안녕하세요. 이번에 리뷰로 가져온 논문은 CVPR 2026 highlight 논문인 WANDERLAND: Geometrically Grounded Simulation for Open-World Embodied AI라는 논문입니다. 이 논문은 최근 embodied AI나 visual navigation 쪽에서 많이 이야기되는 real-to-sim 기반 시뮬레이션 환경에 대한 논문이라고 보시면 좋을 것 같습니다.
그리고 저자는 일전에 제가 리뷰와 세미나로 다뤘던 CityWalker의 저자이고 당시 CityWalker는 평가 자체는 주로 open-loop 기반이었습니다. 모델이 예측한 waypoint가 GT trajectory와 L2 distance 기준으로 얼마나 가까운지 방향 예측이 얼마나 맞는지처럼 단순히 정답과 비슷한 trajectory를 뱉는지를 보는 평가에 가까웠다고 보시면 좋을 것 같습니다. 근데 이번 WANDERLAND에서 저자는 citywalker에서랑은 다르게 실제 agent가 시뮬레이션 안에서 움직이며 평가될 수 있는 closed-loop benchmark를 만들고자 합니다. 그래서 이전 연구인 CityWalker뿐만 아니라 NoMaD, MBRA, 그리고 VLN 계열 방법론까지 저자들이 만든 benchmark 안에서 함께 비교합니다. 지금까지 모바일 로봇 내비게이션 쪽은 자율주행 연구와 다르게 각 논문이 자기 환경에서 자기 방식으로 평가하는 self-evaluation 성격이 강하다는 느낌이었는데 이제 모바일 로봇 내비게이션 분야도 점점 AD의 NAVSIM이나 Bench2Drive처럼 공통된 benchmark 를 만들고자 하는 흐름을 보이는 것 같습니다.
바로 리뷰 시작하도록 하겠습니다.
Introduction
기존 embodied AI 연구에서는 Habitat, Gibson, Matterport3D, HM3D 같은 시뮬레이션 환경이 많이 사용되었습니다. 이런 환경들은 agent가 실제로 움직이면서 point-goal navigation, image-goal navigation, object navigation 같은 태스크를 평가할 수 있게 해줍니다. 근데 이런 기존 이런 시뮬레이션 benchmark들은 대부분 실내 환경 중심입니다. 대부분 집, 방, 복도, 실내 공간 위주로 구성되어 있기 때문에 outdoor를 타깃으로 하는 혹은 실내 실외를 둘다 오가는 연구 같은 경우에는 해당 벤치마크로 평가하기 어려울 수 있습니다.
그래서 최근에는 이런 open-world 환경을 시뮬레이션으로 만들기 위해 video 기반 real-to-sim 연구들이 등장했습니다. 논문에서는 대표적으로 Vid2Sim과 GaussGym을 비교 대상으로 많이 이야기합니다.
이 방식들은 기본적으로 실제 사람이 걸어다니며 찍은 video를 기반으로 3DGS scene을 만들고 그 안에서 배미게이션 policy를 학습하거나 평가하려고 합니다. 굳이 비싼 장비로 직접 장면들을 스캔안해도 된다라는 장점은 있는데 여기서 저자들이 보기에 video-3DGS 기반 파이프라인은 학습용 데이터를 만들기엔 좋을 수 있어도 실제 벤치마크로써 평가환경을 구축하는데에는 문제가 있다고 지적합니다.
Vid2Sim이나 GaussGym 같은 방식은 보통 COLMAP, GLOMAP, VGGT 같은 vision-only reconstruction 방법에 의존합니다. 근데 RGB 이미지만 가지고 reconstruction을 하면 metric scale이 부정확하다라는 단점이 있습니다. 특히 visual navigation 벤치마크에서는 agent가 몇 미터 이동했는지, goal까지 얼마나 남았는지, 충돌이 발생했는지가 중요하기 때문에 metric scale이 무조건 중요하다 라고 저자들은 주장합니다.
그리고 3DGS는 보통 실제와 같은 photorealistic한 좋은 이미지를 렌더링하는 데는 좋지만 로봇이 실제로 움직이면서 충돌 판단을 할 수 있는 신뢰할만한 geometry를 제공하지는 않습니다. 그래서 3DGS 기반 시뮬레이터를 내비게이션 벤치마크로 쓰려면 품질 좋은 렌더링과 별도로 신뢰할만한 collision geometry정보가 필요하다라고 주장합니다.
