보를 source object와 다른 대규모 3D mesh로 매핑하는 방법, (3) source trajectory로부터 다양하고 많은 demonstration을 생성하는 방법에 대해 다룹니다.
Source Demonstration Pre-processing
주어진 전문가 demonstration으로부터 3가지 정보를 추출합니다.
- grasping time t_{grasp}: 그리퍼의 상태로부터 그리퍼가 닫히는 시점 정보.
- skill segment \tau_{s}: 도구를 이용하여 작업을 수행되는 영상 범위. VLMs을 이용하여 video reasoning을 하거나 사람이 annotation하여 구함.
- keypoints(afford point & function point): 3D point cloud에서 그리퍼와 물체 사이의 contact point(afford point), 도구를 이용하여 작업을 수행하며 다른 물체와 상호작용이 이루어지는 지점(function point). 마찬가지로 VLM이나 사람이 annnotation한 결과 사용.
저자들은 이러한 annotation 과정이 적은 전문가 demonstration에 수행되는 것이기 때문에 비교적 효율적이라고 주장합니다. 또한, point cloud는 RGB-D 카메라로부터 취득되며, RGB 이미지에 SAM2를 적용하여 robot, object, goal, others 4가지 카테고리의 영역을 segmentation한 뒤 point cloud로 매핑하여 배경 및 바닥이 제거된 point cloud를 구합니다. 이후 FPS로 down-sampling하여 로봇의 워크스페이스 내부에 위치한 point만으로 이루어진 workspace point cloud \mathcal{O}^e ⊂\mathbb{R}^3를 추출합니다. (이는DP3와 DemoGen의 설정과 동일하다고하네요.)
Semantic Correspondence on 3D Meshs
새로운 mesh에 대하여 의미론적으로 대응되는 3D keypoints를 찾기 위해, 저자들은 여러 viewpiont의 2D semantic feature matching을 거친 뒤, 다시 3D 공간으로 복원하는 과정을 거칩니다. 구체적으로 살펴보면 다음과 같습니다.
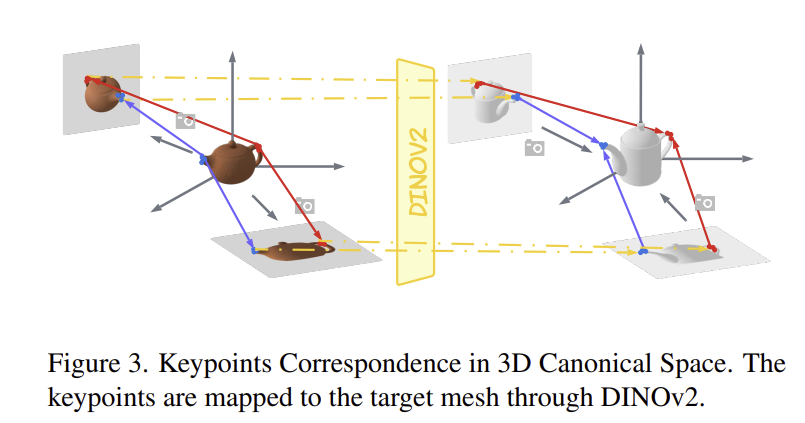
source mesh M_{src}에서 keypoint x \in \mathbb{R}^3와 대응되는 새로운 target mesh M_{tg} 위의 keypoint x'를 찾기 위해 6D Pose Estimator를 이용하여 주어진 mesh를 canonical space로 정규화합니다.(canonical space란, 동일 카테고리의 여러 인스턴스들의 형태를 맞춰주기 위해 정규화된 형태가 사전에 정의된 것이라고 이해하시면 될 것 같습니다.) 이후 n개의 view로 렌더링한 RGB-D 이미지 I_i (i=1,2, ...,n)를 구하고 DINOv2로 feature를 추출하여 semantic representation S_i를 얻습니다. 이후, source keypoint 주변의 m개의 mesh vertex v_j(j=1, 2, ...,m)를 선택하여 카메라 파라미터를 통해 I_i로 투영시켜 pixel coordinate u_{ij}를 구합니다. target image에도 DINOv2로 feature를 추출한 뒤, 코사인 유사도가 최대가 되는 위치u^{tg}_{ij}를 v_j에 대응되는 위치로 결정하고, 아래의 식을 통해 similarity score를 계산합니다.
