Introduction
VPR에서는 이미지를 apperance pattern descriptor로 설명합니다. 결국 VPR를 잘 수행하기 위해서는 이미지마다 구분력 있는 descriptor를 추출하는 것이 중요합니다. 이를 위해서는 변화하는 조명, 이동, 시간에 따른 변화, 계절에 따른 변화, 날씨에 따른 변화처럼 변화하는 것을 무시하고 더 일관적 물체에 집중해야 합니다.
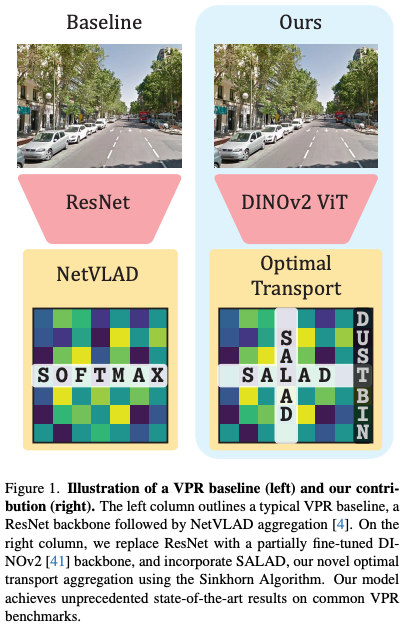
저자는 최근의 VPR 방법론들은 이를 위해, backbone을 바꾸거나 aggregation 방법론을 바꾸어서 발전하고 있다고 얘기합니다. 그렇기에 저자 역시 더 2가지를 개선하고자 하였습니다.
- 먼저, DINOv2를 backbone으로 사용하는 기존의 방법론(e.g. Anyloc)은 finetuning없이 DINOv2를 그대로 사용합니다. 저자는 DINOv2를 적절하게 finetuning 시키면 더 좋은 성능을 끌어낼 수 있다고 주장합니다.
- 또한, VLAD나 GeM pooling과 같은 aggregation보다 횔씬 발전된 SALAD(Sinkhorn Algorithm for Locally Aggregated Descriptors)를 제시합니다. 이는 Optimal Transport 알고리즘을 이용하여, 더욱 구분력 있는 특징을 집약할 수 있고, 불필요한 정보를 ‘dustbin’에 버리는 과정을 통해 노이즈에 강건해집니다.
Related Work
기존의 Aggregation 방법들을 소개하고 있습니다.
먼저 NetVLAD입니다. 기존의 Visual Word에 Hard Assign하여 잔차를 구하는 방식의 VLAD에서 발전하여, Soft Assign을 통해 미분가능하게 만든 집약 방법입니다.
이후에는 GeM Pooling이 VPR에서의 표준이 되었습니다. 학습가능한 값 p를 통해, 채널마다의 Mean pooling과 Max pooling의 비율을 결정하는 방식입니다. 학습하는 파라미터는 겨우 C(channel수)개이지만, 엄청난 성능 향상을 일으켰습니다. 이는 GeM pooling이 Salient한 특징에 집중하도록 유도하였기 때문입니다.
또한 MixVPR의 MLPMixer 방식 역시 효과적인 aggregation 방법입니다. Pooling을 통해 공간적 정보가 유실되는 기존의 pooling과 달리, Mixer를 통해 공간적 정보를 섞어주어 높은 성능을 보였습니다.
