안녕하세요. 이번에 리뷰로 가져온 논문은 CVPR 2026애 올라온 VidEoMT: Your ViT is Secretly Also a Video Segmentation Model라는 논문입니다. 현재 내비게이션 플래닝 분야에서 action을 생성하는데 있어서 과거 시퀀스 프레임들을 입력으로 사용하는데 이런 temporal 정보를 어떻게 하면 모델이 더 잘 이해할 수 있을지 이런 temporal 정보들을 처리하는 방법들에 대해서 한번 알아보고자 비디오 분야의 해당 논문을 읽게 되었습니다. 바로 리뷰 시작하도록 하겠습니다.
Introduction
기존 online video segmentation 쪽 SOTA들을 보면 대체로 구조가 복잡하다고 합니다. 보통은 먼저 프레임별로 segmentation을 수행하는 segmenter가 있고 그 결과를 시간축으로 이어붙여 같은 객체를 계속 같은 아이덴티티로 추적하는 trackjer가 따로 붙는 구조로 이뤄져있다고 합니다. (online video segmentation 모델은 프레임마다 mask와 class를 잘 예측해야 할 뿐 아니라 시간이 지나도 같은 객체를 같은 인스턴스로 유지해야 함) 이렇게 segmenter와 tracker라는 두개 모듈이 나뉘어져서 설계가 되어있는 구조가 기존 연구들의 흐름이었다고 합니다. 논문에서 대표 예시로 드는 것이 CAVIS라는 방법론인데 이 계열은 frame level segmentation을 위한 모듈들과 tracking을 위한 모듈들이 꽤 많이 들어간다고 합니다. 그래서 이 때문에 정확도는 좋지만 구조가 무겁고 연산량도 크다고 합니다. 근데 저자들은 특히 DINOv2 같은 대규모 사전학습 ViT는 이미 학습 목표 자체가 달라진 뷰에서도 같은 객체가 비슷한 표현을 갖게 만드는 방향으로 설계 되어있기 때문에 이런 비디오 세그멘테이션에 적합하고 굳이 이런 강력한 백본을 사용하면 추가적인 모듈들은 불필요할 수 있다고 주장합니다.
정리하면 저자들은 segmenter + tracker를 굳이 분리해서 복잡하게 설계할 필요없이 하나의 encoder-only ViT 안에서 segmentation과 temporal한 연결을 같이 처리하자라는 것이 저자들의 핵심 주장이고 그렇게 해서 제안한 모델이 VidEoMT (Video Encoder-only Mask Transformer)입니다.
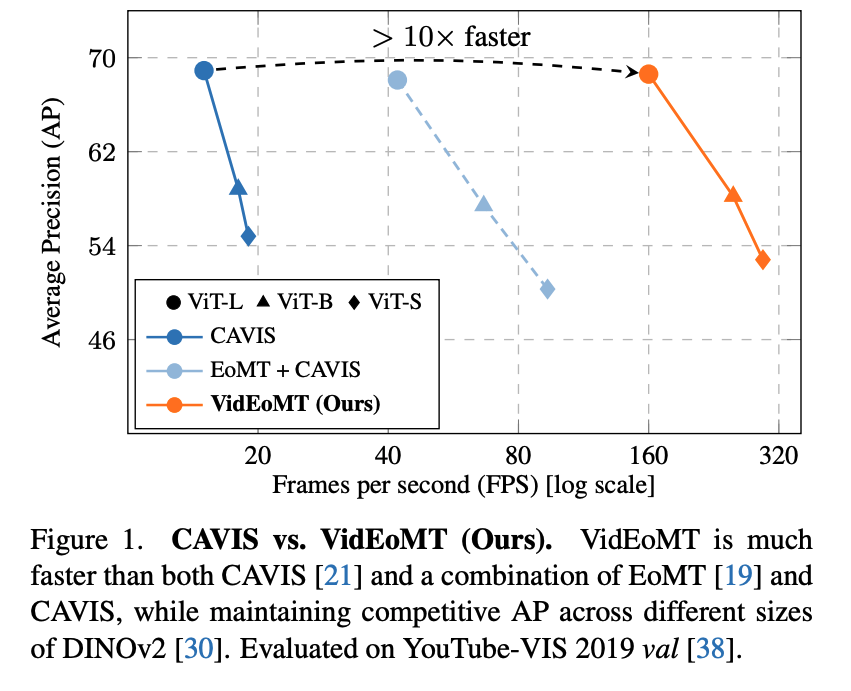
위는 CAVIS vs VidEoMT 속도-성능 그래프인데 결과적으로 저자들이 제안한 방법이 기존 방식과 비교했을 때 비슷한 AP를 유지하면서 FPS는 더 빠르다라는 결과를 보입니다.
