안녕하세요 이번에 들고온 논문도 VLM 에서의 token pruning 논문입니다. 제가 분석하고있는 방법론과 비슷한 키워드로 검색되어 찾아본 논문으로 아이디어를 확인하고자 읽게되었습니다. 바로 리뷰 시작하겠습니다.
Abstract
VLM들은 vision token을 과도하게 생성하기 때문에 상당한 계산 비효율 문제에 직면해 있다고 합니다. 기존 연구들은 visual token의 상당 부분이 redundant, 즉 중복적이라는 것을 보여주었지만, 기존 compression 방법들은 중요한 정보의 보존과 정보 다양성 사이의 균형을 맞추는 데 어려움을 겪는다고 합니다. 이를 해결하기 위해 저자는 PRUNESID를 제안하고 training-free 방식의 Synergistic Importance-Diversity approach로 다음과 같은 2단계 파이프라인을 거칩니다.
- Principal Semantic Components Analysis, PSCA는 token들을 의미적으로 일관된 그룹으로 clustering 하고 다양한 concept들이 포괄적으로 포함되도록 보장합니다.
- 두 번째는 Intra-group Non-Maximum Suppression, NMS이며 이는 각 그룹 내부에서 핵심 representative token을 보존하면서 redundant token들을 pruning합니다.
추가적으로 PRUNESID는 information-aware dynamic compression ratio mechanism을 포함한다고 합니다. 이 매커니즘은 image 의 복잡성에 기반하여 토큰 compression rate를 최적화하고 다양한 scene에서 평균적인 information preservation을 더 효과적으로 가능하게 합니다.
Introduction
우선 VLM은 LLM의 발전에 이어, 이미지를 visual token sequence로 encoding하여 text token과 함께 처리함으로써 multimodal reasoning을 가능하게 하는 방향으로 발전해왔습니다. 하지만 이러한 구조는 필연적으로 계산 비효율성을 유발하게 됩니다. 예를 들어 LLaVA-1.5는 이미지 한 장당 576개의 visual token을 생성하고, LLaVA-NeXT는 high-resolution setting에서 2880개의 visual token을 생성합니다. 이는 이미지의 핵심 semantic content를 표현하는 데 필요한 양보다 훨씬 많은 token 수라고 저자는 설명합니다. 또한 기존 empirical study에서는 약 70%의 visual token을 제거해도 accuracy degradation이 거의 없다는 점을 보였지만, 기존 compression 방법들은 high compression ratio에서 중요한 token을 보존하는 것과 정보의 다양성을 유지하는 것을 동시에 만족시키지 못한다는 한계가 있다고 합니다.
저자는 현재 visual token reduction 기법들을 크게 두 가지 흐름으로 나눕니다. 첫 번째는 attention-guided selection method입니다. 이 방법들은 visual token의 attention score를 기준으로 중요한 token을 남기는 방식입니다. 이러한 방법은 semantic하게 salient한 region, 즉 눈에 띄고 중요한 object 영역을 보존하는 데는 효과적입니다. 하지만 attention이 높은 object 주변 patch들만 반복적으로 남기기 쉬워, 서로 비슷한 object segment token들이 중복적으로 유지되는 문제가 발생합니다. 또한 background나 contextual region을 충분히 보존하지 못하기 때문에 scene 전체 이해가 약해질 수 있다고 합니다. Figure 1(b)가 이러한 attention-guided 방식의 한계를 보여주는 예시입니다.

두 번째는 duplication-aware approach입니다. 대표적으로 DART나 DivPrune과 같은 방법들이 있으며, token 간 similarity를 기준으로 redundant token을 제거하는 방식입니다. 즉, 비슷한 token들을 줄여서 information diversity를 확보하려는 접근입니다. 하지만 이 방식은 token-level semantic importance를 충분히 고려하지 못하는 문제가 있습니다. 따라서 attention score가 높고 의미적으로 중요한 token이라도, 다른 token과 유사하다는 이유로 제거될 수 있습니다. Figure 1(c)는 이러한 duplication-aware 방식이 중요한 semantic region을 버릴 수 있음을 보여주는 예시입니다.
