안녕하세요, 예순 여섯번째 X-Review입니다. 이번 논문은 2024년도 AAAI에 올라온 AnomalyGPT: Detecting Industrial Anomalies Using Large Vision-Language Models입니다. 바로 시작하도록 하겠습니다.
1. Introduction
본 논문은 Large Vision-Langue Model(이하 LVLM)을 industrial anomaly detection task에 활용하고자 한 논문입니다. LVLM이 엄청 많은 양의 데이터로 사전학습을 하기는 했지만, domain specific한 지식은 상대적으로 제한되어 있기도 하고, local한 디테일이 부족하다는 문제도 존재합니다. 특히 이런 점이 IAD(industrial anomaly detection) task를 수행하는데 곧바로 LVLM을 적용하기 어렵게 하죠. IAD task는 산업용 제품 이미지에 대해서 normal인지 abnormal인지 탐지하는 작업이며, 최근에는 실세계에서는 abnormal한 샘플들을 얻는게 어렵기 때문에 practical 측면에서, 학습 중에 normal sample로만 학습해 test때 normal, abnormal을 구분하고자 하는 연구들이 많이 나오고 있습니다. 하지만, 이런 지금까지의 방법론들은 test sample이 모델 입력으로 들어오면, 오직 output으로 anomaly score만 뱉는다는 한계점이 있으며, 각 class에 대해서 normal과 anomalous instance를 구분하기 위해서 그 threshold를 직접 정해줘야 한다는 한계가 존재했습니다. 이는 실제 real production 환경에 완벽히 맞다고 볼수는 없겠죠.
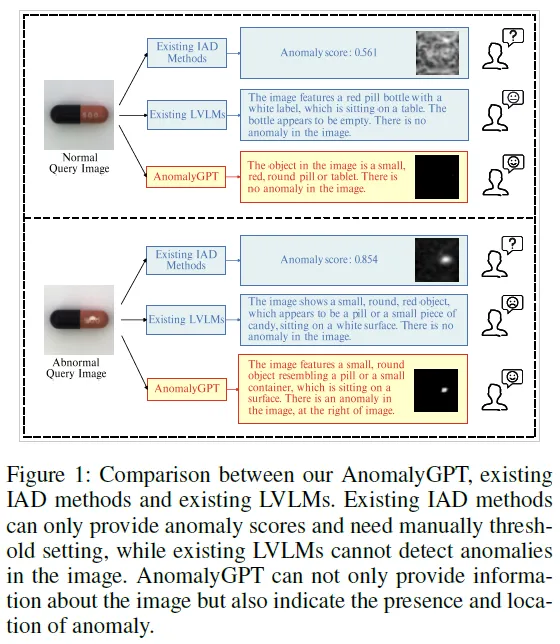
위 Fig1을 보시면, 방금 말한 부분이 그려져 있습니다. 파란색 박스로 그려져 있는 Existing IAD Method 즉 현존하는 Industrial Anomaly Detection 방법론 결과를 보면 output이 anomaly score로 나오기 때문에 직접 normal abnormal을 구분하기 위해서는 그 threshold를 manually하게 정해줘야 했으며, Existing LVLM 결과를 봐도 abnormal인 instance에 대해서 “There is no anomaly in the image”라고 뱉으며 IAD task를 잘 수행하지 못하고 있습니다.

마찬가지로 위 table1을 봐도, traditional IAD 방법론과 LVLM이 수행가능한 범위의 한계가 있음을 확인할 수 있습니다.
이런 문제를 해결하기 위해 본 논문에서는 AnomalyGPT라고 하는 LVLM을 base로 하는 새로운 방법론을 제안합니다. 제안된 AnomalyGPT는 threshold를 임의로 설정하지 않더라도 이상 판단 및 그 위치를 탐지하도록 설계되었으며, Fig1에 마지막 노란색 box로 볼 수 있듯이 LVLM을 기반으로 하기에 anomaly에 대해 자연어로 information도 제공을 합니다. 이에 관해 user가 필요에 따라 이 답변 output을 기반으로 후속 질문을 할 수 있도록 설계되었으며, few shot learning이 가능합니다.
설계한 모델에 관해 더 구체적인 설명은 아래에서 하도록 하겠습니다.