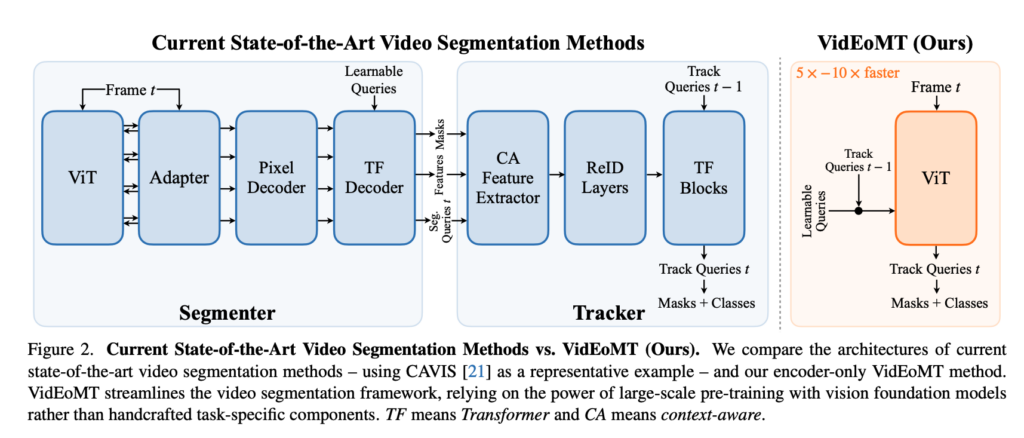
위는 기존 방식과 저자들이 제안한 방식의 구조를 한눈에 비교하기 쉽게 그려놓은 그림인데 왼쪽 파란부분(기존 방법론들)을 보시면 segmenter와 tracker가 나뉘어 있고 그리고 그 안에서도 각각 내부적으로 복잡하게 설계되어있는 모습을 보이는 반면 VidEoMT는 한 개의 ViT만으로 설계되어있는 것을 확인하실 있습니다.
이런 비디오 세그멘테이션 모델에서 복잡한 구성요소들이 사실은 불필요할 수 있다는 저자들의 핵심 주장을 검증하기 위해서 기존의 비디오 세그멘테이션 모델을 가져와서 그 안의 각각의 모듈들을 제거했을 때 어떤 영향이 있는지를 평가도 진행을 합니다. 해당 내용은 방법론에서 자세하게 다루도록하겠습니다.
Method
먼저 기존 sota 모델인 CAVIS구조에 대해서 자세하게 설명드리도록하겠습니다. 기존 방식같은 경우는 fig2 파란색 부분을 참고하면서 보시면 좋을것 같습니다. Segmenter 같은 경우는 프레임 단위 image segmentation을 수행합니다. 논문 기준으로는 보통 pre-trained ViT, ViT-Adapter,Mask2Former 계열 decoder 같은 구조를 조합해서 객체에 대한 mask와 class를 예측합니다. 이 과정에서 learnable query를 사용해 object level representation을 만들게 됩니다. 그리고나서 현재 프레임의 query와 이전 프레임의 query를 맞춰서 같은 객체가 시간에 따라 같은 query index에 남도록 하게끔 합니다. 보통 transformer block 기반 tracker를 두고 query 간 attention으로 temporal정보를 연결을 한다고 합니다. (fig2 tracker 부분) 여기에 더해서 기존 방법들은 추가적인 모듈을 붙이는데 fig2 tracker 부분에서 CA feature Extractor (Context-aware features: 객체 경계 주변 문맥까지 이용해서 tracking하게끔) 그리고 Re-identification layers (같은 instance는 가깝고 다른 instance는 멀어지도록 contrastive하게 학습하는 모듈) 이렇게 두가지를 tracker 앞단에 추가적인 보조장치로 붙입니다. 기존 파이프라인은 은 segmentation과 tracking을 위해 여러 추가적인 모듈을 붙혀놓은 구조입니다. 그래서 저자들은 여기서 모듈을을 하나하나씩 대체하고 제거합니다.
