이번에 제가 리뷰할 논문은 2021 CVPR 페이퍼로 6DoF Pose Estimation 관련 논문입니다.
6DoF Pose Estimation에서 가장 유명한 챌린지인 BOP챌린지 LineMOD에서 SOTA를 달성한 방법론입니다. LineMOD는 6DoF에서 제일 유명한 데이터셋이라고 생각이드네요.
제가 저번에 리뷰한적이 있는 PVN3D과 방법론적으로 많이 유사하며, 마찬가지로 semantic segmentation 하고 3D keypoint 기반으로 6DoF Pose Estimation을 수행하고 있습니다.
먼저 전체적인 그림부터 보겠습니다.
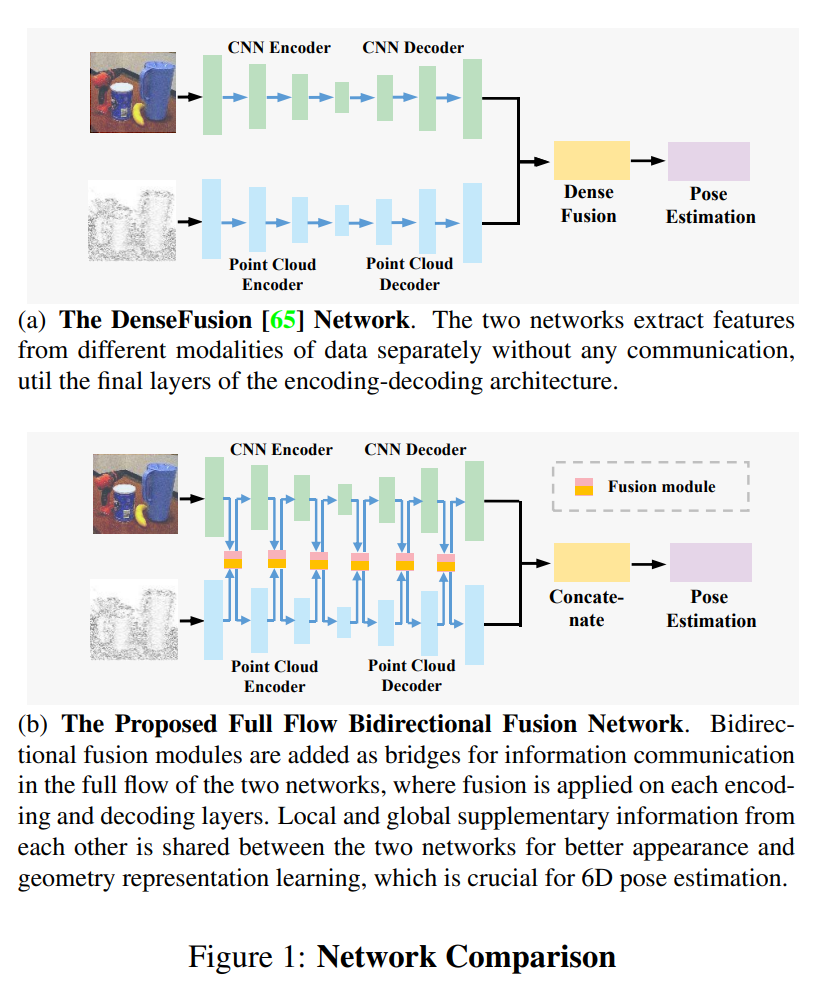
해당 논문에서는 위의 그림 (a)와 같이 모델을 설계하면 서로다른 모달리티간의 정보를 완전히 활용하기 어렵다고 주장하며, (b)처럼 bi-directional한 communication을 통해 rgb영상과 포인트클라우드의 상호보완적인 관계를 완전히 활용하는 방법을 제안합니다.
결국에는 RGB피쳐와 Point 피쳐를 어떤식으로 융합하는게 좋을지에 대한 연구라고 보시면 됩니다. 그와 별개로 해당 논문에서는 3D keypoint를 추출하는 방식인 SIFT-FPS를 추가적으로 제안합니다.
