이번에 소개드릴 논문은 퀄컴에서 작성한 논문이며, 퀄컴의 관심 분야답게 모델의 효율성을 위한 Knowledge Distillation을 목적으로 합니다.
CVPR 참관하면서 포스터로 접하게 된 논문인데 컨셉이 그리 복잡하지 않으면서도 제가 관심있어 하던 문제를 다루고 있어서 이렇게 리뷰로 작성하게 되었습니다.
Intro
일단 인트로 내용은 상당히 직관적입니다. 무거운 모델은 성능이 좋지만 그만큼 모델이 차지하는 메모리나 연산 비용이 크기 때문에 real-time application에 적용하기에는 무리가 있습니다. 반대로 edge device을 위해 고안된 경량 모델들은 연산 비용과 속도 측면에서 상당히 우수하지만 반대로 성능이 그리 좋지는 못하죠.
이러한 연산 효율성과 정확도 사이 trade-off 관계는 공학과 관련된 모든 분야에서 항상 관심을 받아왔던 주제로 어떻게하면 이 trade-off 관계 안에서도 최대한 효율성과 정확도를 동시에 챙길 수 있을지가 주요 문제로 다루어져왔습니다.
다시 본론으로 돌아와서, 컴퓨터비전 분야에서 정확도가 높지만 연산 효율성은 낮은 모델이라고 한다면 단연코 Foundation Model들이 있겠죠. 특히 방대한 양의 데이터로 학습한 DINOv2와 OpenCLIP 같은 모델들이 저자들이 말하는 Large Vision Foundation Models(LVFMs)에 속하게 됩니다.
Pruning 또는 Quantization과 같이 해당 모델들 자체를 경량화 하는 방법도 있을 수 있지만 해당 논문에서는 논문 제목에서도 아시다시피 Knowledge Distillation(KD)을 메인으로 삼습니다. 즉 LVFMs의 강력한 일반화 성능 및 정확도를 비교적 가벼운 엣지 모델(CNN 계열)에게 성공적으로 distillation함으로써 정확도가 높으면서 연산 효율성이 좋은 엣지 모델을 만들어내는 것이죠.
그렇다면 이러한 KD을 수행하는데 있어 예상되는 어려움은 무엇이 있을까요? 저자들은 LVFMs을 선생 모델로 두고, CNN계열의 엣지 모델을 student 모델로 두어 지식을 전이하는 환경에서 기존 KD의 효과가 그리 크지 못하다고 주장합니다. 우선 KD가 잘 되지 않는 이유에 대해 저자는 2가지 요인을 언급합니다.
첫째는 선생 모델과 학생 모델 사이에 너무나도 큰 파라미터 수의 차이를 지적합니다. 기본적으로 Foundation Model들은 백만, 천만, 심지어 억단위의 데이터로 모델을 학습하기 때문에 방대한 지식을 학습하기 위해서는 그에 걸맞는 수많은 파라미터들로 구성이 되어야만 합니다.
하지만 엣지 모델들은 LVFMs의 파라미터 수와 비교해보면 상당히 제한적이기 때문에 각 모델이 표현할 수 있는 근본적인 feature representation 자체가 다릅니다. 쉽게 생각해서 어린아이와 성인이 똑같이 축구공을 찬다고 하더라도 근육량 자체가 다르기 때문에 아무리 성인이 아이한테 축구를 가르쳐주어도 성인의 발차기 파워를 따라갈 수 없는 것이죠.
두번째로는 선생과 학생 두 모델 사이의 네트워크 구조 자체에 다름으로 인한 문제입니다. LVFMs들은 대부분 ViT로 구성이 되어있는데 이는 transformer의 inductive bias가 없다는 점이 방대한 양의 데이터에서 더 강력한 일반화 성능을 달성할 수 있다는 이론적/실험적 배경으로 인하여 많은 연구자들이 트랜스포머 계열을 채택하기 때문입니다. 또한 ViT 계열이 멀티모달로의 확장도 용이하구요.
하지만 연산의 효율성 측면에서는 ViT와 비교했을 때 CNN이 월등히 좋다는게 자명한 사실이기도 하여서 대부분 경량 모델로는 CNN을 많이 채택하는 편입니다. 이러한 CNN은 컨볼루션 연산을 반복적으로 수행하기 때문에 ViT와 달리 long-range dependency를 모델링하기 어렵죠.
즉 이러한 feature modeling 과정에서 두 네트워크의 구조적 차이로 인하여 표현할 수 있는 특징이 서로 상이할 수 밖에 없으며 이러한 차이가 선생 모델의 지식을 학생 모델에게 전이하는 것을 어렵게 만듭니다.
