こんにちは! 오늘은 기존의 VLA랑은 좀 다른 VLA 분야를 가져와봤습니다. 제가 평소에 보던 VLA는 action head 가 붙어있는 VLA였는데, 제가 우편물 잡기 Task를 수행하면서 보니 로봇 동작의 구체적인 의미보다는 우편물이라는 객체에 집중해야 되지 않나 라는 생각을 하게 되었습니다. 왜냐면 우편물을 집는 행위는 동작을 주의해서 해야 한다는 암묵적인 액션에 대한 이해가 필요없고, 오히려 우편물을 카메라한테 잘 보여주고 VLM이 이해를 할 수 있도록 하는가? 가 중요하다고 느껴졌습니다. 그래서 제가 기초교육 때 보던 MOKA 논문을 복습하는 느낌으로 가져와서 제대로 읽어보고 리뷰를 드리려고 합니다.

- Conference: RSS 2024
- Authors: Fangchen Liu, Kuan Fang, Pieter Abbeel, Sergey Levine
- Affiliation: Berkeley AI Research, UC Berkeley
- Title: MOKA: Open-World Robotic Manipulation through Mark-Based Visual Prompting
1. Introduction
로봇이 복잡하고 다양한 환경에서 인간이 지시하는 임의의 태스크를 수행하려면 물리적 세계에 대한 깊은 이해가 필요합니다. 이를 위해 인터넷 규모의 데이터로 사전 훈련된 LLM과 VLM이 유망한 도구로 주목받고 있지만, 이러한 모델들은 3D 공간 이해, 접촉 물리학, 로봇 제어와 같은 영역에서는 여전히 명확한 한계를 보입니다.
기존의 많은 접근 방식은 LLM이 VLM보다 먼저 발전했기 때문에, 원시 이미지 입력을 일단 언어로 변환한 뒤 LLM이 언어 공간에서 추론, 계획을 수행하는 구조를 취합니다. 그런데 이렇게 되면 작업 완수에 중요한 물체의 형상이나 기하학적 정보처럼 미묘한 시각적 세부 사항들이 언어 변환 과정에서 소실될 수 있다는 문제가 있습니다. 또한 기존 방법들은 LLM이 원하는 예측을 내놓을 수 있도록 in-context example을 설계하는 데 상당한 수작업 노력이 필요하다는 한계도 있었습니다.
이를 해결하기 위해 해당 논문에서는 VLM의 이미지 기반 예측과 로봇의 물리적 동작을 연결하는 중간 표현, 즉 어포던스(affordance) 표현을 핵심으로 하는 MOKA(Marking Open-world Keypoint Affordances)를 제안합니다. 이 어포던스 표현은 두 가지 요건을 만족해야 하는데, 첫째로 VLM이 시각적 관찰과 태스크 설명을 바탕으로 예측 가능해야 하고, 둘째로 로봇이 쉽게 실행할 수 있도록 모션의 핵심 속성을 간결하게 담아야 합니다.
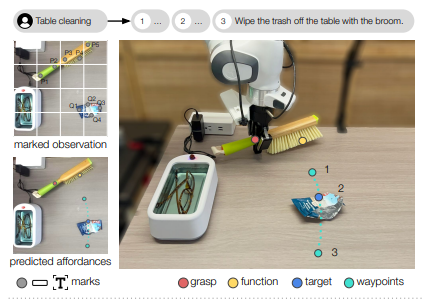

MOKA의 핵심 기여는 세 가지입니다. RGB 이미지 위에서 VLM의 예측과 로봇 동작을 이어주는 포인트 기반 어포던스 표현을 도입하고, 어포던스 추론을 일련의 시각적 질의응답(VQA) 문제로 변환하는 마크 기반 시각적 프롬프팅 방식을 제안하며, zero-shot 및 few-shot 방식으로 개방형 환경의 조작 태스크를 효과적으로 수행할 수 있음을 보입니다.
3. Problem Statement
해당 논문의 목표는 로봇이 처음 보는 객체 및 목표가 포함된 조작 태스크를 자유 형식 언어 지시 l 만 주어진 상태에서 수행할 수 있도록 하는 것입니다.
실험 환경은 7-DoF 로봇 팔과 RGBD 카메라가 갖춰진 탁상형(tabletop) 환경으로, 각 시간 단계 t에서 관측값 s_t를 받고 액션 a_t를 선택하는 구조입니다. 관측값 s_t는 카메라 이미지와 로봇의 고유수용성(proprioception) 정보로 구성되며, 액션 a_t는 6-DoF 그리퍼 포즈와 그리퍼 개폐 상태로 정의됩니다.
