안녕하세요. 이번에 리뷰할 논문은 중국의 알리바바 그룹 AMAP랩에서 작성한 Bridging the Indoor-Outdoor Gap: Vision-Centric Instruction-Guided Embodied Navigation이라는 논문 입니다. 실제 로봇 배달이나 라스트마일 시나리오를 생각해보면 로봇은 길가까지 가는 것만으로 끝나는 게 아니라 건물 근처까지 간 다음에 실제 입구를 찾고 그 안으로 들어가는 과정까지 해결해야 하는데 해당 논문은 outdoor에서 indoor로 잘 들어갈 수 있게끔 하는 그런 문제를 풀고자 하는 논문이라고 보시면 좋을 것 같습니다. 이외에도 데이터 구축 방식이라던가 navigation을 보다 잘 수행하기 위해 저자들이 모델 중간 중간 여러 장치들을 설계했는데 여기서 참고해볼만한 아이디어들이 많아 보여서 읽게 되었습니다. 바로 리뷰 시작하도록 하겠습니다.
Introduction

기존 연구들 같은 경우는 Matterport3D나 HM3D 같은 실내 중심 VLN benchmark를 기반으로 발전해온 흐름도 있고 최근에는 CityWalker, UrbanNav처럼 실외 그 중에서도 도심지를 타겟으로 내비게이션을 수행하는 흐름도 있습니다. 여기서 저자들은 기존 연구 흐름이랑은 살짝 다르게 여기서 새롭게 태스크를 정의 합니다.
현재의 embodied navigation 파이프라인은 보조 정보(좌표 정보나, semantic map)를 활용해서 에이전트를 목적지 근처까지 데려갈 수는 있지만 이런 처음 가는 장소라면 알기 힘든 추가 정보에 의존하지 않으면서도 내비게이션의 마지막 구간(라스트마일)을 잘 완수할 수 있는 해결책은 아직 없다고 합니다.
저자들은 위와 같은 문제를 해결하기 위해 새로운 태스크인 out-to-in prior-free instruction-driven embodied navigation을 정의합니다. 실외에서 실내로 이동하는, 사전 정보에 의존하지 않는 지시문 기반 embodied navigation을 정의하고 이에 대응하는 해결 방법인 BridgeNav 를 제안합니다.
그래서 일단 깔아야하는 가정이 로봇이 이미 상위 point-to-point navigation 모듈 덕분에 목적지 근처까지는 왔다라는 전제가 붙습니다. 그 다음부터는 오직 egocentric visual observation과 간단한 instruction만 가지고 실제 target entrance까지 가서 들어가야 하는 문제를 푸는 것 입니다. 추가적인 GPS 좌표나 semantic map, 자세한 주변 설명 같은 외부 정보를 쓰지 않고도 예를 들어 스타벅스로 가 정도의 짧은 instruction만을 가지고 현제 observation 기반으로 스스로 입구를 찾아 들어가야 하는 태스크라고 이해하면 좋을 것 같습니다.
개인적으로도 실제 로봇 서비스 관점에서 어려운 부분이 오히려 long-horizon global navigation 보다는 오히려 마지막 몇 미터의 fine-grained한 접근인 것 같습니다. 실외를 기준으로 했을 때 GPS가 알려주는 건 이 건물 근처 정도지 어느 문이 입구인지 어떤 문으로 접근해야하는지 모르기 때문입니다. 물론 동시에 조금 드는 생각은 이렇게 navigation pipeline 안에서 분리 가능한 서브태스크로 연구하는 것이 실제 배치 관점에서 상위 global planner와는 완전히 독립적인 벤치마크로 가는것이 좋은 방향일까라는 생각이 들기는 합니다.
