오늘도 CLIP 기반의 Video-Text Retrieval 에 대한 리뷰입니다. 학습 시 정보를 잊는다는 것을 극복하고자 “외부 저장소”라는걸 추가했다는 것이 제법 재밌는 생각인 것 같습니다.

- Conference: ECCV 2024
- Authors: Xianwei Zhuang, Hongxiang Li, Xuxin Cheng, Zhihong Zhu, Yuxin Xie, Yuexian Zou
- Affiliation: Peking University
- Title: KDProR: A Knowledge-Decoupling Probabilistic Framework for Video-Text Retrieval
1. Introduction
Video-Text Retrieval(VTR)은 주어진 텍스트(or 비디오)에 대해 가장 관련 있는 비디오(or 텍스트)를 정확히 찾아내는 것을 목표로 태스크입니다. 기존 VTR 방법들은 주로 텍스트와 비디오 간의 정렬을 개선하기 위해 다양한 cross-modal interaction 구조를 설계하는 데 집중해왔습니다. 특히, CLIP과 같은 대규모 이미지-텍스트 사전학습 모델이 도입 및 성능이 대폭 향상하며, 이런 대규모 모델의 지식을 활용하는 것이 주류가 되었죠
그러나 이러한 방식은 인간의 학습 방식과는 다르다고 합니다. 인간은 새로운 정보를 단순히 암기하는 것이 아니라, 외부의 지식을 적극적으로 탐색하고 연관시켜 활용합니다. 반면 기존 VTR 모델은 학습 데이터에만 의존하며, 마치 암기한 정보로만 시험을 치르는 closed-book 방식과 유사하다고 하죠. 이로 인해 드물게 일어나는 케이스를 기억하거나 일반화하는 데 한계가 존재합니다.
Problem: 기존 CLIP 기반 VTR 모델은 학습 데이터로부터 얻은 지식을 모델 내부에만 저장하기 때문에, 추론 시 외부 지식을 활용하지 못해 일반화에 한계.
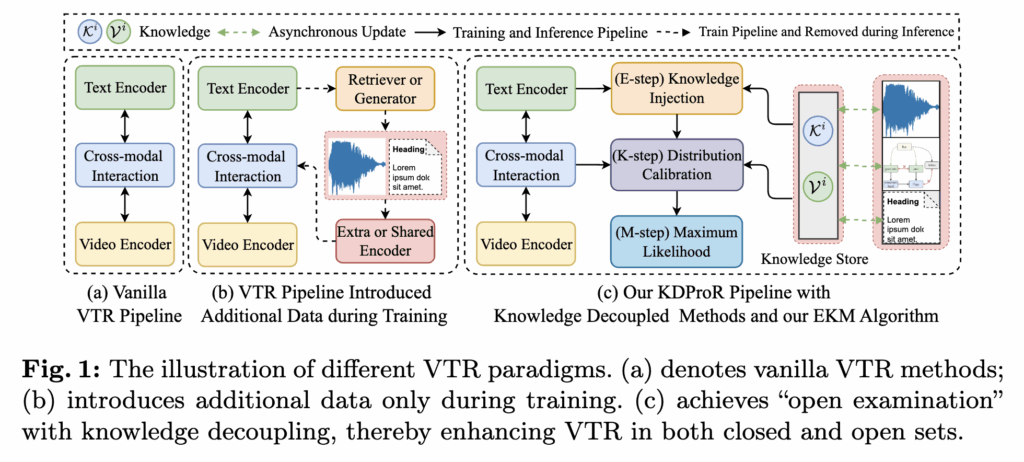
상단 그림 1을 함께 보겠습니다. 가장 왼쪽 (a)는 전통적인 VTR 방식으로, 텍스트와 비디오 인코더를 통해 특징을 추출하고 cross-modal interaction을 통해 유사도를 학습합니다. 이 방식은 학습된 내용만을 기반으로 하기 때문에 closed-book 시험처럼 외부 지식을 활용하지 못합니다. 가운데 (b)는 학습 시점에만 외부 데이터(CLIP)를 사용하는 구조로, 외부 지식이 추론 과정에서는 제거되기 때문에 여전히 일반화에 한계가 있습니다.
이러한 문제를 해결하기 위해 저자들은 지식을 모델로부터 분리(decouple)하고, 이를 지식 저장소 형태로 관리하여 학습과 추론 과정 모두에서 활용하는 방식을 제안하였습니다. 이를 통해 모델이 학습 데이터에만 의존하지 않고, 다양한 외부 지식을 접목시킬 수 있었다고 합니다. 상단 그림 1의 가장 오른쪽 (c)에 제시된 KDProR는 지식을 모델 외부의 저장소에 분리해두고, 학습과 추론 모두에서 이를 적극적으로 활용할 수 있는 구조라고 합니다.
결국 저자는 CLIP을 기반으로 Text-Video-Retrieval을 위해 어떻게 잘 학습할 수 있을까를 고민한 것 같죠? 즉, KDProR (Knowledge-decoupling probabilistic framework for VTR)이라는 새로운 확률론적 retrieval 프레임워크를 제안하였고, 구체적인 방법을 이제 알아보도록 하겠습니다.
2. Method
2.1 Settings and Feature Extraction
notation 먼저 정리하고 가겠습니다. VTR 모델의 입력으로 비디오와 텍스트 쌍 (v_i, t_i)를 사용하여 학습을 진행하였습니다.
- v_i: 하나의 비디오
- t_i: 그에 대응되는 텍스트
- \{f_{i,1}, \dots, f_{i,L}\}: 비디오 프레임 단위
- \{w_{i,1}, \dots, w_{i,M}\}: 텍스트 토큰 단위
- E_v: Visual Encoder.
- 이를 통해 각 프레임 f_{i,l}은 \phi_{i,l} = E_v(f_{i,l})로 임베딩
- E_t: Text Encoder
- 이를 통해 각 텍스트 토큰 w_{i,m}은 \psi_{i,m} = E_t(w_{i,m})로 임베딩
이렇게 얻어진 feature들은 cross-modal interaction 모듈에 전달되어, 두 모달리티 간의 정렬을 학습하게 됩니다.