KD는 상당히 오랫동안 관심 받아온 연구 주제이기 때문에 선생과 학생 모델 사이에 파라미터 격차가 큰 상황에서도 효과적으로 distillation하는 방법론도 이미 많이 존재하고 있으며, 최근에는 선생과 학생 모델 사이의 구조적 차이 (e.g., ViT => CNN)에서도 표현의 차이를 극복하려는 연구들이 나오고는 있지만, 파라미터 수 차이가 큰 경우를 극복하려는 연구들은 선생과 학생 모델 모두 유사한 아키텍처를 지니고 있고, 모델의 구조적 차이를 극복하려는 연구들은 선생 모델의 파라미터 수가 그리 크지 않다는 한계점이 있다고 합니다.
그래서 저자들은 이러한 모델의 구조적 차이 뿐만 아니라 모델의 파라미터 수도 크게 차이나는 상황에서 효과적인 KD를 연구하는 것을 목표로 하고 있으며, 그 결과 2가지 단계로 구성된 KD framework을 제안하게 됩니다.
첫번째는 feature customization step으로, LVFM의 feature를 student model의 head classifier를 통해 student model의 representation에 맞추어 커스터마이징 하는 단계를 수행합니다. 이후에는 knowledge distillation을 수행하는 단계로 넘어가게 되는데 이 때 student model이 teacher model의 일반화 특징을 학습하는 것 뿐만 아니라, customization stage에서 수행한 task에 특정된 특징도 함께 학습하게 됩니다.
보다 구체적인 방법론은 밑에 method에서 다루는 걸로 하겠습니다.
Problem Definition
우선 저자들이 고려하는 KD 상황은 다음과 같습니다. 저자들의 주 task는 classification입니다. 따라서 student model \theta_{s} 는 ( \theta^{e}_{s}, \theta^{c}_{s} ) 로 표현합니다. 마찬가지로 teacher model은 \theta_{t} = ( \theta^{e}_{s}, \theta^{c}_{s} ) 로 표현할 수 있으며, \theta^{e}, \theta^{c} 는 각각 인코더와 분류기 헤드를 의미합니다.
일반적으로 KD 방식은 크게 2가지로 분류기 헤드에서 나온 soft label을 distillation하는 방식과 encoder에서 나온 feature map을 distllation하는 방법으로 크게 2가지가 존재하는데 저자들은 이중에서 encoder의 feature map을 distillation 하는 방식입니다.
그리고 학습의 과정은 우선 student model이 소량의 labeled data를 가지고 지도학습을 마친 뒤 unlabeled data에 대하여 teacher model의 knowledge를 학습하는 방식으로 접근하게 되는데, 쉽게 생각하면 unlabeled 데이터에 대하여 feature level에서도 distllation을 하고, teacher model의 최종 output을 pseudo-label 삼아 task에 대해서도 학습을 한다고 이해하시면 되겠습니다.
따라서 저자들이 메인으로 잡는 task는 unsupervised domain adaptation(UDA)와 semi-supervised learning(SSL)로 구성이 되어있습니다. 또한 논문에서 teacher model로 DINOv2와 OpenCLIP으로 학습한 ViT-Large 모델을 사용하였으며 student model로는 WideResNet28-2를 사용합니다. 참고로 student model이 처음 지도학습하는 데이터셋은 CIFAR-100 데이터셋으로 400개의 labeled sample을 사용했다고 합니다.
논문 방법론에 대해 본격적으로 들어가기 앞서, 저자들이 주장하는 문제정의와 이러한 문제를 기존 KD 방법론들이 효과적으로 풀지 못하는가에 대해 다룬 사전 실험 결과를 보고 가겠습니다.
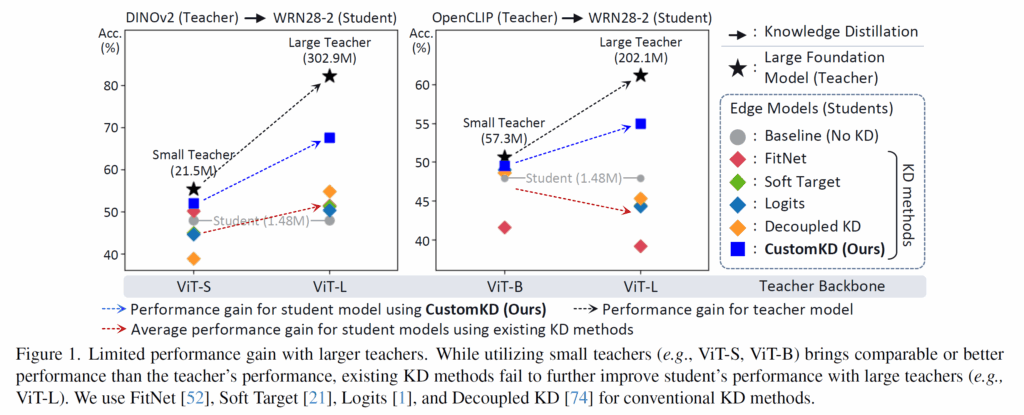
x축은 teacher model의 종류로 상대적으로 작은 크기의 모델 (ViT-Small)과 큰 모델 (ViT-Large)에 대하여 WRN28-2 모델에게 knowledge distillation을 하였을 때의 성능을 나타낸 것입니다. 즉 y축이 분류 정확도를 의미한다고 보시면 되고, 검정색 별표는 teacher model의 성능, 회색 동그라미는 student model의 원래 성능입니다.