2. Method
AnomalyGPT는 정리하자면, industrial anomaly detection을 수행하기 위해 설계된 대화형 모델이라고 할 수 있겠습니다. 구체적으로는 사전학습 된 image encoder와 LLM을 사용하여 IAD image와 이에 대응하는 text description간의 alignment를 수행하며, 이때 simulation 기반의 anomaly 데이터를 사용합니다. 이를 위해 본 논문에서는 decoder 모듈과 prompt learner라고 하는 모듈을 제안함으로써 최종적으로 pixel-level의 localization output을 뽑을 수 있도록 하였습니다.
2.1. Model Architecture
각 모듈에 대해서 살펴보기 전에 전체적인 모델 Architecture에 대해 살펴보도록 하겠습니다.
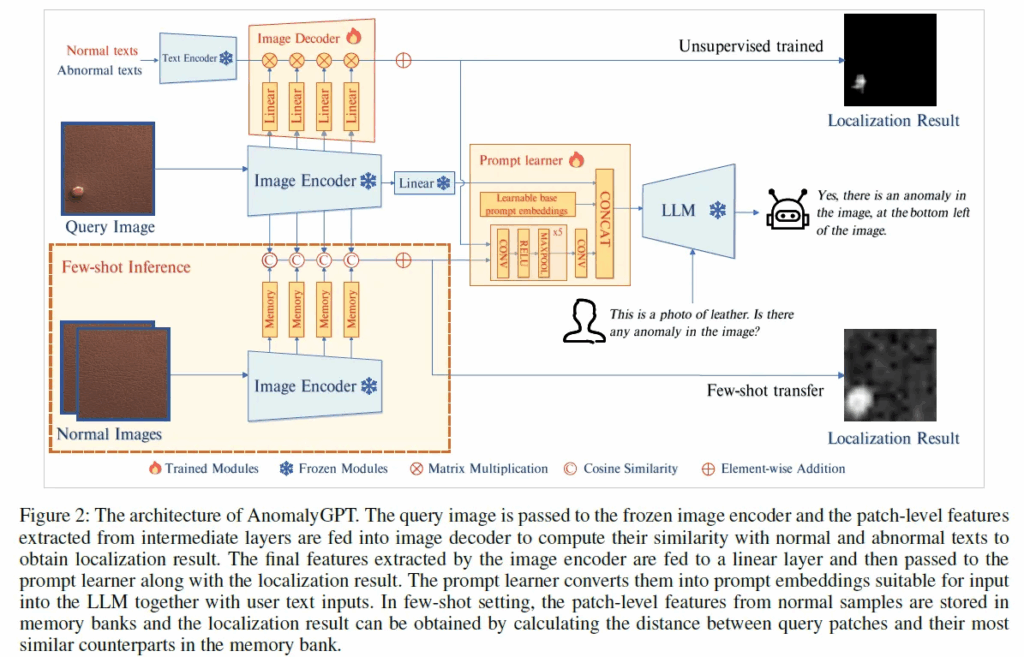
위 Fig2에 AnomalyGPT 아키텍처가 그려져 있는데요, 동작 과정을 말씀드리면 먼저 query image x ∈ R^{H \times W \times C}가 입력으로 들어오면, 사전학습 된 image encoder를 통해 image feature F_{image} ∈ R^{C_1}이 나오게 되고, 이후에 linear layer를 타고 나와 image embedding E_{img} ∈ R^{C_{emb}} 이 됩니다. 이게 이후 LLM으로 들어가는 첫 input이 되게 되구요. 동시에, image encoder 중간 layer들에서 나온 patch-level feature가 나오게 되는데, 이 patch-level feature들은 학습 세팅에 따라 그에 따른 decoder로 들어가게 됩니다.
그림을 보면 크게 위에 있는 unsupervised trained 부분과 Few-shot transfer 부분으로 구분되어 있는 것을 확인할 수 있는데, unsupervised 학습 경우에서는 decoder가 이 patch-level feature들과, 그림 좌상단에 보이는 “Normal text”, “Abnormal text”이 text encoder 입력으로 들어가 나온 text feature와 비교되어, pixel level의 anomaly map이 나오게 됩니다.
또, few-shot의 경우에는 normal image에서 추출한 patch-level feature들을 memory bank (그림에 memory 블럭들)에 저장해두고, test image patch와 가장 유사한 normal patch와의 거리를 계산함으로써 localization 결과를 얻어내는 식입니다.