태스크 수행은 하나 이상의 서브태스크(subtask)로 이루어지며, 로봇은 언어 지시 l에 기반해 이를 순서대로 분해하고 실행해야 합니다. 예를 들어 “안경을 치운 뒤 빗자루로 쓰레기를 쓸어내라”는 지시는 (1) 안경 케이스에 안경 넣기, (2) 빗자루로 쓰레기 쓸기라는 두 서브태스크로 분해됩니다. 각 서브태스크는 손에 쥔 객체와의 상호작용, 손에 쥐지 않은 객체와의 직접 상호작용, 또는 도구를 활용한 상호작용 중 하나에 해당합니다.
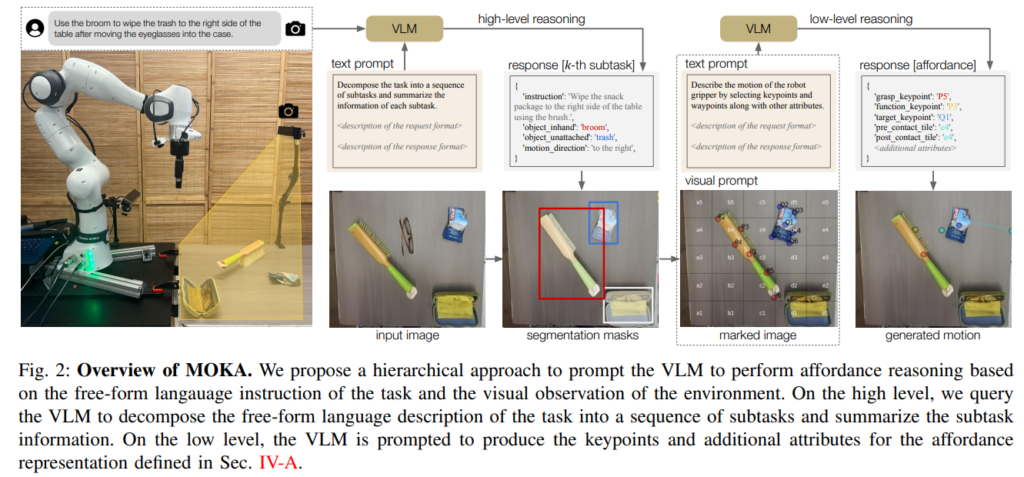
4. Marking Open-world Keypoint Affordances
A. Point-Based Affordance Representations
VLM의 예측과 로봇 동작 사이를 이어주는 인터페이스로, 해당 논문에서는 2D 이미지 위에 정의된 포인트 기반 어포던스 표현을 설계합니다. 사전에 정의된 스킬별로 별도의 모션 프리미티브를 설계하지 않고, 통합된 키포인트와 웨이포인트 집합으로 다양한 조작 태스크를 표현할 수 있다는 것이 특징입니다.
모션은 객체 중심적(object-centric) 방식으로 지정됩니다. 두 종류의 객체, 손에 쥐는 객체 o_{\text{in-hand}}(예: 빗자루)와 직접 쥐지 않는 객체 o_{\text{unattached}}(예: 쓰레기)를 상정하고, 모션을 파악 단계(grasping phase)와 조작 단계(manipulation phase)로 구분합니다. 각 포인트는 다음과 같이 정의됩니다.
- x_{\text{grasp}} : 로봇 그리퍼가 o_{\text{in-hand}}를 잡아야 하는 위치
- x_{\text{function}} : 조작 단계에서 o_{\text{unattached}}와 접촉할 o_{\text{in-hand}} 위의 부위
- x_{\text{target}} : 조작 단계에서 x_{\text{function}}이 접촉할 o_{\text{unattached}} 위의 부위
- x_{\text{pre-contact}}, x_{\text{post-contact}} : 접촉 전후 그리퍼가 지나야 할 자유 공간의 웨이포인트
조작 단계에서 로봇은 x_{\text{function}}이 x_{\text{pre-contact}} \rightarrow x_{\text{target}} \rightarrow x_{\text{post-contact}} 순서의 경로를 따르도록 움직이며, 파악 방향 R_{\text{grasp}}과 조작 방향 R_{\text{manipulate}} 역시 지정합니다. 하나의 통합 표현으로 집기, 놓기, 누르기, 도구 사용 등 다양한 스킬을 커버할 수 있다는 점이 이 설계의 강점입니다.
