안녕하세요.
오늘은 long video understanding을 수행할 때, 모든 query에 대해 같은 방식으로 프레임을 샘플링하는 것이 아니라 query type에 따라 적절한 frame selection strategy를 다르게 적용하는 방법을 제안한 논문을 가져와봤습니다.
이 논문은 먼저 질문을 global query와 localized query로 나누고, global query에는 uniform sampling을, localized query에는 질문과 관련 있는 구간을 찾아내는 DIG pipeline을 적용합니다.
바로 리뷰 시작하겠습니다.
INTRO
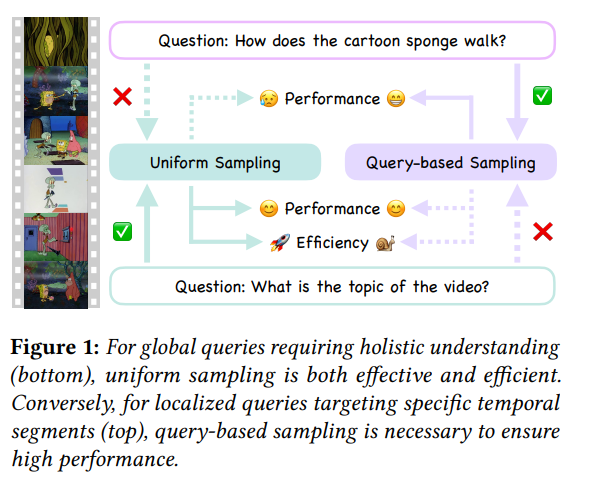
프레임을 선택하는 것에 대해 기존에는 보통 두가지의 선택지가 있습니다.
먼저 uniform sampling으로 비디오 전체에서 일정한 간격으로 프레임을 뽑는 방식입니다. 정해진 간격으로 뽑아내는 방식이기 때문에 비교적 싸고 빠르지만 질문과 관련이 딱히 없는 장면도 많이 들어가게 됩니다.
두번째로는 query-aware frame selection입니다. 이 방식은 쿼리를 보고 이 질문에 답하려면 어떤 프레임이 중요할까? 를 찾아서 뽑아내는 방식입니다. 당연히 uniform sampling보다는 똑똑하지만 계산비용이 발생하게 됩니다.
이때 그럼 qurey aware selection방식을 모든 질문에 다 해야하는가에 대해서 저자들은 아니다라고 답하면서 질문을 크게 Global Query와 Localized Query로 나눌수 있다고 말합니다.
먼저 Global Query는 전체 비디오를 봐야 답할 수 있는 질문을 말합니다. 예를 들면 이 영상의 주제는 뭔지, 전체적으로 무슨내용인지 와 같은 비디오의 전반적인 내용을 담은 질문입니다. 이런 질문은 특정 한 장면보다 영상의 전체 흐름이 중요하기 때문에 uniform sapling이 오히려 잘 맞습니다.
두번째로 Localized Query는 특정한 순간이나 물체, 행동을 찾아야 하는 질문 입니다. 예를 들면 쥐가 고양이를 뭐로 때렸는지, 남자가 어떤 자전거를 타고있는지와 같은 질문들을 말합니다. 요런 질문들은 답이 영상의 어딘가 짧은 구간에 숨어있기 때문에 전체를 대충 골고루 뽑는 uniform sampling은 해당 구간을 놓칠수도 있습니다.
따라서 저자들은 DIG라는 아이디어를 제안합니다. 아이디어는 굉장히 단순합니다. 질문을 먼저 LLM을 사용해 global인지 localized인지로 나누고 global이면 그냥 기존처럼 uniform sampling하고 localized이면 질문 관련 프레임을 찾는 pipeline을 씁니다.
저자들은 프레임 수를 많이 넣는다고 항상 성능이 좋아지는 것은 아니며, 특히 localized query에서는 관련 없는 프레임들이 context에 섞이면서 오히려 성능이 떨어질 수 있다고 봅니다.
따라서 DIG는 localized query에 대해서만 CAFS로 대표 프레임을 뽑고, LMM으로 relevance reward를 매긴 후에 관련 있는 연속 구간을 모아 refined video를 만들고 그 안에서 다시 uniform sampling을 수행합니다.
