안녕하세요 손우진입니다.
오늘 리뷰할 논문은 따끈따끈한 2026 CVPR ACCEPT된 6D 데이터셋 논문입니다. 극한환경(저조도, 연무환경, 극한의 동적)에서의 데이터셋이고 이를 6D 평가 함으로써 현재 6D 데이터셋의 한계와 극한 환경에서의 전처리(Dehazing, Deblur, Light enhance)기법들이 도움이되는지 분석하는 논문입니다.
데이터셋은 요즘 로봇 분야에서 가장 핫한 스마트 글래스 환경으로 취득하였고 이전 6D 데이터셋과는 다르게 1인칭 시점(Egocentric View)에서 발생하는 극한의 시각적 조건들을 다루는 6D 객체 포즈 추정 벤치마크 논문의, “EgoXtreme: A Dataset for Robust Object Pose Estimation in Egocentric Views under Extreme Conditions”입니다.
이전에 리뷰했던 논문들이 주로 새로운 네트워크나 Refinement 구조를 통해 정확도를 끌어올리는 데 집중했다면, 이 논문은 현재의 최신(SOTA) 모델들이 과연 Real-world의 극한 환경에서도 작동하는가?”라는 객관적으로 검증하기 위한 데이터셋을 제안합니다. 그럼 바로 시작하겠습니다!

introduction
최근 6D 객체 포즈 추정 기술은 정적으로 통제된 환경을 넘어 로봇 매니퓰레이션 이나 AR/VR 등 실제 응용 분야로 그 영역을 확장하고 있습니다. 특히 스마트 글래스는 사용자가 양손을 사용하여 작업을 수행할 때 1인칭 시점의 비전 정보를 지속적으로 파악할 수 있는 강력한 인터페이스로 떠오르고 있습니다. 로봇 데이터셋 취득 또한 글래스를 많이 활용하는것으로 알고있습니다.
기존 6D 포즈 데이터셋(YCB-V, LINEMOD 등)을 떠올려 보면, 주로 조명이 통제된 실험실 테이블 위에 물체를 올려두고 촬영한 정적인 환경입니다. 하지만 스마트 글래스가 실제로 쓰이는 1인칭 현장은 다릅니다. 작업자가 양손에 공구를 쥐고 움직이거나, 연기가 자욱한 화재 현장에서 소화기를 찾기 위해 고개를 빠르게 돌리는 상황을 떠올려 보면. 카메라와 물체의 거리는 너무 가깝고, 물체는 손이나 도구에 가려져 반쪽만 보이기 될 수 있습니다. 머리 움직임 때문에 화면은 흔들리고, 조명 역시 지하실의 헤드램프나 비상구 불빛처럼 불안정하게 계속 변합니다. 스마트 글래스가 ‘두 손을 자유롭게 해 준다’는 엄청난 장점을 가졌지만, 비전 알고리즘 입장에서는 망가진 시각 데이터를 처리해야 하는 극한의 센싱 환경에 내몰린다는 것입니다.
이러한 통제된 실험실과 현실 사이의 간극을 좁히기 위해, 저자들은 가장 시각적 조건이 열악한 3가지 실제 시나리오(산업, 스포츠, 긴급 구조)를 설정하고 직접 1인칭으로 촬영한 데이터셋 ‘EgoXtreme’을 제안합니다.
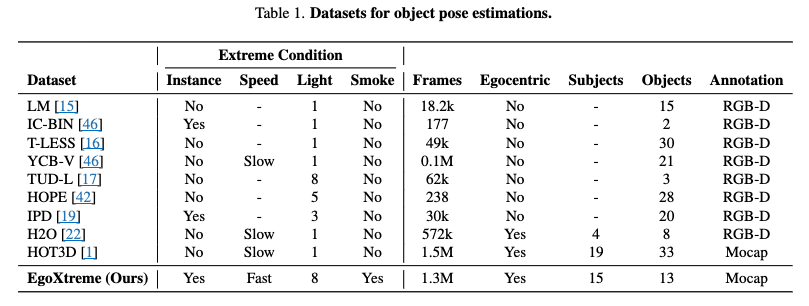
Table 1 은 기존에 6D 벤치마크 데이터셋에 대한 분석입니다. 기존에는 정적인 환경에 제한되어있거나 egocentric한 데이터셋 들이 제한적이였습니다. 또한 극한환경을 모사한 데이터셋은 극히 드물다고 할 수 있습니다
저자들은 이렇게 구축된 EgoXtreme 벤치마크를 통해, 6D 포즈 추정 모델들의 성능을 평가하고 최신 Zero-shot 모델들이 실제 극한 환경에서 얼마나 취약한지 그 한계를 객관적으로 측정합니다. 추가적으로 비전 분야에서 흔히 쓰이는 이미지 전처리 알고리즘을 적용해 이것이 실질적인 도움이 되는지 검증하고, 동적인 환경을 극복하기 위한 Tracking 방식도 종합적으로 분석합니다.
