제가 이번에 리뷰할 논문은 CVPR 2026에 accpet된 것으로 보이는 논문입니다. 이미지나 텍스트 프롬프트가 입력되었을 때, 3D asset을 생성하는 TRELLIS(CVPR 2026 Spotlight)연구를 기반으로 하고있으며, 해당 논문은 물체의 일 부분이 보이지 않는 기존의 affordance grounding 연구의 경우 전체 구조를 이해하지 못한다는 문제가 있다고 보고, 전체 형상을 복원한 뒤, 기능적인 영역을 인식하는(affordance grounding) 연구입니다.
Abstract
affordance grounding은 RGBD 영상 내 물체의 기능적 영역을 인식하는 연구로, 텍스트 쿼리가 주어졌을 때, 대응되는 물체의 영역을 찾아내는 것을 목표로 합니다. 해당 논문은 보이는 물체 표면으로 한정된 기존 affordance grounding의 한계를 넘어서, 보이지 않는 영역까지 포함한 전체 3D 형상 위에서 affordance를 추정하는 Affostrudction 프레임워크를 제안합니다. Affostruction은 부분 관측 정보로부터 전체 형상을 복원한 뒤, 복원된 형상 위에서 affordance grounding을 수행합니다. 또한 flow 기반 예측으로 affordance의 모호성을 다루고, 예측 결과를 활용해 유용한 시점을 능동적으로 선택합니다. 결과적으로 affordance grounding과 3D reconstruction 모두에서 기존 방법 대비 큰 성능 향상을 보였습니다.
Introduction
실제 로봇 환경에서는 가려짐이 많은 partial observation이 발생하므로, 물체의 보이지 않는 기능 부위까지 고려한 affordance 이해가 필요합니다. 그러나 기존 affordance grounding은 관측된 표면에만 제한되고, 3D 재구성은 전체 형상은 복원해도 기능적 grounding은 충분히 다루지 못합니다.
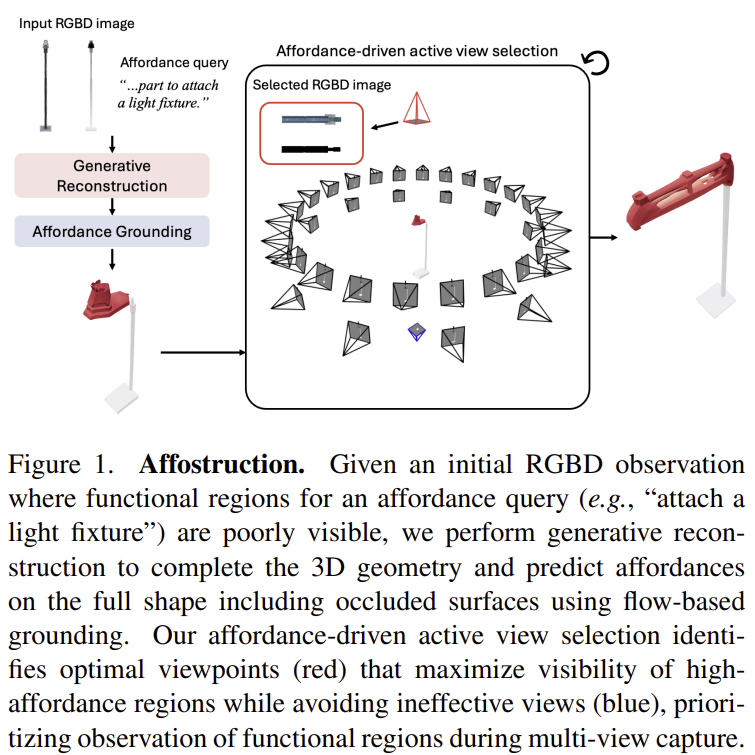
저자들은 가려진 영역까지 포함한 affordance grounding을 위해, partial observation으로부터 먼저 전체 3D 형상을 복원해야 한다고 봅니다. 이를 위해 부분을 기반으로 전체 형상을 복원한 뒤, affordance 영역을 예측하는 Affostruction 프레임워크를 제안합니다. Affostruction은 DinoV2 feature의 다중 시점 RGBD 정보를 sparse voxel fusion으로 통합하여 보이지 않는 영역까지 복원합니다. 또한 행동에 대응되는 영역이 여러 곳이 될 수 있다는 affordance의 모호성(예를들어 컵의 grasp가 주어질 경우, 컵 손잡이가 될 수도 있고, 컵 겉부분이 될 수도 있습니다)을 반영하기 위해, 단일 예측이 아니라 flow 기반의 분포를 학습하는 affordance heatmap을 생성합니다. 즉, 확률 기반으로 접근합니다.