즉, DIG는 항상 복잡하게 찾는 방식이 아니라 localized query일 때만 CAFS와 reward scoring, video refinement를 포함한 복잡한 pipeline을 사용하는 방식입니다. 또한 이 방식은 별도의 추가 학습 없이 기존의 LLM/LMM과 DINO feature를 활용해 프레임 선택을 수행하는 training-free framework입니다. 저자들은 실험적으로 MLVU, LongVideoBench, VideoMME에서 기존 방법보다 좋은 성능을 보이고, 256 frames까지 늘려도 안정적인 향상을 보였다고 합니다!
Method: DIG
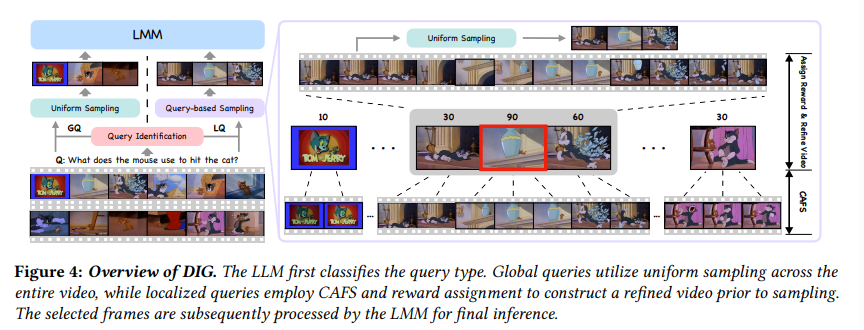
프레임워크는 크게 4단계로 흘러갑니다
1. 먼저 LLM이 query를 보고 global query인지 localized query인지 판단하는 질문 분류단계를 거치고
2. query type에 따라 다른 frame selection을 수행합니다
3. 이때 localized query일 경우 선택된 프레임들이 query와 얼마나 관련 있는지 평가하고
4. 이 평가결과(reward)를 기반으로 최종 생플링을 수행합니다.
1. Query Type Identification
첫번째 단계로 LLM에게 질문을 보여주고 이 질문이 전체를 훑어야하는 global query인지 특정 장면만 잘 찾으면 되는 localized query인지 판단하게 합니다.
만약 Global query로 분류되면 그냥 전체 비디오에서 uniform sampling한 프레임을 LMM에 넣고 바로 답하게 합니다. 하지만 Localized query로 분류 된다면 이후 설명할 파이프라으로 넘어갑니다. (그림에서는 연보라색 박스로 넘어갑니다)
2. Content-Adaptive Frame Selection, CAFS
앞서 query type이 localized query로 구분된다면 요 파이프라인으로 들어오게 됩니다.
CAFS의 역할은 전체 긴 비디오에서 먼저 의미적으로 대표성 있는 후보프레임들을 뽑는것 입니다. 여기서 중요한 점은 CAFS는 아직 질문 관련도를 직접 판단하는 단계가 아닙니다! 무슨말이냐면 이 프레임이 질문에 답하는데 중요하다! 를 기반으로 고르는 단계가 아니라, 비디오 전체 내용을 잘 대표하는 r-frame후보들을 만드는 단계입니다.
[Distance calculation]
CAFS의 첫번째 단계로 먼저 비디오를 2fps로 샘플링을 진행한 후 각 프레임을 DINOv2에 넣어서 visual feature를 뽑습니다. 그 다음 인접한 두 프레임의 feature를 비교합니다.
이 단계의 목적은 비디오 안에서 내용이 크게 튀는(바뀌는)지점을 찾기 위한 신호를 만드는 단계입니다.
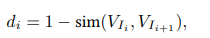
여기서 sim은 코사인 유사도로 두 프레임이 비슷하면 유사도가 높을것이고, 다르면 낮을것입니다.
이때 저자들은 역으로 1-유사도를 사용합니다. 즉 d_i가 크면 두 프레임 사이 내용이 크게 바뀌었다는 뜻이고, 작으면 두 프레임이 비슷한 장면이라는 뜻 입니다. 예를들어 갑자기 야외장면으로 바뀌거나 카메라 컷편집이 바뀌면 feature 차이가 커지고 distance값이 튈 것입니다!
[R-Frame selection]
그럼 방금 만듣 distance sequence(d_i)를 이용해 대표 프레임을 고르게 됩니다.
긴 비디오에서는 장면 전환이나 컷편집이 자주 생기는데 이런 지점에서는 프레임간의 차이가 커지기 때문에 distance sequence에서 peak가 생기게 됩니다.