그리고 실제 로봇 내비게이션에서는 agent가 항상 training camera trajectory 위에서만 움직이지 않습니다. 실제 policy가 움직이면 원래 촬영 경로에서 벗어난 시점 (off-trajectory view)가 계속 발생합니다. 근데 일반적인 video는 보통 한 방향으로 걸어가면서 찍은 trajectory가 많기 때문에 view diversity가 부족합니다. 그래서 training camera path에서 조금만 벗어나도 렌더링 퀄리티가 많이 떨어질 수 있다고 지적합니다.
저자들은 위와 같은 환경들은 학습용으로는 어느 정도 적합할 수 있지만 embodied 내비게이션 시스템으로 benchmark하기 위해 필요한 geometric grounding은 부족하다고 지적합니다.
위와 같은 문제를 해결하기 위해서 결과적으로 저자는 vision-only reconstruction이 아닌 multi-sensor 기반의 다양한 view capture, 정확한 metric-scale geometry, 그리고 강건한 view synthesis를 특징으로 하는 robust real-to-sim framework을 제안합니다.
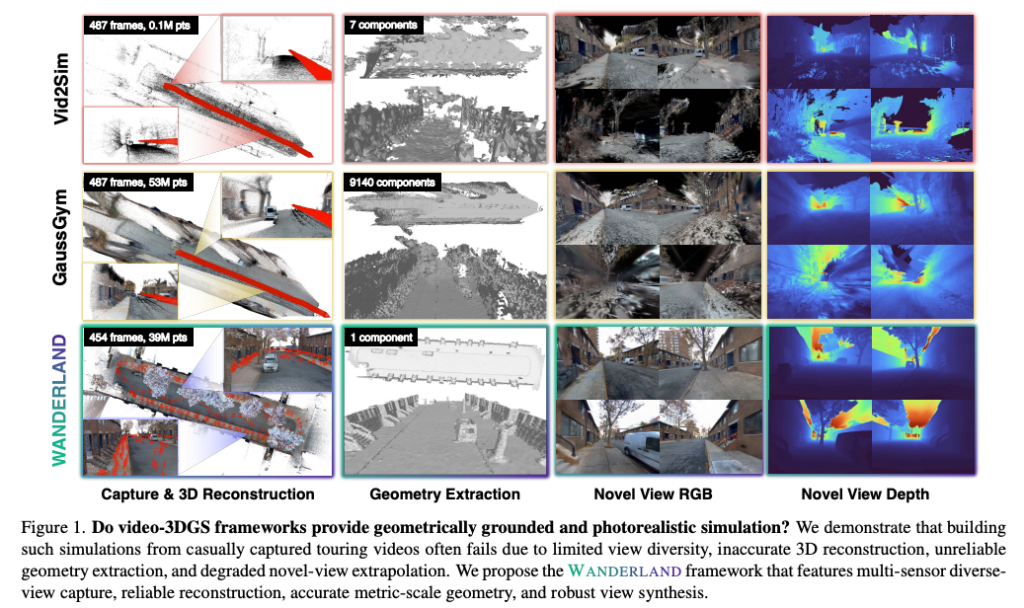
Fig. 1은 Vid2Sim, GaussGym, WANDERLAND를 비교하면서 capture, reconstruction, geometry extraction, novel view RGB, novel view depth가 어떻게 다른지를 보여주는 자료라고 보시면 좋을 것 같습니다. 특히 기존 video-3DGS 방식은 reconstruction과 depth가 깨지는 반면 WANDERLAND는 LiDAR 기반 geometry 덕분에 안정적인 결과를 보여준다라고 주장합니다.
정리하면 기존 video-to-3DGS 방식은 보기 좋은 simulation은 만들 수 있지만 embodied 내비게이션 벤치마크에 필요한 정확한 geometry, collision, metric scale, extrapolated rendering을 보장하기 어렵고 추가적인 센서들을 활용해서 보완해야한다가 논문의 핵심이라고 보시면 좋을 것 같습니다.
뭔가 단순히 센서를 여러 개 사용해서 성능을 올리는 것이 어떻게 컨트리뷰션이 될 수 있지라는 생각이 들었습니다. 근데 embodied 내비게이션 벤치마크를 설계한다는 관점에서 보면 단순히 reconstruction 성능을 높이는 것뿐만이 아니라 agent가 실제로 환경 안에서 움직이고, 벽에 부딪히고, goal까지 도달하는지를 평가해야 합니다. 그렇기 때문에 보기 좋은 RGB rendering도 중요하지만 또 중요한 것이 이 환경이 실제로 로봇이 움직일 수 있는 공간을 얼마나 정확하게 반영하고 있는가라고 봤을 때 저자들이 말하고 싶은 것은 LiDAR를 쓰면 당연히 reconstruction이 좋아진다 정도가 아니라 closed-loop navigation 평가를 신뢰할 수 있게 만들려면 photorealistic rendering과 metric geometry가 동시에 필요하다는 점을 어필하고 싶었던 것 같습니다.