그리고 각 색깔들이 KD 방법론들을 적용하였을 때의 student 성능을 나타내는 것인데 이전 방법론들을 하나하나 다 볼 수 없으니 저자들이 이들의 평균 성능 향상도를 붉은색 화살표로 나타내었습니다. 그리고 저자들이 제안하는 방법론의 성능 향상 정도는 파란색 화살표, 검정색 화살표는 teacher model이 small에서 large로 커졌을 때의 성능향상도를 의미합니다.
우선 그림1에서의 관전 포인트는, teacher model이 small에서 large로 커짐에 따라 매우 높은 성능 향상폭을 보여준다는 점이 하나 있습니다. 이러한 teacher model의 성능 향상 정도와 달리 기존의 KD 방법론들은 teacher model이 small에서 large로 커졌음에도 불구하고 student의 성능 향상폭이 미미하거나 OpenCLIP의 경우에는 오히려 더 떨어지는 모습을 보여줍니다.
정말 아이러니합니다. 더 똑똑한 모델을 선생 모델로 붙여주었는데 학생 모델의 성능이 더 떨어지는 경우가 발생한 것이죠. 이는 저자가 인트로에서 주장한대로 파라미터 수가 너무 차이가 난다는 점, 그리고 선생과 학생 모델의 아키텍처 자체의 차이 등으로 인해 teacher model의 knowledge를 효과적으로 distillation할 수 없음을 의미합니다.
반대로 저자들이 제안하는 KD 방법론을 적용할 경우에는 학생 모델의 성능이 large teacher model을 적용한다 하더라도 기존 KD 방법론들과 비교해서 더 크게 개선이 되는 것을 보여주며 이는 곧 knowledge distillation을 잘 수행했다고 볼 수 있겠습니다.
Method
그럼 본격적으로 방법론에 대해서 알아봅시다. 사실 엄청 단순해서요. 간단하게 설명하고 넘어가도 이해하시는데 전혀 무리가 없다고 생각됩니다.
Feature customization stage
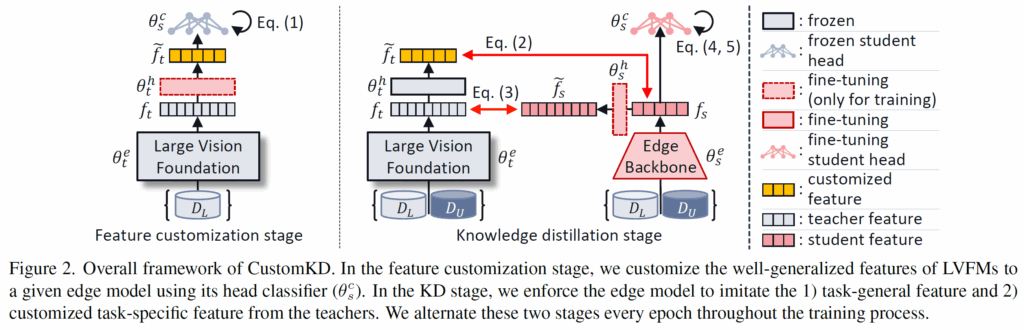
전반적인 학습 과정은 그림2와 같습니다. 인트로에서도 간단하게 소개드렸었는데, 우선 선생 모델의 feature를 커스터마이징하는 단계가 존재합니다. 커스터마이징 과정에 대해서 상세하게 소개를 드리면, 우선 입력영상 x를 선생 모델의 encoder의 입력으로 넣어 특징맵 f_{t} 를 추출합니다. 해당 특징맵은 선생 모델의 강력한 일반화 성능을 바탕으로 풍부한 표현력을 지니고 있음을 기억해두시면 됩니다.
근데 이 풍부한 표현력은 결국 방대한 양의 파라미터와 학생 모델과는 다른 연산 방식(여기서는 어텐션 연산이겠죠?)으로 추출된 것이기 때문에 이 지식을 곧바로 학생 모델에게 전달해주면 학생 모델은 학습에 어려움을 겪을 것입니다.
그래서 해당 특징 맵을 학생 모델이 잘 배울 수 있도록 커스터마이징을 해주어야만 하는데, 저자들은 해당 f_{t} 를 커스터마이징하는 projection layer \theta^{h}_{t} 를 통하여 커스터마이징된 feature \tilde{f}^{h}_{t} 를 추출합니다.
그리고 이 커스터마이징된 특징은 student model이 사용하는 classifier head를 통과하게 되고 이렇게 예측한 prediction과 실제 GT간에 CE loss를 계산하여 모델을 학습합니다.