저자는 이 두 흐름이 각각 반대되는 한계를 가진다고 정리합니다. Attention-guided 방식은 중요한 object region은 잘 보존하지만 정보 다양성이 부족하고, duplication-aware 방식은 diversity는 개선하지만 semantic salience 보존이 약할 수 있습니다. 즉, visual token compression에서는 importance preservation과 information diversity 사이의 trade-off가 존재하며, 기존 방법들은 이 균형을 적절히 해결하지 못했다고 주장합니다.
이러한 문제를 해결하기 위해 저자는 PRUNESID라는 training-free visual token compression framework를 제안합니다. PRUNESID는 task-agnostic하게 적용 가능한 효율적이고 일반적인 framework이며, 핵심적으로 중요도 보존과 정보 다양성 유지를 동시에 최적화하는 것을 목표로 합니다. 저자의 방법론은 크게 두 단계로 구성됩니다. 첫 번째는 Principal Semantic Components Analysis, PSCA이고, 두 번째는 Intra-group Non-Maximum Suppression, NMS입니다.
먼저 PSCA는 PCA-driven decomposition을 활용하여 visual token들을 여러 개의 semantically coherent group으로 자동 clustering합니다. 쉽게 말하면, 전체 visual token을 하나의 pool에서 바로 pruning하는 것이 아니라, 먼저 의미적으로 유사한 token들끼리 group을 형성하게 합니다. 이를 통해 이미지 안에 존재하는 다양한 visual concept들이 빠지지 않고 포괄적으로 고려될 수 있도록 합니다. 예를 들어 object, background, texture, 주변 context와 같은 서로 다른 semantic component들이 각각의 group으로 나뉠 수 있고, 이후 pruning 과정에서 특정 concept만 과도하게 남거나 사라지는 문제를 줄일 수 있습니다.
그다음 Intra-group NMS는 각 group 내부에서 redundant token을 제거하는 과정입니다. Object detection의 NMS에서 영감을 받아, group 내부 token들 간의 pairwise similarity threshold를 동적으로 설정하고, 서로 유사한 token들 중에서는 가장 의미적으로 중요한 representative token을 남기게 됩니다. 즉, PSCA가 concept coverage를 담당한다면, intra-group NMS는 각 concept 내부에서 중복을 제거하여 information density를 높이는 역할을 합니다. 저자는 이러한 dual-stage mechanism이 기존 방법들이 겪던 concept coverage와 information density 사이의 trade-off를 해결한다고 설명합니다.
추가적으로 PRUNESID는 information-aware dynamic compression ratio mechanism을 도입합니다. 기존 token compression 방법들은 보통 모든 이미지에 동일한 compression ratio를 적용합니다. 하지만 실제 이미지들은 매우 다릅니다. 어떤 이미지는 object가 많고 scene이 복잡한 반면, 어떤 이미지는 배경이 단순하고 정보량이 적습니다. 저자는 이러한 차이를 반영하기 위해 image-level information score를 계산하고, 이미지 복잡도에 따라 token budget을 동적으로 할당합니다. 즉, semantic information이 풍부한 복잡한 이미지에는 더 많은 token을 남기고, 단순한 이미지에는 더 강한 compression을 적용하는 방식입니다. 이를 통해 image 간 variability가 큰 dataset에서도 평균적인 information preservation을 향상시킬 수 있다고 합니다.
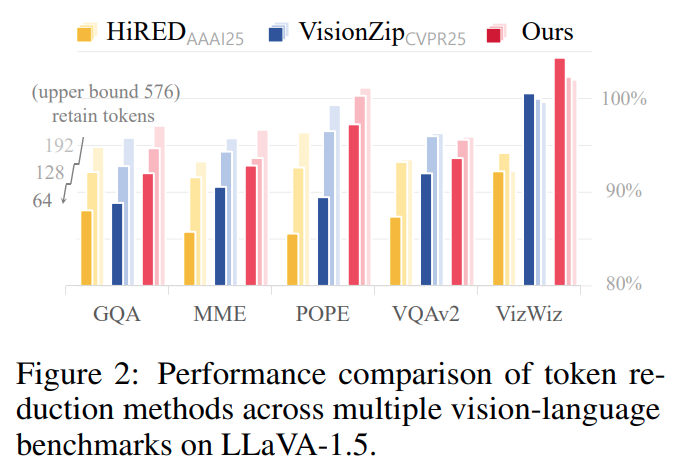
Figure 2에서 보이는 것처럼, PRUNESID는 여러 vision-language benchmark에서 기존 방법보다 높은 성능을 달성했다고 합니다. 특히 LLaVA-1.5에서는 64 token만 사용하여, 즉 11.1% token 만으로도 96.3% accuracy를 달성하였고, VisionZip의 92.5%, HiRED의 87.9%보다 높은 성능을 보입니다. 또한 LLaVA-NeXT에서는 5.6% token retention이라는 극단적인 compression setting에서도 92.8% accuracy를 유지하며, 기존 방법보다 2.5%p 높은 성능을 보였다고 합니다. 추가적으로 Video-LLaVA에서도 6.6% token retention만으로 SOTA를 달성하여, image modality뿐 아니라 video modality에서도 적용 가능함을 보였다고 합니다.