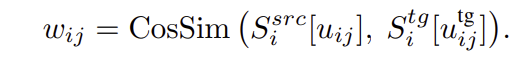
이렇게 구한 모든 matched pixel u^{tg}_{ij}를 다시 3D 공간으로 재투영시키고, similarity score들을 활용하여 가중합을 통해 target mesh 위의 대응되는 keypoint x'를 구합니다.
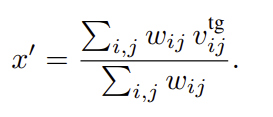
Diverse Demonstration Generation
저자들은 새로운 mesh에 대한 demonstration을 생성하기 위해 3단계 방식을 제안합니다. 또한, end-effector로 active object(e.g. 주전자)를 직접 조작하여, goal object(e.g. 컵)와 상호작용 하는 상황으로 로봇 조작 시나리오를 가정합니다.
1. Keypoint-constrained Trajectory Replay
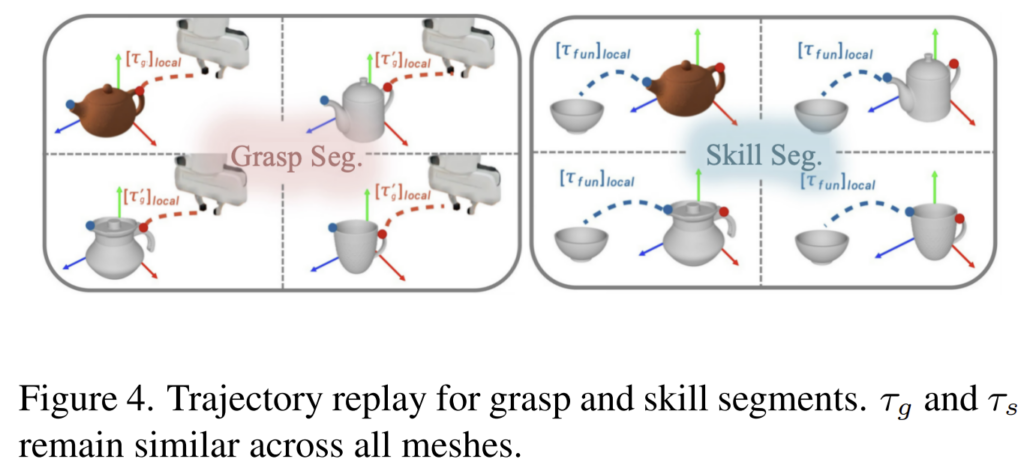
source demonstration의 grasp segment \tau_g와 skill segment \tau_s를 새로운 물체로 효율적으로 전이하는 것을 목표로 하며, affording point (x_{aff},x'_{aff})와 function point (x_{fun},x'_{fun}) 사이의 대응 관계를 활용합니다. 이때 저자들은 같은 function class에 속하는 물체들을 조작할 때, end-effector의 trajectory가 affording point를 기준으로 유사하고, function point의 trajectory는 goal object를 기준으로 유사하다는 가정을 사용합니다. 여기서 function class는 물체 카테고리가 다르더라도 비슷한 기능을 공유할 경우 같은 function class로 보는 개념입니다.
먼저 grasp segment \tau_g를 전이하기 위해, end-effector의 trajectory를 target affording point에 맞추어 전이하며, (**[ ]는 정규화를 의미)
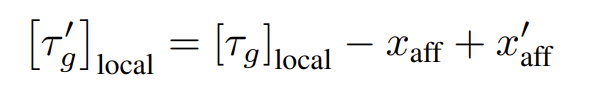
skill segment \tau_s를 전이하기 위해서는 function point trajectory를 target function point에 맞추어 이동시킨 뒤, end-effector로 복원하도록 합니다.
