이번에 읽은 논문은 굉장히 인용수 높은 SayCan이라 불리는 논문입니다. LLM을 로봇 행동에 연결하는 방법을 다루는 논문이라고 보시면 됩니다.
이 논문의 핵심은 언어 모델에게 “무엇을 하면 좋을지”를 묻는 것만으로는 부족하고, 로봇이 실제로 “무엇을 할 수 있을지”를 함께 계산해야 한다는 것입니다.
이름 그대로 언어 모델이 말할 수 있는 것(Say)과 로봇이 할 수 있는 것(Can)을 결합하는 방식이라고 보시면 되겠습니다.
그럼 시작하겠습니다.
1. Introduction
본 논문에서는 최근 LLM이 QA, 대화, 문장 생성에서 강한 성능을 보인다고 설명하는데요. 그리고 이런 모델이 일상 task에 과한 지식을 많이 가지고 있다면 그 지식을 로봇이 실제 세계에서 복잡한 일을 수행하는 데 쓸 수 있지 않을까?라는 질문을 하며 시작합니다.
그런데, 역시나 쉬운 일은 아닙니다. 왜일까요? LLM은 physical world에 행동해 본적이 없고, 자신의 출력이 실제 물리 과정에 어떤 영향을 주는지 관찰해본 적이 없기 때문입니다.
그래서 LLM이 사람에게는 그럴듯한 설명을 할 수 있어도 특정 로봇이 특정 환경에서 실제로 할 수 있는 행동을 바로 고르지는 못합니다.
예를 들어서, 주방 로봇이 “pick up the sponge” 또는 “go to the table”과 같은 기본 기술(skill)을 수행할 수 있다고 해봅시다.
사용자가 “음료를 쏟았는데 도와줄래?”라고 말하면, LLM은 청소 절차를 설명할 수 있겠죠. 그런데 로봇에게 청소기가 없거나 로봇이 청소기를 다룰 수 없다면, 해당 답은 실행 가능한 계획이 아닙니다.
논문에서는 프롬프트 엔지니어링만으로도 고수준의 명령을 하위 task로 나누는 것이 어느정도는 가능하다고 보는데요. 하지만, 로봇의 능력, 현재 로봇의 상태, 현재 환경 상태를 모르면 적절한 하위 행동을 고를 수 없다는 것을 강조합니다. 즉, 중요한 것은 실행가능한 “행동”이라는 것이죠.
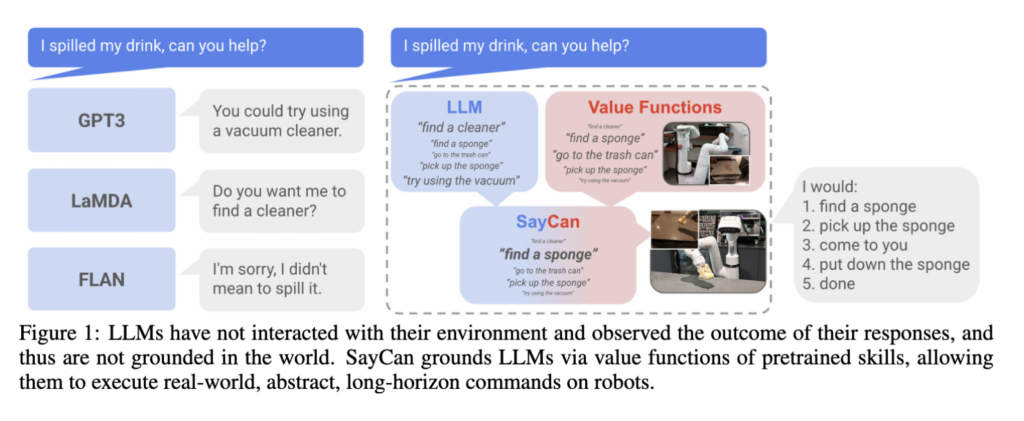
Figure 1을 통해서 제가 앞서 설명한 예제를 확인할 수 있습니다. GPT3, LaMDA, FLAN의 출력물을 보시면, 어떠한 도움에 대한 명령에 대해서 도움을 줄 수 없다고 대답하거나, 사용자에게 행동을 지시하는 대답이 출력된 것을 확인할 수 있습니다.
