안녕하세요. 이번 주는 논문 리뷰가 아닌, OWOD 논문의 코드 리뷰를 진행해보고자 합니다. 제가 OWOD (Open World Object Detection)에 관한 연구를 진행하고 있음은 다들 아실텐데요, 본 글의 제목인 Towards Open World Object Detection (통칭 ORE)는 OWOD를 처음 제안한 논문입니다 (본 논문의 리뷰는 김태주 연구원님께서 해주었습니다). 하지만 ORE는 Detectron2 프레임워크를 활용하는데, 이 프레임워크는 코드에 대해 추상화가 되어 있어 처음 보는 이들은 코드의 구성을 이해하기에 꽤나 어렵습니다. 그렇기에 1. OWOD의 학습 및 평가 프로토콜이 궁금하셨던 분들을 위해 2. Detectron2 프레임워크가 무엇인지에 대해 궁금하신 분들을 위해 3. 이런 코드 구성을 만나면 코드를 어떻게 뜯어보지? 이슈들에 대해서는 어떻게 대응하지? 하시는 분들을 위해, 또는 등등의 이유로 코드 리뷰를 진행해보고자 합니다.
본 리뷰는 1. Detectron2 프레임워크에 대해 소개한 다음 2. ORE의 학습 및 평가 과정을 간편히 살펴보고 3. 이슈 발생 시 대응법 등에 대해 공유해보고자합니다. 물론 연구실의 많은 분들이 저보다 코딩에 뛰어나며 경험이 많은 것을 알기에, 본 글을 한 번쯤 편안하게 보셨으면 하는 바램입니다.
1. Detectron2

그렇다면 Detectron2가 무엇일까요? “Detectron2란?”의 문구로 구글링하면 다음과 같은 설명을 볼 수 있습니다.
detectron2란 FAIR(Facebook Artificial Intelligence Research)에서 만든 pytorch 기반 object detection과 sementic segemanation을 위한 training/inference 플랫폼으로 Detectron2를 이용해 학습을 하게 되면, 우리가 일반적으로 딥러닝 모델을 짤 때 구현하던 training loop를 짜지 않고 engine을 이용하여 학습 과정을 추상화 할 수 있어, 연구자 혹은 개발자는 모델 개발 자체에만 집중할 수 있다.
줄이자면 Detectron2는 object detection 등의 vision perception 태스크를 위해 Meta에서 제작한 오픈소스 인공지능 플랫폼입니다. Detectron2는 engine을 이용하여 학습 과정이 추상화되어 있다고 설명되어 있는데, 이는 추후 소개하는 코드와 그 구성을 보시면 이해하실 수 있습니다. 그렇다면 우리는 이 추상화를 왜 이해하기 어려울까요? 우리는 연구 시 주로 파이썬 언어를 사용하며 이 파이썬 언어도 물론 객체 지향 언어긴 하지만, 제가 생각하기엔 C++, Java와는 달리 객체 지향적 프로그래밍을 다소 덜 사용합니다. 객체 지향에 대해선 어떤 개념인지 잘 알고 계시겠지만, (제가 예전부터 아버지한테 객체 지향 언어의 장점에 대해 귀아프도록 들었기 때문에) 짚고 넘어가자면 객체 지향 언어는 1. 추상화 2. 상속 3. 캡슐화 4. 다형성의 특성을 가지고 있으며 5가지 원칙 (단일, 개방/폐쇄, 대체, 인터페이스 분리, 의존성 역전)을 가지고 있는 언어를 객체 지향 언어로 부릅니다.
이 때, 적어도 제 생각에는 파이썬 코드 (현재 말하는 파이썬 코드란 아무래도 우리가 익숙한 딥러닝 관련 코드를 말합니다)는 객체 지향 언어의 4가지 특성을 충분히 활용하지 않고 있습니다. 물론 4가지 특성을 사용함 자체는 불가능하지 않습니다. 먼저 추상화는 @abstractmethod 데코레이터를 활용하여, 상속은 우리가 많이 쓰는 예시로 모델 선언 시 nn.Module을 상속받는, 캡슐화의 public, protected, private, 다형성의 오버라이딩과 오버로딩, 물론 모두 쓸 수 있습니다. 하지만 위 객체 지향적 프로그래밍 방법을 자주 사용하지 않고 C++과는 달리 명시적인 헤더 파일 (.h)을 활용하지 않아 저는 곰 (객체 지향)의 탈을 쓴 여우라고 느낍니다. 그렇기 때문에 우리는 CustomDataset의 코드를 작성 시 torch.utils.Dataset을 상속받으면서도 해당 라이브러리에서 상속받은 __len__, __getitem__이 어떻게 작동하는진 알지, 라이브러리에서 상속받았기 때문에 해당 코드를 구경해볼 생각은 크게 하지 않습니다. 물론 우리가 해당 코드/라이브러리를 만든 이가 아닌 사용하는 유저의 관점이기에 잘못되었다, 꼭 해야한단건 아니죠. 다만 그렇다보니 추상화된 코드에 대해 이해하기 쉽지 않습니다.
실제로 ORE 논문의 Github를 간단히 살펴보겠습니다.

