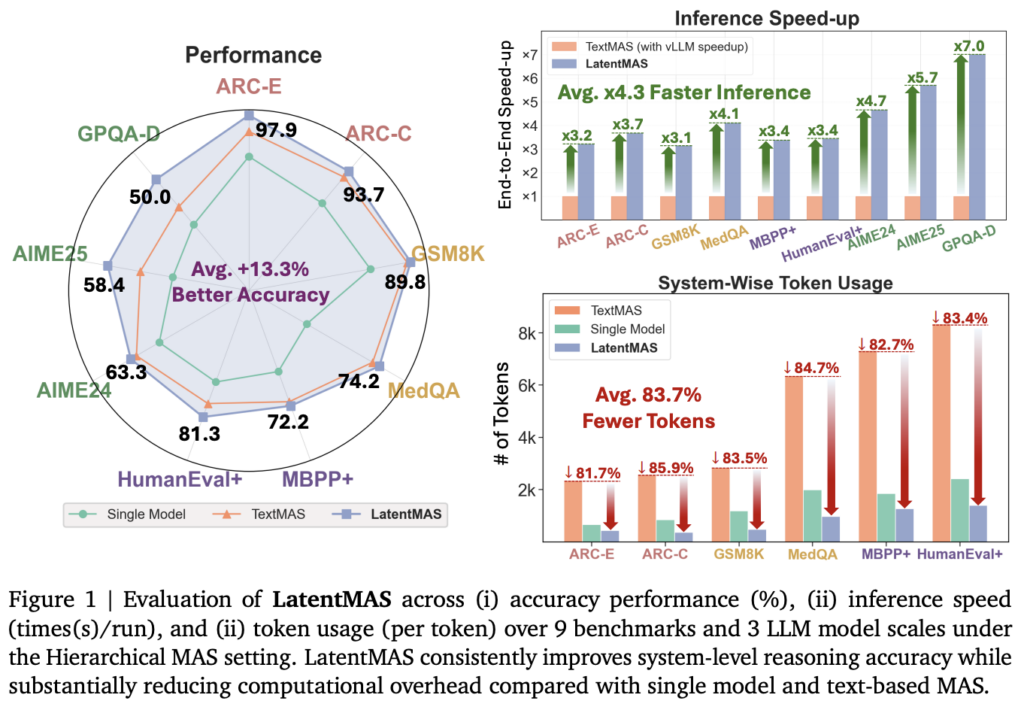
멀티 에이전트간 빠르고 효율적인 소통 방법(MAS, multi-agent systems)을 제안한 연구를 소개하겠습니다. 본 연구는 에이전트간에 latent space에서 소통하였을때 효율 증가를 보이고 있습니다. Figure1에서 보면 제안한 latentMAS가 비교 방법론(Single model, TextMAS) 대비 성능이 좋을 뿐 만 아니라 token 사용률, 추론 속도 측면에서 개선이 상당했음을 보이며 해당 방법의 우수성을 증명하고 있습니다.
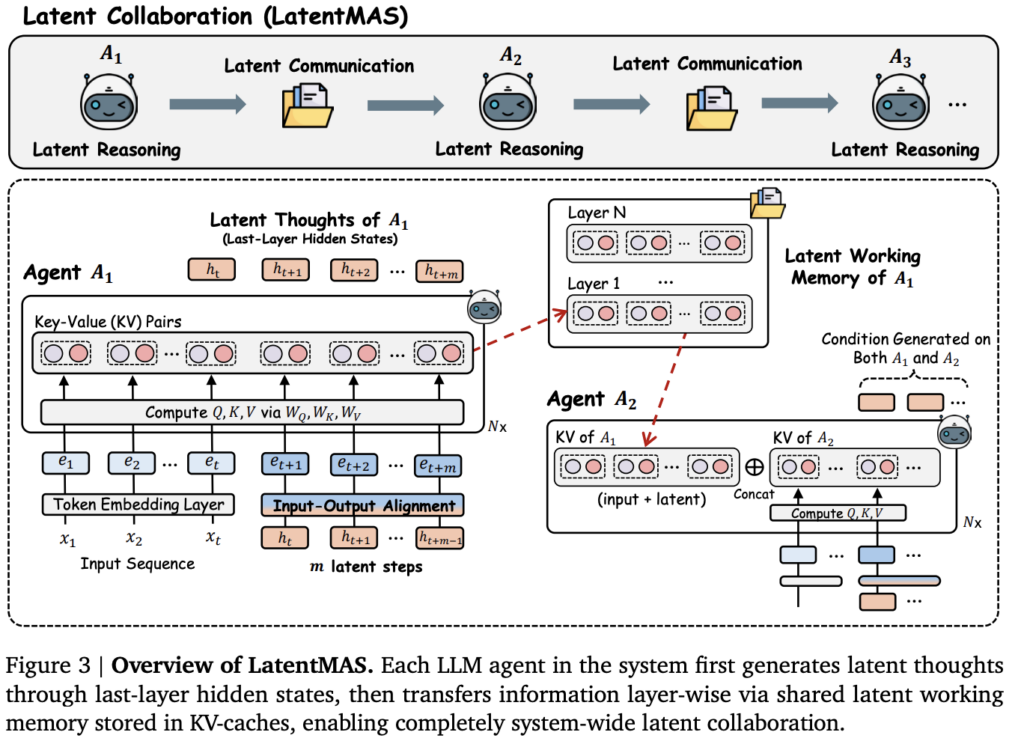
논문은 보다 효율적인 협업 시스템 구축을 위해 기존에 텍스트를 통해 소통하던 방법을 kv-cache를 활용해 latent space 정보로 전달합니다. 즉 hidden state 출력값 자체를 다음 input으로 활용하는 것입니다. Figure3에서는 hidden state(h) 값을 두가지로 사용하고 있는데, 그 중 에이전트 간 소통에 해당하는 부분은 특정 에이전트(A_{1})의 레이어 별 hidden state 결과로 transformer 연산 중 key와 value를 latent working memory에 저장한 후 다음 에이전트(A_{2})가 이용하는 부분입니다. 이용 방법은 다음 에이전트(A_{2})가 메모리의 값과 직접 연산한 값을 단순 이어붙이는(concat) 작업을 수행하며 해당 에이전트가 생성하는 결과가 두 에이전트(A_{2}, A_{1})를 모두 활용하게 합니다.
그 외에도 에이전트 내부에서 맥락적 이해도를 높인 결과 생성을 위하여 hidden state를 입력에 다시한번 사용하는 전략을 취합니다. 논문에서는 에이전트의 내부적 소통이라 할 수 있는 CoT 베이스라인을 기준으로 하였습니다. figure3을 기준으로 t 시점까지 쿼리의 임베딩이라면, t+1~t+m 까지는 생각(thinking) 단계이고, 이후 마지막 토큰이 최종 응답에 해당합니다. 