안녕하세요. 프롬프트 엔지니어링:프롬프트에서 컨텍스트, 하네스까지를 통해서 수업의 절반부분을 다뤘는데요. 후반 수업에서는 추론 기법과 에이전트를 실행하고 이를 어떻게 평가하는지에 대한 방법을 배웠습니다. 이번주를 기점으로 수업이 마무리되어서 아쉬운 마음이 큰데요. 여담이지만, 저에게는 큰 이벤트가 있었습니다. 바로, 프롬프트 엔지니어링 심화반 대표로 수료식 발표를 하게 되었다는 건데요. 제일 마지막으로 발표하는 것이라 부담이 컸는데, 강수진 박사님께서 굉장히 만족해주셔서 저도 만족스러운 발표였습니다.
(강수진 박사님께서 제 링그드인 글을 repost 하셔서 저를 따로 언급까지 했는데 잊지 못하는 일이 될거 같네요)
- 강수진 박사님 링크드인 글: https://www.linkedin.com/feed/update/urn:li:activity:7455144304810934272/
- 제가 작성한 수료식 후기 링그드인 글: https://www.linkedin.com/feed/update/urn:li:activity:7455123905733840896/
여담이 길었습니다. 시작해보도록 하겠습니다.
1. 에이전트 시대의 프롬프트 행동 정책이다.
오늘은 앞에서 배운 구조화 프롬프트, 메세지 구조, 컨텍스트 엔지니어링을 실제 실행 구조로 확장해보고자 합니다. 여기서 프롬프트는 더 이상 “좋은 답변 생성”만을 담당하지 않는데요. 모델이 어떤 방식으로 추론할지, 어떤 도구를 호출할지, 어떤 에이전트에게 작업을 넘길지, 어떤 기준으로 결과를 평가할지 결정하는 행동 정책, 즉 policy가 됩니다.

오늘 글의 핵심은 다음과 같습니다. 프롬프팅을 잘하면 답이 길어지는 것이 아니라, 모델이 수행하는 작업의 경로가 안정화도고, 추론 방식이 명확해지고, 도구 호출 실패가 줄어들며, 평가 기준이 일과되지고, 여러 에이전트가 협업할 때 state와 책임이 분리됩니다.
2. Thought Generation 기법
CoT(Chain-of-Thought)는 모델에게 단계적으로 생각하게 하는 기법으로 알려져 있지만, 수업에서는 더 넓은 관점으로 다뤘는데요. 핵심은 생각을 길게 출력하라가 아니라, 문제를 해결할 절차를 설계하는 것이었습니다.
그 예로, 수업에서 다뤘둰 실습을 말씀드리고자 합니다. 한국어 학습 챗봇을 만드는 과제였는데요. 영어 화자 David가 비즈니스 마케팅 관련 한국어 단어 ‘전략’, ‘목표’, ‘분석’을 배우는 상황에서, 모델은 단어 뜻 설명, 따라 읽기, 예문 요청, 칭산 또는 가이드, 마무리를 순서대로 수행해야 했습니다. 이때 단순히 step-by-step으로 단계적으로 출력하라고 명령하면 의미가 없습니다. 문제를 어떻게 해결할지를 절차를 설계하는 것이 먼저이지요.
여기서 CoT는 내부 추론을 길게 쓰게 하는 장치가 아니라, 학습 상호작용의 흐름을 설계하는 장치입니다. 잘 프롬프팅하면 모델은 답변 생성기가 아니라 튜터처럼 행동하게 됩니다.
CoT 외에 thought generation 기법들을 정리하면 다음과 같습니다
| 기법 | 핵심 단서 | 적합한 과제 | 주의점 |
|---|---|---|---|
| 사고 연쇄(CoT) | 단계별로 처리 | 수학, 절차, 튜터링 | 출력이 길어져 비용 증가 |
| 대조적 사고 연쇄(Contrastive CoT) | 좋은 예와 나쁜 예 비교 | 분류, 평가 | 비추론 모델에 특히 유효 |
| 유추적 프롬프팅(Analogical Prompting) | Recall로 유사 문제 회상 | 어려운 문제 풀이 | 유사성이 틀리면 오도 |
| 한 걸음 물러서기(step-back) | 고수준 개념, 제1원리 | 번역, 정책, 복잡한 판단 | 너무 추상화되면 구체성 손실 |
| 사고 흐름 추적(thread-of-thought) | 중간 단서 기록 | 긴 텍스트 처리 | 요약 과정에서 의미 손실 주의 |
Table 1은 성능 순위로 나열한 것은 아니구요. 문제 유형에 따라 어떤 추론 인터페이스를 선택할지 정리한 것입니다. CoT는 절차가 중요한 문제에 적합하고, Contrastive CoT는 좋은 판단과 나쁜 판단의 차이를 모델에게 보여줄 때 유용합니다. Analogical Prompting은 비슷한 문제를 떠올려 풀이 실마리를 만들지만, 떠올린 유사 사례가 부정확하면 오히려 잘못된 방향으로 끌고 갈 수 있으니 주의해야 합니다.