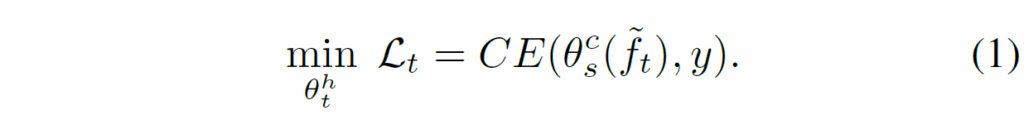
이때 student model의 분류기는 이미 적은 양의 샘플로 사전학습이 되었다는 가정이 깔려있는 것이고, 커스터마이징 단계에서는 커스터마이징을 위한 projection layer만 학습이 되고 나머지 teacher model의 인코더와 student의 분류기는 모두 freeze 상태임을 알아두셔야 합니다.
요약하면, 선생 모델의 인코더도 고정, 학생 모델의 분류기도 고정된 상태에서 projection layer \theta^{h}_{t} 가 최대한 CE loss를 줄이도록 학습하려면 결국 학생 모델의 분류기 입맛에 맞추어 teacher model의 feature map f_{t}를 변형시키도록 학습이 되어야 할 것입니다.
Knowledge distillation stage
다음은 본격적인 KD 단계입니다. 위에 그림 2 중간 부분을 다시 살펴보시면 학생 모델이 선생 모델의 지식을 학습해야하는 것이기 때문에 선생 모델은 여전히 freeze, 학생 모델은 learnable parameter로 구성이 되는 것을 확인하실 수 있습니다.
우선 선생 모델의 지식을 전이하는 부분부터 보겠습니다. 아까 커스터마이징 과정에서 선생 모델의 projection layer \theta^{h}_{t} 를 통해 student model에 친화적인 feature map \tilde{f}_{t} 을 뽑았습니다. 해당 feature map을 label로 삼아 student model의 encoder를 타고 나온 feature map f_{s} 을 아래와 같이 지도학습 합니다.
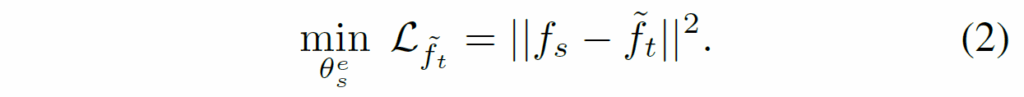
저자는 이 수식2의 과정을 task-specific한 feature distillation이라고 명칭을 붙였네요. 반대로 projection layer를 타고 나오지 않은 원래의 선생 모델의 특징 f_{t} 는 강력한 일반화 성능을 보여주고 있기 때문에 이를 학습하는 과정도 필요합니다. 보통 이러한 특징은 고차원 정보이기 때문에 학생모델의 특징맵 f_{s} 에 또 다른 projection layer를 태워서 선생 모델의 특징과 동일 차원 크기로 맞춘 뒤 아래 수식3과 같이 distllation을 수행합니다.
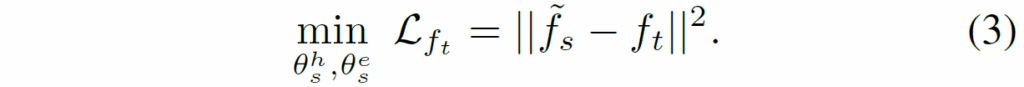
이렇게 knowledge distillation 과정이 마무리가 되고, 그 외에 student model 자체의 분류 성능을 개선시키기 위한 loss 함수들이 아래와 같이 진행됩니다.
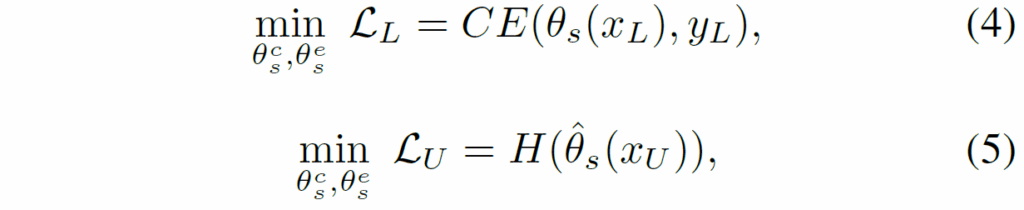
여기서 수식4는 labeled set에 대해서 CE loss로 지도학습을 하는 것을 의미하며 수식5는 entropy minimization loss로 H함수는 다음과 같습니다.
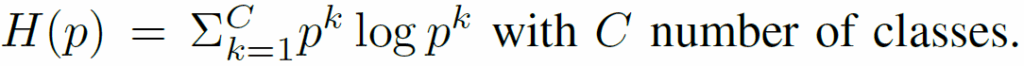
해당 실험 세팅에서는 labeled set이 400개밖에 안되기 때문에 labeled set만으로 학습을 하게 되면 그쪽으로 overfitting이 과하게 일어날 수 있어 저자들이 unlabeled set에 대해 수식5를 추가해서 학습을 진행한 것이라고 하네요.
저는 선생모델이 unlabeled set에 대해서 pseudo label을 생성해서 이를 supervision 삼아 학생 모델을 학습시킬 것으로 예상했는데, 그냥 feature level에서 distillation하는 것 외에는 unlabeled set에 대하여 그 어떠한 supervision을 적용하지 않았다는 점이 의외네요.