해당 파이프라인은 대규모 3D 데이터로 학습된 3차원 asset 생성 방법론인 TRELLIS를 기반으로 구성됩니다. 그러나 TRELLIS는 multi-view를 처리하는 능력과 기능적 이해 능력이 부족하므로 그대로 로봇 시나리오에 적용하는 데는 어려움이 있습니다. 따라서, 저자들은 다음 2가지의 확장을 통해 이를 해결하고자 하였습니다. (1) multi-view sparse voxel fusion을 통해 멀티뷰의 DinoV2 feature를 집계하며, (2) flow-based affordance 모듈을 통해 텍스트 쿼리에 대응되는 heatmap을 생성합니다. 이때 sparse voxel represenation은 시점 수와 무관하게 일정한 토큰 복잡도를 유지하여 효율적으로 정보 통합이 가능합니다. 이러한 확장을 통해, foundation 모델의 기하학적 사전지식을 활용하면서도 멀티뷰 RGBD 이미지로부터 완전한 형상을 복원하고 그 위에서 affordance를 이해할 수 있도록 합니다.
해당 논문의 contribution을 정리하면
- 멀티뷰 RGBD 정보를 sparse voxel fusion으로 통합하여, 부분 관측으로부터 보이지 않는 geometry까지 복원
- 재구성된 전체 형상에 대해 flow-based generative model을 통해 affordance 분포(확률)를 예측하여, 기능적 상호작용의 모호성을 반영
- 예측된 affordance를 활용하여 기능적으로 중요한 영역을 우선 관찰하도록 시점을 선택
Method
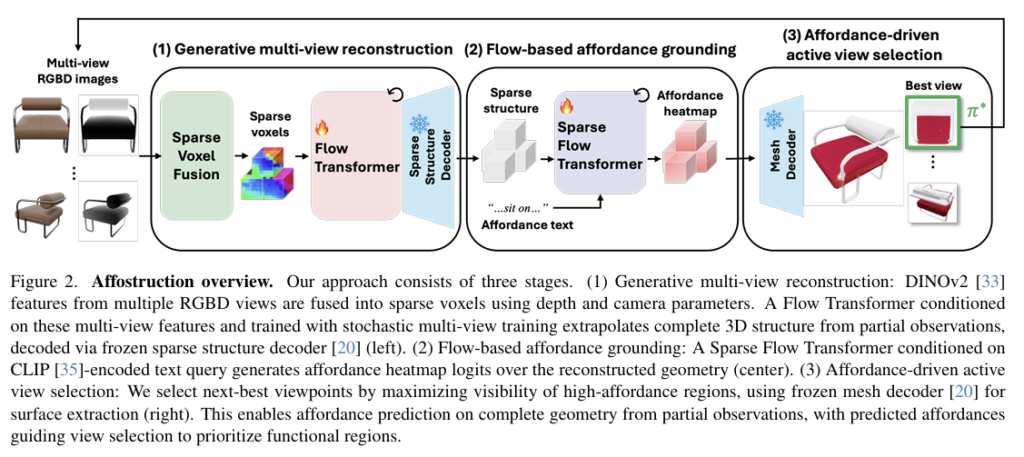
멀티뷰 RGBD이미지가 주어졌을 때, Affostruction은 먼저 전체 형상을 복원하고, 복원된 전체 형상에 대해 open-vocabulary affordance grounding을 수행합니다. 위의 Figure 2는 전체 프레임워크로, 크게 3가지로 구성됩니다. 먼저, Generative multi-view reconstruction과정을 통해 depth와 카메라 파라미터를 사용하여 멀티뷰 RGBD 의 visual feature를 sparse voxel로 융합하여, 보이지 않는 기하학적 구조를 추론하여 완전한 3D 구조를 생성합니다. 이후, Flow-based affordance grounding을 통해 텍스트 쿼리를 조건으로 활용하여 affordance 분포를 예측하고, 마지막으로 Affordance-driven active view selection을 통해 heatmap을 활용하여 최적의 시점을 찾아냅니다.
