안녕하세요, 이번주 X-review는 data generator로써 RL을 활용하며 VLA에 대한 SFT를 진행하며, 제목처럼 self improving 하는 policy 학습법을 다룬 연구입니다. Recovery behavior를 위한 generalist 데이터셋 구성에 대한 관점과 어떻게 이 정보를 distill 할것인지에 대한 연구입니다. 바로 시작하도록 하겠습니다.
Introduction

최근 로봇 분야에서는 VLA 모델이 빠르게 주목받고 있습니다. 이 계열의 모델들은 대규모 비전-언어-행동 데이터를 바탕으로 사전학습된 뒤, 특정 작업이나 특정 로봇 환경에 맞추어 supervised fine-tuning(SFT) 되는 방식으로 발전해 왔습니다. 저자들은 이러한 흐름이 사실상 언어모델 쪽에서 이미 검증된 패턴을 그대로 따라가고 있는 것이라고 합니다. LLM에서는 대규모 사전학습 이후 curated instruction-response pair를 이용한 post-training이 성능 향상에 매우 효과적이었고, 로봇쪽에서도 비슷하게 대규모 로봇/비전-언어 데이터셋으로 base policy를 만든 뒤, SFT를 통해 특정 task와 embodiment에 맞게 전문화하는 방식이 점점 표준화되고 있다고 합니다. 현재 많은 generalist를 표방하는 모델들이 실제로 학습하고 있는 방법입니다.
저자들은 이 패러다임을 로봇에 그대로 옮기는 데에는 본질적인 문제가 있다고 합니다. 일단 고품질 로봇demonstration은 사람의 teleoperation, 로봇 시스템 셋업, 반복 실험, 물리적 환경 정비를 모두 필요로 하기 때문에 매우 비싸고 노동집약적입니다. 따라서 internet 데이터로 학습이 가능한 LLM쪽 처럼 “좋은 pair를 더 많이 모아 fine-tune하면 된다”는 방식이 쉽게 성립하지 않습니다. 저자들은 또 단순히 비용 뿐만 아니라 더 중요한 문제가 있따고 합니다. 저자들은 인간이 수집하는 시연 데이터가 실제 inference 할 때의 VLA policy와 분리된 teleoperation pipeline에서 얻어진다는 점을 핵심 병목으로 보았습니다. 사람은 현재 policy가 inference중 어떤 상태에 빠지는지, 어디에서 실패하고, 어떤 식으로 무너지기 시작하는지를 완전히 반영하지 못한 채 인간 기준으로 자연스러운 데이터만을 수집하게 된다고 합니다. 그 결과 데이터는 고품질일 수 있어도, 실제로 policy가 마주치는 상태 분포를 충분히 담지 못하게 된다고 합니다. 저자들은 이것을 coverage gap이라 하고, SFT가 학습한 task에서는 잘 작동하더라도 새로운 task나 새로운 환경으로 얼마나 잘 일반화되는지는 여전히 불분명하다고 합니다.
따라서 저자들은 VLA 모델이 RL로 정제된 데이터만으로, 최소한의 인간 개입 하에 스스로를 개선할 수 있는가?
와 더불어 이렇게 self-curated된 데이터가 인간 teleoperation 데이터에 의한 fine-tuning보다 더 나은 성능을 낼 수 있는가, 그것도 in-distribution과 out-of-distribution 모두에서 가능한가를 묻는 형태로 문제를 정의했습니다. 저자들은 RL을 최종 policy를 직접 학습시키는 관점보다 더 나은 post-training 데이터를 만들어내는 수단으로 정의했습니다. 이 논문의 핵심중에 어떤 데이터가 VLA를 더 잘 개선시키는가? 가 핵심인 것 같습니다. 저자들은 위 figure처럼 probe, learn, distill 하는 식의 post-training 방식을 통해 인간의 개입 없이 다양하고 복잡한 manipulation을 학습시킬 뿐만 아니라 Libero 데이터셋에서 99%의 성공률을 기록했다고 합니다.
저자들은 해당 연구를 통해 데이터 수집이 base policy와 무관하게 진행되어서는 안되고, 어떤 task에 대한 expert demonstration을 그저 많이 모은다고 해서 좋은 것은 아니며 오히려 데이터를 수집하는 정책과 실제로 개선하려는 generalist policy가 서로 상호작용해야 한다는 것을 밝혔습니다. 그래야 exploration이 generalist의 prior knowledge를 활용할 수 있고, 동시에 수집된 데이터가 generalist가 실제로 방문할 trajectory distribution에 정렬될 수 있다고합니다. 로봇 학습용 데이터의 핵심은 실제로 그 policy가 망가질 법한 상태까지 포함한 policy-aligned data여야 한다고 합니다. Contribution으로는 autonomous post-training 파이프라인, RL generated data에대한 systemic study, 또 결과에 대한 comprehensive empirical validation입니다.