파이썬 파일 (.py) 하나 보이지 않은 채 폴더와 쉘 스크립트로만 구성되어 있습니다. 저자는 모델의 학습을 위하여 다음의 과정을 따르도록 지도합니다.
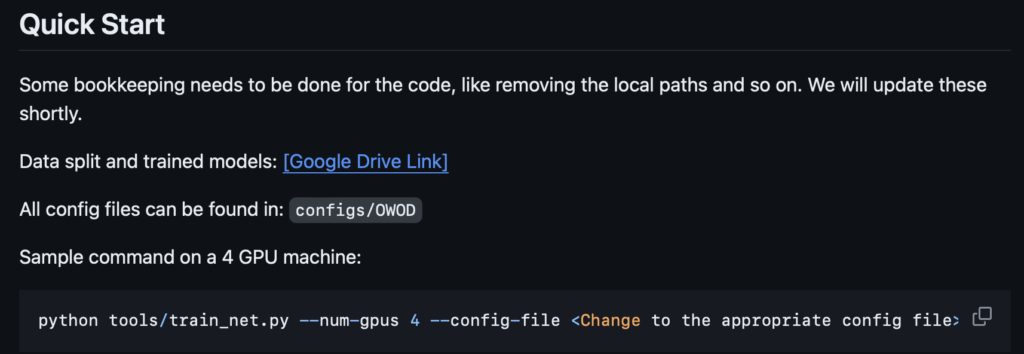
python tools/train_net.py –num-gpus 4 –config-file <Change to …> SOLVER.IMS_PER_BATCH 4 SOLVER.BASE_LR 0.005
자, 우선은 먼저 tools/train_net.py를 살펴보겠죠. 지금부터는 필요 시 실제 코드를 부분 첨부할 생각이기에, 스크롤이 심할 수도 있습니다. 굳이 코드는 안보셔도 되며 “추상화된 코드는 이렇기에 이해하기 어렵구나” 정도만 보시면 좋을듯합니다.
def main(args):
cfg = setup(args)
trainer = Trainer(cfg)
trainer.resume_or_load(resume=args.resume)
if cfg.TEST.AUG.ENABLED: # False
trainer.register_hooks(
[hooks.EvalHook(0, lambda: trainer.test_with_TTA(cfg, trainer.model))]
)
return trainer.train()
if __name__ == "__main__":
args = default_argument_parser().parse_args()
print("Command Line Args:", args)
launch(
main,
args.num_gpus,
num_machines=args.num_machines,
machine_rank=args.machine_rank,
dist_url=args.dist_url,
args=(args,),
)보면 argument를 받은 다음 (위의 –num-gpus 4 등에 해당하겠죠) launch()를 활용해 전체 코드를 동작시킵니다. main 함수를 살펴보니 setup()을 활용해 argument를 cfg 변수에 대입한 이후 Trainer를 활용해 trainer를 정의합니다. 어? 그럼 우리가 아는 model.train()은 어디있지? 아, launch()를 찾아가면 있곘구나 생각합니다. 그 이후 import 라이브러리 목록을 살펴보겠죠.
from detectron2.engine import DefaultTrainer, default_argument_parser, default_setup, hooks, launch
def launch(main_func, num_gpus_per_machine, num_machines=1, machine_rank=0, dist_url=None, args=()):
mp.spawn(
_distributed_worker,
nprocs=num_gpus_per_machine,
args=(main_func, world_size, num_gpus_per_machine, machine_rank, dist_url, args),
daemon=False,
)
else:
main_func(*args)DDP (쉽게 설명하자면 둘 이상의 GPU에서 작업을 진행하기 위한 과정)를 위한 과정일뿐, 현재 코드에서도 model.train()을 살펴볼 수 없습니다. else 구문을 보니 main_func()을 실행하는데, main_func()은 앞선 코드에서 trainer를 정의했을 뿐, model.train()이 없었잖아? 그럼 dataloader는 어디에 있으며, backbone 네트워크, detection head는 어디에 있지? 슬슬 멘붕이 오기 시작합니다.
다시 돌아가 그럼 trainer = Trainer(cfg)를 살펴봐야곘네요. 아 물론 대부분의 연구원분들이 사용하시겠지만 신입 연구원 혹은 추후 이 글을 읽는 어떠한 연구원분들 위해 말하자면 이 코드들을 찾는 과정들을 반복 시 다른 파일에서 불러온 특정 함수, 클래스 등에 대해 어느 파일에서 불러온지 등을 하나씩 살펴보기는 힘든데, VScode에서 Remote Explorer에서 Remotes(SSH)가 아닌 Dev Containers로 접속한 이후 파이썬 관련 Extension을 몇몇 설치하고나면 (정확히 생각나지 않는데, 저는 Extensions에서 파이썬 관련된 Extension을 몇몇 본 이후 설치했었습니다) Ctrl+우클릭을 하면 해당 함수, 클래스를 사용하는 다른 파일로 슉 넘어갑니다.
