안녕하세요, 이번주 X-review는 NVIDIA의 가장 간판 프로젝트 중 하나인 GR00T에 대해 작성하려고 합니다. 기존 로봇 파운데이션 모델들이 주로 단일 팔, 병렬 그리퍼, tabletop manipulation 중심으로 발전했다면, GR00T는 처음부터 휴머노이드 로봇을 주요 대상 embodiment로 놓고 설계된 open foundation model입니다. 논문은 N1에 대한 논문만 존재하지만 N1부터 시작해서 현재는 N1.7까지 발전했고, tabletop에 머물던 policy도 이젠 humanoid locomotion까지 통합해버린 상황입니다. 이번 휴머노이드 과제 제안서를 쓰기 위해 휴머노이드 제어를 위한 VLA는 어떤 차별점이 있는지, 어떤 디테일들이 추가됐는지 알아보려고 합니다.
GR00T N1
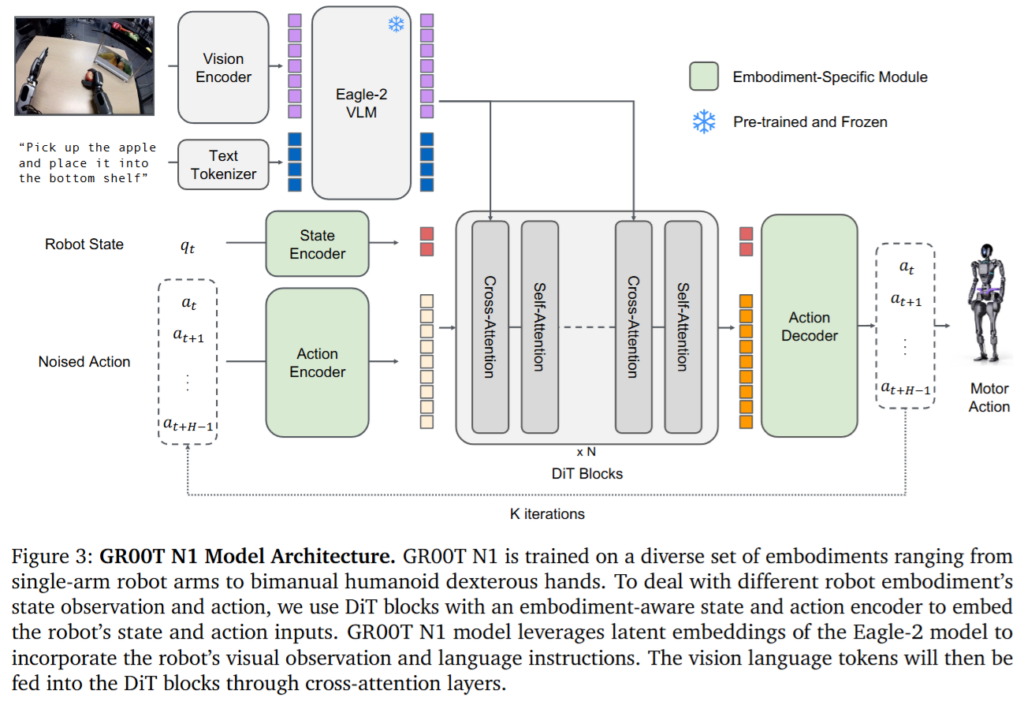
사실 GR00T가 크게 아키텍쳐 적으로 특별하거나 새로운 부분들은 적었습니다. Vision encoder, Text encoder, State encoder의 정보들을 다 같이 처리해 action을 반환하는 구조입니다. VLM 기반 reasoning token과 DiT 기반 action token을 cross-attention으로 엮어서 action expert가 처리해주게 되는데, 언어와 장면에 대한 이해는 System 2가 느리게 담당하고, 실제로 로봇을 제어하는 쪽에 관여하는 연속 motor command는 System 1이 담당하는 구조입니다. 논문 기준으로 System 2는 10Hz, System 1은 120Hz 정도의 closed-loop action을 생성합니다. 다만 이제보니 단순히 모델 구조가 중요한게 아니라 GR00T라는 큰 프로젝트를 달성하기 위해 다양한 연구를 진행하고, 그 연구들이 다 유기적으로 연결된게 중요한 것 같습니다.