Method
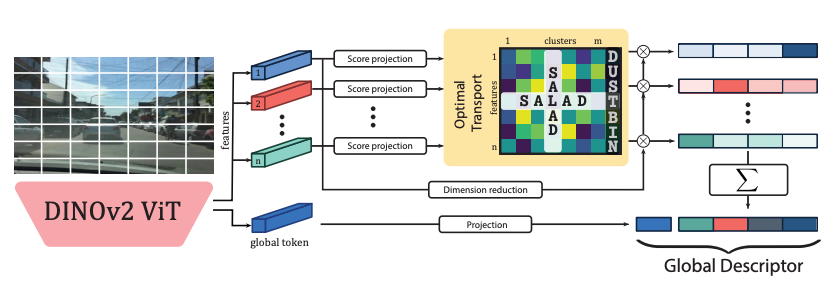
Local Feature Extraction
좋은 Local Feature를 뽑는 것은 밸런스가 중요합니다. 날씨, 조명, 계절등에 따른 것들은 무시하면서도 좋은 매칭을 위해서는 local structure을 충분히 뽑아낼 수 있어야합니다.
저자들은 Anyloc에서 DINOv2가 VPR을 위한 local feature을 잘 뽑아낸다는 것을 보여주었기에, 동일하게 DINOv2를 backbone으로 선택하였습니다. 또한 뒷 4개의 layer를 학습가능하게 두어, VPR의 성능을 끌어올렸습니다. 저자들은 DINOv2 논문에서는 model을 직접 finetuning하는 것이 약간의 향상(dim improvement) 밖에 보기 못할 것이라고 하였지만, 적어도 VPR에서는 상당한 향상(substantial gain)을 보였다고 얘기합니다.
Assignment
NetVLAD에서는 feature를 set of cluster에 assign하고, 각 cluster에 속하는 feature를 aggregating하여 global descriptor를 만듭니다. Assignment를 위해서, NetVLAD는 score matrix S \in \mathbb{R}_{>0}^{n \times m}를 계산합니다. 이는 cluster C_{j}에 할당하는 비용을 의미합니다. 다른 말로는 S는 각 Cluster에 대한 affinity score를 가지고 있다는 뜻입니다.(각 cluster에 할당될 가능성을 가지고 있다로 이해했습니다.) 저자는 NetVLAD에서 영감을 얻어서, 앞으로 나올 SALAD aggregation을 제안하였습니다.
Reduce Assignment Priors
NetVLAD가 score matrix S를 만들 때 랜덤 초기화로 시작하지 않습니다. K-means clustering으로 얻은 Centroid들을 linear layer를 통과시켜 S의 초기값으로 설정합니다. 이는 학습을 가속시키는 장점이 있습니다. 하지만, 이는 inductive bias를 S에 제공하여, model이 local minima에 빠질 가능성을 더 높게 만듭니다. 따라서 저자들은 scratch로부터 학습하고, 각 patch token들을 2 layer MLP를 통과시켜 학습시킵니다.
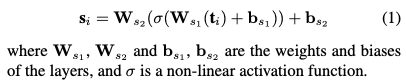
Discard Uninformative Features
VPR에서 모든 패치들이 중요하진 않습니다. 예를들어, 하늘 같이 계속 무의미하게 반복되는 배경은 불필요합니다. 그러나 NetVLAD는 이런 patch들도 모두 동일하게 평가하여 최종 descriptor에 반영됩니다. 저자들은 이러한 불필요한 patch를 제거하기 위해 dustbin을 도입합니다. 기존 score matrix S \in \mathbb{R}_{>0}^{n \times m}에 열하나를 추가합니다(S \in \mathbb{R}_{>0}^{n \times m+1}). 아래 그림이 이를 잘 표현하고 있습니다.
Dustbin은 single learnable parameter z로 정의됩니다. 즉, 어떤 patch의 score matrix S가 dustbin에 대한 affinity가 z 이상이라면 해당 patch는 dustbin에 할당됩니다.
Optimal Transport
논문에는 없는 단락이지만, 꼭 짚고 넘어가야할 것 같아서 추가했습니다. Optimal Transport의 개념에 대해 알아보겠습니다. 쌓여있는 흙더미가 있을때, 이를 어떻게 날라야 빈 구덩이들을 효율적으로 매울 수 있을까?에 대한 문제를 푸는 방식입니다. 좀 더 명확히 얘기하면, 하나의 확률분포를 다른 확률분포로 옮기는데 필요한 비용을 계산하는 문제입니다.