step-back과 thread-of-thought은 긴 입력과 복잡한 맥락에서 특히 중요데요. 전자는 바로 답을 내지 않고 상위 원칙을 먼저 세우게 하며, 후자는 긴 텍스트를 처리하는 동안 중요한 단서를 잃지 않도록 중간 기록을 남기게 합니다. 다만 유념해야할 것이 이 기법들은 내부 사고를 길게 공개하라는 뜻이 아닙니다. 실제 운영에서는 상세한 추론 전체를 노출하기보다, 판단 절차와 검증 가능한 근거를 요약해 출력하게 하는 편이 안전합니다.
3. ReAct: Thought, Action, Observation을 묶기
ReAct는 Reasoning + Acting의 결합입니다. 모델은 답을 바로 말하지 않고, Thought, Action, Action Input, Observation을 반복합니다. 그 예로, 실습에서는 현재 시간 조회, 내일 날짜 계산, 날씨 예보 조회 도구를 연결해 ReAct 에이전트를 구성했습니다.
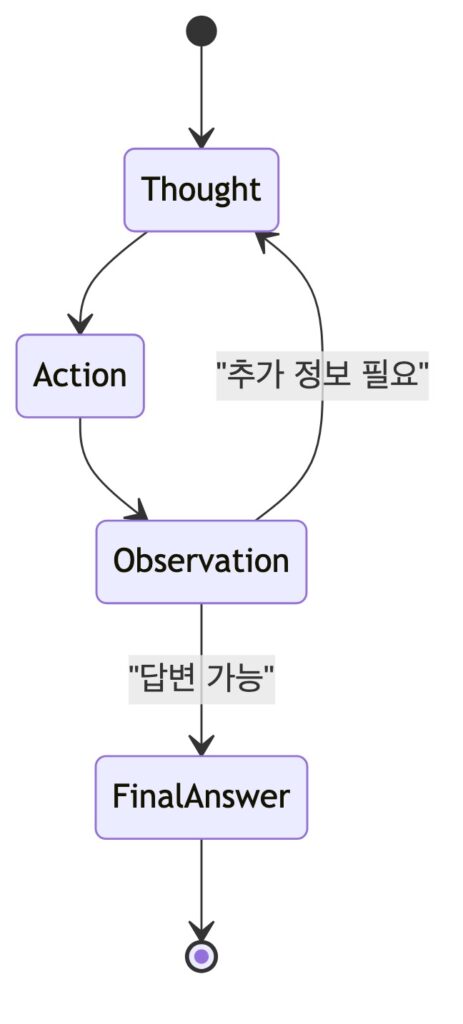
해당 실습에서 가장 중요한 부분은 system prompt의 형식이었는데요.
Use the following format:
Question: the user question
Thought: decide what information is needed
Action: one of [get_current_time, get_weather_forecast]
Action Input: the input for the action
Observation: the result of the action
... repeat Thought/Action/Action Input/Observation as needed
Final Answer: the final answer to the user
해당 형식이 흔들리게 되면 output parser가 깨지게 됩니다. 그렇게 되면 tool name이 조금이라도 바뀌면 runtime이 실제 함수를 찾지 못하게 될 수 있게 되는데요. ReAct는 프롬프트와 코드가 맞물려 돌아가는 구조이므로, 자연어로 유연하게 표현하는 것이 매무 위험합니다.
실제로, 실습 예제를 가져오면, 실습교재의 clean_input 함수인데요. 모델이 생성한 Action Input은 "Asia/Seoul\n", "Tokyo", JSON 문자열, 탭, 개행을 포함할 수 있는데, 도구 실행 전에 이를 정리하지 않으면 pytz, geopy, 날씨 API 호출이 실패할 수 있습니다.
def clean_input(value):
value = str(value).strip()
value = value.strip("\"'")
value = value.replace("\n", "").replace("\t", "")
return value
ReAct의 장점은 명확합니다. 모델이 모르는 정보를 도구로 확인할 수 있고, 중간 관찰을 통해 답변을 갱신할 수 있니다. 다만, 단점도 분명합니다. token과 latency가 증가하고, 초기에 잘못된 관찰이 들어가면 이후 추론이 줄줄이 틀릴 수 있습니다. 그래서 ReAct 프롬프트에서는 if-then-else 구조와 도구 실패 시 행동을 매우 명확히 써야 합니다.
제가 수업을 들으면서 ReAct를 쓰면서 가장 주의해야할 것과 가장 많이 실패하는 부분이 “형식이 살짝 달라지는 것” 이었습니다. Action Input에 따옴표가 붙거나, 도구 이름이 get_weather에서 get_weather_forecast로 바뀌거나, Observation 없이 바로 최종 답변으로 넘어가면 루프가 깨지게 되는 경우가 있었습니다. 따라서 ReAct 프롬프트에는 허용 도구 목록, 입력 타입, 실패 시 재질문 조건, 최대 반복 횟수를 넣고, 코드 쪽에서도 같은 제약을 다시 확인하는 방식으로 작성해야 합니다.
