안녕하세요 이번에 들고온 리뷰할 논문은 Scale Depth 라는 논문입니다. 2024년 10월에 아카이브에 올라왔지만 아직 어느 학회에도 게재가 되지는 않은 논문입니다. 다른 Depth 논문들과는 다르게 이미지를 처리하는 백본이 CLIP encoder라는 점, 그리고 해당 모델이 text를 input으로 받아 text CLIP encoder로 처리한다는 점에서 제가 이제 막 과제와 관련해서 진행하고 있는 연구에 어쩌면 잘 활용해 볼 수 있지 않을까 라는 생각을 가지고 읽게 되었습니다.
아직은 논문을 읽는데에 있어서 논문의 지식을 흡수하고 이해하는데 에너지 소모가 많이 되는 단계라 모든 정보들이 새롭게 느껴지고, 제시된 방법론들이 다 좋은 방법론이다라고 받아들이면서 읽게되는 것 같습니다. 아직까지는 스스로가 비판적인 시각을 가지면서 논문을 읽지 못하는 점이 조금 아쉽게 느껴집니다.
각설하고 리뷰를 시작하도록 하겠습니다.
introuction
한장의 단일 이미지를 가지고 어떤 실제 물리적 단위가 있는 절대 거리를 예측하는 것에 대한 연구가 활발히 진행이 되고있는데, 저자는 서두에서부터 단일 이미지로 부터 실제 깊이를 추정하는 것은 어려운 과제다라고 얘기를 하면서 잘 정의되지 않은 문제(ill-posed problem)이다라고 말하면서 시작합니다.
예를 들어, stereo 카메라 같은 경우 두가지 시점 간의 기하학적인 정보가 명확해 깊이를 유추할 수 있지만, 하지만 오직 한 장의 이미지만으로는 적용될 수 있는 기하학적인 정보가 무수히 많다보니, 예를 들어 해당 이미지가 zoom in 된 이미지 인지, 단순히 crop 된 이미지 인지, 가까이서 찍은 사진 인것인지 등등 여러가지 상황이 될 수 있기 때문에, 잘 정의되지 않은 문제라고 말합니다.
수학적으로 ill-posed란 해가 유일하지 않다 라는 것을 의미한다고 합니다.
정리하자면 단일 이미지 한장으로는 정보가 부족해서 깊이를 정확히 추정하기가 어렵다 라고 생각학시면될 것 같습니다.
저도 처음에는 단순히 depth estimation 분야에 대해 내용을 처음 접하게 되었을 때에는 단순히 이 depth estimation 이라는 친구들이 pixel 단위로 무언갈 예측하는데 segmentation이랑 큰 틀에서는 비슷하게 동작하겠구나 이런 생각을 가지고 조금 쉽게 생각했던 것 같습니다. 실제로는 실제 깊이 추정에 있어서는 해당 영상이 얻어졌을 당시의 카메라 파라미터들, 기하학 정보들, 또 어떤 씬들의 스케일 등등 정말 고려해야할 것이 많구나 라는 것을 깨닫게 된 것 같습니다.
다시 돌아와서 한장의 이미지만으로는 정보가 부족하니 전통적인 방법들은 수작업으로 한장의 이미지를 가지고 기하학적인 사전 지식을 학습하기 위해서 hand-crafted featrues에 크게 의존했다고 합니다. 그래서 위와 같은 수작업의 cost를 줄이고자, 여러가지 학습 기반의 방법론들이 나오게 되었는데, 이를 크게 두가지 범주로 나누게 됩니다.
- Relative Depth Estimation
- Metric Deptrh Estimation
Relative Depth Estimation은 말그대로 단순히 상대거리를 예측하는 것입니다. 수작업으로 기하학적인 사전지식을 뽑는게 힘드니깐 그러한 사전 지식을 조금만 사용하되 물리적인 실제 depth를 뽑는 것이 아닌 해당 물체가 이 물체보다 가깝냐 머냐 이러한 상대적인 거리만을 예측할 수 있도록 하는 방법론들이 제안이 되었습니다. 이러한 방법들은 실제 현실세계의 복잡한 응용 예를들어 로봇의 파지나 장애물 회파와 같은 작업을 처리하는데에는 한계가 있을 수 있습니다.