자 그렇다면 다시 train = Trainer(cfg)를 보기 위해 Trainer를 살펴보면 Trainer는 DefaultTrainer, DefaultTrainer는 SimpleTrainer, SimpleTrainer는 TrainerBase를 상속받아 사용합니다. 위에서 언급한 바와 같이 상속을 받긴 하나, 이 상속 과정이 무려 세 번에 걸쳐 일어나기 때문에 TrainerBase부터 pdb를 걸어보며 코드의 동작 과정을 살펴보아야합니다. 물론 더 이상의 코드를 첨부 시 보기에만 불편할 것이므로 글로 언급하자면, TrainerBase 클래스는 심지어 추상화 함수를 사용합니다. 물론 TrainerBase 클래스는 train()이 존재하기 때문에 얼추 이해할 수는 있지만, 정작 우리가 익숙한 코드는 보이지 않습니다. 그래도 우리는 해당 상속 클래스들을 하나하나 보다보면 눈치껏 다음의 코드에서 힌트는 얻을 수 있습니다.
model = self.build_model(cfg)
optimizer = self.build_optimizer(cfg, model)
data_loader = self.build_train_loader(cfg)오! model, optimizer, dataloader를 선언하네요 (DefaultTrainer 내). 이제 model에 관한 코드가 파이썬 파일로 나오겠지?하고 다시 self.build_model -> build_model() -> (다른 위치의) build_model()로 넘어가고 나면 다음을 발견합니다.
from detectron2.utils.registry import Registry
META_ARCH_REGISTRY = Registry("META_ARCH") # noqa F401 isort:skip
def build_model(cfg):
meta_arch = cfg.MODEL.META_ARCHITECTURE
model = META_ARCH_REGISTRY.get(meta_arch)(cfg)
model.to(torch.device(cfg.MODEL.DEVICE))
return model아.. 정작 모델은 보이지 않은 채 META_ARCH_REGISTRY.META_ARCHITECTURE가 보입니다. 다시 위를 보아 META_ARCH_REGISTRY는 Registry()를 사용하는데, 오! 그럼 Registry()만 보면 되겠다해서 다시 들어가보면,
from fvcore.common.registry import Registry # noqa
__all__ = ["Registry"]딸랑 위 두 줄의 코드만 존재합니다. 코드라고 하기도 어렵죠. 자, 우리가 build_model()에서 model이 선언되어 있을 것을 기대하여 대체 몇개의 .py파일을 타고타고 들어왔는데 (그 동안의 상속된 파일들이 어림잡아 10개 근처입니다), 정작 우리가 원하는 익숙한 파이썬 코드를 살펴보지도 못하였습니다. 이젠 fvcore 라이브러리의 registry 함수까지 살펴봐야되네요. 이렇게 찾다보면 우리가 이미 많은 파일들을 살펴보았기 때문에 해당 파일로 다시 넘어가면 또 엮이는 몇몇의 파일들이 존재할 것이며, 결국 우리는 코드의 전체적인 틀을 이해하기에 어렵습니다. 물론 fvcore 라이브러리의 registry()를 살펴본 후, 해당 파일에서 다시 타고타고 들어가다보면 결국 위 model = META_ARCH_REGISTRY.get(meta_arch)(cfg)에서 cfg로부터 데코레이터를 활용하여 모델을 등록하는 과정을 알 수 있고, 이 때 되어서 config 파일에 선언된 GeneralizedRCNN의 파이썬 파일 (정말 우리가 익숙한)을 만날 수 있습니다. 하지만 이 또한 여태의 수 많은 파이썬 파일을 거쳤기에 우리가 놓친 점이 있으며 cfg란 변수는 첫 코드의 cfg = setup(args)로부터 생성되었기 때문에, 다시 setup 함수를 살펴보겠죠.
위의 과정이 복잡하여 이해하기 어렵다란 이야기를 하기 보단, 코드가 추상화되어 있을 시 기존의 학습을 위한 구성은 이미 짜여져있으니, 원하는 위치에 본인의 아이디어 코드 몇 줄만 넣으면 끝납니다. 이 때의 학습을 위한 모든 코드는 Detectron2에서 이미 짜여져있습니다. 즉, 다시 말하여 만약 우리가 새로운 데이터로 실험하고 싶다면 해당 데이터에 대한 CustomDataset을 구성하지 않아도 Detectron2에서 정의하는 데이터로더를 위한 프로토콜만 따르면 코드라고도 하기 어려운, 몇 줄의 입력만 넣으면 됩니다. 그렇기에, 알면 편할 수 있습니다. 하지만 해당 과정을 이해하는데 예를 들어 Detectron2와 비슷한 플랫폼인 MMDetection의 경우 (물론 저는 코딩 실력이 타 연구원분들에 비해 약한 편이므로) 2주가 넘게 소요되었고, MMDetection을 알고 있었음에도 Detectron2를 이해하는데 다시 일주일이 소요되었습니다. 더 자세한 동작 과정을 소개하고 싶지만, 이번 코드에 국한될 수 있기 때문에 제가 정리한 (ORE에 대해) 노션 페이지의 링크를 공유하며 Detectron2에 대한 소개와 학습을 위한 과정은 마치겠습니다. 위 링크에 들어가시면 적어도 Detectron2의 동작 과정을 이해하는데 어려움은 없을 것이라고 생각합니다.