기존의 NetVLAD는 가장 어울리는 Cluster에 feature를 할당했으면 됐습니다. 하지만, 최적 수송을 적용한다면 기존처럼 할당이 되지 않습니다. 예를들어, 모든 feature가 1번 cluster에 할당되고 싶어한다면 모든 feature의 score가 낮아집니다. 그렇기에 1번 cluster에 애매하게 할당되려던 feature들은 다른 cluster를 택하게 유도됩니다.
Optimal Assignment
기존의 NetVLAD가 assignment하는 방식은 per-row softmax를 S에 적용합니다. 이는 각 cluster에 대해 feature가 어디에 속할지에 대한 분포를 나타냅니다. 하지만 이는 feature가 cluster를 보는 관점만 표현하지, 반대로 cluster가 feature를 보는 관점을 나타내지 못합니다. 그렇기에 저자들은 optimal transport(Sinkhorn Algorithm)를 적용하여 feature들이 cluster나 dustbin에 잘 분포되게 만들었습니다.
Sinkhorn의 과정을 더 자세히 알아봅시다.
먼저 score matrix S를 exp로 표현하여 값을 더 극단화 시킵니다.
그 다음 Row의 합이 1이 되도록 정규화합니다.
그리고 Column 방향의 합이 1이 되도록 정규화합니다.
이러한 Row-Column 정규화를 N번 반복해준 이후에 dustbin column을 버리면 끝입니다.
Aggregation
이 최종적으로 descriptor를 만들기 위한 추가적인 기법들을 소개합니다.
Dimensionality Reduction
DINOv2를 타고 나온 patch token의 채널이 768이고 Centroid가 20개라면, 20×768=15,380차원의 descriptor가 됩니다. 그렇기에 two layer FC layer를 통해, 차원을 축소시킵니다.
Aggregation
NetVLAD는 잔차를 사용하는 반면, 저자는 확률과 Cluster(위에서 차원 축소된)를 곱하여서 aggregation합니다.
각 cluster에 할당된 Probability를 P, 차원축소된 Cluster를 f라 하면, 아래 수식처럼 계산됩니다.
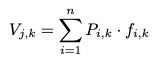
Global Token
global information은 local features만으로 얻어낼 수 없습니다. 그래서 scene descriptor g를 따로 계산합니다. 이는 CLS token을 MLP를 태워서 얻습니다. 그리고 최종적으로 aggregation된 V와 concat한 후 L2-intranorm, L2-norm을 적용하여 최종 global descriptor를 얻습니다.
Experiments
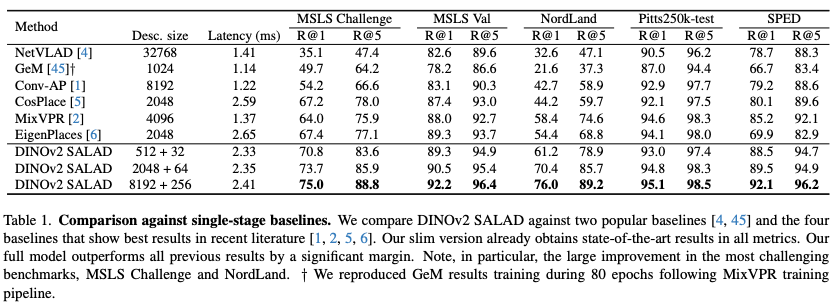
위에서 얘기했던 기존 aggregation 방법론(NetVLAD, GeM)과 최근 좋은 성능을 보이고 있는 baseline(Conv-AP, CosPlace, MixVPR, EigenPlaces)과 비교하고 있습니다.
DINOv2 SALAD는 가장 적은 descriptor size인 512+32로도 다른 방법론의 성능을 능가했습니다. 특히 MSLS Challenge와 NordLand에서 큰 폭의 성능 항샹을 얻었습니다.