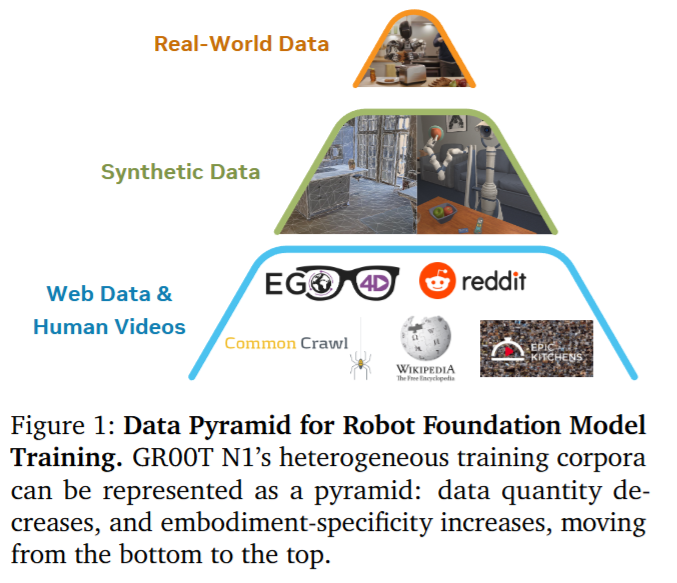
GR00T N1의 첫 번째 차별점은 휴머노이드 데이터 부족 문제를 데이터 피라미드로 접근했다는 점입니다. 저자들은 real-world robot data를 피라미드의 꼭대기, simulation과 neural-generated data를 중간층, web data와 human video를 맨 아래 층으로 정의했습니다. 각각 퀄리티가 좋지만 모으기 힘든 데이터부터 아래로 갈수록 구하기 쉽지만 의미만 남아있는, 로봇 입장에서는 퀄리티가 좀 떨어지는 데이터 입니다. 이 설계가 휴머노이를 고려했을 때 매우 현실적인 판단이었다고 합니다. 실제로 최근 다양한 연구들이 수행되기 이전 시기에 humanoid로 양손 조작 데이터를 수천 시간 모으는 것은 비용이 너무 많이 들기 때문에 어쩔 수 없는 선택이지 않았나 싶긴 합니다. 따라서 저자들은 사람의 egocentric video, simulation trajectory, neural video trajectory, real robot trajectory를 동시에 학습할 수 있도록 유도했다고 합니다. Action label이 없는 human video와 neural video에는 latent action 또는 IDM 기반 pseudo-action을 붙여 robot embodiment처럼 취급했다는 점이 핵심입니다.
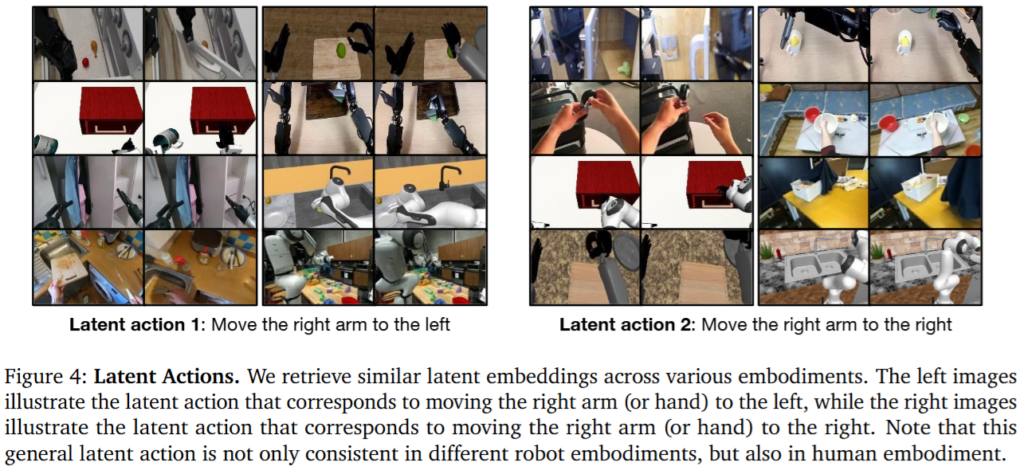
두 번째 차별점은 cross-embodiment 제어를 architecture 수준에서 반영했다는 점입니다. GR00T N1은 로봇마다 state/action dimension이 다르다는 문제를 embodiment-specific state encoder, action encoder, action decoder로 처리했습니다. 각 embodiment의 proprioception과 action을 공통 embedding 공간에서 다루며 policy reasoning을 수행하도록 만든 구조입니다. 휴머노이드 관점에서는 이 설계가 특히 더 중요하다고 합니다. 아마 휴머노이드마다 전부 설계 구조나 dof가 다르기 때문이지 않을까 싶습니다. 다양한 로봇들의 action dimension과 관절 의미가 전부 다르지만, “집기”, “옮기기”, “놓기”, “handover” 같은 조작 의미는 공유될 수 있기 때문에 이 구조가 휴머노이드에 필수적이었던 것 같습니다.