Preliminary: TRELLIS
먼저, 저자들이 기본으로 삼은 TRELLIS는 sparse 3D latent space에서 2개의 순차적인 rectified flow model을 활용하여 3D 물체를 생성합니다.
- Stage 1: Flow Transformer
- 단일 RGB 이미지를 조건 \mathbf{C}으로 활용하여 조밀한 노이즈 텐서 입력을 복원하고, 이를 통해 점유된 복셀 위치를 예측하는 단계입니다. 즉, 물체의 전체 3D 구조가 어디에 존재하는지에 대한 sparse structure \{\mathbf{p}_i\}^L_{i=1}를 먼저 추정합니다.
- Stage 2: Sparse Flow Transformer
- 1단계에서 구한 점유 복셀을 바탕으로, 이미지 특징에 조건화된 latent feature \{\mathbf{z}_i\}^L_{i=1}를 생성한 뒤 이를 3D decoder로 복원하여 최종 3D geometry를 생성합니다. 즉, 1단계가 구조의 위치를 정하는 과정이라면, 2단계는 이를 바탕으로 구체적인 형상 표현을 완성하는 과정입니다.
TRELLIS는 3D 형상을 복원하는 능력이 있으나, 단일 이미지만을 처리하며, affordance를 고려하지 않기 때문에 바로 3D affordance grounding에 적용하기에는 어려움이 있습니다. 따라서 저자들은 TRELLIS의 3D 생성 능력은 유지하면서도, 이를 로봇 조작에 필요한 다중 시점 입력 처리와 affordance heatmap 예측이 가능하도록 확장합니다.
(1) Generative multi-view reconstruction
다중 시점의 RGBD를 처리하기 위해 각 시점을 독립적으로 처리하는 대신, transformer에 입력하기 전에 depth 정보를 활용하여 3D 공간상에서 visual feature를 통합하여 부분 관측으로부터 전체 형상을 복원할 수 있도록 합니다. 해당 방식은 시점이 증가해도, 토큰 복잡도가 일정하게 유지할 수 있다는 장점이 있다고 합니다.
먼저 각 시점 \mathcal{V}_i=(I_i,D_i,K_i,T_i)는 RGB, Depth, 카메라 intrinsics와 extrinsics로 구성됩니다. RGB 영상에 대하여 DinoV2 feature \mathbf{f}를 추출한 뒤, depth 정보를 이용하여 각 픽셀을 3D world 좌표latex]\mathbf{p}[/latex]로 투영합니다. 이렇게 하여 각 시점은 시점은 sparse voxel representation \mathbf{V}_i=\{(\mathbf{p}_j, \mathbf{f}_j)\}^{L_i}_{j=1} (i는 view, L_i는 ovservsed vexel 수)으로 변환됩니다.
그 다음 다중 시점 \{\mathcal{V}_i\}^{N}_{i=1}을 융합하기 위해, 같은 위치의 복셀은 feature를 평균내고, 겹치지 않는 복셀은 그대로 유지하도록 하여 fused representation \mathbf{\bar{V}}_i=\{(\mathbf{p}_j, \mathbf{\bar{f}}_j)\}^{L_i}_{j=1}을 구합니다. 이후 각 3D 위치에 대한 3D positional encode을 추가하여 최종 conditional signal \mathbf{C}_{voxel}을 만듭니다. 이렇게 하여 각 시점을 별도로 transformer로 처리하는 것이 아닌, 여러 시점의 정보를 융합한 결과를 입력으로 사용합니다.
또한, 학습시에는 stochastic multi-view training을 적용합니다. 매 iteration마다 1~8개의시점을 랜덤하게 샘플링하여 학습하므로써, 모델이 단일 시점부터 다양한 수의 시점에도 적응하도록 합니다. 이렇게 학습된 conditional signal은 이후 Flow-based affordance grounding에 cross-attention으로 입력되며, 기존 TRELLIS와 동일하게 학습됩니다. 즉, 해당 모듈은 다양한 수의 다중 시점의 RGBD 관측 정보를 활용하여 전체 3D 형상을 생성해내게 됩니다.
(2) Flow-based affordance grounding
복원된 3D geometry와 자연어 쿼리(e.g. “where to grasp”)가 주어졌을 때, 저자들은 형상에 대한 affordance heatmap을 예측합니다. 이때 affordance 영역은 여러 영역이 가능할 수 있으므로, 저자들은 affordance heatmap을 생성하는 Sparse Flow Transformer를 학습합니다.
