안녕하세요, 박성준 연구원입니다. 최근 CVPR 2026에 accept된 논문들을 읽어보는 중에 흥미로운 주제를 발견하여 리뷰하고자합니다. 당분간은 CVPR 2026 논문들을 읽고 소개하려합니다.
Before Review
리뷰할 논문이 다루는 task가 좀 생소한 task이기에 task를 먼저 간략하게 소개하겠습니다. 본 논문은 Dataset Distillation은 대규모 학습 데이터셋의 핵심 정보를 소규모 합성 데이터셋으로 압축하는 기술입니다. 단순히 원본 데이터셋에서 특정 샘플을 subsampling하는 것과는 다르게 synthetic 데이터를 생성하여 정보의 밀도를 극대화하는 task입니다. 당연히 중요한 점은 적은 데이터로 대규모 데이터셋에서의 성능과 비슷한 혹은 더 좋은 성능을 낼 수 있게 하는 것입니다.
압축하여 생성되는 데이터셋의 크기는 IPC(Image Per Class)로 표현됩니다. IPC가 100이라면, 클래스당 100장의 이미지를 활용하는 것으로 이미지넷 기준 100,000장으로 128만장을 압축하는 것을 의미합니다. CIFAR와 같은 비교적 규모가 작은 데이터셋에서의 Dataset Distillation은 꽤나 좋은 성능을 보이고 있지만, ImageNet과 같은 대규모 데이터셋에서는 아직 발전이 필요한 상황입니다. 논문이 다루는 압축 방식은 생성형 모델 기반으로 사전 학습된 생성형 모델의 prior를 활용하여 synthetic dataset을 생성하는 방법으로 생성 모델이 자연 이미지의 분포를 학습하여 알고 있기 때문에 현실적이면서 고해상도인 이미지를 생성할 수 있습니다.
Introduction
기존 Diffusion 기반의 Dataset Distillation 방법론들은 학습 데이터셋내 클래스의 대표성과 다양성을 위해서 Diffusion 모델을 원래 데이터셋에 fine-tuning을 하고, latent space에서 데이터의 mode(클래스 샘플 그룹)를 발견하고 mode별로 샘플을 생성합니다. 이때 기존 방법론들이 많이 사용하는 방법은 IGD(Influence-Guided Diffusion)으로 전체 데이터셋의 학습 gradient와 일치하도록 생성을 가이드합니다. 저자는 이 기존 방법론들이 redundancy(샘플 간 정보 중복)이라는 근본적인 한계를 가지고 있다고 지적합니다.

Figure 2.는 DiT, IGD(기존 방법론)과 저자가 제안하는 방법론의 교차 정확도를 비교합니다. 히트맵을 통해서 확인할 수 있듯이 기존 방법론들의 교차 정확도가 높다는 것은 하나의 부분집합만을 보고도 나머지 부분집합의 거의 모든 샘플을 맞출 수 있다는 것을 의미합니다. 이것은 각각의 부분집합들이 사실상 동일한 정보를 담고 있음을 의미합니다. 이런 중복이 저자는 모델의 학습 방법때문에 생긴다고 지적합니다. 초기에는 coarse feature를 잡기 위한 강한 gradient가 필요하고 후반에는 fine-grained detail을 잡기 위해서 약한 gradient가 필요하지만 기존에는 하나의 샘플이 모든 단계를 동시에 만족시킬 수는 없기 때문에 평균적인 gradient에 맞췄고, 어떤 단계에서도 최적이 아닌 중간 정도의 gradient를 가진 유사한 샘플들만 만들어지게 되어버렸습니다. 저자는 이러한 문제를 해결하기 위해서 synthetic 데이터를 incrementally하게 구축하는 방법을 제안합니다. 즉, 단계적으로 합성 데이터셋을 구축하면서 단계마다 어떤것을 배워야하는지(learnability)에 초첨을 맞추는 방법인 LGD(Learnability-Guided Diffusion)을 제안합니다.