Experiments
그럼 실험 결과 보고 리뷰 마무리 짓겠습니다. 실험 task는 앞서 소개드린바와 같이 UDA와 SSL 2가지로 진행이 됩니다. 그리고 학생 모델은 사전학습된 off-the-shelf 엣지 모델이고 데이터셋은 UDA task의 경우 OfficeHome과 DomainNet 데이터셋을, SSL task의 경우 CIFAR-100과 ImageNet을 사용합니다. SSL task에서 CIFAR-100 데이터셋으로 학습 및 평가할 때 학습에 사용되는 labeled set의 수를 400, 2500, 1만개로 나누어 평가하는 벤치마크를 활용하였으며, ImageNet의 경우에는 전체 학습 데이터 수 중 1%, 10%의 labeled set을 사용했다고 합니다.
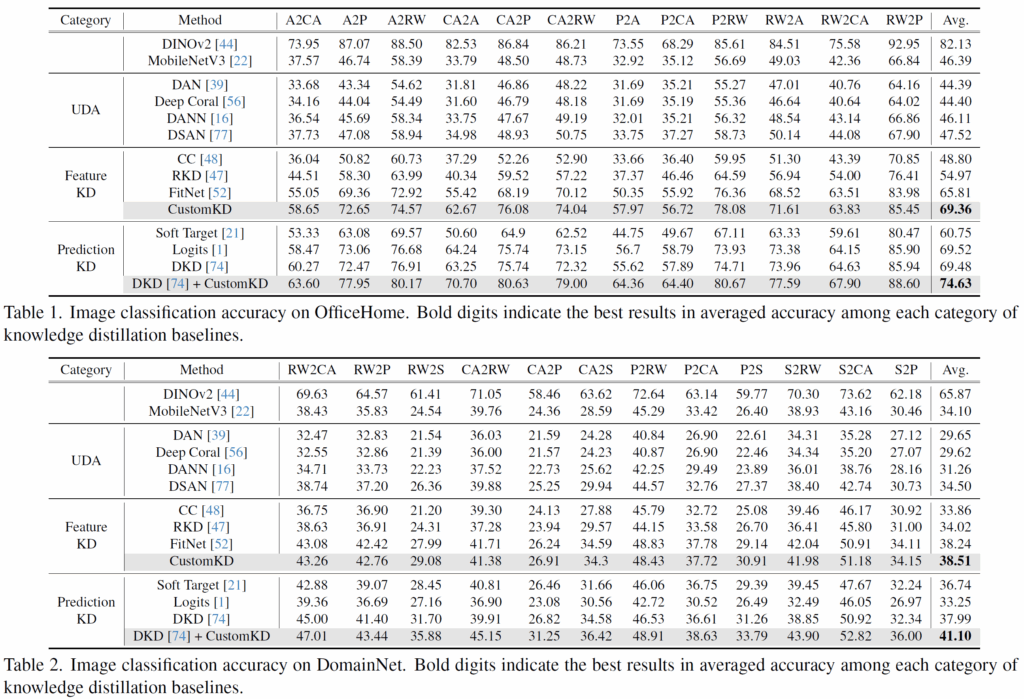
위에 표 1, 2는 모두 UDA task와 관련된 성능을 의미합니다. 우선 자신들의 방법론 (CustomKD)가 UDA 방법론들이나 Feature KD 방법론들과 비교해서 가장 좋은 성능을 보여준다고 합니다. 그리고 자신들의 방법론은 feature level에서의 KD이기 때문에 prediction 레벨에서의 KD를 수행하는 맨 밑에 3가지 방법론들에다가 자신들의 방법론을 추가로 적용할 수 있으며 그 경우에 더 큰 성능 향상폭을 보여주었다고 하네요.
