안녕하세요 4번째 논문리뷰입니다! 이번에 소개해드릴 논문은 2024 CVPR에 기재된 SAM-6D입니다.
6D Pose Estimation은 R(rotation),t(translation)을 동시에 추정하는 과제로 환경과 객체 특성에 따라 모델이 쉽게 overfitting되는 문제가 자주 발생합니다. 특히, 학습되지 않은 unseen objects에 대한 일반화가 매우 어려운 것이 주요 도전 과제입니다. 하지만 최근에는 Foundation Model과 같은 대규모 모델들의 발전 덕분에, 이와 같은 한계를 점차 극복해 나가고 있습니다.
논문의 제목에서 나와있듯 인스턴스 분할 모델인 SAM을 이용한 6D pose estimation에 관한 리뷰 바로 시작하도록 하겠습니다.
Abstract
6D object pose estimation은 로봇팔이 물체를 정확하게 집기위해서 필수적인 Task입니다.뿐만 아니라 AR분야나 물류 자동화 같은 다양한 테스크에서 많은 응용이 되는 기술입니다. 이전 연구들은 Instance-level에서 주로 활발히 연구 되어왔습니다. 하지만 이는 학습된 특정 물체에 대해서만 학습하기 때문에 그 물체에 한정하에 작동되어 집니다. 이를 보완하고자 category-level 까지 발전이 되어 unseen object에 대해서 다루어 지고있습니다. 예를 들어 컵이라는 물체가 있을때 다른 컵들 또한 잘 작동할 수 있게 끔 연구가 이어져 왔습니다. 하지만 이 두 연구 모두 공통적인 한계점이 존재하는데요 처음보는 물체 즉 novel object에는 작동이 어렵습니다. 특히나 real-world에서는 매번 새로운 물체가 등장하기에 이를 처리할 수 있는 Zero-shot 6D model 이 필요한 상황입니다. 하지만 이 Zero-shot에서는 pose만이 문제는 아니긴 합니다. 그에 앞서 물체가 segmentation이 되어야 pose를 추정할 수 있는데 대부분에 segmentation 모델은 특정 class나 객체에 대해서만 작동하는 한계가 있고 가려짐이나, 조명변화에서 문제점이 생깁니다. 이럴때 Segmentation 자체가 잘못 될 수도 있습니다. 이러한 상황을 극복하기 위해서 저자는 2023년에 메타에서 발표한 SAM 모델을 사용합니다. 여기서 SAM(Segment Anything Model)이란 point나 box, text등 다양한 prompt 기반으로 segmentation하는 모델입니다. SAM 같은 경우에는 이미 컴퓨터비전 분야에서 많이 응용되어 지고 있고 입증된 모델입니다.
그래서 저자는 SAM으로 segmentation 문제를 해결하고 6D pose estimation을 하는 방법입니다.
즉, 정리해서 말씀드리면 새로운 네트워크를 제안하는 것이 아니라 foundataion Model인 Segmentation의 모델과 3D Matching을 효율적으로 하는 논문이라고 생각하시면 될 것 같습니다.
Introduction
모델은 총 2가지의 pipeline을 따르게 됩니다.
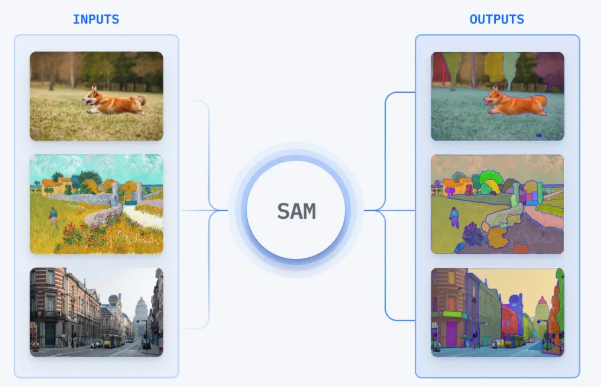
첫째는 ISM(Instance segmentation Model) 입니다. 위에 사진과 같이 SAM은 모든 물체에 해당하는 segmentation을 진행하게됩니다. 그 중에서는 저희가 사용해야 할 타겟 object를 선별해야합니다. 기존에는 segmention을 선별할 때 semantics(객체의 의미)만 고려되었는데 저자는 object matching score를 도입하여 세가지 요소 (semantics, appearance, geometry)를 고려한다고 합니다. 즉 해당 proposal의 semantics적으로 얼마나 유사한가를 따지는 것 뿐만아니라 외형적인 유상성과 객체의 형태와 크기 까지 고려하여 정량적으로 평가합니다. 자세한 부분은 Method에서 설명드리겠습니다.
