안녕하세요!
오늘은 지난주에 이어 stable diffusion 기반 이미지 생성에서 구조적인 조건을 효과적으로 반영할 수 있게 해주는 대표적인 네트워크인 ControlNet에 대해 리뷰해보겠습니다!
그럼 리뷰 바로 시작하겠습니다!
Intro
stable diffusion은 텍스트 프롬프트만으로 그림을 생성하는데 유용합니다. 하지만 사용자가 이 pose로, 이 윤곽선을 따라 와 같은 공간적인 제어(spatial conditioning controls)를 하고싶을 때는 이를 반영하지 못하는 한계가 있습니다. ControlNet은 바로 이 문제를 해결하기 위해 나온 구조입니다.
ControlNet은 이미 잘 학습된 Stable Diffusion 같은 대형 생성 모델을 망가뜨리지 않으면서 스케치나 엣지 같은 구조정보를 입력으로 받아 원하는 형태로 이미지를 더 정확하게 생성해주는 방법입니다.
그럼 이러한 방법이 왜 필요할까요? 기존의 text-to-image모델은 프롬프트만으로 이미지를 생성하죠!
하지만 이런 프롬프트만으로는 물체가 어디에 위치해야하는지, 윤곽선이 어떻게 생겼는지와 같은 것을 정확히 제어하기가 어렵습니다.
예를 들어 부억에서 요리하는 여자 라고 적더라도 생성형 모델이 여자의 팔이나 방향, 주방 구조까지 정확하게 맞춰주지는 못합니다. 이에 따라 저자들은 텍스트 프롬프트 말고도 엣지 맵이나 segmentation 마스크 같은 추가적인 구조 조건 이미지를 넣자고 제안합니다.
이 ControlNet의 아이디어는 간단합니다. 먼저 기존 대형 diffusion모델을 lock하는 것 입니다. 여기서 lock한다는 말은 기존의 pretrained 모델 파라미터를 그대로 고정한다는 의미 입니다.
그럼 왜 그냥 기존 Stable Diffusion을 학습시키는 방식으로 접근하지 않았을까요?
그 이유는 stable diffusion같은 모델은 이미 엄청난 양의 데이터로 잘 학습되어 있는데, 특정 조건(엣지,포즈 등)에 맞추기 위해 전체 모델을 그냥 다시 학습하면 기존의 성능이 망가질수 있고, 또 작은 데이터셋에서는 과적합이 일어나는 등의 이미 잘 학습된 일반적인 이미지 생성 능력을 잃을 수도 있게 됩니다. 그래서 저자들은 기존 모델을 보호하고 control만 안전하게 추가하는 방향을 선택합니다!
두번째 아이디어로는 복사본(trainable copy)을 만들어 조건 제어만 학습합니다. 기존 모델은 고정해 두고 그 구조를 복사한 학습 가능한 가지를 하나 더 둡니다.
그럼 이 복사본이 조건을 입력 받아서 원래 모델의 강력한 표현력을 활용히면서도 새로운 제어 능력을 배우게 됩니다. 무슨 말일지 감이 오시나요..?! 예시로 단순하게 말해보자면 기존의 stable diffusion은 이미 그림을 잘 그리는 베테랑 화가이고 controlnet은 선,자세,깊이 등을 알려주는 조교 정도로 이해하면 됩니다.
그럼 이 조교의 역할인 controlnet은 어떻게 stable diffusion에 작용될까요??
여기서 이 모델에 가장 중요한 기술 키워드인 zero convolutions가 등장합니다. 이건 가중치를 0으로 초기화한 conv layer로, 학습 초반에는 실력없는 초보 조교이기 때문에 이 모델이 학습을 막 시작하는 단계에는 새로 붙은 control branch가 원래 Stable Diffusion의 출력을 방해하지 않도록 설정하는 것 입니다.