핵심 컨트리뷰전은 피쳐를 융합하는 부분에 있으며, 추가적인 컨트리뷰전은 바로 저 3D Keypoint 추출 알고리즘 입니다. 그럼 두가지 컨트리뷰전에 초점을 맞추어서 논문을 이해해봅시다.
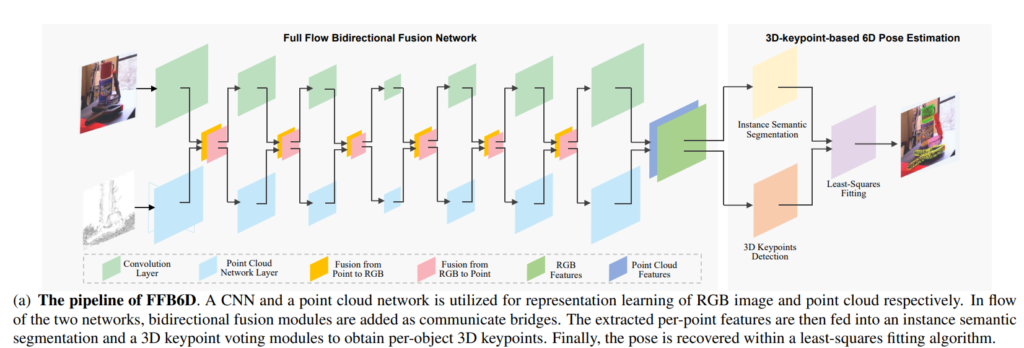
먼저 전체적인 파이프라인 입니다. Figure 1의 (b)하고 같은 내용이며, 좀 더 자세히 그려두었다고 생각하시면 됩니다.
해당 파이프라인에서는 RGB피쳐와 Point 피쳐를 추출하여 중간레벨에서 bi-directional하게 퓨전을 하여 최종적인 fused 피쳐를 구하고 있으며, 해당 fused 피쳐를 이용하여 instance semantic segmentation과 3D keypoint Detection을 동시에 수행한 후, 다른 방법론들과 마찬가지로 least square fittion을 통해 최종 6D pose를 구합니다.
아마 6D Pose Estimation에 익숙하신분들은 위의 내용이 이해가 가실거라고 생각이 되는데, 익숙하지 않으신분들도 많을걸로 생각되어서 좀 더 자세히 설명해드리겠습니다.
먼저, 해당 파이프라인에서 인풋은 RGB-D영상이며, 정합이 된 상태입니다. 최종적으로 구하고자하는 아웃풋은 6D Pose이며, 6D pose란 object 좌표계로 표현된 물체를 camera 좌표계로 변환하는 관계를 나타내느 행렬입니다. 즉, 여기서 말하는 6D Pose 는 Rotation matrix를 구성하는 9개의 인자와 translation matrix를 구성하는 3개의 인자로 총 9개 정보입니다.
위의 아키텍쳐를 보시면 RGB-D 영상을 인풋으로 받아서 최종적인 6D Pose를 구하였습니다. 그렇다면 6D Pose를 구했다는 것이 무엇을 의미하고 어떻게 구할 수 있었을까요? 아마 해당분야가 익숙하지 않으신분들은 의문점들이 많을거라고 생각되기에 단편적인 예시를 들어보겠습니다.
로봇팔이 있다고 가정해봅시다. 해당 로봇팔이 움직일 수 있는 영역을 workspace라고 부르겠습니다. 해당 workspace내에 물건들이 널부러져있고, 로봇팔은 해당 물체들을 잡는 task를 수행하길 원합니다. 이때, 해당 물체들이 어떠한 위치에 있는지 어떠한 회전각을 가지고 있는지에 대한 정보가 바로 6D Pose입니다. 만일 workspace상에 물체A가 있다고 해봅시다. 6D Pose를 구하는 순간 우리는 해당 물체A와 로봇팔에 있는 카메라 사이의 변환관계를 알 수 있습니다.
좀 더 정확히 말하자면 해당 과정에는 3D Modeling 파일이 필요합니다. 카메라 좌표계에 있는 3D modeling파일과 비교를 통해서 object 좌표계에 있는 물체A의 6D Pose를 알 수 있는 것 입니다. 즉, 정리하자면 물체A에 6D Pose parameter 12개로 구성된 matrix를 통해 object좌표계로 표현된 물체A를 transform 해주면 사전에 정의한 Camera좌표계 기준 3D modeling 파일과 일치하게끔 좌표변환을 해주는 matrix를 구할 수 있는 것 입니다. 이때의 해당 변환 matrix를 구하는 것을 6D Pose를 구했다고 말합니다.
