안녕하세요. 이번 논문 리뷰는 RSS 2026′ MINT (Mimic Intent, Not Just Trajectories) 인데요, action chunk를 주파수 도메인에서 분해해서 intent(전역적인 행동 의도)와 execution(세부 실행 디테일)을 명시적으로 disentangle해서 inductive bias를 더 줘서 latent embedding 해보니 좋더라라는 VLA 모방학습 프레임워크입니다. 제목이 되게 fancy한데,, trajectory만 모방학습하지 말고, intent 좀 모방학습해라. 사실 저희 로보틱스 팀이 그동안 생각해오던 게 VA/VLA가 그냥 action을 외워버리나? vision정보를 너무 덜 이해하는 느낌이 드는 게 있었어서 굉장히 공감이 가는 컨셉인데요. VLA가 raw action을 그냥 mimic만 하니까 환경 변화나 새로운 task에 generalize가 잘 안되는 것 같다는 것을 해당 저자들도 좀 주목을 했던 것 같구요. 이걸 풀기 위해 DCT 기반 spectral decomposition으로 token space를 hierarchical하게 구성한 게 좀 흥미로웠습니다(frequency domain으로 분해하면 고주파가 detail, 저주파가 semantic 일 테니까 그거 좀 어떤 uncertainty score로써 어떻게 못 써먹나하는 생각이 평소에 있었거든요.. ).
그래서 뭔가 제 연구 관점에서도 연결될 만한 부분이 있다고 느꼈습니다. 만약 Latent space에서 intent와 execution을 disentangle 할 수 있다면, “어떤 level에서 실패할 것 같은지”에 대한 예측을 intent-level인지 execution-level인지로 분해해서 볼 수 있을 것 같고, 이게 저번에 리뷰한 FIPER가 vision 과 action 관점의 failure prediction score를 따로 뽑았었던 것처럼 뭉쳐있던 뭔가를 쪼개서 의미부여해볼까 하는 것이 비슷하게 결이 닿아있는 인사이트인 것 같아서 읽어봤습니다. (물론 FIPER는 post-hoc 기법이고 MINT는 latent embedding 시 inductive bias를 줘버리는 learning 기법이라 디테일은 다릅니다!)
논문 정보
- 저자: Renming Huang, Chendong Zeng, Wenjing Tang, Jintian Cai, Cewu Lu, Panpan Cai† (Shanghai Jiao Tong University, Shanghai Innovation Institute)
- arXiv: https://arxiv.org/abs/2602.08602
- Project Page: https://renming-huang.github.io/MINT
- Venue: RSS 2026
Introduction
모방학습은 demonstration으로부터 manipulation policy를 학습하는 paradigm으로써 이제는 아예 메인스트림으로 자리잡았는데요. 최근 VLA 모델들은 vision/language input -> continuous action chunk control로 mapping해서 빨래개기, 커피만들기 같이 어렵고 dexterous한 task를 처리하는 수준까지 왔습니다. 그런데 이 VLA 모델들이 closed setting에서는 잘 동작하지만, 환경이 살짝만 바뀌어도 generalize가 처참한 수준으로 떨어진다는 게 잘 알려져 있죠 (LIBERO-Plus 같은 robustness benchmark나 RL 기법들과 policy steering 컨셉이 요즘 들어 많이 등장하는 이유).
여기서 저자들은 앞서 리뷰 서두에서도 말씀드렸듯이, 저희 로보틱스팀이 언젠가 문뜩 의문을 가진 부분에 디테일하게 파고들었습니다. VLA 모델들이 trajectory를 raw signal로 그대로 mimic할 뿐, 왜 그 action sequence가 실행되는지, 행동의 근본적인 intent 자체는 잘 모델링하지 않는 것 같다는 것에 집중을 한거죠. 그러다보니 demonstration에 깔린 surface-level correlation에는 너무 overfit하고, 정작 task 실행에 전반적인 맥락을 담는 그 의도 자체는 캡처를 못 하니까 환경이 바뀌었을 때나 OOD일 때 generalize가 잘 안 된다는 것인데요.
이를 해결하기 위해 사실 그 동안 latent action tokenization 쪽 연구들이 나름대로 접근을 많이 해온 것이라고 보면 될 것 같습니다(UniVLA, LAPA, VQ-VLA 등 VQ-VAE latent token 기반). 연속적인 action trajectory의 어떤 잠재의미를 이산적인 latent token으로 표현해서 써먹자는 건데, 그 동안은 행동 의미론 자체가 구조화될 수 있고, compositional하다 (잠재적인 sub-skill의 조합으로 특정 task를 표현가능하다는 의미)는 직관적인 의미가 잘 받아들여져서 수용되어 왔었는데, 이 컨셉을 기반으로 한 이산적인 latent tokenization 방법들이 결국 의미론적 추상화가 아닌 단순 효율적인 압축(FAST를 예시로 듦.)에 가깝고, 의도와 같은 해석 가능한 개념과 토큰 embedding space를 align 맞추는 명시적인 constraints를 제공하지 못하는 것 같다는 의문을 저자들이 품게 됩니다. 즉 기존의 학습 objective 자체가 action meaning 자체에 집중하기는 어렵게 embedding 해버리니까, 토큰 공간이 해석가능한 행동 의도랑은 align될 보장이 없는 셈입니다. 이를 또 해결하기 위해 [ICCV 25′]CARP(Visuomotor Policy Learning via Coarse-to-Fine AutoRegressive Prediction)라는 Multi-scale/hierarchical tokenization 방법론을 써도 coarse -> fine 에서의 coarse representation의 semantic이 unconstrained라서 결국 마찬가지라고 봤습니다.
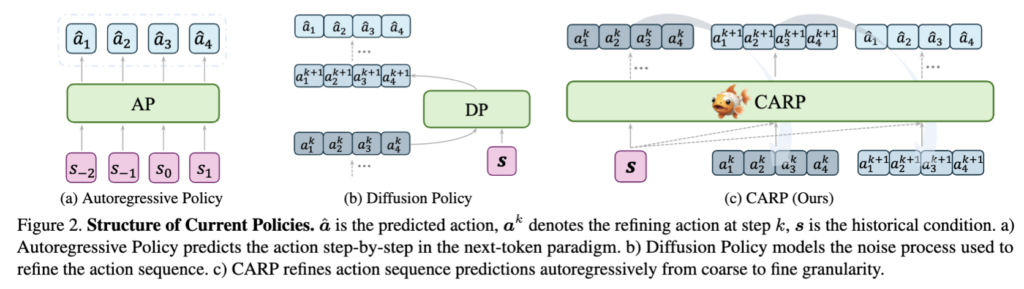
요기서 (c)가 CARP구조입니다. 기존 AR policy나 DP 구조랑 다르게, AP의 autoregressive 자체의 컨셉과 DP의 coarse-to-fine 컨셉을 합쳐서 만든 기법이라고 보시면 될 것 같습니다.