그래서 기존 video-3DGS 방식은 단순히 빠르게 촬영해서 스케일 업 하기는 쉽지만 benchmark로 쓰기에는 geometry가 불안정하고,반대로 WANDERLAND는 추가 센서를 활용해 capture 코스트는 올라가지만 평가 환경의 신뢰성을 확보하려고 한 연구라고 보시면 좋을 것 같습니다.
그래서 이 논문의 컨트리뷰션은 단순히 센서를 더 붙인 것이 아니라 open-world embodied 내비세이션에서 공통 벤치마크로 사용 가능한 geometric grounded simulation을 만들기 위한 조건이 무엇인지 보여줬다는 점에 있는 것 같습니다.
Method
WANDERLAND의 method는 복잡하지 않은데 핵심은 RGB-only video reconstruction에 의존하지 않고, LiDAR + IMU + RGB + GNSS를 함께 사용하는 multi-sensor capture를 통해 metric-scale geometry를 먼저 확보한 뒤에 그 위에 3DGS rendering과 collision mesh를 올린다라고 보시면 좋을 것 같습니다.
전체 흐름을 간단하게 설명드리면 일단 MetaCam이라는 장비로 실제 도시 환경 스캔 —> LIV-SLAM(LiDAR-inertial-visual)으로 metric point cloud와 camera pose 추정 —> LiDAR point cloud 기반 3DGS 학습 —> point cloud에서 collision mesh 추출 —>3DGS와 mesh를 USD scene으로 통합 —> Isaac Sim / Unity에서 navigation task 생성

Fig. 4는 WANDERLAND의 전체 데이터 전처리 파이프라인이라고 보시면 좋을 것 같습니다. MetaCam으로 point cloud, fisheye image, IMU 로그를 수집하고, LIV-SLAM으로 global point cloud와 camera pose를 얻은 후에 3DGS와 collision mesh를 각각 만들고 최종적으로 simulation environment로 통합하는 흐름으로 보시면 좋을 것 같습니다. 아래 이어서 자세하게 각각에 대해서 설명드리도록 하겠습니다.
Data Collection

먼저 데이터 수집 장비부터 보면, 저자들은 MetaCam Air라는 handheld 3D scanner를 사용합니다. 이 장비에는 Livox Mid-360 LiDAR, IMU, RTK-GNSS antenna, 그리고 두 개의 fisheye camera가 들어 있습니다.
그리고 여기서 일반적인 비디오 영상처럼 data collection trajectory를 그냥 자연스럽게 걸어다니며 찍는 방식으로만 두지 않고 저자들은 training view와 extrapolation view를 구분해서 수집합니다.
Training trajectory는 scene 전체를 dense하게 커버하도록 closed-loop 형태로 찍고 extrapolation trajectory는 실제 내비게이션 상황처럼 training path에서 벗어난 view를 평가하기 위한 용도로 사용한다고 보시면 좋을 것 같습니다.

위는 Training views와 extrapolation views가 어떻게 나뉘는지 보여주는 시각화 결과입니다.
LIV-SLAM 기반 Reconstruction
WANDERLAND는 수집된 LiDAR, IMU, RGB, GNSS 데이터를 기반으로 LiDAR-Inertial-Visual SLAM을 수행합니다. 논문에서는 MetaCam Studio라는 software를 사용해서했다고 합니다.(MetaCam Studio는 LiDAR-inertial-visual-GNSS sensor fusion pipeline을 따로 전용 소프트웨어로 가지고 있다고 합니다.)
따라서 SLAM 결과로 Fig. 4에서 보이는 것처럼 dense metric-scale point cloud와 Global camera trajectory 정보를 얻을 수 있게 됩니다.
Image Masking, Dynamic Object 처리
WANDERLAND에서는 image masking을 진행합니다. privacy를 위한 masking을 진행하는데 Egoblur를 사용해서 사람 얼굴이나 차량 번호판을 가립니다. 그리고 여기가 중요한데 또 dynamic object masking도 진행합니다. 사람, 차량 같은 움직이는 dynamic object를 detector로 찾아서 3DGS training에서 invalid pixel로 처리해서 실제 Loss계산이 되지 않도록 합니다.