먼저 CLIP text encoder를 이용하여 자연어 쿼리로부터 text condition \mathbf{C}_{text}을 생성합니다. 이는 conditioning signal로 사용되며, 앞서 예측된 복셀 위치에 초기화된 sparse noise tensor \mathbf{A}_1를 denoising 하여 각 복셀의 clean affordance logit \mathbf{A}_0을 복원하도록 학습됩니다. 이때 noisy state는 \mathbf{A}_t=(1-t)\mathbf{A}_0+t_\epsilon로 정의되며, 학습에는 binary cross-entropy와 Dice loss를 결합한 binary mask loss를 이용하여 voxel 단위 정확도와 영역 수준의 mask 품질을 동시에 반영합니다. 이때, \mathbf{A}'와 \mathbf{A}는 각각 예측된 affordance logit을 의미합니다.
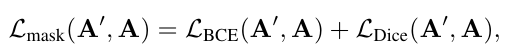
최종적으로 flow matching은 아래의 식으로 정의됩니다.
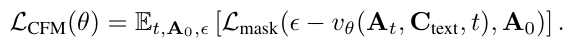
학습시에는 affordance flow model만 학습되며, 구조 생성 모델과 text encoder는 freeze됩니다. 추론시에는 텍스트 쿼리가 조건화된 상태로 noise를 제거하여 affordance logits을 생성하고, 마지막에 sigmoid를 적용하여 확률 형태의 affordance heatmap을 생성합니다.
(3) Affordance-driven active view selection
마지막으로 관찰들을 기반으로, affordance 확률이 높은 영역을 가장 잘 보여주는 view를 선택합니다. 먼저 물체를 중심으로 반원의 균일한 분포로 40개의 시점 후보를 생성합니다. 그 다음, affordance heatmap의 색상을 입힌 3D mesh를 40개의 시점으로 렌더링한 2D 이미지를 생성한 뒤, heatmap 값을 모두 더하여 visibility score를 구해줍니다. 이러한 과정을 통해 visibility score가 가장 높은 시점을 선택합니다.
Experiments
실험은 먼저 3D reconstruction 성능에 대하여 평가한 뒤, 완전한 전체 형상(물체의 가려진 부분은 고려하지 않는 케이스)과 부분 관측이 주어진 경우의 affordance grounding 성능을 평가합니다. 이후 ablation study를 통해 저자들이 제안한 stochastic multi-view training과 active view selection의 효과를 검증합니다.
학습에는 3D-FUTURE, HSSD, ABO와 Affogato train set을 이용하고, 3D reconstruction 평가는 Toys4k, affordance grounding 평가는 Affogato test set에 대해 이루어집니다. 부분 관측 실험은 첫 번째 RGBD 뷰만 입력으로 사용하며, 모델은 8개의 A100에서 450k step 동안 학습됩니다. 또한, visual feature는 DINOv2-large, 텍스트 인코더로는 CLIP ViT-L/14를 사용합니다.
1. 3D reconstruction
부분 관측으로부터 전체 형상에 대한 3D reconstruction을 평가하기 위해, geometry에 대해서는 IoU, CD(chamfer distance), F-score를 측정하고, 외관에 대해서는 렌더링 기반 PSNR, LPIPS를 측정합니다.
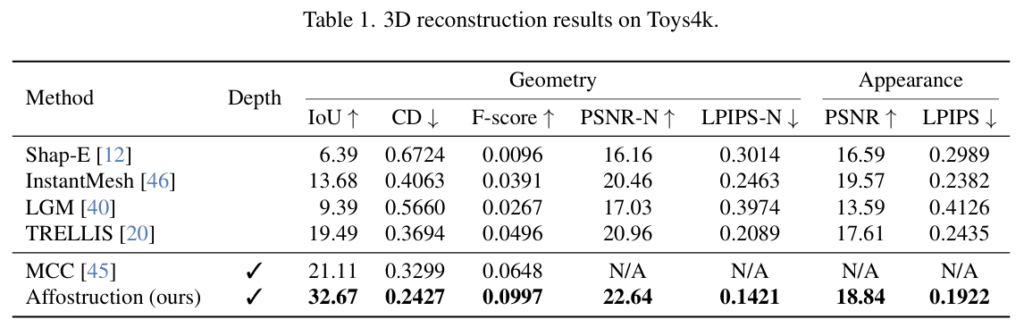
Table 1은 이에 대한 실험 결과로, Affostruction은 IoU에서 32.67를 기록하여 TRELLIS와 MCC보다 우수한 성능을 보였습니다. TRELLIS는 RGB만을 이용하는 방식으로, 물체의 방향과 scale 불일치 문제가 있고, MCC는 depth 기반의 방법론으로 geometry는 개선되지만 mesh 출력을 생성하지 못한다는 한계가 있습니다. 이러한 기존 연구의 한계와 비교하였을 때, 저자들이 제안한 방법론은 depth 정보를 sparse voxel fusion으로 통합한 flow-based generative reconstruction을 통해 부분 관측으로부터 전체 형상(기하학적 외관적 모두)을 더 정확히 복원할 수 있음을 보였습니다.