2.2 Decoupling Knowledge Store
기존의 Video-Text Retrieval 모델은 학습 데이터를 통해 얻은 지식을 모델 내부에 모두 저장해두는 방식이었습니다. 하지만 이 방식은 마치 시험을 외운 내용만으로 치르는 것처럼, 새로운 상황이나 본 적 없는 조합에 대해 유연하게 대응하기 어렵다는 한계가 있었습니다.
이러한 한계를 해결하기 위해, 저자들은 지식을 모델 내부가 아니라 외부에 따로 저장하는 방식을 제안하였습니다. 외부에 따로 저장하는 공간을 지식 저장소(Knowledge Store) 라고 명명했습니다.
다시말해, 저자들은 기존 CLIP 기반의 VTR 모델에 외부 지식을 연동하기 위해, 지식 저장소를 분리된 구조로 설계하였습니다. 이 저장소는 단일 수준의 정보만 담는 것이 아니라, fine-grained와 coarse-grained 두 종류의 지식 쌍을 함께 포함하는 구조로, 각각 세밀한 의미 정보와 전역적인 의미를 포함합니다.
먼저, Fine-grained Knowledge Store는 다음과 같이 정의됩니다: S^f = \{ S_i^f \}_{i=1}^{K^f} = \{ (\mathcal{K}_i^f, \mathcal{V}_i^f) \}_{i=1}^{K^f}.
여기서 {K}_i^f = t_i, \mathcal{V}_i^f = v_i는 각각 텍스트와 비디오에 대한 feature vector로, CLIP의 텍스트 및 비주얼 인코더를 통해 학습 데이터로부터 생성됩니다. 즉, fine-grained 저장소는 학습 데이터 기반의 정확한 키-값 쌍을 통해 의미론적으로 잘 정렬된 정보를 제공합니다.
반면, Coarse-grained Knowledge Store는 보다 전역적인 의미를 포괄하기 위해 다음과 같이 구성됩니다: S^c = \{ S_i^c \}_{i=1}^{K^c} = \{ (\mathcal{K}_i^c, \mathcal{V}_i^c) \}_{i=1}^{K^c}
여기서 coarse-grained representation은 fine-grained 저장소의 키와 값을 K-Mean 클러스터링하여 얻은 클러스터 중심값을 바탕으로 계산된다고 합니다. 이 과정을 수식으로 나타내면 다음과 같습니다:
여기서 \mathcal{C}^t = \{c_1^t, \dots, c_{K_c}^t\}는 fine-grained 텍스트 벡터 집합 \{ \mathcal{K}_i^f \}에 대해 K-Mean을 적용하여 얻은 클러스터 집합이고, \mathcal{C}^v는 \{ \mathcal{V}_i^f \}에 대한 클러스터 집합입니다. \phi(\cdot)는 max pooling 기반의 함수로, 클러스터 내 정보를 압축하여 하나의 대표 벡터로 만듭니다.
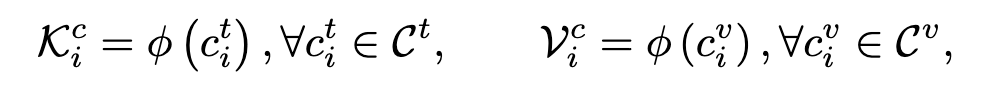
정리하면, fine-grained 저장소는 학습 데이터를 기반으로 정밀하게 구성되고, coarse-grained 저장소는 이를 클러스터링하여 보다 전반적인 의미 구조를 반영하였다고 합니다. 이처럼 두 종류의 지식 저장소를 함께 사용하는 구조는, retrieval 모델이 세밀한 정보와 전역적 의미를 동시에 참고할 수 있게 설계했다고 하네요.
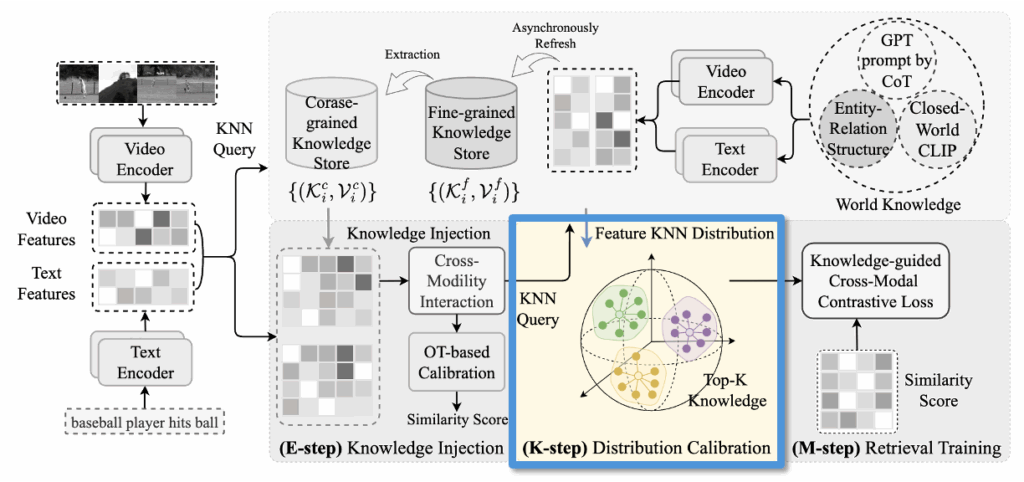
2.3 “E-step” for Multi-Grained Knowledge Injection
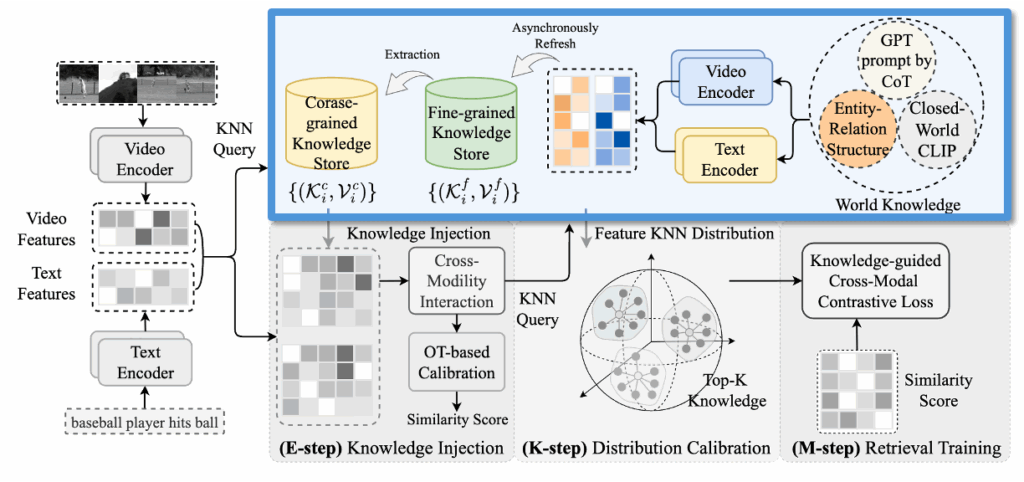
앞서 지식 저장소를 통해 외부 정보를 분리해 저장한 다음, 이를 어떻게 retrieval에 활용할 수 있을지에 대한 구조를 설명하였다면, 이번에는 실제로 이 지식을 어떻게 활용해 모델을 업데이트할 수 있을지에 대한 첫 단계인 E-step (Knowledge Injection)을 설명하겠습니다.
