제가 이번에 리뷰할 논문도 Object Pose Estimation에 관한 논문입니다. 해당 논문의 저자도 제가 이전에 리뷰했던 논문의 저자로, 지난주에 리뷰한 NOPE에서 베이스라인으로 삼았던 논문입니다.
Abstract
로보틱스와 AR에서는 실제 응용을 위해 사전 지식 없이 새로운 객체에 대한 상대 pose를 추정할 수 있어야 합니다. 본 논문에서는 학습이나 3D 기하학정보( CAD 모델 및 depth정보) 없이 RGB 비디오 내의 객체에 대한 6D Tracking 방법론을 제안합니다. 기존 6D Tracking연구와 다르게 학습이나 사전 지식 없이, open-world에서 unknown 객체에 대응이 가능하도록 하였으며, 이전 프레임의 정보를 활용 가능한 Transformer Encoder 기반의 네트워크 구조를 제안하였습니다. 저자들이 제안한 방법론은 unknow객체에 대하여 추가적인 정보(대상 객체에 대한 학습 데이터/3D 모델/depth 데이터 등)가 필요한 기존 방법론들과 비교하였을 때 대등한 성능을 보임을 실험적으로 확인하였다고 합니다.
Introduction
open-world를 고려한 6D 연구의 필요성 및 기존 연구
실세계에서 활용을 고려할 때, 미학습 객체에 대해서도 pose 변화를 추정할 수 있어야 합니다. 그러나 기존의 연구들은 annotation된 대용량 학습 데이터가 요구되었으며, 합성 데이터를 이용하기 위해서도 3D 모델과 학습 과정이 필요합니다. 즉, 임의의 객체인 Unknown 객체에 대해서는 대응하기 어려웠습니다.
최근 미학습 객체에 대한 인식을 위한 연구들이 수행되었으나, 여전히 3D 모델이 필요하다는 조건이 있습니다. 3D 모델은 open-world에서 접근이 불가능한 경우가 많으므로 본 논문에서는 이를 한계로 보았습니다. 또한, 동일 카테고리에 속하는 객체들로 학습하여 새로운 객체에 대한 3D 모델이 없이 pose를 추정하는 연구도 있지만, 이는 새로운 객체가 학습한 객체 카테고리에 포함되어야 한다는 제약이 있습니다. 즉, unknow이 아니라는 것 입니다.
일부 연구들은 3D 모델을 이용하지 않고 pose를 추정하는 연구를 수행하였습니다. 여러 시점에서 촬영한 multi-view의 reference 영상들을 이용하는 방식으로, 이러한 방법론들은 학습 과정이 필요하며, 일부는 depth 정보도 필요하였습니다. 이처럼, RGB 영상만을 활용하여 unknown 객체의 6D pose를 추정하는 방식은 해결이 되지 않았습니다. 따라서 저자들은 3D 모델을 이용하지 않고, 학습을 수행하지 않으면서 Unknown 객체에 대한 pose를 추정하는 연구를 수행하였습니다.
저자들이 제안한 Transformer 기반의 방법론
저자들은 PIZZA(Powerful Image-only Zero-shot Zero-CAD)라는 방법론을 제안하였으며, 이전의 프레임 정보들을 활용하기 위해 Transformer Encoder를 이용하였다고 합니다. (기존 tracking 연구에서는 바로 이전의 프레임만을 고려하였다는 점에서 차별점으로 언급합니다.) Transforemr기반의 방법론을 통해 6D Pose를 구하고 재귀적으로 모든 프레임을 초기 pose와 함께 활용할 수 있도록 하였고, 실험을 통해 여러 frame을 활용함으로써 drift(추정값이 갑작스럽게 크게 변하는 문제라고 이해하시면 됩니다)가 크게 줄어듦을 확인하였다고 합니다.
Unseen segmentation의 도입 필요성 및 장점
또한, 저자들은 이전의 자신들의 연구를 통해 지저분한 배경에서는 unseen 객체에 대한 정확도가 떨어짐을 확인하였으며, 복잡한 배경으로 학습하는 것이 seen 객체에서는 유효하지만(배경이 복잡하게 변해도 대상 객체는 공통된 특징을 학습할 수 있음) unseen객체에 대해서는 유효하지 않음도 확인하였다고 합니다. 이러한 문제를 해결하고자 최근의 2D Unseen Instance Segmentation 연구를 이용하였다고 합니다. 많은 객체에 대한 학습을 통해 segmentation은 일반화 성능이 크게 증가하여 Unseen 카테고리에서도 잘 작동하므로, 이를 이용하여 마스크를 생성한 뒤 pose를 추정합니다. 이때 마스크에 노이즈가 포함되더라도 pose 추정 결과는 크게 개선됨을 확인하였다고 합니다.