기존의 경우 이전 시점까지의 쿼리 토큰이 embeding까지 마친 후 다시 입력으로 사용되곤 하지만 본 아키텍처에서는 latent space의 값에 정보를 단순 alignment만 적용 후 직접 사용하여 불필요한 디코딩 과정을 없앴습니다. 기존 LLM에서 CoT를 수행하려면 hidden state를 vocabulary logits 으로 변환하고 선별된 토큰으로 다시 임베딩에 입력하지만 LatentMAS에서는 hidden state의 디멘전을 유지한 선형 변환(W_{a})을 사용하며 학습없이 추론하는 편의성을 유지하기 위해, 학습 파라미터가 아닌 아래의 정의대로 파라미터를 설정합니다.
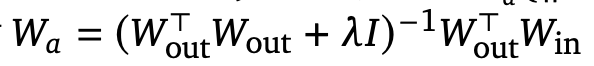
변환의 목적은 hidden state를 다음 입력처럼 사용하고 싶으나, 이는 기존 LLM의 입력과 분포가 다르다는 문제를 해결하기 위함입니다. 기존 입력에서는 hidden state 값을 W_out로 vocab기반으로 token으로 변환한 후, 이를 다시 임베딩 파라미터인 W_in으로 변환하여 사용했습니다. 이러한 컨셉을 직관적으로 차용하여 W_out과 W_in을 행렬곱한 파라미터 W_a를 직접 hidden state에 곱하는 선형변환으로 임베딩(e)를 생성하게 됩니다. (e=hW_{a})
즉, 제안한 LatentMAS 아키텍처는 CoT 과정이나 에이전트 간 소통에서 텍스트를 제외하고 latent space로 이를 대체하여 연산 효율성을 높였습니다. 실제로 연산량을 계산했을 때, LatentMAS는 O((d_{h}^{2} m + d_{h} m^{2} + d_{m} t m)L)이고 디코딩 과정이 발생하는 TextMAS의 경우 O\left(\left(d_{h}^{3}\frac{m}{\log |V|} + d_{h}^{3}\frac{m^{2}}{\log^{2}|V|} + d_{h}^{2} t \frac{m}{\log |V|}\right)L + d_{h}^{2}|V|\frac{m}{\log |V|}\right)로 추가적인 term이 발생하며 연산량이 더 큼을 수식으로 보였습니다.