이런 식으로 얻어내는 localization 결과는 단순 image로 끝나는 게 아니라, 그림 중앙에 있는 prompt learner를 통해 LLM이 이해할 수 있는 prompt embedding으로 변환됩니다. 이 prompt embedding과 함께 앞서 LLM 입력으로 들어가는 첫 번째 input이라고 했던 image embedding이 LLM으로 들어가게 되고, 여기에 user가 입력한 text 질문 (그림에서 “This is a photo of leather. Is there any anomaly in the image?”)이 합쳐져서 LLM이 최종적으로 anomaly가 있는지 판단하고 그 위치에 대해 답변을 생성할 수 있게 됩니다.
결국 정리하자면, 본 논문에서 제안된 AnomalyGPT는 image 자체와, anomaly localization 정보, 그리고 user 질문까지 다 고려해서 anomaly가 있는지 판단해 그 위치를 자연어로 설명할 수 있는 모델인 것입니다.
2.2. Decoder and Prompt Learner
Decoder
먼저, decoder 모듈에 대해서 좀 더 살펴보자면, 이 decoder는 pixel level로 anomaly 부분을 찾아내는 역할을 하는데, unsupervised 뿐만 아니라 few-shot 학습 상황에서도 동작하도록 설계되어 있습니다. 구조적으로 보자면, 앞서 말했듯이 image encoder의 4 stage 각각에서 patch-level의 feature F^i_{patch} ∈ R^{H_i \times W_i \times C_i} 를 추출해 냅니다.
또 동시에 이전 연구인 WinCLIP 논문에서 제안된 방식을 따라서 이 patch-level의 feature들과 text embedding(”normal texts”, “abnormal texts”를 text encoder에 태워 뽑은) 간의 similarity를 계산하게 됩니다. 저자는 여기서 사용되는 이 중간 feature들은 아직 LVLM이 학습해온 text feature와 alignment가 되어 있지 않아서 직접적으로 비교하기 어렵다고 합니다.
이에, 본 논문에서는 그림2의 Image encoder 위에 Linear라고 적힌 블럭들에서 볼 수 있듯이 각 feature를 별도의 linear layer를 태워 뽑은 feature를 가지고 유사도를 계산하도록 하였습니다. 무튼, 이렇게 각 위치의 patch feature와 text embedding 간의 유사도를 계산하고, softmax를 취해서 이 patch가 normal일 확률과 anomaly일 확률을 얻어냅니다. 이걸 4개 layer에 대해 모두 계산한 다음에, 그 결과를 합쳐 upsampling하면 최종적으로 원본 영상과 크기가 같은 pixel level의 anomaly map을 얻어낼 수 있는 것이죠. 식으로 나타내자면 아래와 같습니다.
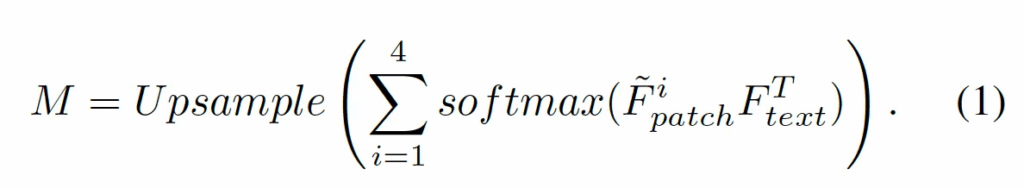
유사하게 Few-shot 학습의 경우에는 몇 장의 normal sample만 주어지는 상황이기 때문에 normal sample에서 patch-level feature를 뽑아 memory bank에 저장해두고 test image가 들어오면 이 memory bank에 저장해뒀던 patch-level feature와 test image의 patch level feature들을 비교해서 그 중 가장 유사한 patch를 찾아 그 patch와의 distance를 계산하게 됩니다. 이때 가장 유사한 normal patch와 distance가 작다면 normal 일 가능성이 높고, 그 반대라면 abnormal일 가능성이 높다는 것이겠죠. 이런 계산을 통해 얻어내는 map은 아래 수식으로 표현해볼 수 있습니다.