따라서 실제 물리적 거리를 예측하는 Metric Depth Estimation 방법들이 현재 단안 깊이 추정(단일 이미지)분야에서 주류로 자리잡게 됩니다. 보통 이러한 MDE 방법들은 일반적으로 이미지-깊이 쌍으로 구성된 단일 데이터 셋에서 학습이 이루어지고 각 픽셀에 대한 절대 깊이 값을 직접 regression하는 방식을 따르는데요, 근데 이러한 방법들은 스케일 차이가 큰 장면들에 대해서는 고려를 하지 않기 때문에 indoor데이터에서 학습된 모델이 outdoor일반화 되기는 어렵다는 문제가 있습니다.
그래서 단안 깊이 추정 모델인 Zoedepth는 위와 같은 문제 때문에 indoor depth estimation과 outdoor depth estiamtion을 별도의 prediction Head로 처리하는 구조로 설계를 하여 처리를 하고, 또 다른 방법론들은 깊이를 일정한 구간(bin)으로 이산화해서 그 구간을 학습 가능한 파라미터로 두어 각 이미지에 대해 적응적으로 깊이 분포를 추정하려고 시도를 하고, 또 다른 방법론은 카메라 파라미터를 이용해서 저자가 언급한 문제를 해결하고자 하였습니다.
하지만 저자는 앞서 언급한 방법들은 scene scale을 명시적으로 모델링하지 않고, 방대한 양의 학습데이터에 의존한다는 한계가 있다고 지적을 합니다.
따라서 저자는 위와 같은 장면간 scale 문제를 해결하기 위해 2가지 핵심 고려사항을 제시합니다.

(1) 장면 범주 간에는 깊이 범위의 차이가 크고, 같은 범주 내에서는 차이가 작다
먼저(c)와 (d)를 보시면 같은 classroom이라는 범주에 속하는 씬의 깊이 범위는 유사하다라는 것을 확인할 수 있고, (a)와 (b)를 비교해보시면 실외와 부엌에 해당하는 씬은 일반적으로 더 큰 깊이 범위의 차이를 보이는 것을 확인 할 수 있습니다. (b)와 (c)또한 비교를 해보면 같은 실내이지만 부엌과 교실 역시 (a)와(b)정도의 차이는 아니지만 그래도 어느정도 스케일 차이가 존재한다고 볼 수 있습니다. 저자는 이러한 스케일 차이가 여러 장면들 특히 실내와 실외를 통합한 모델을 만들지 못한 주된 원인이라고 주장하는데요. 여기서 장면의 스케일만 명시적으로 모델링을 할 수 있으면 모델은 그 이후에 상대적인 깊이 관계만 추론하면 끝이다 라는 식으로 metric depth estimation을 scale prediction과 relative depth estimation의 문제로 분리를 해버리게 됩니다.
결국 해당 장면에 대한 시멘틱 정보를 활용해서 모델이 해당 씬이 oudoor 씬인지, kitchen인지, classroom인지를 알고 이 장면이 kitchen이라면 이 씬의 스케일은 이정도가 되겠구나 라는 아이디어를 가지고 해당 장면의 시멘틱 정보로 스케일을 알도록 하는 Scale-Aware Scale Prediction(SASP)이라는 모듈을 제안하게 됩니다.
(2) 동일한 범주의 객체도 장면 내 위치에 따라 깊이가 다를 수 있다
그리고 위는 두번 째 고려사항인데요, 처음 저 문장을 읽었을 때는 너무 당연한 이야기라서 어떻게 해석을 해야할지 몰랐었습니다. 아직도 제가 올바르게 이해했는지 살짝 의문이 들긴하지만 최대한 이해한 내용을 바탕으로 풀어서 작성해보도록 하겠습니다. 먼저 (e) Plants 사진을 보시면 똑같이 생긴 화분 3개가 각기 다른 위치에 각기 다른 depth를 가지고 있는 것을 확인할 수 있습니다. 그럼 저런 화분들은 저 그림처럼 사실 어디에나 위치할 수 있고 상황에 따라 각기 다른 Depth를 가질 수 있기 때문에, 만약에 저런 테이블 위에 화분하나만 덩그러니 놓여있게 된다면, 모델은 저 화분의 특징만으로는 정확한 깊이를 추정하기 어려울 수 있게 됩니다. 그래서 이러한 경우에는 화분의 주변 정보들 예를 들어 테이블 표면등의 정보를 활용을 해야 보다 정확한 깊이를 추정할 수 있게 됩니다. 따라사 저자는 depth 추정에 있어서 주변 정보를 활용하는 것이 중요하기 때문에 마스킹을 통해 주변 정보를 좀더 주의 깊게 보고 깊이를 추정하는 모듈인 Adaptive Relative Depth Estimation(ARDE)라는 모듈을 제안합니다.