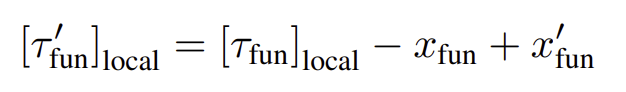
이후 Inverse kinematics solver를 이용하여 해를 구하여 각 waypoint마다 joint position을 구합니다.
2. Motion Planning for Transition Segment
앞서 grasp segment와 skill segment의 trajectory를 구하였고, 이 두 행동 사이를 연결하는 과정입니다. 이 두 행동 사이에서는 어떠한 상호작용이 포함되지 않으므로, 저자들은 collision-free free-space motion으로 보았습니다. 따라서 motion planning을 사용하거나 spherical linear interpolation을 이용하여 두 trajectory 사이를 보간하여 trajectory \tau_{m_i}를 구하였습니다. 즉, grasp segment의 마지막 pose와 skill segment의 첫번째 pose를 연결하는 경로를 구하는 것 입니다.

3. Point Cloud Digital Cousin Generation
새로운 물체에 대하여 trajectory를 구한 뒤, source data의 point cloud도 이에 맞추어 변환해야 합니다. DemoGen은 기존 point cloud에 단순한 global translation과 rotation을 적용하여 새로운 trajectory에 맞는 point cloud를 생성합니다. 이는 DemoGen이 생성한 trajectory가 주로 translation에 변화를 주었기 때문입니다.
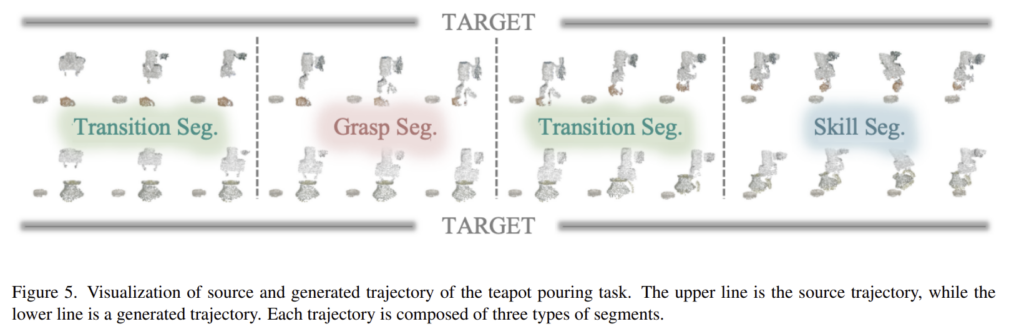
반면, 해당 논문에서는 workspace 안에서 다양한 3D 모델과 다양한 6D pose를 갖는 데이터를 생성하는 것을 목표로 합니다. 따라서, 시뮬레이션에서 물체의 point cloud를 렌더링 한 뒤, 대응되는 point cloud를 해당 렌더링 결과로 바꿉니다. 이를 통해 실제 시뮬레이션 환경을 완전히 재구성하는 번거로움을 피할 수 있으며, 실제 시뮬레이션으로 생성된 point cloud를 포함하므로 sim-to-real의 차이를 완화할 수 있었다고 합니다. 또한, 높은 처리 효율을 위해 병렬로 렌더링을 수행하며, 생성된 trajectory가 source demonstration과 어떻게 다른지는 Figure 5를 통해 확인하실 수 있습니다.
Experiments
저자들은 시뮬레이션과 real-world에서 모두 일반화 실험을 수행하였습니다.
1. Simulation Experiments
먼저, 시뮬레이터로는 ManiSkill3를 사용하였다고 합니다. 또한, grasp stage와 skill stage는 모두 포함하는 4가지 조작 task를 구성하여 실험을 진행하였습니다.

