최근 다양한 도메인에서 멀티 에이전트가 도입되고 있습니다. 다양한 페르소나 부여를 통한 전문가 간의 비교나 작업을 분업하는등 다양한 방식으로 활용되고는 하며, 실제로 멀티 에이전트 도입으로 유의미한 성능 개선을 보이곤 합니다. 그러나 멀티 에이전트를 도입하면 연산의 횟수 등이 증가하게 됩니다. 그렇다면 멀티 에이전트 도입을 통한 성능 개선은 연산량 증가에서 오는것일까요 아키텍처로 부터 오는 것일까요? 본 논문은 이러한 질문에 대해 토큰의 개수를 통제한 실험으로 답변합니다.
물론 기존에도 멀티 에이전트라는 개념 자체에 대해 연산량 제악으로 그 효율을 검증하려는 연구는 있었습니다. 본 연구의 특이점은 정보이론을 기반으로 싱글 에이전트 시스템의 이점을 이론적으로 가정하고 실험을 통해 검증한데 있습니다. 그 과정에서 토큰수를 제한하였으며 특히 기존 방법보다 엄밀하게 토큰수를 통제하였습니다.
이론적 설계
이론적 설계는 단순합니다. 먼저 응답(Y)과 입력 context(C),agent 간 소통에 사용되는 메세지(M)이 서로 마르콥스 체인 관계가 존재한다고 가정합니다. C로부터 M이 발생하고 SAS(single agent systems) 에서는 C로부터 Y가, MAS(multi-agent systems)에서는 M으로부터 Y가 생성됩니다.
Y↔C↔M
정보이론의 DPI(data processing inequality)에 따르면 정보의 변형은 정보의 손실이나 축약이 있을 뿐 증가하지 않으며, 그렇다면 C로부터 생성한 Y보다 M으로부터 생성한 Y가 더 적은 정보로 생성한 불확실성이 같거나 높은 답변이라고 할 수 있습니다. multi agent communication 은 본질적으로 정보손실 가능성을 갖고다는 것입니다.
그럼에도 MAS관련 연구는 활발하게 진행되고 있습니다. MAS가 SAS보다 무조건적으로 비효율적이라는것은 사실 직관과 맞지 않습니다. 논문에서는 MAS의 성능 개선 효과에 대한 가능성 또한 열어놓았습니다. MAS는 context degradation이 발생할 경우 SAS 대비 우수할 가능성이 있음을 이론을 통해 보였습니다. 앞서서 C와 M은 정보이론에 따라 명확한 정보량의 우위가 있었습니다. 그러나 context의 손실이 있을 경우 C로 부터 손실된 C’과 C로 부터 손실이 포함된 변형인 M’은 직접적 연관관계가 없으며 정보의 우위도 없는것입니다. (Y↔C↔M’/Y↔C↔C’) 즉, 입력 context가 복잡하거나 정보량이 적게 주어지는 경우에는 MAS가 상황에 따라 우수할 수있는 것입니다.
실험적 증명
실험은 NLP도메인에서 진행되었으며 reasoning 과정에서 여러단계의 연결이 필요한 추론테스크인 multi-hop reasoning을 수행했습니다. (단순한 사실 검색이 아닌 데이터셋 관점에서 추론을 수행해야 해결할 수 있는 질문) 사용한 데이터셋은 FRAMES 벤치마크와 MuSiQue의 일부 데이터셋을 사용했으며, 아래의 예시와 같습니다.