4.Tree-of-Thought
ToT(Tree-of-Thought)는 하나의 사고 경로만 따르지 않습니다. 여러 후보의 thought를 생성하고, 평가하고, 선택하는데요. ToT의 장점은 복잡한 탐색 문제에서 하나의 잘못된 첫 생각에 갇히지 않는다는 점입니다. 다만 단점은 명확한데요. 비용이 많이 든다는 점이지요. 여러 후보를 만들고 평가하기 때문에 API 호출 수가 늘어나기 때문입니다. 그렇기 때문에 박사님께서는 ToT가 단순 분류나 짧은 요약에는 과하고, 복잡한 탐색이 필요한 문제에 적절하게 사용해야한다고 말씀 주셨습니다.
아래의 실습을 예를 들어 설명해보겠습니다. 4개의 숫자로 24를 만드는 문제 단순히 하나의 thought만 생성하지 않고, 여러 후보를 만들어 생각을 한 뒤, 이를 평가해 선택하여 최종 답을 고르는 방식으로 ToT가 동작하는 것을 볼 수 있습니다.
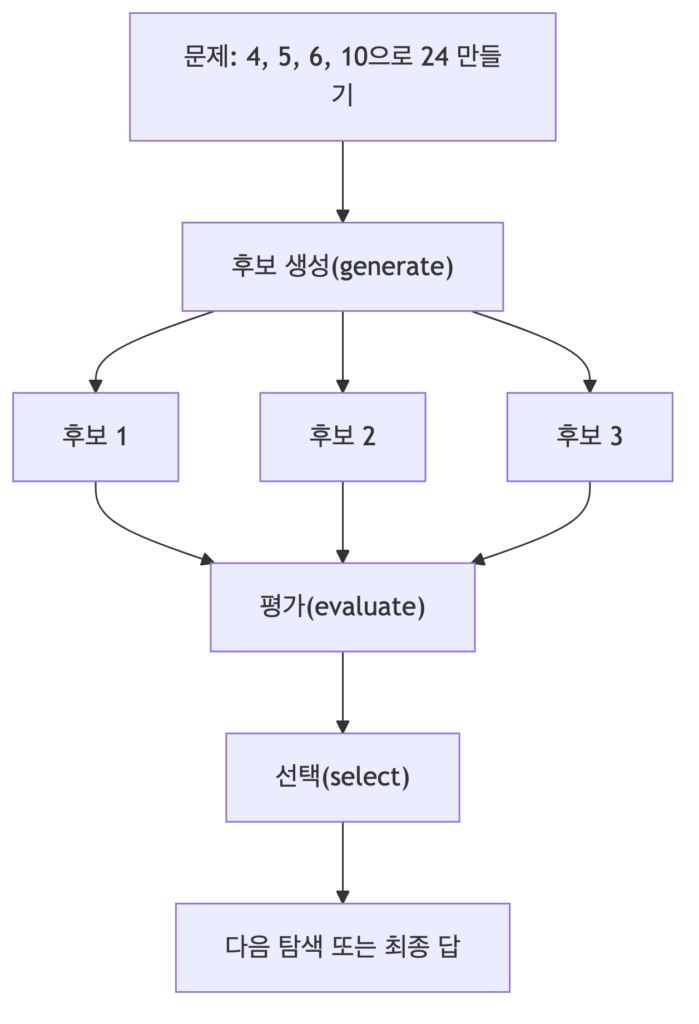
5. Graph-of-Thought
GoT(Graph-of-Thought)는 선형(Chain)이나 Tree 형태를 넘어서, thought node를 그래프로 연결합니다. GoT 실습으로 굉장히 복잡한 실습을 진행했었는데요. 바로 의료 다중 증상 분석 시스템이었습니다. 무슨 말인지 잘 모르겠죠? 결론적으로는 복잡한 판단을 여러 노드로 나누고 관계를 추적하는 방식을 의료 진단에 접목했다는 것인데요. 먼저 프롬프트부터 자세히 살펴보겠습니다.
먼저, MedicalPrompter을 통해 단계별 프롬프트를 만듭니다.
- 문진(intake): 한 번에 1-2개 질문만 하고 충분하면
[문진 완료]표시 - 추출(extract): 대화를 JSON 증상 리스트로 변환
- 증상 분석(symptom analysis): 증상별 의미 분석
- 가설 생성(hypothesis generation): 가능한 설명 후보 생성
- 통합(aggregate): 여러 후보를 결합
- 개선(refine): 부족한 부분 수정
- 점수화(score): 후보의 신뢰도 평가
MedicalParser는 모델 출력을 구조화된 데이터로 파싱하고, GraphReasoningState는 노드와 엣지를 관리합니다.