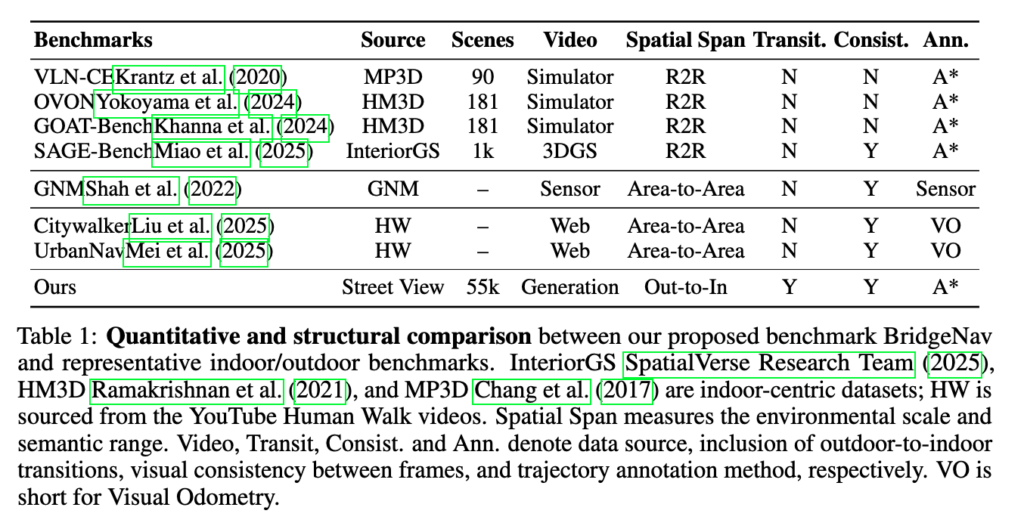
위 테이블을 보면 저자들은 자신들의 벤치마크를 기존 VLN-CE, OVON, GOAT-Bench, SAGE-Bench, GNM, CityWalker, UrbanNav와 비교하면서 자신들은 out-to-in 이동을 포함하고, frame 간 visual consistency가 유지되고(그냥 비디오처럼 연속된 프레임들로 구성되어있느지) 그리고 annotation도 A* 기반으로 궤적이 라벨링되어 있다고 합니다. 여기서 저자가 주장하는 CityWalker, UrbanNav와 차별화된 부분은 웹 비디오 기반의 noisy supervision 대신 좀더 정교한 synthetic generation pipeline으로 터미널 내비게이션을 위한 퀄리티를 높였다는 것 같습니다. 이 부분은 뒤의 dataset 파트에서 자세하게 설명드리도록하겠습니다.
Method
이 논문의 방법론은 크게 두 부분으로 나눠지는데 첫 번째는 BridgeNav라는 저자들이 제안하는 navigation framework 이고 두 번째는 그 모델을 학습시키기 위한 BridgeNavDataset 생성 파이프라인입니다.
저자들이 제안한 내비게이션 프레임워크에서의 핵심 포인트는 이 task에 맞춰 로봇이 가야할 target이 시간에 따라 달라진다는 관찰(예를들어 타겟에 가까워지면 타겟이 시야 밖으로 벗어난다는 등), 그리고 그걸 반영한 latent intention / dynamic perception 설계인 것 깉고 그리고 BridgeNavDataset 생성 파이프라인에 있어서 핵심 포인트는 synthetic하지만 trajectory-conditioned하게 비디오를 생성하는 데이터셋 구축 방식에 있는 것 같습니다. 이에 대해 차근 차근 설명드리도록 하겠습니다.
먼저 모델은 시점 t에서 agent는 현재 RGB observation o_t와 instruction l (dense route instruction도 아니라 짧은 자연어 goal instruction)을 받고, 과거 몇 step의 observation history를 바탕으로 action을 예측합니다. 여기서 action은 저번에 리뷰했던 citywalker, urbannav,nomad와 같이 low level control이 아니라 유클리드 공간상 좌표 waypoint로 표현됩니다. 논문에서는 history 길이 h=10을 사용하고 앞으로의 5 step waypoint를 한 번에 예측한다고 합니다.