Methods
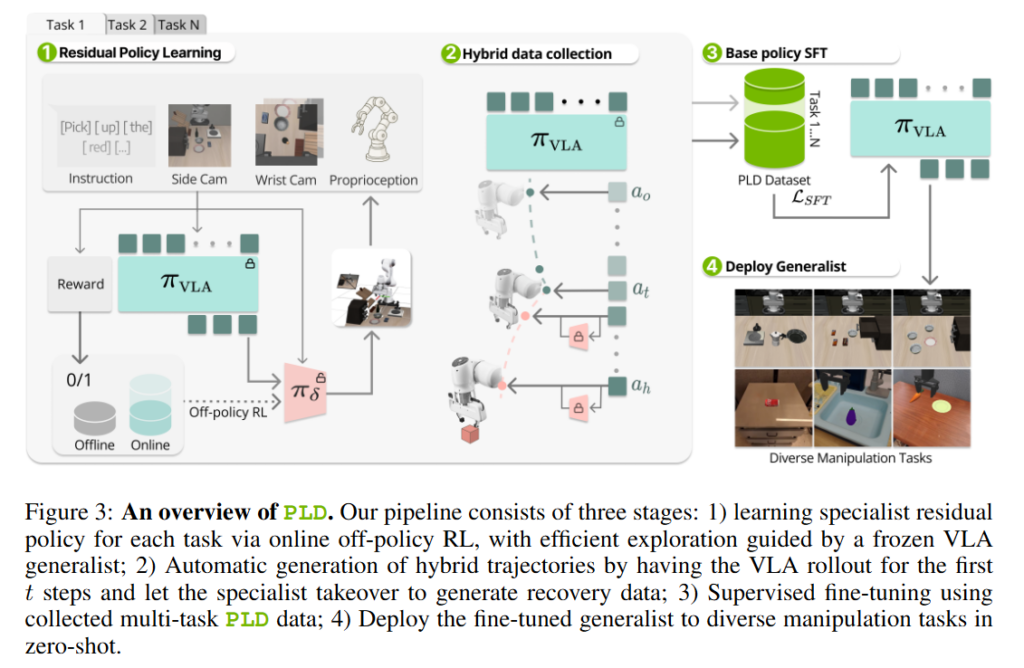
전체적으로는 보시는것과 같이 Probe, Learn, Distill 3stage로 구성돼있습니다. 저자들은 결국 인간 수집으로만 구성된 데이터가 VLA의 한계라고 보고, 데이터 생성 방식으 바꾸는 점에 힘을 줬고, 더 나아가 어떻게 SFT를 통해서 distill 할것인가 까지 보시면 될 것 같습니다. 핵심은 policy가 실제로 실패하는 상태를 중심으로 데이터를 생성하고, 그 데이터를 다시 policy에 반영하는 self-improving 구조입니다. 따라서 Base policy -> failure 탐색 -> recovery 데이터 생성 -> base policy 개선으로 이루어진다고 생각하시면 될 것 같습니다.
Specialist Acquisition vida Residual RL (Probe)
저자들은 먼저 기존 Vision-Language-Action (VLA) 모델을 개선하는 방식 자체에 근본적인 문제가 있다고 보았습니다. 일반적으로 VLA를 향상시키기 위해서는 더 많은 인간 시연 데이터를 수집하거나, 강화학습을 통해 정책을 직접 개선하는 접근이 사용됩니다. 그러나 저자들은 이 두 가지 방법 모두 실질적인 한계를 가진다고 지적했습니다.
먼저, 인간 시연 데이터는 고품질이지만 수집 비용이 매우 크고, 무엇보다도 실제 로봇이 실패하는 상태를 거의 포함하지 않는다는 문제가 있습니다. 반대로 강화학습을 사용하면 이러한 실패 상태를 포함한 다양한 데이터를 생성할 수 있지만, 로봇 조작 환경에서는 보상이 sparse하고 탐색이 어렵기 때문에 학습이 매우 불안정하며, 실제로는 많은 샘플을 요구합니다. 또한 RL로 학습된 정책은 기존 VLA와 행동 분포가 달라지기 때문에, 이를 그대로 supervised learning에 활용하기 어렵다는 문제가 존재합니다. 따라서 저자들은 residual reinforcement learning 구조를 선택했습니다.