논문에서는 SayCan을 통해서 LLM을 physically-grounded task에 사용할 수 있다고 하는데요. SayCan에서 “Say”는 LLM이 어떤 행동이 task에 유용한지 판단하는 부분이고 “Can”은 로봇이 현재 상태에서 그 행동을 할 수 있는지 판단하는 부분이라고 보시면 됩니다.
2. Preliminaries
Large Language Models
(오랜만에 개념 정리하는 겸 정리해봤습니다!)
$p(W)=\prod_{j=0}^{n}p(w_j|w_{<j})$
LLM은 텍스트 전체의 확률을 모델링하는데요. 텍스트 $W$ 가 문자열 $w$ 들의 순서라고 하면, 언어 모델은 위의 수식과 같은 확률을 다룹니다. $W$는 전체 텍스트이고, $w_j$는 $j$번째 문자열이며, $w_{<j}$는 $j$번째 문자열보다 앞에 있는 문자열을 의미합니다. 그래서 해당 수식은 문장 전체의 확률을 앞에 나온 단어들이 주어졌을 때 다음 단어가 나올 확률들의 곱으로 나타내며, LLM은 이런 방식의 확장을 통해 여러 task에 일반화할 수 있습니다.
Value Function and RL
로봇에서 필요한 것은 “현재 상태에서 특정 언어 명령으로 주어진 기술을 실행할 수 있는가”를 예측하는 능력인데요. 이를 위해서 시간차(temporal-difference) 기반 강화 학습을 사용합니다.
$\mathcal{M}=(\mathcal{S},\mathcal{A},P,R,\gamma)$
먼저, 로봇의 의사결정 문제를 마르코프 결정 과정(Markov decision process, MDP)으로 정의하는데요. $S$는 상태 공간(state space), $A$는 행동 공간(Action space), $P$는 상태-전이 확률 함수(state-transition probability function), $R$은 보상 함수(reward function), $\gamma$는 discount 계수입니다.
$Q^\pi(s,a)=\mathbb{E}_{a\sim\pi(a|s)}\sum_t R(s_t,a_t)$
$Q^\pi(s,a)$는 상태-행동 가치 함수(state-action value function)이고, $R(s_t,a_t)$는 시간 $t$에서의 보상입니다. 상태s에서 행동a로 시작한 뒤 정책(policy) $\pi$를 따라 행동할 때 받을 보상의 합을 예측합니다. 어떤 행동이 장기적으로 좋은지 판단하기 위해서 사용하는데요. “지금 이 행동을 하면 결국 성공할 가능성이 얼마나 되는가?”를 숫자로 나타낸 것이라고 생각하시면 이해하시는데 도움이 될 것 같습니다.
$L_{TD}(\theta)=\mathbb{E}_{(s,a,s’)\sim\mathcal{D}}[R(s,a)+\gamma\mathbb{E}_{a^*\sim\pi}Q^\pi_\theta(s’,a^*)-Q^\pi_\theta(s,a)]$
$\mathcal{D}$는 상태와 행동 데이터셋이고, $\theta$는 가치 함수의 파라미터이며, $s’$는 다음 상태입니다. 시간차 학습을 통해 현재 보상과 다음 상태의 가치 추정으로 만든 목표값에서 현재 가치 추정을 뺀 시간차 오차 항을 계산합니다. 로봇이 모든 결과를 끝까지 기다리지 않고도 가치 함수를 점진적으로 학습할 수 있게 하기 위해서 사용합니다.
논문에서는 보상이 희소하고, 성공하면 1, 실패하면 0을 받는 경우 가치함수가 곧 affordance function에 해당한다고 설명합니다. 여기서 affordance는 어떤 환경에서 어떤 행동이 가능한지를 나타내는 개념으로 이해하시면 쉬울 것 같은데요. 이 논문에서는 “현재 상태에서 이 기술이 성공할 확률”로 이해하시면 됩니다.