B. Affordance Reasoning with Vision-Language Models
어포던스 표현을 실제로 예측하기 위해, MOKA는 계층적 프롬프팅 프레임워크를 사용합니다.
하이레벨 추론에서는 초기 관측값 s_0과 언어 지시 l을 받아 VLM에 쿼리해 태스크를 서브태스크 시퀀스로 분해합니다.
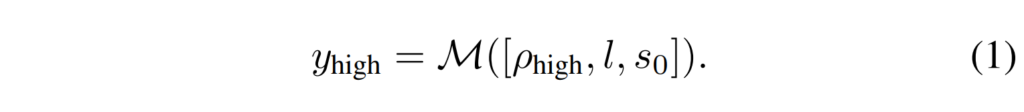
응답 y_{\text{high}}는 각 서브태스크에 대한 딕셔너리 리스트로, 서브태스크 지시문, o_{\text{in-hand}} 설명, o_{\text{unattached}} 설명, 동작 방향(예: “왼쪽에서 오른쪽으로”) 등이 포함됩니다. 이 고레벨 정보가 이후 low level 추론의 입력으로 활용됩니다.
low level 추론에서는 k번째 서브태스크 시작 시점의 관측값 s_{t(k)}를 추가로 받아 어포던스 표현을 생성합니다.
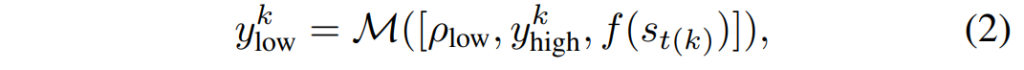
여기서 f(\cdot)는 원시 관측값을 마크 오버레이 이미지로 변환하는 함수입니다. 3D 좌표를 직접 예측하는 것은 어렵고 불확정적이기 때문에, VLM에게는 2D 이미지 좌표만을 출력하도록 유도하고 이를 깊이 이미지와 카메라 파라미터를 이용해 3D 공간으로 역투영(deproject)합니다.
C. Mark-Based Visual Prompting
연속적인 좌표값을 직접 생성하는 것은 기존 VLM에게 어려운 과제입니다. MOKA는 이 문제를 VQA 형태의 다지선다 문제로 변환함으로써 해결합니다.
키포인트 후보 생성의 경우, o_{\text{in-hand}}와 o_{\text{unattached}} 각각에 대해 GroundingDINO로 바운딩 박스를 검출하고, SAM으로 분할 마스크를 추출한 뒤, farthest point sampling으로 윤곽선 위의 K개 경계 포인트와 기하학적 중심점을 합쳐 총 K+1개의 후보 키포인트를 이미지 위에 오버레이합니다. o_{\text{in-hand}} 위의 후보는 P_i, o_{\text{unattached}} 위의 후보는 Q_j 형식으로 색상을 달리해 표기합니다.
웨이포인트 후보의 경우, 웨이포인트는 자유 공간의 위치이므로 전체 이미지를 5 \times 5 격자로 균등 분할하고 체스 표기법(열: a~e, 행: 1~5)으로 각 타일에 이름을 붙입니다. VLM은 사전, 사후 접촉 웨이포인트가 위치할 타일을 선택하면, 해당 타일 내에서 웨이포인트가 균일하게 샘플링됩니다.

이렇게 하면 원래 VLM이 직접 연속 좌표를 생성해야 했던 어려운 문제가, 미리 표시된 후보들 중에서 적합한 것을 고르는 객관식 문제로 단순화됩니다.
D. Motion Generation with Predicted Affordances
VLM이 선택한 2D 포인트들을 실제 로봇이 실행 가능한 모션으로 변환하기 위해 SE(3) 공간으로 리프팅하는 과정이 필요합니다. 객체 위에 정의된 키포인트는 깊이 이미지의 대응 픽셀에서 바로 3D 좌표를 얻을 수 있습니다. 반면 자유 공간의 웨이포인트는 깊이를 결정하기 어려우므로 VLM에게 타겟 포인트와 같은 높이(“same”) 또는 타겟 포인트보다 위(“above”) 중 하나를 선택하게 합니다.