- “Teapot pouring”: 로봇으로 찻주전자 손잡이를 잡아 이동 및 기움여 주둥이로 목표 컵 위에 가도록 함
- “Mug haning”: 로봇으로 머그컵 손잡이를 잡고 이동시킨 뒤, 머그컵 손잡이 구멍에 랙의 돌출부 삽입
- “Knife cutting”: 로봇으로 칼 손잡이를 잡은 뒤, 칼날로 목표 음슥과 접촉하도록 조작
- “Shoe organizing”: 장기작업 및 다중 객체 작업으로, 신발 뒤꿈치 부분을 잡고 가까운 신발과 먼 신발을 올바른 방향으로 신발장에 배치
각 과제는 1개의 전문가 demonstration 데이터로 구성되며, PAM 데이터나 3D 생성 모델로 얻은 3D asset을 이용하여 1000개의 demonstration을 생성하였다고 합니다. 또한, 3D asset을 무작위로 seen/unseen으로 나누어 seen 데이터는 학습에, unseen 데이터는 평가에 사용합니다.
In-category Generalization Results
먼저 저자들은 각 작업에 ablation study를 수행하였습니다. 전체 demonstration 수는 고정한 상태에서, 데이터 생성에 사용된 mesh 수와 mesh당 demonstration 수를 변화시킨 조합(#mesh, #demos per mesh)이며, 학습된 policy는 mesh의 초기 위치와 방향을 무작위로 배치하여 50회씩 테스트 한 결과입니다.
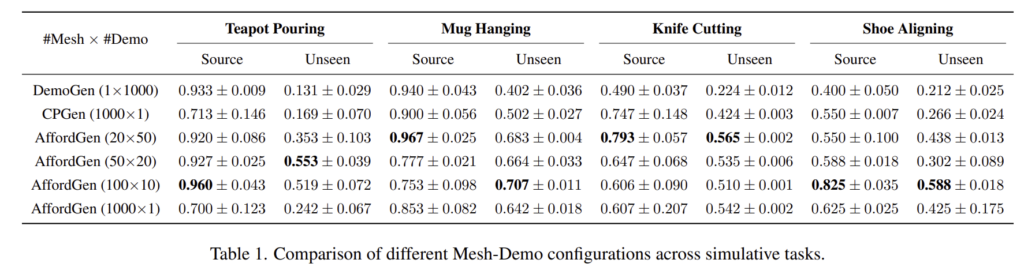
Table 1은 이에 대한 실험 결과로, DemoGen, CPGen, AffordGen은 모두 source mesh에 대해서는 공간적 일반화 성능을 보였습니다. AffordGen은 모든 task에서 DemoGen과 CPGen보다 우수한 성능을 달성하였으며, 특히 100×10 설정에서 unseen object에 대한 평균 성능이 24.1% 개선되는 것을 보였습니다.
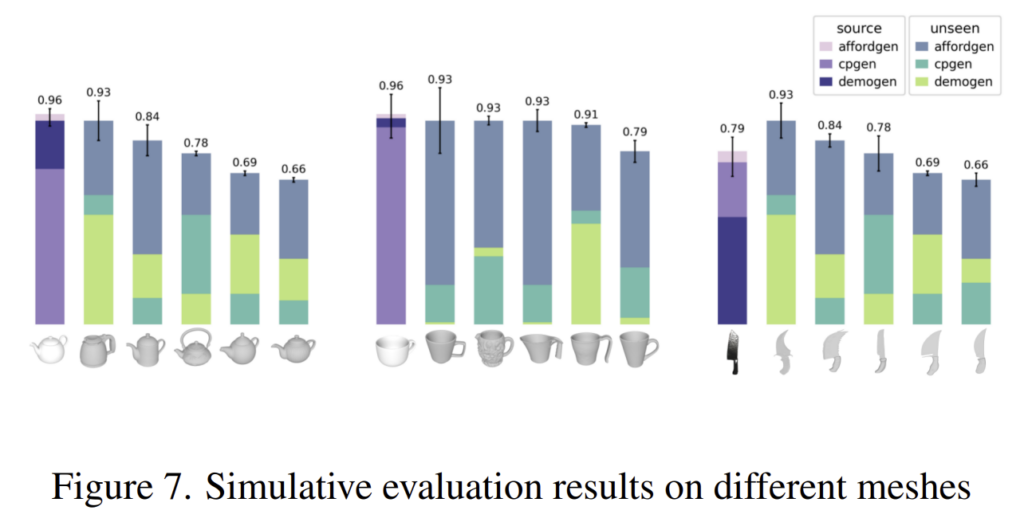
추가로, 저자들의 방식의 일반화 범위를 검증하기 위해 5개의 mesh를 선택하여 성능을 그래프로 나타내었습니다.(figure 7) 평가 mesh가 source mesh와 점점 달라질수록 성능이 점차 감소하지만, AffordGen은 모든 mesh에서 여전히 높은 성능을 유지하였습니다.