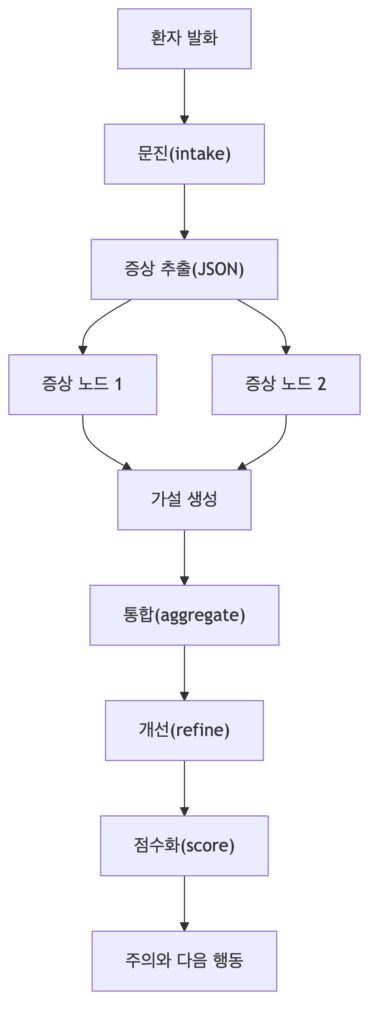
그렇게 되면 위와 같이 행동할 수 있게 됩니다. 굉장히 복잡한 프롬프트인데 뜯어보면 GoT 방식으로 동작하는 구나를 볼 수 있습니다.
GoT의 핵심은 verification인데요. 박사님께서는 고급 프롬프트 기법으로 갈수록 생성만 하는 것이 아니라 검증, 개선, 자기 수정이 들어간다고 합니다. 그 예로, CoT에는 검증이 약하고, ReAct는 도구 관찰을 통해 일부 검증하며, ToT는 후보 평가를 넣고, GoT는 사고 노드 간 결합과 재검토를 포함합니다.
GoT도 장단점이 있는데요. 정확도가 높아질 수 있지만 구현 난이도와 비용이 놀라가게 됩니다. 따라서 단일 프롬프트로도 충분히 해결된다면 굳이 GoT까지 갈 필요는 없습니다.
6. self-reflection
self-reflection은 실습 위주로 진행이 됐었는데요. linkedin 게시글 생성기를 만드는 것으로 self-reflection을 경험하였습니다. generator가 초안을 만들면, critic이 품질, 전문성, hook, 가독성, hastag, 알고리즘 최적화 관점에서 피드백합니다. 이후 피드백이 다시 generator에게 들어가는 식으로 self-reflection이 진행됩니다.
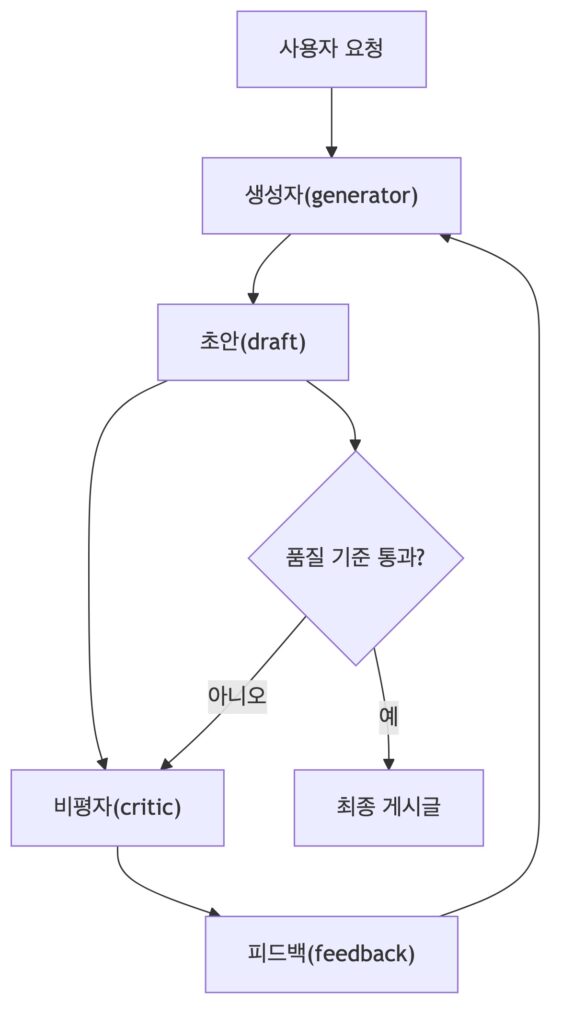
중요한 점은 critic 프롬프트는 생성 프롬프트가 아니라 평가 프롬프트라는 점인데요. 더 좋게 만들어주는 것이 나닌, 어떤 기준으로 무엇을 비평해야 할지 명확하게 해야 합니다.