이제 다시 돌아와 우리가 평소 파이썬 코드를 작성 시에 추상화, 상속을 적극적으로 활용하지는 않기 때문에 (사실 그보다는 클래스 또는 함수화하여 하나 혹은 몇몇의 파일에서 import하는 방식이 직관적이기 때문에 선호합니다), 하나의 detection 프레임워크를 이해하기 어렵습니다. 하지만 특히 요즘의 object detection 코드들은 보통 MMDetection 또는 Detectron2를 활용해 작성되어집니다. 해당 코드를 이해하기 위해선 평소 큰 관심을 가지지 않았던 데코레이터, 상속의 개념을 다시 보아야합니다. 이 때 평상 시에는 무심코 지나친 __all__, @classmethod 등에 대해 어느정도의 이해가 필요하며 (물론 저도 기억력이 좋지 않아 그때그때 구글링합니다), 굉장히 복잡하기 때문에 이러한 코드를 만난다면 스스로 한번은 동작 과정을 정리할 필요를 느꼈습니다. 사실 이번 리뷰는 위의 노션 페이지를 통해 혹시 연구원분들이 언젠가 베이스라인으로 삼고 싶은 코드가 Detectron2를 활용한 코드일 때 기피하지 않고자 소개드리고자 하는 목적이 컸습니다. 모든 코드의 변수들이 어디에 존재하고 등등을 해당 리뷰에서 소개하기엔 너무 코드양이 방대함이 아쉽습니다.
2. ORE
다시 잡담은 각설한 채, 이번엔 OWOD 태스크의 학습 및 평가 프로토콜에 대해 살펴보겠습니다. 우선, 아래의 쉘 스크립트는 이번에 제가 원복을 위해 작성한 파일의 일부입니다.
# General flow: tx_train.yaml -> tx_ft -> tx_val -> tx_test
# tx_train: trains the model.
# tx_ft: uses data-replay to address forgetting. (refer Sec 4.4 in paper)
# tx_val: learns the weibull distribution parameters from a kept aside validation set.
# tx_test: evaluate the final model
# x above can be {1, 2, 3, 4}
################################## Task 1 ##################################
# Task 1 (train)
CUDA_VISIBLE_DEVICES=0,1,2,3 OMP_NUM_THREADS=5 python tools/train_net.py \
--num-gpus 4 --dist-url "tcp://127.0.0.1:42209" --resume \
--config-file /home/silee/workspace/ORE/configs/OWOD/t1/t1_train.yaml \
SOLVER.IMS_PER_BATCH 4 SOLVER.BASE_LR 0.005 \
SEED 12917085 VIS_PERIOD 1000 IS_STORE "True" FEATURE_STORE "t1" \
OUTPUT_DIR "./output/t1"
# No need to finetune in Task 1, as there is no incremental component.
# Task 1 (val)
CUDA_VISIBLE_DEVICES=0,1,2,3 OMP_NUM_THREADS=5 python tools/train_net.py \
--num-gpus 4 --dist-url "tcp://127.0.0.1:42209" \
--config-file /home/silee/workspace/ORE/configs/OWOD/t1/t1_val.yaml \
MODEL.WEIGHTS /home/silee/workspace/ORE/output/t1/model_final.pth \
SOLVER.IMS_PER_BATCH 4 SOLVER.BASE_LR 0.005 \
SEED 54956683 OWOD.TEMPERATURE 1.5 \
OUTPUT_DIR "./output/t1_final"
# Task 1 (eval)
# TODO: does we need SOLVER in evaluation phase?
CUDA_VISIBLE_DEVICES=0,1,2,3 OMP_NUM_THREADS=5 python tools/train_net.py \
--num-gpus 4 --eval-only \
--config-file /home/silee/workspace/ORE/configs/OWOD/t1/t1_test.yaml \
MODEL.WEIGHTS /home/silee/workspace/ORE/output/t1/model_final.pth \
ENERGY_DIST_DIR /home/silee/workspace/ORE/output/t1_final \
SOLVER.IMS_PER_BATCH 4 SOLVER.BASE_LR 0.0025 \