그래서 저자들이 제안하는 연구 철학은 다음과 같습니다:
- Intent와 execution을 embedding 단에서 명시적으로 disentangle해야 한다. 이걸 휴리스틱이나 post-hoc 해석에 맡기면 안 되고, 학습 단계에서 강제해야 한다.
- Trajectory를 time domain이 아니라 frequency domain에서 보자. trajectory는 여러 주파수의 superposition라고도 볼 수 있는데, 저주파 성분이 global structure(intent), 고주파 성분이 reactive detail(execution)이라는 직관이 잘 맞아떨어진다.
- [ICCV 25′]CARP 방법론처럼, Multi-scale coarse-to-fine token(([NIPS 24′ Oral] VAR(Visual AutoRegressive)모델) )구조로 가되, 각 스케일에 명시적인 reconstruction constraint를 걸어서 강제로 disentangle을 유도한다. 가장 coarse한 scale은 single token으로 쫙 압축해서 dominant한 어떤 semantic 저주파 성분을 캡처하게 만들고, 그 다음 finer scale은 residual을 처리하게한다. (이 때 앞서 2번에서 말했듯이 time 도메인이 아니라 주파수 도메인으로 multi-scale coarse-to-fine AR 컨셉을 접목하게 된 게 핵심 차이점입니다.)
- 이렇게 얻은 Intent token을 task specification 요소로써 직접 쓸 수 있게 한다. Language보다 훨씬 grounded해서 one-shot transfer가 가능할 수 있더라.
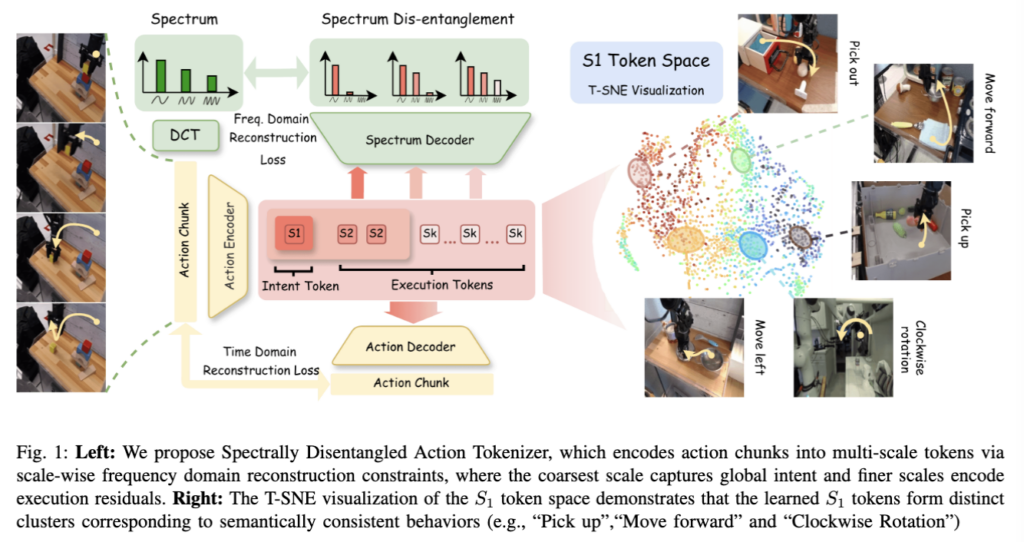
제안한 프레임워크는 그래서, multi-scale frequency-space action tokenization을 사용하는 MINT 프레임워크입니다. 핵심은 행동 궤적을 주파수 성분의 조합으로 보고, 저주파는 전역 구조 즉 의도를, 고주파는 세부 실행을 나타낸다는 점입니다. 이를 위해 DCT와 multi-scale VQ-VAE (앞선 VAR 모델 방식) 기반으로 주파수 도메인에서 궤적을 재구성하도록 학습하며, 잠재 표현은 coarse-to-fine 구조로 구성되어 가장 거친 스케일은 전역 정보를, 더 세밀한 스케일은 잔여 세부 정보를 담도록 의도했습니다.
그리고 점진적 재구성 학습을 통해 각 스케일이 서로 다른 주파수 영역을 담당하도록 강제하며, 이 구조는 의도와 실행을 명시적으로 분리하는 표현을 학습하도록 유도합니다. 따라서 가장 coarse 토큰은 Intent Token으로, 나머지는 Execution Tokens로 해석가능하다는 주장을 하게됩니다.
time-variant action chunk -> DCT(discrete cosine transform) -> 기존의 time 도메인이 아닌 좀 더 고수준 의도와 저수준 동작 자체의 분리와 조합이 용이한 주파수 도메인 활용 -> multi-scale coarse-to-fine VAE 구조(CARP가 쓴 VAR구조 활용) -> 그렇게 inductive bias로 인해 잘 담긴 action representation -> multi-scale AR기반 action decoding 시 intent weighted chunk 이라는 구조로 흘러갑니다.
Related Work
Action Tokenization
이쪽 연구는 두 가지 줄기로 나눠 볼 수 있는데요
- 수학적 접근 위주: direct binning (RT-1, ACT), FAST, BEAST 같이 수학적으로 discretized tokenization을 어떻게 할까라는 방식이 주였습니다. 이게 Reconstruction은 보장되지만 intent 캡처 constraint은 중요하게 다루지 않았다는 게 저자들의 주장이구요.
- Learning 기반: VQ-VAE 변종들이라고 보면 될 것 같습니다. 즉 VQ-VAE부터 시작해서 VQ-BeT랑 LAPA부터 시작된 latent action embedding space 컨셉인데 이걸 discretized tokenization 기반으로 학습하니까 compression은 잘 되는데, internal constraint가 없어서 결국 low-level dynamics의 latent만 보존하는 느낌이고 intent는 못 잡는 느낌이 나타나게 된 것 같습니다. 그 동안의 latent action embedding의 정체성을 좀 직접적으로 꼬집는 문장이 많았습니다.
그에 반해서 MINT는 tokenization 자체에 주파수 도메인 기반으로 intent vs execution disentangle constraint를 거는 게 핵심인지라, action tokenization의 의미를 좀 더 explicit하게 드러냈다는 점에서 의미가 큰 것 같다는 생각도 듭니다.
