안녕하세요 최인하입니다. 이번주 리뷰도 저번주와 비슷하게 Robot learning에 사용되는 Demonstration Data의 Quality에 관련된 논문을 가져왔습니다. Behavior Cloning 방식의 등장으로 robot learning 방식에서도 Data driven 방식이 생기고 그로 인해서 방대한 데이터의 양이 등장하는 추세에서 과연 policy를 학습하는데 있어서 Quality가 중요할까 Quantity가 중요할까?에 대한 연구를 진행하는 논문이 최근들어서 많이 등장하는 것 같습니다. 저번주에 리뷰한 논문은 좋은 데이터의 기준을 state와 action pair의 mutual information을 고려하여 로봇의 행동 관점에서 데이터의 quality를 정의했다면, 이번에 리뷰하는 논문은 과연 어떤 데이터가 policy의 성능 향상에 직접적인 영향을 미치는가? 를 기준으로 quality를 정의합니다. 리뷰 시작하겠습니다.
논문에서는 Influence function을 사용하여 data curation을 진행합니다. 하지만 Influence function을 로봇 demo에 단순하게 적용할경우 신호가 매우 noisy해지고, 중복된 state-action pairs를 고르는 경향이 있어서 충분한 state space를 커버하지 못한다는 단점이 있다고 합니다. 따라서 논문에서는 이러한 단점을 극복하고자 QoQ 제목과 같은 Quality over Quantity 방법을 제시합니다. 이 방식은 두 가지 기법을 통하여 로봇 demo에 효과적으로 적용되었는데요. 두 가지 방법은 다음과 같습니다.
- 각각의 state-action pair의 influence를 전체 validation data에 대해서 평균을 내는 것이 아니라 가장 관련성이 높은 validation state-action pair에만 집중합니다. 즉 validation sample들 중에서 최대 influence 값으로 측정합니다.
- 논문은 trajectory-wise curation을 수행합니다. 위에서 말한 방식으로 같은 trajectory 안에 있는 state-action pair의 influence score를 모은 후 집계 점수를 기반으로 높은 quality의 trajectory를 선택하는 방식이죠.
논문은 위와 같은 방식으로 Robomimic sim에서는 23.2% real env에서는 30% 정도의 성능 향상을 보였다고 합니다.
Related work
Related work에서 중요한 부분만 가져오면 기존의 Influence function을 사용했던 Robot data curation 연구들은 state-action pair쌍의 Influence funtion score를 전체 validation data에 대해서 평균을 냈다고 합니다. 하지만 이런 방법은 validation data의 task와 실제 평가하고자 하는 episode data의 task가 다를 수 있기 때문에 score 측정에 불안정성을 더한다고 합니다. 따라서 논문은 위에서 언급한 것 처럼 관련성이 높은 validation state-action pair에만 집중하여 최대 influence score 값으로 측정합니다.
Influence funtion
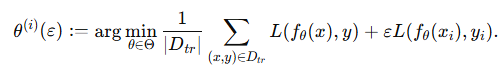
Loss function과 training demo dataset이 주어졌을 때 특정 데이터에 대한 가중치 ε을 부여했을 때 이를 최소화 하는 model parameters는 위와 같이 정의할 수 있습니다.
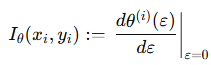
이때 Influence funtion은 특정 데이터 (x,y)로 인해 model parameters가 어떻게 변화하는지 나타냅니다. 따라서 맨 위에 설명한 식을 ε으로 미분하면 되는거죠.
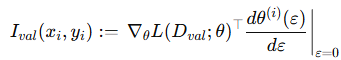
논문에서는 위에서 설명한 것 처럼 validation dataset을 가지고 training demo의 state-action pairs를 평가하므로 위와 같이 정의할 수 있습니다. 이렇게 정의된 이유는 chain rule을 사용했기 때문인데요. validation loss를 미분 했을 때 model parameters는 ε의 함수이므로 chain rule을 적용하면 위와 같은 식이 성립됩니다.