각각의 모듈에 대해서 좀더 자세하게 설명을 드리고 메서드 파트로 넘어가도록 하겠습니다.
SASP(Semantic Aware Scale Prediction)
먼저 SASP(Semantic Aware Scale Prediction)라는 모듈에 대해서 소개드리자면, 저자는 장면의 시멘틱 정보를 활용해서 scene scale을 예측할 수 있도록 하나의 query 구조를 설계합니다. 이 query를 scale query라고 부르는데요, 이 scale query는 transformer를 통해 이미지의 특징과 상호작용을 하면서 장면의 구조적인 정보(structural information)를 얻게 됩니다. 그리고 시멘틱 정보를 통합하기 위해서 텍스트 프롬프트(text prompt)를 구성하고, 이 프롬프트들을 CLIP 텍스트 인코더를 통해 scene category의 텍스트 임베딩으로 변환합니다. 이후 scale query와 텍스트 임베딩 간의 유사도를 계산함으로써, 이 장면이 ‘교실인지’, ‘부엌인지’, ‘야외인지’와 같은 scene category label 정보를 활용해 미리 스케일을 제약을 해버리는 방식입니다. 즉, scene-level의 semantic 정보를 이용해서 해당 장면의 깊이 범위가 어느 정도일지 예측하고, 이를 기반으로 이후의 깊이 추정이 더 안정적으로 이루어질 수 있도록 하는 것이 이 모듈의 핵심이라고 보시면 될 것 같습니다.
ARDE(Adaptive Relative Depth Estimation)
다음은 ARDE(Adaptive Relative Depth Estimation)라는 모듈입니다. 앞서 언급한 scale은 장면 단위의 전역적인 정보였다면, ARDE는 장면 내에서의 지역적 상대 깊이를 추정하는 역할을 합니다. 이를 위해 저자는 bin query라는 구조를 도입하는데요, 이 query는 이미지 내의 depth-related regions와 마스크 어텐션(masked attention)을 통해 상호작용하면서, 각 위치의 상대 깊이를 예측합니다. 구체적으로는 깊이 공간을 여러 개의 bin(깊이 구간)으로 나눈 뒤, 각 픽셀이 어떤 bin에 속할 확률을 예측하고, 이 확률을 기반으로 각 bin의 중심값을 가중합하여 상대 깊이를 추정합니다. 마지막으로 이렇게 얻은 relative depth map에 앞서 SASP 모듈에서 예측한 scene scale 값을 곱해줌으로써 최종적인 절대 깊이 맵(metric depth map)을 생성하게 됩니다.
이렇게 구조적인 정보와 시멘틱 정보를 나눠서 처리함으로써, 장면 간 깊이 차이와 장면 내 깊이 분포 모두를 효과적으로 반영할 수 있도록 설계한 것이 이 논문의 핵심 아이디어 중 하나라고 볼 수 있습니다.
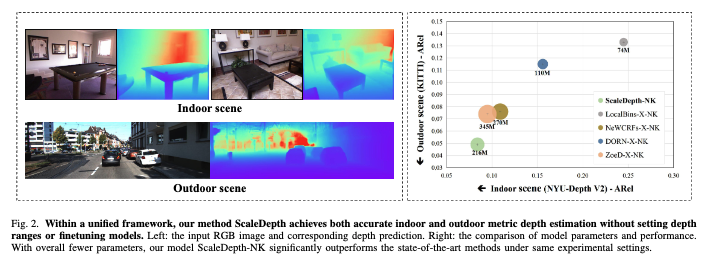
위는 해당 방법론에 대한 성능을 보여주는 figure입니다. 왼쪽은 indoor씬 outdoor씬 모두 한번에 depth 추정이 가능하다라는 것을 보여주는 것 같고, 오른쪽 fig는 이를 뒷받침하는 정량적인 표라고 보시면 될 것 같습니다. 여기서 파라미터가 다른 좋은 성능의 모델들에 비해서 적지만 성능은 높게 나온다는 것도 추가적으로 확인하실 수 있습니다.
이제 바로 메서드파트로 넘어가도록 하겠습니다.
Method
이제 메서드 파트 부분을 설명드리겠습니다.