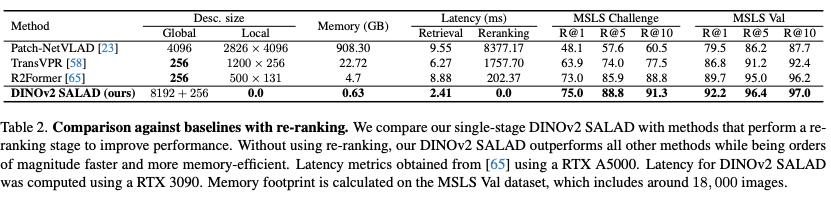
Table 2.는 연산이 추가적으로 필요하지만 높은 성능을 보이는 reranking 방법론들과 비교하였습니다. SALAD는 reranking을 진행하지 않기에 메모리, 속도 모두에서 압도적입니다. 게다가 성능 역시 MSLS Chanllenge/Val에서 reranking 방법론보다 우세하였습니다. 추가적으로 SALAD는 local feature에 의존적이기에 추가적인 reranking 방법론을 적용한다면 횔씬 성능이 증가할 것이라는 저자의 기대가 있었습니다.
Ablation Studies
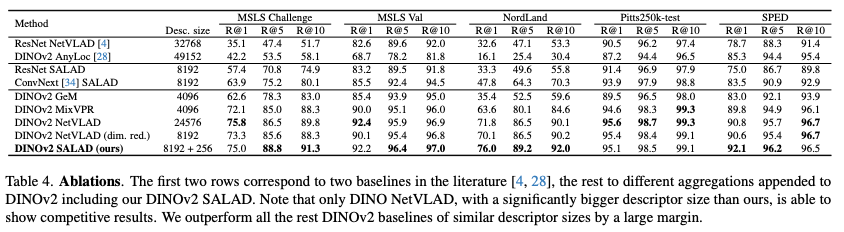
Table 4.는 단순히 DINOv2를 썼기 때문에 성능이 오른게 아닌 SALAD의 우월성을 보여줍니다. DINOv2와 다른 aggregation 방법을 적용한 것들과 비교한 것을 확인할 수 있습니다. 그럼에도 대부분의 지표에서 SALAD가 가장 우세합니다. 특정 지표에서는 DINOv2 NetVLAD가 SALAD를 이기는 것을 볼 수 있지만, NetVLAD의 desc. size가 SALAD보다 3배 정도 많습니다.
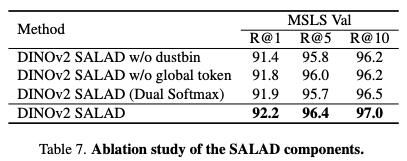
Table 7.은 dustbin의 효과, global token을 추가 여부에 따른 효과. 그리고 optimal transport가 아닌 LoFTR이나 Gluestick에서 쓰이는 dual-softmax를 사용해 보았을때의 성능 비교입니다.
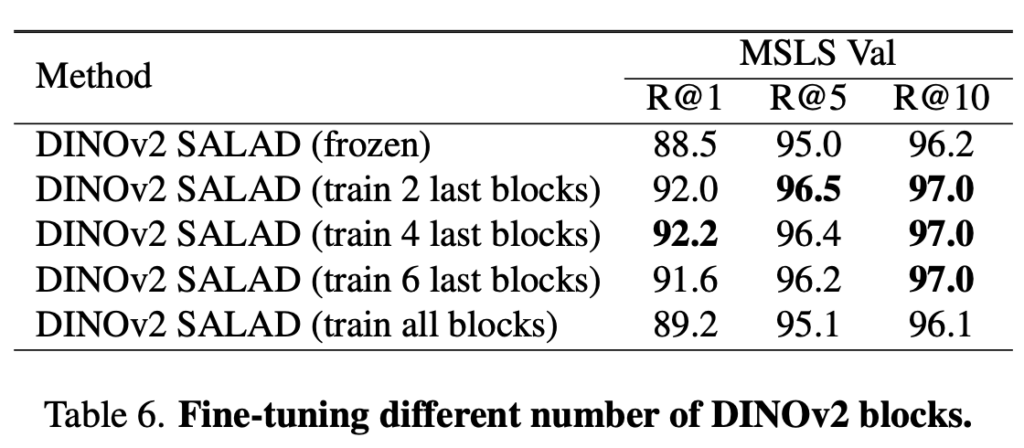
Table 6.은 DINOv2를 finetuning했을때의 성능차이를 ablation하고 있습니다. 결과적으로 마지막 2개나 4개의 layer를 풀고 학습하는게 가장 좋은 성능을 보였습니다.