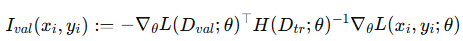
이제 맨 처음 소개했던 식을 ε으로 미분을 진행하고 풀어서 쓰게 되면 위와 같은 식이 나오게 됩니다. 헤시안 행렬을 이용해서 표시했는데요. 하지만 헤시안 행렬은 model parameter가 무수히 많은 model에서 계산량이 기하급수적으로 늘어나기 때문에 (이차 미분을 진행하기 때문에) 논문에서는 [Estimating Training Data Influence by Tracing Gradient Descent] 논문에서 나온 방식을 이용해서 아래와 같이 1차 근사로 표기했다고 합니다. 위의 언급된 논문은 따로 읽어 보려고 합니다.
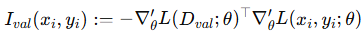
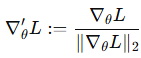
어려운 수식이지만 말로 정리해서 말해보면 쉽습니다. 결국 training demo data의 action-state pair가 validation loss에 얼만큼 영향을 미치는가?를 보고 싶은 것입니다. 즉 논문에서 강조하는 data quality의 척도는 pretrained된 policy에 얼만큼의 기여를 하는가?입니다.
Quality over Quantity (QoQ)
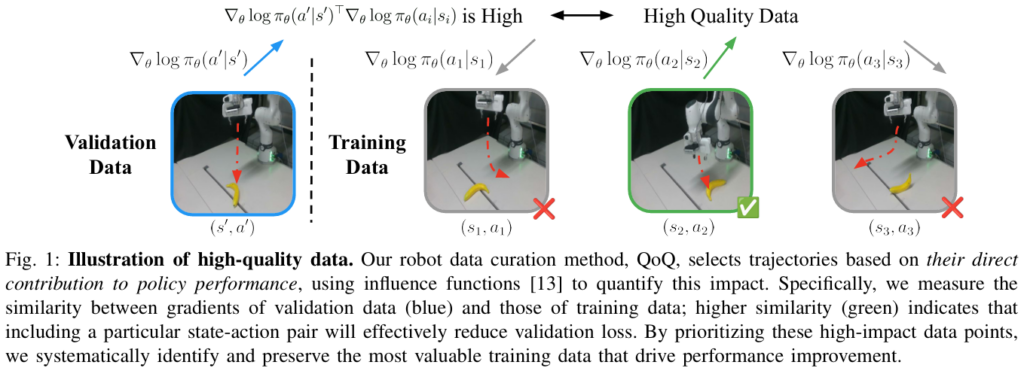
이제는 논문에서 제시하는 data curation 방법론인 QoQ에 대해서 설명해보겠습니다. 위에서 간단하게 설명한 것처럼 2개의 step으로 나누어집니다.
step1에서는 Influence funtion을 기반으로 training demo data 각각의 state-action pair가 validation loss를 줄이는데 얼마나 기여를 하는지 측정합니다.
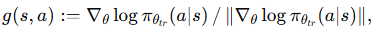
위에서 설명한 것처럼 정규화를 진행합니다. log-likelihood의 gradient 변화를 정규화를 통해서 나타냅니다. 풀어서 설명해보면 특정 state-action pair가 model parameters를 어떻게 변화시키는지 정규화해서 나타낸거죠.
그 후 Influence funtion 마지막에 최종적으로 나온 식에 -를 붙여 적용한 QoQ score는 다음과 같습니다.
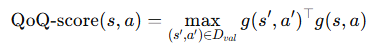
이 score가 높다면 더 좋은 데이터라고 논문은 말합니다. 이렇게 되면 validation data의 의존성이 매우 커지게 될 것 같습니다. 또한 논문에서는 기존의 방식들이 validation sample에 대해서 gradient 곱을 평균내는 방식을 사용했다고 하는데요. 아래와 같습니다.