저자들은 기존에 학습된 VLA policy를 그대로 유지한 상태에서, 그 위에 추가적인 policy를 학습했습니다. 이때 학습되는 policy는 기존 행동을 완전히 대체하는 것이 아니라, 기존 action에 더해지는 보정값(residual)을 출력합니다. 따라서 최종 action은 base policy의 출력과 residual policy의 출력이 합쳐진 형태로 결정됩니다. 기존 policy를 완전히 바꾸는 대신, 이미 학습된 행동 패턴을 유지하면서 부족한 부분만 보완할 수 있기 때문에 이미 다양한 행동 prior를 학습하고 있는 foundation policy의 성능을 무너뜨리지 않는다고 합니다.
저자들은 이 residual policy를 단순한 보조 정책이 아니라 specialist라고 정의했습니다. 이 specialist policy는 전체 상태 공간에서 최적의 행동을 수행하는 것이 아니라, 특정 failure region에서만 작동합니다. Base policy가 잘 수행하는 영역에서는 그대로 두고, 실패하거나 불안정한 영역에서만 개입합니다. 저자들은 residual policy가 항상 action을 보정하는 방식이 아니라, trajectory의 중간 어느 시점에서든 base policy를 대신하여 control을 이어받을 수 있도록 학습 takeover 방식으로 학습했다고 하빈다.초기 상태에서부터 RL을 적용하는 방식은 실패 상황을 제대로 다루지 못하지만 takeover가 가능하도록 하면, 실제 실패 상황을 직접적으로 다루는 정책을 학습할 수 있습니다. 또한 저자들은 이 residual policy를 학습할 때 복잡한 reward shaping을 사용하지 않았습니다. 대신 성공 여부만을 기반으로 한 sparse reward를 사용했습니다. 이는 reward 설계에 의존하지 않고도 충분한 성능을 낼 수 있다는 점을 보여주기 위함이며, 동시에 다양한 task에 일반적으로 적용 가능한 구조를 유지하기 위한 선택이라고 합니다. 이 residual policy는 최종 fine tuning을 위한 데이터 생성용 탐색기(probe)라고 생각하시면 됩니다.
Distribution aware data collection
저자들은 VLA 성능 향상의 본질이 모델 구조가 아니라, 어떤 데이터로 학습하느냐에 달려 있다고 주장합니다. 특히 기존 데이터 수집 방식이 실제 환경에서의 실패 상황을 충분히 반영하지 못한다는 점을 강조하면서 기존 데이터의 한계를 세 가지로 구분했습니다. 첫 번째는 인간 시연 데이터입니다. 이 데이터는 대부분 성공적인 trajectory로 구성되어 있기 때문에, 모델은 실패 상황에서 어떻게 행동해야 하는지를 학습할 수 없습니다. 두 번째는 RL expert trajectory입니다. 이 데이터는 최적의 경로를 따르기 때문에 다양성이 부족하고, 실제 VLA가 수행하는 행동 분포와도 맞지 않습니다. 마지막으로 base policy rollout은 실제 deployment 상황을 반영한다는 장점이 있지만, 실패 이후에 이를 회복하는 행동을 포함하지 못합니다.