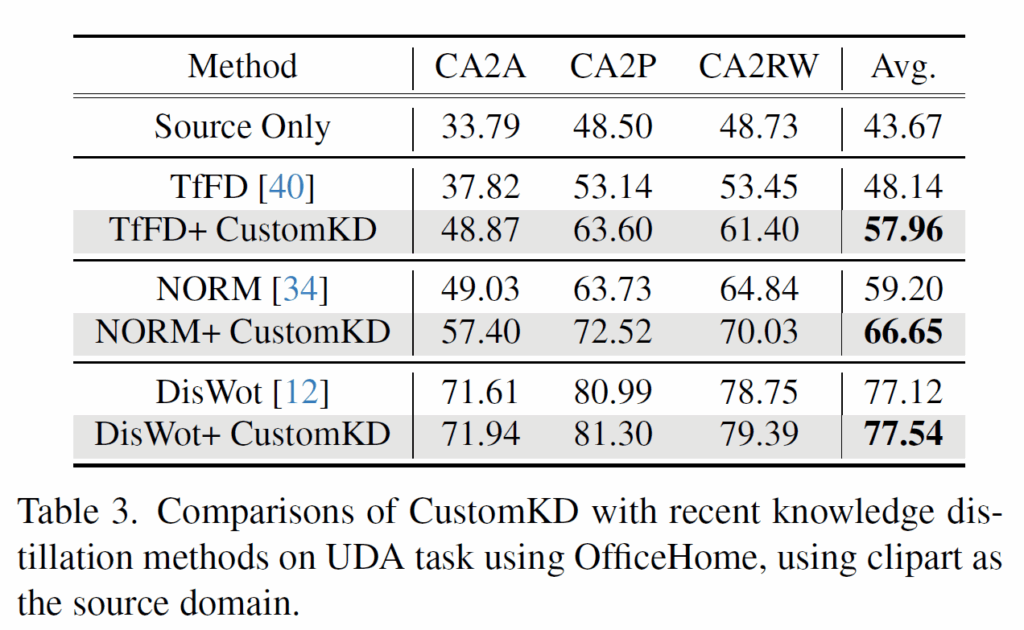
위에 표3은 똑같이 UDA task에 대해서 가장 최신의 KD 방법론들에 자신들의 방법론을 추가하였을 때의 결과물로 이들 역시도 일관성있게 자신들의 기법을 추가하면 성능이 올라간다는 점을 어필합니다. (근데 DisWot에서는 성능 향상이 미미.)
Semi-supervised learning
다음은 SSL에 대한 실험 결과들입니다.
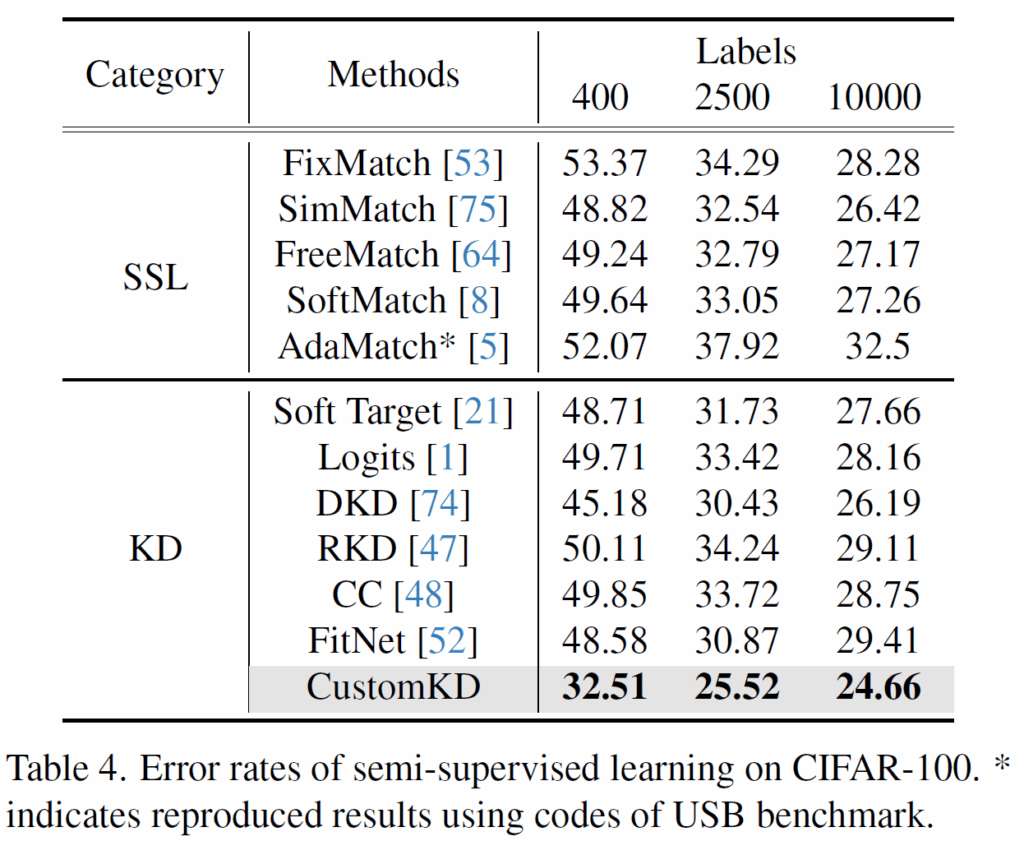
SSL 방법론들과 KD 방법론들을 비교하였을 때 자신들의 방법론이 가장 낮은 에러율을 보임으로써 제일 성능이 좋다!라고 주장하고 있네요. 저자들이 이 실험에서 추가로 어필하는 것은, 기존의 SSL 연구들은 strong data augmentation과 thresholding 등 정교한 기법들이 사용된 반면에 자신들의 방법론은 그러한 기법들이 전혀 필요없음에도 좋은 성능을 보여준다는 점입니다.