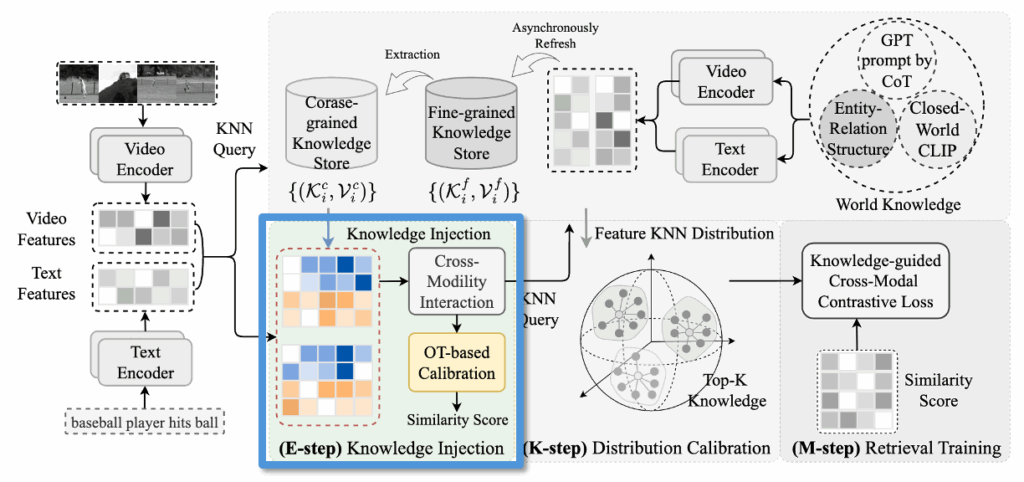
KDProR에서는 외부 지식 저장소에 있는 정보를 현재 쿼리 (t_i, v_i)에 결합하여 retrieval 성능을 높이고자 합니다. 하지만 지식 저장소에서 검색된 정보는 현재 쿼리와 정확히 일치하지 않고, 유사한 예시들에 기반하므로 그대로 사용할 경우 오히려 노이즈가 될 수 있습니다. 이를 해결하기 위해 저자들은 쿼리 표현과 저장된 지식 표현을 보간(interpolation)하여 새로운 텍스트 및 비디오 특징을 만듭니다.
보간은 현재 쿼리 표현 (t_i, v_i)에 대해 지식 저장소에서 가져온 top-K들의 평균 표현을 혼합하는 방식이며, 수식은 다음과 같습니다:
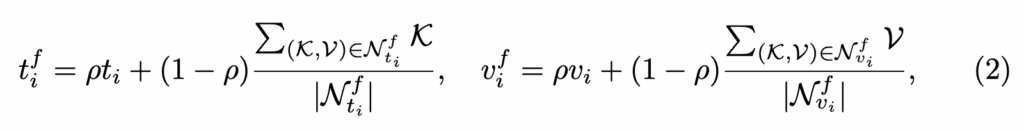
(\rho는 원본 쿼리와 보간 비율을 조절하는 하이퍼파라미터)
보간(interpolation) 과정을 통해 얻은 텍스트 및 비디오 특징들은 각각의 top-K 이웃들로부터 독립적으로 뽑히기 때문에, 이들 간의 페어가 어긋날 수 있습니다. 예를 들어, 텍스트 쪽에서는 “사람이 공을 치는 장면”과 유사한 예시를 불러왔지만, 비디오 쪽에서는 “사람이 공을 던지는 장면”과 유사한 장면을 불러왔을 수 있죠. 이처럼 일대일 대응이 어긋난 경우, 단순 평균이나 임의 정렬로는 두 모달리티 간 의미 정렬을 확보하기 어렵습니다. (그럼 학습 시 노이즈로 작용하겠죠?)
이를 해결하기 위해 논문에서는 Optimal Transport (OT) 기법을 활용하였다고 합니다. OT는 상단 그림처럼 물리학, 물류, 경제학 등에서 한 분포에서 다른 분포로 최소 비용으로 질량을 옮기는 방법을 계산하기 위해 사용되는 수학적 도구라고 합니다.