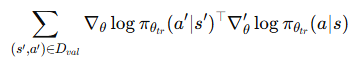
위에서 언급한 것 처럼 이렇게 정의를 하게 되면 관련 없는 task sample일 경우 오히려 score가 noisy해질 수 있으므로 최댓값을 취해서 가장 관련성인 높은 쌍에 집중한다고 합니다. 하지만 수많은 parameters를 가지고 있는 foundation model에 대해서 gradient를 각 sample마다 계산하고 저장하는 것은 엄청난 계산량이 수반되겠죠. 따라서 논문에서는 이 문제점을 언급하면서 몇가지 해결책을 제시했는데요.
- Vision encoder와 같은 파라미터 수가 매우 많은 구성요소는 제외한다고 합니다.
- gradient 간 내적 관계를 보존하면서 압축시키기 위해서 one-permutation one-random-projection(OPORP) 기법을 사용했다고 합니다. 이 기법을 사용하면 score 계산 방식의 정확도를 해치지 않으면서 저장 요구량을 줄인다고 합니다.
step2에서는 trajectory-wise curation을 수행합니다. 위에서 구한 QoQ score를 사용하여 각 trajectory에서 점수들을 평균냅니다.
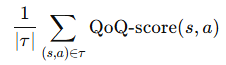
specific sample을 사용하지 않고 trajectory 별로 평균을 내어 사용하는 이유는 각각의 sample을 scoring하여 비교하는 경우에는 grasping 같은 부분이 높은 점수를 차지하여 나머지 action들이 걸러진다고 합니다. 따라서 논문에서는 위와 같은 방식으로 평균을 사용하여 상위 N개의 trajectory를 선정한다고 합니다.
Experiment
논문에서는 다음과 같은 사항을 중점적으로 실험했다고 합니다.
- Can QoQ data curation improve policy success rate?
- How robust is QoQ to in-the-wild robot data under diverse domains?
- Can QoQ leverage policy rollout as validation set?
- How doew each QoQ component impact perforamance?
Robomimic benchmark를 사용한다고 하며, Metrics로는 curation accuracy 즉 curation된 dataset 에서 trajectory가 차지하는 비율로 정의된다고 합니다. 또한 curation된 dataset으로 학습한 policy의 SR도 확인하다고 합니다.
실험에는 GR00T N1을 사용한다고 하며 QoQ score를 계산할 때 log-likelihood 대신 flow matching loss의 gradient를 사용한다고 합니다.
Can QoQ data curation improve policy success rate?
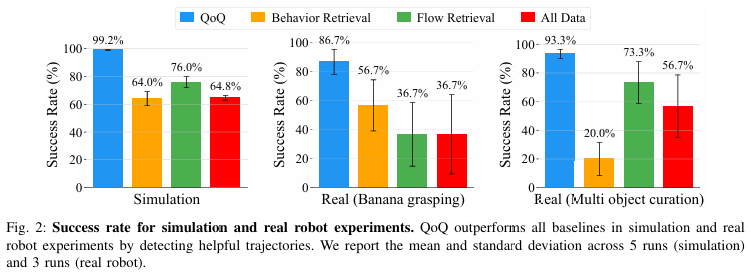
single task curation으로 Sim 상황에서는 can을 올바른 bin에 넣는 task를 진행합니다. Dataset은 100개의 성공 trajectory와 100개의 실패 trajectory로 구성되어 있습니다. real env에서는 바나나를 grasping 실험을 진행합니다. 100개의 trajectory 중 60개는 성공 40개는 실패 trajectory로 구성되어 있다고 합니다. validation set은 두 실험 모두 10개의 성공 trajectory로 구성돼있다고 하네요.
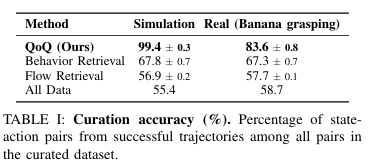
이렇게 실험을 수행한 결과, curation을 진행하지 않은 방법들 보다 model performance 측면과 curation accuracy 측면에서 더 좋은 성능을 보여줬습니다. 위에서 소개한 CUPID와 같이 혹은 mutual information 과 같은 다른 curation을 수행한 방법론과 비교를 해야 될 것 같은데 실험이 조금 아쉬웠습니다.