여기서 WANDERLAND는 실제 도시 환경을 다루지만 현재 버전에서는 dynamic object랑 함께 interactive하게 시뮬레이션하는 것이 아니라 기본적으로 static environment reconstruction만 한다고 보시면 좋을 것 같습니다. 저자들은 오히려 dynamic object는 3DGS 학습에서 방해 요소이기 때문에 제거하거나 mask하는 쪽에 가깝습니다. 이 부분은 해당저자들도 인정하는 한계이긴 합니다. AD 평가처럼 사람이나 차가 움직이는 behavior까지 모델링하는 CARLA식 traffic simulation은 아니다라고 보시면 좋을 것 같습니다.
Training 3D Gaussians
다음으로 3DGS 학습 부분입니다. WANDERLAND는 3D Gaussians를 그냥 랜덤 initialization하는 것이 아니라 MetaCam Studio에서 나온 dense colorized global point cloud로 초기화합니다. 3DGS가 image supervision만으로 학습되면 geometry가 쉽게 불안정해질 수 있기 때문이라고 합니다. 특히 large scale outdoor scene에서는 floaters가 생기거나, depth가 부정확하거나 unseen view에서 geometry가 무너질 수 있는데 WANDERLAND는 LiDAR point cloud를 초기 geometry prior로 사용함으로써 이런 문제를 줄일 수 있다고 합니다.
그리고 여기서 정확한 초기화가 주어졌기 때문에 즉 LiDAR point cloud에서 얻은 Gaussian 중심 위치가 정확하니 Gaussian 중심을 고정해두고 색상이나 opacity만 학습하면 될 것처럼 보이는데 저자들은 이런 rigid한 설정이 오히려 지나치게 균일한 geometric prior를 강제한다고 설명합니다. 결과적으로 모델이 이미지로부터 고주파 디테일을 포착하는 능력이 제한되고 최종 시각 퀄리티가 저하될 수 있다고 합니다. 그래서 WANDERLAND는 Gaussian center를 완전히 고정하지 않고 depth loss로 geometry를 regularize하면서도 image fitting이 가능하도록 뒀다고 합니다.
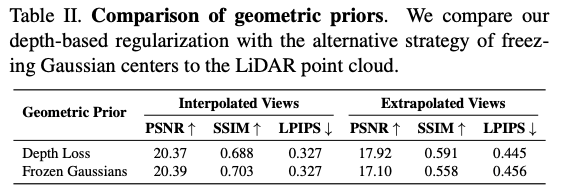
위는 Depth loss 방식과 Frozen Gaussians 방식을 비교한 표인데, frozen 방식이 interpolated view에서는 비슷하거나 약간 좋을 수 있어도 extrapolated view에서는 depth loss 방식이 더 좋은 결과를 보입니다. 결국 LiDAR geometry를 그대로 고정하는 것보다 regularization으로 활용하는 것이 더 낫다라는 것을 보여주는 결과입니다.
Training View Augmentation
WANDERLAND는 extrapolated view synthesis를 개선하기 위해 Difix3D+ 기반 training view augmentation도 사용합니다. 간단히 설명드리면 현재 3DGS 모델이 특정 extrapolated camera pose에서 이미지를 먼저 렌더링하고 이 이미지와 주변의 실제 training view들을 reference로 Difix3D+에 넣어 더 깨끗하고 geometry가 맞는 novel view로 보정합니다. 그리고 이렇게 생성된 view를 다시 training supervision으로 사용한다고 합니다. 근데 이 이미지는 실제 관측 이미지가 아니라 생성된 이미지이기 때문에 원본 이미지보다 낮은 loss weight로 학습에 사용한다고 보시면 좋을 것 같습니다. training trajectory 주변 또는 바깥쪽의 새로운 camera pose를 샘플링해서 synthetic supervision을 만듦으로써 3DGS가 training camera path에서 조금 벗어난 view에도 더 잘 일반화되도록 만든다고 보시면 좋을 것 같습니다.
그리고 여기서 중요한 점은 처음부터 멀리 떨어진 viewpoint를 막 추가하는 것이 아니라 training 초반에는 training trajectory 주변의 가까운 novel view부터 시작하고 학습이 진행될수록 더 먼 extrapolated viewpoint를 추가하는 curriculum 방식을 사용했다고 합니다.