본 논문에서는 텍스트-비디오 특징 간 정렬 행렬 \mathbf{Q} \in \mathbb{R}^{B \times B}을 학습합니다. 여기서 \mathbf{Q}[i,j][latex]는 텍스트 [latex]t_i^f와 비디오 v_j^f가 서로 짝을 이룰 확률을 의미하죠. 즉, 고정된 순서를 강제하는 것이 아니라, 부드러운 소프트 정렬 방식으로 더 의미 있는 페어를 찾아가는 과정이라고 이해하면 좋을 것 같네요. 아래 수식 (3)은 지금까지 설명한 OT 문제의 수식화:
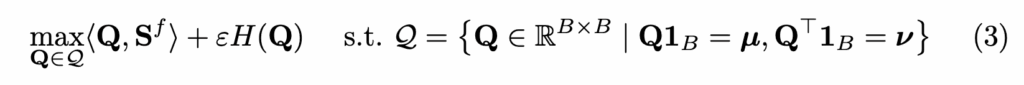
- \langle \mathbf{Q}, \mathbf{S}^f \rangle: 텍스트–비디오 유사도 점수의 합. 이 값을 최대화함으로써 의미 있는 정렬을 유도
- H(\mathbf{Q}): 확률 분포 \mathbf{Q}의 엔트로피. 정렬의 정도(smoothness)를 조절합니다.
- \epsilon: 엔트로피 항의 가중치를 조절하는 하이퍼파라미터.
- 제약 조건 \mathbf{Q} \mathbf{1}_B = \boldsymbol{\mu}, \mathbf{Q}^\top \mathbf{1}_B = \boldsymbol{\nu}: 각 텍스트와 비디오가 일정한 가중치로 대응되도록 균형을 맞추는 조건
OT는 이 정렬을 확률 분포로 표현하고, 전체 유사도(예: 텍스트–비디오 간 의미 정합도)를 최대화하는 방향으로 정렬 행렬 \mathbf{Q}를 최적화합니다. 저자들은 이 OT 문제를 해결하기 위해 Sinkhorn-Knopp 알고리즘을 사용했고, 이를 통해 결과적으로 유사도 행렬을 다음과 같이 보정하였다고 합니다:
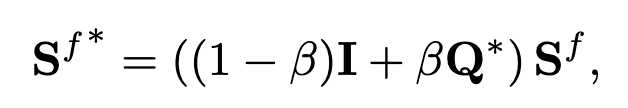
최종적으로, 이 보정된 유사도 행렬은 뒷단 학습 단계에서 cross-modal contrastive loss를 통해 활용됩니다. Coarse-grained knowledge에 대해서도 동일한 방식으로 적용됩니다.
2.4 K-step for Retrieval Distribution Calibration
앞선 E-step에서는 외부 지식 저장소에서 가져온 fine/coarse-grained 정보를 현재 쿼리와 보간하여 새로운 특징을 생성하고, OT 기반의 alignment를 통해 정렬된 텍스트–비디오 유사도 행렬을 구성하였습니다. 이렇게 구성된 유사도 행렬은 K-step에서 확률 분포 형태로 보정되어 실제 학습에 반영되게 됩니다.
K-step의 핵심 목적은 retrieval 결과를 확률 분포 형태로 정규화하여 학습에 활용하는 것입니다. 기존 연구들에서도 KNN 기반의 non-parametric 분류나 보간 방법이 일반화에 강하다는 점이 잘 알려져 있었기 때문에, 본 논문에서는 이를 retrieval 확률 분포로 변환하여 다중 정밀도(granularity) 기반의 정규화를 수행했다고 하네요
Fine-grained Distribution Calibration
우선 fine-grained 지식 저장소에서 쿼리 (t_i, v_i)에 대해 KNN 검색으로 얻은 이웃들을 기반으로 확률 분포를 계산합니다. 구체적으로, 비디오 v_i가 텍스트 t_i에 얼마나 잘 대응하는지를 다음 수식처럼 softmax 형태로 나타냅니다:
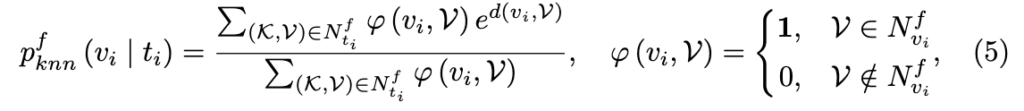
- d(v_i, \mathcal{V}): cosine 유사도로 계산된 거리값
- \varphi(v_i, \mathcal{V}): 해당 비디오 \mathcal{V}가 KNN 이웃에 포함되어 있는지를 판단하는 indicator 함수
즉, fine-grained 저장소에서 검색된 이웃들과의 유사도를 기반으로 soft한 확률 분포를 만들어주는 과정이라 볼 수 있습니다. 이 과정은 대칭적으로 p_{knn}^f(t_i | v_i)에 대해서도 동일하게 적용됩니다.
Coarse-grained Distribution Calibration
Coarse-grained 저장소는 fine-grained 저장소에서 클러스터링으로 파생된 구조이므로, 단순한 포함 여부만으로는 KNN 이웃을 판별하기 어렵습니다. 이를 보완하기 위해, 저자들은 새로운 indicator 함수 \phi(v_i, \mathcal{V}^c)를 도입하였습니다. 이 함수는 다음 조건을 만족하면 1, 아니면 0을 반환한다고 합니다:
- d(v_i, \mathcal{V}^c) < \alpha: 비디오 간 cosine 유사도가 임계값 \alpha 미만
- 해당 coarse-grained 쌍의 원소가 KNN에 포함된 fine-grained 클러스터에 속할 것.
이 조건을 기반으로 coarse-grained 확률 분포는 다음 수식으로 정의됩니다:
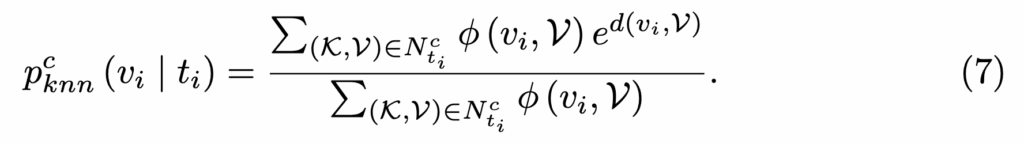
이렇게 fine/coarse 양쪽에서 KNN 기반 확률 분포를 만들고, 이후 학습 손실에 반영합니다. 이 과정은 retrieval 결과를 보다 안정적이고 의미론적으로 정렬되도록 보정하는 데 핵심적인 역할을 합니다.
마찬가지로 p_{knn}^c(t_i | v_i)에 대해서도 동일한 방식으로 계산됩니다.