SEED 54611310 \
OUTPUT_DIR "./output/t1_final"
################################## Task 2 ##################################
# Task 2 (train)
cp -r /home/silee/workspace/ORE/output/t1 /home/silee/workspace/ORE/output/t2
CUDA_VISIBLE_DEVICES=0,1,2,3 OMP_NUM_THREADS=5 python tools/train_net.py \
--num-gpus 4 --dist-url "tcp://127.0.0.1:42209" --resume \
--config-file /home/silee/workspace/ORE/configs/OWOD/t2/t2_train.yaml \
MODEL.WEIGHTS "/home/silee/workspace/ORE/output/t2/model_final.pth" \
SOLVER.IMS_PER_BATCH 4 SOLVER.BASE_LR 0.005 \
SEED 19370639 VIS_PERIOD 1000 \
OUTPUT_DIR "./output/t2"
# Task 2 (fine-tuning)
cp -r /home/silee/workspace/ORE/output/t2 /home/silee/workspace/ORE/output/t2_ft
CUDA_VISIBLE_DEVICES=0,1,2,3 OMP_NUM_THREADS=5 python tools/train_net.py \
--num-gpus 4 --dist-url "tcp://127.0.0.1:42209" --resume \
--config-file /home/silee/workspace/ORE/configs/OWOD/t2/t2_ft.yaml \
MODEL.WEIGHTS /home/silee/workspace/ORE/output/t2_ft/model_final.pth \
SOLVER.IMS_PER_BATCH 4 SOLVER.BASE_LR 0.005 \
SEED 21674076 \
OUTPUT_DIR "./output/t2_ft"
# Task 2 (val)
CUDA_VISIBLE_DEVICES=0,1,2,3 OMP_NUM_THREADS=5 python tools/train_net.py \
--num-gpus 4 --dist-url "tcp://127.0.0.1:42209" \
--config-file /home/silee/workspace/ORE/configs/OWOD/t2/t2_val.yaml \
MODEL.WEIGHTS /home/silee/workspace/ORE/output/t2_ft/model_final.pth \
SOLVER.IMS_PER_BATCH 4 SOLVER.BASE_LR 0.005 \
SEED 52618166 OWOD.TEMPERATURE 1.5 \
OUTPUT_DIR "./output/t2_final"
# Task 2 (eval)
CUDA_VISIBLE_DEVICES=0,1,2,3 OMP_NUM_THREADS=5 python tools/train_net.py \
--num-gpus 4 --eval-only \
--config-file /home/silee/workspace/ORE/configs/OWOD/t2/t2_test.yaml \
MODEL.WEIGHTS /home/silee/workspace/ORE/output/t2_ft/model_final.pth \
ENERGY_DIST_DIR /home/silee/workspace/ORE/output/t2_final \
SOLVER.IMS_PER_BATCH 4 SOLVER.BASE_LR 0.0025 \
SEED 38640072 \
OUTPUT_DIR "./output/t2_final"쉘 스크립트의 주석을 토대로 보자면 t1, t2, t3, t4에 대해 나뉘어져 있습니다 (t3-t4는 아래에서 언급하겠지만 t2와 동일한 과정이므로 생략하였습니다). 이 t1-t4가 ORE에서 처음 소개하는 OWOD의 태스크 세팅입니다. 이후의 많은 OWOD 연구들이 해당 세팅을 보통 따르며, t1은 Pascal VOC, t2-t4는 Pascal VOC의 20개 클래스를 제외한 MS-COCO의 60개의 클래스에 해당합니다. 헷갈리지 않아야하는 점은 test images에 Task 1, Task 2로 나뉘어져 평가하는 것으로 보이지만, 막상 코드를 뜯어보면 test image는 t1-t4가 모두 t1-t4의 test images를 합친 하나의 test dataset을 활용합니다. 즉, Task에 따라 test images가 변하는건 아니라는 점이죠. 저도 이 점에서 굉장히 많이 헷갈렸습니다. 왜냐하면, 아래의 실험을 보면 Task 1에서는 Current known만을 평가하기 때문에 Task 1의 test images만을 가지고 평가하는 것으로 오해하였으나, 그것이 아닌 Task 2 – Task 4는 평가할 수 없기 때문에 (학습하지 않았으므로) 실험 표에서 제외했었더라구요.