Coarse-to-Fine Tokenization
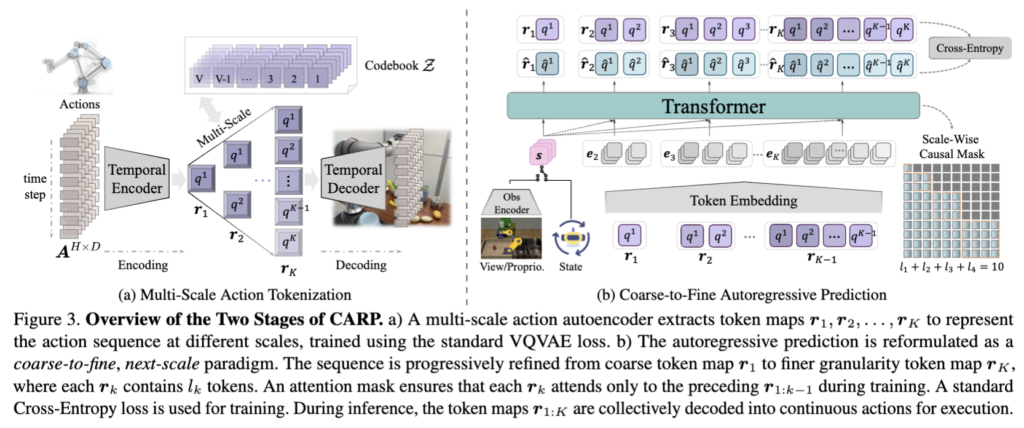
위는 CARP 방법론의 framework overview입니다.
Standard residual VQ (RVQ)는 모든 스케일에 좀 flat하게 coarse-to-fine capacity를 주는데, 저자들은 이게 여전히 disentangle하지 못한 구조라고 봅니다. Intent는 sparse하고 abstract한데, execution detail은 dense하고 high-frequency거든요. 이 내재된 비대칭성에 대해서 어떻게 보면 조금 더 쎈 inductive bias를 저자들이 좀 정의를 하고 잘 활용하자는 게 저자들의 취지입니다. 어찌저찌 CARP가 multi-scale token을 접목했었는데, time-domain reconstruction만 가지고는 explicit한 scale-wise supervision이 없어서 결국 local fidelity에만 치우치게 된다는 고찰을 얻게됐다는 게 저자들의 핵심입니다.
이렇게 정리해놓고 보면, MINT의 contribution이 그냥 더 좋은 tokenizer를 제안한 게 아니라 token space의 semantic 구조를 강제하는 inductive bias이고, 이게 성능이 좋더라까지 실험으로 보인 게 개인적으로는 제가 머릿속으로 상상하던 inductive bias가 실현된 느낌이라 너무 신기했습니다.
Methods
MINT는 two-stage 학습 프레임워크인데요, (1) Spectrally Disentangled Action Tokenizer (SDAT) 를 먼저 학습해서 multi-scale discrete representation을 얻고, (2) 이 토큰 위에서 MINT policy가 next-scale autoregression으로 action chunk를 생성하는 구조입니다.
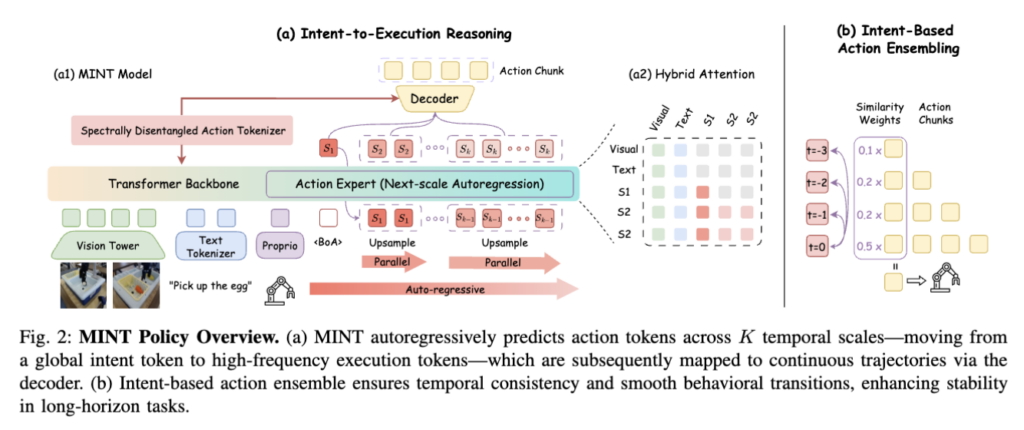
Spectrally Disentangled Action Tokenizer (SDAT)
핵심 아이디어는 action chunk A \in \mathbb{R}^{H \times D}를 받아서 시간 도메인이 아닌 주파수 도메인에서 reconstruction loss를 걸자는 것입니다. 여기서 H는 action sequence horizon, D는 action dimension입니다. 구체적으로 다음과 같이 동작합니다.

먼저 action encoder \mathcal{E}가 A를 continuous latent embedding f \in \mathbb{R}^{L \times C}로 압축합니다. 이 때 L은 compressed temporal length이고, C는 latent feature dimension입니다. 그 다음 Multi-Scale Residual Quantization (RQ-VAE와 VAR 기법 결합)으로 f를 K개 스케일의 discrete token map {s_1, …, s_K} 으로 분해합니다.

이 때 각 s_k는 각 increasing resolution인 l_k 에 따라 정의되는 건데, Z를 V개의 code북이라고 치면, 모든 K개의 스케일 즉 s_k들이 Z라는 codebook을 공유하는 형태입니다.
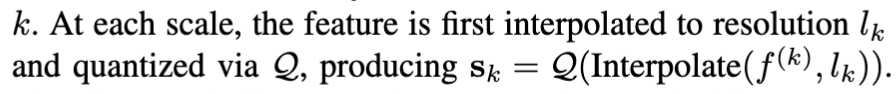
또한 각 scale k 가 변할 수록 latent feature f 는 resolution인 l_k에 맞게 interpolate되고 quantized됩니다. 이걸로 k번째 스케일까지의 누적 residual latent feature를 scale-specific projector 인 ϕ_k 를 사용해서 residual feature 형태로 다음과 같이 f^ 로써 표현하게 됩니다.