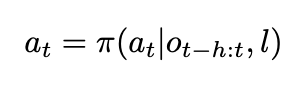
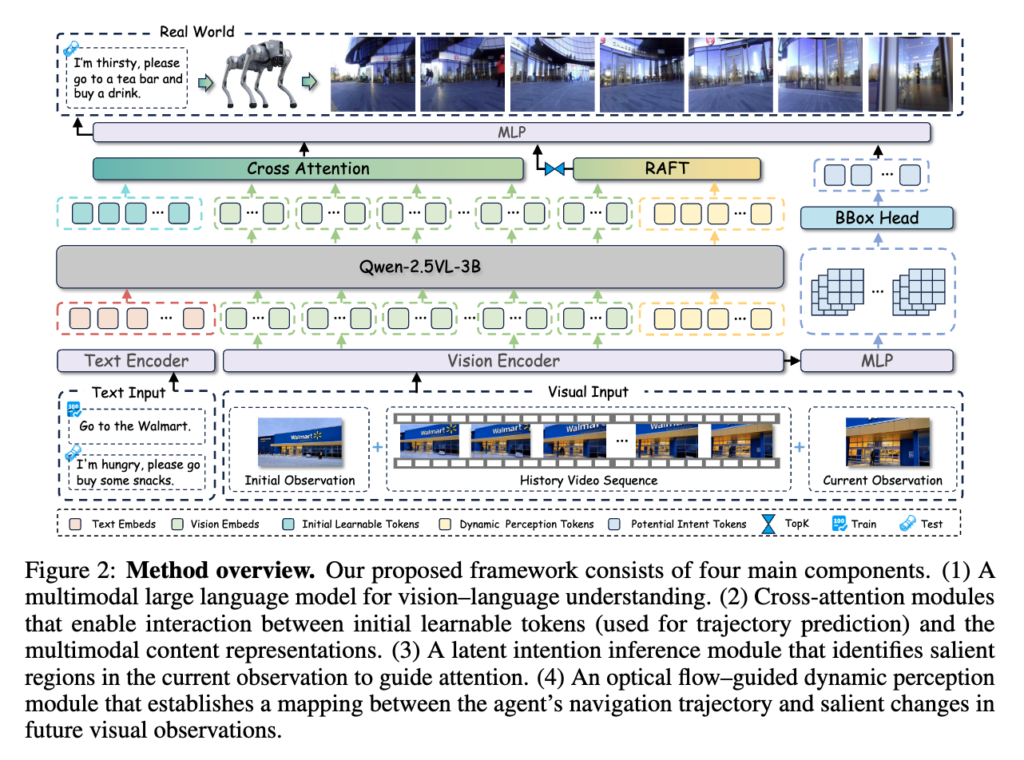
위 그림이랑 논문 설명이랑 매칭해보면서 한시간 넘게 봤는데 이해를 못한 점 죄송합니다. 일단 이해한 선에서 최대한 열심히 설명드리도록 하겠습니다. 일단 전체 pipeline은 네 개의 핵심 구성요소로 되어 있습니다. 우선 text instruction은 learnable embedding layer로 인코딩 되고, visual observation은 ViT 기반 vision encoder로 인코딩됩니다. 그 다음 visual token은 바로 옆에 Latent Intention Inference module로 들어가게 되고 learnable dynamic percetion token들이 추가된 뒤 전체 Qwen2.5-VL-3B를 기반으로 cross-modal interaction을 수행하게 되됩니다. 마지막으로 추가로 inital learnable tokens가 붙어어 함께 decoder를 통해 future trajectory를 예측하는 식으로 동작하게 됩니다. 자세한 내용은 이어서 설명드리도록 하겠습니다.
Latent Intention Inference module
이 논문에서 저자가 주장하는 핵심적인 아이디어 중 하나는 navigation 과정에서 agent가 집중해야 하는 visual cue가 고정되어 있지 않다는 것 입니다. 저자들은 target과의 거리에 따라 attention 해야하는 대상이 바뀌어야 한다고 주장합니다.
먼저 멀리 있을 때는 현재 시야 안에 target이 있는지 자체를 판단해야 하고 중간 거리에서는 건물의 간판을 보는 것이 중요하고 가까워졌을 때는 실제 해당 건물의 출입문을 정확히 찾아야 한다는 것입니다.