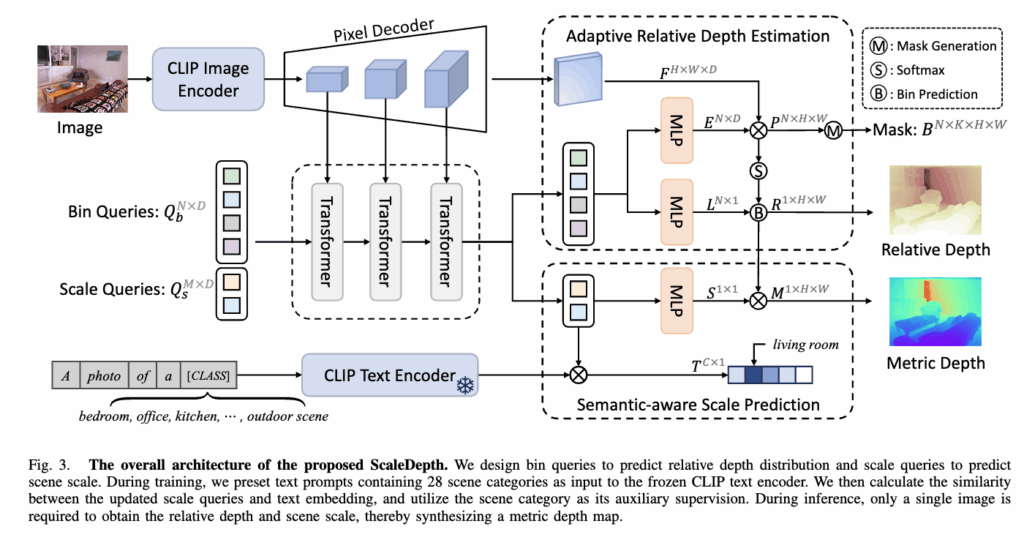
위는 해당 방법론의 아키텍쳐인데요, 먼저 전체 파이프라인을 큰틀에서 간단히 정하자면 먼저 하나의 입력 이미지가 들어오면, 이 이미지는 CLIP 이미지 인코더를 통해 다단계 multilevel feature로 추출됩니다. 이 특징들은 이후 Pixel Decoder를 통해 픽셀레벨로 임베딩 벡터를 생성한 후, Transformer Layer로 전달되면서 두 종류의 query와 상호작용하게 됩니다.
여기서 두 종류의 쿼리는 각각 다른 목적을 가지는데요, 앞선 introduction에서도 설명드렸었고 이름에서 알 수 있듯이
하나는 Scale Query로, 주어진 장면의 스케일을 추정하기 위한 것이고,
다른 하나는 Bin Query로, 상대적인 깊이 분포를 예측하는 데 사용됩니다.
이 쿼리들은 Transformer Layer를 거치면서 Masked Attention을 통해 업데이트되고, 업데이트된 Scale Query는 SASP 모듈로, Bin Query는 ARDE 모듈로 전달되어 각각 스케일 팩터 S 와 상대 깊이 맵 R 을 추정하게 됩니다. 마지막으로 이 둘을 곱해 최종 metric depth 맵 M 을 얻는 구조라고 보시면 됩니다.
그리고 학습 시에는 CLIP 텍스트 인코더를 통해 SASP 모듈이 장면의 시맨틱 정보를 잘 학습할 수 있도록 하는데, 다만 이 텍스트 인코더는 추론 단계에서는 사용하지는 않습니다.
앞서 inroduction에서 SASP와 ARDE를 개념적인 측면에서 설명을 드렸다면 해당 파트에서는 메서드 측면에서 좀더 자세하게 설명을 드리겠습니다.
먼저 ARDE 모듈은 모델이 relative depth를 예측을 잘하도록 하는 목적을 가진 모듈이라고 보시면 될 것 같습니다. 그리고 여기서는 bin query가 사용이 되게되는데, 깊이 공간을 정규화시킨 뒤, 이를 여러 개의 bin으로 나눕니다. 그럼 각각의 bin은 일종의 깊이 클래스로 작용하게 되고, 각 픽셀이 이 bin들 중 어디에 속하는지를 분류(classify)하는 방식으로 상대 깊이를 추정하게 됩니다. 그리고 이후에는 각 bin의 중심값을 구하고, 이 중심값들을 픽셀의 분류 확률에 따라 가중합해서 최종 relative depth map을 얻게되는 식으로 동작합니다. 해당 과정이 Discrete Regression 기반의 상대 깊이 추정이라고 보시면 될 것 같습니다.