저자들은 일단 먼저 image segmentation 쪽 선행연구인 EoMT를 가져옵니다. 이 EoMT는 잘 사전학습된 ViT에 learnable query만 잘 넣어주면 복잡한 업댑터나 decoder 없이도 segmentation이 된다는 아이디어를 보여준 모델인데 VidEoMT는 이 철학을 그대로 비디오쪽으로 확장했다고 보시면 좋을 것 같습니다.
앞서 말씀드린대로 저자들은 EoMT를 가져와서 기존의 ViT-Adapter + Mask2Former 계열 segmenter를 버리고 query를 ViT encoder 내부에 직접 넣는 EoMT 기반 segmenter로 바꿉니다. 그리고 나서 Context-aware features Extractor 모듈을 제거합니다. 여기서 저자들은 잘 사전학습된 ViT feature라면 굳이 boundary 주변 문맥을 별도 필터링한 정보가 추가적으로 필요가 없을 거라고 하는데 그 이유가 그런 ViT의 feature 자체가 이미 충분히 세밀하고 특정 객체 identity를 포착하고 뷰 변화나 가림 상황에서도 안정성을 유지할 수 있고 또 이를 위해서 쉽게 파인튜닝될 수 있기 때문이라고 합니다. 그리고 Re-identification layers 제거도 진행합니다. (별도의 ReID head와 contrastive objective도 없앰) 마찬가지로 저자들은 DINO같은 잘 사전학습된 ViT 인코더의 feature 자체가 이미 풍부한 instance level 정보를 담고 있을 뿐더러 앞서 segmetor에서 나온 segmentation query는 이러한 feature들에 대해 cross attention을 수행하기때문에 그 안에 담긴 인스턴스 구별 능력을 자연스럽게 물려받고 이를 프레임 간에도 유지할 수 있기 때문에 이러한 re-identification layer는 제거해도 된다고 합니다.
앞서 설명한 단순화 과정을 거친 뒤의 모델은 결과적으로 보면 segmenter로서의 EoMT 와 단순화된 tracker(CA Feature Extractor제거, ReID layer제거) 로 구성되게 됩니다. 어떻게 보면 사실상 남는 것은 frame wise EoMT가 되는데 이렇게 하면 프레임을 독립적으로 처리하기때문에 tracking이 약해집니다. 실제로 논문에서도 tracker를 제거한 naive EoMT는 속도는 엄청 빨라지지만 AP가 많이 떨어졌다고 합니다. 그래서 저자들은 encoder only 구조 안에 temporal modeling하는 방식을 설계합니다.
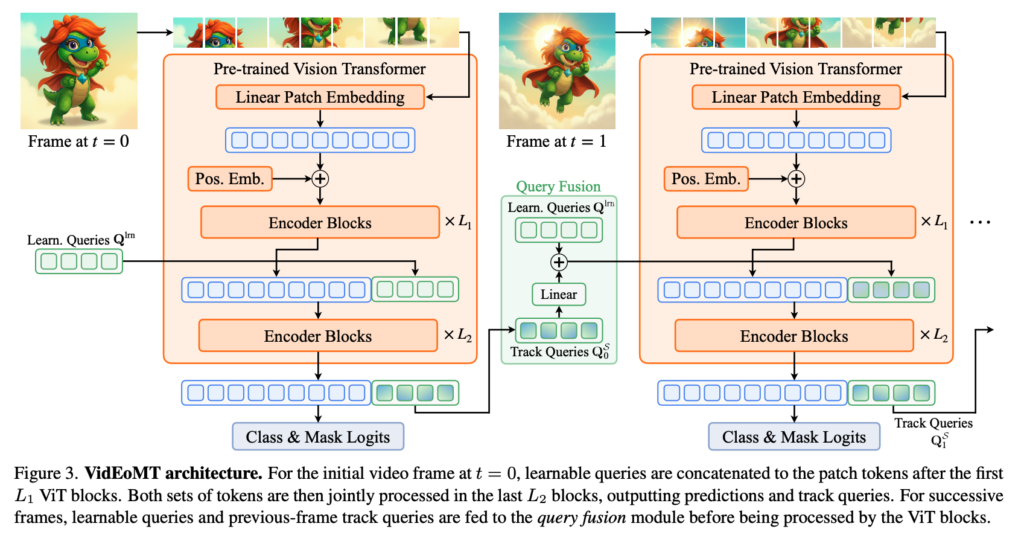
위 아키텍쳐가 encoder only 구조 안에 temporal modeling하는 방식으로 저자가 제안한 방법론인 VidEoMT입니다. 먼저 저자가 말한 기존에 방식에서 다 쓸모 없다고 생각하는 모듈을 제거 했을 때 생기는 tracking문제를 해결하기 위해서 설계한 방식에 대해서 설명드리도록 하겠습니다.