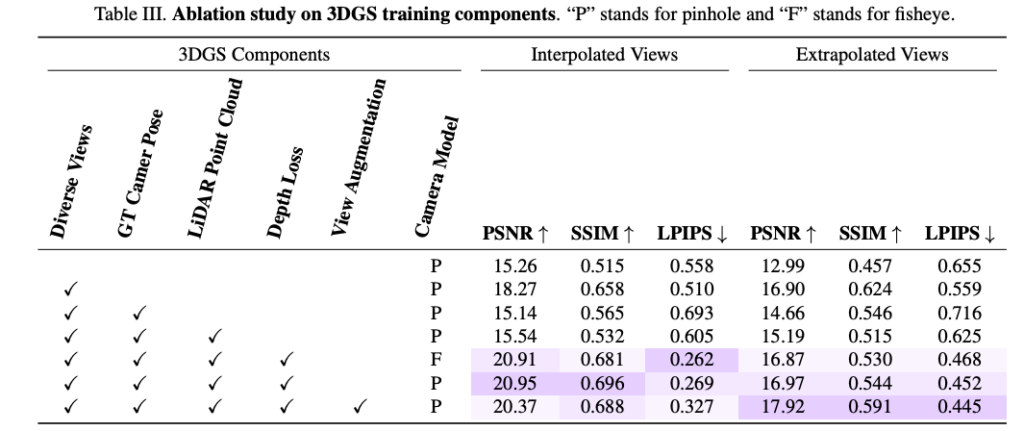
위는 Diverse views, GT camera pose, LiDAR point cloud, depth loss, view augmentation, camera model 각각이 NVS 품질에 어떤 영향을 주는지를 어블레이션으로 보여주는데 특히 view augmentation은 interpolated view보다는 extrapolated view에서 성능 향상이 두드러지는 결과를 보입니다.
Collision Mesh와 Scene Integration
WANDERLAND의 또 다른 핵심은 렌더링용 3DGS와 collision용 mesh를 분리해서 사용한다는 점입니다. 3DGS는 photorealistic한 렌더링을 담당합니다. 근데 서두에 잠깐 언급한것 처럼 3DGS 자체는 agent가 물리적으로 부딪힐 수 있는 명시적인 surface mesh로 보기 힘들기 때문에 WANDERLAND는 LiDAR point cloud를 voxelize한 뒤, marching cubes를 사용해서 collision mesh를 추출한다고 합니다. 이 mesh는 visual rendering을 위한 mesh가 아니라, navigation과 collision 판단을 위한 geometry layer이기 때문에 아주 세밀하게 예쁘게 추출할 필요는 없고 agent가 걸을 수 있는 공간과 obstacle을 안정적으로 표현가능하도록 추출한다고 합니다. 최종적으로 WANDERLAND는 3DGS model과 collision mesh를 같은 coordinate system에 두고 USD scene으로 통합합니다. 그리고 이 scene을 Isaac Sim에 넣어서 embodied navigation policy를 학습하고 평가할 수 있게 합니다.

위는 Vid2Sim, GaussGym, WANDERLAND의 mesh extraction 결과를 비교하는 그림입니다. 기존 video-3DGS 기반 mesh는 fragmented하거나 불완전한 반면에 WANDERLAND는 LiDAR point cloud 기반이라 좀더 완전한 mesh를 보여줍니다.

위는 실제 WANDERLAND에서 point cloud로부터 추출한 mesh 예시들입니다. (위는 visual mesh가 아니라 collision, navigation용 mesh라고 보시면 좋을 것 같습니다.)
Defining Navigation Tasks
드디어 마지막인데 WANDERLAND는 단순히 scene dataset만 제공하는 것이 아니라 embodied navigation task를 정의할 수 있도록 expert trajectory도 생성합니다. 먼저 mesh를 Unity에서 불러온 뒤, Unity의 NavMesh baking API를 사용하여 삼각형으로 구성된 navigable surface라고 부르는 agent가 이동 가능한 표면을 추출한다고 합니다. 그 다음 pathfinding이라는 모듈을 사용해서 이 NavMesh를 기반으로 collision이 발생하지 않는 expert trajectory를 생성한다고 합니다. 시작 위치와 목표 위치는 capture camera 주변 영역에서 샘플링이 되. 이렇게 생성된 trajectory들은 point-goal navigation과 image-goal navigation task에서 활용 가능하다고 합니다.
그리고 VLN 태스을 위해서는 각 trajectory에 대해 추가로 navigation instruction을 생성한다고 합니다. 이를 위해 저자들은 먼저 시뮬래이션 안에서 각 trajectory를 리플레이해서 agent 시점의 egocentric video를 생성합니다. 그 다음 Gemini 2.5을 사용해서 이 video를 기반으로 자연어 navigation instruction을 생성합니다. 그리고 나서 생성된 instruction은 신뢰성 검증을 위해 사람이 추가로 검수했다고 합니다.
Experiments
실험은 크게 세 가지 질문을 중심으로 구성합니다.

Q1: 가장 좋은 vision-only 3D reconstruction 방법은 LIV-SLAM만큼 좋은가?
Q2: geometric grounding은 더 나은 photorealistic simulation 품질로 이어지는가?