그런데 3D modeling파일과 임베딩된 피쳐 사이의 모든 점들을 다 매칭해서 변환관계를 구하기에는 computation time이 너무 많이 들 것입니다. 이러한 이유로 modeling파일에서 해당 물체를 대표하는 몇가지 키포인트만 추출하여 비교하는 방식을 취하는 것이 3D keypoint based 방법입니다. 그리고 해당 논문에서는 3D Keypoint 기반의 방법을 취하고 있습니다. 보통 FPS를 사용하여 3D keypoint를 추출하는게 일반적이나 해당 논문에서는 SIFT-FPS를 사용하고 있습니다. 이부분에 대해서는 뒤에서 좀 더 자세히 설명해드리겠습니다.
이야기가 좀 샌거 같은데 결과론적으로 해당 논문에서는 6D Pose를 구하기 위해 bi-directional fusion module을 설계해서 사용합니다. 해당 모듈에 대해서 좀 더 자세히 살펴보겠습니다.
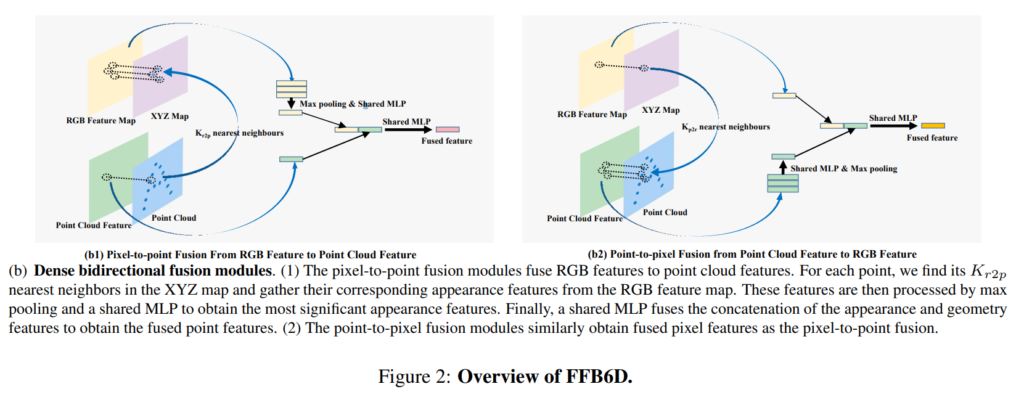
<pixel-to-point> 해당 모듈에서는 먼저 각각 포인트들 마다 corresponding하는 RGB피쳐를 nearest neighbor로 구한 후 해당 피쳐를 포인트 피쳐에 추가 해줍니다. 이후 Max pooling과 Shared MLP를 통해 나온 피쳐와 포인트 피쳐를 concatenate한 후 다시 shared MLP를 취하는 방식으로 퓨전을 해줍니다. 이렇게 되면 point 피쳐에는 없던 RGB영상에서의 텍스쳐 정보가 어느정도 반영되게 됩니다.
<point-to-pixel> 해당 모듈에서는 비슷한 방식을 반대로 수행합니다. 즉, 이전스텝에서 우리는 point피쳐에 텍스쳐정보가 추가된 피쳐를 구했습니다. 해당 피쳐에 추가적으로 다시 point피쳐를 더해서 퓨전하는 방식을 취해줍니다.
사실 컨셉적인면으로는 간단한데 코드적으로는 어떻게 구현했는지 살펴봐야할거 같습니다. 특히나 Nearest Neighbor 부분은 코드를 봐야 이해가 될거 같습니다.