저자의 연구 기여도를 요약하면 크게 3가지입니다.
- VLM에서 training-free visual token compression framework인 PRUNESID를 제안하였고, PSCA 기반 semantic clustering과 intra-group NMS 기반 redundancy pruning을 통해 importance-diversity trade-off를 해결하고자 함
- Image-level information score를 계산하여 이미지별 token budget을 동적으로 할당하는 information-aware dynamic compression ratio mechanism을 제안하였고, 이를 통해 복잡한 scene과 단순한 scene 모두에서 효과적인 information preservation을 가능하게 함
- 다양한 VLM과 image/video task에서 기존 SOTA보다 우수한 성능을 보였으며, 특히 5.6% retention과 같은 extreme compression setting에서도 최대 2.5%p의 accuracy gain을 달성하여 강한 generalization 성능을 보임
Method
저자의 방법론은 입력 이미지가 주어졌을 때, VLM의 pre-trained vision encoder가 먼저 visual token embedding sequence를 생성한다는 설정에서 시작합니다. 이 token sequence는 X = \{x_1, ..., x_T\} \in \mathbb{R}^{T \times D} 로 표현되며, 여기서 T는 token 수, D는 embedding dimension을 의미합니다. 저자의 목표는 이 token sequence를 훨씬 더 compact한 representation인 \tilde{X} \in \mathbb{R}^{N \times D} 로 줄이는 것입니다. 여기서 N<T, 즉 남기는 token 수 N은 원래 token 수 T보다 훨씬 작습니다. 하지만 token 수를 줄이면서도 두 가지를 보장하고자 합니다. 첫째, semantically salient한 visual pattern을 최대한 보존하는 것, 둘째, downstream language modeling task에 필요한 정보의 integrity를 거의 완전하게 유지하는 것입니다.
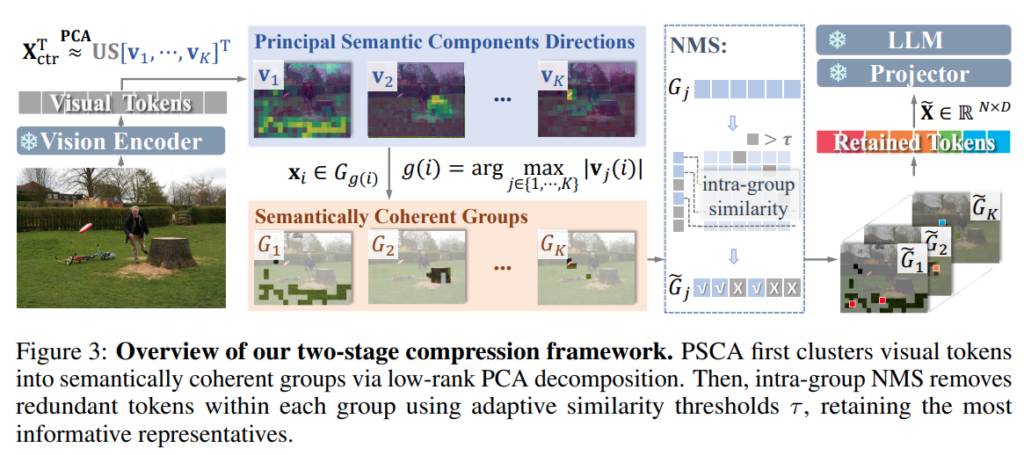
Figure 3에서 보이는 것처럼, 전체 방법론은 크게 두 단계로 구성됩니다. 첫 번째는 Principal Semantic Component Analysis, PSCA를 통한 semantic-aware token grouping이고, 두 번째는 Non-Maximum Suppression, NMS를 통한 intra-group redundancy elimination입니다.