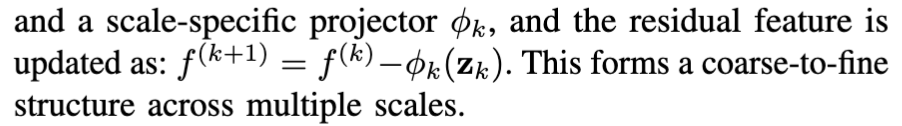
그 다음, 이걸 가지고 spectral decoder \mathcal{D}_{spec}로 디코딩한 뒤 DCT로 주파수 도메인으로 변환하는데요. 각 action 차원 d에 대해
F_{k,d} = \sum_{h=0}^{H-1} \hat{A}_{h,d} \cos\left[\frac{\pi}{H}\left(h + \frac{1}{2}\right)k\right]위와 같이 frequency representation을 얻습니다. 그리고 이 F^{(k)}가 ground-truth F = \text{DCT}(A)와 얼마나 유사한지를 scale-wise spectral recon loss로 강제하게 됩니다.
\mathcal{L}_{freq} = \sum_{k=1}^{K} \lambda_k | F - F^{(k)} |^2람다k는 스케일별 가중치로, 각 스케일의 recon weight을 조절하는 역할을 한다고 하는데,, 코드에서는 각 스케일별 다 더하고 단순 평균했네요. 그럼에도 왜 이렇게 했는지 이유가 킥인 것 같습니다. 첫 번째 스케일(S_1)은 단 하나의 토큰입니다. 한 토큰만으로 전체 action chunk의 주파수 표현을 reconstruction해야 하니까, 자연스럽게 dominant한 저주파 성분(global intent)을 캡처할 수밖에 없게 compression이 들어가는 셈이죠. 이후 finer scale은 capacity를 늘려가면서 residual high-frequency를 처리하게 되고요. 이 점진적인 느낌의 reconstruction이 spectral disentanglement를 유도하는 핵심입니다.
전체 loss는 scale-wise spectral recon loss + codebook/commitment loss + auxiliary L1 recon loss로 구성되고, 다음과 같게 됩니다.
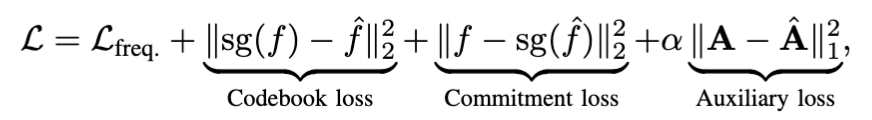
gradient collapse 막으려고 EMA codebook update를 쓰고, stop gradient도 쓰고, gripper의 binary 차원은 DCT/spectral reconstruction에서 빼는 등 디테일한 implementation detail도 꽤 있긴 합니다. (gripper는 step function 같아서 spectral하게 다루기 부적합한 듯 싶습니다..).
MINT Policy
Tokenizer 학습 후엔 그 위에서 policy를 학습합니다. 입력은 visual observation, language instruction, proprioceptive state이고, 출력은 next-scale autoregressive하게 생성되는 multi-scale token map입니다.
p(s_1, …, s_K) = \prod_{k=1}^{K} p(s_k | s_1, …, s_{k-1})각 s_k는 token sequence가 아니라 token map으로써 다루고, 한 스케일 안의 모든 토큰은 parallel하게 생성하면서 스케일 간에는 autoregressive를 유지하는 hybrid attention 구조입니다. 결국에 각 토큰맵이 조건화 역할을 해주면서 토큰 간 coarse-to-fine 결합 분포가 만들어져서 효율적인 인퍼런스가 가능해진다고 합니다.
Intent-Based Action Ensemble
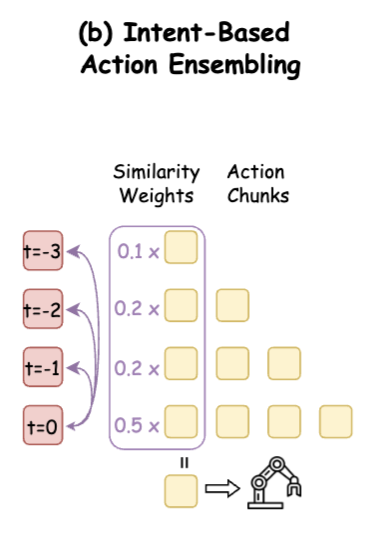
여기가 또 특이한 부분인데요. decoding할 때 action chunking을 쓰면 어쩔 수 없이 시간 t에 여러 chunk의 prediction이 겹치게 되는데, 보통은 temporal-based weighting (ACT의 EMA 같은 것)이나 action-based ensemble을 씁니다. 근데 MINT는 intent token 간의 cosine similarity로 weighting 하는 방식을 사용하는데요.
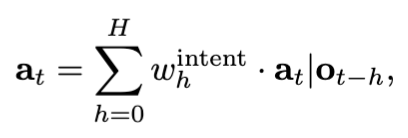
같은 intent 안에서 prediction끼리는 부드럽게 합쳐주고, intent가 전환되는 시점에서는 옛날 chunk의 영향을 빠르게 잘라내는 거라고 합니다. 이게 Behavioral transition에서 conflict가 생기는 걸 막아주는데, intent token이 정말로 의미 있는 representation이어야만 작동할 수 있어서 SDAT의 quality validation 역할도 하는 셈이라고 하네요.
Experiments
모델 구성
저자들은 작은 모델, 큰 모델로 두 모델을 만들었습니다.
- MINT-30M: VLM backbone 없이 처음부터 학습하고, SigLIP+DINOv2(frozen) vision encoder, BERT text encoder, FiLM conditioning 방식으로 가벼운 baseline 형태를 구성했습니다.
- MINT-4B: 기존 VLA들과 유사하게 PaliGemma-2.6B backbone 위에 300M 정도의 action expert를 붙인 형태입니다. Action expert는 from-scratch 학습이지만, π0/π0.5와 달리 DiT flow matching이 아니라 decoder-only Transformer로 가서 scale-wise AR과 호환되게 만든 게 차이점이라고 합니다.
실험한 벤치마크가 꽤 광범위한데, LIBERO 4종 + LIBERO-90, CALVIN ABCD→D, MetaWorld 50 task, LIBERO-Plus, real-world까지 진행했습니다.