하지만 N1이 처음 등장했을 때에는 한계가 존재했습니다. 주로 short-horizon tabletop manipulation에 집중되어 있으며, loco-manipulation을 다루지 못 했습니다. GR00T 모델들은 향후에 단순히 모델 크기를 키우는 방향이 아니라, 언어 grounding 강화 -> embodiment 확장 -> whole-body/loco-manipulation stack 결합 -> egocentric data scaling을 통한 dexterity 확장으로 이루어졌습니다.
GR00T N1.5
N1.5에서 생긴 가장 큰 핵심 변화는 FLARE (Future Latent Representation Alignment) 가 추가된 것입니다. N1은 flow matching으로 action generation을 학습하는 구조였지만, N1.5는 미래 latent representation에 대한 objective 까지 더했습니다. 휴머노이드 제어 관점에서는 언어 지시를 따라 행동하려면 현재 프레임에서 바로 다음 action만 맞추는 것이 아니라, “이 행동이 몇 초 뒤 어떤 상태로 이어져야 하는가”를 representation 수준에서 학습 되어야 한다고 합니다. (근데 이건 뭔가 휴머노이드 특화라고 보긴 좀 어렵지 않나 싶긴 합니다.) 어쩄든 N1.5는 FLARE를 통해 human video로부터 더 직접적으로 배울 수 있게 되었고, 결과적으로 novel object manipulation과 new verb generalization에서 개선을 보였다고 합니다.
FLARE를 간단하게 소개하자면 implicit world modeling을 수행하는 보조 학습 구조입니다. 이 시기에 world model이 학습하듯이 다음 상황을 pixel level로 학습을 해야 VLA가 단순히 궤적을 외우는 것에서 벗어날 수 있다는 연구들을 접하기 시작했던 것 같은데, FLARE는 미래 이미지를 전체적으로 다 구성할 필요 없이 compact한 representation 형태로만 예측하는 쪽으로 갔습니다. 그래서 future frame을 생성하지 않고, 미래 observation을 VLM/embedding model이 뽑은 latent embedding과 현재 policy 내부 feature를 정렬했습니다.
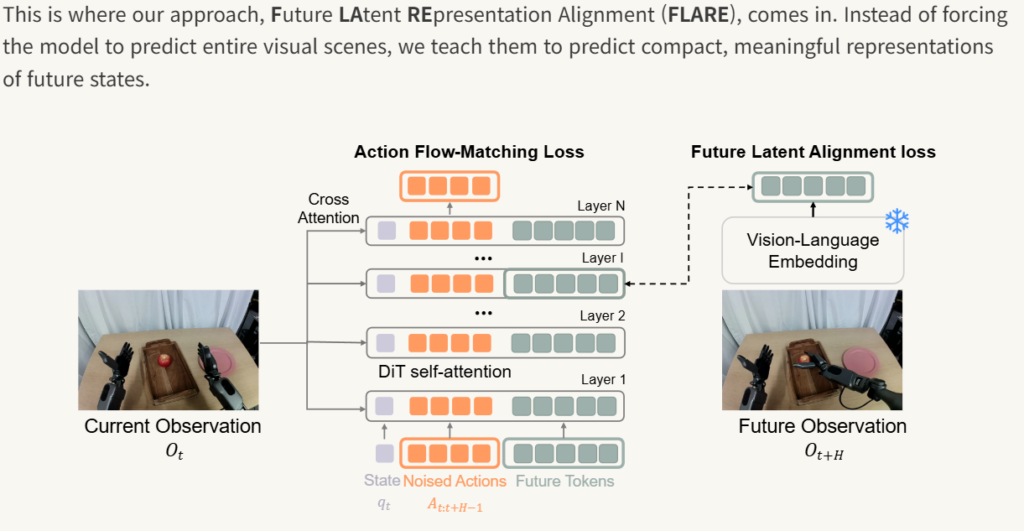
FLARE는 기존 VLA/Diffusion Transformer policy에 learnable future token을 더해주었습니다. Policy는 원래처럼 flow matching loss로 action chunk를 예측합니다. 이 때 DiT 내부의 future-token feature가 실제 미래 observation의 latent embedding과 가까워지도록 alignment loss를 추가로 학습했습니다. 이를 통해서 action label이 없는 human egocentric video를 본격적으로 학습에 쓸 수 있었다고 하빈다. Action에 대한 loss는 주지 않고 future alignment loss 쪽으로만 활용해서 많은 egocentric 비디오를 통해서 모델이 세상에 대한 이해를 할 수 있도록 유도했다고 합니다. 이 FLARE loss가 GR00T N1.5에서도 policy performance를 높이는데 핵심 구조였다고 합니다.