# Critic Role
Evaluate the draft as a LinkedIn content strategist.
# Evaluation Criteria
1. Hook strength
2. Professional credibility
3. Readability
4. Specificity
5. CTA clarity
# Output Format
- Strengths
- Weaknesses
- Concrete revision instructions
7. Agent Architecture: ReAct, Plan-and-Execute, Multi-Agent
다음으로는 본격적으로 agent의 구조를 다뤄보고자 합니다. agent는 model, tool, obervation, planning, memory, system prompt가 결합된 실행 단위 인데요.
대표 아키텍처는 다음과 같습니다.
| 아키텍처 | 구조 | 장점 | 위험 |
|---|---|---|---|
| 추론-행동(ReAct) | 생각, 도구 호출, 관찰 반복 | 단순하고 구현 쉬움 | 한 번 틀리면 연쇄 오류 |
| 계획-실행(Plan-and-Execute) | 먼저 계획하고 단계별 실행 | 긴 작업에 유리 | 계획이 좋지 않으면, 실행이 어긋남 |
| 다중 에이전트(Multi-Agent) | 역할별 에이전트 분리 | 전문화, 병렬화 | 조율, 비용, 상태 관리 어려움 |
agent architecture는 복잡할수록 좋은 구조라고 판단할 수 있는데 당연히 그렇지 않구요. ReAct는 단순한 도구 사용 과제에 적합하고, Plan-and-Execute는 긴 작업을 여러 단계로 나눌 때 유리하며, Multi-Agent는 역할 분리가 실제 품질 향상이나 병렬 처리 이득을 만들 때 의미가 있습니다. 단순 질의응답이나 짧은 분류 문제에 다중 에이전트를 붙이면 비용과 지연 시간만 늘어날 수 있습니다.
Table2의 위험 열은 운영에서 특히 중요한데요. ReAct는 첫 관찰이 틀리면 이후 답변이 연쇄적으로 흔들리고, 계Plan-and-Execute는 초기에 세운 계획이 상황 변화에 맞게 갱신되지 않으면 실행이 엉뚱해집니다. Multi-Agent는 각 에이전트가 자기 역할을 잘해도 전체 state, 파일 소유권, 종료 조건, 평가 기준이 맞지 않으면 결과가 어긋납니다. 그래서 에이전트 설계에서는 프롬프트뿐 아니라 상태 관리, 로그, 테스트, 사람 개입 지점을 함께 정해야 합니다.
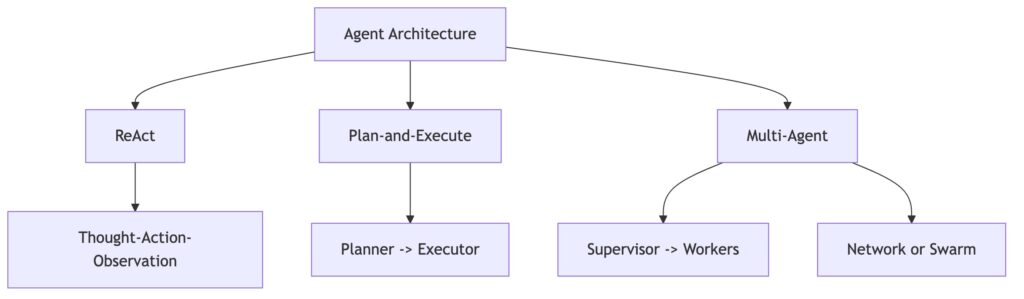
수업에서 박사님께서 따로 supervisor-worker pattern, hierarchy, network/swarm pattern을 언급하셨는데요. 여기서 프롬프트의 역할은 더 커집니다. 단일 에이전트에서는 모델의 답변을 제어하면 되지만, 멀티에이전트에서는 각 에이전트의 책임, 도구 권한, 상태 전달, 종료 조건까지 프롬프트와 코드가 함께 제어해야 하기 때문입니다.
8. Tool Calling
도구 호출(tool calling)은 실행하지 않고 호출을 제안하는 것인데요. 수업에서는 개념을 실습으로 이해하는 시간을 가졌습니다. 실습은 함수 만드는 3단계로 설명됐는데요.
- 도구 스키마(tool schema)를 정의한다.
- 실제 파이썬 함수를 구현한다.
- 모델이 제안한 도구 호출(tool call)을 client가 실행하고 결과를 모델에 다시 넣는다.