3. SayCan: Do As I Can, Not As I Say
Problem Statement
먼저, 시스템이 사용자 자연어 명렁$i$ 를 입력받습니다. 해당 명령은 길 수도 있고, 추상적일수도, 모호할 수도 있습니다.
또한, 로봇은 기술, 즉, skill의 집합 $\Pi$를 가지고 있다고 가정합니다. 각 기술 $\pi\in\Pi$는 특정 물체를 집는 것처럼 짧은 task를 수행하며, 짧은 언어 description \ell_\pi이 붙어 있습니다. 추가로 현재 상태 $s$에서 그 기술이 성공할 확률 $p(c_\pi|s,\ell_\pi)$도 있습니다.
예를 들어서, $\ell_{\pi}$가 “find a sponge”라면 $p(c_\pi|s,\ell_\pi)$는 현재 상태에서 로봇이 그 명령을 성공시킬 확률로 볼 수 있습니다. 논문에서는 이 값을 “내가 로봇에게 $\ell_\pi$를 시키면, 로봇이 그것을 해낼 수 있는가”라는 질문으로 해석하기도 합니다.
$p(c_i|i,s,\ell_\pi)\propto p(c_\pi|s,\ell_\pi)p(\ell_\pi|i)$
$p(\ell_\pi|i)$는 LLM이 보는 task-grounding 확률이고, $p(c_\pi|s,\ell_\pi)$는 로봇의 world-grounding 확률입니다. 수식적으로 어떤 skill이 사용자 명령을 진전시킬 확률은 그 skill이 현재 상태에서 성공할 확률과 그 skill description이 사용자 명령에 적절할 확률을 곱한 값에 비례함을 의미하는데요. 언어적으로 맞지만 실행불가능한 행동과, 실행가능하지만 task와 무관한 행동을 모두 피하기 위해서 필요하다고 봅니다.
Connection Large Language Models to Robots
LLM이 높은 수준의 명령을 로봇이 실행하기 적합한 수준의 하위 명령으로 바로 분해하지 못할 수도 있는데요. 예를 들어서 “로봇이 나에게 사과를 가져오려면 어떻게 해야 하는가”라는 질문에 대해, LLM은 근처 가게에 가서 사과를 사오세요라는 식의 답을 할 수 있습니다. 이렇게 보면 문장으로는 자연스럽지만, 특정 로봇에게는 실행가능한 행동이 아닐 수도 있겠죠.
그래서 본 논문에서는 이를 해결하기 위해 LLM의 출력을 generation에만 사용하지않고, 고정되 후보 skill에 대한 점수 계산용으로도 사용하는데요. 즉, 언어 모델에게 아무 문장이나 만들게 하는 대신, 로봇이 실제로 가진 기술 설명들 중 어떤 것이 다음 단계로 적절한지 확률을 계산하게 만드는 것입니다.
$\ell_\pi=\arg\max_{\ell_\pi\in\ell_\Pi}p(\ell_\pi|i)$
$\ell_\Pi$는 모든 skill description의 집합이고, $p(\ell_\pi|i)$는 명령 i가 주어졌을 때 해당 skill description이 다음 단계로 적절할 확률을 의미합니다. 해당 수식은 LLM만 볼 때 사용자 명령 i에 가장 적절한 skill description $\ell_\pi$를 고릅니다. LLM을 로봇이 가진 skill 후보 안에서만 선택하기 위해서 해당 수식이 사용되었는데요. 그럼에도불구하고 논문에서는 이 방식만으로는 부족하다고 설명합니다. LLM이 고르는 skill이 로봇이 가진 skill 목록 안에 있더라도, 현재 상황에서는 적절하지 않을 수 있기 때문입니다. 사과를 가져오라는 명령은 사과가 보이는지, 이미 로봇 손에 무엇이 들려 있는지에 따라 다음 행동이 달라지기 때문입니다.
SayCan
그래서 본 논문에서는 가치 함수를 통해 LLM을 grounding합니다.