두번째로는 PEM(pose Estimation Model) 입니다. 선별된 물체에 대한 6D pose Estimation을 계산하는 단계입니다. 3D Mesh로 샘플링된 포인트클라우드 집합과 실제 RGB-D로 객체의 포인트클라우드 집합의 Feature map 매칭을 시켜서 계산을 하게됩니다. 하지만 여기서 생기는 문제가 occlusion이나 sensor noise등 현실적인 요인들이 있습니다. 저자는 이를 해결하기 위해서 background token을 사용한다고 합니다. 이 토큰은 두포인트 집합 각각에서 서로 겹치지않는 포인트들을 background token과 정렬 되도록 학습합니다.
저자는 PEM을 two – stage로 확장을 합니다. 초반에 sparse 한 대응 관계를 통해서 object pose estimation을 추출하고 추출 된 자세를 활용하여 추후에 fine point Matching 단계에서 Dense 한 대응관계를 학습한다고 합니다. 물론 이 과정은 밑에서 fig들을 보면서 더욱 자세히 설명 드리겠습니다.
전체적으로 저자의 main contribution은 아래와 같습니다.
- RGB-D 이미지로부터 novel object에 대해 인스턴스 분할과 6D pose estimation을 동시에 수행하고 BOP()벤치마크의 기존 방법들보다 우수한 성능을 보여줌
- SAM의 Zero-shot을 활용하여 propolals를 생성하여 타켓 물체와의 식별을 위한 object matching score를 제안
- pose estimation에서 partial to partial point matching 문제로 접근하며 단순하지만 효과적인 background token도입과 동시에 novel object에 대한 two-stage point matching model 제안
Method
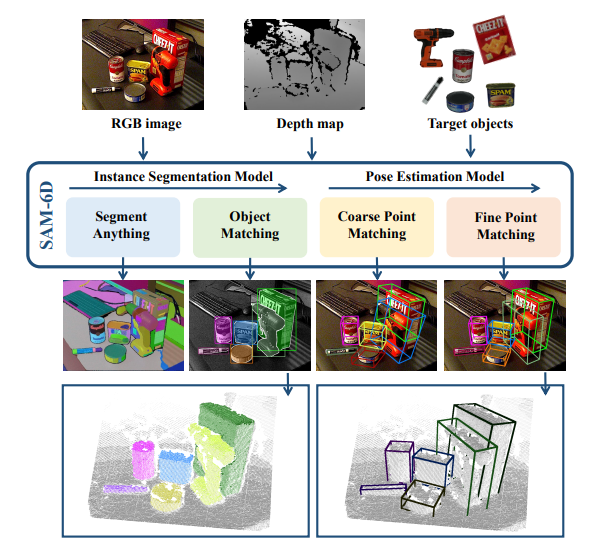
위 사진과 같이 ISM 과 PEM으로 나뉘게 됩니다. 그럼 우선 SAM에서 나온 segmentation을 통해서 타겟 물체를 선별하는 ISM을 먼저 설명 드리겠습니다.
Instance Segmentation Model
우선 SAM은 RGB->𝓘 가 주어졌을 때 다양한 형태의 프롬프트 𝓟ᵣ를 활용하여 segmentation를 수행할 수있습니다. 이를 수식으로 나타내면 아래와 같습니다
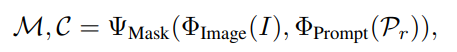
이미지 인코더, 프롬프트 인코더, 마스크 디코더를 포함합니다 여기서
M : 예측된 마스크 영역
C : confindence score를 의미합니다.