결과적으로 현재 프레임에서 바로 다음 action만 맞추는 것이 아니라, “이 행동이 몇 초 뒤 어떤 상태로 이어져야 하는가”를 representation 수준에서 이해하는 모델이 되었고, novel object manipulation과 new verb generalization에서 확연한 개선을 보였다고 합니다.
추가로 DreamGen이라는 연구를 통해서 부족한 데이터를 Synthetic Data로 수급하기도 했습니다. 해당 부분에 대한 자세한 내용은 기현님 리뷰 참고해주시면 될 것 같습니다,,!
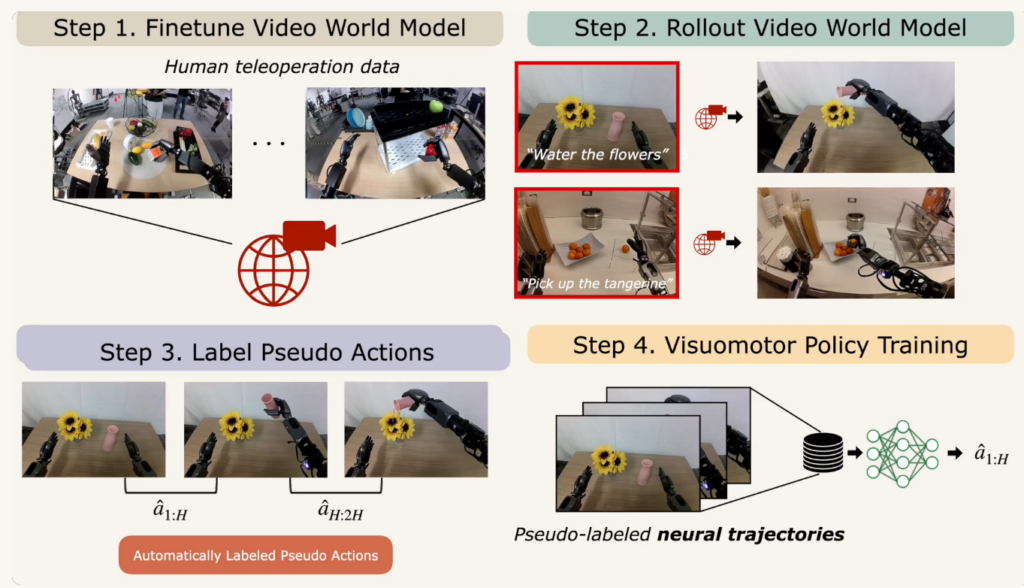
GR00T N1.6
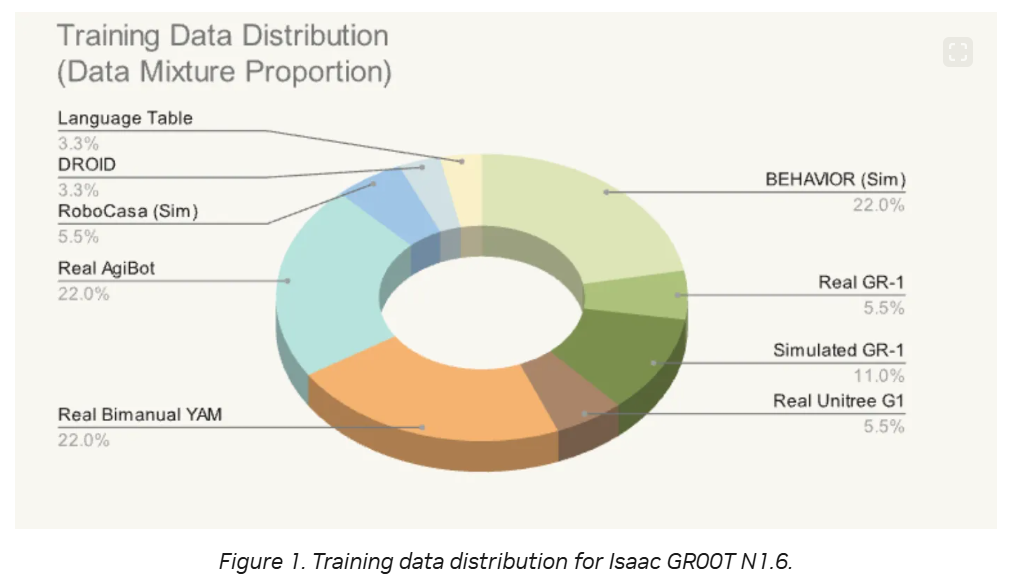
N1.6에서 가장 두드러지는 변화는 이전까지는 tabletop manipulation만 고려되었다면, loco manipulation으로 확장되었다는 부분입니다. 그러면서 DiT layer도 16에서 32로 두배로 늘렸다고 하네요. Pretraining용 데이터도 N1.6 pretraining에는 N1.5 mixture를 넘어 bimanual YAM arms, AGIBot Genie1, BEHAVIOR suite의 simulated Galaxea R1 Pro, Unitree G1 whole-body locomanipulation 데이터가 추가되었다고 합니다. GPU rail insertion, dish rack placement, t-shirt folding, cube handover, table bussing, fruit packing, cart에서 물체 집기, drawer에서 eraser 집기 같은 더 복잡한 bimanual 및 mobile manipulation에 대한 데이터가 수집되었다고 하네요. 또 absolute action대신 state-relative action chunk를 예측하도록 바뀌었습니다.