Query Propagation
tracker가 제거되면 모델은 각 프레임을 서로 독립적으로 처리하는 단일 이미지 수준의 EoMT 아키텍처와 다를게 없어집니다. 그래서 저자들은 query propagation을 통해 시간적 모델링을 다시 도입합니다. 시각 t=0에서는 표준 EoMT 설정을 그대로 따라서 학습 가능한 query Q^{lrn}를 ViT의 마지막 L_2개(논문 기준 4개) 층에 입력하여 객체 query embedding Q_0^S와 그에 대응하는 세그멘테이션 예측을 하고 그 이후의 t>0에서는 학습 가능한 query를 다시 사용하는 대신 이전 프레임에서 전달된 propagated query, 즉 track query에 해당하는 Q_{t-1}^S를 ViT의 마지막 L_2개 층의 입력으로 사용하게됩니다. 이 시점들에서 세그멘테이션 절차 자체는 EoMT와 동일한데 유일한 차이는 학습 가능한 query 대신 propagated query가 사용된다는 점입니다. 단순히 이전 learnable query를 다음 프레임 인코딩 과정에 사용된다고 보시면 좋을 것 같습니다. 근데 이 전략은 프레임당 추가 계산 비용 없이도 temporal 축을 따라 정보가 흐를 수 있게 만들수 있긴 하지만 ViT가 계속 이전 프레임의 정보만 받게 되기때문에 원래의 학습 가능한 query Q^{lrn}의 영향이 점점 약해지게 됩니다. 결과적으로 모델은 비디오에서 새롭게 등장하는 객체를 인식하는 능력을 잃게 된다고 합니다.
Query Fusion
위와 같은 문제를 해결하고자 저자들은 Fig 3에 나타난 query fusion 모듈을 설계합니다. 이 설계에서는 이전 프레임의 query Q_{t-1}^S를 먼저 가벼운 linear layer에 태우고 이를 원래의 학습 가능한 query Q^{lrn} 와 element-wise sum을 진행합니다.
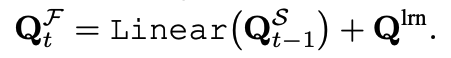
위와 같은 fusion을 통해 모델은 Q_{t-1}^S를 통해 과거로부터의 temporal context)에 접근할 수 있고 다른 한편으로는 Q^{lrn}를 통해 새로운 객체에 대해서 적응할 수 있는 능력이 유지된다고 합니다.
Training
학습같은 경우는 VidEoMT는 Mask2Former 와 동일한 목적함수를 가지고 학습이 진행되고 classification에는 cross-entropy loss를 사용하고 세그멘테이션 예측에는 에는 binary cross-entropy loss와 Dice loss를 사용한다고 합니다. 그리고 여기서 시간적으로 일관된 supervision을 보장하기 위해 즉 쿼리가 다음 프레임에서도 같은 객체에 대해서 이어지도록 저자들은 DVIS++ 의 ground truth matching 전략을 따랐다고 합니다. 여기서는 어떤 ground-truth 객체가 처음 등장하는 프레임에서만 하나의 query와 매칭되고 그리고 그 이후의 나머지 프레임들에서, 그 ground-truth 객체가 계속 같은 query에 유지되어 매칭되게끔한다고 합니다. 이를 통해 temporal consistency를 보장했다고 합니다.
supplementary까지 보면 학습은 2-stage라고 합니다. 먼저 image segmentation을 위한 학습 그 다음 temporal modeling을 포함한 video segmentation fine-tuning이렇게 두단게로 학습이 이뤄집니다.그리고 VidEoMT는 encoder-only 구조라서,기존 baseline처럼 encoder를 고정하기보다 ViT encoder도 계속 fine-tune했다고 합니다. 별도의 decoder나 tracking module이 아니라 인코더 자체가 비디오 세그멘테이션을 수행할 수 있도록 학습되어야 하기때문에 여기에 맞게 인코더 가중치를 최적화해야만 했다고 합니다.