저자들은 이 d_i가 양옆보다 크면 peak로 봅니다. 이때 작은 흔들림이나 노이즈까지 전부 피크로 보면 너무 많은 fake경계가 생길수 있기 때문에 prominence가 0.1(요 값은 실험적으로 정한 스레시홀드라고 합니다!…)보다 큰 피크만 유효한 피크로 사용한다고 합니다.
이 유효한 피크들이 비디오를 나누는 세그먼트 포인트가 됩니다. 각 세그먼트 구간에서는 프레임들이 비교적 비슷하기 때문에 대표 프레임 하나만 뽑습니다. 저자들은 단순하게 각 세그먼트의 중간프레임(midpoint frame)을 선택합니다. 이렇게 뽑힌 프레임이 r-frame 즉 representative frame이 됩니다.
3 Reward Assignment
앞서 뽑은 r-frame들을 이제 질문과 매칭해서 점수는 매기는 단계로 들어갑니다.
기존 query-aware selection 방법들은 보통 두가지 방식으로 관련성(relevance)를 판단하는데, 먼저 CLIPScore같은 image-text similarity기반 방식으로 프레임과 질문을 각각 임베딩해서 둘이 얼마나 비슷한지 보는 방식이고 두번째로 object detector를 사용하는 방식으로 질문에 등장하는 object나 entity를 프레임 안에서 찾는 방식이 있습니다.
저자들은 이 기존의 방식이 좀 부족하다고 말하는데 먼저 첫번째 방식은 표면적인 feature matching으로 만약 질문에 bike가 있고 프레임에 자전거가 있으면 점수는 높게 나오게 됩니다. 하지만 질문이 여자가 자전거를 왜 멈췄는지 같은 reasoning이 필요하면 단순히 자전거가 보인다고 해서 좋은 프레임으로 판단하기가 어렵습니다.
두번째 방식도 마찬가지겠죠! 정해진 vocabulary안에서 객체를 찾는건 잘하겠지만 의미나 인과관계까지 파악하기는 어렵습니다.
따라서 relevance 판단도 더 복잡한 맥락파악과 추론이 가능한 LMM에게 그냥 맡기는 방법을 선택했습니다. LLM이 프레임을 보고 질문을 읽고 이 프레임이 답에 얼마나 도움이 되는지 직접 점수를 메기게 하는 것 입니다.
[Two-dimensional scoring]
질문 Q와 각 r-frame을 비교해서 이 프레임이 질문에 답하는데 얼마나 유용한지에 대한 reward score를 매깁니다. 여기서 중요한 포인트가 two-dimensional scoring으로 단순히 프레임 하나만 보는것이 아니라 해당 프레임의 앞뒤 프레임까지 함께 봅니다.
LMM은 이 프레임들을 평가하기위해 두가지를 확인합니다.
먼저 현재 프레임 자체가 질문에 직접적으로 유용한지로, 예를들어 질문이 쥐가 고양이를 무었으로 때렸는가? 라면 현재 프레임에 쥐, 고양이, 도구가 보이면 직접적으로 유용한것 입니다.
두번째로는 현재 프레임을 보면 주변프레임에 답이 있을것 같은지를 체크합니다. 예를들어 현재 프레임에 쥐가 도구를 들고 고양이 옆에 서있다면 때리는 순간은 다음 프레임에 있을수도 있고 이런 경우 현재 프레임 자체가 완전한 답이 아니더라도 주변 구간이 중요하다는 신호가 되게 됩니다

프롬프트는 위의 사진과 같습니다. 먼저 프레임을 질문과 관련있는 요소 중심으로 설명하게 하고 0~100사이의 reward score를 매기게 합니다.
4. Video Refinement
이 단계는 앞서 얻은 reward score를 이용해서 실제로 어떤 r-frame이 진짜 중요한지, 그 r-frame주변의 어떤 비디오 구간을 최종 비디오로 남길지 정하는 단계입니다.
즉 단순히 프레임 몇장을 고르는게 아니라 질문과 관련있는 연속 구간들을 모아서 refined video를 만드는것 입니다.
[Iterative reward-guided selection]
이때 reward가 높은 r-frame을 고르는데, 단순히 top-k를 고르면 쉽겠지만 이 방식이 아닌 parameter-free 방식을 씁니다. 프레임을 사람이 하이퍼파라미터로 정하는것이 아니라 reward 분포를 보고 자동으로 남길 프레임을 정합니다.