논문에서는 효율성에 대해 이론적 증명 뿐 만아니라 실험 결과를 보였습니다. 실험에는 수학/과학적 추론에 관한 데이터셋(GSM8K, AIME24, AIME25, GPQA-Diamond, MedQA)와 상식 추론(ARC-Easy,ARC-Challenge), 코드 생성(MBPP-plus, HumanEval-Plus)에 관한 총 9개의 벤치마크에 대한 실험을 수행했습니다. 모델로는 Qwen3족(4B, 8B, 14B)를 활용했으며 single agent와 text 기반의 소통 시스템인 textMAS와 비교한 성능을 리포팅했습니다. 또한 멀티 에이전트 소통의 방식을 planner, critic, refiner, solver와 같은 역할을 기반으로 순차적인 소통방식을 활용하는 구조(Sequential MAS)와, 특정 도메인 전문가 에이전트가 추론을 병렬적으로 수행하는 Hierarchical MAS 구조로 나누어 베이스라인으로 하였습니다. 이러한 에이전트의 역할은 프롬프트를 통해 구현되었으며 실험 결과는 아래와 같습니다. (표1이 sequential mas, 표2가 hierachical mas)
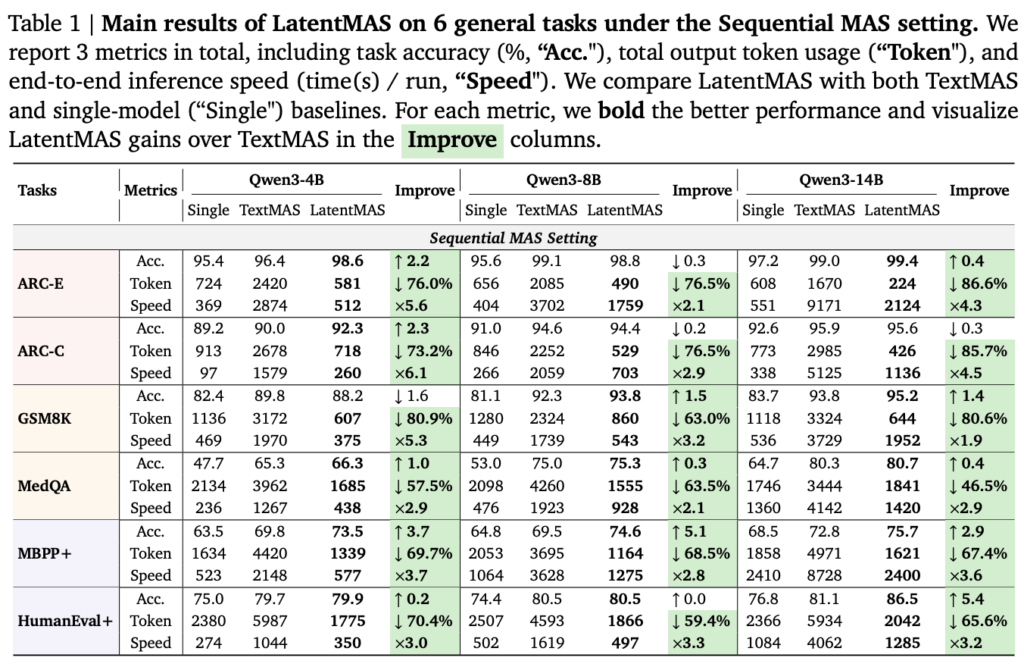
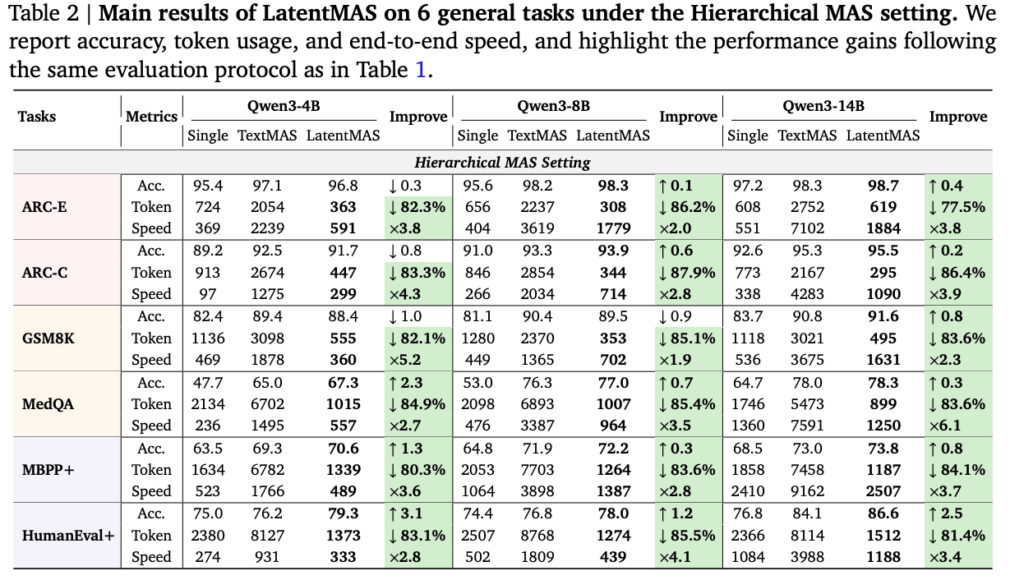
위의 결과에서 각 세팅에 대해 정확도, 충력 토큰수, 추론 시간 측면에서 비교하고 있습니다. 비교 결과 대부분의 방법이 성능을 유지하거나 개선하였으며 토큰수와 연산량 측면에서는 모두 큰 개선을 보였다는 것이 특징입니다. 