이렇게 하면 처음에는 원래의 Stable Diffusion 출력 그대로 유지하고 controlnet쪽 영향은 0으로 둔 후 학습이 진행되면서 필요한 만큼 조금씩 영향이 생기게 됩니다. 그럼 새로운 조건 제어 모듈을 붙였을떄 흔히 생기는 문제인 초기에 이상한 노이즈가 들어가거나, 기존의 표현이 깨지거나 학습이 불안정해지는 상황을 줄여줍니다. 즉 처음에는 건드리지 않고 안전하게 조금씩 배우라고 하는 장치인거죠!
ControlNet모듈은 작은 데이터(<50k)에서도 강건합니다. 보통 이런 conditional generation모델은 데이터가 많이 필요한데 사실 이런 edge-to-image, pose-to-image같은 테스크용 데이터는 일반 텍스트-이미지 데이터셋보다 훨씬 작을때가 많습니다. 따라서 저자들은 이 논문을 통해 엄청 크고 좋은 일반적인 생성 모델은 이미 있으니까 그걸 처음부터 다시 배우지 말고 거기에 안전한 제어 모듈만 붙이면 비교적 적은 데이터로도 쓸만한 제어성능을 얻을수 있다고 합니다.
즉 대형 사전학습 모델의 일반 능력을 재사용해서 데이터에 효율적인 조건 제어를 학습한다는 것이 핵심입니다!
또 저자들은 이 방법이 단순히 아이디어 차원에서만 그럴듯~한 것이 아니라 실제로 다양한 조건 입력에서 잘 작동하는지, 작은 데이터셋에서도 안정적으로 학습되는지를 실험으로 확인합니다! 이 부분 마지막에 Experiment에서 살펴보죠!
Method
1. ControlNet
ControlNet의 기본 구조를 살펴보겠습니다.
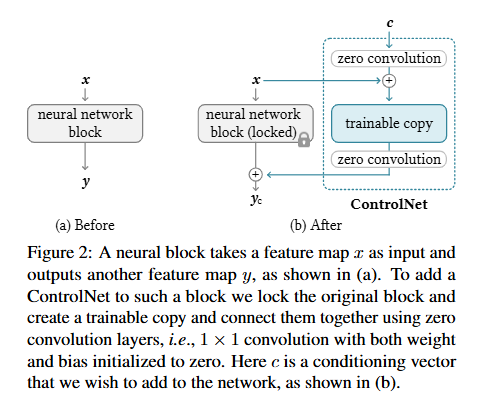
fig2에서 network block은 conv-bn-relu block이나 attention, transformer블록 같은 것들을 의미합니다. 이렇게 어떤 학습된 neural block F(·; Θ)가 파라미나 Θ를 가지고 입력 피처맵x를 다른 피처맵y로 출력한다고 해봅시다. 그럼 일반적인 neural block 식은 아래와 같습니다.

F는 어떤 신경망 블록이고 Θ는 그 블록의 파라미터 입니다 x,y는 각각 입력과 출력의 피처맵 입니다. 즉 입력를 넣으면 파라미터 Θ를 가진 블록 F가 출력 y를 만듭니다.
fig2(b)처럼 원래 블록의 파라미터 Θ는 고정(lock,freeze)하고 동시에 그 블록을 학습 가능한 복사본(trainable copy)으로 복제하여 파라미터 Θc를 갖게 합니다. 이 학습 가능한 복사본은 외부 조건 벡터c를 입력받아 zero convΘ Z를 통과해 lock된 원래 모델과 연결됩니다. 이 controlnet 네트워크는 w와 bias가 모두 0으로 초기화 된 1×1 conv layer로 하나의 controlnet을 만들기 위해 Θz1, Θz2를 각각 갖는 두개의 zero conv(Z)를 사용합니다. 컨트롤넷이 붙은 전체 수식은 다음(2)과 같습니다.