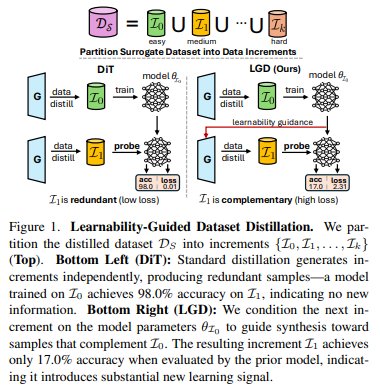
Figure 1.은 저자가 제안하는 LGD를 보여줍니다. 왼쪽 아래의 DiT(기존 방법론)은 첫번째로 increment 로 학습한 모델이 두번째 increment [latex]I_1에서 유사도 98을 보이는 것을 확인할 수 있습니다. 반면 저자가 제안하는 오른쪽 아래의 LGD는 유사도가 17입니다. 저자는 이러한 경향성이 저자가 제안하는 실질적인 새로운 학습을 했다는 것을 보인다고 주장합니다.
이에 따른 저자의 Contribution은 다음과 같습니다.
- 첫번째는 Learnability-driven Incremental Framework를 제안합니다. 합성 데이터셋을 한번에 생성하는 것이 아닌 incremental 방식을 도입하여 단계적으로 합성 이미지를 생성합니다.
- 두번째는 Learnability-Guided Diffusion(LGD) sampling을 제안합니다. 현재 모델의 loss와 reference 모델의 loss의 차이를 통해 결정되는 learnability score를 활용하여 모델의 sampling 과정에 guidance로 통합합니다. 이 LGD sampling을 통해 기존 데이터를 보완하는 샘플을 생성할 수 있도록 guide를 줍니다.
- 세번째는 Redundancy Anlaysis를 제안합니다. Incremental formulation을 활용하여 distillationi 방법들의 정보 중복을 정량적으로 진단하는 분석 방법을 제안하여 distilled dataset의 중복성을 확인할 수 있습니다.
- 네번째는 Improved Sample Efficiency입니다. 저자가 제안하는 방법론을 통해 중복을 줄이면서도 기존 SOTA 대비 높은 성능을 달성합니다.
Method
Incremental Distillation Formulation
저자가 제안하는 LGD의 핵심 아이디어는 최종 데이터셋을 K번의 단계를 통해 구축하는 것입니다.
우선 Incremental learning은 각각의 increment를 최적화하는 것이 중요합니다. 각각의 increment 최적화 목표는 다음과 같습니다.
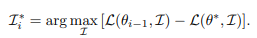
여기서 \theta는 모델을 의미하고 i는 순서를 의미합니다. 첫번째 항 \mathcal{L}(\theta_{i-1}, \mathcal{I})은 현재 모델이 해당 샘플에서 높은 loss를 보이는지를 확인합니다. 여기서 loss가 높다는 것은 모델이 배울 것이 남아있다는 것을 간접적으로 보여준다고 해석할 수 있습니다. 두번째 항은 \mathcal{L}(\theta^*, \mathcal{I})으로 전체 데이터로 학습한 reference 모델도 높은 loss를 보이는지를 확인하는 항입니다. 이 loss가 높다면 너무 어렵거나 out-of-distribution인지를 확인합니다. 측, 해당 최적화 목표는 현재 모델에게는 어려운 동시에 reference 모델에게는 쉬운 샘플을 찾을 수 있도록 최적화합니다. reference 항이 없으면 모델이 라벨과는 무관한 degenerate 샘플을 생성할 수 있기 때문에 regularizer의 역할을 한다고합니다.