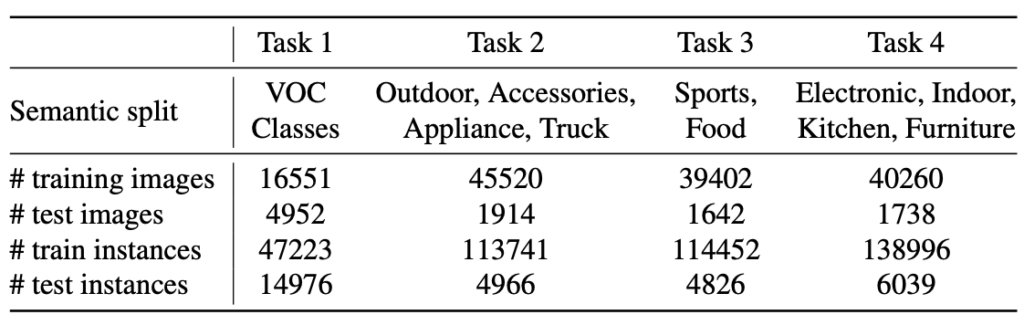
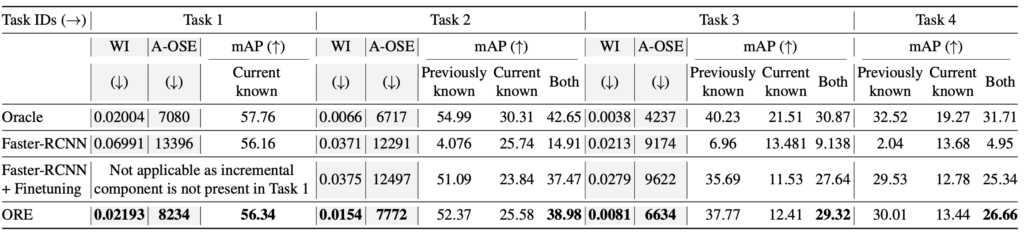
어찌되었든, t1-t4의 흐름에서 각각의 학습 이미지들이 존재합니다. 쉘스크립트를 보면 각각 IMS_PER_BATCH에 따라 배치 사이즈를 정하고 (IMS_PER_BATCH가 4라고 해서 각 GPU당 4배치가 아닌, 4개의 GPU를 사용하기에 GPU당 배치는 1에 해당합니다) SOLVER.BASE_LR과 같이 learning rate도 지정하고 (solver는 detectron2에서 optimizer, learning rate 등에 대해 이미 정의되어 있습니다. 우리가 learning rate를 변경하고 싶으면 SOLVER.BASE_LR, 최대 학습 수를 조정하고 싶으면 SOLVER.MAX_ITER 10000과 같이 사용하기만 하면 됩니다. 이 점이 detectron2를 알고 있는 연구진은 연구에 굉장히 편하단 점이죠), 필요한 몇몇의 argument를 정의하여 우선 1) t1 데이터에 대해 학습합니다. 2) t1에서는 fine-tuning (fine-tuning이라 함은 exampler replay, 즉 A 데이터 셋으로 학습한 이후 B 데이터 셋에 대해 학습하면, A 데이터 셋의 정보에 대해 모델이 까먹게 되는 catastrophic forgetting 현상을 방지하기 위해 이전 데이터 셋의 샘플 몇몇을 학습시키는 방법입니다)이 필요하지 않기에, held-out validation set을 활용하여 enery_distribution을 학습합니다 (energey_distribution이라함은 validation set을 활용하여 모델이 known과 unknown에 대한 enery (entropy 개념) 기반의 분포도를 학습하는 과정입니다. 아래 첨부된 사진을 확인하시길 바랍니다). 3) t1에 대해 평가합니다. 4) t1의 학습 시의 weight를 그대로 연이어, t2에 대해 학습합니다. 이 때 # Task 2 (train)에서는 MODEL.WEIGHTS가 t1을 학습 시 활용한 weight을 그대로 활용합니다. 이 weight을 활용하지 않는다면 t1에 대해 학습한 것이 무의미해집니다. 5) t2에선 위에 언급한 fine-tuning이 필요합니다. fine-tuning을 통해 t1의 데이터 일부를 잠깐의 iteration으로 학습합니다. 6) t2 모델에 대해 평가합니다. 이제부턴 Previously known, 즉 t1의 클래스에 대해 평가가 가능합니다. 7) t3, t4는 t2와 동일한 방식으로 이루어집니다. 당연히도, t3 학습시에는 t2 fine-tuning 시의 weight을, t4 학습 시에는 t3 fine-tuning 시의 weight을 활용합니다.
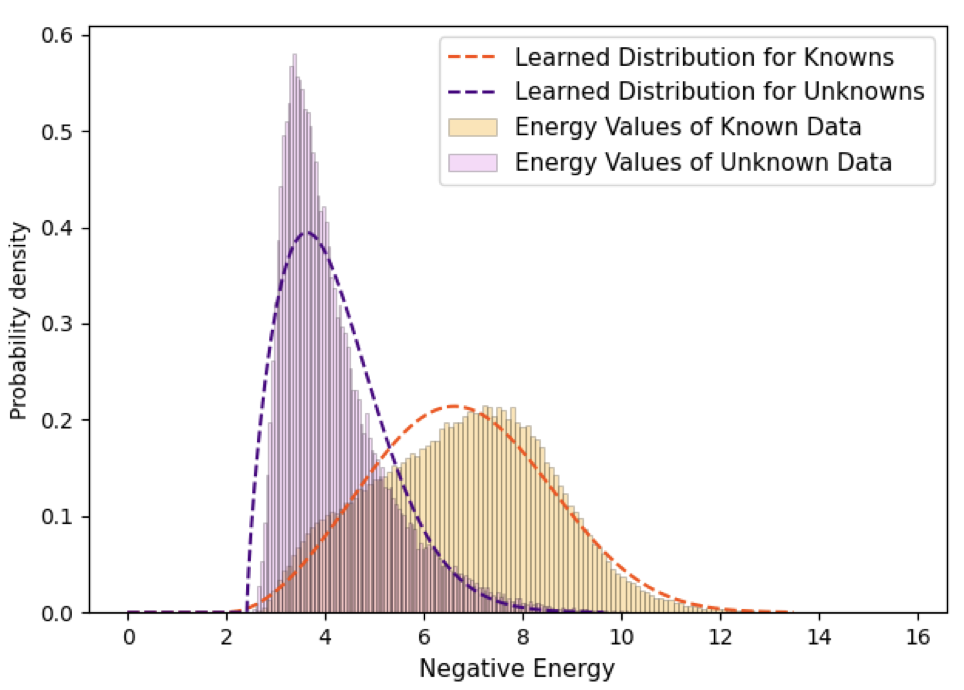
이로써 OWOD의 시초 논문인 ORE의 학습 과정에 대해 간략히 살펴보았습니다. 마지막으로는, 연구 시 환경설정 이슈, 코드 이슈 등의 상황에 대응하는 몇몇의 과정을 공유합니다. (사실 이 과정도 이미 많은 분들이 잘 아는 과정입니다. 구글링, ChatGPT 등의 방식 외 깃허브 이슈, 특히 환경 설정 시의 고려할 점을 공유하고자 합니다)
3. Issue
마지막으로는 이슈 발생 시입니다. 음, 많은 분들이 이미 이슈 발생 시 각자 대응을 잘 하고 있으시라 생각하는데요, 개인적으로 특히 원복 시 이슈의 경우, 몇몇으로 나뉜다고 생각합니다. 그 중 대표적으로는 1. 환경설정 시 이슈 2. 성능 원복 시 이슈. 음, 특히 이번 ORE 논문의 경우 많은 이슈들이 발생하였는데, 먼저 환경설정 시 이슈는 Docker내 환경 세팅 시 Torch, CUDA 버전등을 적절히 맞출 수 있는지에 관한 이슈나, Requirements (dependencies 라이브러리)의 환경 버전에 따른 문제등이 존재할 것으로 예상됩니다. 특히 연구 공개 시 Docker 환경 코드를 그대로 공개하지는 않습니다. 보통 필요한 몇몇 버전 (CUDA, Torch, Torchvision, …)을 공개하며 우리 서버에 적용하기 위해선 Dockerfile, Makefile등을 수정해야합니다 (PORT 문제 등도 존재하죠). 지금은 아쉽게도 광진님이 연구실 졸업을 하시면서 서버 전문가가 없어져 아쉬운 느낌인데요, 특히 Docker 컨테이너 생성 시 해당 코드들에 대해 그냥 가져다 써보기만 했었다면 다른 연구의 Dependencies로부터 내 서버에 적절하게 맞추기엔 쉽지 않습니다.