Experiments
평가는 6개 benchmark에서 진행합니다.
-OVIS, YouTube-VIS 2019/2021/2022: VIS (instance)
-VIPSeg: VPS (panoptic)
-VSPW: VSS (semantic)
하나의 video instance segmentation task에만 맞춘 게 아니라 video segmentation 전반에 대해 어느 정도 범용성을 보이기위한 세팅을 한것 같습니다. 구현은 기본적으로 DINOv2-pretrained ViT를 backbone으로 사용하고 temporal window 5 frame으로 설정합니다.
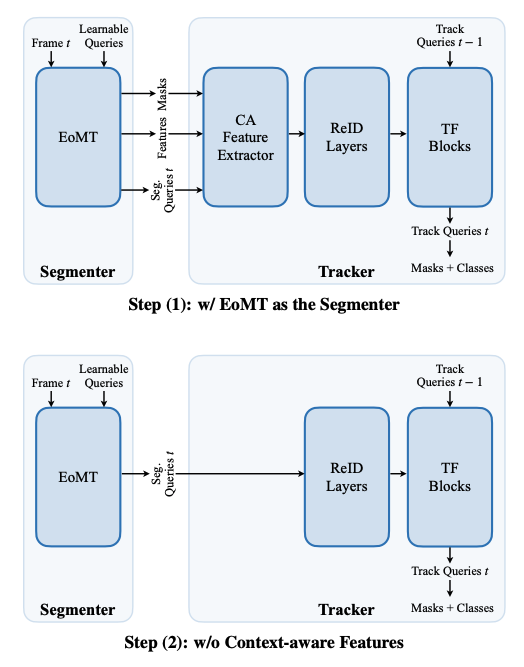
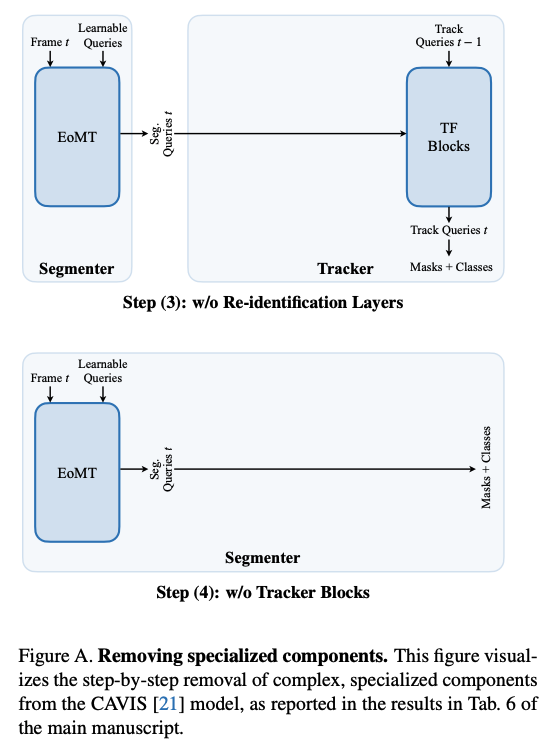
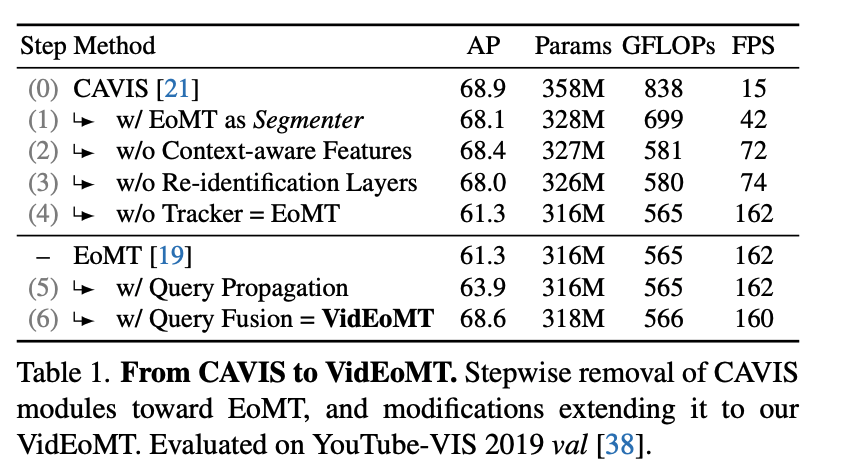
위 실험 결과는 CAVIS에서 출발해서 모듈을 하나씩 덜어내면서 어디까지 성능이 유지되는지를 보는 step wise experiment입니다.