학습 및 평가 방식
본 논문에서는 먼저 CAD모델로 합성 데이터를 만들어 평가를 수행하였으며, 이후 BOP challenge의 합성 데이터로 학습한 뒤 real 데이터로 평가하여 SOTA 방법론들과 성능을 비교하였다고 합니다. 또한, Domain Randomization과 realistic한 렌더링을 통해 합성에서 Real 데이터로 일반화가 잘 이루어지도록 하였으며 저자들이 제안한 방법론을 통해 새로운 객체 카테고리로의 일반화가 가능하도록 하였다고 이를 실험적으로 검증하였습니다.
저자들에 따르면, 해당 논문이 처음으로 학습 및 테스트에 3D 정보를 활용하지 않고 RGB 이미지만을 이용하여 학습한 적 없는 카테고리의 객체로의 일반화가 가능하도록 제안된 방법론이라 합니다.
Methods
저자들은 첫 프레임에서 인식하고자 하는 객체에 대한 2D bounding box를 제공하며, 배경에 대한 영향을 줄이기 위해 segmentation을 수행하여 mask를 생성합니다.
1. 2D Unseen Object Tracking and Segmentation
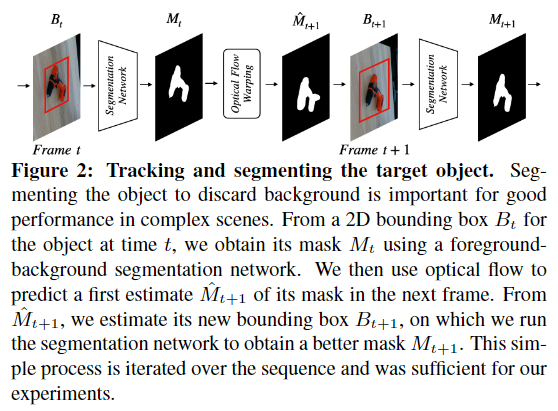
위의 [Figure 2]가 pose 추정을 위해 객체 영역과 mask를 생성하는 과정으로, 첫 프레임에서 Bounding box B_0가 주어졌을 때, Segmentation(2D Object Tracking인 Place Solution for the UVO Challenge에서 1등한 segmentation 방식)을 적용하여 Mask M_0를 생성합니다. 이후 M_0에 대해 optical flow(RAFT를 적용하였다고 합니다. 해당 방법론에 대해서는 정민님의 X-review를 통해 더 자세한 내용을 확인하실 수 있습니다)를 적용하여 다음 프레임에 대한 임시 Mask \hat{M}_1를 생성한 뒤 해당 영역에 대하여 BBox B_1를 구하고 앞선 과정을 반복합니다.

K개의 frame에 대하여 위의 과정을 반복한 뒤 모든 프레임의 Bounding box를 포함할 수 있는 가장 작은 영역으로 Crop한 뒤, masking을 적용하여 배경에 대한 영향을 제거한 6D Pose Tracking이 가능하도록 합니다. 이렇게 잘린 이미지를 local frame이라 표현합니다.
2. Estimating the 3D Relative Translation
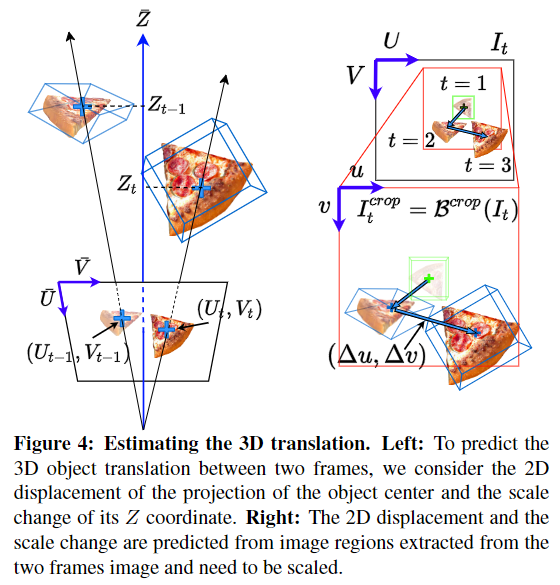
<parameterization of 3D Relative Translation>
t-1과 t 프레임 사이의 상대 translation은 \Delta \mathbf{T}_{t-1,t}=\mathbf{T}_{t}-\mathbf{T}_{t-1}, ∈\mathbb{R}^3로, \mathbf{T}_t는 카메라 좌표계를 기준으로 각 object의 center좌표이며 아래의 식으로 정리할 수 있습니다.