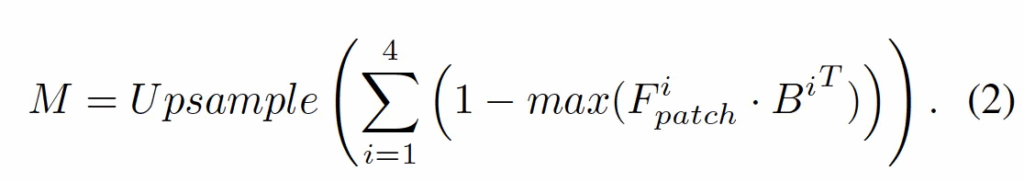
Prompt Learner
다음 prompt learner 모듈은 LLM이 anomaly image를 좀 더 잘 이해하도록 하는 모듈인데, 다시 말하자면 decoder가 만들언 낸 pixel level anomaly localization 결과를 LLM이 이해할 수 있도록 prompt embedding으로 변환해주는 과정을 합니다.
Fig2에 prompt learner안에 부분을 보시면 learnable base prompt embedding이 보이는데, 단순 decoder output만 input넣는게 아니라 여기에 추가적으로 learnable한 prompt embedding도 포함이 됩니다. 일종의 task context로 작용하는 것이죠.
최종적으로 이 둘을 합쳐 하나의 전체 prompt로 만들어 원본 image embedding과 함께 LLM input으로 넣어주게 됩니다.
2.3. Data for Image-Text Alignment
Anomaly Simulation
AnomalyGPT에서는 image와 text간의 alignment를 맞춰주기 위해 anomaly가 있는 영상과 그에 대응하는 text를 만들어야 합니다. 하지만, 실제로 anomaly영상이 많이 없기 때문에 NSA라고 하는 방식을 사용해 anomaly data를 simulation으로 만들어 사용합니다.
NSA 방식에 대해 잠깐 설명을 드리자면, 이는 Cut-Paste 기법을 기반으로 Poisson image editing 방식을 추가한 것인데, Cut-Paste는 이름에서도 알 수 있듯이 한 image의 일부분을 잘라내어 다른 위치에 덧붙이는 방식입니다. 다만, Cut-Paste의 단점은 잘라 붙인 그 경계 부분이 너무 뚜렷해서 discontinuity가 생기기 쉽다는 것인데, 이를 줄이기 위해 Poisson image editing 방식을 사용하는 것입니다.

위 그림을 통해 Cut-paste의 예시를 확인할 수 있습니다. 좀 이질적으로 붙여 넣은 부분이 확 눈에 띄는 것을 확인할 수 있습니다. 여기에 Poisson은 붙여넣은 영역이 주변 이미지와 자연스럽게 어우러지도롣 PDE(poisson 편미분 방정식)을 통해 경계를 부드럽게 연결해주는 기법입니다. 그림에서도 Cut-paste보다 좀 더 자연스럽게 보이는 것을 확인할 수 있습니다. 결과적으로 이렇게 합성한 anomaly 영상들은 LLM이 image-text alignment를 잘 학습할 수 있게 합니다.
Question and Answer Content
AnomalyGPT는 LLM이 anomly detection task를 잘 수행하도록 학습하기 위해 prompt tuning을 적용했었고, 이를 위해서는 앞에서 만든 합성 anomaly image에 대해 그에 맞는 text 기반 question-answer pair도 만들어야 합니다.
각 prompt는 크게 두 부분으로 구성됩니다. 첫 번째는 image에 대한 설명으로 image에 어떤 object가 있고 그게 어떻게 생겼어야 하는지 알려주는 문장입니다. 예를 들어 “This is a photo of leather, which should be brown and without any damage, flaw, defect, scratch, hole or broken part.”식의 문장인데 해석하자면 “이는 가죽 사진이며, 원래 갈색이고 손상이나 흠집, 구멍, 긁힘 같은 결함이 없어야 한다”는 문장이죠.
두 번째는 question으로, “Is there any anomaly in the image?”와 같이 anomaly 존재 여부를 묻는 질문입니다. 그럼 LLM이 판단해서 이상이 있다면 “Yes, there is an anomaly in the image, at the bottom left of the image”라는 식으로 그 위치와 개수까지 설명하게 되고 이상이 없다면, “No, there are no anomalies in the image”처럼 답하게 됩니다.

이때, 위치 정보를 좀 더 명확하게 표현하기 위해 위 Fig4처럼 image를 3x3 grid로 나눠서 LLM이 Top, left, Center, Bottom Right와 같은 방식으로 위치를 표현할 수 있도록 하였습니다.