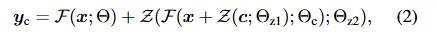
수식(2)를 다시 살펴보면 조건c를 복사본에 넣는 부분은 x + Z(c;Θz1)로 여기서 조건 c가 바로 들어가는게 아니라 먼저 zero conv를 한번 거칩니다.
이때 zero conv는 처음엔 0을 내보내기 때문에 초반엔 사실상 x+0=x가 됩니다. 즉, trainable copy도 처음에는 조건이 섞이지 않은 원래 입력 x만 받는 셈입니다. (따라서 첫 학습 스텝때는 zero conv의 파라미터가 모두 0으로 초기화 되어있기 때문에 당연히 yc=y가 됩니다)
이 복사본의 처리 결과 F(x + Z(c;Θz1))를 다시 zero conv에 통과시킵니다. (식 2의 Z(F(x + Z(c;Θz1));Θz2)) 이렇게 하는 것으로 복사본을 통과하면서 뭔가 출력값을 내더라도 마지막에 zero conv를 다시 한번 더 지나가게 하면서 초기에는 복사본의 출력이 원래 모델에 영향을 주지 못하게 막는거죠!
즉, ControlNet의 핵심은 잘 학습된 블록은 그대로 freeze하고 똑같은 복사본 하나를 학습가능하게 만든 뒤, 그 복사본이 조건정보c를 배우게 하는것 입니다. 이때 처음부터 원래 모델을 망치지 않도록 zero conv로 안전하게 연결하는 것입니다.
2. ControlNet for Text-to-Image Diffusion
그렇다면 이 ControlNet을 이미지 diffusion모델인 stable diffusion에 구체적으로 어떻게 적용되는지를 살펴보겠습니다
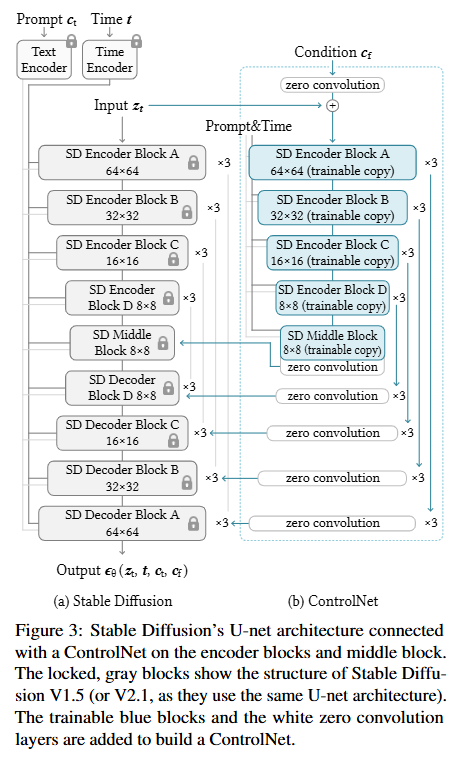
위 fig3그림의 (a)부분처럼 회색으로 된 블록이 Stable Diffusion의 U-Net구조로 encoder(12개), middle block(1개), skip-connected decoder(12개)로 총 25블록으로 구성되어있습니다.
기존의 stable diffusion은 input latent z_t와 프롬프트 c_t, time t를 받아서 U-Net이 noise prediction을 수행합니다 (stable diffusion 내용은 직전 리뷰를 참고해주세요)
그럼 여기서 컨트롤넷을 어디에 붙일까요?
저자들은 그림과 같이 ControlNet을 U-Net의 각 encoder level에 적용했다고 합니다. 정확히는 인코더블록 12개, 미틀 블록1개 에 대해 trainable copy를 만듭니다. 이때 decoder는 복사하지 않고 encoder와 middle만 ControlNet branch를 붙인 이유로, 저자들은 조건정보로 넣어주는 c_f가 기본적으로 공간 구조 정보 이기 때문에 생성 초반에 feature를 만드는 encoder쪽에서 잘 반영되는 편이라 이 인코 쪽에 ControlNet을 붙이는게 자연스럽다고 합니다 또한 여러 해상도 단계에 조건신호를 주입하는것으로 높은 해상도에서는 더 세밀한 local구조, 낮은 해상도에서는 더 거친 global 레이아웃을 함께 반영할수 있다고 합니다.