파악 단계에서는 VLM이 예측한 x_{\text{grasp}}에 가장 가까운 antipodal 파악 후보를 DexNet 2.0 기반 파악 샘플러를 통해 제안받아 실행합니다. 순수한 VLM 예측만으로는 접촉 물리학이나 그리퍼 설계를 완벽히 반영하기 어렵기 때문에 분석적 방법을 보완적으로 결합한 것입니다.
조작 단계에서는 x_{\text{function}}이 x_{\text{pre-contact}} \rightarrow x_{\text{target}} \rightarrow x_{\text{post-contact}} 경로를 순서대로 따르도록 궤적을 생성하여 실행합니다.
E. Bootstrapping through Physical Interactions
MOKA로 수집한 성공 궤적을 활용해 성능을 추가로 끌어올리는 두 가지 방법을 제안합니다.
In-context learning은 수집된 성공 사례 중 2~3개를 어노테이션 이미지와 VLM 응답 쌍으로 프롬프트에 추가하는 방식입니다. 이 정도의 few-shot 예시만으로도 VLM 성능이 크게 향상될 수 있음이 알려져 있으며, MOKA 역시 별도의 프롬프트 재설계 없이 이를 그대로 활용합니다.
Policy distillation은 MOKA가 생성한 성공 궤적을 데이터셋으로 삼아 학습 기반 정책을 훈련하는 방식입니다. 실험에서는 사전 훈련된 로봇 파운데이션 모델 Octo를 각 태스크별 50개 성공 궤적으로 파인튜닝(MOKA-Distilled)하여 활용합니다. MOKA가 training-free 방법임에도 불구하고 고품질 실세계 데이터를 자동으로 생성하는 데이터 생성기 역할을 수행할 수 있음을 시사하는 부분입니다.
5. Experiments
A. Experimental Setup
MOKA는 두 가지 베이스라인과 비교됩니다. Code-as-Policies(CaP)는 코드 예제를 통해 LLM이 로봇 실행 가능한 프로그램을 생성하는 프레임워크이고, VoxPoser는 LLM이 3D 복셀맵 형태의 가치 함수를 구성하는 방식입니다. 두 베이스라인 모두 지각 모듈만 동등하게 맞추고 나머지는 원 구현을 유지해 공정한 비교를 수행했습니다.
MOKA는 zero-shot 설정(MOKA Zero-Shot), in-context learning 설정(MOKA In-Context), 정책 증류 설정(MOKA Distilled) 세 가지로 평가되며, 각각 2개의 서브태스크로 구성된 4가지 실세계 조작 태스크에서 시험합니다.

B. Quantitative Evaluation
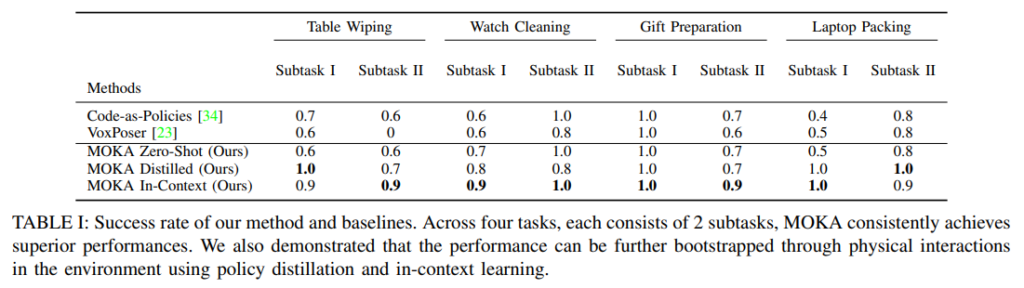
MOKA는 zero-shot 설정만으로도 대부분의 태스크에서 베이스라인과 동등하거나 우수한 성능을 보입니다. VoxPoser는 Table Wiping의 도구 사용 서브태스크(Subtask II)에서 0점을 기록하는 등 도구를 활용하는 조작에서 약점을 드러낸 반면, MOKA는 이 태스크에서도 안정적인 성능을 유지했습니다. 또한 VoxPoser는 복셀맵 해상도에 민감해 하이퍼파라미터 튜닝이 필요한 반면, MOKA는 예제 프롬프트 없이도 잘 작동하고 단 두 개의 직관적인 예시만으로도 추가 성능 향상이 가능합니다.