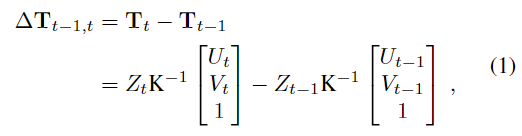
- Z_t: depth 정보
- (U_t,V_t): 객체 중심이 이미지 프레임I_t로 투영된 픽셀의 좌표
- \mathbf{K}: 카메라 intrinsic 파라미터
이때, 앞서 mask를 생성하는 과정에서 optical flow를 통해 mask를 예측하였으므로 (\Delta U_{t-1,t}, \Delta V_{t-1})를 예측하는 것이 더 쉬우며 아래의 식(2)로 정리할 수 있습니다.
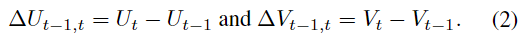
또한 depth 정보를 활용하지 않으므로 depth에 대한 offset을 아래의 식(3)과 같이 정규화하며, S_{t-1,t}는 실제로 0에 가까운 값을 갖는다고 합니다.(아무래도, 연속적인 프레임이다보니, depth값이 크게 차이가 나지 않는다는 점을 통해 depth를 활용할 수 없는 한계를 극복하고자 한 것으로 보입니다.)
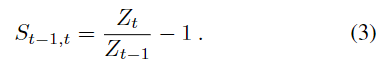
저자들은 배경의 영향을 제거할 뿐만 아니라 translation에 대한 영향을 줄이기 위해서 피사체가 이미지의 중심에 위치할 수 있도록 제한하는 것이 중요하다고 합니다. 스케일링된 crop 영역에서의 2D 좌표 변화량 (\Delta u, \Delta v) 는 crop된 영역의 크기와, scaling에 사용한 파라미터(\alpha_{u},\alpha_{v})를 이용하여 식 (4)와 같이 정의하며,
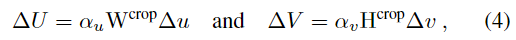
네트워크는 depth offset인 s도 예측하며 이를 활용하여 다시 아래의 식으로 스케일링을 수행합니다.

<Recovering \Delta \mathbf{T}_{t-1,t} and \mathbf{T}_{t} >
\mathbf{T}_{t-1}을 알고 있을 때, \Delta U, \Delta V, S를 통해 \Delta \mathbf{T}_{t-1,t}와 \mathbf{T}_t를 추정할 수 있습니다. 저자들은 기존 연구와 동게 첫번째 위치에 대한 \mathbf{T}_{1}을 알 수 있다고 가정하며, 실제 시나리오에서는 depth를 이용할 수 없는 경우 임의의 양수 값으로 Z_1을 설정하고 이후 궤적을 통해 scale factor를 복원하였다고 합니다.
crop된 이미지 I_{t-1}^{crop}과 I_{t}^{crop}로부터 (\Delta u_{t-1,t}, \Delta v_{t-1,t}, s_{t-1,t})를 예측한 뒤, 식 (4)를 통해 local 좌표를 이미지에서의 픽셀 좌표로 변환한 뒤, 식(2)를 통해 객체의 중심 좌표를 구하며, 식(3)을 통해 depth값을 구합니다. 이후 식(1)을 이용하여 두 프레임 사이의 3D translation vector를 구합니다.
<Translation Loss>
Translation에 대한 loss는 L1 loss를 이용하여 아래의 식(6)으로 정의합니다. 두 프레임 사이에서 대상 객체의 3D 이동은 2D에서의 offset과 scale 계수로 파라미터화됩니다.