2.4. Loss Functions
마지막으로 loss에 대해 설명을 드리자면, 먼저 LLM을 학습할 때 사용하는 cross entropy loss를 사용하였습니다.
Cross-Entropy Loss
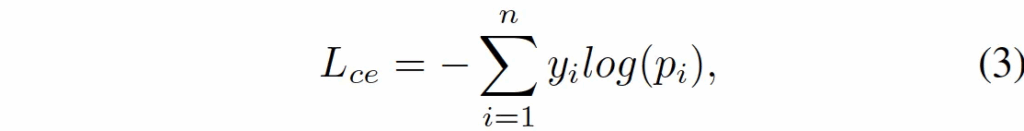
모델이 생성한 text sequence와 실제 gt text간의 차이를 줄이도록 학습됩니다.
Focal Loss
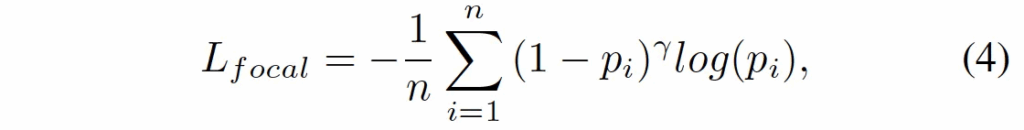
다음으로 사용되는 Focal loss는 class imbalance 때문에 사용하였는데, anomaly detection에서는 대부분 pixel이 normal이기에 imbalance가 커서 focal loss를 사용하였습니다.
Dice Loss
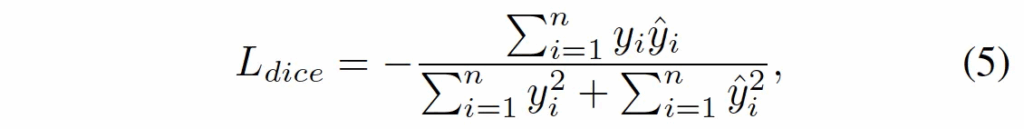
마지막으로 Dice Loss를 통해 segmentation 학습을 하게 됩니다.
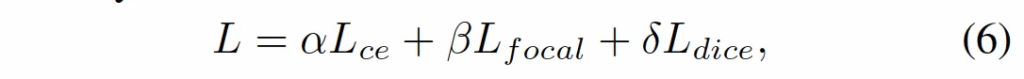
total loss는 이 세 loss의 가중합으로 계산됩니다.
3. Experiments
이제 실험 부분 살펴보도록 하겠습니다. 실험에서는 MVTec-AD 데이터셋과 VisA 데이터셋을 사용하였으며, 평가지표로는 image-level AUC와 pixel-level AUC를 사용하였는데, 각각 image 단위로 normal인지 anomaly인지 판단하는 성능과 image내에서 anomaly 위치를 얼마나 잘 찾았는지 평가하는 지표입니다.
근데, intro 부분에서 AnomalyGPT는 anomaly를 판단하는 threshold없이도 anomaly여부를 판단할 수 있도록 설계되었다고 했기에, 이 두 평가지표에 더해 image-level accuracy도 함께 평가 지표로 사용하였습니다. 즉, 단순 anomaly score가 높으면 anomaly로 판단하던 이전 모델들처럼 평가하는 것에 추가로 모델이 직접 anomaly라고 판단한 accuracy도 함께 본 것입니다.