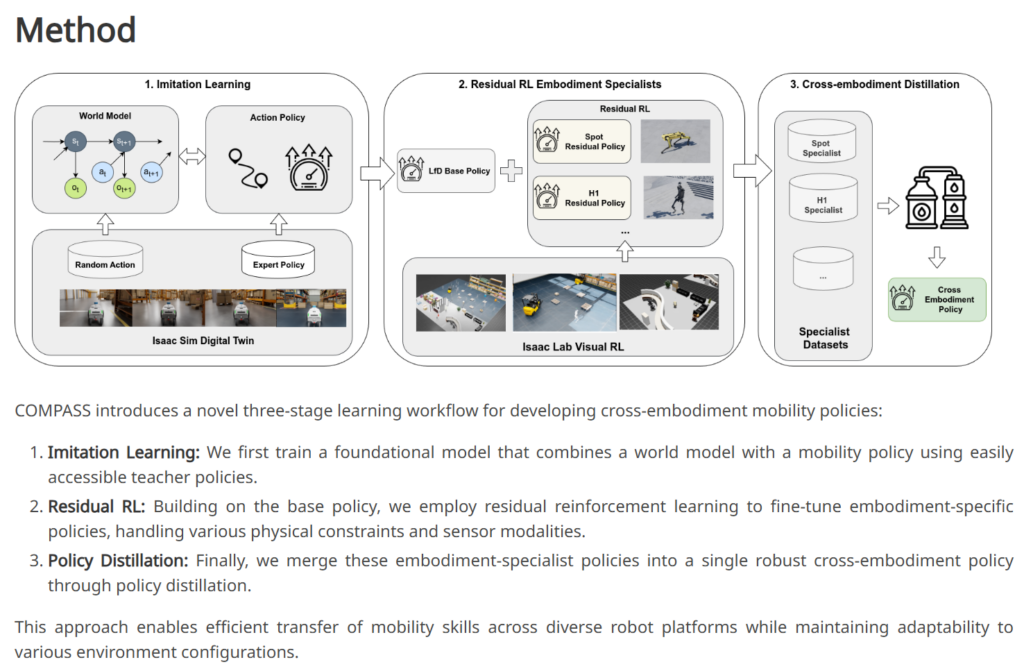
또 humanoid control을 해야하기 때문에 이를 위한 연구들이 추가됐습니다. Control stack 관점에서 더 명확한 계층화를 진행했다고 합니다. COMPASS라는 연구 기반의 synthetic-data-trained navigation, CUDA-accelerated visual mapping/SLAM과 결합된 sim-to-real workflow가 사용됐다고 하네요. Whole-body controller는 balance와 contact 안정성을 담당하고, GR00T의 high-level VLA는 task sequencing과 scene-aware decision-making에 집중하는 구조라고 합니다.
COMPASS (ICRA 2026)라는 연구는 Imitation Learning 기반으로 velocity command를 출력하는 base policy를 학습하고, 시뮬레이션 상에서 base action을 보정하는 residual correction을 RL을 통해 학습한 뒤 다시 policy로 distill하는 구조입니다. GR00T가 cross embodiment를 강조하는데, loco manipulation에서도 이 부분을 챙겨간 포인트라고 보시면 될 것 같습니다. (필요시에 추후 리뷰로 좀 더 자세하게 다루도록 하겠습니다) 핵심은 GR00T가 high level에서 뭘 해야하는지를 안 다면, 어떻게 해야하는가를 navigation 쪽에서 집중한 모듈입니다.