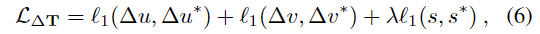
- ^*: GT값
- \lambda: 실험적으로 1로 설정하였다고 합니다.
3. Estimating the 3D Relative Rotation
<parameterization of 3D Relative Rotation>
상대 rotation은 더욱 간단하게 파라미터화가 가능합니다. I_{t-1}과 I_t 사이의 \Delta \mathbf{R}_{t-1,t}∈SO(3)은 아래의 식(7)로 정의되며,
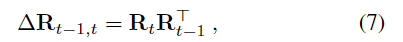
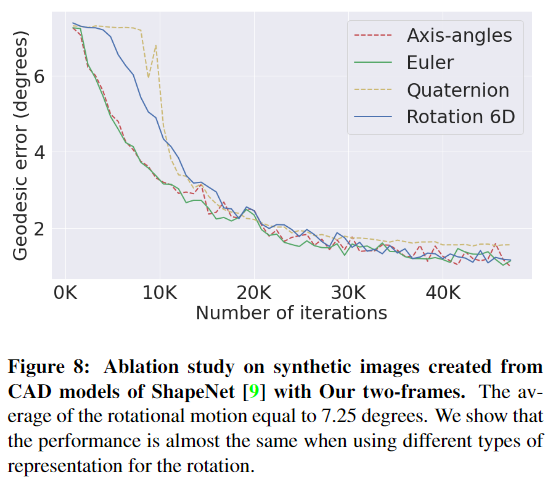
rotation을 표현하는 다양한 방식이 있으며, 이에 대해서는 실험을 통해 axis-angles 방식(각 축에 대한 회전 각도로 표현하는 방식)을 채택하였다고 합니다.(이에 대한 실험은 아래의 [Figure 8]에 나타나있습니다.) rotation vector \omega∈\mathbb{R}^3는 축에 대한 각도로 표현하며 ||\omega||와 \omega/||\omega||는 rotation각도와 축을 의미합니다.
** rotation에 대한 표현을 위해 다양한 방식으로 ablation 실험을 하였고 학습될 경우 대부분이 비슷한 성능을 보이는 것을 확인하였으며, axis-angles(축에 대한 회전각도로 표현하는 방식) 방식을 채택하였다고 합니다.
<Rotation Loss>
각도에 대해 학습하기 위해 L2 loss를 적용하여 아래의 식(8)로 정의하였다고 합니다.
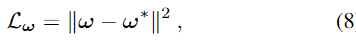
<Recovering \mathbf{R}_t>
\mathbf{R}_{t-1}를 알 때, \Delta \mathbf{T}_{t-1,t}를 추정하면 \mathbf{R}_{t}를 구할 수 있으며, 기존 연구와의 비교를 위해 첫번째 frame의 \mathbf{R}_{1}는 알려져 있다고 가정합니다. 그러나 실제 시나리오에서는 3D 모델이 없으므로 첫번째 프레임에서의 rotation을 정의할 수 없으므로 항등 행렬과 같이 임의의 행렬로 설정하였다고 합니다.
4. Proposed Architecture
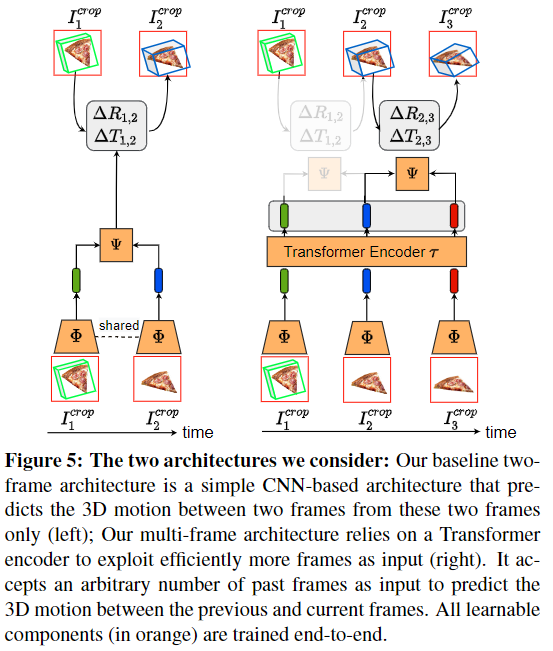
여러 frame에서의 정보를 효율적으로 통합하기 위해 위의 [Figure 5]와 같이 연속적인 frame을 입력으로 받아 두 frame 사이의 pose를 예측합니다. 먼저 crop된 이미지에 대하여 ResNet18을 적용하여 임베딩 feature를 추출한 뒤, 이를 Transformer Encoder를 통해 또다른 임베딩 spaced로 투영합니다. 이때 Transformer Encoder \mathcal{T}를 통해 self-attention을 적용하므로써 frame사이의 상관 관계를 강화하였습니다.