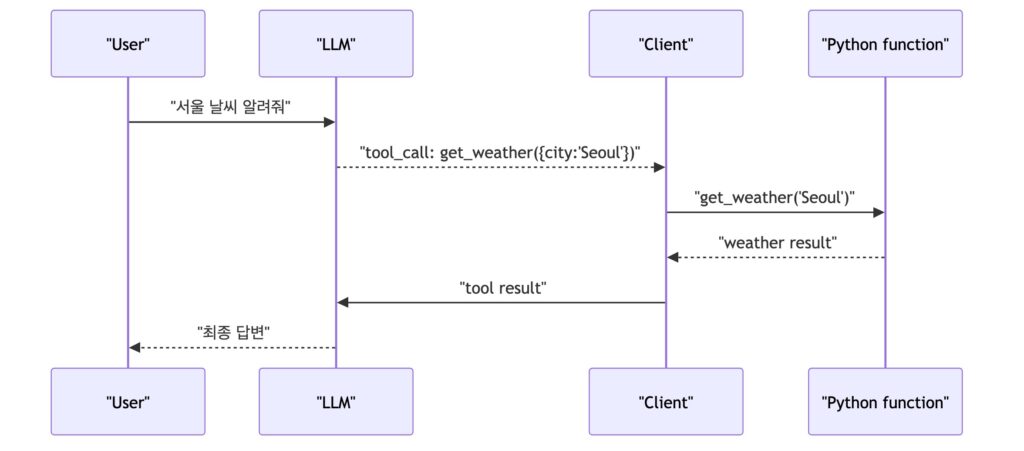
수업에서 중요한 부분은 extension과 function calling의 차이를 구분하는 것이었는데요. extension은 에이전트가 실행까지 맡는 구조에 가깝고, function calling은 모델이 함수 이름과 arguments를 제안하지만 실제 실행은 클라이언트가 담당합니다. 프롬프트의 영향력은 function calling에서 특히 크다는 것을 말할 수 있습니다.
tool schema의 예시가 궁금하실 것 같아 보여드리자면 아래와 같이 구성됩니다.
{
"type": "function",
"name": "get_weather_forecast",
"description": "Get the weather forecast for a specific city and date. Use this when the user asks about future weather. Do not use it for historical weather.",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "City name in English, such as Seoul or Tokyo."
},
"date": {
"type": "string",
"description": "Date in YYYY-MM-DD format. Convert relative dates like tomorrow to an absolute date."
}
},
"required": ["city", "date"],
"additionalProperties": false
}
}
해당 프롬프트를 작성하면서 굉장히 중요한 피드백 4가지를 받았는데요.
첫째, 이름이 중요하다는 것입니다.
-> get_weather_forecast처럼 행동이 보이는 이름이 좋으며, 모호한 이름은 라우팅 실패를 만듭니다.
둘때, description은 “언제 호출하는지”와 “언제 호출하지 않는지”를 모두 담아야 한다는 것입니다.
-> Get flight information 같은 한 줄 설명은 부족한데요. 설명이 부족하면 모호한 설명으로 인해서 부족한 맥락을 임의로 LLM이 채워서 동작하게 됩니다. 그러면 동작을 안하거나 이상하게 동작하는 경우가 정말 많았습니다.
셋째, parameter schema는 type, required, enum, format, 상대 날짜 변환 규칙까지 적어야 한다는 것입니다.
-> 출력 형식을 정해주지 않으면, LLM은 임의의 형식으로 만들어 사용하게 됩니다. 그러면 불규칙한 형태로 출력이 되게되는 경우가 많아지고 예상하지 못한 문제가 발생하게 되게 됩니다.
넷째, system prompt에 호출 정책을 써야 한다는 것입니다.
-> 예를 들어 “도구 호출은 최대 3회까지”, “정보가 부족하면 사용자에게 질문”, “비용이 큰 도구는 필요한 경우에만 호출” 같은 규칙을 작성해야 합니다. 이러한 정보를 작성하지 않으면, LLM이 끊임없이 도구 호출을 반복할 수 있어 많은 비용이 발생할 수도 있습니다.
description을 쓸 때의 감각은 제가 프롬프트 엔지니어링:프롬프트에서 컨텍스트, 하네스까지에서 설명한 구조화 프롬프트와 같습니다. 나쁜 설명은 “날씨를 가져온다”처럼 기능만 말하는데요. 좋은 설명은 “사용자가 미래 날짜의 날씨를 물을 때 호출한다. 과거 날씨나 일반 기후 설명에는 호출하지 않는다. tomorrow 같은 상대 날짜는 절대 날짜로 변환한다”처럼 호출 조건, 비호출 조건, 인자 변환 규칙을 함께 담습니다. 모델은 도구를 실제로 실행하지 않고 호출을 제안할 뿐이므로, 설명이 모호하면 도구 선택과 인자 생성이 동시에 흔들린다는 것을 인지해야 합니다.