저자들의 핵심 contributions)는 다음과 같습니다.
- 강건한 포즈 추정을 위한 대규모 1인칭 벤치마크 제공: 심한 모션 블러, 동적 조명, 시야 방해 등 극한의 조건이 포함된 다양한 시나리오에서 수집된 최초의 대규모 1인칭 6D 포즈 추정 데이터셋인 EgoXtreme을 공개합니다. 이 데이터셋은 향후 스마트 글래스 응용 분야를 위한 도전적인 벤치마크로 활용될 수 있습니다.
- 포괄적인 베이스라인 분석: 최신 범용 6D 객체 포즈 추정 모델들을 EgoXtreme 데이터셋 상에서 평가하고, 극한의 1인칭 환경이 가지는 한계와 실패 원인(Failure modes)을 분석합니다.
EgoXtream Datatset
EgoXtreme은 사실 스마트 글래스로(Aria)만 비디오 데이터셋은 아닙니다. 6D 정보들도 함께 어노테이션을 해야하기 때문에 세팅은 매우 까다롭게 진행되었습니다. 우선 비디오 시퀀스로 775.5분(약 1.3M 프레임) 동안 수집한 대규모 RGB 비디오로, 학습용(Train 518.8분), 검증용(Val 80.7분), 테스트용(Test 176분)으로 분할되어 제공됩니다. 6D 포즈 모델의 강건성을 평가하기 위해 다음과 같이 3가지 시나리오와 환경 조건(Table 2 참조)을 설계했습니다.

또한 물체들 또한 산업 또는 운동에 쓰이거나 응급키트와 같은 물체들로 총 13개의 객체들로 진행하였습니다.

Scenario details
이 13개의 객체들은 1인칭 시점의 극한 환경을 평가하기 위해 설계된 3가지 시나리오에 배치됩니다. Table 2에서 나타나듯, 각 시나리오별로 물체와 카메라의 이동 속도, 그리고 조명 및 연기 조건이 다릅니다.
- Industrial Maintenance : 드릴, 망치, 렌치 등의 공구를 조작하거나 동일한 조립 블록들을 맞추는 정밀한 작업을 다룹니다. 이 시나리오에서는 작업자의 손에 의한 객체 가림이 발생합니다. 또한, 작업장 환경을 모사하기 위해 일반, 저조도, 중간, 고조도 뿐만 아니라 헤드램프와 플래시라이트같은 동적 조명까지 총 6가지 조명 조건을 적용했으며, fog 발생기를 사용하여 Smoke를 추가해 시야 방해 상황을 구현했습니다.
- Emergency Rescue: 어두운 환경에서 소화기, 구급상자, 플래시라이트 등의 구조 용품을 탐색하고 집어 드는 상황입니다. 카메라의 평균 이동 속도가 0.47m/s로, 이동에 따른 심한 카메라 흔들림을 동반합니다. 조명 조건으로는 일반적인 4가지 밝기 외에 회전하는 경광등과 비상구 조명을 도입했고, 화재 상황을 가정한 연기조건이 포함됩니다.
- Sports : 야구 배트, 테니스/탁구 라켓, 골프 클럽 등을 고속으로 스윙하는 실제 스포츠 환경입니다. 객체의 평균 이동 속도가 1.37m/s인것을 보면 모션 블러(Motion blur)가 많습니다. 이 시나리오는 극단적인 흔들림 자체에 집중하기 위해 연기나 동적 조명 없이 4가지의 기본적인 밝기 조건(Normal, Low, Middle, High)에서만 촬영되었습니다.