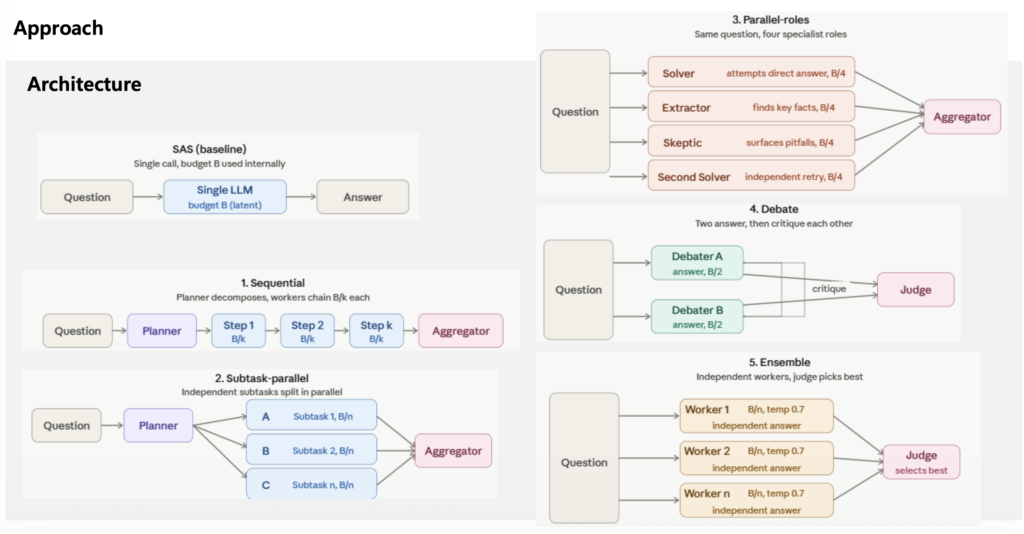
실험에는 5개의 multi agent system 구조(아래 그림의 좌측 2번째부터 반시계 방향으로 Sequential, subtask-parallel, parallel roles, debate, ensenmble)와 single agent system 구조가 비교되었으며 구조는 아래와 같습니다. 각 에이전트와 aggregator/judge에는 동형 모델이 사용되었으며 qwen3-30b, deepseek-r1-70b, gemini2.5-Flash/Pro 에 대해 실험이 진행되었습니다.
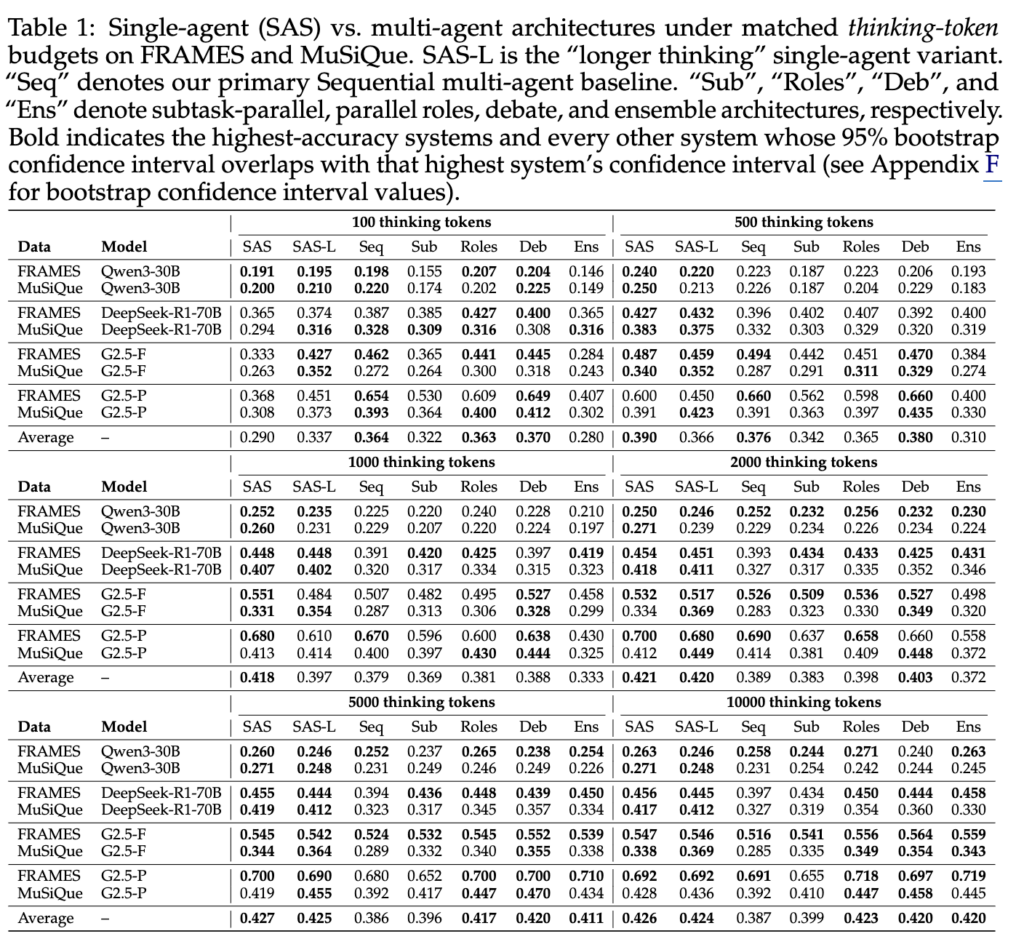
데이터셋에 대한 메인 실험 결과는 table1과 같습니다. 볼드채는 신뢰구간 기준으로 비교군 대비 높은 가장 높은 성능을 표기한 것이며 그 결과 다양한 모델과 데이터셋에서 토큰이 통제되었을 때 단일 에이전트 시스템(SAS/SAS-L)의 성능이 우수한 경향이 있음을 확인할 수 있습니다. 이를 통해 토큰이 제한될 경우 멀티 에이전트 시스템보다 싱글 에이전트 시스템이 효과적일 수 있음을 확인하였습니다.