Main Performance (Table I)
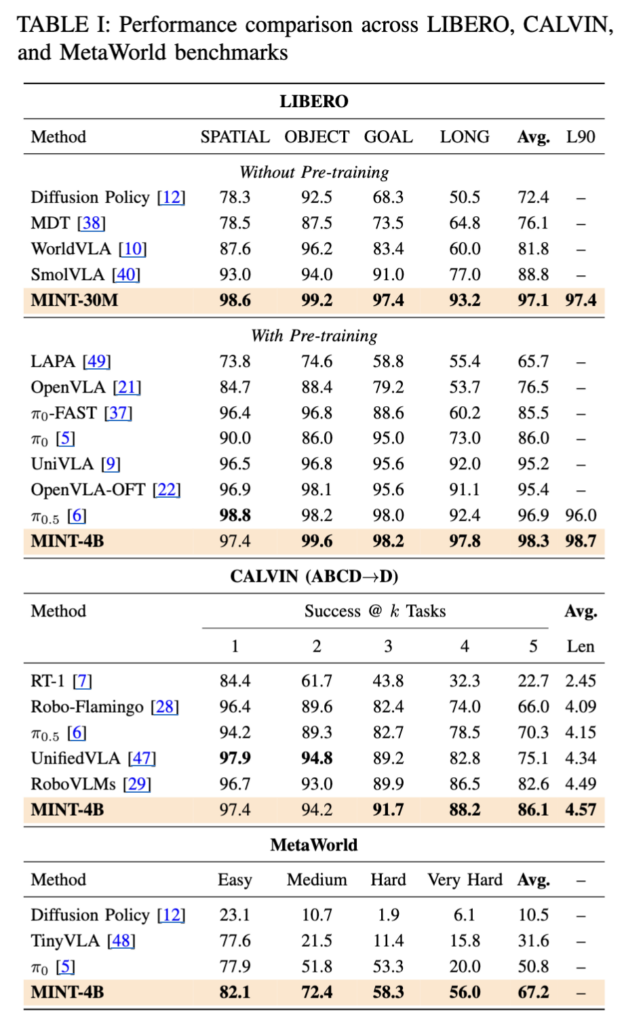
메인 실험입니다. MINT가 기존 DP나 VLA 기반 방법들을 일관되게 상회하며 30M, 4B 모두 인상적인 성능 향상폭을 보입니다. 특히 인상적이었던 건 MINT-30M이 pretrain 없이 from-scratch로 학습했는데, DP,smolVLA 등은 LIBERO에서 가뿐히 이긴다는 점이었습니다. CALVIN 도 보면, long-horizon 작업에 있어 intent와 execution에 대한 tokenizer의 이런 inductive bias가 유의미하게 작용할 수 있다는 것을 경험적으로 보이구요. 이제 슬슬 benchmark saturation이 되고 있는 만큼,, 앞으로 action latent manifold 자체에 대한 inductive bias 쪽 연구들이 ML 쪽에서 스멀스멀 넘어오는 패러다임이 지속될 수도 있을 것 같습니다. 저 같은 경우는 이걸 uncertainty 요소로써 활용해보면 어떨까 싶습니다.
Generalization (LIBERO-Plus, Table II)
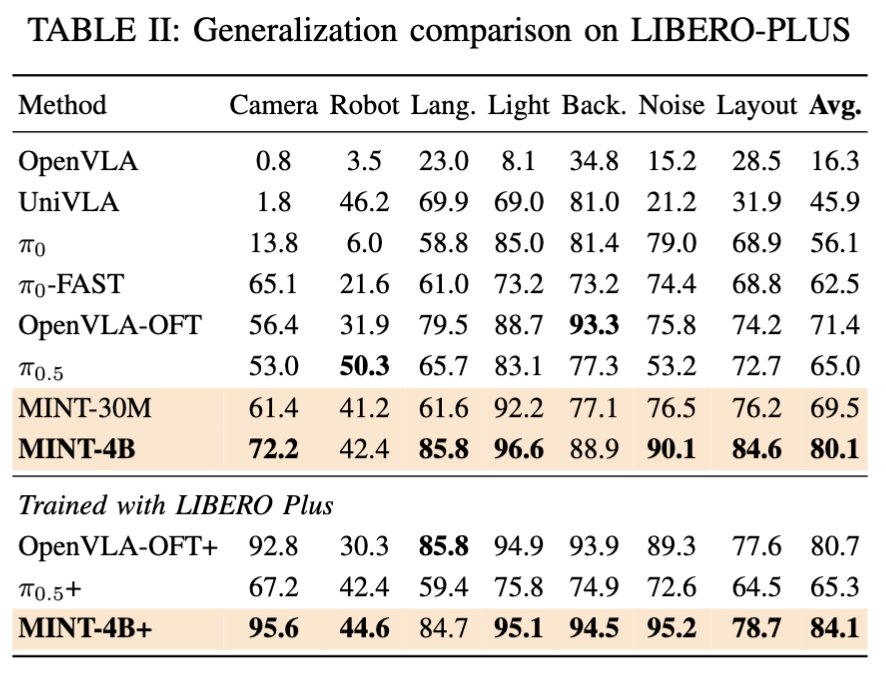
LIBERO-Plus는 7가지 perturbation factor (camera, robot init, language, light, background, noise, layout)에 대한 robustness를 평가하는 벤치마크인데요, MINT-4B가 80.1% avg로 OpenVLA-OFT(71.4%) 랑 π0.5 잘하는 모습을 보였습니다. 특히 camera viewpoint shift에서 강한데, 이건 data-driven pretraining을 넘어 intent token에 대한 inductive bias를 설계했을 때 시각적 변화에 invariant한 행동 의도를 잡는데 주요했다는 것으로도 해석이 되는 것 같습니다.
One-Shot Transfer (Table III)
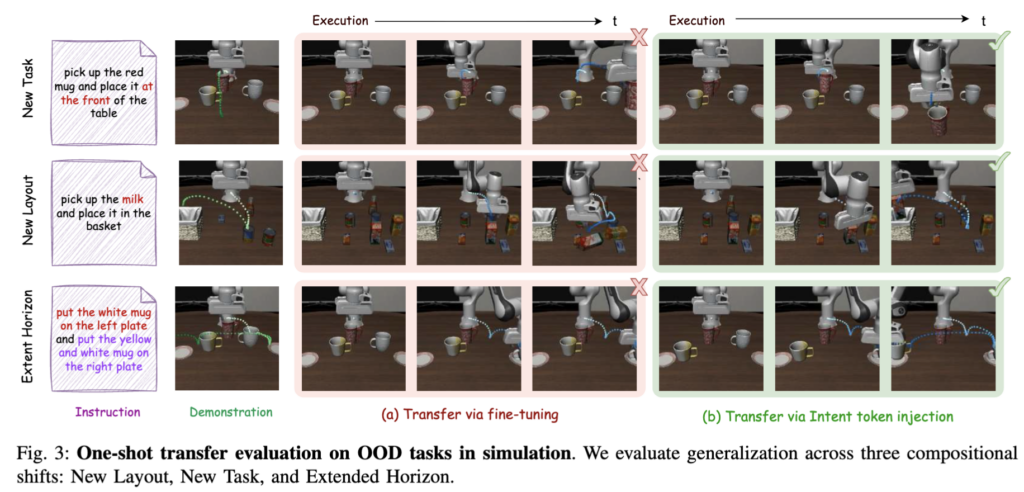
이 파트가 제 연구 관점에서 가장 흥미로웠는데요. New Task / New Layout / Extended Horizon 세 가지 OOD 시나리오에 대한 실험입니다.