2. Complete 3D affordance grounding
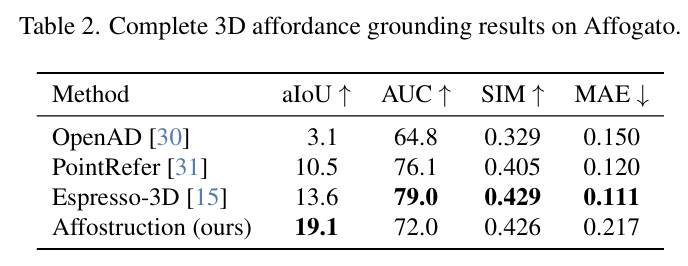
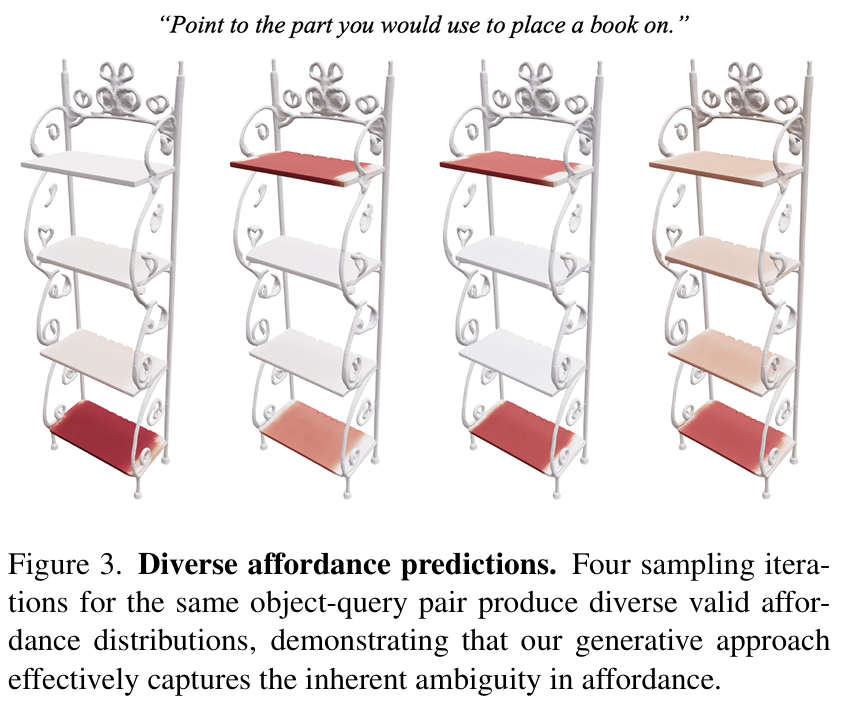
완전한 전체 형상에 대한 3D affordance grounding 성능을 평가하기 위해 aIoU, AUC, SIM을 주요 평가지표로 사용하였으며, MAE를 추가로 사용하여 보조적으로 heatmap의 절대 오차를 측정하였다고 합니다. 저자들이 제안한 방식은 추가적인 vision encoder 학습 없이도 aIoU 19.1을 달성하여 Espresso-3D 대비 40.4% 향상된 localization 성능을 보였습니다. 반면 AUC와 SIM에서는, vision 인코더를 discriminative 방식으로 학습한 기존 방법론들이 조금 더 좋은 성능을 보였으며, 이는 제안 방법이 단일 결정값보다 affordance 분포 자체를 생성하는 접근이기 때문이라고 설명합니다. 또한, Figure 3을 통해 동일한 쿼리에 대해 여러 유효한 affordance heatmap을 생성할 수 있어, affordance의 모호성을 자연스럽게 반영한다는 점을 보였습니다.