Latent intention module은 현재 observation에서 모델이 주의 깊게 봐야하는 영역을 bbox 형태로 추정하게끔 학습됩니다. 현재 단계에서 지금 주의 깊에 봐야 할 곳이 어디냐를 추론하는 느낌입니다.

latent intention module은 위 그림 처럼 중간 정도에서는 간판 sign, 가까이서는 entrance 쪽으로 attention을 이동시키게끔 모델이 어딜보고 가야할지를 가이드해주는 친구라고 보시면 좋을 것 같습니다.
Optical Flow-Guided Dynamic Perception
두 번째 핵심 모듈은 optical-flow-guided dynamic perception 입니다. 저자들은 최근 VLA 쪽이나 citywalker의 future state를 상상하게 하는 것이 도움이 된다는 흐름을 가지고 와서 navigation에서도 agent가 자기 movement 때문에 시각적으로 어떤 부분이 크게 변할지를 예측하게끔 만들고자 합니다.
뭔가 아키텍쳐에서는 토큰이 RAFT의 입력으로 들어가는 것 처럼 그려져있는데구체적으로는 현재 프레임 o_t와 다음 프레임 o_{t+1} 사이 optical flow F를 RAFT로 계산하고 각 픽셀에서 flow magnitude를 구합니다.
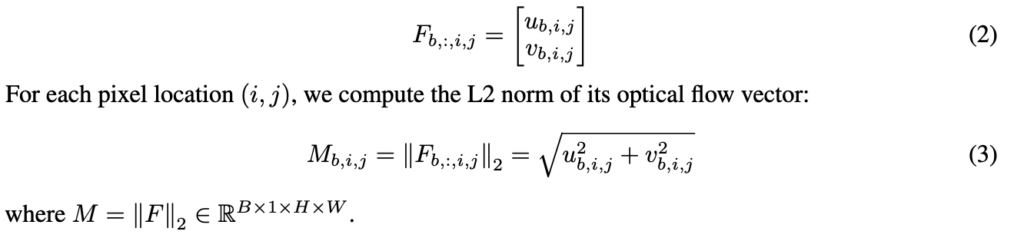
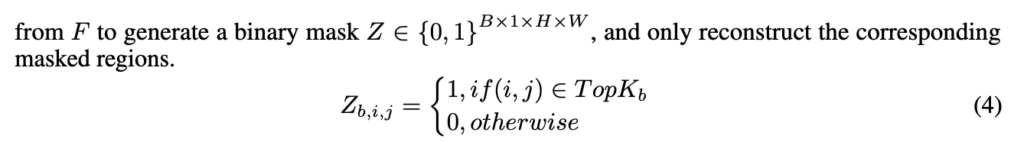
그 뒤 magnitude가 큰 top-k 픽셀 위치만 남겨 binary mask Z를 만들고, 이 마스크된 salient region만 모델이 재구성 하게끔하는데 이를 supervision으로 사용합니다. 논문에서는 k를 전체 픽셀의 10%로 둡니다.
이 부분은 CityWalker의 hallucination future feature prediction 아이디어랑 비슷하면서 다른데 차이는 미래 궤적을 맞추려는 게 아니라 변화가 가장 큰 부분만 복원하려고 한다는 점입니다. 즉 현재 프레임과 미래프레임 사이 가장 변화가 큰 부분 탑K에 대한 픽셀값들을 예측한다고 보시면 됩니다.
optical flow magnitude가 크다고 해서 항상 navigation적으로 중요한 영역인 것은 아닐 수 도있다고 생각이 드는 이유가 예를 들어 바로 앞에 지나가는 사람이 있으면 더 큰 flow를 만들 수도 있을텐데 이 경우에 대해서 모델이 대응할 수 있을지는 모르겠습니다. 요 부분을 개선해서 약간 다이나믹한 객체가 존재하는 상황을 고려해서 flow를 뽑아낸다면 더 좋을 것 같고 추가적으로 여기에 단일 프레임 옵티컬 플로우 대신 과거 시퀀스까지 포함한 비디오 모션 벡터들 활용하는 방안도 괜찮을 것도 같습니다. 암튼 저자들은 이를 통해 에이전트의 움직임과 그에 따라 시각 입력에서 발생하는 중요한 변화 사이의 대응 관계를 학습하게 한다고 합니다. 그리고 당연히 추론시에는 미래 프레임을 알 수 없으니 학습때만 사용해서 최대한 learnable한 dynamic perception token 친구가 학습과정에서 최대한 도움이되는 정보만 빼먹을 수 있게끔 한다음 추론시에는 RAFT, 픽셀 복원 디코더 싹다 뺀다고 보시면 좋을 것 같습니다. 단순히 auxiliary task로써 쓴다라고 이해하시면 좋을 것 같습니다.