그리고 이 ARDE 모듈의 또 다른 핵심은 단순히 분류하고 끝나는 게 아니라, Attention Mask를 함께 생성해서 bin query가 depth-related regions에 집중할 수 있도록 만든다는 점입니다. 각 Transformer layer마다 이러한 마스크를 생성하고 다음 계층으로 넘기는 식으로 동작합니다. 참고로 이 attention mask는 bin query에만 적용되고, scale query에는 적용되지 않습니다. 이유는 scale query는 장면의 global한 영역을 보고 해당 씬에 대한 시멘틱 정보를 추출하기 때문인 것 같습니다.
그 다음으로 SASP 모듈은 앞선 ARDE보다는 간단한데요 이 친구는 장면의 스케일을 예측하는 역할을 하는 친구라고 보시면 될 것 같습니다. 해당 모듈에서는 CLIP의 좋은 이미지–텍스트 정렬 능력을 활용하게 됩니다. 사전정의 됨 텍스트 프롬프트를 CLIP 텍스트 인코더에 넣어서 scene category의 텍스트 임베딩을 만들고,
이를 이미지에서 나온 scale query와 정렬(alignment)시켜주는 방식으로 작동합니다. 이렇게 하면, scale query는 CLIP 이미지 인코더에서 나온 특징들을 바탕으로 장면 전체의 시맨틱 정보와 구조적 정보를 모두 고려해 스케일을 예측하게 됩니다.
최종적으로 출력된 scale query는 앞선 부분에서 짧게 설명드렸지만 다시 정리하면 MLP를 통해 어떤 스칼라 값인 스케일 팩터 S로 투영되고, 해당 S 는 relative depth map R과 곱해 최종 metric depth 맵 M을 최종적으로 구하게 됩니다.
이처럼 전체 구조는 두 단계로 분리해서 처리함으로써, 기존 방식들의 단점을 보완하려고 했다는 점이 핵심이라고 볼 수 있습니다.
앞서 주저리 주저리 전체 플로우를 나눠서 설명을 드렸습니다. 이제는 loss 부분이 어떻게 설계되어서 학습이 이루어지는지에 대해서 설명드리도록 하겠습니다.
Loss
손실함수는 생각보다 단순해서 놀랐던 것 같습니다. 먼저 손실 함수는 크게 두 가지로 구성되어 있습니다.
첫 번째는 SI (Scale-Invariant) Loss입니다. 이는 픽셀단위 relative depth 차의 분산과 metric depth 차의평균 오차를 조합해서 계산이됩니다. 이는 상대 깊이를 잘 추정하면서도 절대 깊이와의 오차를 최소화할 수 있게 도와줍니다.
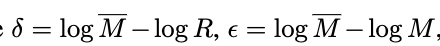
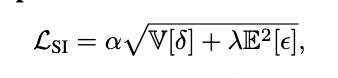
두 번째는 TI (Text–Image Similarity) Loss입니다. 이건 SASP 모듈이 텍스트 임베딩과 잘 align이 맞춰지도록 해주는 손실로, 훈련 중에만 사용되고, one-hot 형식의 scene label과 유사도 결과 간의 cross-entropy로 계산됩니다.
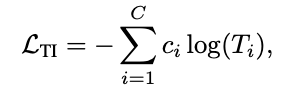
최종 손실 함수는 아래와 같이 구성되어있습니다.
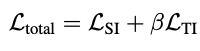
이렇게 메서드 파트를 정리해보면, ScaleDepth는 장면 스케일이라는 전역 정보를 명시적으로 예측하고, 지역적인 상대 깊이를 이산화된 bin을 통해 정밀하게 추정하는 구조로 설계되어 있다는 점, 그리고 기존 방법들이 주로 하나의 회귀 구조에 모든 것을 맡겼다면, 이 방식은 문제를 두 가지 하위 문제로 분리해서 해결하는 점이 인상 깊었습니다. 근데 나중에 알게되었지만 해당 방법론이 binsformer라는 방법론의 아이디어에서 살짝 살만 덧 붙힌 것 이었습니다.
이제 실험결과로 넘어가도록 하겠습니다.
Experiments
먼저 사용된 데이터셋부터 정리해보겠습니다.
실내 장면에 대해서는 대표적으로 NYU-Depth V2가 사용되었고,
실외 장면에 대해서는 KITTI가 사용되었습니다.
그리고 실험에서는 NYU는 최대 깊이를 10m로, KITTI는 80m로 설정해 평가를 진행하였지만, 이 설정은 어디까지나 유효한 픽셀을 필터링하기 위한 조건일 뿐이지 모델 학습에는 직접적인 영향을 주지 않는다고 보시면 될 것 같습니다.