2.5 M-step for Unified Retrieval Optimization
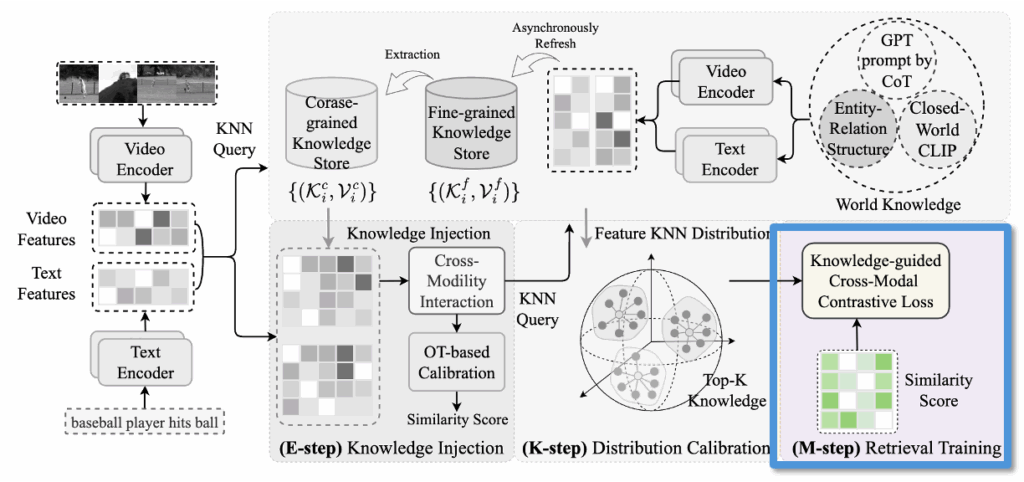
M-step은 앞서 보정된 유사도 행렬(S^{f*}, S^{c*})을 활용하여 전체 모델을 학습하는 단계입니다. 더 자세하게 말하자면, InfoNCE 기반의 cross-modal contrastive loss를 계산하며, 양방향(text→video, video→text) 손실을 모두 고려합니다. 수식 (8)은 이를 수식화한 것으로, 텍스트–비디오 간 정렬된 유사도가 높아지도록 설계되었숩니다.
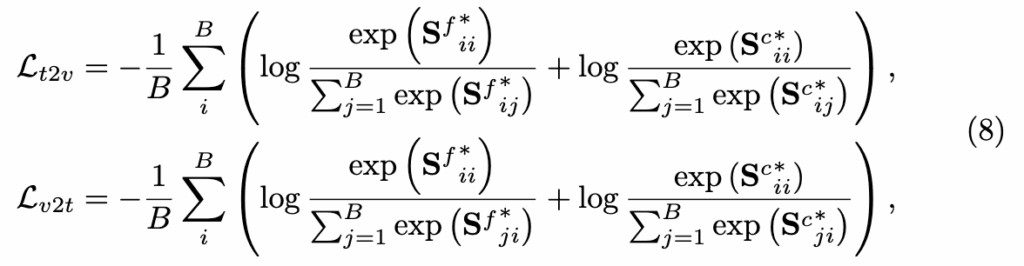
하지만 단순한 InfoNCE만으로는 hard negative에 민감하거나 불완전한 정렬에 취약할 수 있기 때문에, 저자들은 앞서 계산한 KNN 기반 확률 분포(p_{knn})를 활용해 손실을 보정하였습니다. 아래 수식 (9)에서 보이듯, KNN 분포로부터 얻은 음의 로그 가능도(NLL)를 보정 계수로 사용하여, 정답 후보에 더 가중치를 주는 방식입니다.
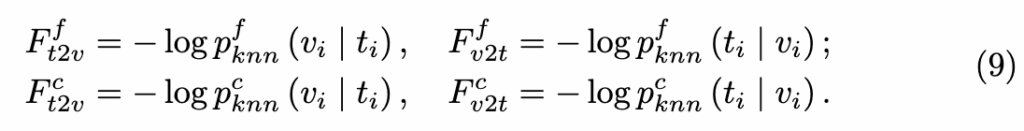
최종 손실 함수는 fine/coarse-grained 손실에 각각 다른 가중치(\lambda_1, \lambda_2)를 부여하여 결합한 형태이며, 수식 (10)과 같이 표현됩니다. 이렇게 함으로써, 외부 지식 기반의 soft한 정렬과 내부 학습 간 균형을 맞춘 unified training이 가능해집니다.

2.6 Applications of Our KDProR Framework
KDProR 프레임워크의 지식 저장소(Knowledge Store)는 다양한 방식으로 구축될 수 있으며, 저자들은 다음 세 가지 예시를 통해 이를 설명하고 있습니다.
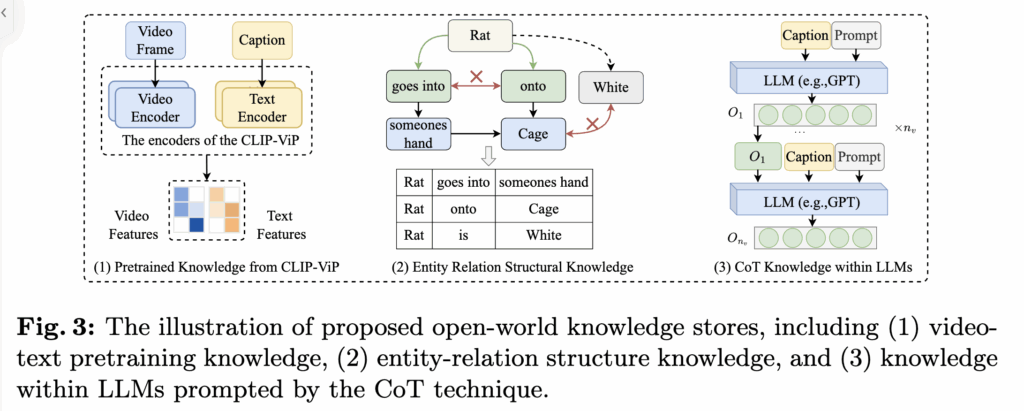
1. Video-Text Pretraining 기반 지식 구성
사전학습된 CLIP-ViP 모델을 활용하여 비디오와 텍스트 쌍으로부터 의미 있는 feature를 추출하고, 이를 기반으로 지식 저장소를 구성합니다. 특히 HD-VILA-100M과 같은 대규모 데이터셋에서 사전학습된 모델을 사용하여, 고품질의 비디오-텍스트 표현을 확보할 수 있다고 하네요.