그렇다면 이 controlnet출력은 어디로 들어갈까요?
위 그림3 (a)의 skip-connected decoder(12개)과 middle block(1개)에 더해집니다.
즉, controlnet은 원래 stable diffusion을 대체하는게 아니라 기존 u-net흐름에 추가적인 signal처럼 얹히는 구조입니다. 쉽게 말하자면 원래 Stable Diffusion이 기본 생성을 담당하고, controlnet이 “이 구조를 따라가라!” 라고 하는 보조 신호담당입니다.
controlnet에 넣어주는 조건 이미지를 간단히 살펴보자면, Stable Diffusion은 512×512 픽셀 공간에서 바로 diffusion을 하는 게 아니라 더 작은 64×64 latent 이미지 공간 에서 진행됩니다. 따라서 조건 이미지(edge map 등)도 크기와 표현공간을 맞추어 주어야 하기 때문에 작은 네트워크 E를 둡니다.
이 네트워크E가 이미지 공간 조건 c_i를 feature 공간 조건 c_f로 바꿔줍니다. (식(4)참고)

여기까지 내용이 많아보이지만 결국 한마디로 말하자면! ControlNet은 Stable Diffusion의 U-net(회색블럭)전체를 다 바꾸는게 아니라 인코더쪽 12개 블록과 middle블록 1개에 trainable copy를 붙이고, 그 출력을 원래 U-net의 skip connection들과 middle블록에 더하는 방식으로 조건정보를 주입하는 것 입니다.
3. Training
그럼 이 ControlNet을 그럼 어떻게 학습하는지 살펴봅시다!
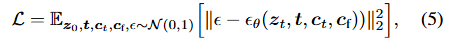
위의 식(5)가 디퓨전 모델의 전반적인 목적함수입니다. 입력이미지 z_0이 주어지면 diffusion알고리즘은 여기에 점진적으로 노이즈를 추가하여 noisy img z_t를 만듭니다. (여기서 t는 노이즈가 추가된 횟수를 말함)
따라서 시간 step t, 텍스트 프롬프트 ct, 그리고 작업별 조건 cf를 포함하는 조건 집합이 주어졌을때, diffusion 알고리즘은 noisy image zt에 추가된 노이즈를 예측하도록 네트워크 ϵθ를 학습합니다.
컨트롤넷은 구조는 새롭긴 하지만 학습 자체는 기존 diffusion의 노이즈 예측 목적함수를 그대로 씁니다.
이때 학습과정에서 저자들은 텍스트 프롬프트 c_t의 50%정도를 무작위로 빈 문자열로 대체합니다. 이렇게 하는 이유는 이 controlnet이 프롬프트에 의존하는게 아니라 입력 조건이미지 자체에서 의미정보를 직접 인식하는 능력을 높혀주기 위함이라고 합니다.
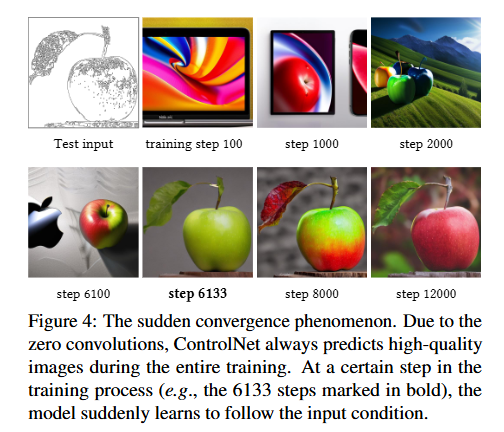
저자들 학습과정에서 sudden convergence phenomenon를 관찰했습니다. 이 현상이 무슨말이냐면!