3. Partial 3D affordance grounding
해당 실험은 부분 관측이 주어졌을 때, 전체 3D 형상을 복원하고 affordance 영역을 추론하는 두 단계로 이루어집니다. complete 세팅에서는 가려지는 영역이 없다는 가정으로 관측된 표면에 대해서 affordance를 평가하는 것으로, 전체 형상을 복원한다는 저자들의 아이디어를 검증하기 위해서는 새로운 평가지표를 제안합니다. 예측된 affordance point cloud와 GT affordance point cloud를 5개의 thershold(0.1, 0.2, 0.3, 0.4, 0.5)를 기준으로 binary affordance region을 구한 뒤, 각 thershold 마다 volumetric IoU와 CD(chamfer distance)를 계산하여 모든 threshold의 평균을 구한 aIoU와 aCD를 제안합니다. 해당 지표는 affordance localization 뿐만 아니라 3D reconstruction도 정확해야 높은 성능을 얻을 수 있으므로 종합적 평가가 가능하다고 저자들은 주장합니다.
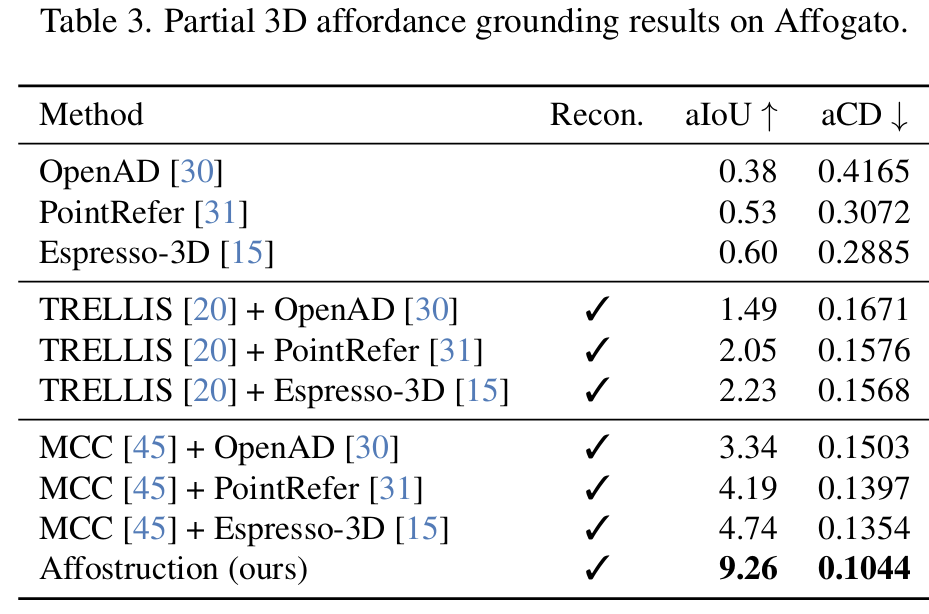
Table 3은 이에 대한 실험 결과로, 위의 3개 행은 3D reconstruction 없이 affordance grounding을 수행한 결과이며, 가운데 3개 행과 아래 3개 행(마지막 행은 Ours)은 3D reconstruction에 TRELLIS와 MCC를 사용한 결과입니다. 먼저, 기존 affordance grounding 방법들은 관측된 표면에만 예측이 이루어지므로, complete geometry 기준에서는 매우 낮은 성능을 보였으며, reconstruction 후 affordance를 적용하는 2-stage 방식은 일정 수준 개선되지만 reconstruction error가 이후 affordance grounding에 까지 영향을 미치는 reconstruction error propagation 문제가 존재합니다. 반면 저자들이 제안한 Affostruction은 reconstruction과 affordance grounding을 하나의 프레임워크 안에서 함께 수행하여, 단일 RGBD view에서도 9.26 aIoU를 달성했고, active view selection을 적용하면 2 views에서 11.17, 4 views에서 12.46 aIoU까지 추가 향상되는 결과를 보였습니다.