Discussion을 보면 GR00T N1.6의 핵심 개선 방향은 실제 로봇에서의 post-training 안정성 강화입니다. 대부분의 embodiment에서 absolute action보다 relative action을 기본 action space로 사용해 더 부드럽고 정확한 motion을 얻었지만, 데이터가 적을 경우 오차가 누적되어 correction 능력이 떨어질 수 있었다고 합니다. Task 분포가 pretraining과 유사하면 pretrained statistics가 성능을 높이지만, 분포가 다르면 post-training statistics를 써야 underfitting을 줄일 수 있다고 하네요. Finetuning 시에 활용되는 데이터에 대한 분석의 중요도가 중요해진다고 볼 수 있을 것 같습니다.
다만 N1.6은 N1.5보다 빠르게 수렴하고 더 smooth한 action을 만들지만 overfitting 위험도 커서, 강한 state regularization, 추가 data augmentation, pretraining data와의 co-training이 필요했다고 합니다. 또 DAgger가 효과적인 보정 전략으로 작용할 수 있을 것이라고 합니다. 다만 multi-task language following과 OOD task generalization은 여전히 어렵고, robust generalization까지도 도달하지 못한 상태로 마무리됐다고 하네요. 어떻게 보면 Sim2Real이 큰 부분을 차지한 연구라고 볼 수도 있을 것 같습니다.
GR00T N1.7

마지막으로 N1.7인데요, 1.7은 dextrous함에 초점을 맞췄다고 합니다. 일단 System2의 VLM 백본으로 Cosmos-Reason2를 사용했다고 합니다. 다만 핵심은 human egocentric video pretraining이라고 하네요. N1.6에 사용된 전체 pretraining용 로봇 데이터가 몇천시간 정도인데, N1.7에서는 2만 시간이 넘는 human video가 포함됐다고 합니다. 요 연구가 이번에 발표된 EgoScale이고, 해당 부분에 대한 자세한 사항은 제 이전 리뷰를 참고해주시면 좋을 것 같습니다. 결국 핵심은 robot dexterity에 대한 scaling law를 human video에서 찾아냈고, human video를 학습하는 방법까지 제안해싿고 보시면 될 것 같습니다.
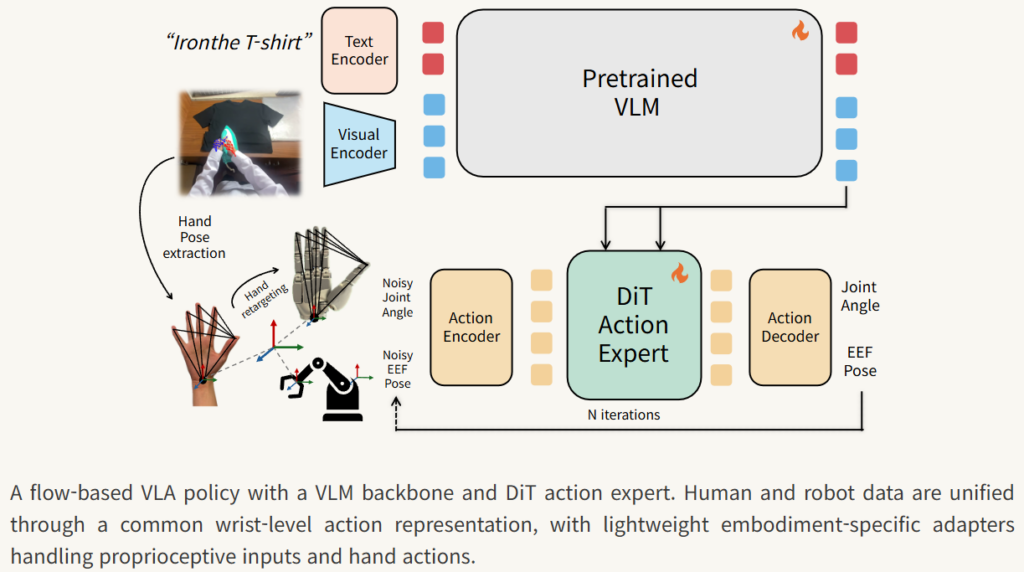
22-DoF dexterous hand처럼 finger-level control이 중요한 상황에서는 robot teleoperation data만으로는 scale을 만들기 어려운게 크기 떄문에 해당 방법론이 더 의미를 갖는다고 합니다. N1.7은 이 병목을 human egocentric video와 wrist/hand action representation으로 푸는 방향입니다.