Step (1) – segmenter를 EoMT로 바꾸기
FPS가 거의 3배 가까이 좋아지는데 AP는 0.8 정도만 떨어지는 결과를 보입니다. 어떻게 보면 기존 segmentation 쪽 복잡한 head는 생각보다 덜 중요할 수도 있다라는 생각이 들게끔 보여주는 결과이자 EoMT의 learnable query 방식의 강력함을 보여주는 결과인것 같습니다.
Step (2)-(3) – context-aware features, ReID 제거
속도는 더 빨라지는데 성능 저하는 거의 없는 모습을 보입니다. 이 부분이 앞서 저자들이 주장한 가설 DINO처럼 잘 사전학습된 ViT가 있으면 이 task-specific module들이 굳이 필요없다라는 것을 뒷받침해주는 결과라고 볼 수 있습니다.
Step (4): tracker까지 제거
여기서 FPS는 162까지 10배이상으로 올라가는 대신 AP가 7.6이나 떨어집니다. 결과를 보면 확실히 temporal modeling은 필요하다라는 것을 알 수 있지만 여기서 저자들은 tracker를 완전히 없앴는데도 성능이 완전히 무너지진 않는다는 점에 대해서 이건 encoder + query만으로도 EoMT가 시간적 상호작용 없이 각 프레임을 독립적으로 처리하더라도 프레임들 사이에서 객체들을 어느 정도 일관된 순서로 출력하는 것을 학습할 수 있음을 보여주는 결과라고 주장합니다.
Step (5): query propagation 추가
AP가 다시 올라가는 모습을 보입니다. 위 실험결과 테이블만으로는 직접적으로 알 수 없지만 저자들은 temporal modeling이 회복되긴 하지만 새 객체 탐지가 약한 모습을 보였다고 합니다.
Step (6): query fusion 추가 = VidEoMT
최종적으로 거의 원래 CAVIS 수준의 AP의 수준까지 올라오는 결과를 보이면서 속도는 160 FPS로 10배 이상 빠릅니다.
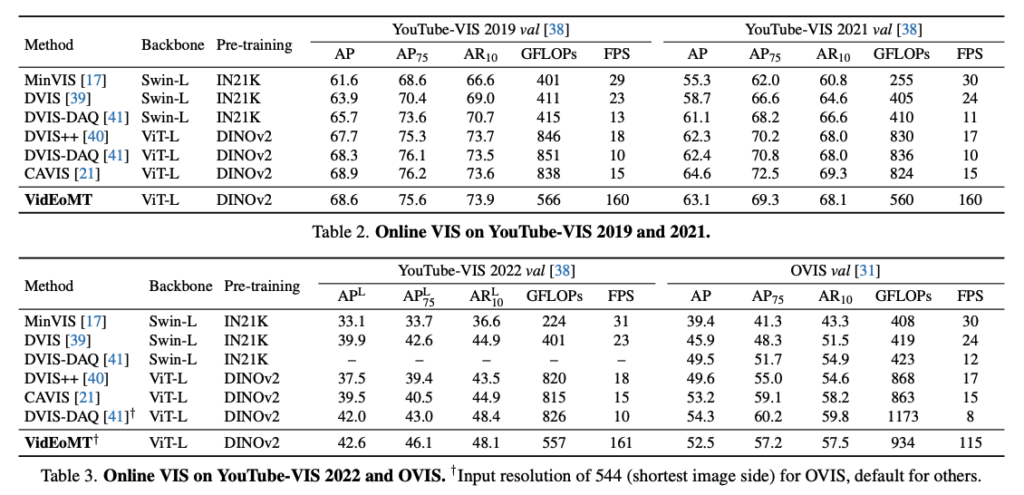
위는 기존 모델간의 VIS benchmark 비교입니다. 결과적으로 저자의 방법론은 기존 모델과 비교했을 때 대체로 비슷하거나 더 좋은 정확도를 보이면서도 속도 측면에서는 훨씬 빠른 결과를 보입니다.