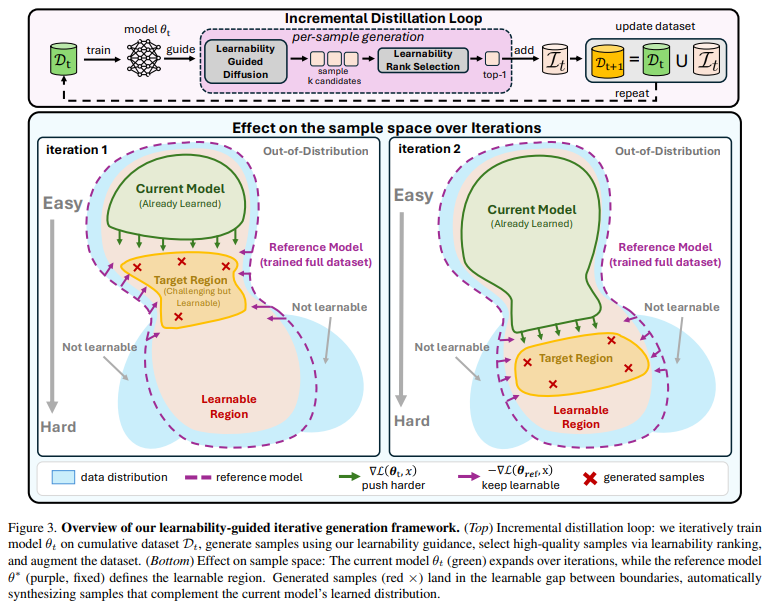
Figure 3는 방금 설명한 과정에 시각적으로 드러납니다. 초록색 영역인 모델이 학습한 영역이 점점 커지면서 빨간색의 learnable region을 초록색이 점점 잡아먹으면서 모델의 지식이 확장됩니다.
Learnability-Guided Diffusion Sampling
incremental 목적함수를 diffusion의 샘플링 과정에서 guide를 주는 것이 중요하기에 저자는 learnability score를 정의합니다.
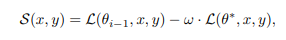
여기서 \omega는 정규화 강도입니다. 위에서 설명한 최적화 목표에서 정규화 강도가 추가된 형태입니다. 이 score의 gradient를 diffusion의 noise prediction를 더해 learnability guidance를 구성합니다.
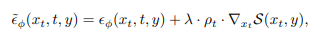
\lambda는 guidance의 강도이고 \rho_t = \frac{\sqrt{1-\bar{\alpha}_t} \cdot \|\epsilon_\phi(x_t, t, y)\|}{\|\nabla_{x_t} \mathcal{S}(x_t, y)\|}는 timestep-dependent scaling factor입니다. 이 \rho는 noise level에 따라 gradient의 크기가 달라지기 때문에 정규화하여 guidance가 일관되게 작동하도록 합니다. Guidance는 50번의 step 중에 10~45번째 step에서 적용됩니다. 초기에는 순수 noise에 가까워 guidance가 거의 의미가 없고 마지막에는 이미지가 거의 완성이 되어 guidance가 오히려 품질을 저하시키기 때문입니다.
Learnability Sample Selection
Guidance가 trajectory(사전적으로 궤적이라는 의미인데 여기서는 diffusion의 각 스텝의 방향성을 의미합니다)를 유도하더라도 샘플링은 확률적으로 편차가 있을 수 있습니다. 이를 보완하기 위해서 저자는 각 샘플마다 먼저 k개의 후보를 생성하고 learnability score가 가장 높은 1개를 선택합니다. 선택된 샘플은 memory buffer에 추가되고 이후 guidance에 영향을 줍니다. 이러한 greedy한 순차 선택 방식을 사용함으로 나중에 선택되는 샘플은 앞서 선택된 모든 샘플에서의 다양성이 보장됩니다.
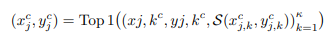
Experiments
평가는 3가지 데이터셋에서 수행되고 256×256 해상도에서 수행됩니다. ImageNette, ImageWoof, ImageNet-1k에서 수행되는데, Nette는 이미지넷에서 쉬운 10개의 클래스, Woof는 이미지넷에서 어려운 10개의 클래스로 구성된 데이터셋입니다. IPC는 50, 100으로 설정되어 50step으로 sampling됩니다.
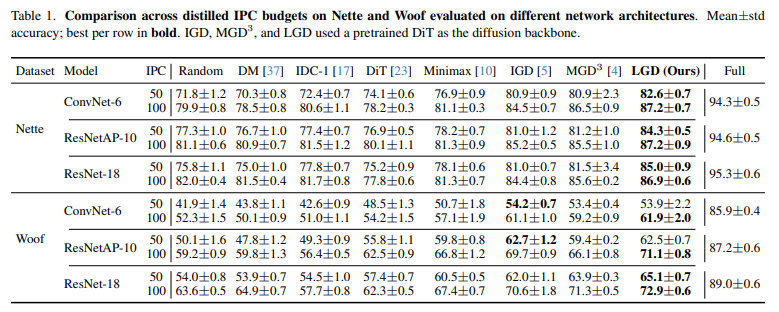
Table 1.은 ImageNette와 ImageWoof에서 저자가 제안하는 LGD는 전반적으로 기존 방법론을 능가하는 성능을 보입니다.