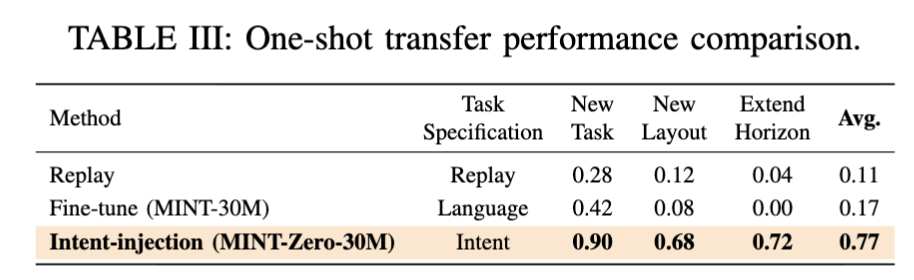
1개의 demo 데이터에서 추출한 S_1 token을 policy generation 과정에 아예 inject해서 고정했는데 transfer 성공률이 4배 가까이 뛰는 괴랄한 성능을 보이는데요. 특히 New Layout에서 fine-tuning은 0.08, intent injection은 0.68로 차이가 극명한데, fine-tuning은 그 1개 demo에 overfit해서 수렴하는 반면 intent token은 task 의미를 보존한 채로 execution detail은 in-distribution으로 자연스럽게 푸는 셈이라는 해석을 저자들이 남겼습니다.
추가로 이 결과가 의미하는 바로 language instruction보다 intent token이 훨씬 grounded하고 execution-aligned한 task spec일 수 있다고 하는데. 사실 우리가 자연어로 task를 설명할 때 잃어버리는 정보(미세한 timing, 접근 angle 같은 것)가 많은데, intent token은 demonstration에서 직접 추출하니까 그런 정보가 latent하게 보존되는 셈이라고 어필한 것 같습니다.
Real-World (Fig. 5)
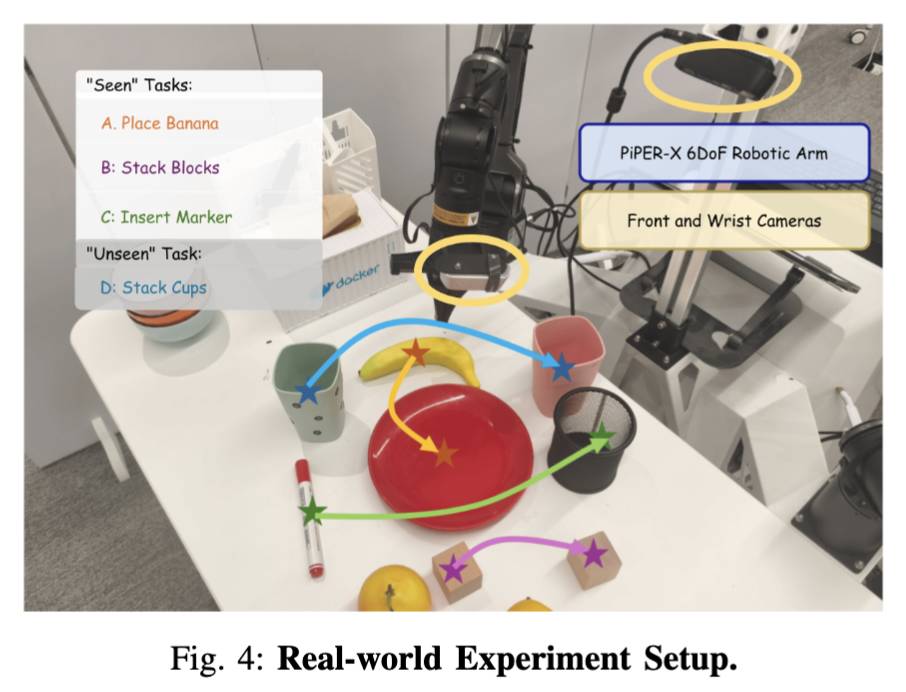
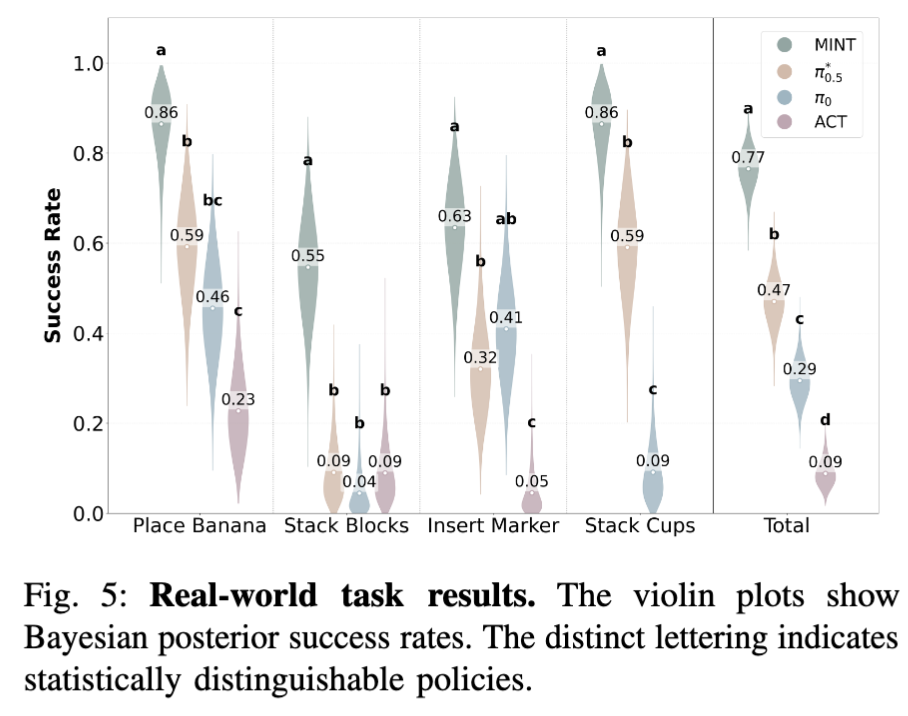
Piper-X 6-DOF 팔로 4개 task (Place Banana, Stack Blocks, Insert Marker + zero-shot Stack Cups). Task당 20 demo만 가지고 finetune했는데, Bayesian posterior로 보면 MINT가 모든 baseline (ACT, π0, π*₀.₅) 대비 통계적으로 distinguishable한 우위를 보입니다. Stack Cups는 demo 자체가 없는 zero-shot인데도 Stack Blocks의 stacking intent를 transfer해서 성공시킨다는 게 인상적이었습니다.