실험은 크게 네 가지 설정으로 나뉘어 진행되지만 리뷰에서는 3개만 다뤄보도록하겠습니다.
실내 평가 (Indoor Scenes)
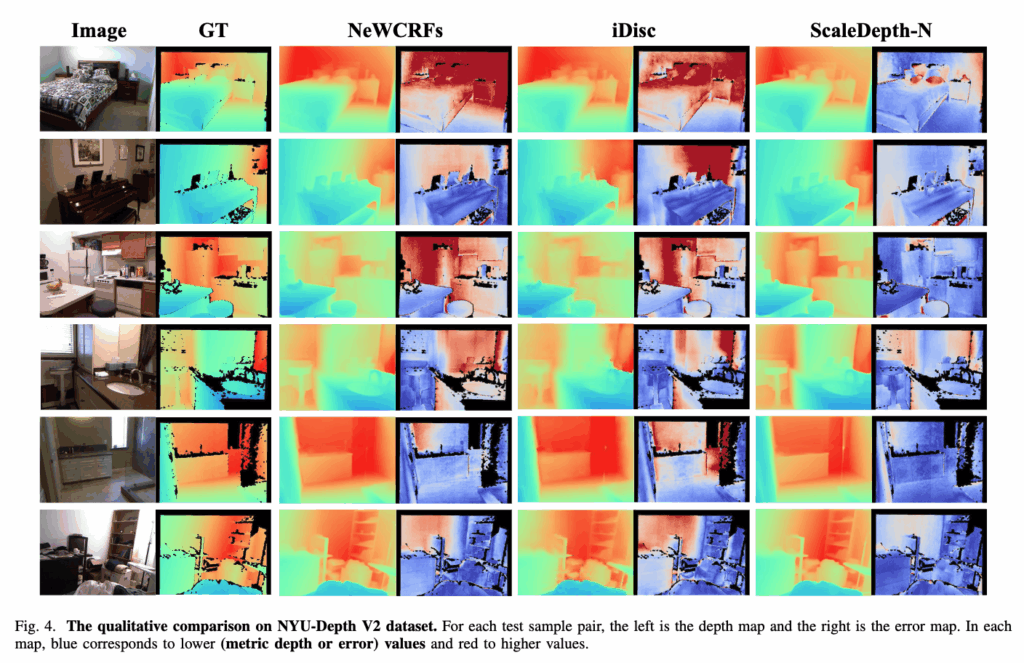
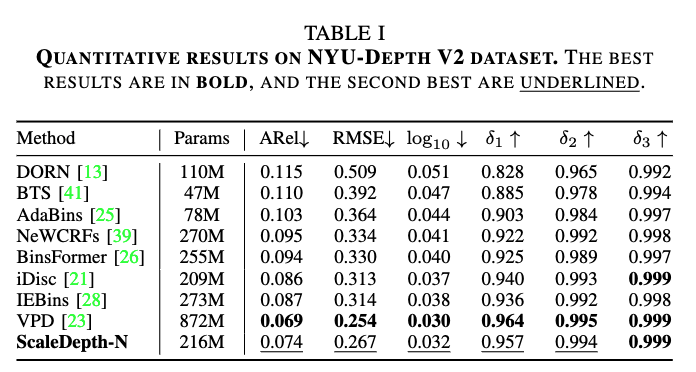
먼저 figure4에서 오른쪽에 파란색 빨간색으로 표시된 맵들이 GT와 Predict간의 error(차이)를 시각화한 그림입니다. scale Depth가 다른 모델들보다 좋은 결과를 보이는 것을 정성적으로 확인할 수 있습니다. 그리고ScaleDepth-N (NYU로만)은 기존의 diffusion 기반 기법들보다 훨씬 적은 파라미터 수에도 불구하고, 같은 파라미터대의 모델들보다 좋은 성능을 보이는 것을 확인할 수 있습니다.