Multi object curation
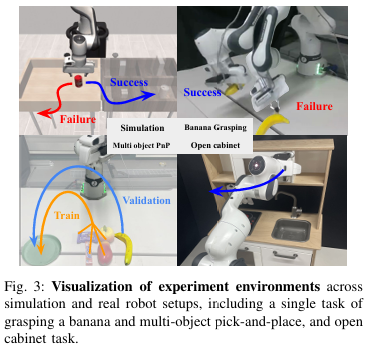
이 부분에서 논문은 서로 다른 object에 대한 pap 로 구성된 training dataset으로 부터 banana pap에 도움이 되는 trajectory를 선별한다고 합니다. validation은 banana pap 10개의 trajectory로 구성되어 있으며, training dataset은 gum, peach, mango, snack의 성공 trajectory 20개씩 총 80개로 구성되어 있습니다. 실패 trajectory는 없다고 하며 성공 trajectory만 있는 구성에서 어떤 trajectory가 policy에게 가장 도움이 되는 정보를 가지고 있냐를 판단한다고 하네요! 이 부분이 신기했습니다. 결국 성공된 trajectory 내에서도 도움이 되는 trajectory를 식별해낸다면 위의 Fig2와 같이 policy의 SR을 크게 향상시킬 수 있는 것 같습니다.
이때 저자들은 결과를 보고 Behavior Retrieval에서 VAE를 통해 얻은 state – action pair가 여러 다른 object 때문에 방해를 받아 성능이 좋지 않게 나왔다고 추정합니다. 반면 flow retrieval은 optical flow에 포착된 로봇의 움직임에 집중하기 때문에 상대적으로 더 나은 성능을 보여준다고 하네요.
How robust is QoQ to in-the-wild robot data under diverse domains?
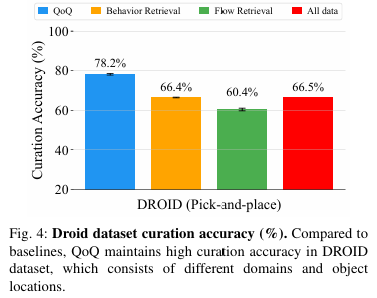
다양한 in-the-wild한 환경에서 평가를 진행하기 위해서 논문에서는 대규모 데이터셋인 DROID를 활용했습니다. 그 중에서도 pen/pencil pap trajectory를 200개를 sampling하여 133개의 성공, 실패 데이터셋을 만들었다고 합니다. validation data는 동일한 task에서 성공 data 20개를 사용했다고 하며, curation accuracy는 위와 같습니다. model performance 측면에서는 실험을 수행하지 않은 것 같습니다.
Can QoQ leverage policy rollout as validation set?
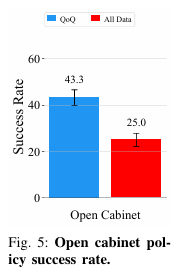
이 부분은 간단하게 실제 rollout으로 validation set을 만들 수 없을까?에 대한 질문입니다. 이때 문제가 되는 점은 rollout은 종종 실패를 포함하며, 이러한 실패 trajectory를 validation set으로 사용하기 위해서 fail trajectory QoQ score에 음수값을 사용한다고 합니다. 이로 인해서 실패 trajectory의 QoQ score는 낮아지게 되고 좋은 score가 아니게 되겠죠. 그 후 최종적으로 성공한 trajectory score와 차를 계산하여 최종적인 episode의 score를 만들게 됩니다. 이 때 만약 20개의 validation set이 있다고 할 때 15개의 실패와 5개의 성공이 있으면 크기가 달라 점수가 이상하게 측정될 수도 있겠죠? 따라서 논문에서는 이 부분에 대해서 가중치도 부여한다고 합니다.
20개의 rollout validation set을 사용하여 5개의 성공 15개의 실패 trajectory를 validation set으로 사용하였고, 100개의 성공 50개의 실패 trajectory가 있는 data를 curation을 진행하여 학습한 결과는 fig5와 같습니다.
How doew each QoQ component impact perforamance?