Q3: video-3DGS framework는 학습과 평가를 위한 신뢰할 수 있는 환경을 제공하는가?
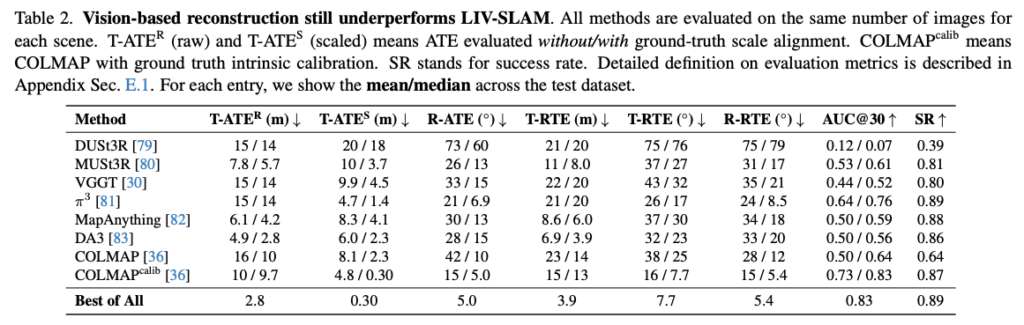
먼저 Q1에 대한 실험입니다. 3D reconstruction 실험에서는 DUSt3R, MUSt3R, VGGT, π3, MapAnything, DA3, COLMAP 같은 최신 vision-only reconstruction 방법들을 비교합니다. 여러 방법 중 가장 좋은 성능만을 단순히 골라서 보더라도 camera pose estimation결과 2.8m정도의 에러를 보입니다. 평균은 거의 10m정도 되는 거 같습니다. 저자들은 최신 foundation geometry model도 아직 open-world navigation benchmark를 만들 만큼 정확하지 않다고 위 결과를 기반으로 주장합니다. VGGT, DUSt3R 같은 모델은 최근 좋은 성능의 3D reconstruction 방법으로 주목받고 있지만 WANDERLAND 기준에서는 여전히 meter-level translation error와 큰 rotation error가 남는 모습을 보여주고 또 COLMAP도 GT intrinsic calibration을 넣어주면 많이 좋아지지만 그래도 모든 scene에서 안정적이라고 보기는 어렵습니다.
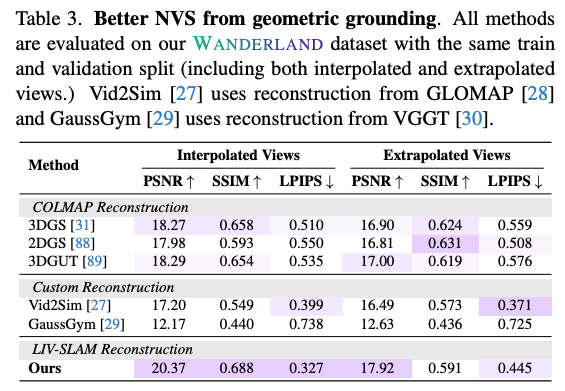
위는 NVS 실험입니다. 저자들은 WANDERLAND dataset의 train/validation split을 사용해서 interpolated view와 extrapolated view를 모두 평가합니다. 결과적으로 WANDERLAND가 단순히 LiDAR를 사용해서 collision mesh만 좋아진 것이 아니라 rendering quality 자체도 좋아지는 결과를 보여줍니다.
GaussGym의 경우 VGGT 기반 reconstruction을 사용하기 때문에 pose와 geometry가 불안정하고,그 결과 NVS metric이 낮게 나왔다라고 주장하고 Vid2Sim은 monocular depth supervision을 사용하는데 이 pseudo-depth 자체가 부정확할 수 있기 때문에 성능이 낮게 나왔다고 저자들은 설명합니다.