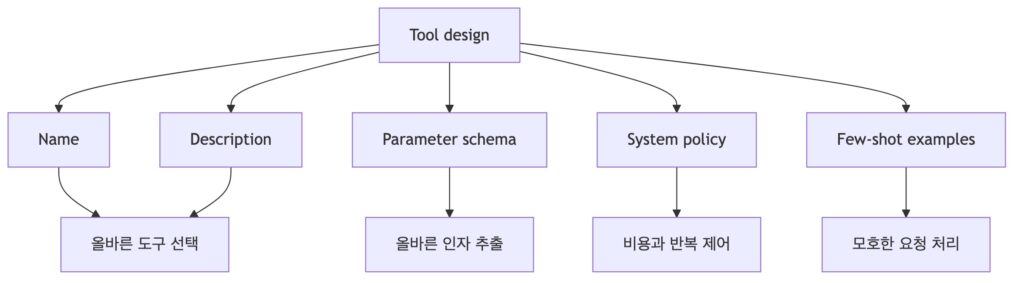
tool calling 디버깅 순서는 다음과 같습니다.
- 설명(description)이 모호한지 먼저 본다.
- 파라미터 설명이 부족한지 본다.
- type과 format이 맞는지 본다.
- system prompt에 호출 정책이 있는지 본다.
- 모호한 입력을 다루는 few-shot 예시가 필요한지 본다.
- 코드 레벨에서도 최대 호출 횟수와 실패 처리를 강제한다.
주의할 점은, 프롬프트에만 “3번까지만 호출”이라고 써두면 충분하지 않습니다. 모델은 규칙을 대체로 따르지만 항상 보장하지는 않기 때문입니다. 비용과 안정성은 코드에서도 제어해야 합니다.
9. Router, Turn Chunking, Query Decomposition
Router는 사용자 요청을 보고 어떤 도구, 어떤 에이전트, 어떤 하위 작업으로 보낼지 결정하는 구조인데요. 아래와 같이 일반 대화(chi-chat)와 비일반 대회(non-chit-chat)으로 나누고, 멀티턴 대화에서 실행 가능한 발화를 분리하는 작업을 수행합니다.
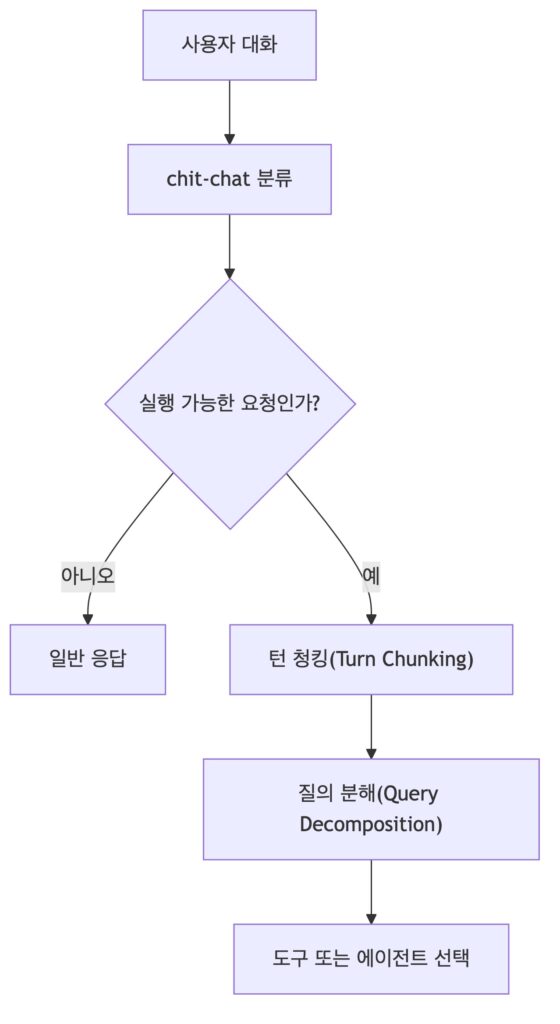
Turn Chunking 실습으로는 대화 데이터를 읽고 single-tur과 multi-turn을 구분해 JSON을 반환하게 했는데요. 아래와 같이 pythonic prompting 스타일로 pseudo code를 제공하였습니다.
# Goal
Split a Korean dialogue into chunks.
# Rules
- Group consecutive lines that share the same topic into one multi_turn chunk.
- If a line stands alone or changes topic, label it as singleton.
# Output Format
{
"chunks": [
{"id": "chunk_01", "type": "multi_turn", "text": "..."},
{"id": "chunk_02", "type": "singleton", "text": "..."}
]
}
Query Decomposition은 모호한 사용자 입력을 실행 가능한 하위 질문으로 나누게 하는데요. decomposition은 단순히 문장을 여러 개로 자르는 것이 아니라, 생략된 주어와 목적어를 채우고, 숨은 의도와 암시적 의도, 행동 설명을 뽑아야 합니다. 박사님께서 수업에서 강조하셨던 것중에 행동 설명이었는데요. 사용자가 준 자연어를 그대로 분해하면 한국어의 생략 때문에 의미가 잘못 잘릴 수 있기 때문에 먼저 사용자의 발화가 어떤 행동을 요청하는지 서술하게 한 뒤에 분해하면 라우팅 정확도가 올라간다는 것을 강조하셨습니다.