그 다음, t-1과 t 프레임 사이의 상대 pose를 예측하며 이는 아래의 식(10)으로 정의됩니다. 이때, \Psi는 rotation과 translation에 대하여 각각 3개의 MLP layer로 구성된 Regressor \Psi_{\mathbf{R}}과 \Psi_{\mathbf{T}}입니다.
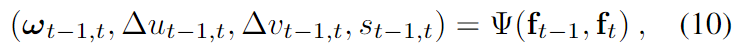
아래의 [Figure 9]와 [Figure 10]은 Transformer Encoder와 Regressor 구조입니다. 네트워크 구조에서는 새롭게 제안된 부분은 없어보입니다.
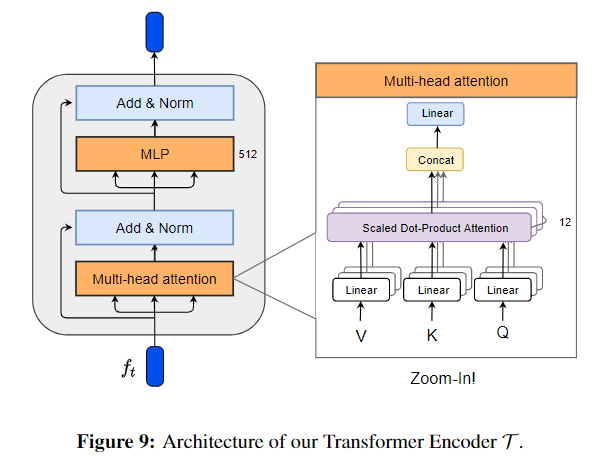
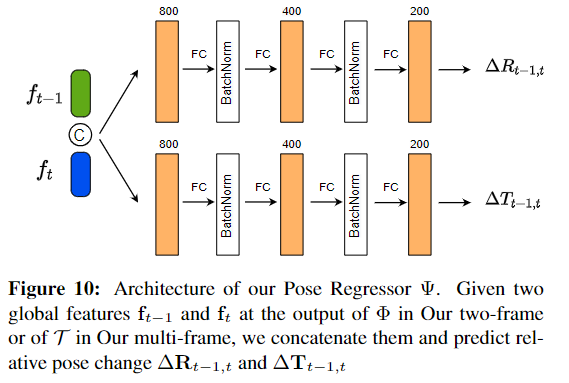
네트워크는 앞서 정의한 loss를 활용하여 end-to-end로 학습됩니다.
6D Tracking
6D Tracking 알고리즘을 pseudo code로 표현하면 아래와 같습니다.

n개의 프레임에 대하여 ResNet18과 Transformer Encoder를 통해 feature로 임베딩 한 뒤, Rotation과 Translation regressor에 입력하여 rotation offset과 2D 이미지에서의 offset, scale값을 예측한 뒤, 식(4,2,3,1)을 통해 3D Translation을 복원하고 오차를 활용해 Rotation 값을 복원한다.
Experiments
Unseen 카테고리에 대한 일반화 능력을 평가하기 위한 실험을 수행합니다. CAD 모델을 이용하는 방법론(DeepIM, MultiPath, MoveIt)과 RGB-D데이터를 입력으로 사용하고 CAD 모델을 이용하는 방법론(LatentFusion, Laval)과 비교를 수행합니다. LatentFusion은 pose 추정 전에도 3D feature를 구하기 위해 depth map과 reference 이미지를 사용합니다.
해당 논문은 다양한 방법론과의 비교를 위해 다양한 데이터에서 여러 평가지표를 이용하여 실험을 진행합니다.