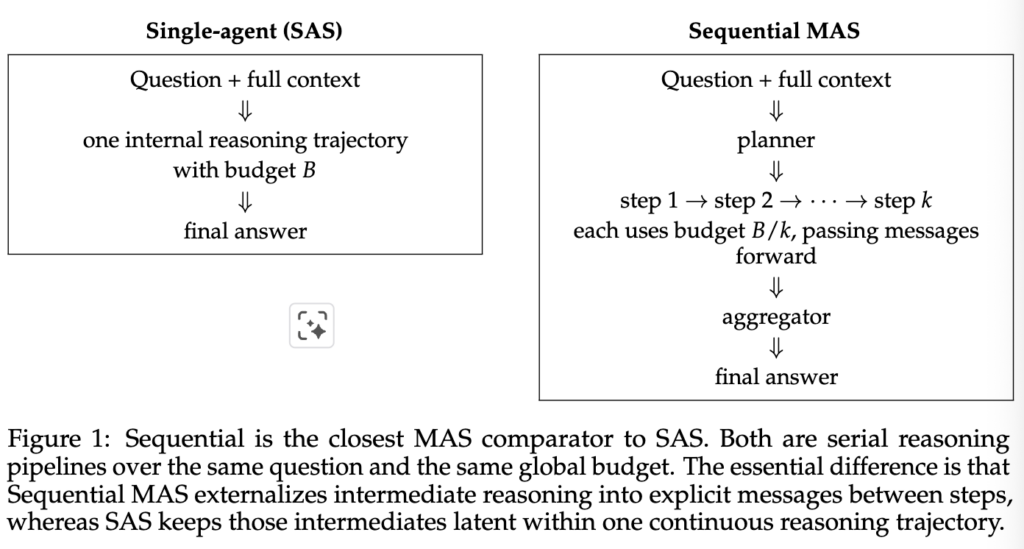
둘째로는 context degradation이 있을경우 실제로 MAS가 SAS보다 효과적일 수 있는지 검증했습니다. 해당 검증에서는 SAS와 가장 구조적으로 유사한 sequential MAS 구조가 MAS의 대표로 비교되었습니다.