좀 큰 흐름으로 다시 정리를 해보자면 GR00T의 발전 흐름은 다음과 같습니다. N1은 humanoid VLA foundation model의 기본 구조를 세웠습니다. System 2 VLM과 System 1 DiT를 결합하고, data pyramid를 통해 human video, synthetic data, real robot data를 통합했습니다. 그 다음에 N1.5는 그 구조 위에서 language following과 grounding을 강화했습니다. FLARE와 DreamGen을 활용해 neural trajectory, human video와 synthetic robot video와 같은 피라미드의 아래층에 있는 풍부한 데이터들을 효과적으로 학습시켰다고 볼 수 있습니다.
N1.6부터는 실제로 일할 수 있는 휴머노이드 로봇용 policy를 노린 느낌이어서 그런지 Cosmos VLM 활용, 더 커진 32-layer DiT, state-relative action, 다양한 real humanoid/semi-humanoid embodiment, whole-body/navigation/localization workflow가 통합된 것을 볼 수 있습니다. N1.7은 더 나아가서 human egocentric video scale을 결합해 dexterous manipulation까지 해결하려는 움직임 입니다.
안녕하세요 영규님, 좋은 리뷰 감사합니다.
휴머노이드 과제를 목전에 두고, 활용가치가 높아보이는 GROOT-N 시리즈를 큼직하게 핵심 위주로 잘 정리해주신 것 같습니다. NVIDIA의 행보에 대한 좀 막연한 의견을 묻는 질문이 하나 있는데요.
N1부터 시작된 NVIDIA의 변치 않는 하나의 큰 목적은, cross-embodiment 제어를 위해선 역시 data scaling law가 우선이고 핵심이다로 이해했습니다. 개인적으로는 그 방대한 데이터를 기가 막히게 action generation 용으로 꽉꽉 눌러 담고 뽑아 쓰기 용이하게 하는 latent space나 아키텍쳐에 대한 패러다임 설계 자체도 중요하다고 생각이 드는데요. 지금은 왠지 NVIDIA가 다들 쓰고 있는 구조(Dual-system VLA, LAPA, IDM, flow matching loss) 위에 data scaling 위주 변화들만 적응적으로 덧붙이고 있는 느낌도 들거든요. NVIDIA가 groot 1.7 이후로 data scaling law의 잠재력을 더 폭발적으로 키울 또 다른 제2의 무기는 무엇이 될 수 있을지, 혹은 간과하고 있는 건 무엇일지, 혹시 대략적으로 짐작가는 방향이 있는지 궁금합니다.
감사합니다.
안녕하세요 재찬님 댓글 감사합니다.
Cross Embodiment 제어에 대해서는 다양한 미국 중국 테크 회사들이 풀어내고 있고 해석도 다각화 되어있는 것으로 보입니다. NVIDIA는 cross embodiment에 대한 설계는 데이터를 통해 간접적으로 증명하는 것 같고, 와중에 휴머노이드에 집중하는 모습이 요새는 보이고 있는 것 같습니다.
재찬님이 집중하고 계시는 manifold 설계를 직접적으로 다루는 연구는 못 본것 같고, latent를 모델링하는 경우는 LAPA나 cosmos-policy 정도 있는 것 같습니다. 해당 연구들은 기존 VLA와는 다른 latent 설계를 하고 있다고 생각합니다.
마지막 질문에 대해서는 요즘 NVIDIA는 egocentric한 human video에 집중하고 있는 것으로 보입니다. 실제로 세미나 발표했던 EgoScale의 pretraining또한 gr00t 1.7에 적용되었고 이후에도 human video를 통한 연구를 하고 있는 것으로 압니다. 물론 워낙 다방면으로 연구하니 world model등 다른 연구들도 많지만 그 중 gr00t에 적용된 연구가 EgoScale이라 해당 답변 남깁니다.
오 영규님 좋은 리뷰감사합니다.
GROOT의 발전단계를 보면서 NVIDIA의 큰그림도 동시에 글에 작성되어있어서 재밌게 읽었습니다. 근데 제가 이해하기에는 좀 어려운 부분이 System 1, 2 를 따로 받는 그 말이 아직 이해가 안되는 것 같습니다. 그 제가 알기론 옵티머스 로봇도 그런식으로 system 1 , system 2로 두고 다르게 받으면서 한다고 했었던거같은데 그런거랑 동일한건가요 ? 이 부분이 이해가 좀 필요할거같고 가장중요한거 같아 질문 남깁니다…!