여기서 proposal 집합 M이 주어졌을 때, 이들 중 novel-object(𝓞) 와 일치하는 proposal을 식별해서 object score (S_m)부여 해서 선택해야 합니다. 선택은 위에서 살짝 언급했던 (semantics, appearance, geometry) 3 가지 점수를 계산해야합니다.
정밀한 스코어 계산을 위해 3D target object에 대한 3D mesh를 활용하여 SE(3)공간의 Nt(코드상 42개 입니다)개를 ![]() 렌더링 합니다.
렌더링 합니다.
이후에 사전학습된 DINOv2 기반의 ViT 백본에 입력되어 각 템플릿 𝒯ₖ 에 대해
class embedding![]() , patch embeeding
, patch embeeding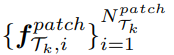 를 생성합니다.
를 생성합니다.
이제 SAM에서 나온 예측된 마스크를 기반으로 기존 RGB이미지 또한 Embedding을 통해서
class embedding![]() , patch embeeding
, patch embeeding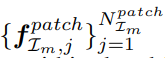 을 얻습니다.
을 얻습니다.
이제 이 embedding된 수식들을 가지고 score들을 계산을 해주게됩니다.
우선은 1) Semantic Matching Score 입니다.
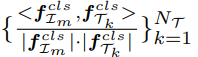
이미지 전체를 feature map딴에서 코사인 유사도를 계산함으로써 의미적인 관점을 측정합니다. 상위 K개를 평균 냄으로써 계산되고 유사도가 높은 템플릿은 T-best로 저장되어집니다.
다음은 2) Appearance Matching score 입니다
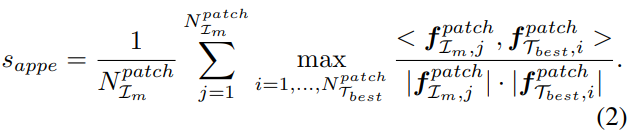
이것은 조금 더 raw-level정보에 가까운데요 proposal 영역의 이미지들의 패치들을 추출해서 타켓 오브젝트들과의 1:1로 비교를 하게 됩니다(1)에서 말씀드린 T_best기준입니다. 이는 texture나 시가적인 정보를 비교한다고 보시면 될것 같습니다.
마지막으로는 3)Geometric Mathcing Score입니다.
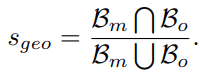
여기서는 proposal mask의 boung box와 Targe object 의 3D mesh 를 2D로 투영하여 IOU를 계산함으로써 형태나 크기들의 점수를 계산할 수 있습니다.
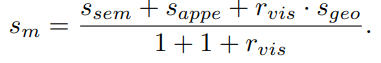
이렇게 하여 3가지정보들의 평균을내서 찾고자 하는 novel-object와 매칭을 시킬 수 있게됩니다.Pose Estimation Model
Pose Estimation Model
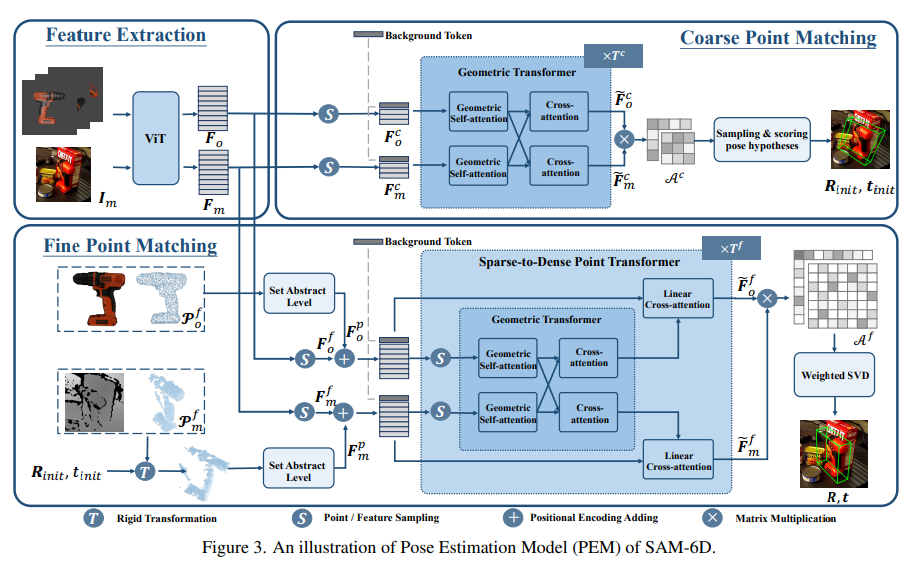
위의 보시는 fIg는 pose estimation model의 전체 파이프라인 입니다. 세분화해서 살펴보시겠습니다.