논문에서는 GR00T N1 모델의 서로 다른 layer에서 QoQ score를 계산할 때 curation accuracy 비교를 수행하였는데요. 수많은 파라미터 수를 가진 VLA 모델에서 위와 같은 결과는 고무적인 것 같습니다.
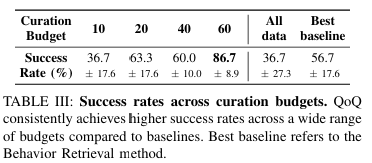
논문에서는 Curation Budget의 변화에 따른 downstream policy의 성능이 달라지는가?에 대해서 실험을 진행하였는데요. N의 수가 적으면 학습 데이터의 양이 부족해지기 때문에 성능이 떨어지는 모습을 볼 수 있습니다. 따라서 논문에서는 training dataset에서 성공 trajectory 비율보다 살짝 낮거나 비슷하게 설정했을 때 높은 작업 성공률을 보인다고 합니다. 당연한 말을 하는 것 같습니다. 이 부분은 따로 언급되어 있었는데 여러 curation budget을 실험해 보는 것을 권장한다고 합니다.
이번 논문은 어떤 것이 quality가 좋은 데이터인가의 물음에서 model의 성능에 직접적으로 좋은 영향을 미치는 데이터가 좋은 데이터라고 답하는 논문이었습니다. 이전에 리뷰했던 로봇 관점에서의 데이터가 아닌 model 중심적으로 판단한 논문이라고 생각이듭니다. 실험 측면에서는 아쉬웠던 점이 다른 curation 논문과의 비교가 없다는 점이 아쉬웠습니다. 감사합니다
안녕하세요 인하님, 좋은 리뷰 감사합니다.
질문이 몇가지 있는데요.
1. 저자들이 validation data를 정하는 기준이 뭔가요? 어떤 기준이나 방식으로 어떻게 선정했다 라는 기준이 잘 파악이 안되어서요. 기존 벤치마크에서의 그 validation(test) data인가요? 만약 전자라면 기존 데이터에서 samping하는 과정에서 저자들의 휴리스틱 편향이 들어갔을 수도 있을 것 같고, 만약에 설마.. 후자라면 validation 데이터에 overfitting으로 학습한 거일텐데,, 아무래도 전자겠죠?
2. 그럼 결국에 해당 방법론은 validation data를 어떻게 잘 선정해줄거냐에 따라 QoQ score가 급격하게 갈리게 되는 것 같은데, related work를 보면 로봇 도메인에서의 IL data pruning에 대한 다른 방법론들도 influence function을 사용하고 이 때 validation data를 사용하는 거로 이해했습니다. 이 validation data를 사용해서 학습 데이터 품질을 정량화한다는 기조가 해당 분야에서의 메인스트림인가요?
3. 예은님이 저번에 리뷰하신 data pruning 태스크에 대한 리뷰를 보니, 학습 도중에 pruning을 위한 loss 연산을 해서 그걸 기준으로 데이터를 pruning을 하는 dynamic pruning 방식이 있던거로 이해했습니다. 저도 예은님의 리뷰를 꼼꼼하게는 읽지 않아 정확히 이 방식인지는 모르겠지만, 그런 dynamic pruning 방식을 활용하면 인하님이 리뷰하신 본 방법론에서 필수로 필요하게 되는 validation data를 사용하지 않고도 학습을 하는 기준을 만들어볼 수 있을 것 같다는 생각이 듭니다. 그렇게 되면 어떤 validation data를 어떻게 선정해야하는 것인가에 대한 모호성이나 특정 성공집합 데이터들을 임의로 정의하는 heuristic bias를 좀 우회할 수 있을 것 같기도 하구요. 인하님은 이것에 대해 어떻게 생각하시나요? 모방학습의 핵심은 역시 gt를 모방하는 방식인지라 지금의 validation set 선정방식이 가지는 heuristic bias가 오히려 더 중요한 거라고 생각하시나요? 혹은 이에 대한 저자들의 논의가 논문에 있는지 궁금합니다.