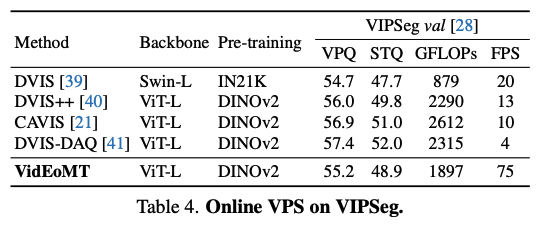
위는 VPS 결과 비교 입니다. VIPSeg에서는 최고 VPQ는 아니지만 정확도 손실은 작고 속도는 훨씬 빠른 결과를 보입니다.
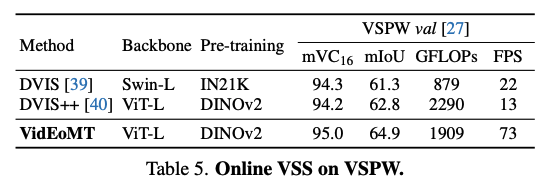
VSPW에서는 mIoU, temporal consistency(mVC) 둘 다 좋은 결과를 보입니다. 마찬가지로 속도도 5배 이상 빠른 모습을 보입니다.EoMT를 segmenter로 쓰고 기존 tracker를 붙이는 것보다 VidEoMT가 낫다
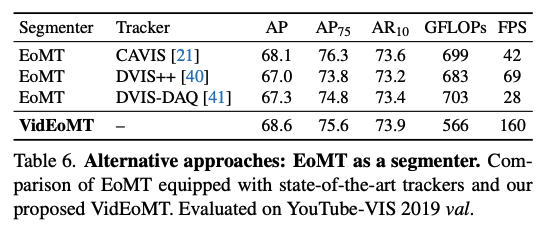
저자들은 그냥 EoMT를 좋은 segmenter로 쓰고 기존 tracker를 붙이면 되는 것 아닌가?라는 생각이 들 수 있기 때문에 위와 같은 실험을 진행합니다. 결과적으로는 VidEoMT가 훨씬더 빠르고 성능도 더 좋거나 비슷한 결과를 보입니다.

또 다른 비교로 VidEoMT에서는 객체 query를 직접 ViT 인코더 안으로 propagate하는데 저자들은 이게 query를 별도의 decoder로 전달하는 방식과 비교해도 동일하게 효과적인지 검증하기 위해서 위해서 DINOv2 + ViT-Adapter encoder 와 Mask2Former decoder 를 사용한 encoder–decoder 구조를 구성하고,이 decoder 안에 query propagation을 적용해보는 실험을 진행합니다. 결과는 VidEoMT의 encoder-only 방식이 비슷하거나 더 좋은 정확도를 보이면서 속도도 빠른 결과를 보입니다.
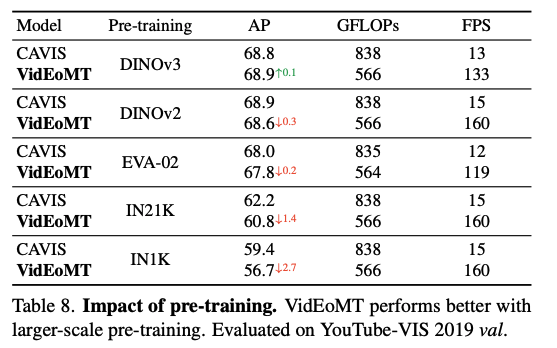
위는 백본 ablation인데 결과적으로 VidEoMT는 대규모 pretraining일수록 좋은 성능을 보인다고 합니다.DINOv2, DINOv3, EVA-02 같은 대규모 pretraining에서는 CAVIS와 성능 차이가 거의 없거나 작은 결과르 보이고 반면 IN21K, IN1K처럼 pretraining 규모가 줄어들면 VidEoMT가 CAVIS보다 좀더 성능이 떨어지는 모습을 보입니다. 백본이 강할수록 모델에 덕지 덕지 뭘 더 붙이는게 도움이 안될 수도 있다라는 저자의 주장을 뒷받침하는 결과인 것 같습니다.
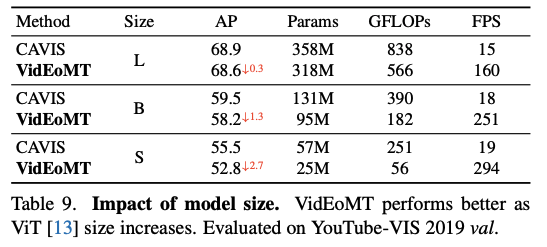
위는 모델 사이즈 ablation인데 ViT-L, ViT-B, ViT-S를 비교하면 모델이 커질수록 VidEoMT와 CAVIS 사이의 성능 격차가 줄어드는 결과를 보이고 큰 ViT일수록 더 성능이 좋은 모습을 보입니다.