감사합니다
안녕하세요, 우진님. 댓글 감사합니다.
Dual-system, 즉 System 1 / System 2 구조는 최근 pi 시리즈나 말씀하신 Helix와 같은 로봇 파운데이션 모델에서도 자주 사용되는 설계 방향입니다. 이는 이미 인간 인지 분야에서 연구된 인간의 인지 구조에서 이야기되는 System 1 / System 2 개념을 로봇 정책 구조에 대응시켰다고 보면 됩니다.
예를 들어 사람이 “흰색 컵 좀 전달해줘”라는 요청을 받았을 때, 먼저 흰색 컵이 어디 있는지 찾고, 어떤 물체를 집어야 하는지 판단하는 과정은 비교적 느리고 의식적인 인지 과정에 가깝습니다. 이 과정이 system 2 입니다. 반면, 컵을 인식한 뒤 손을 뻗고, 컵을 잡고, 이동 중 놓치지 않도록 미세하게 힘과 자세를 조절하는 과정은 훨씬 빠르고 자동화된 감각-운동 제어에 가깝습니다. 이 과정이 system 1 입니다.
VLA에서도 이를 비슷하게 나누어 볼 수 있습니다. System 2는 주로 시각-언어 정보를 바탕으로 현재 장면과 명령을 이해하는 역할을 하고, 이 부분에는 VLM이 백본으로 사용됩니다. 반면 System 1은 System 2에서 얻은 고수준 정보와 현재 로봇 상태를 조건으로 받아 실제 action을 생성하는 역할을 합니다. 이때 action expert는 diffusion 또는 flow matching objective 기반으로 구성되는 경우가 많습니다.
핵심은 System 2가 “무엇을 해야 하는지”를 이해하고, System 1이 그 이해를 바탕으로 “어떻게 움직일지”를 빠르게 생성한다는 점입니다.
안녕하세요. 좋은 리뷰 감사합니다. 읽으면서 궁금한 부분이 있어서 질문 남깁니다!
Q1. 피라미드 하단의 데이터가 양이 많아서 활용하면 좋을 것 같은데, pseudo labeling과 같은 방법으로 robot에 맞는 data로 변환을 해주는 과정을 통해 활용 가능하도록 만든 것이라고 이해했습니다. 이런 방법의 한계나 성능에 영향을 주는 큰 차이가 무엇인가요?
Q2. action에 대한 loss를 주지 않고, future alignment loss만 활용하는 방식은 action label이 없는 데이터에만 적용하나요? pseudo labeling을 거친 데이터도 해당하는 부분인지 모든 데이터에 적용하는 방식인지 궁금합니다.
감사합니다.
안녕하세요 성민님 댓글 감사합니다.
A1. pseudo labeling을 하게되면 perception pipeline에 의존하게 되면서 정밀한 annotation이 불가능합니다. 또한 데이터의 소스 자체가 로봇 embodiment나 로봇의 작업 환경에서 취득한 데이터가 아니기 때문에 internet scale의 인간 시연 영상에는 kinematics에 대한 gap과 실제 시각적인 gap 둘 다 존재합니다.
A2. FLARE에서 action loss 없이 future alignment loss만 사용하는 경우는 주로 action label이 없는 데이터에 해당합니다. 로봇 teleoperation 데이터처럼 실제 action label이 존재하는 경우에는 기존의 action flow-matching loss와 future latent alignment loss를 함께 사용합니다. 반면 human egocentric video처럼 현재 관측과 미래 관측은 있지만 로봇 action이 없는 데이터에서는 action supervision을 줄 수 없기 때문에 future alignment loss만 사용해 latent dynamics를 학습합니다.
따라서 future alignment loss는 action label이 있는 데이터와 없는 데이터 모두에 적용될 수 있지만, action loss는 action label이 존재하는 데이터에만 적용된다고 보는 것이 맞습니다. 논문에서 다루는 human video 활용 방식은 pseudo action label을 만들어 action loss를 주는 방식이라기보다는, action label 없이도 future observation embedding을 맞추는 방식으로 데이터를 활용하는 쪽에 가깝습니다. 만약 별도로 pseudo labeling을 통해 신뢰 가능한 action label을 만든다면 action loss를 추가할 수도 있겠지만, FLARE 논문에서 핵심적으로 주장하는 설정은 pseudo-labeled action supervision보다는 action-free video를 future alignment로 활용하는 방식이라고 보면 될 것 같습니다.