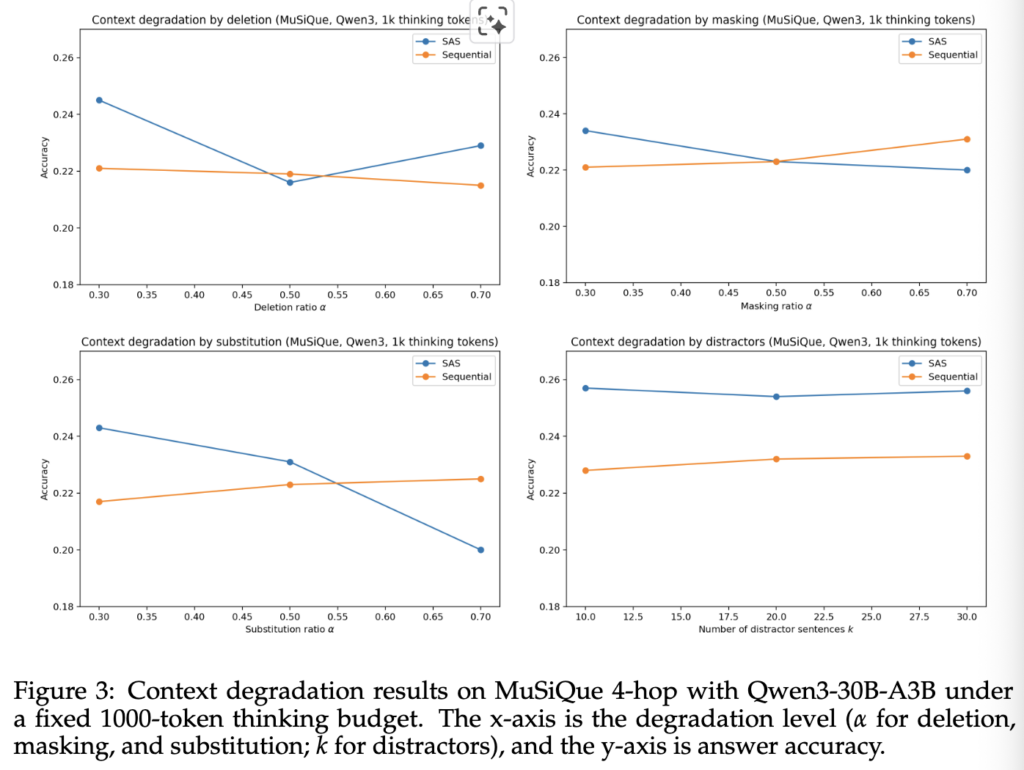
실험은 주석에서 확인가능하듯이 MuSiQue 데이터에 대해 Qwen3-30B-A4B 모델로 진행되었으며 결과는 아래와 같습니다. 먼저 질문에 일부 누락이 있는 Deletion(제2사분면)과 누락된 부분에 마스크를 채운 Masking(제1사분면), 누락된 부분을 단어장 내 랜덤 단어로 채운 substitution(제2사분면)의 경우 노이즈의 강도가 강해질수록(x축이 우측으로 갈수록, α 증가할수록) MAS가 강점을 보이고 있으며, 노이즈를 끝단에 계속 추가한 distractor(제4사분면) 역시 α가 증가할 수록 성능의 갭이 줄어들며 MAS의 효율이 개선되고 있음을 확인할 수 있습니다. 이를 통해 위에서 이론적으로 확인한 MAS의 성능 이점의 가능성을 실험을 통해 확인하였습니다.
추가
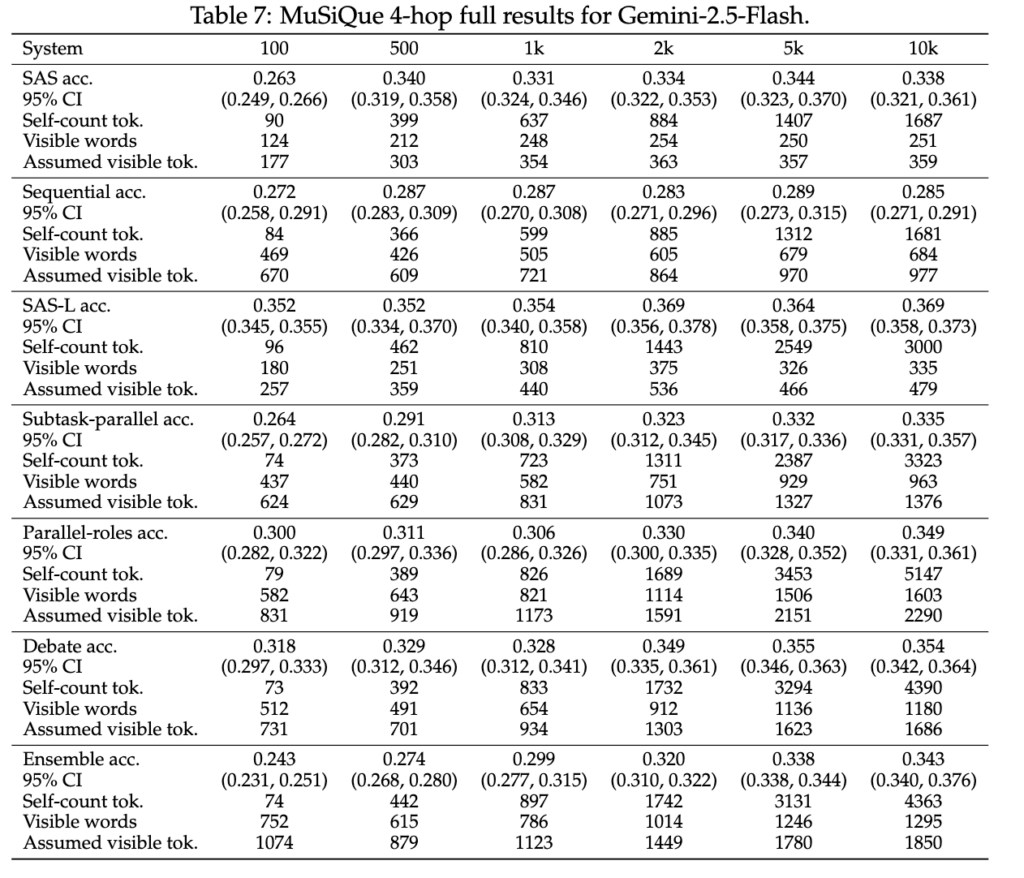
앞서서 기존 연구보다 토큰수를 엄밀하게 제약했다고 언급하였습니다. 특히 api 호출시에 발생하는 문제를 발견하고 이를 통제하였습니다. 아래의 table7은 gemini-2.5-flash 모델에 대한 결과입니다. 특히 api가 리포팅한 토큰 수(self-count tok.)와 실제 출력 기반 추정치(assumed visible thought tokens)의 불일치를 확인할 수 있는데요, api 가 보고하는 reasoning budget이 실제보다 작을 가능성이 있다고 우려합니다. 이를 보안하기 위해 조금 더 긴 reasoning을 수행하도록 프롬프트를 구성하였으며 실험에는 SAS-L로 리포팅하였습니다. SAS 대비 SAS-L에서 이러한 현상이 개선되었음을 확인할 수 있습니다. 한편 gemni 모델을 제외한 open source 모델에서는 이러한 불일치 현상이 적었으며 SAS 대비 SAS-L로 인한 성능 개선 역시 작았다고 합니다.