$\pi=\arg\max_{\pi\in\Pi}p(c_\pi|s,\ell_\pi)p(\ell_\pi|i)$
$p(c_\pi|s,\ell_\pi)$는 affordance score이고, $p(\ell_\pi|i)$는 LLM score 입니다. 해당 수식을 통해 현재 상태에서 성공 가능성이 높고, 사용자 명령에도 적절한 skill을 최종 선택하는데요. 최종적으로 SayCan이 “말로 적절한 행동”과 “몸으로 가능한 행동”을 동시에 고려하게 됩니다.

Figure 2는 가치 함수가 어떻게 작동하는지 시각적으로 보여주는데요. 로봇이 현재 인지하는 실제 환경의 모습을 입력받아, 로봇이 수행할 수 있는 다양한 기본 skills들대해 현재 상태에서 얼마나 성공적으로 수행될 수 있는지를 나타내는 확률값을 계산하는 것을 확인할 수 있습니다.

알고리즘 1에서는 SayCan의 반복과정을 확인할 수 있는데요. 사용자 명령 i, 초기 상태 s, skill set \Pi , skill set description $\ell_{\Pi}$를 입력으로 받고, “done”이 선택될 때까지 위와 같은 과정을 반복합니다. 사실상, 앞에서 설명드렸던 “[skill에 대해 LLM score 계산] -> [skll에 대해 affordance score 계산] -> [두 점수 곱한 점수 만들기] -> [선택된 skill을 환경에서 실행하고 상태 갱신]->반복”이라고 보시면 되겠습니다.
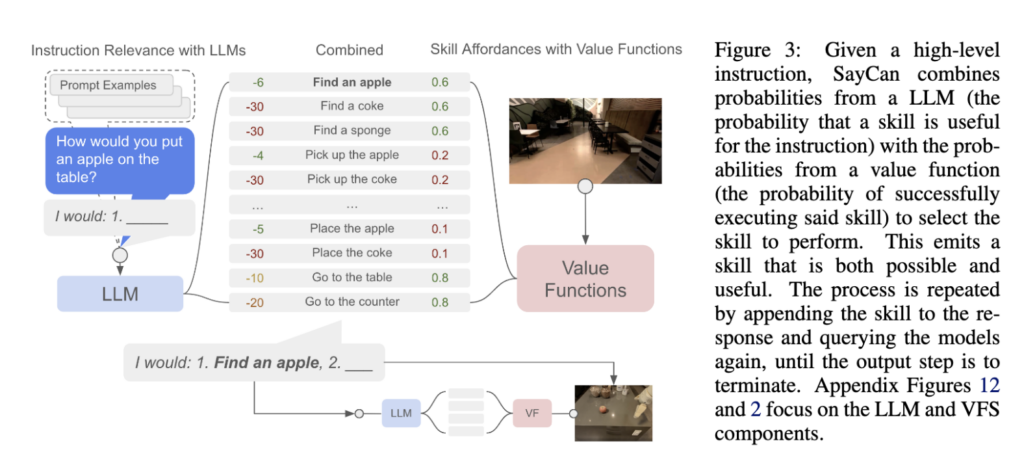
Figure 3의 경우, SayCan의 결합 과정을 확인할 수 있습니다. 높은 수준의 명령이 주어졌을 때 LLM이 각 skill을 평가하고 가치 함수가 각 skill의 실행 가능성을 평가한 뒤, 두 확률을 결합해 실행할 기술을 고르는 과정을 보여줍니다.
4. Implementing SayCan in a Robotic System
SayCan을 실제 로봇 시스템에 구현하기 위해서는 각 skill이 3가지는 가져야한다고 본 논문에서는 설명하는데요.
첫 번째 기술을 기술을 실행하는 정책이고, 둘째는 성공 가능성을 알려주는 가치 함수이며, 셋째는 짧은 language description입니다.
먼저, 개별 skill을 이미지 기반 행동 복제(behavioral cloning, BC) 또는 강화 학습으로 합니다. 여기서 행동 복제는 사람이 로봇을 조종한 시연을 보고 따라 배우는 방식을 말합니다. 논문에서는 데이터 수집 단계에서 행동 복제 정책이 더 높은 성공률을 보였다고 합니다.