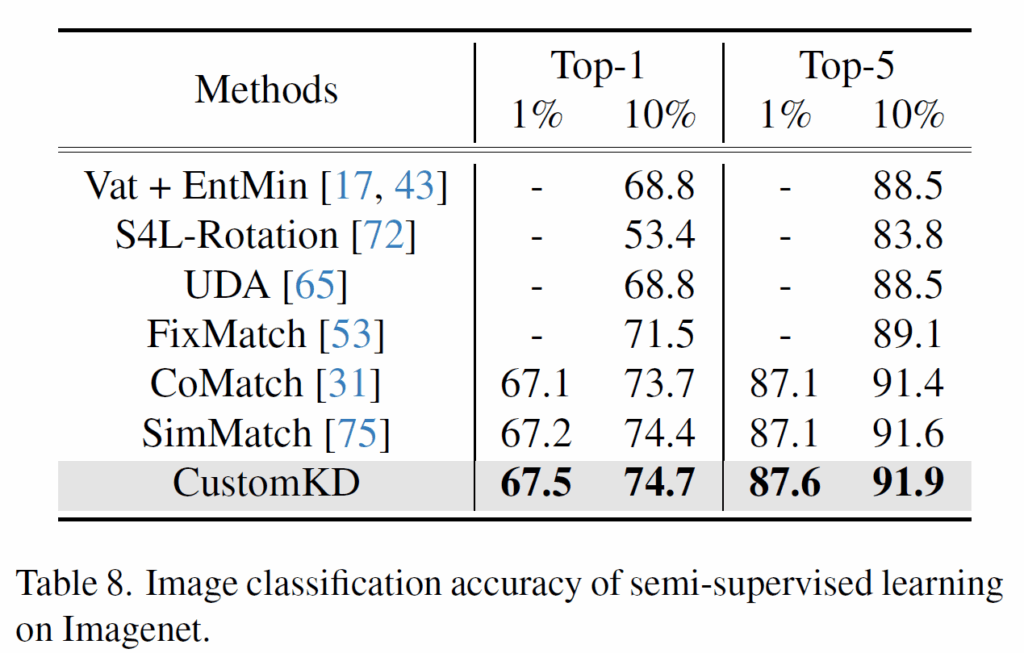
다음은 ImageNet에서의 성능인데요, 다른 방법론들과 비교하면 가장 좋은 성능을 보여주기는 하는데, 사실 이전 방법론들 대비 성능 향상이 그리 드라마틱하지는 않은 것 같아서 아쉽네요. 그래서 그런지 저자들도 해당 실험 결과는 main paper에서 넣지 않고 서플로 빼버린 것 같아요. (분량상의 이유를 들면서 빼기는 했지만 성능이 드라미틱하게 올라갔어도 뒤로 뺏을지..?ㅋㅋ)
Ablation study
다음은 ablation study에 대한 내용입니다. 아까 method 섹션에서 KD 할 때 사용했던 loss 함수들을 다시 복기해보면 커스터마이징된 선생 모델의 feature map과 student model 사이에 차이를 계산하던 \mathcal{L}_{\tiled{f}_{t}} 가 있고 (수식2), teacher model의 feature map 자체를 학습하기 위해서 student model을 커스터마이징한 뒤 오차를 계산하던 목적 함수 \mathcal{L}_{f_{t}} 가 있었습니다 (수식3).
저자들의 방법론 중 가장 큰 contribution을 가지는 것은 결국 이 선생 모델의 특징맵을 커스터마이징하는 것이기 때문에 수식2번의 loss가 얼만큼의 KD 성능에 영향을 미쳤는지에 대하여 실험을 진행하였습니다.
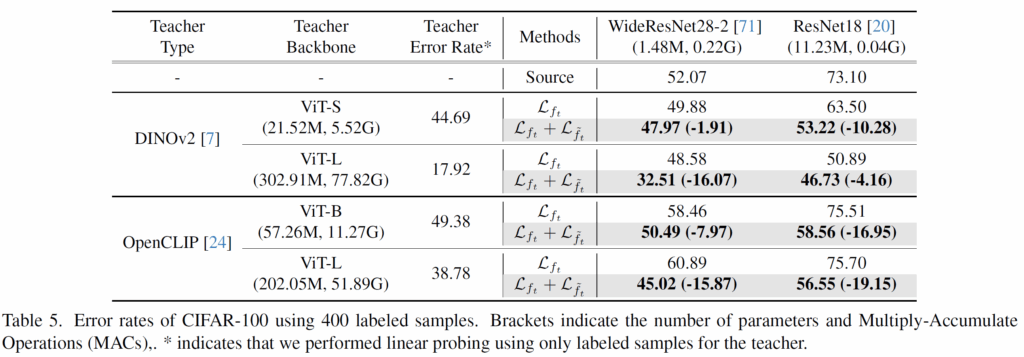
task는 SSL이고 CIFAR-100에 대하여 400개의 labeled sample로 학습하였을 때의 결과를 의미합니다. 에러율이기 때문에 값이 낮을수록 성능이 좋아지는 것인데, 수식3을 단독으로 사용하였을 때보다 수식2를 추가하여 KD하였을 때 학생 모델이 더 높은 성능을 달성하는 것을 보여주었습니다.