안녕하세요 유진님 리뷰 감사합니다.
이 논문의 결론이 MAS자체가 비효율적이라는 뜻이라기보다는 토큰 버싯이 제한된 상황에서는 MAS의 communication 오버헤드가 장점보다 커질수 있다는 뜻으로 이해해도 될까요?!
안녕하세요 찬미님 리뷰 읽어주셔서 감사합니다.
네 정확히 이해하셨습니다.
특히 context 에 대한 누락이 거의 없는 경우 (특히 NLP 테스크에서) token이 제한된 경우 SAS가 더 효율적임을 보인 논문으로 이해하시면 됩니다
감사합니다.
안녕하세요 유진님 좋은 리뷰 감사합니다.
Agent 관련 리뷰는 처음 봐서 궁금해서 읽게 되었습니다.
질문이 있어 댓글로 남기겠습니다!
1) 먼저, api 호출시에 생기는 문제가 무엇인지 궁금합니다! 단순히 인증 문제, 토큰 문제와 같이 흔히 생각할 수 있는 문제인지, 아니면, 토큰을 제한하면서생기는 API 호출 문제인지 궁금합니다!
2) 두번째로, 토큰을 제약이 필요한 경우가 어떤 경우인지 궁금합니다. 단순히 실험적인 분석을 위한 연구인지, token pruning 처럼 효율성에 대한 연구인지 궁금합니다!
3) 이어서, 토큰의 제약이 필요한 경우가 있다면, 그런 경우에는 위 실험 결과처럼 SAS를 사용하는 것이 합리적인 것 같은데, 이런 경우에, SAS와 MAS 중 어떤 방식을 사용할 지 결정하는 기준이 있을까요?!
Agent 연구에 대해 깊은 이해가 없어 생긴 의문일 수도 있을 것 같습니다!
감사합니다!