또한, 많은 skill을 각각 따로 학습하는 비용을 줄이기 위해서 language description에 조건화된 multi-task BC와 multi-task RL을 사용하였는데요. 기술마다 완전히 별도의 모델을 만드는 대신, 하나의 모델이 skill description을 입력으로 받아 서로 다른 skill을 수행하거나 평가하도록 만드는 방식을 말합니다.
그리고, 정책을 language에 조건화하기 위해 사전 학습된 large sentence encoder language을 사용하였습니다. 학습 중에는 인코더 파라미터를 고정하고 skill description을 입력해 얻은 임베딩을 정책과 가치 함수의 입력으로 사용합니다.
5. Results

먼저 결과를 보여드리기 전에 실험 환경에 대해서 잠깐 설명을 드리면, 실험은 오피스 주방이랑 이를 반영한 모의 주방에서 수행되고, 5개의 위치와 15개의 객체가 사용되었습니다. Figure 4를 통해서 예시를 확인할 수 있습니다. 로봇은 Everyday Robots의 이동 매니퓰레이터를 사용하였으며, 7자유도 팔과 두 손가락 그리퍼를 가집니다. 그리고 앞으로 별도 언급이 없으면 PaLM 언어 모델을 사용하고 이를 PaLM-SayCan이라고 언급하도록 하겠습니다.
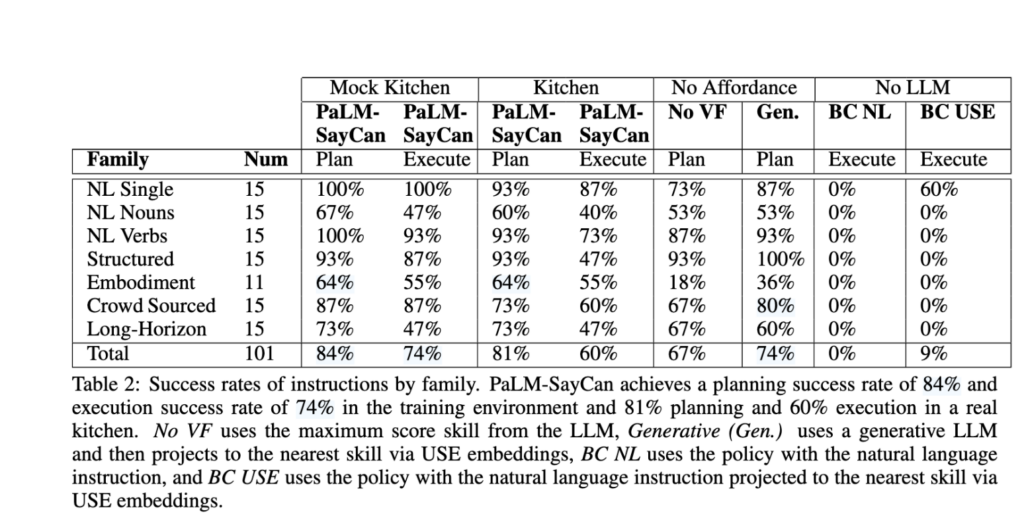
Table 2를 통해서 가장 먼저 정량적인 수치부터 확인하실 수 있습니다. 101개 task에서 성능을 확인할 수 있는데, 실제 주방에서 Plan 성공률은 81%, 실행 성공률은 60%를 달성한 것을 볼 수 있습니다. 모의 주방에서 실제 주방으로 옮겼을 때 Plan은 3%, 실행은 14%로 감소하였네요.

Figure 5는 long-horizon query에 대해서 로봇이 여러 단계로 이동하고 조작을 수행하는 시간 수선대로 장면을 보여준 것인데요. SayCan이 단일 행동을 고르는데 그치지 않고, 여러 단계가 필요한 명령을 수행할 수 있음을 보이는 예시인 것 같습니다.