In-context learning과 policy distillation 모두 zero-shot 대비 일관적인 성능 향상을 보였습니다. 특히 MOKA Distilled는 VLM 추론 단계 자체를 없애버림으로써 추론 실패(reasoning failure)가 완전히 사라지는 효과를 보였고, MOKA In-Context는 단 2개의 예시 프롬프트만으로도 전반적인 성능이 크게 개선되었습니다.
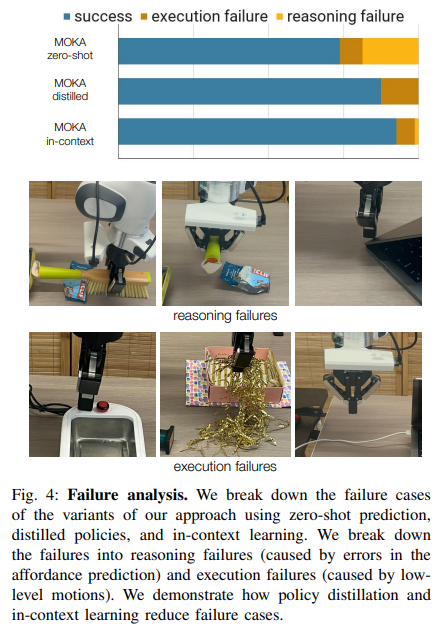
실패는 크게 두 종류로 나뉩니다. 추론 실패(reasoning failure)는 GPT-4V가 그리퍼 파악점과 기능점을 혼동하거나 목표 각도를 잘못 예측하는 등 어포던스 예측 자체의 오류로 발생합니다. 실행 실패(execution failure)는 예측은 올바랐지만 저수준 모션 실행 단계에서 그리퍼가 버튼을 아슬아슬하게 놓치거나 케이블이 그리퍼 손가락 사이로 미끄러지는 식의 물리적 실패입니다. 그림에서 볼 수 있듯이 policy distillation의 경우 VLM이 파이프라인에서 제외되기 때문에 추론 실패가 완전히 사라지고, in-context learning은 두 종류의 실패 모두를 줄이는 데 효과적이었습니다.
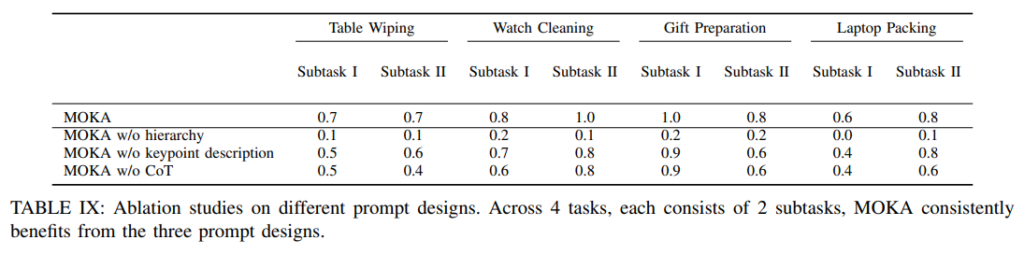
또한 ablation 연구를 통해 각 프롬프트 설계 요소의 효과를 확인했습니다. 계층적 구조(hierarchy)를 제거했을 때의 성능 저하가 가장 극적으로 나타나는데, 예를 들어 Laptop Packing Subtask I에서 0.6에서 0.0으로 떨어집니다. 태스크를 서브태스크로 분해하는 단계가 없으면 VLM이 태스크 순서 자체를 틀리거나 엉뚱한 키포인트를 예측하는 완전한 실패로 이어지기 때문입니다. 키포인트 정의 설명 제거(w/o keypoint description)와 CoT 제거(w/o CoT)는 성능을 소폭 떨어뜨리는 정도이지만, 역시 모든 태스크에서 일관적인 성능 저하를 보이며 각 요소가 모두 기여하고 있음을 확인할 수 있습니다.

C. Qualitative Evaluation

다양한 언어 지시, 초기 배열, 객체 종류에 걸쳐 MOKA가 일관된 키포인트와 웨이포인트 예측을 유지하는 것이 정성적으로 확인됩니다. 동일 태스크에 대해 표현 방식을 달리한 지시어를 사용해도, 그리고 색상·재질·형태가 다른 객체를 사용해도 예측이 견고하게 유지됨을 보입니다.