Appendix의 optical flow visualization 피규어입니다.
Training Strategy
학습은 2-stage로 진행되는데 1단계에서는 latent intention bbox 예측을 주로 학습하고, 2단계에서는 intention branch를 freeze한 뒤 navigation, dynamic perception, 그리고 vision-instruction alignment를 학습합니다. 그리고 observation-image와 instruction을 랜덤하게 뒤섞은 negative sample을 만들어, 현재 instruction과 observation이 맞는 조합인지 binary classification으로도 학습합니다.
최종 loss는 아래처럼 구성됩니다.
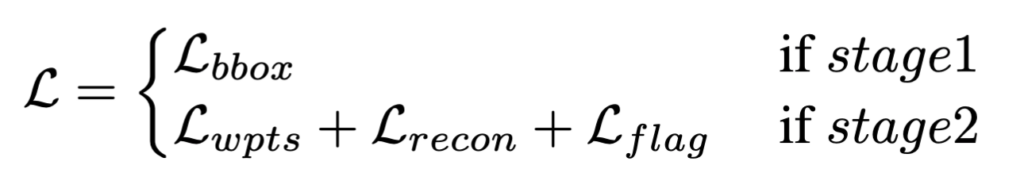
다시 정리하면 지금 어디를 봐야 하는지는 bbox grounding(Latent Intention Inference module)으로 긜고 움직이면 어떻게 변할 것 같은지는 masked region reconstruction(Optical Flow-Guided Dynamic Perception)으로 지금 instruction과 observation이 잘 맞는 쌍인지는 flag prediction으로보조학습을 시키면서 waypoint prediction을 잘 하도록 유도하는 구조라고 보시면 좋을 것 같습니다.
BridgeNavDataset 생성 파이프라인

일단 전체 흐름은 55K개의 고해상도 streetview image를 기반으로 local occupancy grid를 만들고, OCR로 간판 semantic을 추출하고, target bbox를 잡고, 거기에 A* path planning으로 trajectory를 입히고, 마지막에는 trajectory-conditioned video generation까지 수행합니다. 요 아이디어는 데이터가 시퀀스 기반으로 주어지지 않은 즉 비디오로 주어지지 않은 상황에서 내비게이션 데이터 구축하는데 있어서 아주 도움이 많이 될 것 같습니다.