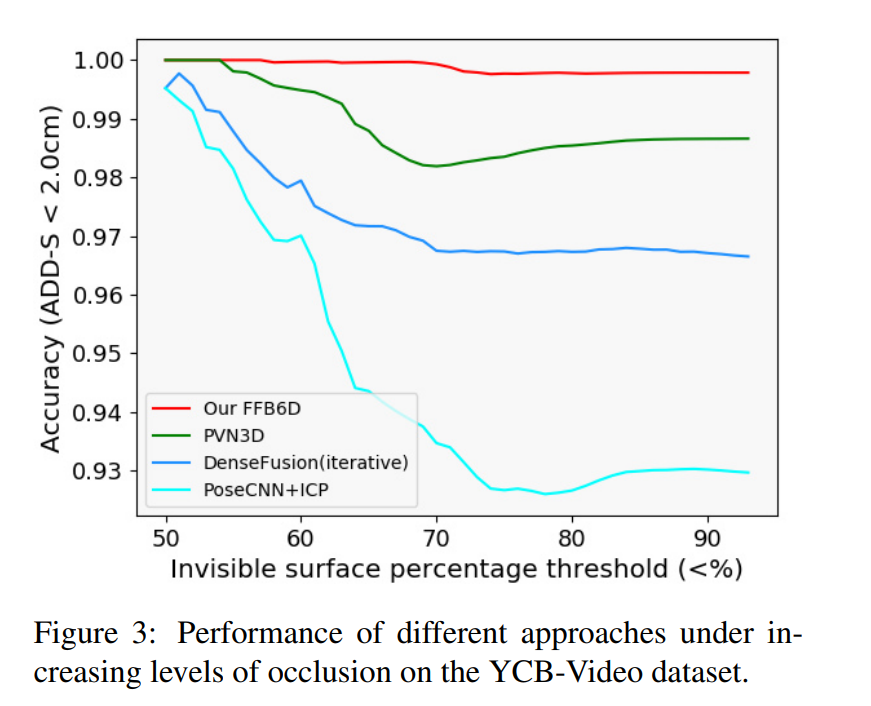
방법론적인 면에서 기존 SOTA 였던 PVN3D와 큰 차이가 없다고 생각되는데 추가적인 ICP과정 없이도 성능은 압도하였습니다. bi-direction fusion module이 역할을 하였다고 볼 수 있을거 같습니다.
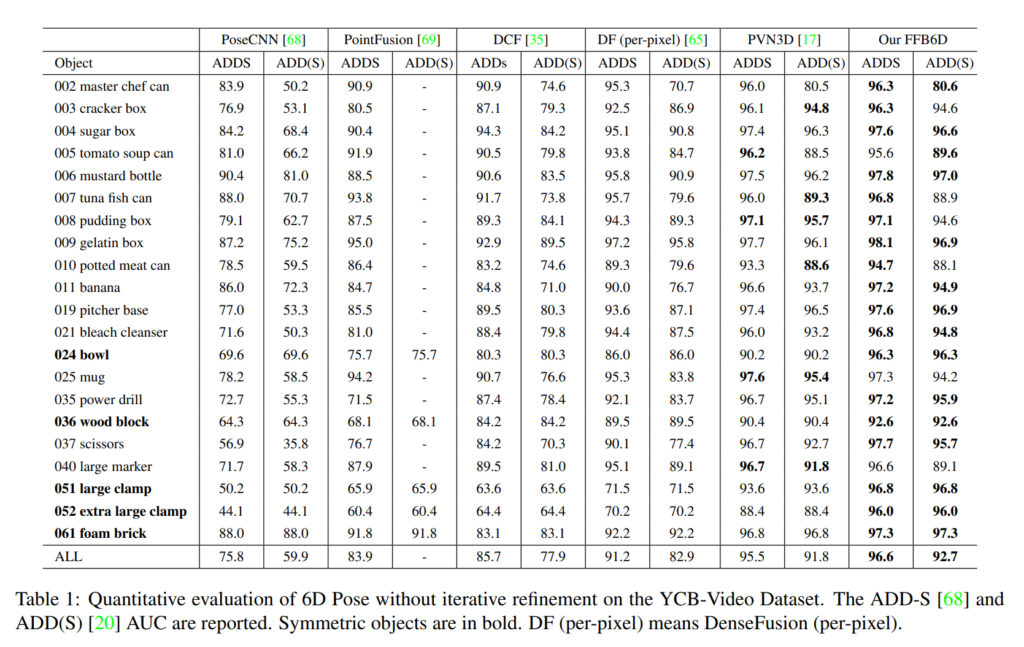
YCB-Video, LineMOD, LineMOD-Occlusion에서 평가를 진행하였으며 해당 3개 데이터셋은 벤치마킹하는데 아주 자주사용되는 데이터셋들 입니다. YCB-Video에서 제가 알기로 reconstruction 기반 방법론을 제외하고는 SOTA를 달성했습니다.