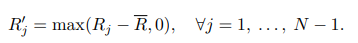
구체적으로는 위의 수식처럼 reward들의 평균 Rˉ를 구하고 그다음각 reward에서 평균Rˉ을 빼는데, 이때 평균보다 높은 리워드만 잘리고 평균 이하의 리워드는 0으로 만들게 됩니다. 그럼 양의 리워드만 가진 인덱스만 후보로 남게 됩니다.
저자들은 이 단계를 한번만 진행하는 것이 아니라 양수 인덱스 집합이 이전 이전 iteration과 달라지지 않을때까지 반복합니다. 쉽게 말하면 평균보다 좋은 애들만 남기고, 그안에서 다시 평균보다 좋은애들은 남기는 방식으로 점점 reward가 높은 후보들만 추려내는것이죠!
그렇게 최종 positive reward를 가진 r-frame들이 I_f가됩니다. 이 I_f는 그냥 대표 비디오 프레임이 아니라 질문과 관련도가 높다고 판단된 대표 프레임으로 최종 선택 되는것이죠!
[Segment combination]
DIG는 여기서 최종 선택된 r-frame 집합 I_f를 그대로 LMM입력으로 쓰는것이 아니라 I_f에 포함된 각 r-frame I’_j주변의 연속 비디오 구간까지 가져와 temporal context와 fine-grained한 디테일을 보존합니다.
이렇게 하는 이유는 r-frame 하나가 그 구간을 대표하기는 하지만 질문에 답하려면 앞뒤 장면이 필요할수 있기 때문입니다.
구체적으로는 각 I’_j는 피크인덱스 K_j와 K_j+1사이의 세그먼트 구간[K_j, K_j+1]을 대표하는 프레임으로 선택된 r-frame 한장만 사용하는 것이 아니라 해당 r-frame이 대표하는 세그먼트 전체를 가져옵니다.
여기에 wlen(=2)이라는 window length를 사용해서 주변 세그먼트들까지 함께 포함됩니다. 즉 I’_j를 기준으로 앞뒤 wlen만큼 확장해서 [K_j-wlen, K_j+1-wlen] 범위의 구간을 가져오는것 입니다.
이렇게 선택된 여러 비디오 구간들을 union operation으로 합쳐서 하나의 refined video가 되고 마지막으로 DIG는 이 refined video안에서 다시 uniform sampling을 수행해 최종 LMM입력 프레임을 구성하게 됩니다!
Experiment
벤치마크는 MLVU, LongVideoBench, VideoMME을 사용하였고 모델은 주로 Qwen2.5-VL-7B / 32B를 씁니다.
1. Main result
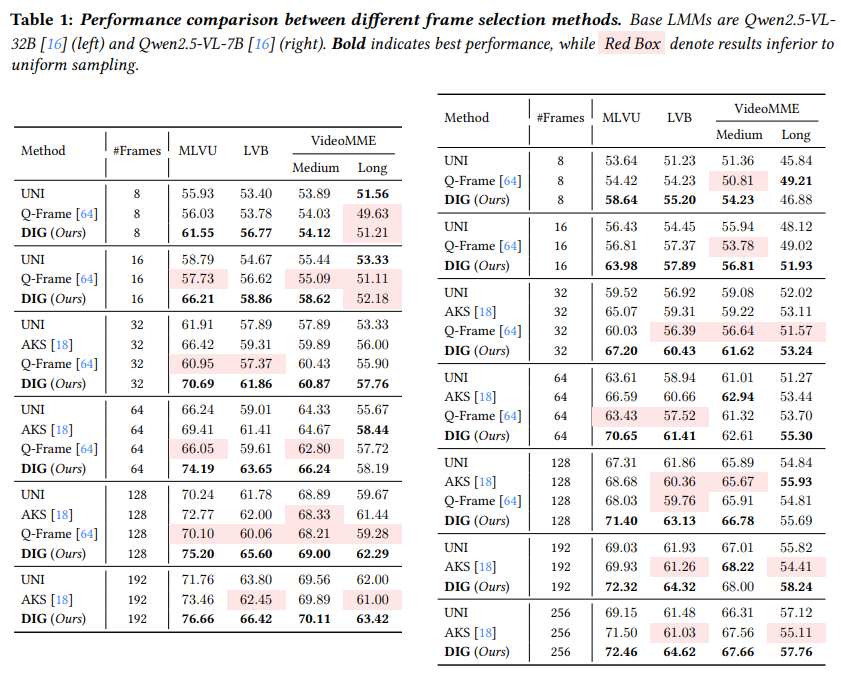
Table 1은 DIG와 Uniform Sampling, AKS, Q-Frame을 비교하는데, 프레임 수를 8, 16, 32, 64, 128, 192, 256까지 늘려가며 봅니다.