Ablation Studies (Table IV)
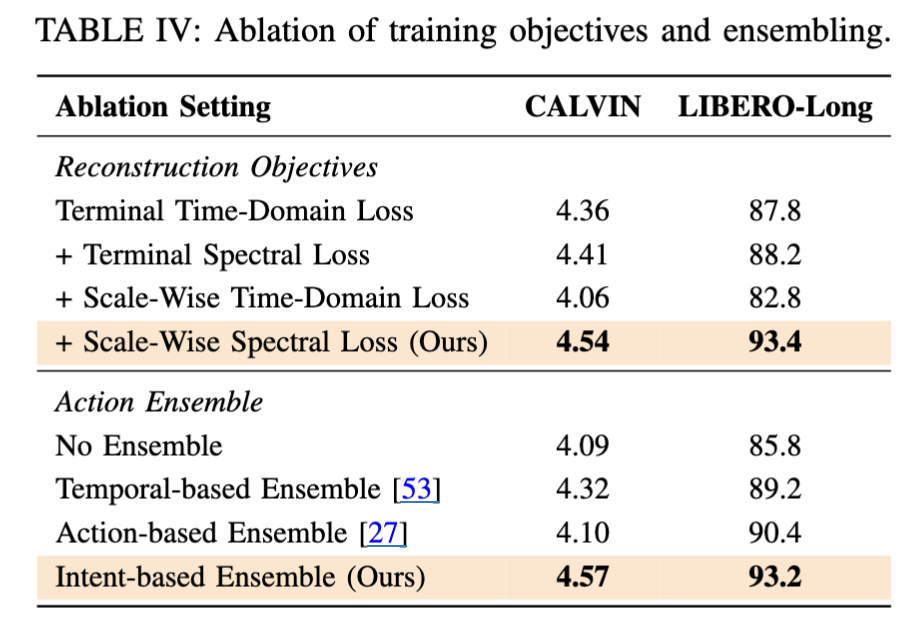
Ablation 결과를 정리해보면, scale-wise spectral loss가 결정적인 요소입니다. scale-wise time-domain loss는 오히려 성능을 깎아먹더라고요 (LIBERO-Long에서 82.8%까지 하락). 이게 왜 그런지 저자들은 high-frequency noise에 overfit하기 때문이라고 해석하는데, time domain에서는 모든 주파수 성분이 섞여있으니까 scale-wise constraint가 잘못 걸리면 노이즈만 따라가게 되는 거라고 하구요. 반면 frequency domain에서는 저주파/고주파가 명시적으로 분리되니까 scale-wise constraint가 spectral hierarchy를 정확히 induce하게 된다고 합니다.
Action ensemble 쪽도 비슷한 경향인데, Intent 호환성으로 weighting을 동적으로 조절해서 behavioral transition 시점의 conflict를 해소하는 게 기존 ACT방식의 쌩 Action Chunking과 CogACT 방식의 Adaptive Action Ensemble (AAE) 보다 효과적이라는 주장에 힘을 싣는 결과 같습니다.
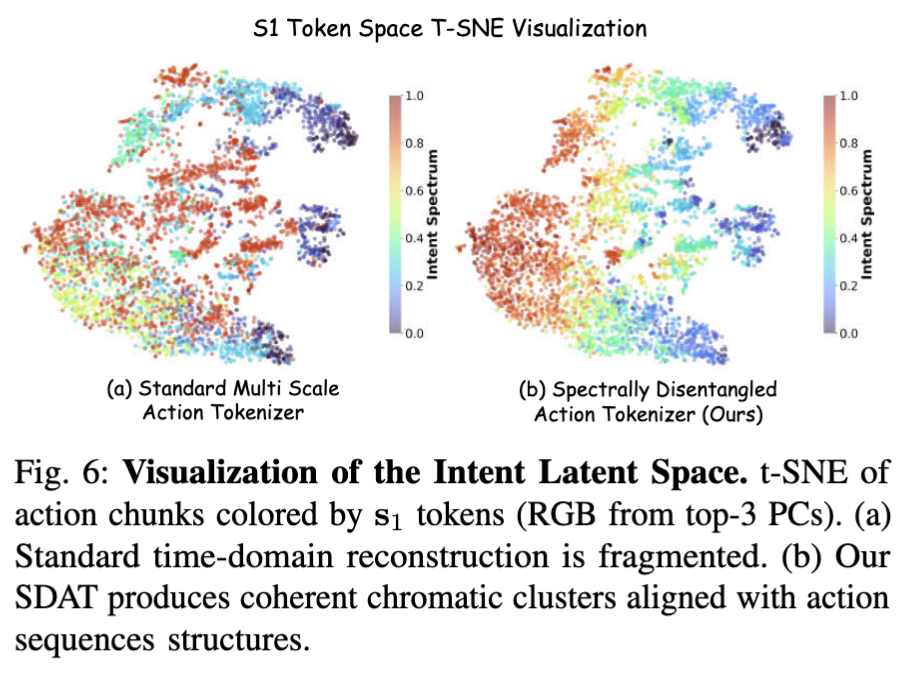
이건 이제 intent latent space의 t-sne 시각화인데요. 기존 time-domain 기반 기법일 때와 spectral-domain 기반 MINT기법일 때의 차이라고 보면 될 것 같습니다. 조금 더 구분력이 있는 것 같은데, 어디까지나 t-sne는 참고용인 것 같습니다.