2. Entity-Relation 기반 구조적 지식
자연어 설명 문장을 Scene Graph Parser를 통해 '주어-관계-목적어' 형태의 구조적 지식으로 변환합니다. 이렇게 구성된 삼중항(triplet)을 원래 캡션 대신 사용하여, 의미론적 관계가 더 분명한 형태로 지식을 표현하게 됩니다. 이후 CLIP을 사용해 이러한 삼중항 기반 텍스트-비디오 feature를 추출해 저장소를 구축합니다.
3. LLM 기반의 CoT (Chain-of-Thought) 지식 생성
대형 언어 모델을 프롬프트하여 각 비디오 프레임에 대한 보조 캡션을 생성하고, 이 보조 캡션을 CLIP을 통해 임베딩한 후 저장소에 저장합니다. 이러한 방식은 단순 설명 이상의 고차적 추론이 필요한 정보도 포함할 수 있다는 장점이 있다고 하네요..
이처럼 KDProR는 정형화된 데이터뿐 아니라, LLM이나 Scene Graph 등 다양한 도구를 활용하여 지식 저장소를 구성할 수 있어, 유연하고 확장 가능한 구조를 가진다는 장점이 있습니다.
[ KDProR 전체 파이프라인 요약 ]
이 논문이 제안한 것이 제법 많아서.. 파이프라인 요약을 하고 마무리하겠습니다. KDProR은 외부 세계 지식을 활용하여 Text-Video Retrieval 모델의 성능을 향상시키는 프레임워크로, 크게 지식 저장소 구축, 지식 주입(E-step), 분포 정렬(K-step), 최종 학습(M-step)의 4단계로 구성됩니다.
① 지식 저장소 구성 (World Knowledge → Knowledge Store)
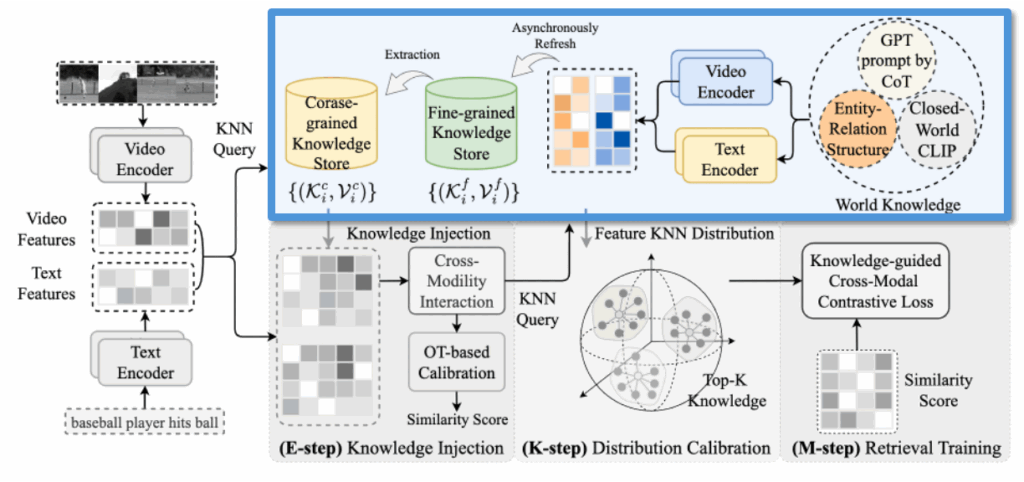
- World Knowledge는 세 가지 방식으로 구성됩니다:
- (a) CLIP 기반의 Video-Text Pretraining
- (b) Scene Graph를 활용한 Entity-Relation Structure
- (c) LLM에 CoT prompt를 입력하여 만든 Auxiliary Caption
- 위 정보로부터 Coarse-grained 및 Fine-grained Knowledge Store를 비동기적으로 구성합니다.
각각은 ⟨텍스트, 비디오⟩ feature 쌍으로 표현되며, KNN 기반 retrieval을 위한 인덱스로 활용됩니다.
② 쿼리 입력 및 임베딩
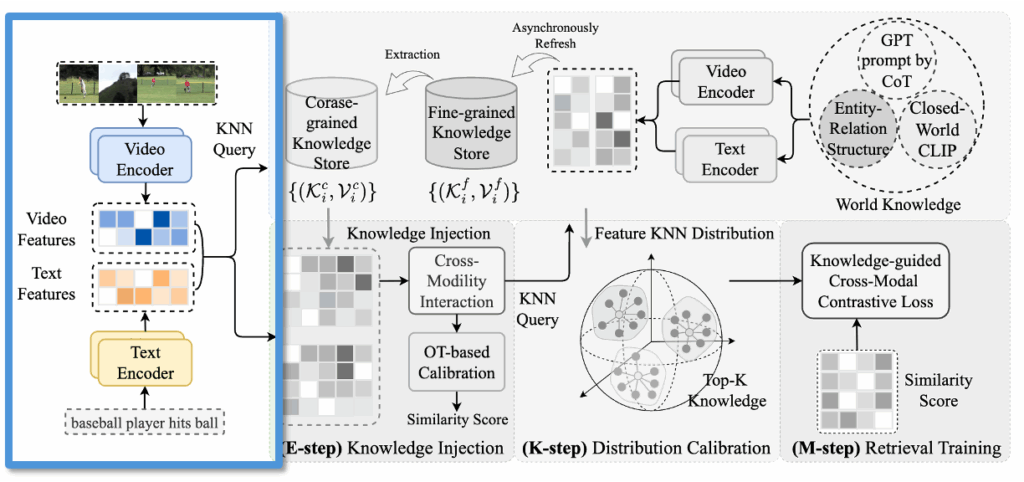
- 사용자가 입력한 쿼리(텍스트 및 비디오)는 각각 Text/Video Encoder를 거쳐 임베딩됩니다.