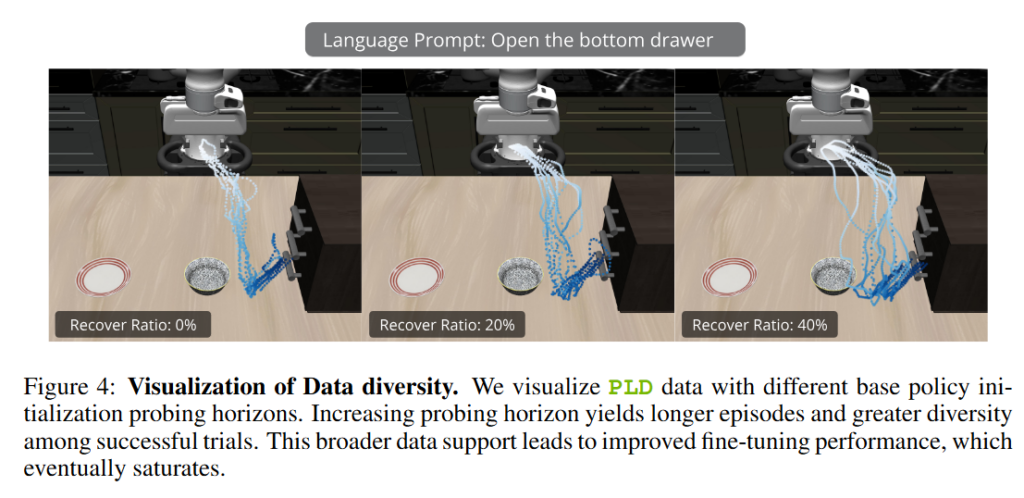
이러한 문제를 해결하기 위해 저자들은 base policy와 앞서 학습한 residual policy를 결합한 hybrid rollout 방식을 제안했습니다. 먼저 base policy를 사용하여 trajectory를 생성합니다. 이는 실제 deployment 상황에서 policy가 방문하는 상태 분포를 그대로 반영하기 위함입니다. 이후 특정 시점에서 residual policy가 개입하여 control을 takeover하고, 그 상태에서부터 성공까지 trajectory를 이어갑니다. 이를 통해 생성되는 데이터의 분포가 실제 deployment 상황과 일치하고 하나의 trajectory 안에 실패와 복구 과정이 동시에 포함되어 기존 데이터로는 얻을 수 없는 유형을 얻는다고 합니다. 저자들은 probing horizon을 조절하여 데이터의 다양성을 확보했습니다. 너무 짧으면 충분한 recovery behavior를 담지 못하고, 너무 길면 데이터의 다양성이 감소하는 문제가 있기 때문에 적절한 균형이 필요했다고 합니다. 이렇게 얻은 데이터로 다시 base policy를 fine tuning해 발전된 generalist를 얻게됩니다.
Experiments
저자들은 제안한 PLD의 효과를 데이터 생성 방식이 실제로 VLA의 일반화 능력과 failure recovery 능력에 어떤 영향을 미치는지를 검증하는 방식으로 실험을 설계했습니다. PLD를 통해 얻은 데이터가 실제로 좋은 데이터인지, 왜 좋은지, 어떤 요소가 핵심인지와 더불어 당연하지만 real environment에서의 실험도 진행했습니다.
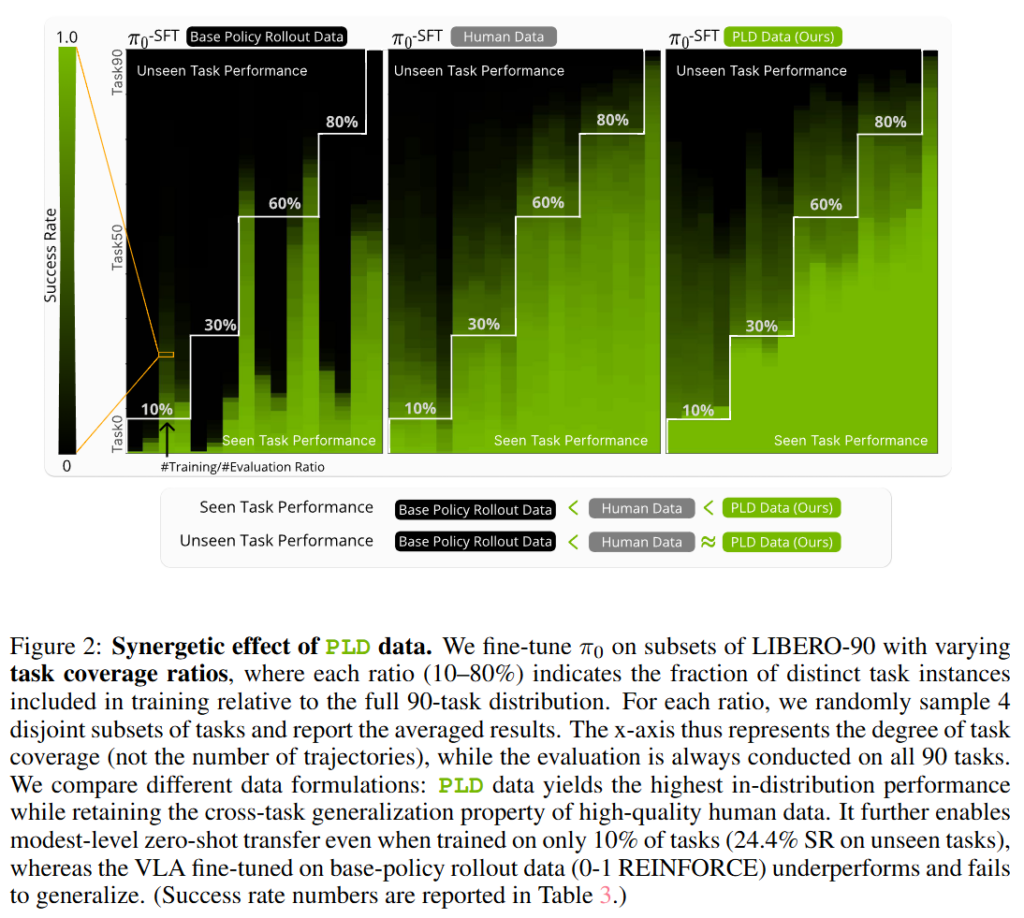
Libero 90에서 10%부터 80%까지의 일부 task만 학습해 전체 Libero-90으로 평가한 결과입니다. 오른쪽으로 갈수록 더 많은 데이터 coverage로 학습을 한 것이고, 색이 밝을수록 SR이 높다고 보시면 됩니다. 흰색 구분선 아래가 Seen task에 대한 성능, 위가 unseen task에 대한 성능입니다. 이를 통해서 PLD 데이터가 human 데이터에 비해 in distribution 성능이 높고, unseen task에 대해서도 유사한 성능을 보이는 것을 알 수 있습니다.