Zero-shot Cross-Category Results
저자들은 keypoint 대응 관계를 통해 서로 다른 카테고리의 물체에 대한 training 데이터를 생성하여 학습을 수행하였으며, 이렇게 합성된 데이터는 물체 카테고리가 다르더라도 기능적으로 공유된다면 새로운 물체에도 policy 학습이 가능합니다. 이를 검증하기 위해 저자들은 3가지 zero-shot cross-category policy learning 실험을 수행하였습니다.

- source task → target task
- teapot pouring → mug pouring
- mug haning → handbag hanging
- knife cutting → saw cutting
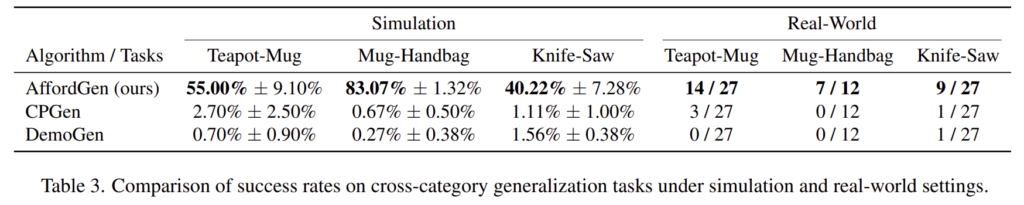
실험 결과는 Table 3에서 확인할 수 있으며 AffordGen을 통해 out-of-category 물체에 대해서도 효과가 있음을 보였습니다. Cross-category로 실험을 진행하였으며, 성능이 크게 개선되었다는 점에서 굉장히 유의미한 실험 같습니다.
2. Real World Experiments

시뮬레이션과 마찬가지로 4가지 작업을 수행하였으며, 각 과제마다 10개의 전문가 demonstration을 수집하였으며, 1000개의 학습 demonstration을 생성하였습니다. DemoGen의 설정을 따라, overfitting을 피하기 위해 실제 demonstration 수를 늘렸으며, 이후 생성된 데이터만으로 policy를 학습한 뒤, 이전에 보지 못한 다양한 실제 물체에 대해 학습된 policy를 평가했습니다.
In-category Generalization Results
모든 test object는 고정된 pose에서 평가되었으며, 대부분 27개의 pose(9개 위치 3개 방향 조합)를 사용하였습니다. 그러나 shoe organizing의 경우, long-horizon task이므로 10개의 pose(2개 위치 5 방향 조합)에서 평가되었습니다.