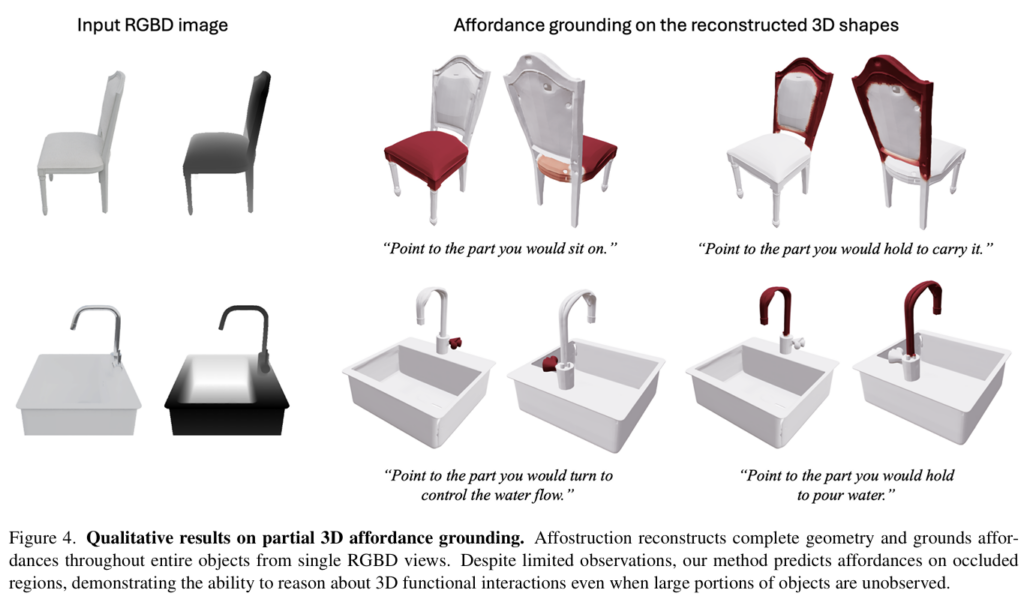
4. Ablation study
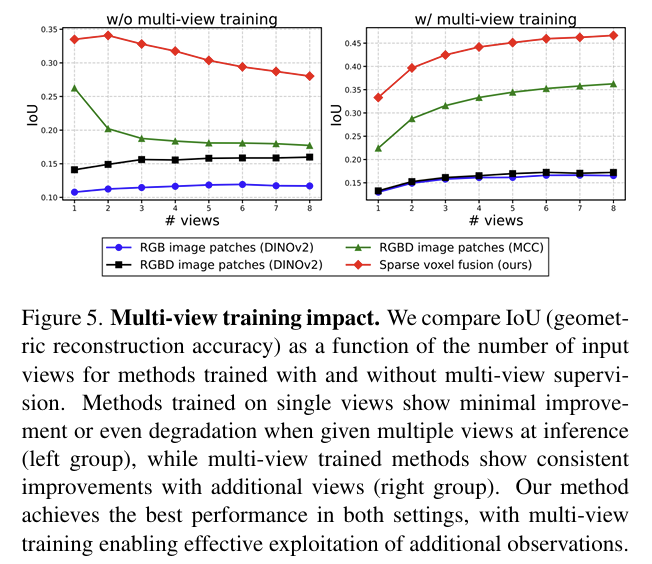
먼저 stochastic multi-view training의 효과를 검증합니다.(Figure 5) 저자들은 동일한 Flow Transformer 구조에서 RGB image patches, RGBD image patches(DINOv2), RGBD image patches(MCC), 저자들이 제안한 sparse voxel fusion의 네 가지 conditioning 방식을 비교하였고, 각각에 대해 single-view training(w/o multi-view training)과 multi-view training을 나누어 실험합니다. 그 결과, 단일 시점만으로 학습한 모델은 추론 시 여러 시점이 주어져도 추가 정보를 제대로 활용하지 못해 성능 향상이 거의 없거나 오히려 저하되었지만, stochastic multi-view training을 적용하면 시점 수가 증가할수록 reconstruction 성능이 안정적으로 향상되었습니다. 특히, Affostruction은 multi-view training에서 가장 우수한 성능을 보였으며, IoU가 33.32(1 view)에서 46.65(8 views)까지 개선되어 sparse voxel fusion이 다중 시점 정보를 효과적으로 통합함을 보여줍니다.