1. Experimental Setup
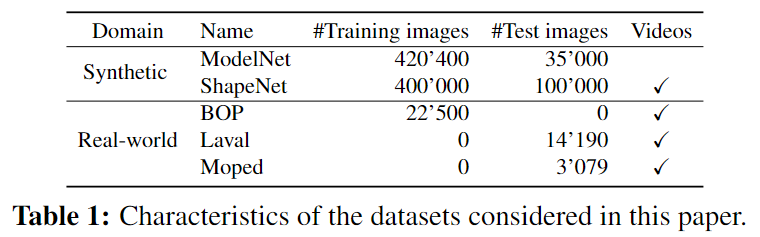
Table 1에 사용하는 데이터의 특징이 요약되어있습니다.
- Synthetic Datasets
- 기존 연구 따라 ModelNete의 CAD 모델을 이용하여 합성 데이터를 생성합니다. 대상 view는 일정한 translation t=(0,0,500mm) 변화를 주고 임의의 rotation을 적용하여 렌더링합니다. 이후 추가적으로 각 축에 대하여 ±15° 이내의 임의의 값으로 rotation을 주고 x,y축으로 ±10mm, z축으로 ±50mm 이내의 임의의 값으로 translation을 적용하여 새로운 view를 만들어냅니다.
- 이전 방식은 이미지 쌍만으로 모델을 평가하였지만, 해당 논문에서는 sequence 전체에 대한 성능을 평가하기 위해 ShapeNet의 CAD 모델을 이용하여 multi-view로 일반화하여 평가를 수행합니다. 이를 위해 합성 데이터를 생성하였으며, 첫번째 프레임은 t=(0,0,Z)로 무작위로 렌더링하고, Z는 0.4~2m를 균일하게 샘플링하고 rotation은 임의의 값을 적용하여 합성 데이터를 생성합니다. 추가로 각 축에 대하여 ±20°, ±20 mm이내의 임의의 변화를 주어 CAD모델마다 1000개의 frame을 생성합니다.
- Real Datasets
- 2개의 real 데이터를 이용하여 평가를 수행합니다.
- Laval데이터는 11개의 real object를 3개의 시나리오에서 촬영한 297 sequence로 구성됩니다.
- MOPED 데이터는 11개의 가정용 object로 구성됩니다.
Evaluation Metrics
- (k°,k cm): pose 오차가 k° 이내이고 k cm 이내일 경우 정답으로 간주함.
- ADD(-S): GT pose 와 예측 pose를 이용하여 랜더링 한 뒤, 포인트 사이의 거리를 측정하는 방식이며, 대칭 객체에 대해서는 가장 가까운 점 사이의 거리를 측정.
- Proj.2D: GT와 예측 Pose를 2D로 투영하였을 때, 픽셀의 오차 측정.
- Error: 15개 프레임의 모든 sequence에 대한 GT와 예측 pose 사이의 geodesic error와 translation error
2. Evaluation on Synthetic Dataset
- Results on ModelNet
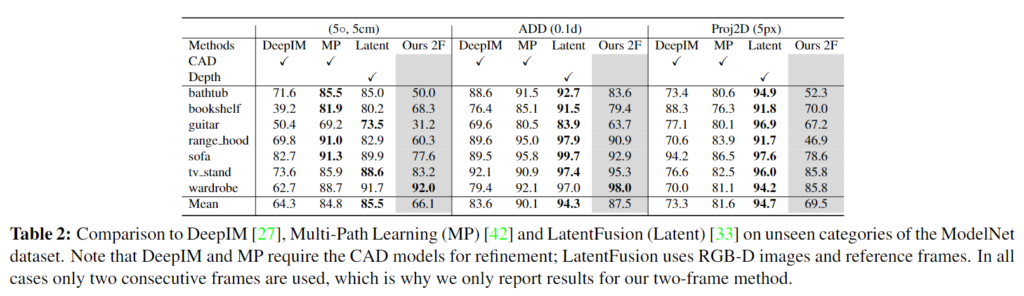
위의 Table 2는 합성 데이터에 대한 평가 결과로, DeeIM과 MultiPath(MP)는 사전에 CAD 모델을 이용하여 학습을 수행하며 LatentFusion은 test 과정에 depth 정보에 의존합니다. 이에 반해 해당 논문에서 제안한 방식은 RGB 이미지만을 입력으로 사용하며, 훨씬 적은 정보를 활용함에도 불구하고 ADD(-S)에 대하여 기존 방법론과 유사한 성능을 달성함을 확인할 수 있습니다. 또한 (5°,5 cm)에 대한 결과는 지도학습 기반인 DeepIM보다 더 좋은 성능을 보이며, 반복적인 refinement를 수행하는 DeepIM과 MP 방법론과 비교할만한 성능을 달성하였음을 어필합니다.