대부분 보통 모델이 학습되면 결과가 서서히 좋아질것이라고 생각하는데, 이 Controlnet은 처음엔 그냥 고품질 이미지가 나오다가(zero conv이기 때문) 어느 순간 갑자기 조건을 따르기 시작하는 현상을 봤다고 합니다.(그림4 참고)
이러한 현상은 보통 1만번 미만의 optimization step 즈음에서 나타난다고 합니다! 이러한 현상이 왜 생기는지 따로 설명은 없지만 직관적으로 이해해보자면 처음에는 zero conv라서 컨트롤넷 신호가 거의 0이지만 학습이 진행되면서 zero conv와 copy branch가 조금씩 의미 있는 신호를 갖게 되고, 그럼 어느 순간 이 조건정보를 출력에 반영할 만큼 연결강도가 카져서 갑자기 조건을 따르는 현상이 나타난다고 이해했습니다.
Experiment
1. Qualitative Results
먼저 정성적인 결과먼저 살펴보겠습니다.

위의 fig1은 ControlNet이 조건 이미지와 텍스트 프롬프트를 함께 활용해 이미지 생성을 제어할 수 있음을 보여 줍니다. 같은 조건의 입력이라도 프롬프트에 따라 결과 객체의 분위기나 정체성이 달라지며 조건이미지는 주로 구조를 담당하고 프롬프트는 의미와 스타일을 보완하는 역할을 합니다

위의 fig7로 프롬프트 없이도 ControlNet이 스케치나 depth map, edge, segmentagion 등 다양한 조건 이미지에서 의미를 해석해서 결과 이미지를 잘 생성해 낼수 있음을 확인할수 있습니다.
2. Ablative Study
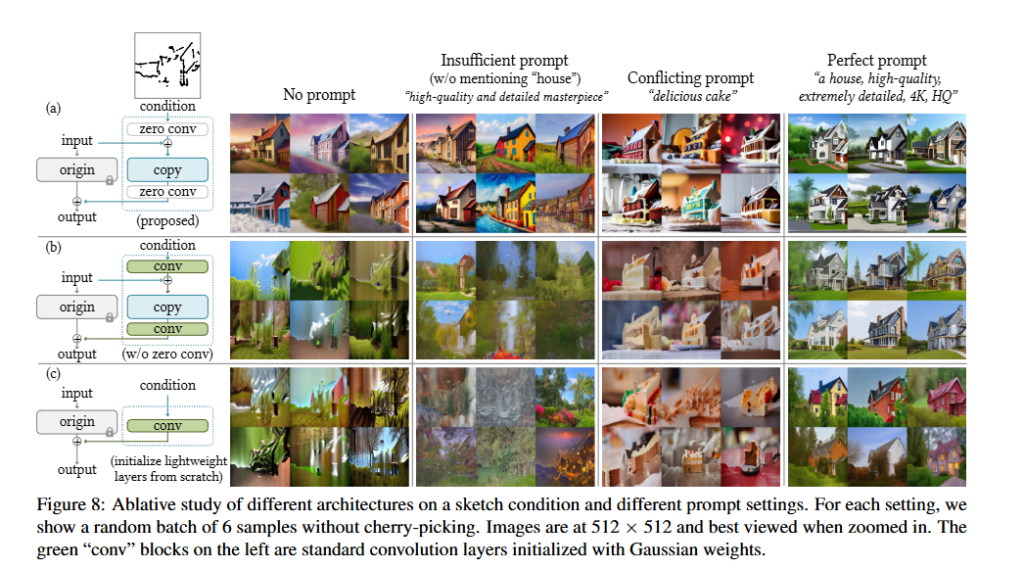
여기서는 이 ControlNet이 잘되는 이유가 진짜 구조 덕분인건지를 확인하는 실험을 진행합니다. 먼저 크게 3가지 구조로 나누어 비교합니다.