실외 평가 (Outdoor Scenes)
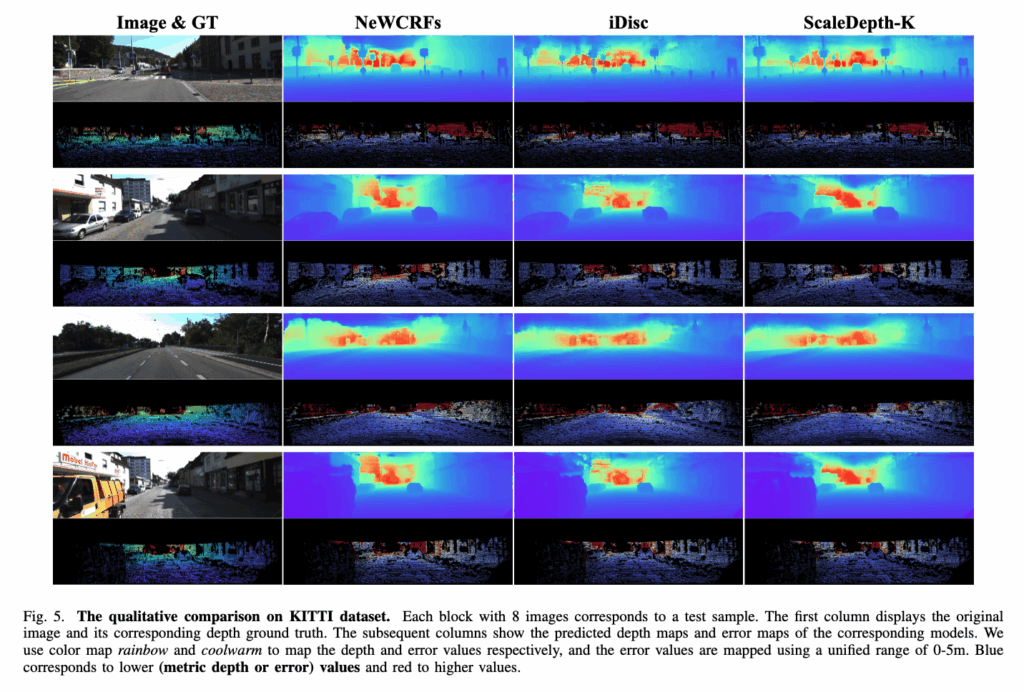
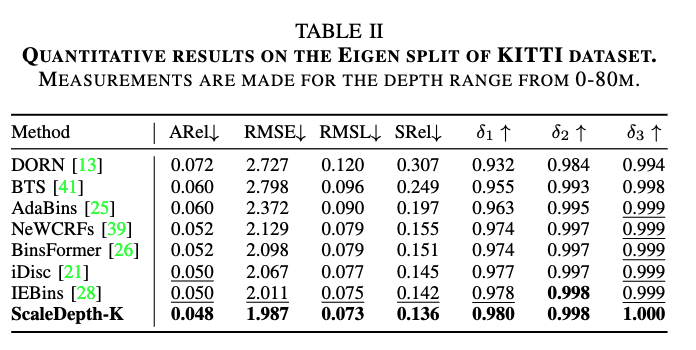
KITTI 데이터셋은 라이다 센서 특성상 80m까지만 주석이 존재하고, scene category 정보도 없습니다. 그런데도 이런 제약된 상황임에도 불구하고 ScaleDepth-K는 다른 기법들을 능가하는 성능을 기록하는 것을 확인하실 수 있습니다.
비제약 장면 평가 (Unconstrained Scenes)
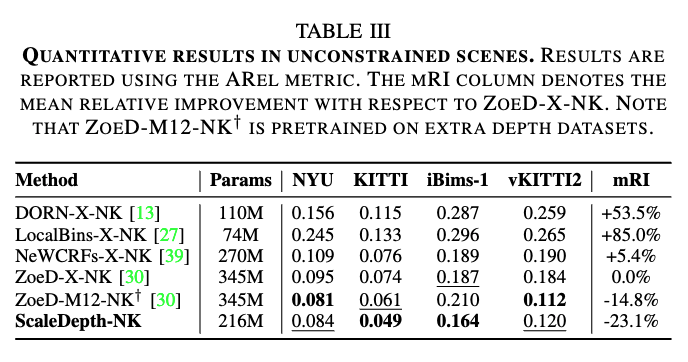
여기서는 비제약상황을 실내와 실외를 모두 포함한 상황이라고 합니다 이 경우에서의 실험결과가 가장 중요하게 봐야될 부분이라고 생각을 합니다.
ScaleDepth-NK는 Zoedepth 대비 평균 23.1%의 상대적 향상률을 보입니다. 그리고 out of domain 데이터셋(ibims-1,vKITTI2),실제 스케일의 범위가 다양하게 섞인 장면들에서도 안정적인 성능을 보여줍니다. 물론 Zoedepth가 NYU,vKITTI2 데이터 셋에 대해서는 성능이 더 좋은 결과를 보이지만 저자가 말하기를 ZoeD-M12-NK+같은 경우는 추가적인 데이터로 학습이 이루어졌다고 합니다.