논문을 읽다보니 객체에 대한 파지점과 동작되는 부분에 대해서 상당히 큰 신경을 쓰는 것 같았습니다. 이를 통해서 사물들이 잘 상호작용하는 방법에 대한 중요성을 느끼게 되었는데, 제가 진행하는 우편물 동작의 경우에는 아직까지는 상호작용이 크게 존재하지 않지만, 매번 잡을 때마다 우편물이 정렬되지 않은 모습을 보고 이를 정렬하기 위한 방법이 필요하지 않을까? 라는 생각이 들었는데, 우편물로 다른 우편물을 정렬하는, 우편물의 넓은 면적을 활용하는 방식에 이러한 방식을 적용할 수 있지 않을까 라는 생각을 하게 되었습니다.

아직까지는 Xlerobot에 많은 Task를 부여하지 않았지만, mobile이 결합된만큼 좀 더 Affordance 기반의 상호작용을 통해 더 많은 Task들을 수행할 수 있도록 임무를 부여해도 좋지 않을까 라고 느꼈습니다.
긴 리뷰 읽어주셔서 감사합니다!

안녕하세요 기현님. 좋은리뷰 감사합니다.
예전에 해당 논문을 읽는 모습을 보았었는데 다시 보니까 반갑네요.
몇가지 질문이 있습니다. 먼저 5×5가 적게 분할한다는 생각이 들었습니다.
물론 큰 물체로는 충분할 거 같지만, 더 작은 분할을 택하지 않은 이유는 연산량 때문인가요?
그리고 평가지표에 대한 질문이 있습니다. Table I에서의 1.0과 같은 성능이 어떤걸 의미하는건지 궁금합니다.
감사합니다!
안녕하세요 정우님. 답글 감사합니다.
우선 첫번째 질문에 대해서는 우선 너무 작은 그리드로 하면 물체가 있는 곳을 판별을 하는데 너무 많은 후보들이 생기기도 하고 연산량도 늘어날 수도 있을 것 같다고 보입니다. 다만 5×5가 최적의 뷰인것은 해당 뷰에서 5×5그리드로 나누었을때 물체들이 하나의 그리드에 적절히 들어오는 것 같다고 보이기도 합니다.
평가지표에서 1.0은 성공률을 0~1로 나타낸 것입니다. 해당 논문에서는 10번 실행한다고 했으니 한 번 성공할 때마다 성공률을 0.1 씩 증가하여 해당 결과가 나온 것으로 보입니다.
좋은 질문 감사합니다!
안녕하세요 기현님 좋은 리뷰 감사합니다!
subtask의 세 가지 종류 중에 “손에 쥐지 않은 객체와 직접 상호작용”은 어떤 경우인가요? pick and place처럼 grisp를 하지 않는 push와 같은 작업을 의미하나요?
감사합니다.
안녕하세요, 예은님 답글 감사합니다.
손에 쥐지 않은 객체와 직접 상호작용은 말씀해주신 것처럼 push와 같은 작업을 의미하는 것이 맞습니다. 논문에서도 로봇이 별도의 물체를 grasp하지 않고, gripper 자체로 환경의 객체에 직접 접촉하는 경우(예: 버튼 누르기, 물체 밀기 등)를 해당 유형으로 설명하고 있습니다. 따라서 pick-and-place처럼 grasp가 필요한 작업이 아니라, 말씀하신 push와 같은 형태의 상호작용으로 이해하시면 정확합니다.
좋은 질문 감사합니다!
안녕하세요 기현님 리뷰 감사합니다.
정말 간단하고 개인적인 질문인데, 최신 VLA 연구들 리뷰하다가 MOKA에 눈이 가신 이유가 있나요? 혹시 지금 진행중이신 프로젝트에 활용하려고 하시는건지 궁금합니다!
안녕하세요 영규님. 답글 감사합니다.
제가 SmolVLA를 기반으로 실험을 하다보니 우편물의 호수가 보이는 면을 제대로 보여주고 있는 것일까? 그리고 호수 이해까지 VLA가 원테이크로 해서 할 수 있을까?에 대한 궁금증이 생겼습니다. 그러다보니 대형 vision language 모델을 기반으로 하는 MOKA가 생각났고 이를 다시 읽어보게 되었습니다.
근데 아무래도 해당 모델은 다양한 테스크에 대해서 파지점을 잘 잡는 것이 목표이다보니 제가 지금 진행중인 프로젝트인 단순 우편물 잡기에서는 조금 거리가 멀지 않나 라는 생각이 논문을 읽으면서 들게 된 것 같습니다.
좋은 질문 감사합니다.