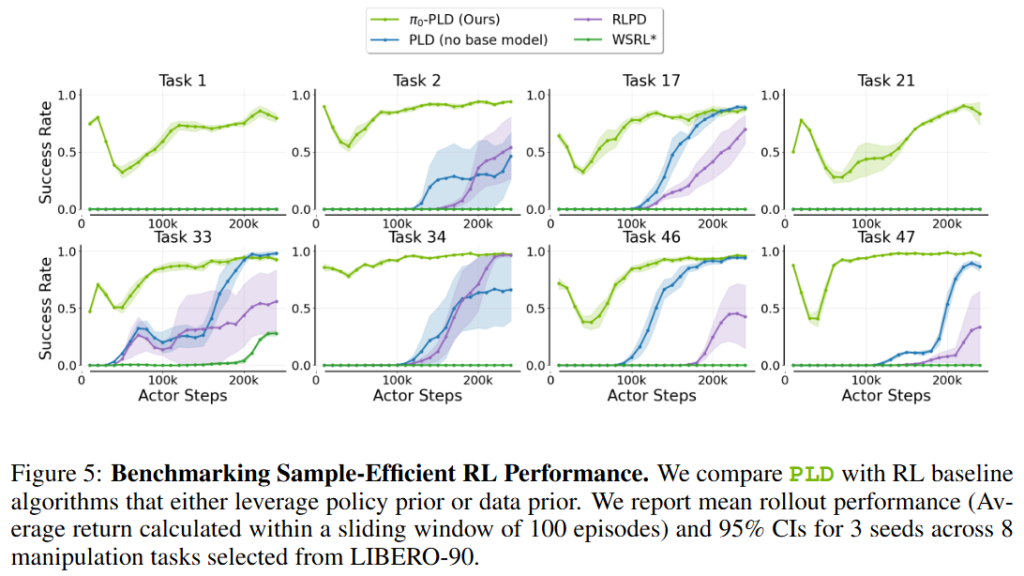
저자들은 policy 자체의 RL 방법론들과 비교를 진행했습니다. 흔히 쓰이는 WSRL과 RLPD와 더불어 base model 없이 PLD만 사용한 경우로 구분지었는데, policy를 학습하려는 목적의 RL과 데이터를 생성하려는 목적의 RL의 성능 차이를 확인할 수 있었다고 합니다. 특히 convergence가 불안정한 모습과 sample efficiency가 낮은 한계를 극복하면서 SR을 높일 수 있었다고 합니다. 또 아래 table1과 같이 LIBERO 벤치마크 기준으로 상당한 성능 향상을 볼 수 있었다고 합니다.