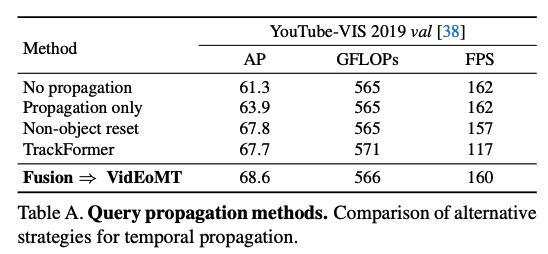
위는 supplementary에 있는 propagation 방식 비교 결과입니다. 결과적으로 fusion이 가장 정확하고 효율적이다 라는 것을 보여주줍니다. propagation only는 새 객체 탐지가 약하고TrackFormer 스타일은 느리다고 합니다.
아래는 정성적결과 입니다.



Conclusion
현재 구조는 이전 프레임 query를 현재 프레임으로 넘기는 1 step propagation인데 물론 query 안에 정보가 누적되긴 하겠지만 지금보다 좀더 긴 temporal 을 처리할때에도 잘 적용될 수 있을까라는 생각이 들긴합니다. 그래도 현재 내비게이션 플래닝 쪽에서는 그렇게 긴 temporal 정보를 다루지는 않기 떄문에 한번 적용시켜볼만한 방법론인것 같다는 생각이 들고 효율성 측면에서도 좋은 것 같습니다. 복잡한 temporal module보다는 encoder 내부에서 이전 query state를 가볍게 넘겨주는 방식을 잘 활용해보면 좋을 것 같습니다. 이만 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요 우현님 좋은글 감사합니다.
기존의 방법론들이 tracker를 사용하는 편이었다면 Dino의 강력한 백본과 temporal 축의 설계로 기존 방법론들의 복잡함을 줄여준 것 같네요. 기존 방법론들의 FPS 가 느린 것은 아니지만, 저자의 방법론 FPS 가 굉장히 현실적인 영상도 반영할 수 있게끔 향상되어 좋은 학회에 붙은 것으로 보입니다. conclusion에 작성해주신 우려처럼 기존 tracking 모듈을 제거하는 방식이 만들어낼 다른 문제점등을 생각해보신게 있는지 궁금합니다.
감사합니다.
안녕하세요 인택님 댓글 감사합니다.
사실 해당 논문은 기존 tracking 모듈을 제거 하고 query propagation, query fusion을 통해서 tracking 모듈을 제거했을 때 생기는 문제점을 보완하고자 한 논문입니다. 그래서 여기서 제가 생각하기엔 문제점은 아니지만 단순한 궁금증으로 지금보다 좀더 긴 temporal 을 처리할때에도 잘 적용될 수 있을지에 대한 그런 생각 정도만 한 것 같습니다.
감사합니다.
안녕하세요 우현님 리뷰 감사합니다.
소개해주신 연구를 보면서 다시 한 번 잘 사전학습된 모델의 강력함을 느꼈던 것 같습니다. Temporal 정보들을 처리하는 방법들에 대해서 고민을 하고 계신다고 하시면서 소개를 해주셨는데, video segmentation이라는 task 자체가 navigation쪽에 쓰이는 걸까요? 아니면 이런 연구들을 통한 인사이트를 다른 방향으로 연구에 적용하려는 목적이신가요?
안녕하세요 영구님 좋은 댓글 감사합니다.
비디오 세그맨테이션이라는 태스크 자체가 내비게이션 쪽에 많이 쓰이지는 않는 것 같은데 비디오 세그멘테이션 태스크에서 연구되는 다양한 아이디어는 차용해서 써볼 수는 있을 것 같습니다. 입력으로 들어오는 프레임 시퀀스의 temporal한 정보를 모델이 어떻게 잘 이해할 수 있을까 라는 관점에서 비디오 세그맨테이션 쪽의 아이디어를 한번 가져오고 인사이트를 다른 방향으로 내비게이션 연구에 적용해보고자 해당 논문을 읽어봤습니다!
감사합니다.