PSCA는 visual token들을 semantic principal component direction에 대한 contribution을 기준으로 clustering합니다. 이를 통해 semantic coherence와 structural diversity를 모두 유지하는 group을 생성합니다. 이후 adaptive intra-group pruning을 결합하면, 정보 보존과 다양성 사이의 균형을 맞춘 compact하지만 expressive한 token representation set을 얻을 수 있다고 합니다.
쉽게 말하면, PRUNESID는 전체 token을 한 번에 top-K로 자르는 방식이 아닙니다. 먼저 token들을 의미적으로 비슷한 group으로 나누고, 그다음 각 group 내부에서 중복 token을 제거합니다. 그래서 특정 object나 salient region만 과도하게 남기는 문제를 줄이고, 동시에 background나 texture 같은 다른 semantic component도 어느 정도 보존하려는 구조입니다.
Semantic-Aware Token Grouping via PSCA
PSCA는 일반적인 PCA와 다르게 정의됩니다. 일반적인 PCA는 feature dimension에서 variance가 큰 방향을 찾는 방식입니다. 반면 PRUNESID의 Principal Semantic Components Analysis, PSCA는 token dimension 자체를 semantic axis로 보고 decomposition을 수행합니다. 즉, feature 차원에서 분산이 큰 방향을 찾는 것이 아니라, token들 사이의 variation을 분석하여 coherent visual concept을 반영하는 global semantic direction을 찾으려는 접근입니다. 저자는 이를 통해 object, background, texture pattern과 같은 latent conceptual structure를 token space에서 발견할 수 있다고 설명합니다.
구체적으로 token embedding matrix X가 주어지면, 먼저 각 element에 sigmoid activation σ를 적용합니다. 이는 feature scale을 bounded하고 comparable하게 만들기 위한 과정입니다. 그다음 token dimension을 기준으로 feature를 centering하여 global bias를 제거합니다. 이렇게 얻어진 mean-centered feature matrix는 다음과 같이 정의됩니다.
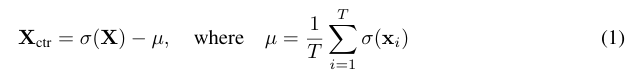

X_{ctr} 값은 zero-mean token matrix가 되고, 각 row는 하나의 token에 대응됩니다. 그 다음 저자는 X centor가 아니라 transpose matrix에 low-rank PCA decomposition을 적용합니다. 여기서 V는 token dimension 위에서 orthonormal basis를 정의하는 top-K right singular vector를 의미합니다.
그리고 |V_{i,:}| 의 각 row는 i-번째 token이 K개의 principal component 각각에 얼마나 기여하는지를 나타냅니다. 값이 클수록 해당 token이 그 component direction과 더 강하게 관련되어 있다는 의미입니다.
이후 discrete token group을 만들기 위해, 각 token x_i를 absolute contribution이 가장 큰 principal direction에 할당합니다.

이 과정을 통해 원래 T개의 visual token은 K개의 semantically coherent group으로 나뉩니다. 각 group은 이미지 전체에서 공유되는 semantic information을 포착하게 됩니다. 여기서 중요한 점은 PSCA가 단순히 중요한 token을 고르는 과정이 아니라 token들을 먼저 semantic component별로 나뉘는 과정입니다. 그래서 attention score가 높은 token만 남기거나 similarity가 높은 toekn만 제거하는 방식입니다. 서로 다른 semantic concept들이 pruning 전에 분리되어 관리될 수 있습니다.
Intra-group Redundancy Removal via NMS
PSCA를 통해 token들이 group으로 나뉘면, 각 group 내부에는 여전히 spatial 또는 semantic overlap이 큰 token들이 많이 존재할 수 있습니다. 특히 dense texture가 있는 영역이나 salient object가 있는 영역에서는 비슷한 patch token들이 여러 개 존재할 가능성이 높습니다. 이를 줄이기 위해 저자는 각 group $G_k$에 대해 Non-Maximum Suppression, NMS 전략을 적용합니다. 이 NMS는 가장 informative한 token은 보존하면서, spatial 또는 semantic redundancy를 보이는 token들을 제거하는 역할을 합니다.