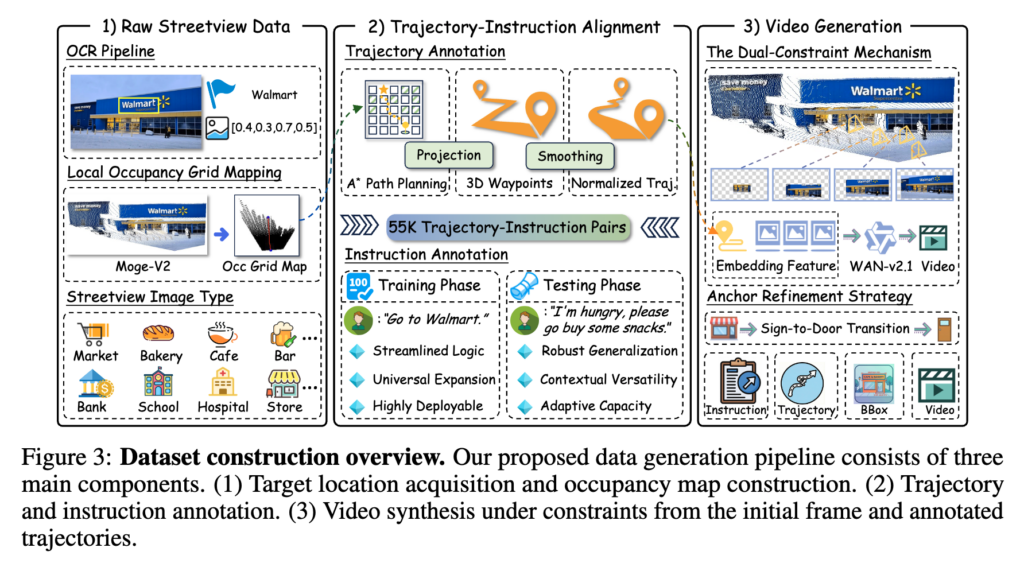
위 파이프라인을 보면 먼저 raw streetview image에서 OCR pipeline으로 가게명이나 sign semantic을 뽑고, MoGe-v2로 depth, geometry를 추정해서 local occupancy grid를 만듭니다. 그리고 그 occupancy grid 상에서 A*로 최단경로를 뽑아내고 이를 다시 inverse projection해서 3D waypoint [x,y,z,yaw]trajectory로 바꿉니다. trajectory는 origin normalization, resampling, smoothing까지 거칩니다.
이후 instruction annotation은 train과 test에서 다르게 구성됩니다. train에서는 “Go to Walmart.” 같은 간결한 instruction을 써서 핵심 목표 의미에 모델이 집중할 수 있도록하는데, test에서는 “I’m hungry, please go buy some snacks.” 같이 좀 더 모호한 natural language를 사용함으로써 모델의 적응 능력을 평가했다고 합니다.
그리고 저자들은 annotated streetview data에서 연속적인 시퀀스를 만들기 위해 Wan2.1-I2V Diffusion Transformer를 이용한 trajectory-guided video generation 프레임워크를 제안했는데 개인적으로 리소스만 많이 잡아먹지 않는다면 요 아이디어를 가져와서 나중에 사용해보고 싶은 생각이 듭니다. 돌아와서 자세하게 설명드리면 구체적으로는 앞서 만든 planned trajectory의 각 discrete point를 virtual camera pose로 보고, MoGe-v2에서 얻은 global point cloud를 주어진 카메라 내외부 파라미터를 가지고 각 pose에 대응하는 2D 이미지 평면으로 재투영함으로써 경로의 기하학적 구조를 반영하는 이미지 시퀀스를 얻을 수 있게 됩니다. 이렇게 재투영된 시퀀스는 에이전트가 움직이는 동안 발생하는 가림이나 FOV 변화 를 현실감 있게 시뮬레이션 할 수 있다고 합니다. 그 다음 여기에 plucker embedding으로 가상 카메라의 pose 시퀀스를 인코딩 함으로써 다양한 원근 변환속에서도 생성된 비디오와 앞서 만든 planned trajectory사이의 일관성을 보장했다고 합니다. 결과적으로 55k pair, 100시간 이상 비디오, 1천만 장 이상 이미지를 얻었다고 합니다. 영상 해상도는 1440×1080, 23fps라고 적혀 있습니다. 아래는 위 과정을 통해 만든 결과라고 합니다.

그리고 그다음 Target Anchor Refinement에서는 생성된 비디오 시퀀스에서 에이전트가 목적지에 가까워질수록 멀리서 유도하는 랜드마크 역할을 하던 상점 간판은 FOV 때문에 점차 프레임 밖으로 사라지게 되는데 여기서 에이전트가 목표에 가까워질 때에도 anchor의 연속성을 유지하기 위해 저자들은 생성된 비디오 데이터에서 20k장의 이미지 를 샘플링하고, 내비게이션 목표의 bounding box를 상점 간판에서 상점 출입문(entrance) 으로 옮기는 식으로 다 수작업으로 라벨링했다고 합니다.