10. Prompt Optimization
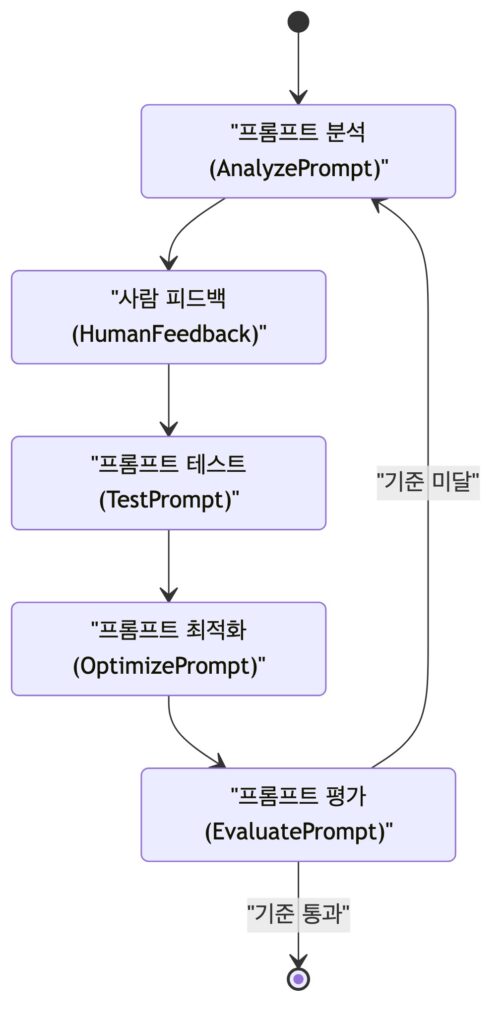
수업에서 중요한 점은 프롬프트만 평가하지 않는다는 것입니다. original prompt, revised prompt, previous response, revised response을 함께 놓고 비교합니다. 답변까지 같이 봐야 실제 품질을 평가할 수 있기 때문입니다.
평가 방식에서도 중요한 포인트가 있는데요. 다음과 같습니다.
- pairwise 비교: A와 B 중 어느 것이 나은지 선택
- closed question:
Yes/No또는 이진 선택으로 중간값 편향 줄이기 - 0/1 점수화: 기준을 만족하면 1, 아니면 0
- justification 작성: 점수의 근거를 짧게 기록
- human-in-the-loop: AI 피드백과 사람 피드백을 함께 반영
여기에서 특이했던 점은 점수를 측정할 때 0에서 100점 사이의 점수로 채점하는 식으로 동작시키면 안된다는 것입니다. 그러면 결국에는 표준분포로 도달하게 된다고 해서 제대로된 점수를 받을 수 없다고 합니다. 그래서 0,1과 같은 점수로 평가를 하는 것이 좋다고 합니다.
11. LLM-as-judge
LLM 평가자(LLM-as-judge)는 모델이 다른 모델의 응답을 평가하게 하는 방식입니다. 평가 프롬프트의 기본 구조는 아래와 같이 설계할 수 있습니다.
# Role
You are an evaluator.
# Inputs
- Original prompt
- Candidate A
- Candidate B
# Evaluation Criteria
1. Does the answer follow the instruction?
2. Is the answer grounded in the provided input?
3. Is the output format valid?
4. Is there unsupported speculation?
# Scoring
For each criterion, answer Yes or No.
Then choose A or B.
이때 주의할 점은 평가 기준은 도메인별로 만들어야 합니다. 교육 문제 생성, 법률 문서 검토, 공인중개사 교재 검증, 뉴스 요약은 모두 다른 기준을 가져야 합니다. 단일 질문 하나로 평가하면 신뢰하기 어렵기 때문에 같은 범주의 질문을 여러 개 넣어 반복 크로스체크해야 합니다.
명심해야할 점은, LLM 평가자는 편리하지만 사실 검증기나 절대 심판은 아닌데요. 평가 프롬프트가 모호하면 평가자 모델도 산문적 인상에 끌리고 긴 응답에서는 앞부분이나 끝부분에 과도하게 영향을 받을 수 있습니다. 따라서 평가 기준은 가능한 한 관찰 가능한 항목으로 쪼개야 합니다. 예를 들어 “좋은 답인가?”보다 “입력에 없는 사실을 추가했는가?”, “요구한 JSON 필드를 모두 포함했는가?”, “출처가 있는 주장과 추론을 분리했는가?”처럼 닫힌 질문으로 만드는 편이 안정적입니다.
추론 기법부터 프롬프트의 평가까지 모두 다뤄봤습니다. 수업에서 실습으로 Multi-agent, 에이전트 오케스트레이션까지 다뤄봤는데 생각보다 글로는 다루기가 쉽지가 않아서 이 부분은 나중에 세미나로 다루면 좋지 않을까 싶어 추후를 기약하며 제외하였습니다. 지금까지 읽어주셔서 감사합니다.