Conclusion
MINT는 frequency domain의 spectral decomposition을 inductive bias로 활용해서 intent와 execution을 명시적으로 disentangle한 점, single intent token만으로 one-shot transfer를 가능하게 한 점 이 2개가 가장 큰 임팩트라고 생각합니다. 한계점으로는 저자들도 지적하듯 trajectory demonstration에 의존하기 때문에 intent의 다양성이 결국 데이터셋 스코프에 갇혀있다는 게 있는데, 이건 점차 large-scale video data 같이 data scaling을 활용하는 후속 연구로 풀 여지가 매우 크게 남아 있는 것 같습니다. data scaling으로 최대한 비슷한 intent token을 anchor삼게하고, 해당 intent token에서 점차 multi-scale tokenizing으로 action자체의 low-level execution token을 잘 모아낼 수 있다면요..! 개인적으로는 그런 관점에서 본 논문의 spectrum decomposition 컨셉이 현존하는 time-domain의 모든 robot 데이터의 action trajectory들을 다 frequency domain으로 변환해서(어쩌면 video 데이터조차도) 좋은 latent embedding manifold로 표현해낼 수 있지 않을까… 하는 막연한 생각이 듭니다. 물론 제가 할 사이즈는 아니지만요. 그럼에도 또 드는 생각으로는 지금까지의 논문들이 다루는 그런 general한 robotic task의 의미로써는 잘 표현될 수도 있긴 하겠지만, 진짜 섬세한 디테일을 가지고 성공 실패가 갈리는 high-frequency feedback이 중요한 contact-rich task (예: assembly나 dexterous manipulation)에서는 “고주파=노이즈”라는 가정이 깨지지 않을까 하는 의문이 들었습니다 (MetaWorld의 Very Hard task에서 56%로 다른 baseline 대비 압도적이지만 절대 수치는 여전히 낮은 편).
안녕하세요 재찬님 리뷰 감사합니다.
Intent와 execution의 차이에 대해 조금 더 질문이 있습니다. 둘을 구분하는것은 정보의 양(coarse or not)인가요?
기존 방법 중에 discretized tokenization은 어떻게 이를 구분하는 것인가요? 또한 VQ-VAE 방법은 어떤 방식인가요?
Standard residual VQ (RVQ)는 모든 스케일에 균등한 capacity를 주는 방식에 대해 조금 더 설명해주시면 감사드리겠습니다.
감사합니다
안녕하세요 유진님, 좋은 질문 감사합니다.
1. 오.. 생각해본 적 없었던 질문입니다! 되게 오래 생각을 해봤는데, 제가 내린 결론은 정보의 양이 차이가 있어서 둘이 구분된다. 라기 보다는, 둘을 구분하게끔 주파수 도메인과 multi-scale이라는 특정 capacity형태의 inductive bias로써 애초에 설계됐기 때문에 표면적으로 봤을 땐 토큰 수 자체가 차이가 있을지라도 decoding되는 과정에서 정보의 양이 차이가 있다. 라는 표현이 맞을 것 같습니다. 즉 양이 어찌되었든 토큰을 각자 하나씩만 봤을 때는, s1 token 하나에는 global한 intent에 해당하는 latent context가 담기고, s_k token 하나에는 global하지 않은 latent context가 담길테니까요.
2. 기존 방법 중 discretized tokenization은 이를 명시적으로 disentagle하게 제약을 두지않아왔다는 것이 이 논문과의 핵심적인 차이점이었습니다! VQ-VAE 방법론은 1. encoder → latent z / 2. z -> discrete codebook vector에서 nearest vector 선택 / 3. decoder → reconstruction 의 방식으로 학습되는데요. 이런 VQ-VAE 방식에서의 z->codebook은 data distribution을 잘 근사하는 방향으로 학습되는 경향이 있습니다. 저도 일전에는 이 쪽의 latent embedding을 semantic한 embedding이 담기게 되는거구나~ 로 이해했었는데, 이 논문에서 주장하는 바를 봐보니, 기존 VQ-VAE 방식은 단순히 데이터 distribution 근사다. 단순히 kinematics나 trajectory의 pattern 을 반영한 것뿐이지, semantic한 intent를 의도적으로 반영하기엔 constraints가 없어서 약했다. 우리는 semantic한 intent를 disentangle해서 더 잘 반영한 token을 만들었다를 주장한 것이라고 보시면 될 것 같습니다.
3. RVQ에 대해 조금 오해의 소지가 있게 작성했던 것 같습니다! 기존 RVQ방식을 활용한 coarse-to-fine quantization은 저자들이 활용한 VAR 방식의 multi-scale prediction 방식보다 상대적으로 “flat”한 capacity를 나눠준다. 라는 표현이 맞습니다! 표현 수정하였습니다!
안녕하세요 재찬님 리뷰 감사합니다.
최근 VLA/IL 쪽에서 intent라는 키워드가 자주 보이는데, 재찬님 리뷰를 보니 확실히 하나의 트렌드가 생긴 것 같다는 생각이 들었습니다. 한 가지 궁금한 점은, MINT에서 말하는 S1 token이 intent라고 여겨질 수 있는 포인트(?) 입니다.
MINT는 action chunk를 multi-scale RVQ로 토큰화하되, S1에 전체 trajectory의 큰 구조를 담도록 강제하고, 이후 token들이 고주파 execution 을 채워주는 구조라고 이해했습니다. 그럼 결국엔 trajectory에 의존하는 것 아닌가? 싶긴 합니다. 물론 behavior를 알아내는 가장 직접적인 단서는 결국 trajectory 안에 있을 수밖에 없다고 생각하는데, 그렇다면 “일반화의 핵심이 intent를 이해하는 것이고, 그러기 위해선 trajectory를 쓰느냐 안 쓰느냐가 아니라, trajectory를 frequency 기준으로 해석하는게 중요하다”가 맞는 이해일까요?
안녕하세요 영규님, 좋은 질문 감사합니다.
저도 고민해봤는데, 결론적으로는 영규님이 말씀해주신 포인트가 맞는 것 같습니다.
결국 behavior의 semantic 일관성을 끌어올릴 실마리는 trajectory 정보 안에 있었다 가 맞는 것 같습니다.
근데 반대로 좀 생각해보면 MINT-4B의 경우에는 VLM backbone을 freeze했다는 것도, 오히려 그 동안의 VLM backbone -> latent action tokenization -> action experts chunking 의 구조가 intent ~ execute token에 대한 명시적인 constraints 없이 잘 활용되지 못했음을 반증하는 거라고도 생각이 듭니다. 즉 이미 VLM은 충분히 그럴듯한 정보를 담고 있었는데, 진짜 action tokenization이 behavior 의미는 집중 못하고 action trajectory의 경향성만 요상하게 담아버려서, VLM이 넘겨주던 의미가 암묵적으로 내재된 reasoning 정보를 써먹지 못했던 걸 잘 써먹을 수 있었던 건 MINT가 intent를 trajectory 내부에서 frequency domain으로 추출할 수 있었기 때문인 것 같습니다.
이는 특히 Table3. OOD one-shot transfer 실험, ablation에서의 intent-based action chunk ensemble 실험에서 잘 느껴지는 대목인 것 같습니다.
감사합니다.