Experiments
실험에서는 success rate와 navigation efficiency를 기준으로 간단하게 평가했다고 합니다. Success rate는 target 근처 반경 0.1m, 0.2m, 0.3m 이내 도달 여부로 측정합니다. fine grained하게 잘 도달했는지를 평가하기 위해서 이렇게 보수적으로 세팅한것 같습니다.(citywalker, Urbanav는 5m이내로 평가 합니다.) 그리고 Navigation efficiency는 GT A* trajectory와 agent trajectory 사이 차이를 보면서을 보며 agent가 비효율적으로 돌아가지는 않았는지를 평가하는 지표라고 보시면 좋을 것 같습니다.
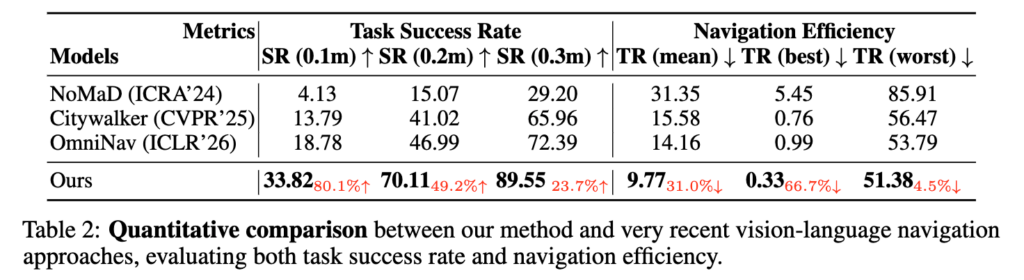
비교 대상은 NoMaD, CityWalker, OmniNav이고 모두 BridgeNav dataset 위에서 다시 학습시켜서 vision-language backbone은 Qwen2.5-VL-3B로 통일했다고 합니다. 일단 위 테이블 결과같은 경우 real world closed loop 평가인지 아니면 저자들인 제안한 데이터셋에서 open loop로 오프라인 평가를 진행한결과인지 자세한 실험 세팅에 대한 내용은 없습니다. 결과적으로는 전체적으로 다 좋은 성능을 보입니다.

위는 real-world deployment 정성적 결과 입니다. 실제 사족 보행 robot이 luckin coffee, MOLLY TEA, CHAGEE 같은 장소의 entrance 쪽으로 잘 접근하는 장면이 나옵니다. 그리고 위에도 잠깐 보여줬지만
아래 결과에서는 latent intention box가 실제로 attention 해야하는 target 를 골라내고, 가까워질수록 entrance 쪽으로 이동하는 모습을 보여줍니다.

Ablation Study
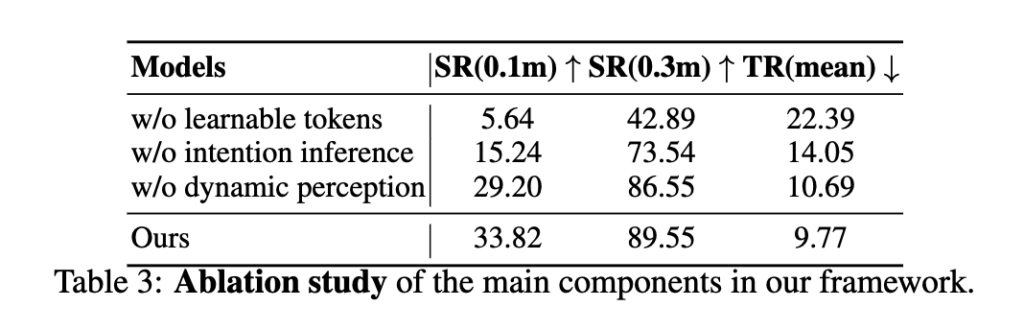
ablation을 보면 세 요소가 다 도움이 되지만 특히 learnable token 제거 시 성능이 크게 떨어진다고 합니다. 이부분에 대해서 저자들이 방법론에서 깊게 다루지는 않았지만 learnable한 토큰이 dynamic token이외에도 아키텍쳐 그림에서 하늘색짜리 토큰이 하나더 있었습니다. 요런 learnable한 토큰을 가지고 알아서 필요한 정보만 쏙쏙 뺴먹게 하는 방식이 다양한 분야에서도 사용되는 것 같습니다. Qwen 전체 representation을 그대로 행동예측에 쓰지말고 행동 예측 전용 query token이 거기서 필요한 정보만 알아서 뽑아오게 하는 느낌으로 설계를 함으로써 이해와 행동 결정을 분리해서 처리하게끔 설계한 방식으로 보시면 좋을 것 같습니다. 나머지 bbox 가이드나 옵티컬 플로우 가이드도 다 성능 향상에 도움을 주는 결과를 보입니다.