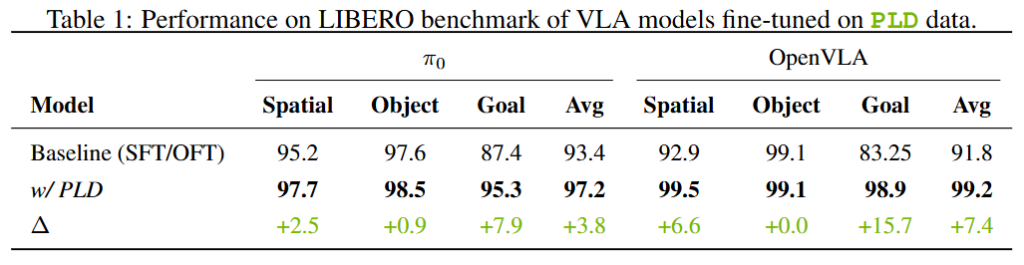
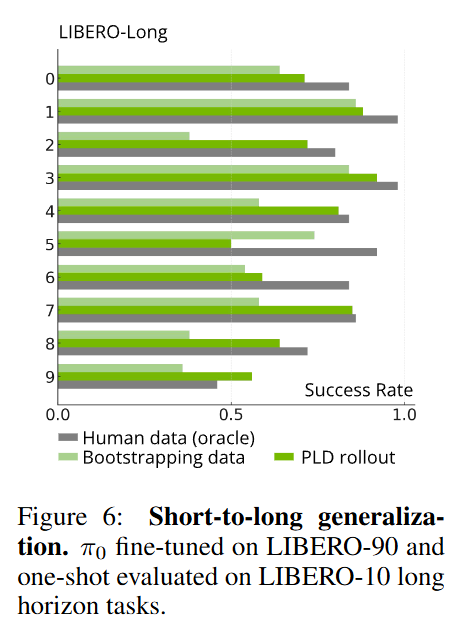
figure 6에서는 long task로 갈 떄의 성능 collapse를 막아주는 실험에 대한 내용입니다. Libero 90 데이터로 finetue된 policy를 LIBERO-10 long에서 one-shot evaluation했을 때 short task로만 학습했음에도 불구하고 long task에서 bootstrapping보다 성능이 좋고 human data로 학습한 경우 보다도 좋은 모습을 보여주는 경우도 존재합니다. Short trajectory들만 가지고도 local recovery를 통해 long task로 학습한것과 같은 모습을 볼 수 있습니다.
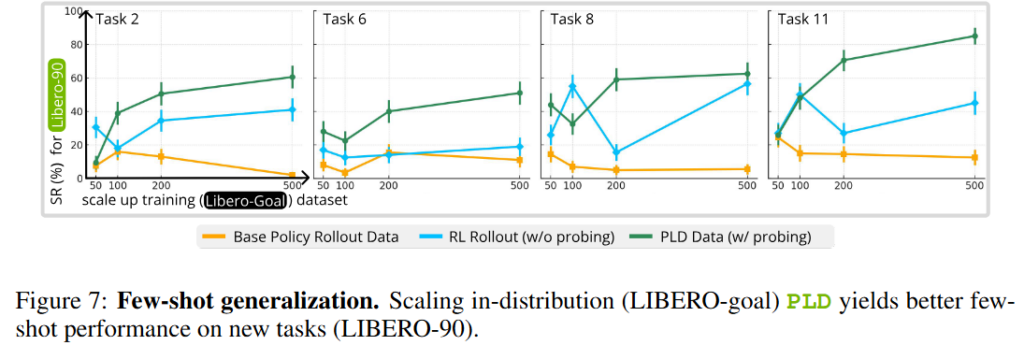
다음은 few shot generalization에 대한 내용입니다. LIBERO-goal에서 취득한 데이터로 학습해 LIBERO-90에서의 few shot generalization능력을 실험했는데, PLD를 거쳐 생성한 데이터로 학습한 policy가 항상 우위를 점할 뿐만 아니라, source task에서의 데모 수가 늘어날수록 선형적으로 성능이 오르는 것을 볼 수 있었다고 합니다.
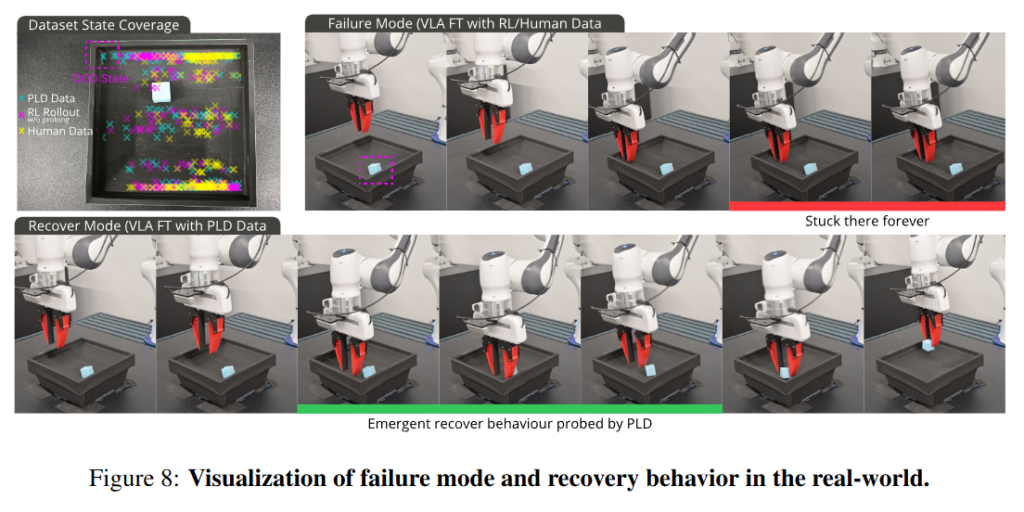
Figure 8은 데이터의 품질이 얼마나 optimal 한지보다 얼마나 policy의 distribution과 잘 정렬됐는지에 따라 결정된다는 실험입니다. RL과 human 데이터는 로봇이 실제로 작동하면서 마주하는 observation의 분포를 제대로 담지 못해 여전히 stuck there forever 현상이 발생하지만 PLD 데이터를 통해서는 recover 하는 모습을 볼 수 있습니다.