Data collection and processing
연기와 조명, 심한 모션 블러 속에서 6D GT를 얻기 위해, 저자들은 외부 빛이 완전히 차단된 실험실에서 진행하였고 두 가지 센서 시스템을 사용하였습니다.
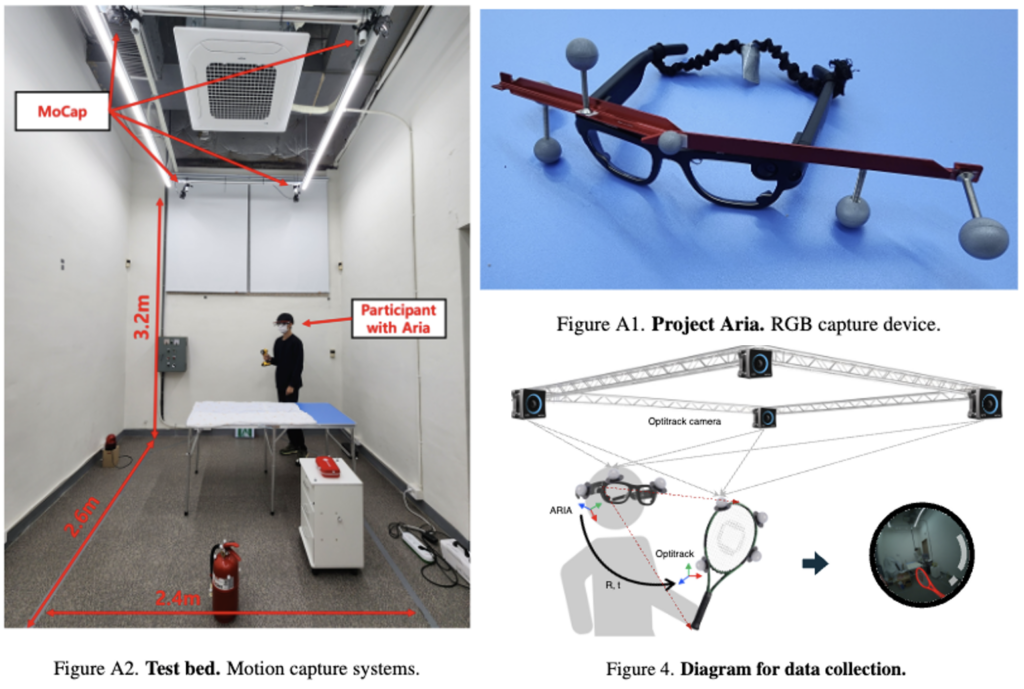
1인칭 시점의 시각적 데이터와 3 시점의 3D 추적 데이터를 확보하기 위해, 1408×1408 해상도의 RGB 카메라(30fps)와 1000Hz 듀얼 IMU가 있는 Project Aria 스마트 글래스를 착용하고 실험을 진행합니다. 또한, 이 스마트 글래스 위에는 7개의 반사 마커가 고정되어 기기 자체의 SLAM 궤적을 지속적으로 기록하게 됩니다. 또한 실험실 천장 모서리에는 120fps로 동작하며 0.2mm의 3D 정확도를 보장하는 4대의 OptiTrack 적외선 모션 캡처 카메라가 설치되어 3D 추적을 수행합니다. 이 모션 캡처 시스템은 스마트 글래스는 물론 실험에 사용되는 13개의 모든 객체에 부착된 Marker clusters의 움직임을 인식하여, 각 물체에 대한 Annotation을 자동으로 계산하였습니다.
실제로 구현하고 세팅하려면 작업 코스트가 엄청들었을것 같습니다..캘부터 동기화( 동기화 같은 부분은 하나의 섹션으로 작성되어 있긴하나 핵심은 아닌것 같아 다루지는 않았습니다. 혹여 궁금하신 부분있으시면 댓글 주시면 감사하겠습니다.)까지 이 방법의 데이터셋 취득은 유리하긴하지만 구현 난이도가 높을 듯 합니다. 그리고 한 가지 의문이 드는것은. 물체에 직접 반사 마커를 부착하고 RGB 영상을 촬영해서, 추후 이 이미지가 모델 평가나 학습에 사용될 때 마커 자체가 시각적 노이즈로 작용하지 않을까 하는 점도 있지만 저자들은 이런부분에서는 추가적인 언급은 없었습니다.