Conclusion
기존 단순한 아키텍쳐를 기반으로 내비게이션을 수행하는 연구와는 다르게 해당 논문은 내비게이션을 fine grained하게 잘 수행하기 위해 모델이 학습하는데 있어서 가이드를 받을 수 있는 여러가지 모듈을 설계하고 해당 모델을 잘 학습시키기위해 살짝 복잡하지만 VO 방식보다는 훨씬 정교하고 디테일한 데이터셋 구축 파이프라인을 제안했다는 점에서 개인적으로 참고할 만한 다양한 아이디어가 녹아들어있는 논문이었던 것 같습니다. 아카이브에 한달전에 올라온 논문이라 그런지 아직 코드 공개는 되어있지는 않은데 공개되면 한번 참고해봐도 좋을 것 같습니다. 이만 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요 우현님 좋은 리뷰 감사합니다.
해당 방법론이 in-out 을 중심적으로 해결하려고 하는 논문으로 이해했는데요,
우선 우현님께서 말씀주신 long-horizon global navigation 보다는 오히려 마지막 몇 미터의 fine-grained한 접근이 중요하다고 하셨는데 기본적으로는 Long-horizon이 더 어려운게 아닌가요 ??? 혹시 그럴만한 이유가 있는지가 궁금하고 두번째로는 ablation 에서도 그렇고 Latent Intention Inference module 이 가장 핵심인것같은데 간판이나 입구같은거에 집중해서 학습시키는것 같은데 자세하게 어떻게 학습시키고 어떻게 attention을 주는지 모르겠습니다. 설명주시면 감사하겠습니다.
좋은 리뷰 감사합니다
안녕하세요 우진님 좋은 댓글 감사합니다.
주변 Map 정보가 있다는 조건하에서는 오히려 fine grained 접근 보다는 long horizon이 더 쉬운 문제일도 있겠다는 제 개인적인 생각을 그냥 적어뒀습니다 허허 그리고 두번째 질문에 대해서는 일단 저자가 간판이나, 문, 건물 정도만 annotation을 수행했기 때문에 자연스럽게 모델은 문에 가까워지면 문에 BBox를 치도록 학습이 이뤄지고 해당 정보를 모델에 가이던스로 넣어줌으로써 모델이 해당 부분에 집중하도록 설계가 되어있다고 보시면 좋을 것 같습니다. 감사합니다.
안녕하세요 우현님 리뷰 감사합니다.
indoor 문제가 확실히 어려워보이고, dataset도 많지 않을거라고 생각했는데 synthetic data를 사용하는 접근들이 있구나 하면서 읽었습니다. Bbox를 만들면서 작동하는 구조도 여태 우현님 리뷰나 세미나를 참고했을때 되게 의미가 있을 것 같은데, 혹시 이에대한 ablation이나 분석은 없나요? indoor의 좀 복잡하거나 모호한 상황에서 기여도가 얼마나 되는지 궁금합니다
안녕하세요 영규님 좋은 댓글 감사합니다.
해당 내용에 대한 ablation은 table3에 w/o intention inferece를 참고하시면 좋을 것 같습니다!
일단 해당 모델 자체가 outdoor to indoor 타겟이라 indoor에서 만의 좀 복잡하거나 모호한 상황에서 기여도는 잘 모르겠으나 뭔가 해당 컨셉을 fine grained한 움직임이 중요한 indoor에 적용하면 오히려 해당 방법론이 indoor안에서 좀더 좋게 적용될수 도 있지 않을까 생각이 듭니다.
감사합니다.