Visualization

Figure 3.는 model이 dustbin으로 포함시키지 않은 것들에 대한 heatmap입니다. 이를 통해, dustbin이 하늘과 도로 같은 불필요한 patch를 효과적으로 무시하게 만든 것을 확인할 수 있습니다.


안녕하세요 정우님 리뷰 감사합니다.
Table 4를 보면서 SALAD가 단순히 DINOv2를 써서 좋아진 것이 아니라 aggregation 자체로도 강점이 있다는 점은 이해가 되었는데, 그래도 백본에 대한 파인튜닝이 함께 들어간 설정이다보니 실제 성능 향상에서 SALAD와 DINOv2 파인튜닝의 기여를 각각 어느 정도로 해석해야 할지 궁금합니다!
안녕하세요 찬미님 좋은 질문 감사합니다.
ablation에서 그 부분이 누락되어서 table 6.를 추가하였습니다.
보시면 DINOv2 finetuning이 상당한 성능향상을 보이는 것을 확인할 수 있습니다.
Table 4.의 DINOv2 GeM과 DINOv2 SALAD의 차이가 더 큰 폭이기에
SALAD aggregation 방법론이 성능향상에 더 큰 영향을 미쳤습니다.
감사합니다.
안녕하세요, 정우님. 좋은 리뷰 감사합니다.
읽다 보니 제가 이번 주에 리뷰했던 Semantic VLA와도 어느 정도 맞닿아 있는 느낌이 들어서 흥미롭게 봤습니다. 결국 place를 잘 구분하려면 공간에 대한 의미 있는 정보를 잘 잡아내는 것이 중요하다는 점에서 비슷한 방향성을 가진 것 같다고 느꼈습니다.
그런데 시각화 결과를 보면 건물 같은 구조물에 attention이 많이 가는 것처럼 보이더라고요. 이런 건물 정보도 자율주행 관점에서는 충분히 중요한 단서가 될 수 있다고 봐야 할지 궁금합니다. 예를 들어 단순히 place recognition을 넘어서, 실제 주행 환경을 이해하는 데에도 유의미한 semantic cue로 작용할 수 있는지 여쭤보고 싶습니다.
리뷰 감사합니다.
안녕하세요 기현님 좋은 질문 감사합니다.
place를 잘 구분하기 위해서는 정적이면서 특징적인 물체를 잘 잡아낼 수 있어야합니다.
예를 들어, 사람이나 자동차는 시간이 지나면 변화하는 물체이므로 무시하고
상대적으로 오랜시간 정적인 건물 같은 구조물이 위치 인식에서는 중요합니다.
특징적이고 구분력 있는 대상을 찾아내야하는 VPR과 달리
자율주행 및 주행환경에서는 보행자, 자동차 등이 중요하기에
정적인 물체에 집중하는 것은 오히려 좋지 못한 방향이라 생각합니다.
하지만 위 SALAD의 방식은 결국 loss를 통해 무엇을 dustbin에 버릴지 결정하므로,
주행환경에 맞는 loss를 흘린다면 해당 방법론을 자율주행에도 적용될 수 있어 보입니다.
감사합니다.