Table 2.는 ImageNet에서의 성능을 보여줍니다. Table 1.과 마찬가지로 저자가 제안하는 LGD가 높은 성능을 보이는 것을 확인할 수 있습니다.
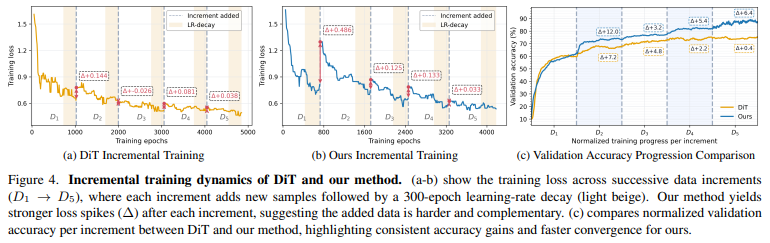
Figure 4.는 중복이 줄어들게되면 학습에 어떤 효과가 있는지를 보여주는 그림입니다. loss spike는 새로운 데이터를 추가했을때 training loss가 얼마나 튀는지를 확인하는 지표입니다. (a)와 (b)를 확인하시면 DiT는 평균 0.06, LGD는 평균 0.2입니다. LGD가 약 3배 정도 높은데 이는 실질적으로 새로운 학습 신호가 투입되고 있음을 의미합니다. (c)는 정확도 향상폭입니다. DiT는 increment를 추가할수록 향상폭이 줄어드는 반면 LGD는 계속해서 성능이 향상하는 것을 확인할 수 있습니다. 이것 또한 저자가 제안하는 LGD가 실제로 학습에 유의미한 도움이 된다는 것을 의미합니다.
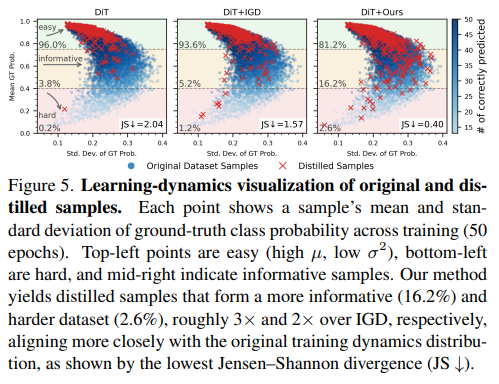
Figure 5.는 원본 샘플과 압축된 샘플의 분포를 보여줍니다. DiT는 원본 데이터셋의 분포를 따라가지 못하고 편향된 모습을 보여줍니다. 특히 난이도가 어려운 샘플들을 거의 포함하지 못하고 있습니다. 반면, 저자가 제안하는 방법은 원본 데이터셋의 분포를 어느정도 잘 반영하고 있는 것을 확인할 수 있습니다.
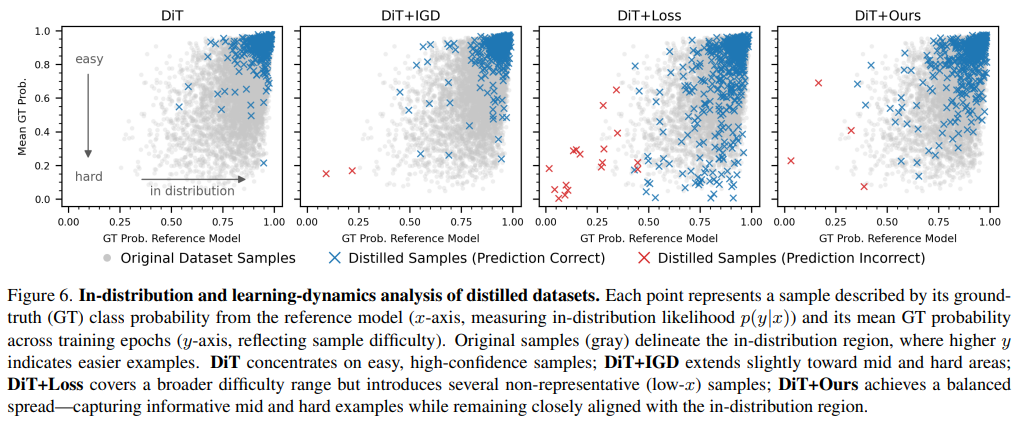
Figure 6.은 reference 모델의 정규화를 하는 것의 중요성을 보여줍니다. 정규화 없이 loss만 사용하면 난이도의 범위가 넓어지지만 out-of-distribution의 수가 많아지는 것을 확인할 수 있습니다.