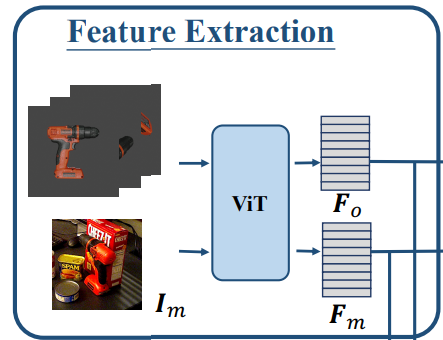
첫번째로는 Feature Extraction 입니다. 이번 단계에서는 RGB-D 이미지로부터 추출된 object proposal과 CAD 기반 3D mesh사이의 초기 정합을 하기위한 것입니다. 먼저 RGB-D 이미지를 기반으로 object proposal영역을 자르고 해당 부분의 포인트 클라우드를 vit를 통해서 Fm으로 임베딩하고 3D mesh또한 포인트들의 공간상의 정보를 가지고 있기때문에 ViT를 통해서 Fo object feature로 표현 됩니다.
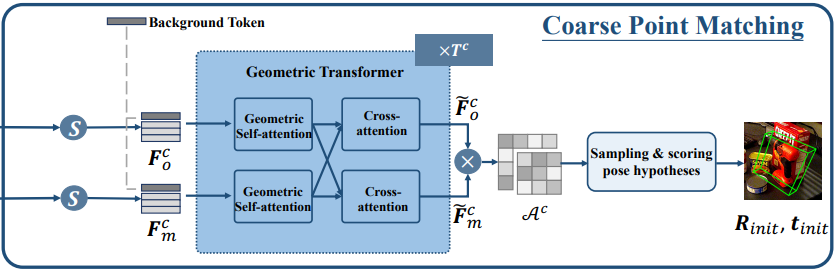
두번째로는 Coarse Point Matching입니다. Fo : 3D mesh에서 나온 feature Fm : RGB-D이미지로 부터 나온 Feature입니다. 이 둘의 입력으로 매칭을 수행하게 되는데 각각에 Backgroud 토큰이 추가가 되어집니다. 이는 일치하지 않는 포인트들을 억지로 매칭하지않도록 하기 위해 만들어주는 것 입니다. 가려진 영역이나 잘못된 세그멘테이션 부분이 있더라도 Backgroud Token을 통해서 강제적으로 높은 점수를 부여하지 않도록 유도합니다.
이렇게 두 feature는 Geometric Transformer를 통해서 처음에는 Self-attention을 통해서 내부적으로 관계를 먼저 학습하고 이어서 서로 다른 도메인 과의 feature 관계를 학습할 수있게 cross-attention을 진행합니다. 이로써 두 포인트 유사도 행렬 Ac를 얻게 됩니다.
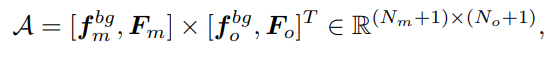
위 식은 각각의 출력 된 F와 Background 토큰이 포함된 두 feature를 Soft Matching metrix기반으로 여러 개의 pose의 hypotheses를 sampling하게 됩니다. 예를 들어서 다양한 포인트 상에서 T(변환)후보를 만들어서 가장 높은 스코어를 갖는 pose 를 R,t로 설정하게 됩니다. 이때는 아주 정밀하지는 않지만 이후에 fine pose refinement 에서 초기 값으로 사용하게 되면서 강인해지게 됩니다.