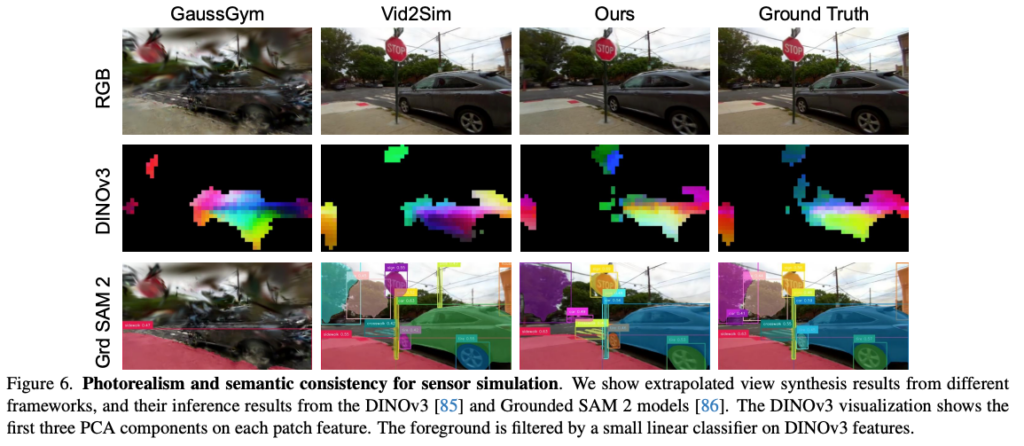
위는 GaussGym, Vid2Sim, WANDERLAND, Ground Truth의 rendered RGB와 DINOv3 feature PCA, Grounded SAM 2 segmentation 결과를 비교하는 그림입니다. 위 그림에서 저자들이 말하고 싶은 것은 렌더링된 이미지가 사람이 보기에는 어느 정도 그럴듯해 보여도 퍼셉션 모델이 보는 피쳐 공간에서는 크게 다를 수 있다는 점입니다. 예를 들어 Vid2Sim은 피쳐 형태는 GT와 비슷해 보일 수 있지만 즉 detection과 segmentation을 어느 정도 지원할 수 있는 일관된 이미지를 만들지만 DINOv3 feature PCA 컬러가 ground truth와 다르게 나옵니다. 위는 DINO feature를 semantic understanding에 활용하는 end-to-end navigation policy학습에 방해가 될 수 있다고 합니다. 반면에 저자들의 방법론은 structural integrity와 semantic consistency를 모두 유지할 수 있었다고 합니다.
Embodied Navigation
마지막은 실제 embodied navigation policy 평가입니다. 논문에서는 NoMaD, CityWalker, MBRA, NaVid, NaVILA 를 벤치마킹 합니다.
평가 메트릭은 NE, SR, SPL, IR입니다. NE는 Navigation Error, 즉 최종 위치와 goal 사이의 거리이고 SR은 Success Rate입니다. 그리고 SPL은 path length까지 고려한 success metric입니다. IR은 Intervention Rate로, agent가 스턱 되거나 scene 밖으로 나가거나 해서 타임아웃이 아닌 이유로 에피소드가 조기 종료되는 비율이라고 합니다. 일반적인 navigation benchmark에서는 SR/ SPL만 보는 경우가 많은데,WANDERLAND에서는 simulation geometry가 불안정하면 agent가 이상한 곳에 끼거나 scene 밖으로 나가는 failure가 생기기 때문에 이를 따로 측정한 것으로 보입니다.
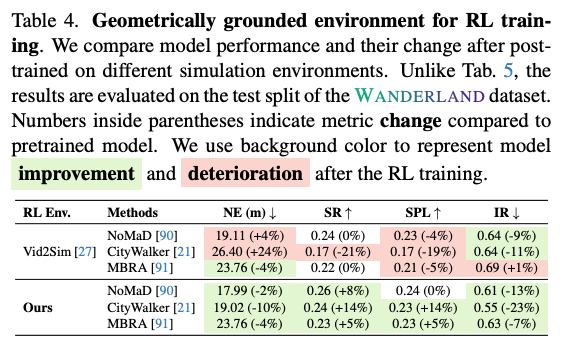
먼저 RL post-training 실험을 보면 같은 pretrained policy를 Vid2Sim 기반 environment와 WANDERLAND environment에서 각각 fine-tuning합니다. Vid2Sim 환경에서 RL fine-tuning을 하면 NoMaD, CityWalker, MBRA의 성능이 오히려 악화되는 경우가 있고, WANDERLAND 환경에서는 전반적으로 개선되는 결과가 나옵니다. RL은 environment reward를 따라 policy를 업데이트하는데 environment geometry가 부정확하면 policy는 실제 navigation 능력을 배우는 것이 아니라 시뮬레이션의 artifact에 적응할 수 있습니다. 예를 들어 collision mesh가 이상하거나 visual 렌더링과 actual traversability가 맞지 않으면 agent는 locally reward가 좋아 보이는 행동을 학습하지만 실제 test에서는 더 나빠질 수 있습니다. 결국 시뮬레이터에서 policy를 학습했을 때 정말 도움이 되는지가 중요한데 여기서 저자들은 해당 부분과 geometric grounding의 필요성을 실험적으로 보여준 결과라고 보시면 좋을 것 같습니다.