Figure 10은 다양한 데이터 source를 보여주며 실제로 어떤 데이터들이 수집되는지를 보여줍니다. 기존의 policy는 한 번 틀어지면 복구할 수 없는 경로로 계속 빠지고, RL Rollout 데이터는 shaping된 trajectory로만 가는 것을 볼 수 있습니다. PLD의 학습데이터로 SFT된 정책의 경로들을 보면 확실히 error correction을 시도하는 것을 볼 수 있습니다.
Conclusion
현재 제가 생각하는 것과 컨셉이 유사한데, 어느 부분을 신경써야 할지에 대한 인사이트를 얻을 수 있었던 것 같습니다. 다만 Large scale데이터로 학습한 모델을 finetuning 하는것과 작은 모델을 scratch부터 학습하는 것은 다르기 때문에 어떤 결과가 나올지 궁금합니다. 다만 RL을 직접 하는것과 failure recovery를 하는것과의 차이를 잘 다루고, failure 상황에서 어떤 recovery 데이터를 만들것인지, 어떻게 failure detection을 할것인지는 정말 중요한 문제인 것 같습니다.
영규님 좋은 리뷰 감사합니다.
로봇 관점과 사람 관점에서의 좋은 데이터가 다를 수 있다는 접근 방식이 흥미롭습니다. 해당 논문은 base policy를 두고 residual policy를 통해 이를 보정할 수 있도록 하는 방식을 제안하였다고 이해하였습니다. 해당 논문과 관련하여 몇가지 궁금한 점이 있습니다.
먼저, 해당 논문의 저자들은 failure 탐색한 뒤 recovery 데이터를 만들어 residual policy를 학습하고 이를 통해 base policy를 개선하는 방법을 제안하였는데, 그렇다면 저자들은 failure 케이스의 데이터가 좋은 데이터라고 결론을 내린 것 일까요? 제가 논문을 이해하였을 때는, residual policy의 역할 때문에 failure 케이스 데이터가 좋다고 판단한 것 같은데, 저자들의 주장인 로봇 관점의 좋은 데이터가 사람의 관점과 다를 수 있다는 게, 다시 사람입장에서 특정 역할을 위한 데이터인 것 같아서 이에 대한 영규님의 의견이 궁금합니다.
또한, 어느 시점에서든 base policy를 대신하여 control을 이어받을 수 있도록 학습 takeover 방식으로 학습된다고 하셨는데, 그렇다면 그 결정은 어떻게 이루어지는 지 궁금합니다. residual policy를 학습하는 것으로 이해하였는데, 이 두 policy를 컨트롤하는 policy가 또 있는 것 일까요?
마지막으로, 해당 논문의 success rate 평가 시 성공 기준이 궁금합니다. 중간에 실패해도 최종적으로 성공하면 되는 것 일까요? 혹은 중간에 의도적으로 작업을 실패하도록 하여 이에 대한 recovery 능력은 따로 평가하지 않는 지 궁금합니다.
안녕하세요 승현님 댓글 감사합니다.
저자들이 정의한 문제 (failure recovery)에서 좋은 데이터란 policy가 inference 할 때 마주하는 failure observation에 대한 성공 케이스를 담은 데이터입니다. 로봇 관점의 좋은 데이터가 사람의 관점과 다른 이유는 사람이 직관적으로 행동하는대로 로봇이 정확히 움직이지 않기 때문에 로봇의 inference시의 순간과 가장 align된 데이터가 아니기 때문입니다.
takeover 방식은 최종 action 출력값이 항상 a = a_base + a_residual 형식인데, base policy가 fail하는 구간에선 강화학습으로 학습한 a_residual의 보정값이 더 유의미한 값이 됩니다. 이 순간을 takeover하는 순간으로 생각하시면 될 것 같습니다. residual은 항상 돌아가고있습니다.