각 token x_i에는 selection score s_i가 부여됩니다. 이 값은 해당 token이 자신이 할당된 group의 principal direction에 얼마나 기여하는지를 나타냅니다.
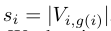
즉 s 값이 클수록 해당 token은 자신이 속한 semantic component를 대표하는 정도가 큰 token입니다.
그다음 각 group 내부에서 greedy NMS를 수행합니다. 과정은 다음과 같습니다. 먼저 token들을 s_i값 기준으로 정렬합니다. 이후 어떤 token을 남길지 판단할 때, 이미 선택된 token들과의 최대 similarity가 threshold τ보다 낮은 경우에만 해당 token을 보존합니다. 즉, 이미 선택된 token들과 너무 비슷하면 redundant하다고 보고 제거합니다. 이 과정을 통해 refined subset G_k 를 얻으며, 이는 group의 semantic diversity를 유지하면서 redundant token을 효과적으로 제거하는 역할을 합니다.
여기서 threshold τ는 고정값이 아니라 adaptive하게 설정됩니다. 이를 위해 저자는 이미지 내 모든 token 간 average pairwise similarity를 계산하여 global redundancy score ρ를 정의합니다.
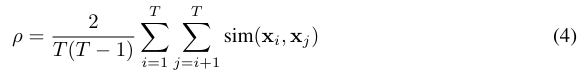
여기서 similarity는 L2 normalized token 사이의 cosine similarity로 계산됩니다.
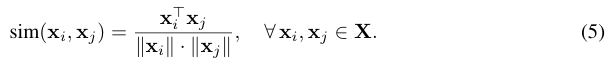
이후 NMS의 임계값은 다음과 같이 설정됩니다.
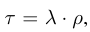
여기서 람다값은 필요한 token수를 32로 나눈 값으로 하이퍼파라미터로 생각하면 됩니다.
즉, PRUNESID는 group별로 token을 남기기 때문에 특정 semantic component만 과도하게 남는 것을 방지하고, 각 group에서 대표성 높은 token을 선택하는 구조입니다.
Information-Aware Dynamic Compression Ratio Across Images
기존 token compression 방법들은 보통 모든 이미지에 동일한 fixed token compression ratio를 적용합니다. 예를 들어 모든 이미지에서 576개 token 중 64개만 남긴다거나 2880개 token중 320개만 남기는 식입니다. 하지만 저자는 이러한 uniform compression이 suboptimal 하다고 지적하고 복잡한 scene에서는 미리 정해진 N이 부족해서 excessive information loss가 발생할 수 있고, 반대로 단순한 scene에서는 같은 N이 불필요하게 커서 redundancy가 남을 수 있기 때문입니다.
이를 해결하기 위해 저자는 앞서 정의한 global redundancy measure ρ 를 기반으로 image information ratio를 다음과 같이 계산합니다.
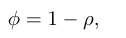
여기서 ϕ가 높다는 것은 semantic diversity가 크고 redundancy가 적다는 뜻입니다. 즉, 이미지 안에 서로 다른 정보가 많이 포함되어 있을수록 ϕ가 커지고, 비슷비슷한 token이 많을수록 ϕ는 작아집니다.