몇몇의 경우를 들어보죠. 예를 들어 연구들은 INSTALL.MD와 같은 마크다운 페이지에서 본인 연구의 Environment, Dependencies들을 공개하곤 합니다. 단순히 Dockerfile이나 yaml 파일만 공개하는 경우도 존재하죠. 예를 들어 ORE는 CUDA 10.1의 환경에서 구동되었다고 합니다. 파이썬은 3.6버전이고 Torch는 1.4버전 이상이라고 하네요. 특히 CVPR급의 탑 티어 학회, 저널의 경우 본인의 환경 뿐만 아니라 다른 환경에서도 한 두번 정도 돌려보기 때문에, “꼭 3.6버전이어야해!” 보다는 3.6 이상의 버전에서 구동 가능하다고 표기해놓습니다. 만약 이 세팅 정보만을 토대로 “아, 내 서버에 CUDA 10.1의 Docker 이미지가 있나?”하고 docker images로 검색해본 이후, 없다면 도커 허브에서 Nvidia의 docker image 버전을 찾습니다. 다만 CUDA10.1의 정보밖에 없기에 저자의 Dockerfile을 보니
오! nvidia/cuda:10.1-cudnn7-devel의 이미지를 찾아 베이스 이미지를 설치해놓으면 되겠네요. 이제 해당 Dockerfile에서 몇몇 정보들을 찾고 그대로 돌리면, 물론 한 번만에 되면 좋겠지만 에러 코드들이 생기며 자주 중단되게 될 것 입니다. 자 다시 보면
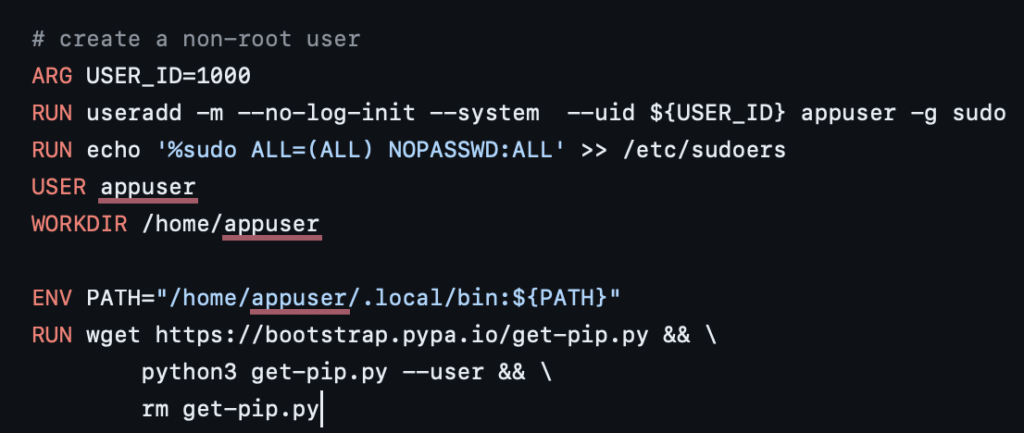
USER_ID는 우리가 각자의 User들만의 ID가 존재하기 떄문에 1000!이렇게 박아 놓으면 안되고, USER 이름도 (보통 우리의 이름으로 useradd를 하니, 물론 현재의 코드에선 RUN useradd -m …의 코드로 유저를 추가하긴 하지만 이렇게 돌리면 우리가 원치 않은 다른 user가 생기게 되니 지양해야합니다) 우리의 이름이 아니기에 바꿔줘야 합니다. 많은 연구원분들이 각자 쓰시는 Dockerfile이 존재할텐데요, 선배 연구원분들이 만들어놓으신 Dockerfile을 기반으로 보통 Torch 버전 정도만 바꾸어가며 사용했곘지만 그렇게 했을 시 새로운 환경에 계속 대응하긴 어려운 문제가 생깁니다. 현재 Dockerfile의 경우 Dependencies문제로 fvcore 등을 torch 이전에 설치해야하며, 그렇기 떄문에 해당 정보도 Dockerfile 내 포함시켜야 합니다 (굳이 알아야하는 내용은 아니지만). 이 때 우리가 Dockerfile에 대해 그냥 가져다 썻다면 새로운 환경 설정에 어려움을 겪을 수 있습니다. 한 번쯤은 Dockerfile의 ARG, RUN, USER, WORKLIR, ENV, 등등 사실 어려운 명령어는 아니니 한 번쯤 보심이 좋지 않을까 싶습니다.