결과로 확인할수 있다싶이 DIG가 대부분의 설정에서 가장 좋은데, 특히 Qwen2.5-VL-7B에서 32 frames 기준으로 uniform sampling보다 MLVU와 LongVideoBench에서 꽤 크게 좋아지고 프레임 수가 많아져도 DIG가 안정적으로 좋습니다. 기존 frame selection 방법들인 AKS나 Q-Frame은 프레임 수가 커지면 uniform sampling보다 못해지는 경우도 있는것을 볼수 있습니다.
2. Frame Selection Strategy vs. Query Type
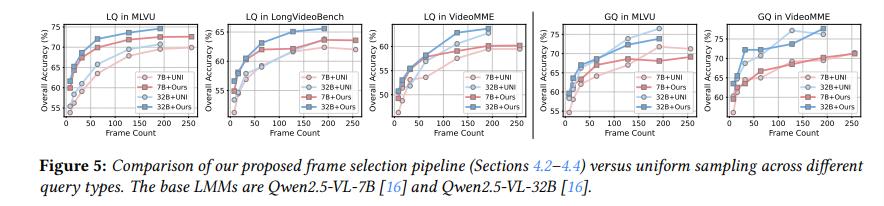
global query와 localized query를 나눠서 uniform sampling과 DIG pipeline을 비교하는 실험으로 frame selection strategy가 query type에 따라 다르게 작동한다는 주장을 실험적으로 확인합니다.
먼저 fig5를 보면 왼쪽의 3개의 그래프는 localized query결과이고 오른쪽 두개는 global query에 대한 결과입니다.
오른쪽의 Global query는 영상 전체의 주제나 흐름을 묻는 질문이라서, 특정 장면을 찾기보다 전체를 골고루 보는 게 중요합니다. 그래서 uniform sampling만으로도 충분히 잘 작동합니다. 반대로 localized query는 답이 특정 짧은 구간에 있는 질문입니다.
이때 uniform sampling을 쓰면 답과 상관없는 프레임이 많이 섞이고, 정작 중요한 장면을 놓칠 수 있습니다. 그래서 DIG처럼 질문과 관련 있는 구간을 먼저 찾고, 그 안에서 프레임을 뽑는 방식이 더 좋은 성능을 보입니다.
3. Analysis of CAFS Effectiveness
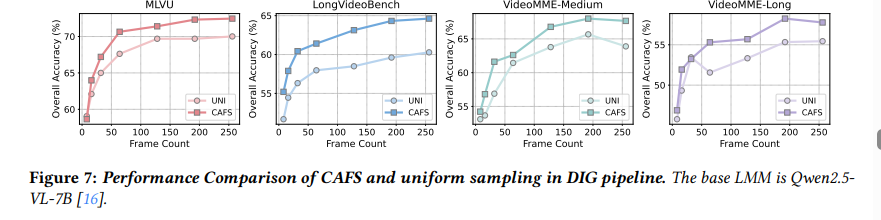
이 실험은 DIG 안에서 CAFS가 실제로 좋은 대표 프레임을 뽑는지를 분석하는 것으로 위의 fig7을 통해 DIG pipeline 안에서 CAFS를 사용했을 때와 CAFS 대신 uniform sampling으로 r-frame 후보를 뽑았을 때를 비교합니다.
결과를 보면 CAFS를 사용한 경우가 대부분의 벤치마크에서 uniform sampling보다 더 좋은 성능을 보이는 것을 확인할수 있습니다. 이것으로 localized query에서 중요한 장면을 찾기 위해서는 단순히 시간 간격대로 프레임을 뽑는것보다 비디오의 실제 내용 변화에 맞춰 대표 프레임을 뽑는것이 더 효과적이라는 것을 알수 있습니다.