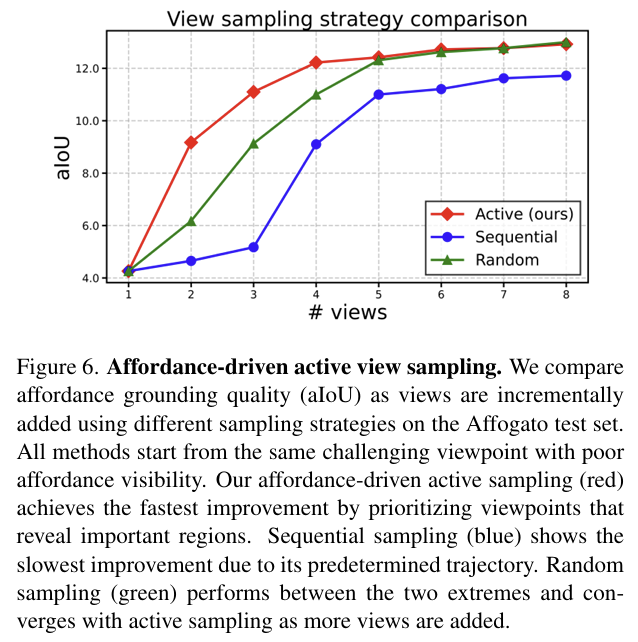
또한 저자들은 affordance-driven active view selection의 효과도 검증합니다.(Figure 6) 초기 시점이 주어졌을 때, sequential, random, affordance-driven의 세 가지 view sampling 전략을 비교한 결과, affordance-driven 방식이 가장 빠르고 크게 성능을 향상시키는 것을 확인할 수 있습니다. 예를 들어 추가 시점 1개만 사용했을 때 9.2 aIoU를 기록하여 sequential(4.7)과 random(6.2)보다 우수했고, 4 views에서도 12.4 aIoU로 sequential(9.1)과 random(11.0) 방식보다 높은 성능을 보였습니다. 시점이 충분히 많아지는 8 views에서는 active와 random이 비슷한 수준(13.3 vs 13.2 aIoU)으로 수렴하였으나, 제한된 view budget에서는 active view selection이 훨씬 효율적으로 기능 영역을 우선 관찰하게 하여 성능 향상에 더 유리함을 보여줍니다.
Conclusion
저자들은 부분 RGBD 관측으로부터 전체 3D 형상을 복원하고 그 위에서 affordance를 grounding하는 생성형 프레임워크 Affostruction을 제안합니다. Affostruction은 sparse voxel fusion, flow-based affordance generation, affordance-driven active view selection의 세 과정을 통해, 보이지 않는 영역까지 포함하여 기능적 이해가 가능하도록 하는 것을 목표로 합니다. 실험을 통해 reconstruction과 affordance grounding 모두에서 기존 방법론에 비해 우수한 성능을 입증하였으며, 저자들은 다중 물체 환경으로 확장을 future work라고 정리하였습니다.
안녕하세요 승현님 좋은 리뷰 감사합니다.
3D reconstruction 을 실제 스케일에 맞게 잘 재구성 한다음에 voxel 과 fusion 하여 예측하는 걸로 이해하면될까요 ?
사실 제가 affordance 쪽은 아직 보지못해서 multi view로 재구성하고 Affordance를 찾으려면 그만큼 시간은 걸릴 것 같은데 이쪽연구 흐름에서는 그런거는 고려되지않고 있는지 궁금합니다. 또한 MCC라는것이 mesh를 추출하지 못해서 성능차이가 이루어졌다고 말씀주셨는데 mesh를 추출하기위해서 어떤 어려움이 있는건가요 ?
감사합니다
일단 멀티뷰의 RGB-D, intrinsic/extrinsic 파라미터를 이용하여 3차원 공간으로 올려서 sparse voxel을 만들고, 이 멀티뷰를 융합하기 위한 fusion을 제안하여 3D reconstruction을 합니다. 그리고 이를 활용하여 affordance를 예측하게 됩니다.
시간에 대해서는 저자들이 따로 이야기하고있지는 않습니다. 그러나 이야기하신 것 처럼 시간이 걸리는것은 한계이며 추후 보완해야할 것으로 보입니다.
일반적으로 mesh는 세밀한 형상 표현이 가능하지만, 저장 용량이 크고 상대적으로 처리가 어렵습니다. MCC는 mesh가 아닌 point cloud와 occupancy를 이용하여 표현의 유연성, 일반성, 그리고 대규모 데이터 학습에서의 효율성을 확보하는 데 집중한 방법론입니다.