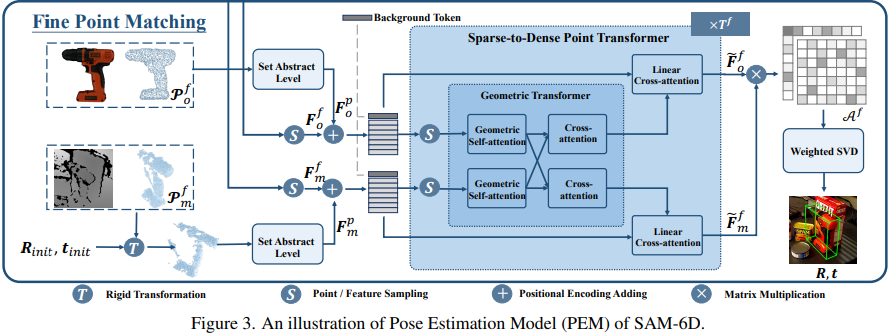
마지막으로 3번째인 Fine Point Matching입니다. 앞에서 설명 드린 매칭에서 저희는 초기의 pose를 계산했습니다. 하지만 그것은 대략적인 정렬일 뿐이고 세밀한 수준에서의 alignment는 부족하다고 저자는 말을 합니다. 그래서 이 단계에서는 보다 Dense한 포인트를 기반으로 수행하게 됩니다. 맨 왼쪽부터 보시게 되면 point cloud들이 있습니다. 해당 그림은 처음에 Feature Extraction에서 생성된 dense한 포인트 클라우드들 입니다. 이때 위에서 말씀드린 Coarse Point Matching에서 얻은 초기대응 정보(R_init, t_init)을 RGB-D로 부터 얻은 포인트 클라우드에 적용하여 Set Abstract Level을 통해 각각은 position encdoing(PointNet ++) ![]() ,
,![]() 를 얻습니다(위에서 vit로 embedding된것과 더해줍니다). 이 후에는 Background Token과 같이 사용됩니다. 여기서 학습시에 self-attention과 cross attention을 사용하기에 Transformer 연산 특성상 비용이 매우 크다는 점이 문제가 됩니다. 저자는 이를 해결하기 위해서 SDPT(sparse to dense point Transformer)를 사용하게됩니다. 이는 Sparse한 Feature들을 샘플링을 한 후, 그 샘플링된것을 Geometric Transformer를 통과시키게 됩니다. 그 출력을 통해 key, value에 역활을하고 Linear Cross-attention을 통해 초기 Dense 와 연산을 하게됩니다.
를 얻습니다(위에서 vit로 embedding된것과 더해줍니다). 이 후에는 Background Token과 같이 사용됩니다. 여기서 학습시에 self-attention과 cross attention을 사용하기에 Transformer 연산 특성상 비용이 매우 크다는 점이 문제가 됩니다. 저자는 이를 해결하기 위해서 SDPT(sparse to dense point Transformer)를 사용하게됩니다. 이는 Sparse한 Feature들을 샘플링을 한 후, 그 샘플링된것을 Geometric Transformer를 통과시키게 됩니다. 그 출력을 통해 key, value에 역활을하고 Linear Cross-attention을 통해 초기 Dense 와 연산을 하게됩니다.
그럼 이제 Fine-level에서의 두 Feature가 Soft correspondence 행렬이 계산이되고 이를 기반으로 Weighted SVD로 R,t를 정밀하게 추정되게 되어집니다
Experiments
이제는 그에 따른 Experiments를 설명드리겠습니다. 우선은 SAM-6D는 세그멘테이션 하는 부분과 Pose Estimation하는 부분이 따로 존재하기 때문에 나눠서 실험을 진행을 하였습니다.