4. Reward Assignment: LMM vs. CLIPScore
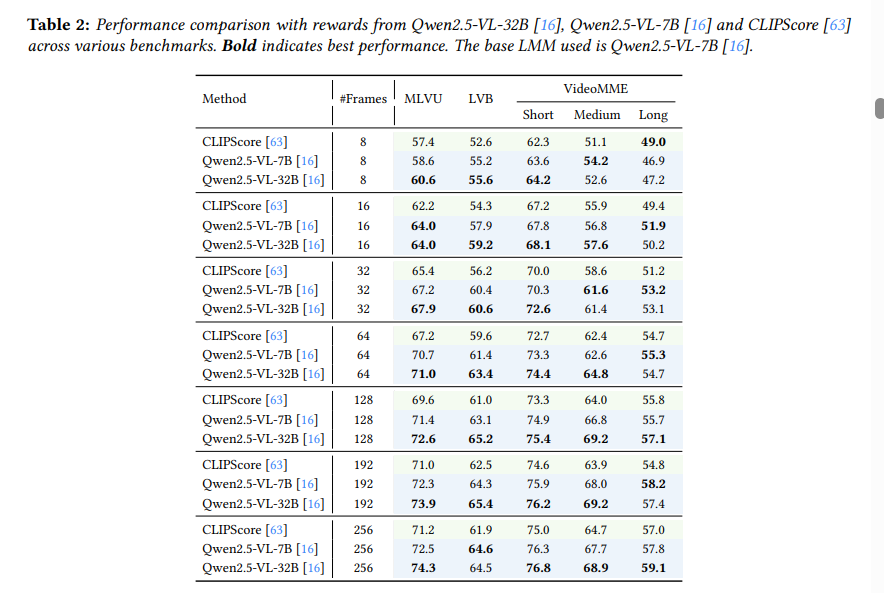
이 실험은 r-frame에 관련도 reward를 줄때 CLIPScore를 사용하는 것과 LMM을 사용하는 것 중 어떤 방식이 더 효과적인지 비교하는 실험입니다
기존의 방법들은 프레임과 쿼리의 관련도를 볼때 LIPScore 같은 image-text similarity 점수를 많이 사용하지만 CLIPScore는 표면적인 유사도에 의존하기 때문에 복잡한 reasoning이나 context가 필요한 질문에서는 한계가 있다고 합니다.
위의 table에서 확인할수 있다 싶이 reward를 할당하는 툴을 CLIPScore와 Qwen류로 바꿔 비교해보니 결과적으로 대부분의 설정에서 LMM을 reward 툴로 썻을때가 더 좋은 성능을 보입니다.
좋은 리뷰 감사합니다
Distance calculation 의 노이즈에 대해 추가 질문이 있습니다. 뉴스나 컷편집이 많은 데이터의 경우 threashold로 가려지지 않는 노이즈가 많을 것 같습니다. 예를 들어 현장에서 뉴스데스크로 장면전환이 있다고 항상 중요데이터가 아닐 수도 있을것같고, 그렇다면 이러한 전처리가 특정 데이터에만 적합한 가공일수도 있다는 생각이 있습니다.
이러한 우려에 대해 언급이 있었는지 궁금합니다. 혹시 실제 노이즈라던가 정보량을 측정하는 실험/방법이 있었나요?
(예를 들어 클러스터랑 이후 랜덤 샘플링 적용시 효과라던가…)
감사합니다
안녕하세요 유진님 댓글 감사합니다
저도 이부분은 보면서 조금 걸렸던 부분인데, CAFS가 결국 장면 변화가 크게 튀는 지점을 잡는 방식이라 뉴스나 컷 편집이 많은 영상에서는 장면 전환 = 중요한 정보가 항상 맞지는 않을 것이라 생각했습니다.
논문에서도 컷편집이나 장면전환 때문에 피크가 만힝 생길수 있다고 언급하고 이걸 prominence threshold로 어느 정도 걸러내려 한것입니다! 다만 이 값 자체가 경험적으로 냅다 고정한 값이라 말씀 주신 것 처럼 데이터 특성에 따라 민감할수 있을것 같습니다
하지만 noise 자체를 직접 측정하거나 컷 전환이 많은 데이터에서 실제로 noise가 얼마나 생기는지, threshold가 얼마나 적당한지 등은 따로 분석한 실험은 없습니다..!
안녕하세요 찬미님, 좋은 리뷰 감사합니다.
저도 최근에 adaptive frame sampling 논문을 읽게 되서 제가 읽은 논문과 어떤 차이가 있을지 궁금해서 읽어보게 되었습니다. 상당 부분 비슷한 점이 많아보이지만, 본 논문은 LLM/LMM 의존성이 꽤 높아보입니다. 질문을 global/localized query로 구분하거나 relevance를 판단하는 등 많은 작업을 맡겼는데, 논문에 혹시 이런 LLM 작업을 신뢰할 수 있는지를 보여줄 수 있는 내용 또는 결과가 있는지 궁금합니다.