위 fig8의 1행(a)는 이 논문이 제안한 구조이고, 2행(b)는 zero conv를 없애고 일반 covn로 바꾼 구조로 연결은 하지만 처음부터 랜덤 초기화 된 일반 conv가 들어갑니다. 마지막으로 3행(c)는 ControlNet-lite라고 지칭하는데 복제된 큰 pretrained block자체를 두지 않고, 그냥 얇은 conv층만 새로 학습 하는 구조입니다. 이렇게 구성한 이유는 굳이 큰 pretrained copy가 필요한지 & 굳이 zero conv가 필요한지 를 확인해 보기 위해서라고 합니다!
이 실험을 위해 프롬프트도 4가지로 나누었습니다.
1열은 No prompt로 아예 텍스트 힌트가 없고 모델이 조건이미지 자체만 보고 의미를 읽어야 합니다.
2열은 Insufficient prompt로 “high-quality and detailed masterpiece”같은 품질이나 스타일만 말하고 이미지의 객체가 집인지, 사람인지와 같은 핵심 내용은 말하지 않는 프롬프트 입니다.
3열은 Conflicting prompt로 스케치가 집처럼 생겼는데 프롬프트는 “delicious cake”처럼 아예 다른 의미를 넣어주어 조건과 텍스트가 충돌하도록 합니다.
4열은 Perfect prompt로 “a house, high-quality, extremely detailed, 4K, HQ”처럼 구조와 의미가 다 잘 맞는 정답 프롬프트 입니다. 이렇게 설정한 이유는 좋은 모델이면 좋은 프롬프트에서만 잘되는게 아니라 프롬프트가 빈약하거나 없어도 조건이미지를 잘 해석해야하기 때문입니다!
위의 fig8결과를 보면 1행 (a)는 4가지 프롬프트 설정에서 비교적 안정적으로 집 형태를 유지하는 것을 확인할 수있습니다. 즉 제안하는 구조가 조건 이미지의 구조적 의미를 강하게 반영한다는 의미로 해석할 수 있습니다.
2행(b)의 결과를 보면 특히 no prompt, insufficient prompt에서 형태 해석이 불안정해지는 것을 확인 할수 있는데, 저자들은 이 부분을 zero conv 없이 시작하면 랜덤초기화 된 연결부가 pretrained backbone에 노이즈를 너무 빨리 주입하게 되어서 원래의 큰 모델이 가지고 있던 좋은 표현이 파인튜닝중에 망가진다고 합니다. 이것으로 zero conv가 pretrained copy를 보호하는 안전장치가 되는것을 확인 할수 있습니다.
3행(c)의 결과를 보면 이 구조도 특히 no prompt와 insufficient prompt에서 약한것을 볼수 있습니다. 이 경우에도 텍스트로 거의 힌트를 안주기 때문에 모델이 조건 이미지 자체를 보고 해석해야하는데 , 이 얇은 conv 몇개 층 만으로는 의미 해석능력이 부족한 것을 확인할 수 있습니다.
3. Extra analysis

또한 위의 Table 2에서는 segmentation 조건을 입력으로 사용했을 때, 생성된 이미지가 원래 segmentation label을 얼마나 잘 복원하는지를 IoU로 평가합니다. 표에서 확인할 수 있듯이, ControlNet이 다른 비교 방법들보다 더 높은 IoU를 보이며 조건을 가장 잘 보존하는 것을 확인할 수 있습니다.\

Figure 10에서는 학습 데이터셋 크기에 따른 성능 변화를 보여줍니다. 데이터가 1k, 50k, 3m으로 증가할수록 생성 결과가 점점 더 안정적이고 자연스러워지며, 적은 데이터에서도 학습이 완전히 무너지지 않는다는 점에서 ControlNet 학습의 안정성과 확장성을 확인 할수 있습니다.