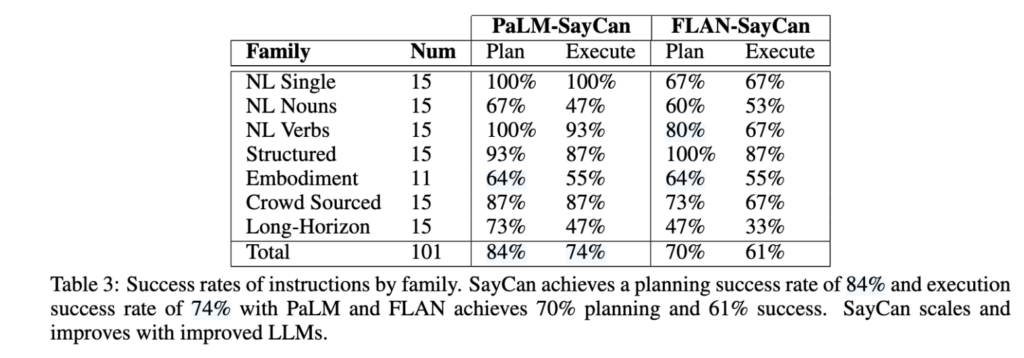
Table 3은 lanuage model에 대해서 ablation 실험을 진행하였습니다. Language 모델의 성능에 따라서 SayCan 전체의 성능이 얼마나 변하는지를 확인할 수 있는데, PaLM-SayCan에서 FLAN-SayCan으로 변하자마자, Plan, 실행 모두 성공률이 하락한 것을 볼 수 있습니다. 근데 그럴것이 파라미터가 PaLM은 540B, FLAN은 130B 모델을 사용하였습니다. 그래서 논문의 저자는 더 좋은 language 모델을 사용한다면 성능이 좋아질 것이다라고 언급합니다.

Figure6은 SayCan의 decision making 과정을 확인할 수 있는데요. 사용자가 음료를 쏟았다고 말했을 때, 모델이 스펀지를 찾고, 집고, 가져오는 순서를 선택하는 과정을 볼 수 있습니다. LLM 쪽에서 어떤 skill이 명령에 맞는지 점수가 나오고 affordance 쪽에서 어떤 skill이 현재 가능한지 점수가 나오는 것을 통해서 어떻게 action을 선택하고 있는지를 확인할 수 있습니다.
이렇게 SayCan을 리뷰해봤는데요. 과거 논문이라는 말이 어색하게, 정말 가능성이 엄청난 논문인 것 같습니다. 그래서 인용수가 이렇게 많은 것이겠죠? 계속해서 해당 논문들을 팔로업 해가보겠습니다. 읽어주셔서 감사합니다.
주연님 좋은 리뷰 감사합니다.
value function을 설계할 때, 로봇이 최종 결과를 보지 않고 가치함수를 점진적으로 학습하는 것은, 학습 데이터가 모두 성공한 상태이기 때문인 것으로 이해됩니다. 그렇다면, 로봇은 이 기술이 성공할 확률의 기댓값이 항상 1이 되는 게 아닌 지 궁금합니다. 저자들이 이를 해결하기 위한 연구를 제안한 것이라면, 이 가치함수는 SayCan 논문에서 어떻게 활용되는 지 궁금합니다.
안녕하세요. 좋은 질문 감사합니다.
해당 질문은 아마도 “로봇이 모든 결과를 끝까지 기다리지 않고도 가치 함수를 점진적으로 학습한다”라고 설명한 부분 때문에 나온 것 같습니다. 여기서 TD 학습은 최종 결과를 아예 보지 않는다는 뜻이 아니라, 최종 성공 및 실패 보상 신호를 앞선 상태들로 점진적으로 전파한다는 의미인데요. SayCan 논문에서는 기술 실행이 성공하면 1.0, 실패하면 0.0의 sparse reward를 사용합니다. 따라서 value function이 성공 데이터만 보고 항상 1을 예측하는 구조는 아닙니다. 만약 정말 성공 trajectory만 학습한다면 말씀처럼 값이 1에 가까워지는 문제가 생길 수 있지만, 여기서 affordance로 쓰이는 value function은 현재 상태에서 특정 skill이 성공 가능한지를 예측하게 됩니다.