마지막으로 정성적 결과입니다. DiT는 비슷한 고딕 양식의 건물이 반복적으로 생성되고 LGD는 조금 더 나아졌지만 여전히 비슷한 고딕 양식을 반복하고 있습니다. 저자가 제안하는 LGD는 초기에는 단순한 외곽부터 시작하여 뒤로 갈수록 복잡한 외형의 양식을 보여주며 난이도가 쉬운 데이터부터 어려운 데이터까지 자연스럽게 진행되는 것을 확인할 수 있습니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰감사합니다.
제목을 보고는 뭔가 양질의 dataset 에서 좋은 정보들만 모아서 더 좋은 데이터셋을 만드는건가? 하는 생각이 들었는데 읽어보니 그거는 아니였네요 ..ㅎㅎ 우선 제가 이해하기로는 규모가 큰 데이터셋 에서 예를들어 5장의 데이터셋의 특징들을 1장의 이미지에 다 담길수있도록 압축해주는 방법론 같은데 맞나요 ?? 그럼 이를 통해서 연산량도 많이 줄면서 모델의 이해도를 줄일 수 있겠네요..그럼 이런 데이터세 distillation 방법론을 통해 비디오에 접목해보실 계획이신가요 ?? 궁금함다!
감사합니다~
안녕하세요 우진님 좋은 댓글 감사합니다.
Dataset Distillation의 모티브는 우진님이 말씀해주신 것처럼 대규모 데이터셋에서 좋은 정보들만 모아 규모가 작은 데이터셋으로 학습했을 때에도 대규모 데이터셋으로 학습했을 때와 근사한 학습이 가능하도록하는 것입니다. 본 논문은 위 task를 수행하기 위해 생성형 모델을 통해 대규모 데이터셋의 좋은 정보들을 압축한 데이터를 생성하는 방법론입니다. 말씀해주신 것처럼 작은 규모의 데이터셋을 활용하니 연산량이 줄면서 모델의 이해도를 올릴 수 있습니다. Dataset Distillation을 비디오에 접목시키고 싶긴한데 아직 어떻게 활용할지는 잘 모르겠습니다. 최근에 비디오를 효율적으로 이해하는 연구를 하고싶다는 생각이 들어 논문들을 서베이하는 와중에 생성형 모델을 활용한 효율성 연구들이 최근에 활발하게 연구되는 것 같아 읽어보게 되었습니다. 어떻게 비디오에 접목시킬지는 아직 잘 모르겠습니다..
리뷰 읽고 댓글 남겨주셔서 감사합니다.
안녕하세요 성준님 좋은 리뷰감사합니다.
Incremental Distillation Formulation 부분에 질문이 있습니다. 식을 보면 현재 모델에게는 어려운 샘플인 동시에 reference 모델에게는 쉬운 샘플이기 때문에 추출된 샘플들에는 어려운 샘플이 없을것이라 생각했습니다.
헌데 fig 5를 보면 기존 방법론들보다도 어려운 샘플의 비율이 많던데, 혹시 추가적으로 어려운 샘플을 추가해주는 부분이 있나요?
감사합니다.
안녕하세요. 정의철 연구원님 좋은 댓글 감사합니다.
추가적으로 어려운 샘플을 추가하는 부분은 Learnability Sample Selection이 나중에 선택되는 샘플이 앞서 선택된 모든 샘플과 다른 샘플을 샘플링하게 됩니다. 이로인해서 다양성이 보장되고 다양한 난이도의 샘플을 추가하게됩니다. 이 과정을 통해서 난이도가 어려운 샘플들도 포함됩니다.
감사합니다.