- 이 임베딩된 쿼리를 기반으로 Knowledge Store에 KNN Query를 보내 주변 이웃(top-K)을 검색합니다.
③ E-step: Knowledge Injection
- 검색된 이웃 정보를 바탕으로, 원본 쿼리 feature와 보간(interpolation)을 수행하여 새로운 표현을 생성합니다.
- 그러나 텍스트-비디오 페어가 맞지 않을 수 있어, Optimal Transport (OT) 기법을 활용해 텍스트–비디오 간의 유사도 정렬 행렬을 학습합니다.
- 이를 통해 의미 있는 쌍을 찾아내어 Similarity Score를 계산합니다.
④ K-step: Distribution Calibration
- 위에서 계산된 feature를 바탕으로, Fine/Coarse knowledge store에서 각각 KNN 기반 확률 분포를 구합니다.
- 정답과 유사한 이웃들이 얼마나 존재하는지에 따라, 샘플별 신뢰도 기반 보정 가중치(calibration factor)를 부여합니다.
⑤ M-step: 최종 학습
- 보정된 Similarity Score를 기반으로 InfoNCE Loss를 계산하며,
- 각 샘플에 대해 앞서 구한 calibration factor를 곱하여 지식 기반 가중 contrastive loss를 계산합니다.
- 이 과정을 통해 모델은 retrieval 정확도를 높이도록 학습됩니다.
3. Experiments
Table 1 – MSR-VTT 성능 비교
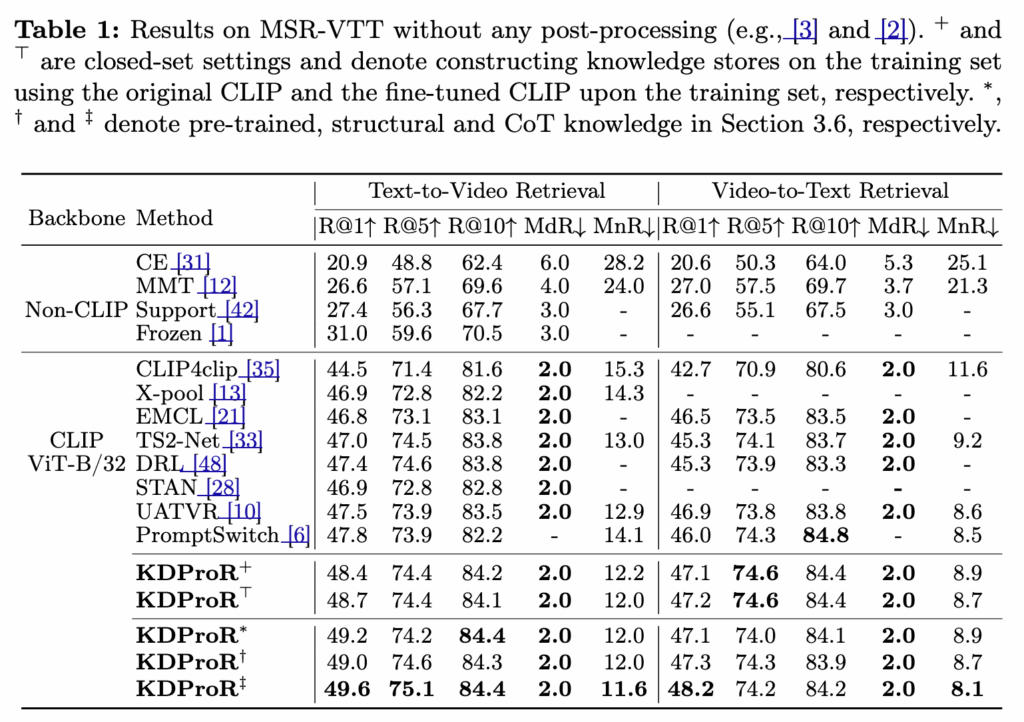
KDProR는 기존 Text-to-Video Retrieval 기반 방법들과 비교했을 때, 지식 저장소(Multi-grained Knowledge Store)를 활용하여 더 높은 성능을 보였다고 합니다.
기존 DRL 대비 최대 +2.2% 향상된 R@1 성능(49.6%)을 기록했고, Text-to-Video와 Video-to-Text 모두에서 고른 성능을 보였습니다. 특히 기존의 CLIP 기반 방법들(TS2-Net, DRL, PromptSwitch 등)은 정렬된 feature를 학습에 직접 활용하지 않아 KNN 기반 보정이 어려운 구조였던 반면, KDProR는 지식 기반으로 정렬된 분포를 효과적으로 활용하여 retrieval loss에 의미 있는 가중치를 부여하는 것이 성능 향상의 핵심으로 작용하였다고 합니다. 그중에서도 open-world knowledge(COT, structural knowledge 등)를 결합한 KDProR‡ 모델이 가장 뛰어난 성능을 보여주며, 다양한 구성에서도 일관된 우수한 결과를 보였습니다.