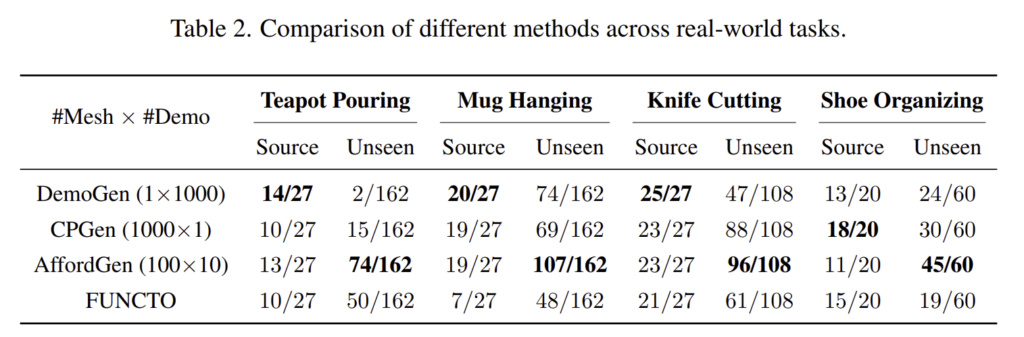
Table 2는 이에 대한 실험 결과로, 시뮬레이션과 유사한 경향을 보여주고 있습니다. 소량의 시연 데이터만을 사용했음에도 DemoGen, CPGen, AffordGen은 모두 source mesh에 대해 높은 성공률을 달성하였습니다. 그러나 Unseen object에 대한 실험 결과 저자들이 제안한 AffordGen이 뛰어난 성능을 보이는 것을 확인할 수 있습니다.
Zero-shot Cross-category Results

마찬가지로 real-world에서 cross-category에 대한 실험 결과로, figure 10은 이에 대한 세팅이며 정량적 결과는 위의 Table 3에서 확인하실 수 있습니다. Table 3의 실험 결과는 AffordGen이 real-world에서도 cross-category object manipulation data를 효과적으로 생성할 수 있음을 보여줍니다. 이를 통해 낮은 비용으로 실제 로봇의 조작 능력을 더 넓은 범위로 확장할 수 있음을 보였습니다.
Conclusion
AffordGen은 로봇 학습 과정에 발생하는 데이터 부족 및 일반화 문제를 해결하기 위해 affordance 대응 관계를 활용하는 새로운 프레임워크를 제안하였습니다. AffordGen을 통해 최소한의 demonstration을 다양한 물체 카테고리 전반에 걸쳐 수천개의 다양한 학습 데이터로 확장하며, 이 합성 데이터 셋을 통해 unseen object에도 일반화 가능한 policy를 학습할 수 있었음을 실험적으로 보였습니다.
리뷰 잘 읽었습니다. 몇 가지 궁금한 점 댓글 남겨두겠습니다
DINOv2 feature 기반으로 2D→3D semantic matching을 수행한다고 했는데, 서로 다른 카테고리 간(out-of-category)에서도 이 매칭이 안정적으로 유지되는지 궁금합니다. 특히 texture나 geometry가 크게 다른 경우에도 correspondence가 잘 유지될 수 있는걸까요?
다음으로 방법론에서 keypoint 기반으로 trajectory를 생성한 뒤 inverse kinematics로 joint를 구한다고 했는데, IK 해가 존재하지 않거나 unstable한 경우는 어떻게 처리하는지 궁금합니다.
질문 감사합니다.
말씀하신대로, texture와 geometry가 다르다는 어려움이 존재하지만, 해당 논문에서 canonical space를 사용하는 것이 핵심인 것 같습니다. canonical space는 특정 카테고리에 해당하는 물체들에 대한 표준화된 참고 자료를 만든 것으로, 예륻릉러 “주전자”라는 카테고리가 있다면 다양한 texture와 기하학적 형태를 가진 주전들을 평균내어 손잡이, 주둥이, 몸통 부분으로 구성되는 대표적 형태로 만들어 사용하는 것 입니다. cross-category에 대해서도, 이러한 손잡이 부분의 공통적인 특성을 활용한 것이 아닐까 하는 생각이 듭니다.
IK 해가 존재하지 않거나 불안정한 경우에 대해서는 따로 저자들이 언급하고 있지는 않습니다. 사용하는 라이브러리를 통해 최대한 안정적으로 해를 구하고 joint를 조절하도록 하지 않을까요..?