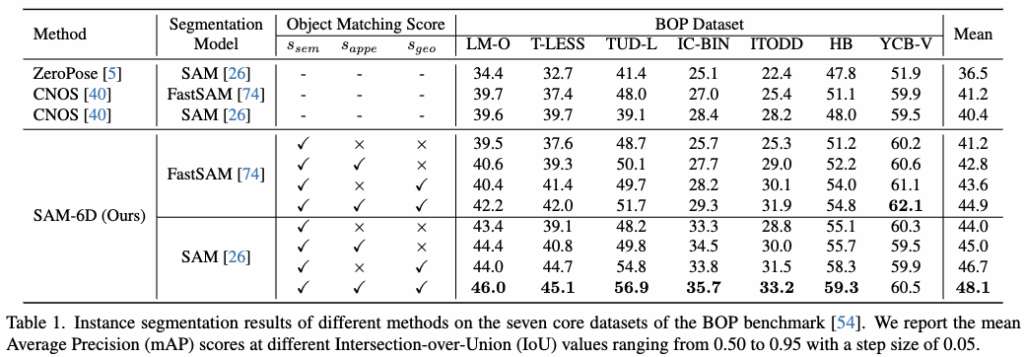
Table 1 이 나타내는 실험은 Segmentation에 대해서만 평가한 지표입니다. 우선 데이터셋은 BOP입니다. 아시는 분들은 아시겠지만 Benchmark of 6D pose Estimation의 약자입니다. 이 중 7가지의 dataset을 비교해서 실험하였습니다. 비교모델들은 각각 Segmentation을 추출하는 부분까지만 비교를 하였고 Object Matching Score의 Ablation study도 함께 나타내었습니다. 이 7가지 Dataset에서 object Matching Score 3개를 모두 사용했을때 평균적으로 가장 높은 성능을 보여주고 있는것을 볼 수 있습니다. 추가적으로 SAM은 모델이 Vit기반으로 무겁기 때문에 Encoder를 YOLO로 경량화 한 FastTSAM을 통해서도 비교해 보았을 때도 좋은 성능을 나타내는 것을 볼 수 있습니다.
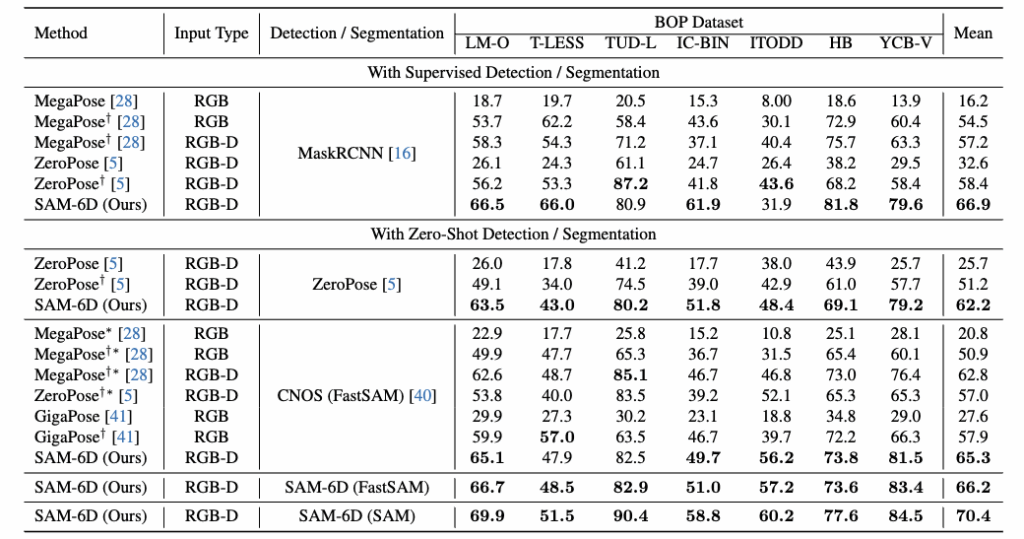
다음으로는 Pose Estimation에 대해서 평가한 실험입니다. 실험은 Zero-shot 성능과 Zero-shot이 아닐때(학습된 물체)를 평가합니다. 각각의 Model들은 그 당시 SOTA 모델들과의 비교입니다. SOTA들과 비교를 해보았을 때 두 실험 모두 제일 좋은 성능을 내는 것을 볼 수있습니다. 한가지 재밌는 점은 오히려 Zero-shot일때 가 학습된 물체보다 더 좋은 성능을 보여주고 있습니다. 이에 대해서 저자는 Instance segmentation에서 생성된 마스크가 다른 마스크 예측 방식에 비해 PEM의 성능을 유의미하게 향상 시켰다고 얘기를 합니다.