Experiments
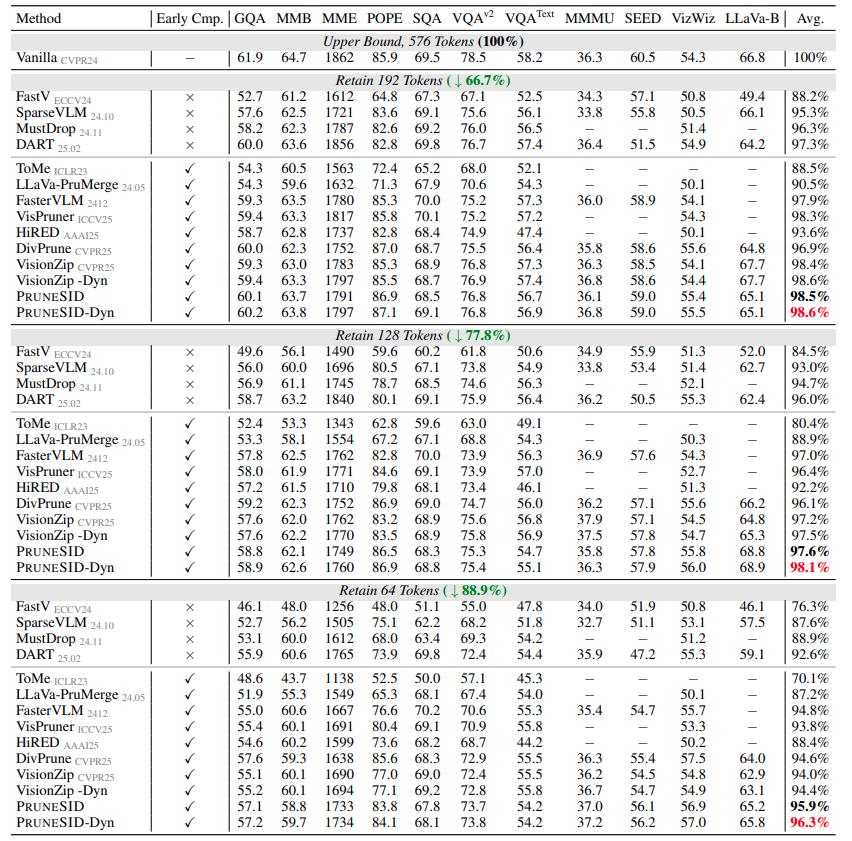
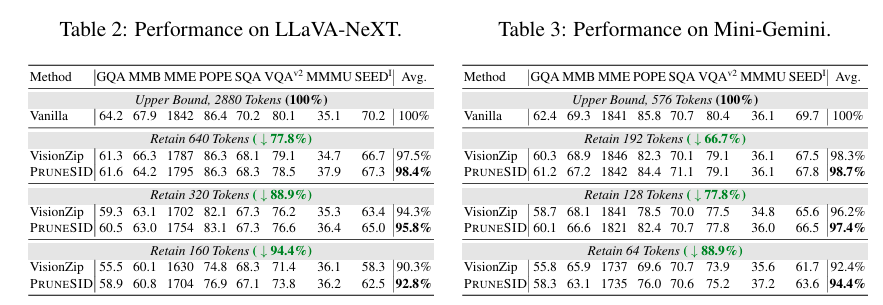
우선 Table 1,2 는 LLaVA-1.5-7B 와 LLaVA-NeXT-7B 로 다른 pruning 논문들에서도 흔히 리포팅하는 메인 테이블입니다. 저자의 방법론이 비슷한 시기에 쓰인 논문들처럼 VisionZip을 메인으로 이겨서 리포팅했습니다. 아마 text를 사용하지 않아 다른 논문들이 리포팅하는 32token 세팅을 리포팅했다면 많이 낮아졌을거라 생각합니다.
Ablation on Token Grouping Strategy
먼저 저자는 intra-group NMS 이전에 어떤 방식으로 token grouping을 하는지가 중요한지 확인합니다.
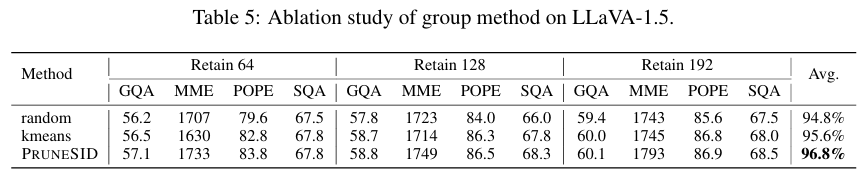
결과로는 단순히 group을 나누는 것 자체가 중요한게 아니라, semantic principal component 구조를 반영해서 group을 나누는 것이 중요하다는 결과입니다.
Ablation on ViT Layer Features for PSCA Grouping
다음은 PSCA grouping에 어떤 ViT Layer feature를 사용하는 것이 좋은지에 대한 ablation입니다.