Ablation Study
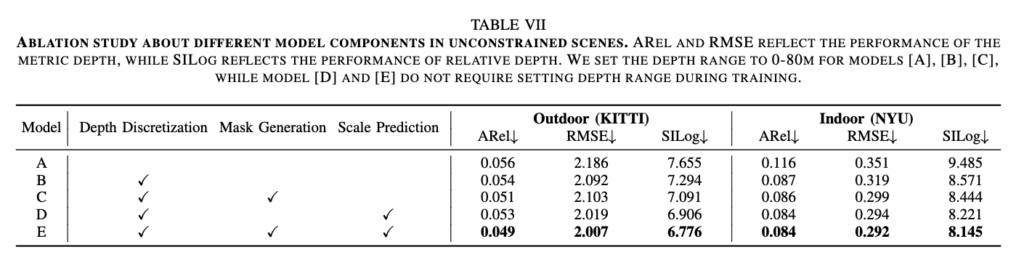
위를 보시면 단순 회귀만 사용하는 모델 A보다 bin 기반 구조 B는 A보다 좋은 성능을 보이고 여기에 마스크를 추가한 C는 attention을 더욱 효과적으로 수행할 수 있게 해줘서 성능향상에 기여를 한 것으로 보이고 마지막으로 시맨틱 기반 스케일 예측을 결합한 E는 최종적으로 가장 우수한 성능을 보입니다. 결과적으로 ScaleDepth의 핵심 아이디어들이 실질적인 성능 향상으로 이어졌음을 보여주는 테이블이라고 보시면 되겠습니다.
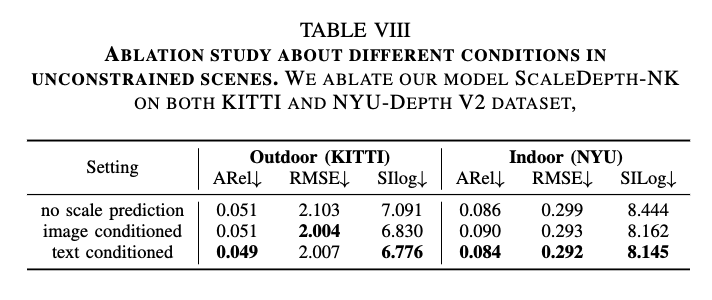
또한 scale prediction 과정에서 텍스트 프롬프트를 사용하는 것의 중요성도 함께 실험하였고, text-conditioned 방식이 image-conditioned 방식보다 훨씬 좋은 성능을 보였다는 결과도 확인할 수 있습니다.
안녕하세요 우현님 좋은 리뷰 감사합니당
궁금한점 있어 남깁니다!!
해당 논문은 결국에 scale에 강인하게 metric depth map을 구하고자 하는 것으로 이해했습니다. 근데 Loss함수는 Scale invariant loss로 설계하여 Relative error를 계산하는 부분이 loss로 구성이 되어있는데 왜 손실함수에 해당 부분이 포함되어있는지가 궁금합니다
안녕하세요 우진님 좋은 질문 감사합니다.
말씀하신 것처럼 이 논문은 scale에 강인하면서도 절대적인 거리 값을 예측하는 metric depth estimation을 목표로 하고 있습니다. 그런데도 손실 함수에 relative error (log M − log R)를 포함한 이유는 결국에 metric depth를 구하는 과정에서 relative depth와 scale의 곱을 통해 구하기 때문이지 않을까 싶습니다. 예측값이 실제 scale을 잘 맞추는 것도 중요하지만, 장면 내의 깊이 관계(예: A가 B보다 멀다)를 잘 반영하는 것이 모델의 전반적인 이해력을 높이는 데 중요하기 때문에 Metric depth에 대한 손실과 더불어 사용한 것 같습니다.
감사합니다!
안녕하세요 우현님 좋은 리뷰 감사합니다.
clip으로 정보를 더 얻어내어, 횔씬 성능을 끌어낸 방법론인것 같습니다.
질문이 있습니다. 기존 adabins와 같이 bin들을 적응적으로 하는 방법론들과 달리
이 방법론은 bin을 단순 이산적으로 나누는것 같은데, adaptive한 방법을 추가로 적용하지 않은 이유가 궁금합니다.