LineMOD에서도 마찬가지로 SOTA를 달성했고 아직까지도 SOTA인걸로 알고 있습니다.
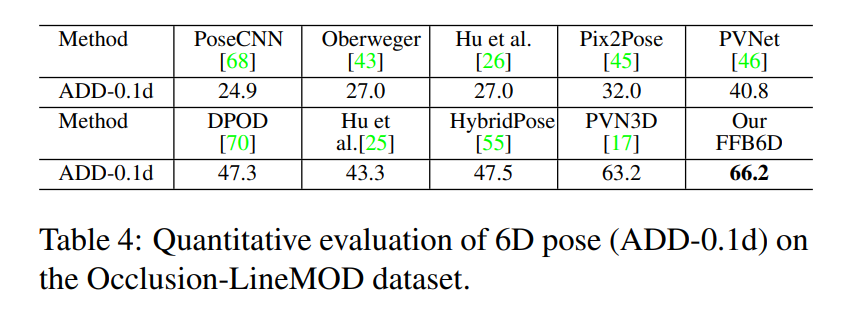
LineMOD를 인위적으로 가공하여 만든 Occlusion-LineMOD에서도 좋은 성능을 보였습니다.

Fusion의 위치에 대해서도 ablation study를 진행하였는데 결과는 위와 같습니다. 캡션을 참고해주세요.
SIFT-FPS
추가적으로 해당 논문에서는 3D 모델링 파일로부터 3D Keypoint를 추출하는 방법으로 SIFT-FPS를 제안합니다. 기존 FPS(Farthest Point Sampling)에서는 랜덤하게 n개의 키포인트를 초기화하고 각 키포인트 별로 거리가 멀어지는 방식으로 keypoint를 구하였습니다. 해당 방식을 개선하기 위해 해당 논문에서는 SIFT연산자를 추가적으로 활용합니다. 먼저 2D영상으로 2D keypoint를 추출하고, 해당 keypoint들을 3D 모델링 파일위에 올립니다. 그리고 그러한 keypoint들을 candidate로 사용한 상태에서 FPS알고리즘을 동일하게 적용해줍니다. 이렇게 되면 불필요한 point들을 고려하지 않고 3D keypoint selection이 가능하게 됩니다.
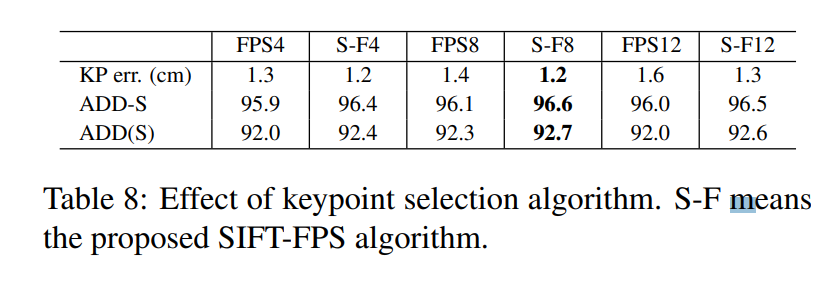
결과론적으로 8개의 keypoint를 SIFT-FPS로 뽑았을때 가장 성능이 좋았다고 하네요.

마지막으로 정성적인 결과를 보여드리며 이상 리뷰 마무리 하겠습니다.
질문은 댓글로 남겨주세요.
예측된 Pose 값은 실제 pose 값하고 L1 distance와 같은 loss로 학습을하나요?
네 맞습니다. 근데 L1은 아니고 L2 loss와 비슷하게 각 point들에 Rotation matrix를 곱한후 translation vetor를 더하여 변환된 값과 GT point간의 차이의 제곱을 fitting합니다.