그렇게 다 설치해놓고나니, 이제 문제점이 생깁니다. 분명 설정을 다 맞춘 이후 코드를 돌렸는데, 코드가 시작부터 돌아가지 않습니다. 그 이유는 알고보니 내 서버는 CUDA10 버전을 지원하지 않는단 점이죠! 우리 연구실의 서버 (GPU 이름으로 구분하자면 2080, 3090, A6000, A100, V100)은 각 GPU에서 지원되는 CUDA 버전이 있는데요, CUDA wiki의 GPUs Supported에서 잘 보면 A100은 CUDA 11버전 이상만 지원합니다. 그렇기에 CUDA 10은 처음부터 안되는거였습니다! 그렇게하면 다시 문제점은 CUDA 버전을 올렸을 때 그 Pytorch 버전이 존재하는질 찾아봐야하지만, 아마 CUDA10의 저자의 예전 PyTorch 버전과 CUDA 11의 현재 PyTorch 버전은 안맞을 가능성이 꽤나 높습니다 (CUDA 버전이 다르다고 PyTorch 버전이 아예 다르진 않습니다). 그럼, 그때는 적절한 PyTorch 버전 정도로 설치해줘야합니다. 이 때는 구글에 “Previous Torch Version”으로 친 이후 본인의 CUDA 버전에 따른 Torch 버전들을 찾아봅니다. 물론, 대부분의 연구원분들이 이 사실 다 알고 있습니다. 이 보다는 위에 말한 “우리가 정말 Dockerfile을 알고 쓰는가? 그렇지 않다면 내가 나만의 환경을 설정할 줄 아는가?”에 대해 한 번 짚고 넘어가기 위함이였습니다.
환경설정이 마친 이후 분명 저자의 순서를 다 따라 원복 실험을 진행했다고 생각하지만, 원복이 안될 수 있습니다. 사실 꽤나 안될 가능성이 높습니다. 물론, 바꾸기 어려운 몇몇의 문제 (CUDA, Torch 버전, 시간이 지남에 따라 현재 사용할 수 없는 버전 등으로 인한 성능 변동)로 성능이 원복안될 수 있지만, 우리가 돌리다보면 조금 의심스러울 때도 있죠. 예를 들어 ORE에선 아무리 몇몇 해도 성능이 원복되지 않으니, 이슈들을 살펴보기 시작합니다. 이 때 지금과 같이 꽤나 유명한 논문의 코드의 경우, 이슈들이 워낙 많아 하나 둘 살펴보지 못하는데요, 이 때 만약 우리가 에러에 대해 찾아보려면, 에러 메시지를 그대로 복사하기보다, 에러 명이나 에러 내용 정도만 찾는게 나아보입니다. 예를 들어 “KeyError: Bounding Box Key errors: [14965]”와 같은 경우, KeyError로 찾거나 혹은 구어체로 Bounding box not found 정도로 찾는게 더 나을 때도 많습니다. 성능 원복 이슈는 저자도 꽤나 예민한 문제이기 때문에 성능이 원복이 안된다는 이슈 글이 달릴 시 저자가 때로 “그냥 랜덤시드 고정 안해서 그럴껄? (제가 겪고 있는 이슈가 그냥 이렇게 말해버리길래.. 좀 황당하긴 합니다)”로 하면, 저자에게 저자가 사용한 로그 파일을 달라고 요청합니다. 해당 로그 파일엔 저자가 랜덤 시드를 썻더라도, 보통 시드가 남아있기 때문에 이 때는 저자가 사용한 시드를 그대로 사용한 후 다시 따져볼 수 있습니다. (한 3년 지나서 그런지, 이젠 대응을 안해주더라구요.. 허허)
이외의 이슈 대응 방안, 혹은 제가 겪었던 이슈들을 공유하고 싶지만, 제가 그때그때 기록을 잘 안해놔서.. 기억나는대로 써놓았습니다. 물론 저는 제가 주로 연구하는 태스크 이외의 코드는 돌려보지 않았기 때문에, Detectron2가 어느 범주까지 사용가능한지는 정확히 알지는 못합니다. 태스크에 대해 한정적일 수는 있지만 Meta에서 만든 만큼, 앞으로 더 넓은 범주에 사용될 수도 있습니다. 그보단 Detectron, MMDetection과 같이 새로운 코드 상황을 겪을 때 당황하는 경우가 많은데, 그에 관해서 어느정도 도움이되고자 한 번 글을 써봤습니다. 후에 Detectron2를 쓰는 그 누구에게는 도움이될 수 있었으면 좋겠네요. 그럼 리뷰 마치겠습니다.