또한 single agent대비 multi agent가 성능 개선이 있음을 통해 소통 구조가 효과적임도 같이 확인할 수 있는 결과입니다. 이러한 결과는 보다 복잡한 추론을 요구하는 벤치마크에서도 동일한 경향을 보임을 Table3을 통해 확인할 수 있습니다.

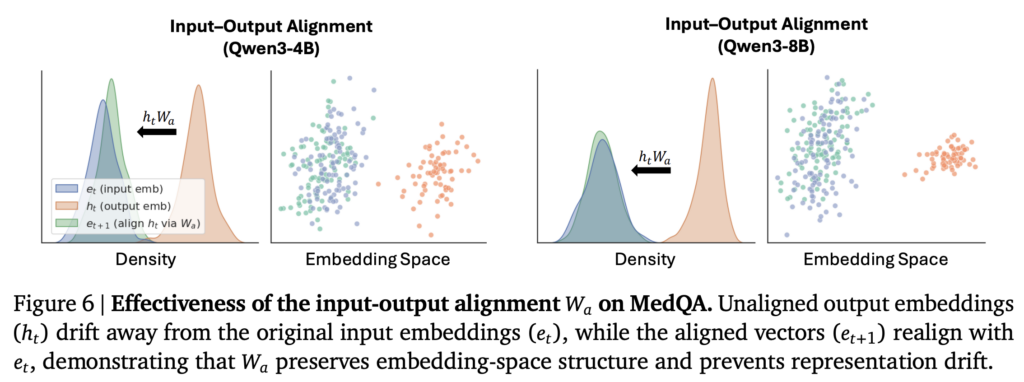
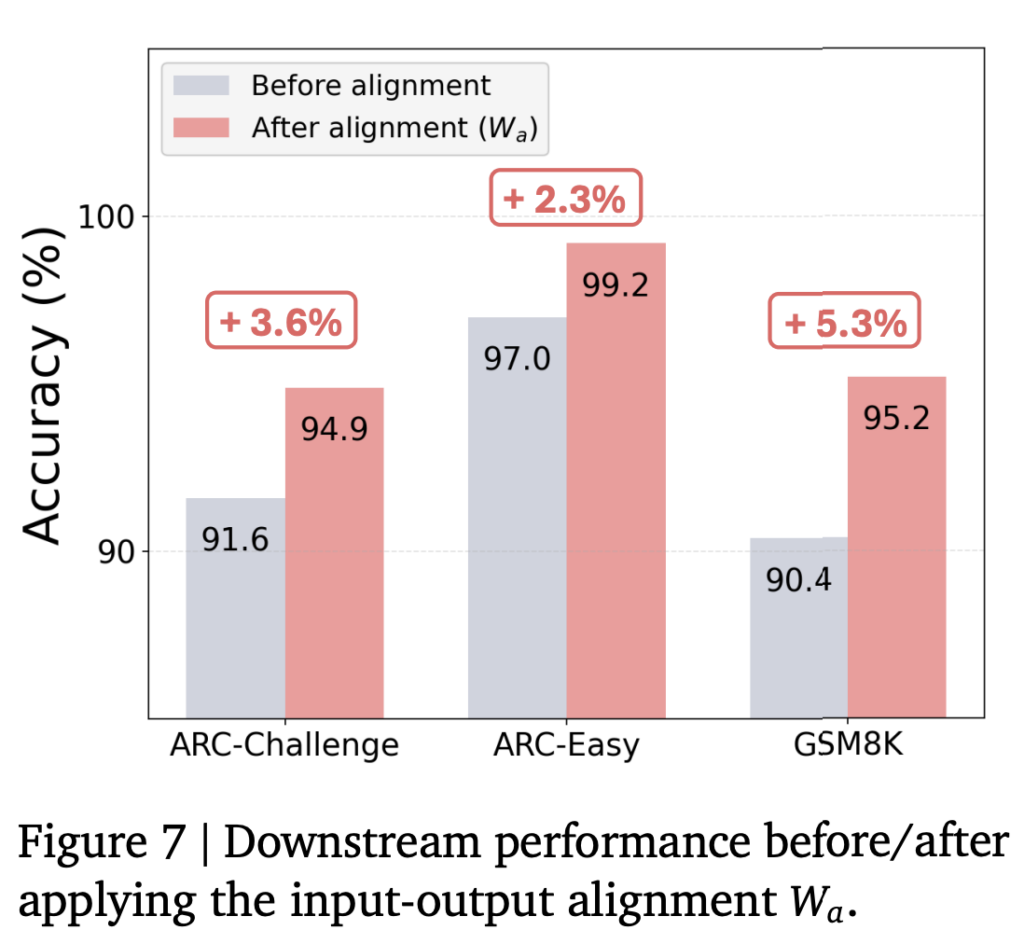
위의 실험을 통해 제안한 latent 기반의 소통구조의 효율성을 확인했습니다. 실제로 성능 보존 및 개선과 효율성 증대를 확인할 수 있었는데요, 두번째로 제시한 에이전트 내 소통 효율성 개선을 위한 hidden space 정보 활용과 alignment의 효과를 확인해보겠습니다. 아래의 figure6은 해당 연산 (W_a)이 실제로 정렬 효과가 있었음을 정성적으로 보여주는 자료입니다. hidden space의 출력값 분포(주황색)가 제안하는 선형연산을 수행(녹색)했을 때 기존의 쿼리 입력에 대한 텍스트 임베딩의 분포(파란색)과 유사한 분포로 옮겨가며 성공적으로 alinment를 수행했음을 확인할 수 있습니다. 이 뿐만 아니라 하단의 Figure7을 통해 제안한 얼라인먼트를 수행했을 때 성능 개선이 있었음을 보이며 본 구조의 효과를 다시한번 확인할 수 있었습니다.
마치며 본 논문에서는 latent space를 활용한 소통구조의 효율성과 성능 개선 효과를 정성/정량적 결과와 big O등의 이론적 분석을 제시하고 있습니다. 논문을 통해 latent space 의 임베딩값의 유용성을 다시한 번 검증할 수 있었습니다. 이상으로 리뷰를 마치겠습니다. 감사합니다.