추가적인 Ablation Study 입니다. BackGround Token과 비교가 되는 것이 Optimal Transport입니다. 이는 point-to-point 매칭에서 확률 분포를 통해 맞춰주는 기법이라고 보시면 됩니다. 이와 비교했을대도 Average Recall이 높음을 보여주고 효율적인 것을 볼 수 있습니다
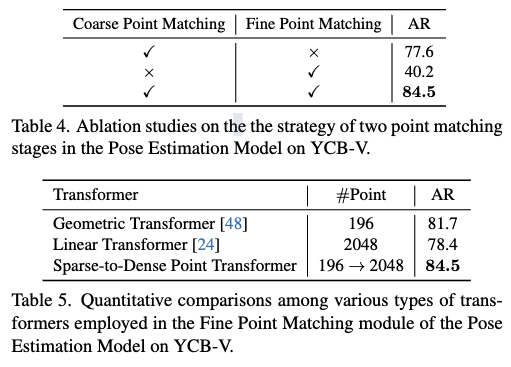
마지막으로 Coarse Point Matching과 SDPT의 Ablation study 입니다. Coarse Point Matching과 Fine Point Maching모듈이 Coarse Matching 결과를 의미있게 개선함을 보여줍니다. 그 밑에 실험은 저자가 제시한 Sparse-to-Dense Point Transformer의 Ablation study 입니다. Geometric Transformer는 sparse point에서는 높은성능 이나, dense point set에는 적용하기 어려움 (연산 비용 큼) 문제가 발생합니다. 또한 Linear Transformer는 Dense 처리를 사용했을때는 attention이 비교적 단순하여 낮은 성능을 나타내고있습니다. 제안한 SDPT는 Sparse 에서 Dense로 결합함으로써 최고의 성능을 나타냄을 보이고 있습니다
감사합니다! 부족한 부분은 질문을 통해서 답변드리도록 하겠습니다!
안녕하세요. 좋은 리뷰 감사합니다.
coarse point matching에서 3D mesh에 대해서는 제가 알기로 일반적인 ViT의 입력으로 사용하지 못하는 것으로 알고 있는데요, 어떻게 동작하는 지 조금 더 부연설명 해주시면 감사하겠습니다.
그리고 fine point matching은 보다 dense한 포인트를 기반으로 수행하게 된다면 위의 2번째 단계에서 사용하는 포인트 클라우드와의 차이점이 무엇인가요 ? 샘플링을 하지 않은 온전한 데이터셋이 제공하는 raw data임을 얘기하는걸까요 ?
감사합니다.
좋은 질문 감사합니다!
-> Q1. 3D Mesh 가 Vit 입력으로 어떻게 들어가는가?
A1. 알고계신바로 3D Mesh는 바로 Vit입력으로 들어가지 못합니다. 그래서 위에 설명과 같이 3D mesh를 SE(3)자세로 렌더링하여 2D image로 변환하여 Vit 에 입력이됩니다
-> Q2. fine point matching은 보다 dense한 포인트를 기반으로 수행하게 된다면 위의 2번째 단계에서 사용하는 포인트 클라우드와의 차이점
A2. Fine Point Matching과 Coarse Point Matching은 동일한 포인트를 사용합니다. 하지만 2번째 단계에서는 sparse한 point(코드상 196개 point)만을 샘플링하여 빠르게 초기 R,t 값을 사용합니다.
마지막 단계 또한 raw point cloud를 모두 사용하는 것 이아닌 2048개만을 샘플링해서 사용하게 되어 정밀한 대응 관계를 학습하게 됩니다
감사합니다
안녕하세요 우진님 리뷰 감사합니다.
Zero shot일 때 성능이 더 좋다는 점이 흥미롭네요 SAM이 그만큼 segmentation을 잘한다는거 같은데 혹시 정량적으로는 좋지만 될 것 같은데 안 되는(?) / 쉬운걸 못 하는 경우나 한계점도 있을까요? point matching 할 때 생기는 문제나 한계점이 궁금합니다!!