- Results on ShapeNet

위의 Table 3은 ShapeNet에 대한 실험 결과로, 2F는 두개의 프레임 정보만을 이용하는 방식, MF는 이전의 여러 프레임 정보를 모두 이용하는 방식입니다. 해당 실험을 통해 multi-frame을 활용할 경우 모든 Unseen 카테고리에서 개선된 성능을 보임을 나타내며, 이를 통해 multi-frame Transformer 네트워크의 효과를 입증하였습니다.
2. Evaluation on Real-World Dataset
- Results on Laval
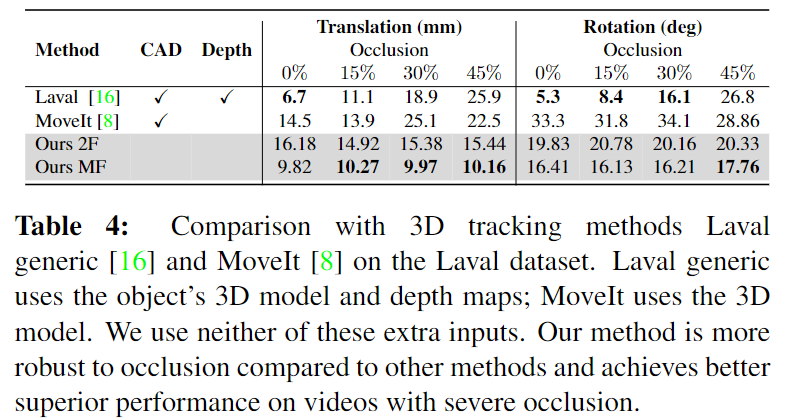
최신 방법론인 Lavalgeneric과 MoveIt과 비교를 수행한 것으로, 기존 연구의 프로토콜을 활용하여 평가를 수행합니다. 위의 Table 4가 이에 해당하며, 2개의 frame을 이용하는 방법론(Ours 2F)과의 비교를 통해 CAD 모델과 Depth 정보를 활용하지 않고도 좋은 성능을 달성하였음을 보이고, 다중 frame을 이용할 경우 성능이 더욱 개선됨을 보이고자 하였습니다. 저자들이 제안한 방식은 항상 좋은 성능을 보이지는 않았으나, occlusion이 심해질 경우의 성능 저하 정도가 작다는 점을 통해 occlusion에 강인하다고 주장합니다. (아래의 [Figure 7]의 1행을 통해 정성적 결과를 확인하실 수 있습니다.)
- Results on MOPED
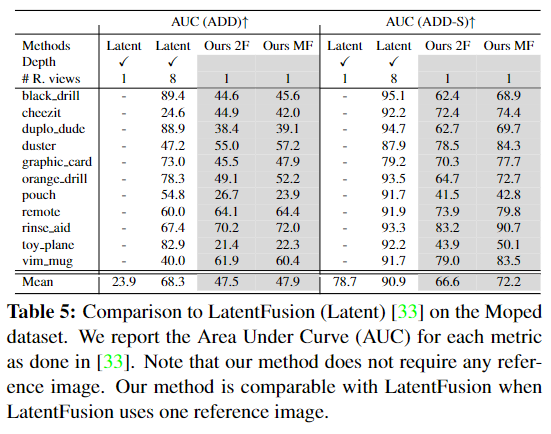
Table 5는 Moped 데이터 셋에 대한 정량적 결과로 LatentFusion과 비교하였을 때, 1개의 reference 프레임을 이용할 경우 비슷한 성능을 보이며, LatentFusion이 8개의 프레임을 이용할 경우에는 약 20% 성능 차이가 발생합니다.