Experiments
저자들은 이렇게 구축된 EgoXtreme 데이터셋을 바탕으로, 실제 SOTA 모델들이 극한 환경에서 얼마나 취약한지, 그리고 이를 해결할 수 있는 방안은 무엇인지 다각도로 실험을 진행했습니다. 모델이 악조건에서 어떻게 무너지는지 명확히 비교하기 위해, 평가 환경은 크게 Standard(일반 조명)와 Extreme(극한 조명 및 연기) 두 가지로 나누어 분석했습니다. 저자들은 RGB 기반의 방법들로만 평가하였고 연기상황같은경우 Depth가 노이즈가 심하여 사용하지 않았다고 합니다. 모델같은 경우는 Zero-shot 6D 포즈 추정 모델들(FoundPose, GigaPose, PicoPose)의 평가 결과입니다.
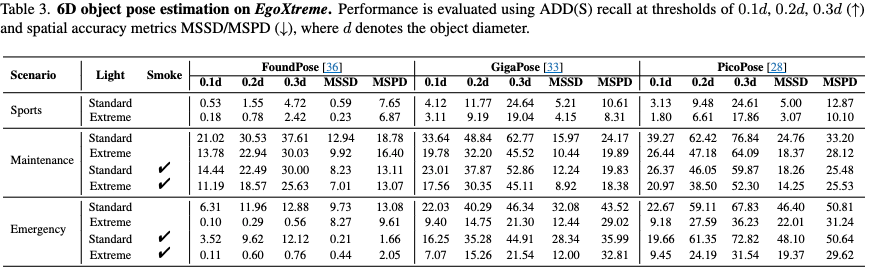
표를 보면 기존 모델들이 실제 1인칭 환경에서 취약하다는게 나타나는 것 같습니다. 우선 Emergency와 Maintenance 시나리오의 결과를 살펴보면, PicoPose의 경우 조명이 Standard 에서 Extreme로 변하자 ADD-0.3d 지표 기준으로 성능이 무려 31.6%p나 폭락했습니다. ADD-0.3d같은 평가지표는 후한 평가 지표임에도 불구하고 성능이 많이 낮은 것을 볼수있습니다. GigaPose 역시 Maintenance에서 Smoke 조건이 추가되자 성능이 9.91%p 저하되는 모습을 보였습니다. 또한 모션 블러가 많은 Sports 시나리오는 거의 예측하지 못하는 결과가 나왔습니다. 특히 FoundPose는 이러한 흔들림 속에서 피처 매칭에 필요한 최소한의 특징점조차 추출하지 못해, 6D 포즈 예측 자체가 완전히 실패하는 빈도가 매우 높게 나타났습니다. 아직까지 6D Task가 굉장히 어렵다는 것을 현실로 검증하였습니다. 특히나 일반화를 주장하는 6D 모델들도 많지만 현실은 그렇지않은 것 같습니다. 또한 보통의 6D pose 는 초기에 2D detection 알고리즘으로 해당영역을 Crop하고 matching하는데 저자들은 GT를 사용해서 평가를 하였다고 합니다. 만약 Detection 까지 End-to-End로 하였다면 성능은 더 바닥이나겠죠.
이런 궁금증들은 Appendix에 담겨있었습니다.
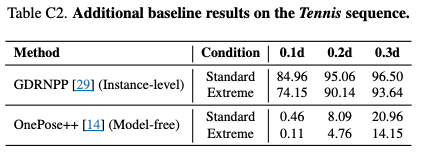
우선 학습 기반의 GDRNPP 모델은 현시점 RGB 기반의 6D 중 SOTA로 불리는 모델입니다. 학습기반이라고 하면 해당 물체에 대한사전적으로 학습을 시키고 추론하는 방법이고 다른 물체는 다루지 못합니다. 이런 학습기반의 성능은 ADD-0.1D 기준(엄격한 평가지표입니다.) standard에서 84.96으로 꽤나 높은 성능을 보였습니다. 또한 극한 환경에서도 74.15로 꽤나 높은 정확도를 보여줍니다. 이런 실험들을 통해서 6D 같은 경우는 학습기반이 가장 신뢰성있고 사용할 수 있다고 판단이 됩니다. 하지만 의문은 이 실험 또한 GT Detection 을 사용했을 가능성이 매우 높은 것 같습니다. 그 이유는 다음 Detection 을 사용하고 zero-shot한 결과를 appendix에서 보여줍니다.