Quantitative Results
Few-Shot Industrial Anomaly Detection
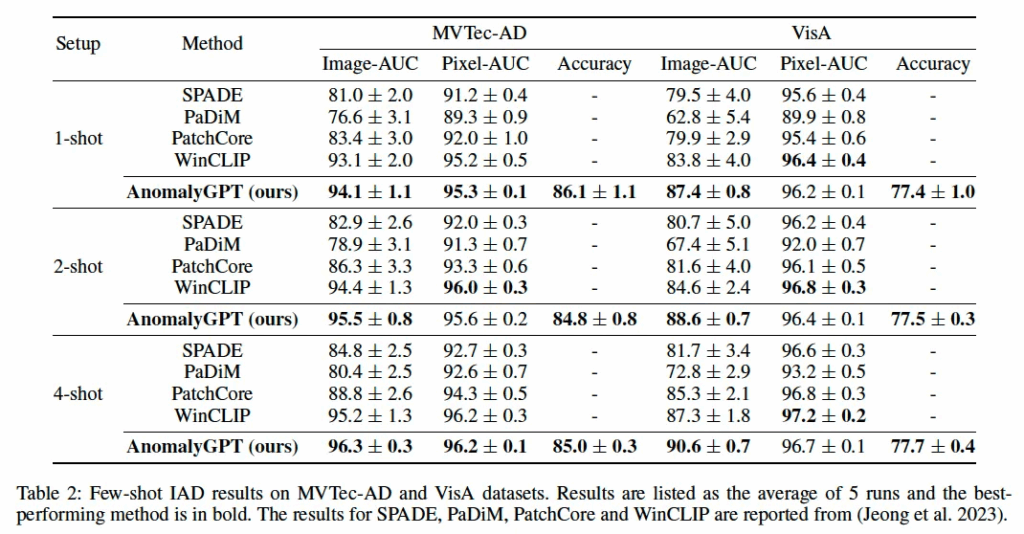
먼저, few-shot 세팅에서의 성능을 살펴보자면, table2에 그 결과가 나와있는데 직접적으로 비교하고 있는 PatchCore 방법론은 본 방법론과 유사한 patch-level의 memory 기반 방식으로 동작하며, WinCLIP은 CLIP기반의 방법론입니다. 실험 결과를 보면, AnomalyGPT는 image-level AUC 기준으로 두 데이터셋 모두에서 기존 방법론들도 더 좋은 성능을 보익 凸있으며, pixel level AUC에서도 전부 다는 아니지만,, 일부 sota를 달성하였습니다.
여기서 볼 만한 점은 image-level AUC의 성능이 모델이 직접 threshold 없이 이상 여부를 직접 판단하는 구조로 설계되었음에도 불구하고 기존 방법론들보다 더 좋은 성능을 보인다는 점에서 의의를 갖는다는 점입니다.
Unsupervised Industrial Anomaly Detection
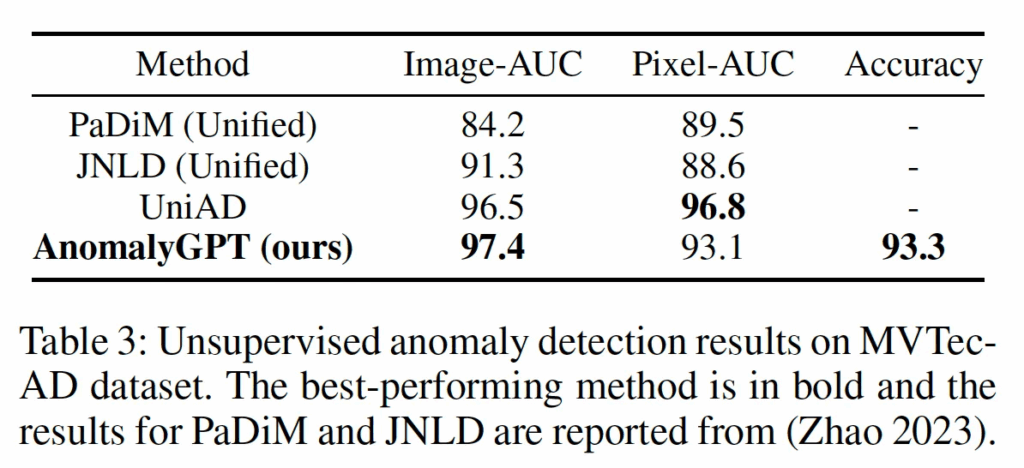
다음으로 Unsueprvised 세팅에서는 normal sample에 대해 충분히 학습한 다음 평가하게 되는데요. 여기서 AnomalyGPT는 이 하나의 모델로 전체 class에 대해 unified하여 학습을 수행하기에 이 방식이 기존 방법론 UniAD와 동일하기에 비교 대상으로 삼았습니다. 위 표3에서 결과를 보시면, MVTec-AD 데이터셋에서 image-AUC에서 가장 좋은 성능을 보였으며 pixel level에서도 sota는 달성하지 못했지만,, 준수한 성능을 보입니다. Accuracy 측면에서도 비교 대상이 없지만 좋은 성능을 보이구 있구요.