Limitations
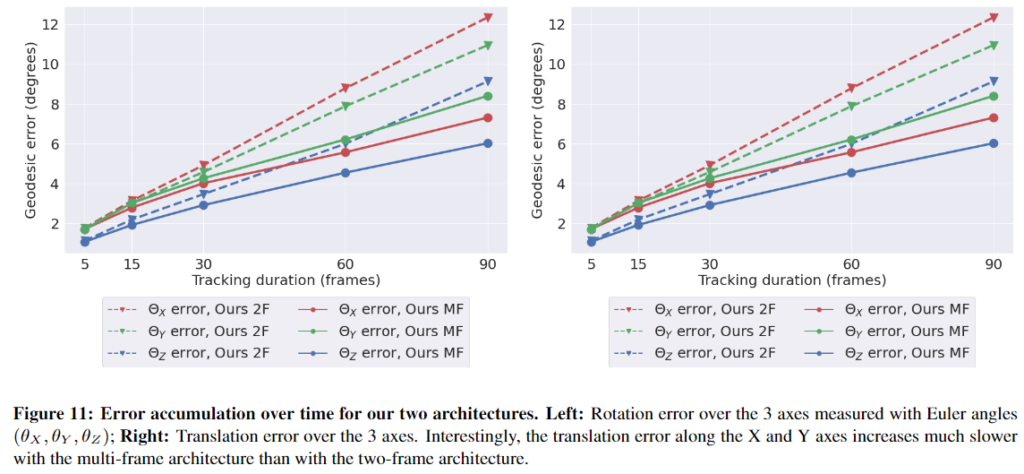
- 저자들에 따르면 다른 축에 비해 Z축에 대한 translation오차가 크다고 합니다. 이는 6D Pose Estimation에서 흔히 발생하는 결과로, scale 정보를 추정하기 어렵기 때문입니다. 이를 저자들은 한계라고 언급합니다.
- 두번째 한계는 해당 방법론이 segmentation을 적용한 결과를 입력으로 사용하기 때문에, segmentation이 실패할 경우에는 pose 추정도 불가능하다는 것 입니다. 그러나 저자들은 실험적으로 segmentation이 강인하게 작동하였으며, 노이즈가 있어도 강인하게 작동한다고 주장합니다.
해당 방법론은 새로운 객체에 대한 학습 및 CAD 모델을 사용하지 않았다는 점에서 contribution을 인정 받았습니다. 다양한 세팅에서 기존 방법론들과의 비교를 통해 자신들의 방법론이 추가적인 데이터 없이도 작동 가능함을 실험적으로 보였으나, 이에 대한 분석이 부족하여 아쉽습니다. 그리고 object가 중심에서 크게 벗어나지 않아야 한다는 제약 조건과 clutter한 환경에서 잘 작동하도록 배경에 대한 영향을 줄이기 위해 Segmentation을 수행한다고 하였는데, 실험한 환경은 clutter하지 않아서 실험 세팅이 아쉬웠습니다. 실험 결과에 대한 추가적인 정성적 결과는 supplementary에 확인하실 수 있습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
본 논문의 연구 방향이 3D 모델을 이용하지 않는 연구를 수행한다고 말씀해주셨는데 이 3D 모델과 논문에서 사용한 CAD 모델은 다른건가요 ?? 3D 모델을 사용하지 않았다는 것은 결국 depth 정보를 이용하지 않고 RGB 이미지만으로 pose를 추정했다고 이해해야 할까요 .. ?
그리고 결국 추정하는 pose는 이전 프레임 대비 변화하는 상대적인 pose를 추정한다고 저는 이해했는데, 그런 관점에서 바로 이전 프레임 뿐만 아니라 여러 시점의 프레임을 모두 사용하는 것이 어떤 점에 있어서 효과적일 수 있는지 저자의 고찰이나 혹은 승현님의 생각이 궁금합니다 !
감사합니다.
질문 감사합니다.
우선 3D모델과 논문에서 사용한 CAD모델은 동일한 의미입니다. 학습 과정에 CAD를 전혀 사용하지 않는 것이 아니라, 새로운 객체에 대해서 CAD모델이 없더라도 pose를 추정할 수 있도록 한 것입니다. 또한, 이야기하신대로, depth 정보도 활용하지 않고 RGB 비디오(연속적인 프레임)만을 이용하여 상대 pose를 추정합니다.
또한, 여러 프레임을 사용하는 것이 어떤점에서 효과적일 수 있는 지에 대해서 질문해주셨는데, 물론 비디오 내에서 객체의 pose가 갑작스럽게 크게 변할 경우도 존재하겠지만, 그렇지 않은 경우가 많고, 대략적으로 translation/rotation 변화 정도를 고려할 수 있다는 점에서 효과적이라고 생각합니다.