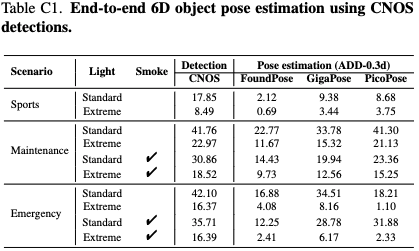
위 표는 Detection 을 사용하고 그 박스를 통해서 zero-shot 모델을 평가 한것인데 탐지 성공률 자체가 급격히 감소합니다. 특히나 sport같은 블러한 이미지가 많은경우에는 더 낮아집니다. 기존 6D Task 에서는 보통의 detection 알고리즘인 CNOS 모델을 사용하는데 이 또한 zero-shot입니다. 학습기반의 Detection을 사용하여 instance level의 평가도 궁금하였지만 그것은 담겨있지않았습니다. 이를 통해서 GDRNPP 또한GT detection 을 사용한 것 같습니다. 물론 환경이 극한환경이란 것에 있지만 6D의 일반화는 현시점 머나먼 길인것 같습니다.
다음으로는 전처리 기반들의 비전 알고리즘이 6D Task에 도움을 주는지 저자들은 실험을 진행하였습니다.
저자들은 이를 검증하기 위해 현재 널리 쓰이는 디블러링(Deblurring), 디헤이징(Dehazing), 그리고 저조도 개선(Low-light enhancement) 기술을 원본 이미지에 전처리로 적용한 후 6D 포즈 추정을 수행해 보았습니다. 결과는 물음표들이 많습니다. 이미지 복원 기술은 6D 포즈 추정에 실질적인 도움을 주지 못했으며, 오히려 성능을 더 떨어뜨리는 결과입니다.
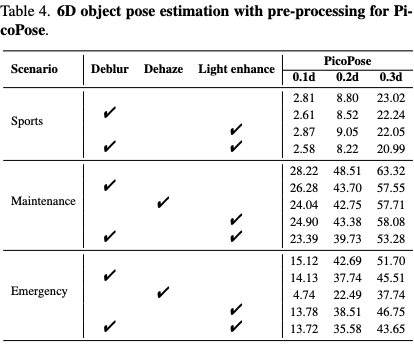
어떤 단일 전처리 기법을 적용하더라도 유의미한 성능 향상은 없었으며, 특히 디블러링과 저조도 개선을 동시에 적용하는 식으로 두 가지 방법을 결합했을 때는 ADD-0.3d 기준 약 5%p의성능 하락이 발생했습니다. 저자들은 불균일하게 퍼져 있는 연기 환경에 디헤이징 알고리즘을 억지로 적용하자 심각한 시각적 노이즈가 발생했고, 그 결과 ADD-0.1d 기준 성능이 낮아졌다고 합니다,. 극단적으로 대비가 심한 저조도 환경에서의 Light enhancement 역시 예측을 더 어렵게 만드는 노이즈를 추가할 뿐이었습니다.
정성적으로 볼 때는 전처리를 이미지가 훨씬 선명하고 깨끗해 보일 수 있습니다.

하지만 6D 포즈 추정은 본질적으로 3D 기하학적 특징을 2D 픽셀 수준에서 찾아 매칭해야 하는 Task라서 그런지 인위적인 것이 노이즈를 준다고 저자는 분석합니다. 사람눈에 잘 보인다고해서 모델 또한 더 잘받아드리는지?에 대한 의문점들에 대한 좋은 예시인것 같스빈다. 하지만 이 또한 Zero-shot 성능입니다. 전처리 알고리즘들 또한 zero-shot 알고리즘이라 성능 하락이 영향이 미쳤을 가능성도 있습니다.