특히나 WideResNet의 경우에 단순히 수식3을 적용하였을 경우 선생 모델이 small에서 large로 커졌을 때 학생 모델의 성능 개선 폭이 크지 않거나 오히려 떨어지는 반면에 커스터마이징과 관련된 수식2가 적용되면 매우 큰 성능 개선이 이루어지는 것을 파악할 수 있습니다.
저자들은 수식3의 방식은 단순히 학생 모델의 특징을 선생 모델의 특징에 모방하도록 학습이 되다보니 선생 모델의 크기가 클수록 그 복잡함을 단순 모방하는 방식으로는 제대로 이해하고 파악할 수 없어서 성능에 이점이 되지 않았지만, 커스터마이징 과정 및 이를 통한 지식의 전이를 통해 더 효과적으로 학습이 가능하였다는 식의 주장을 펼치고 있습니다.
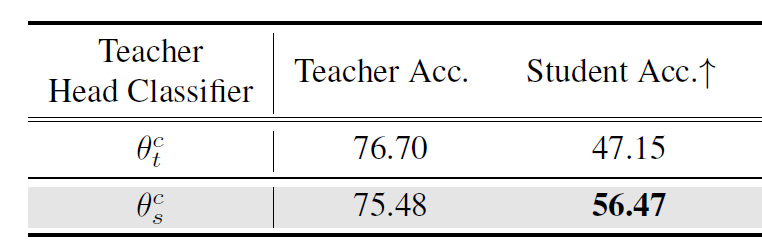
또한 커스터마이징 단계에서 사전학습된 학생 모델의 분류기를 사용하여 선생 모델의 특징을 커스터마이징하도록 학습하게 되는데, 이때 사전학습된 학생 모델의 분류기가 아닌 단순히 랜덤하게 초기화된 분류기를 사용하게 될 경우 어떻게 되는지를 실험한 결과입니다. 결론만 말씀드리면 학생 분류기를 사용할 경우 그렇지 않을 때보다 UDA task에서 학생의 성능이 8%가량 더 올라간다고 합니다.

위에 표 좌측은 맨 처음 ablation study와 비슷하게 loss function에 따른 distillation 성능을 ablation한 것인데, UDA task를 기준으로 다시 진행한 것 같습니다. 결과적으로 수식2번의 커스터마이징 관련 loss가 상당히 지대한 영향을 끼친다는 것이 포인트라고 이해하시면 될 것 같습니다.
그리고 우측은 커스터마이징 단계와 KD 단계가 몇에포크 기준으로 수행되는 것이냐인데 결과적으로는 1:1 비율로 번갈아가는 것이 가장 좋은 성능을 달성했다고 합니다. 즉 1에포크는 커스터마이징을 위한 projection layer만을 학습시키고 그 다음 에포크에서는 student model을 학습시키는 방식을 의미합니다.
결론
방법론이 직관적이고 단순합니다. 그리고 좋은 성능을 달성하였기 때문에 좋은 평가를 받아서 CVPR에 게재된 것이 아닐까 싶습니다. 다만 ImageNet에서의 성능도 그렇고 특정 방법론에 적용하는 상황에서는 성능 향상의 기대치가 매우 낮아서 아쉬움이 존재합니다. 그리고 저자들도 논문에 언급했듯이 실험결과가 image classification으로 한정되어있습니다. 따라서 semantic segmentation과 같은 pixel-level task에서 해당 방법론을 어떻게 녹여넣을지가 불분명하긴 한데 사실 방법론 자체가 그리 어렵지는 않아서 마음만 먹으면 해당 논문의 컨셉을 쉽게 녹일 수는 있습니다. 다만 성능이 얼만큼 개선이 될지에 대해서는 여전히 불확실성이 큽니다.
CIFAR100과 같은 단순한 데이터 셋에서의 성능 이점은 크지만 아까도 이야기했다시피 ImageNet에서의 성능 향상이 미미한 상황에서 데이터의 분포나 task마저 복잡한 pixel-level prediction task로 넘어가게 될 경우 해당 방법론의 컨셉이 얼만큼 잘 동작할 수 있을지 예측하기가 어렵네요.
그럼에도 직관적인 아이디어를 잘 녹여서 다양한 실험 결과를 보여주었다는 점에서 만족스러운 논문이었습니다.
안녕하세요 신정민 연구원님, 흥미로운 논문 리뷰해주셔서 감사합니다.
학습의 순서를 읽던 중 궁금한것이 생겨 댓글을 남깁니다!
stduent 모델은 소량에 labeled datasets에 대해 학습한 후 unlabeled에 대해 학습한다고 소개해주셨는데, 실험에서 unlabeled data가 어떻게 정의되는지 궁금합니다. 예를 들어 10%의 데이터가 labeled data로 사용되었다면, 나머지 학습 데이터는 모두 unlabeled data로 가정하고 학습에는 사용하게 되는것일까요?
감사합니다
네 나머지 학습 데이터를 모두 unlabeled data로 보는게 맞습니다.