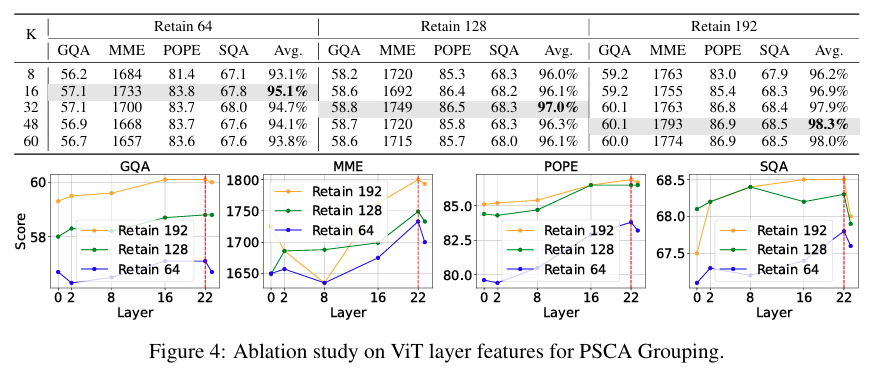
Figure 4를 보면 layer0,2 같은 early layer보다 16,22같은 middle-to-late-layer를 사용할때 성능이 더 좋습니다. 저자는 early layer가 low-level visual feature가 강하고 semantic information이 부족하기 때문에 grouping에 적합하지 않다고 설명합니다. layer22가 -2번째 layer인데 보통 다른 논문들도 해당 layer를 사용합니다. 기존에 관례처럼 사용하던 layer에 대한 ablation을 진행했다고 이해해도 될 것 같습니다.
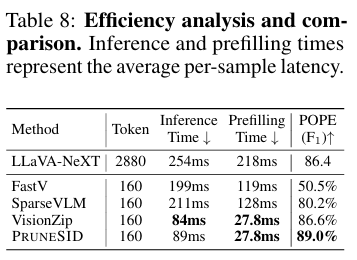
Table8은 실제 inference efficiency를 보여줍니다. 특히 LLaVA-NeXT에서 visual token이 많아 prefilling time이 길어지는 문제를 다룹니다.
VisionZip과 비교하여 latency는 거의 비슷하지만 성능이 좀더 높은걸 확인할 수 있습니다.
Conclusion
저자는 PRUNESID를 training-free, task-agnostic visual token reduction framework로 제안합니다. 핵심은 PSCA와 intra-group NMS의 결합입니다. 본 논문 내용중에는 왜 둘을 같이 사용하는것이 합당한지 설명하는 파트도 존재하는데 수식적인 내용으로 리포팅하지 않았습니다.
PSCA는 visual token들을 semantically coherent group으로 나누어 concept coverage를 확보하고, intra-group NMS는 각 group 내부에서 redundant token을 제거하여 information diversity를 유지합니다. 이를 통해 PRUNESID는 importance-aware selection과 information diversity 사이의 균형을 맞추고자 합니다. 또한 dynamic compression ratio mechanism을 통해 image complexity에 따라 retained token 수를 조절함으로써 전체 성능을 더 개선합니다. 여러가지 sub 실험들이 기존에 다른 논문들이 리포팅하지 않았던 형태기도 하고 각 분석들이 한 0.1 contribution처럼 느껴지긴 했습니다.. 어느정도 task가 고인만큼 세세한 실험들을 어떻게 구상했는지 좀 얻어간 것 같습니다.
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
layer 22처럼 middle-to-late layer를 사용하는 것이 좋다고 했는데 이게라바 계열에서는 잘 맞더라도 다른 비전 인코더나 다른 해상도 설정에서도 동일하게 유지되는지 궁금합니다. 그냥 단순히 만약 모델마다 최적 layer가 다르면 training- free라고 하더라도 어느 정도 모델별 튜닝이 필요할 수 도 있지 않을까라는 생각이 들었습니다. 만약 해당 내용에 대한 언급이 없다면 middle-to-late-layer가 성능이 좋게 나오는 이유가 궁금합니다. 감사합니다.
안녕하세요 우현님 좋은 답글 감사합니다.
해당 layer 22같은 발언은 라바 계열에서는 그냥 당연하게 쓰이고 있는 그런 설정이고 다른 모델에서도 그러한 특징이 발견되었다면 아마 널리 알려졌을텐데, 지금 당장 저는 잘 모르긴 하네요.. middle to late layer가 성능이 좋게 나오는 이유에 대해서는 아마 그런 layer별 분석만을 메인 타겟으로 하는 논문들이 있긴 할겁니다. 뭔가 설명드리기에는 제 단순 추측에 불과할거같아서 검색이 불가피할 것 같네요..
감사합니다.