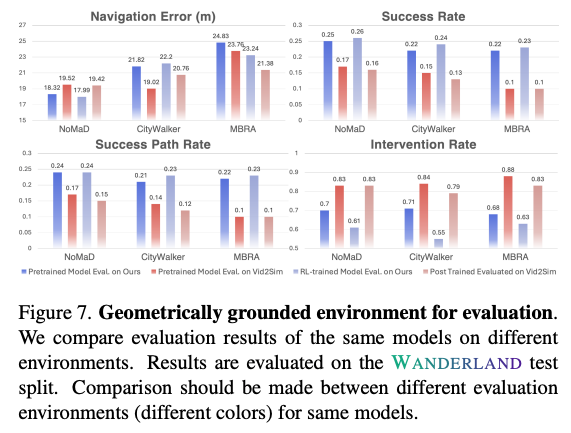
위는 같은 pretrained model을 서로 다른 simulation environment에서 평가했을 때 NE, SR, SPL, IR이 어떻게 달라지는지를 보여주는 결과 입니다. 여기서 WANDERLAND 환경과 Vid2Sim 환경에서 같은 model의 성능이 크게 달라집니다. Vid2Sim 환경에서는 success rate가 낮고 intervention rate가 높게 나오는 경향을 보입니다. 평가 환경의 geometry가 부정확하면 model이 실제로 못해서 실패한 것인지 simulator 자체가 이상해서 실패한 것인지 구분하기 어려워집니다. 따라서 저자들은 좋은 benchmark는 모델 간 차이를 공정하게 드러내야 하기 때문에 navigation policy를 closed-loop로 평가하려면 visual 만으로는 부족하고 agent가 실제로 움직이는 geometry와 collision layer가 정확해야 한다라는 것을 주장합니다.
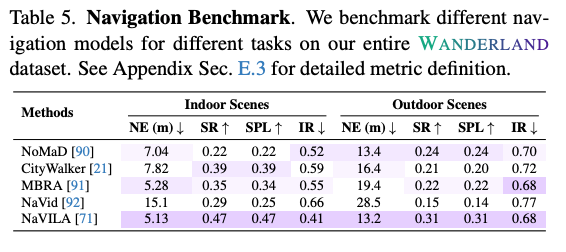
마지막으로 WANDERLAND 전체 dataset에서 여러 pretrained navigation model을 비교해서 indoor/outdoor scene에서 평가한 결과인데, 결과를 보면 아직 어떤 모델도 SR이 50%를 넘지 못하는 결과를 확인할 수 있습니다. 여기서 저자들은 현재 navigation policy들이 open-world embodied navigation에서 아직 부족하다는 점을 보여주는 결과라고 합니다.
이상 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요 우현님 좋은 글 감사합니다.
몇가지 질문이 있는데, 사람이나 차량같은 dynamic object를 마스킹하는거면 open-world navigation을 표방하더라도 실제 도시환경에서는 중요한 obstacle이 지워지게 될텐데 한계점으로 인식하면 되는건가요?
그리고 WANDERLAND에서 학습한 policy가 실제 로봇 환경으로 transfer되는 실험도 있는지 궁금합니다.
감사합니다.
안녕하세요 인택님 좋은 댓글 감사합니다.
위에서 언급했듯이 실제 도시환경에서는 중요한 obstacle이 지워지게 되는 점은 저자가 언급하는 중요한 한계라고 보시면 좋을 것 같습니다. 그리고 WANDERLAND에서 학습한 policy를 평가한 실험은 있는데 이걸 실제 로봇 환경으로 transfer하는 실험은 없는 것 같습니다. 감사합니다.
안녕하세요 우현님 좋은 리뷰 감사합니다.
이전 방법들은 Depth estimation을 통해서 수도 Depth 를 만들고 그것을 활용해 real meticsclae로 맞추려고 했지만 realmetiric과는 좀 차이가 있고 이를 문제삼아 저자들은 IMU 나 lidar를 통해서 real Metric으로 맞춘거 맞나요 ? 그러면 맵을 만드는것이 단순 lidar나 고가의 장비를 통해서 rendering해보니 퀄리티도 좋아지고 realmetric으로 맞출수있었다 라고 주장하는거같은데…혹시 뭐 map 생성하는 것에 있어서 저자의 의도나 하고자하는 핵심이 어떤건가요 ?
안녕하세요 우진님 좋은 댓글 감사합니다.
단순히 센서를 더 붙인 것이 아니라 open-world embodied 내비세이션에서 공통 벤치마크로 사용 가능한 geometric grounded simulation을 만들기 위한 조건이 무엇인지 보여줬다는 점이 저자의 의도라고 보시면 좋을 것 같습니다. 질문 주신 내용에 대해서 introduction에 자세하게 설명해드렸으니 참고하시면 좋을 것 같습니다. 감사합니다.