리뷰 읽어 주셔서 감사합니다.
우선 될 것 같은데 안되는? 이 말이 모호하긴한데….흠 뭐 텍스처가 거의 없는 대상에서 over segmentation된다거나 하나로 합쳐버리는 segmentation이 있을 경우 안되지 않을까? 생각이 듭니다.
안녕하세요 우진님 리뷰 감사합니다.
한가지 궁금한점이 object score를 만들기 위해 더한 3가지 방법중 geometric score 에 대해서 단순 투영을 사용하는 방식말고 depth 정보까지 이용하는 것은 어떨지 단순히 생각해보았고, 3D mesh를 단순히 2D로 투영시키는 것 이외에 생각해보신 방법이 있는지 궁금합니다. 저 3가지 방법을 가중합하는 것이 아닌 단순 덧셈으로 이용한다면 그 이유는 무엇인지 궁금합니다.
그리고 fine point matching 이전의 초기 pose값이 최종 결과에 얼마나 영향을 미칠지도 궁금합니다. 초기 값은 coarse한 매칭 결과일텐데 그 결과가 최종 fine matching에 미치는 영향이 궁금합니다. 논문에 나와있지 않다면 우진님 생각이 궁금합니다.
리뷰 읽어주셔서 감사합니다
먼저, geometric score에 대해 depth 정보를 활용하는 방안에 대해 말씀주신 부분, 저 역시 유의미하다고 생각합니다. SAM-6D에서는 coarse pose로 object를 2D로 투영한 뒤, proposal의 2D bbox와의 IoU를 계산해 geometric matching을 수행하고 있습니다. 3D 상에서 이루어진다면 유의미하기도 하고 그러한 연구도 진행되고있습니다 ㅎㅎ 두번째 질문에 답변으로써는 coarse pose가 fine matching 결과에 얼마나 영향을 주는지는 ablation 결과(Table 4)에서 명확하게 드러납니다. coarse stage를 제거하면 AR이 약 84.5 → 40.2로 반토막 나는 것을 볼 수 있습니다 ㅎㅎㅎ 감사합니다.
하이요. 리뷰 읽고 질문할게 있어서 댓글 남깁니다.
method를 초반부에 템플릿을 어떻게 추출하는지에서부터 이해하는데 어려움이 있어서요. 뭔가 중간의 설명이나 변수들의 정의가 빠진듯해서 이해하기가 힘드네요ㅜ
리뷰 내용을 보면 Proposal 집합 M이 주어졌다고 했는데 우선적으로 proposal 집합이 어떤건가요? object detector등을 통해서 foreground 후보군을 뽑았다는건가요? 아니면 SAM을 통해 추론한 mask map들을 의미하는건가요?
그리고 3D mesh를 활용하여 SE(3) 공간의 Nt(42)개를 렌더링한다는 말이 잘 와닿지 않아서요. SE(3) 공간이라는게 뭔가요? 랜더링이라 함은 3D mesh를 projection 시켜서 image를 생성했다는 의미인가요?
감사합니다.
안녕하세요 정민님. 리뷰 및 질문 남겨주셔서 감사합니다.
먼저 말씀하신 proposal 집합 M은 SAM을 통해 추론된 object-level mask map들을 의미합니다.SAM이 출력하는 segmentation 결과를 object 후보로 간주하여 그 중에서 템플릿과의 유사도를 계산하게 됩니다.
SE(3) 공간은 3D R과t을 포함하는 rigid transformation 공간입니다, 쉽게 말해 3D 물체가 가질 수 공간입니다. 논문에서는 3D mesh를 이 SE(3) 공간 상에서 Nt=42개의 서로 다른 pose로 설정한 뒤, 각 pose에서의 2D projection 이미지를 생성합니다. 이 과정이 바로 템플릿 생성을 위한 렌더링 단계이고, 3D mesh를 다양한 시점에서 2D 이미지로 투영해 템플릿 이미지 집합을 구성한 것입니다.
감사합니다
해당 부분이 논문 본문에 좀 더 명확하게 정의되어 있으면 좋았겠다는 말씀에 공감하며, 질문 주셔서 다시 한번 감사드립니다!