Table 2 – DiDeMo / ActivityNet / LSMDC 성능 비교
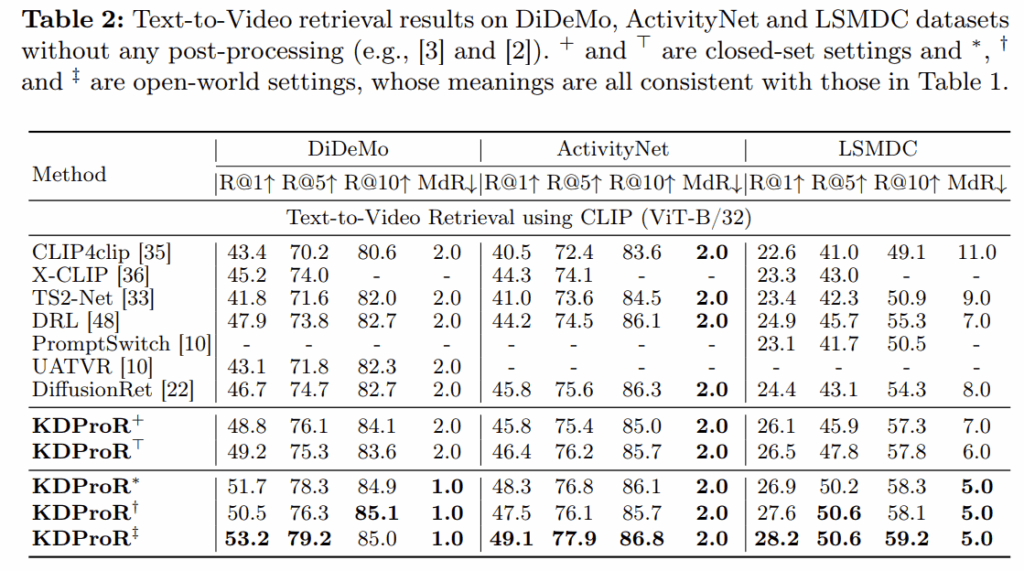
- DiDeMo: 시간 단위로 세분화된 caption과 정렬해야 하는 구조로, 세밀한 정렬 능력이 요구.
- KDProR는 기존 DRL 대비 R@1 기준 +5.3% 향상된 53.2% 성능을 기록하며, 시계열 정렬 능력이 크게 향상됨
- ActivityNet: 다양한 길이의 비디오 클립과 고차원 의미를 포함하는 caption에 대한 정렬 성능이 중요.
- KDProR는 DRL 대비 +2.2% 향상된 49.1%의 R@1을 기록
- 특히 fine-tuned knowledge를 포함하는 설정에서 consistently 높은 R@5, R@10 성능을 보임.
- LSMDC: 비디오와 자막 간 의미적 일치가 낮은 어려운 데이터셋
- KDProR는 전 지표에서 SOTA를 기록. 기존 방식 대비 약 +3.3% 향상된 R@1=28.2%를 달성
- open-domain knowledge를 기반으로 한 보정이 의미적 불일치를 극복하는 데 효과적
Table 3 – LSMDC 및 DiDeMo 성능 비교
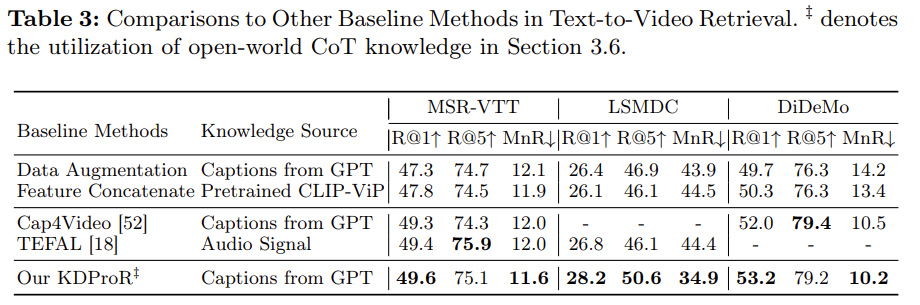
- 기존 방법(LLM 기반 Data augmentation, CLIP-VIP feature concat)은 성능 향상 제한적
- KDProR는 정렬된 외부 지식을 활용해 의미 있는 성능 향상
- LSMDC: Cap4Video 대비 R@1 +1.4%
- DiDeMo: TEFAL 대비 R@1 +1.2%
- 단순 보강보다 구조적 지식 통합이 효과적이었음
Table 4 – Generalization 성능
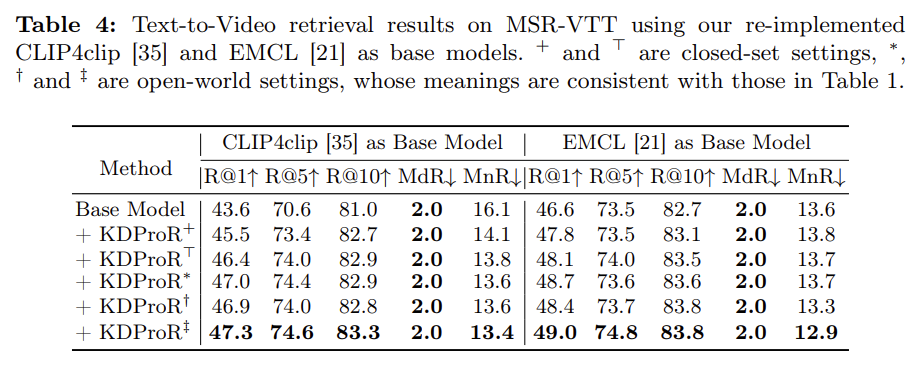
- KDProR는 DRL 외에도 CLIP4Clip, EMCL 등 다양한 백본과 결합 가능
- 모든 조합에서 성능 향상 → plug-and-play 모듈로서의 강점
- closed-set & open-world 모두에서 일반화 능력 입증
4. Summary
본 논문에서는 비디오 검색(Text-to-Video Retrieval) 성능을 높이기 위해 KDProR라는 새로운 방법을 제안하였습니다. 기존 방식들은 파라미터 수를 줄이거나, 시간 정보를 잘 다루는 데 각각 초점을 맞췄지만 두 가지를 동시에 만족시키기는 어려웠습니다. KDProR는 다양한 해상도의 지식을 저장하고 이를 검색 과정에 활용함으로써, 학습에 필요한 정보 정렬을 더 정교하게 반영할 수 있었다고 합니다.
그 결과, 대표적인 데이터셋인 MSR-VTT에서 기존 최고 성능보다 더 높은 49.6%의 정확도(R@1)를 달성했으며, LSMDC, DiDeMo, ActivityNet 등 다양한 데이터셋에서도 일관되게 좋은 성능을 보였죠. 특히 KDProR는 구조적 지식이나 Chain-of-Thought와 같은 open-world 지식도 함께 활용하여 성능을 한층 더 끌어올렸고, 다른 모델들과 쉽게 결합해 사용할 수 있는 장점도 있었습니다.