Qualitative Examples

다음으로 정성적 결과를 확인해볼건데, 먼저 위 FIg5에서는 unsupervised 세팅에서의 결과입니다. 보시면 anomaly 존재 여부를 판단하고 있고, 그에 대한 위치와 pixel 단위로 anomaly 영역을 localization해내는 모습을 보입니다.
또, 본 모델은 단순 한 질문에 대해 답변하고 끝이 아니라, user가 추가적으로 그림에서처럼 “What’s this in the image?”처럼 추가 질문을 한 경우에서도 image 를 바탕으로 multi-turn 대화가 가능한 구조입니다.

또 위 Fig6을 보시면 이는 1-shot 세팅에서의 정성적 결과인데, 여기서는 학습 없이 normal image하나만을 가지고 anomaly localization을 수행해야 하다보니 위의 unsupervised setting보다는 localization 정확도가 좀 떨어지는 경향을 보이기도 합니다. 그럼에도 이 이전 정보를 context로 활용해 anomaly를 추론하는 능력을 잘 보여주고 있습니다.
Ablation Studies

마지막으로 본 논문에서 제안된 각 구성 요소들이 실제 성능 향상에 어느정도 영향을 미치는지 확인하는 ablation study 결과입니다. 여기서는 표4에서도 보이다시피, decoder, prompt learner, LLM을 통한 추론 여부, LoRA를 통한 tuning여부에 대해 실험을 하였습니다.
여기서 볼만한 점은 기존 방식들처럼 threshold를 수동으로 정해서 anomaly score 기반으로 anomaly를 판단하는 것에 비해 LLM을 통해 직접 anomaly를 판단하도록 했을 떄가 Accuracy 측면에서 훨씬 더 좋은 성능을 보입니다. (표에서 4행과 7행 비교 72.2 vs 90.3) 또, LLM을 fine-tuning하는 방식에서도 LoRA를 사용해 tuning한 경우보다 prompt tuning만 한 경우가 전반적으로 더 좋은 성능을 보이는데, (6행 vs 8행) 이는 prompt tuning방식이 기존 LLM 능력을 보존하면서도 더 나은 일반화 성능과 transferrability를 제공한다는 것을 시사한다고 해석해볼 수 있습니다.
안녕하세요 윤서님 좋은리뷰 감사합니다.
성능적으로도 이미 유의미한데 대화까지 가능하게 만든점이 신기하네요. 간단하게 드는 궁금점들 질문드리자면 poisson 방식으로 정상이미지에 anomaly한 상황을 넣는다는게 실제 anomaly인 데이터들과의 이미지 픽셀적 유사도가 높은지 궁금합니다. 저 방법을 사용했을때 일반화가 어느정도 가능하니 성능이 나오는거겠지만 논문에 저 방법으로 충분히 실제 anomaly한 상황을 대체할 수 있었다는 다른 증거가 있는지 궁금합니다.
그리고 실제 저 모델을 사용한다고 가정할때 알약이나 이런곳에 조명의 빛반사등이 anomaly로 충분히 예측될 수 있을 것 같은데 이러한 언급이 없었는지..? 도 궁금합니다. 마지막으로 기존의 threshold를 인간이 설정해주는 방식을 픽셀간의 distance를 softmax로 확률화시켜 해결했다고 생각하면 될까요? 감사합니다.
댓글 감사합니다.
물론 인택님이 언급한 것처럼 성능을 보면 어느정도 일반화 가능한 것은 사실이지만, 실제로 논문에서는 simulation한 anomaly sample과 실제 anomaly sample간의 유사도를 분석하거나, 정성적으로 확인하고 있지는 않습니다. 또한, 빛반사 같은 것이 noise로 작용할 수 있을 것 같다고 했는데, 이에 대해서는 실제 application단 환경에 맞춰 augmentation을 추가하면 좀 더 robust해질 것이라고 생각됩니다.
마지막으로, 기존 threshold를 설정해주는 방식에 대해서는 distance를 계산하고 이 distance 값 기준으로 thresholding을 하는 것입니다. 즉, softmax로 확률화시키지 않는다고 보면 됩니다.
안녕하세요. 좋은 리뷰 감사합니다.
이 모델이 기존 모델과 다른 차별점은 score 기반으로 thresholding해서 결과를 내는게 아니라 모델 스스로 판단한다는 점으로 이해를 했습니다. 그런데 그 부분이 정확히 어떻게 수행되는 건지 잘 이해가 안돼서 모델 구조의 어느 부분으로 인해 그런 결과가 나오는 것인지 구체적으로 설명해 주실 수 있나요? 또 이로 인해 측정 가능하다고 한 Accuracy는 어떻게 계산한건지 궁금합니다.