이 논문은 저에게 있어 데이터셋 찍는 방법? 이런 것도 있겠지만, 현시점 6D 모델들의 한계를 명확히 나타내어 주는 것 같습니다.
감사합니다.
안녕하세요 우진님 좋은 리뷰 감사합니다.
이렇게 더더욱 현실적인 모습을 반영한 데이터셋들도 나오고있는데, 논문 주장이 결국 실제 SOTA 모델들이 진짜 현장에서는 잘 동작하지 않더라 라면, 우진님이 미래에 (데이터셋 관련 논문을 작성한다면) 할 연구 방향은 이러한 egocentric한 데이터셋을 만들고싶은건지, 아니면 정제된 상황에서의 clean 한 데이터셋 기반 연구를 하고싶은건지 궁금합니다.
감사합니다.
안녕하세요 인택님 좋은 질문 감사합니다,
작성해주신 내용처럼 현재로서는 제가 직접 Egocentric view 형태의 데이터셋을 구축할 계획은 없습니다. 다만 6D 포즈 추정을 연구하다 보니 휴머노이드나 로봇 조작 기술이 발전함에 따라 ‘과연 1인칭이나 동적인 실제 환경에서도 기존 모델들이 잘 동작할까?’ 하는 의문이 있었는데, 이 논문이 그 객관적인 한계를 데이터로 명확히 증명해 준 것 같습니다.
질문해주신 저의 향후 데이터셋 연구 방향에 대해 답변드리자면, 저는 완전히 정제된 Clean 데이터셋보다는 ‘실제 현장의 악조건을 센서 융합으로 극복하는 데이터셋’ 구축에 포커스를 맞추고 있습니다.
단, EgoXtreme처럼 ‘Sports의 극단적인 흔들림의 라는 상황 자체를 구현하는 데 집중하기보다는, 조명 변화나 시각적 한계를 객관적으로 극복하기 위해 열화상 카메라와 RGB를 결합한 6D 포즈 데이터셋을 구축하는 방향으로 연구를 진행 중입니다.
결과적으로 인택님이 말씀하신 두 가지 방향 중에서는 현실의 악조건을 반영하고 극복하는 데이터셋 쪽에 가깝지만, 그 해결책을 단순히 1인칭 뷰에서 찾는 것이 아니라 다중 센서들(열화상_) 통해 로봇이 실제 환경에서 강건하게 객체를 조작할 수 있도록 만드는 데 목적이 있습니다.
질문 주셔서 다시 한번 감사합니다!
우진님 좋은 리뷰 감사합니다.
연무환경이 포함된, 로봇 작업(?) 상황의 6D 논문이네요..
Table 3의 표를 통해 1인칭 환경에서 취약하다고 하셧는데, exocentric 결과가 따로 있나요?
그리고 스포츠의 경우 Standard 케이스에서 도 성능이 굉장히 낮은 것 같은데, 혹시 왜 이런지 설명이 따로 있었나요?
마지막으로, Table 4에서 Emergency 케이스에서 dehazing을 사용하지 않는 기본 페이스보다 dehazing을 하면 성능이 크게 저하되는 것 같은데 이에 대한 저자들의 분석이 따로 있나요?
안녕하세요 승현님 질문 감사합니다.
Exocentric결과 비교 논문에 직접적인 3인칭 비교표는 없습니다. 다만, 실험에 쓰인 모델들이 이미 3인칭 데이터셋에서 최고 성능을 달성한 모델들입니다. 이들이 1인칭 환경에서 무너진 것 자체가 난이도의 차이보이는 것이 아닌가 싶습니다. 또한 Sports 시나리오의 낮은 성능은 빠른 이동 속도로 인한 모션 블러와 물체가 잘리는 뷰로 인해 모델이 매칭에 필요한 최소한의 특징점조차 추출하지 못해 예측 자체에 실패하게 됩니다. 마지막으로 Emergency에서 Dehazing의 악영향 같은 경우 분석은 따로 없으나 아마도 dehazing 처럼 도메인에 따라 성능이 다르기때문이지 않을까 생각이 듭니다 또한 Zero-shot 모델들이라 학습기반의 dehazing알고리즘과의 비교가 없어 저희가 생각한것과는 다르게 나온 것 같습니다
다시 한번 좋은 질문주셔서. 감사합니다!