SR은 binary하게 goal을 만족했는지 여부로만 판단합니다. failure의 경우는 의도적으로 작업을 실패하게 하는것이 아니라 figure8처럼 inference시에 무한 루프에 빠지는 경우를 failure로 정의하고 그 상태에서 벗어나는 것을 recovery로 정의합니다.
안녕하세요 영규님 좋은 리뷰 감사합니다.
OOD 문제로 인한 compounding error의 문제를 residual policy로 해결하는 논문이라고 이해했습니다. 제가 정확히 이해를 못한 것일 수도 있어서 몇가지 질문 드립니다.
1) Human teleoperation data에서 failure case 가 없어서 단점이라는 말이 잘 와닿지가 않네요. failure case가 task를 완전히 실패하는 case를 말하는건가요 아니면 경로가 noisy한 경우를 말하는 건가요?
2) residual policy를 학습할 때 label 값은 기존 policy의 trajectory인가요? residual policy가 어떻게 학습 되는지 궁금합니다. 조금 풀어서 설명해주실 수 있나요?
안녕하세요 인하님 댓글 감사합니다.
1) failure case 는 모델 inference 중 무한 루프에 빠지는 현상으로 정의했습니다. (figure 8 참고 부탁드립니다) Failure 지점까지 모델의 inference를 진행하다가 거기서 빠져나오는 양상의 데이터가 failure recovery에 적합한 데이터인데, 사람은 그 순간을 재현하기 힘들기 때문에 failure case와 덜 align 됐다고 생각하시면 됩니다.
2) residual policy는 강화학습으로 학습됩니다. Label이 없고 trial에 따른 reward로만 학습됩니다. Base policy가 실행되면서 residual policy는 계속 고정값을 출력하는데, (a = a_base + a_residual) 해당 액션에 대한 reward가 최대로 되도록 학습하면 다양한 failure 상황에서 빠져나올 수 있는 보정값을 출력할 수 있도록 residual policy만 학습이 됩니다. 이렇게 학습한 policy를 통해 rollout하면서 데이터를 생성합니다.
안녕하세요, 영규님. 좋은 리뷰 감사합니다.
리뷰를 보면서 RL을 활용해 데이터를 생성하고 학습하는 방식이 인상 깊었습니다.
한 가지 궁금한 점은, 이 방법이 사람 시연이 아닌 policy rollout 기반이라면 결과적으로 trajectory가 사람 기준이 아니라 로봇의 dynamics나 embodiment에 더 잘 정렬된다고 볼 수 있을지입니다.
나아가 이러한 방식이 특정 로봇의 embodiment에 대한 최적화로 이어질 수 있을지도 궁금합니다.
리뷰 감사합니다.
안녕하세요 기현님 댓글 감사합니다.
저자들은 사람 시연이 아니라 policy를 실제로 inference 하면서 마주할 수 있는 실패지점에서 유의미한 데이터를 모으자는 핵심 아이디어를 가지고 문제를 해결했습니다. 실험 결과들이 전부 policy rollout 기반의 데이터가 inference 상황과 align된 데이터이기 떄문에 특정 embodiment와 policy의 실제 작동과 더 잘 정렬된다고 말하고있습니다.
안녕하세요 영규님, 좋은 리뷰 감사합니다.
1. base policy -> residual policy의 takeover에 대한 시점이 언제인가요?
2. offline data와 online data의 차이가 무엇인가요?
안녕하세요 재찬님 댓글 감사합니다.
1. takeover 시점은 episode 전체 length 기준으로 사용자가 정의한 특정 비율 ( 저자들의 task의 경우 0.6에서 optimal한 성능을 보였다고 합니다) 내에서 랜덤으로 정해집니다.
2. offline data는 base policy의 성공 rollout들로 구성됩니다. SAC 학습을 initialize하는 과정에서 critic을 먼저 학습시키는데 사용되며, 이는 critic이 성공하는 상황에 대한 scoring을 할 수 있도록 하기 위해서입니다. 이후에 exploration을 진행하면서 online 데이터를 수집하고 actor 와 critic을 업데이트 하는데, 업데이트 할 때 offline data를 online data와 1:1로 샘플링하여 base policy에서 학습한 지식을 최대한 유지하도록 유도하는 데이터로도 사용됩니다.