감삼다.
안녕하세요. 댓글 감사합니다.
score 기반의 thresholding이 아닌 모델 스스로 판단한다는 점은, 본 모델이 LLM을 사용하고 있기 때문입니다. 최종적으로 output이 자연어 “yes”나, “no”로 나오기 때문에 스스로 판단한다고 언급하였습니다.
또, 이로 인해 측정 가능하다고 한 Accuracy는 모델 output(yes 혹은 no)과 GT를 비교해 정답 prediction/ 전체 image 수 로 계산한 것입니다.
안녕하세요, 좋은 리뷰 감사합니다.
사전학습 된 image encoder랑 LLM을 써서 image와 text 간 alignment를 수행하고, simulation에서 cut-paste로 anomaly image를 만들어서 fine-tuning한 것으로 이해했는데요, 한가지 궁금한게 cut-paste는 결국 일종의 합성 이미지인것으로 보이는데, 이것만을 사용해도 anomaly를 모델링하기에 충분하다고 이해하면 될까요? 제가 올바르게 이해한건지 궁금합니다.
감사합니다.
안녕하세요. 댓글 감사합니다.
본 논문에서는 단순 cut-paste만 하는게 아니라 추가적으로 PDE(poisson 편미분 방정식)을 통해 경계를 부드럽게 해줘 simulation해 사용하는데요. 이는 본 논문에서 제안한게 아니라 이전 NSA라고 하는 논문에서 제안한 방식으로 몇 IAD task에서 사용되고 있는 simulation 방식입니다. 다만, 재연님이 가진 의문처럼 모든 anomaly를 모델링하기에는 부족하다고 볼 수 있는데요. 이 부분에 대해서 후속 연구들로 diffusion 등을 통해 좀 더 사실적으로 모델링하는 연구들이 나오고 있습니다.
안녕하세요 정윤서 연구원님, Oral 논문을 소개해주셔서 감사합니다.
실험 부분에서 몇가지 궁금한것이 생겨서 댓글을 남깁니다. simulation 데이터의 경우 단순히 cut-paste를 하면 discontinuity가 발생할 수 있어 문제가 된다고 하셨는데, 이것이 문제가 되는 이유가 무엇인가요? 경계면이 너무 명확하여 학습이 너무 쉬워 overfitting 이 발생하기 때문으로 이해하면 되는지 궁금합니다 ㅎㅎ
다음으로 “Question and Answer Content” 부분에서 prompt는 두 부분으로 구성되며 1) image에 대한 문장과 2)anomarly 존재여부를 묻는 질문이라고 소개해주셨습니다. 이때 prompt learner가 생성하는 learnable prompt는 두 부분의 프롬프트에 추가적으로 더해지게 되는 것인가요..?
해당 연구의 장점의 threshold 없이도 anomaly 를 판별하는 이점이 있다고 했는데, 오히려 학습기반이기 때문에 데이터셋 의존성이 생겨 도메인 변경마다 재학습/재튜닝이 필요하다는 관점에서 문제가 해결되지 않은것으로 볼 수있지 않을까 우려되는데요, 또한 질의에서 “원래 갈색이고 손상이나 흠집, 구멍, 긁힘 같은 결함이 없어야 한다”와 같은 조건을 더해야 하여 오히려 사람의 개입으로 튜닝해야하는 개입이 많이 발생하는것이 아닌가싶습니다. 혹시 제 이해에 잘못된 부분이 있을까요?
감사합니다
댓글 감사합니다.
1. 넵 맞습니다. 단순 붙이게 되면 그 경계가 뚜렷하게 되고, 이를 학습하게 되면 anomaly라는게 경계가 좀 튀어나온 부분이라고 모델이 학습하게 되기 때문입니다.
2. 넵 prompt learner가 생성하는 learnable prompt는 기존 image describe + question 앞에 concat되어 input으로 들어가게 됩니다.
또, 유진님이 언급해주신 오히려 describe를 사람이 다 써줘야 하는 점에서 개입이 많이 발생하는 것은 맞습니다. 이 부분은 본 논문의 limitation이라고 볼 수 있을 것 같습니다.