안녕하세요 유진님 좋은 리뷰 감사합니다.
이 방법의 이점이 긴 수학/과학 추론이나 코드 생성처럼 reasoning 과정이 긴 문제에서 특히 더 크게 나타나는지가 궁금합니다. 아니면 비교적 짧은 추론 문제에서도 일관되게 비슷한 성능을 보이는지도 궁금합니다. LatentMAS의 장점이 단순히 효율 개선을 넘어서 좀더 긴 reasoning 을 요구할수록 더 커지는 구조적 이점으로 볼 수 있는지 궁금합니다. 감사합니다.
안녕하세요 우현님 댓글 감사합니다.
우선 긴 reasoning에 대해 직접적 분석을 다룬것은 확인하지 못했습니다.
다만 Table3에 리포팅된 AIME, GPQA 데이터셋이 긴 추론이 필요한 벤치마크라고 합니다. 결과를 통해 제안 방법이 긴 문제에서도 일관되게 좋은 성능을 보임을 알 수 있습니다.
latent space에서의 정보공유 역시 손실이 없다면 decoding 과정에서 생길 수 있는 노이즈가 누적되지 않기 때문에 제안하는 방법이 긴 reasoining에도 구조적 이점을 갖는다 볼 수 있을 것 같습니다.
감사합니다.
안녕하세요 유진님 리뷰 잘 읽었습니다!
LatentMAS는 효율성 측면에서 장점이 확실해 보이는데 TextMAS처럼 중간 reasoning이 자연어로 드러나지 않는다는 점은 trade-off로 느껴졌습니다.
latent memory 안의 정보가 agent role별로 실제로 다르게 형성되는지에 대한 분석도 있었는지 궁금합니다!