1. Introduction
Vision-Language Pre-training(VLP)은 대규모 웹 크롤링 이미지-텍스트 데이터셋을 바탕으로 학습되는 대표적인 멀티모달 사전학습 방식입니다. 보통은 self-supervised learning 형태로 학습되며, masked language modeling(MLM), image-text contrastive(ITC), image-text matching(ITM) 같은 여러 pre-task와 loss를 함께 사용합니다. 최근까지도 이 계열 모델들은 매우 좋은 성능을 보여주고 있지만, 여전히 완전히 해결되지 않은 문제가 하나 있습니다. 바로 image-text pair 안에 포함된 noisy caption 문제입니다.
이 noisy caption은 어떤 캡션은 이미지의 핵심 내용을 일부만 설명하고, 어떤 경우에는 아예 틀린 설명이 붙어 있기도 합니다. 그래서 최근 연구들은 주로 이 noisy correspondence를 줄이는 방향에 집중해 왔습니다. 대표적으로 BLIP은 image captioning model과 filtering 과정을 활용해 synthetic clean caption을 만들고, 품질이 낮은 캡션은 제거하는 전략을 사용합니다. 쉽게 말하면, 잘못 붙은 설명을 좀 더 깨끗하게 정제해서 false positive를 줄이겠다는 접근이라고 볼 수 있습니다.
그런데 저자들은 여기서 한 걸음 더 나아갑니다. 기존 VLP가 주로 noisy caption, 즉 false positive 문제에 주목해왔다면, 사실 그 못지않게 중요한 또 다른 문제가 있다는 것입니다. 바로 image-text 데이터가 본질적으로 many-to-many correspondence를 가진다는 점입니다. 말 그대로 하나의 이미지가 현재 짝지어진 텍스트 말고도, 다른 텍스트와 의미적으로 충분히 가까울 수 있고, 반대로 하나의 텍스트도 여러 이미지와 양의 관계를 가질 수 있다는 이야기입니다. 그런데 기존 데이터셋은 오직 “주어진 pair”만 수집해 두었기 때문에, 이렇게 짝지어지지 않았지만 의미적으로 가까운 positive connection은 데이터 안에 명시적으로 드러나지 않습니다.
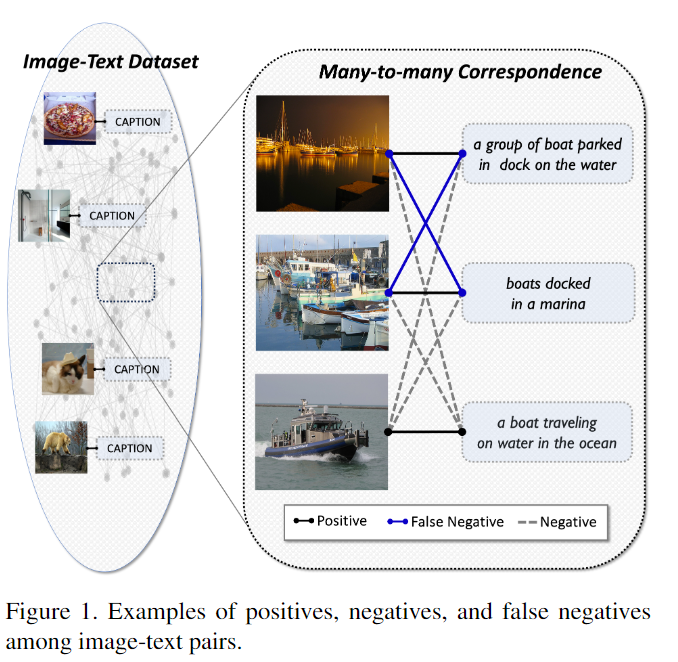
이 지점에서 문제가 생깁니다. 학습 과정에서는 각 이미지와 텍스트에 대해 주어진 pair만 유일한 positive로 취급하고, 나머지는 전부 negative로 처리하게 됩니다. 결국 실제로는 positive일 수도 있는 샘플들이 negative로 들어가게 되고, 이것이 바로 false negative 문제입니다. 저자들은 ITC나 ITM loss를 계산할 때 이런 false negative가 꽤 빈번하게 등장하며, 결국 모델의 학습을 혼란스럽게 만든다고 설명합니다.
물론 가장 단순한 해결책은 있을 수 있습니다. 데이터셋 안의 모든 image-text 조합을 전부 검사해서, 빠져 있는 positive connection을 찾아주면 됩니다. 하지만 이건 사실상 불가능합니다. 예를 들어 500만 개 규모의 image-text pair만 있어도 가능한 조합 수는 거의 12조 수준이 되기 때문입니다. 사람이 직접 보든, 모델로 평가하든 계산량이 너무 커서 현실적으로 감당하기 어렵습니다.
저자들이 특히 지적하는 부분은, 이런 false negative 문제가 최근 VLP에서 충분히 심각하게 다뤄지지 않았다는 점입니다. 특히 ITM 학습에서 널리 쓰이는 in-batch hard negative sampling은 원래 informative한 negative를 고르기 위한 전략이지만, false negative가 존재하는 환경에서는 오히려 진짜 positive에 가까운 샘플을 hard negative로 뽑아버릴 위험이 있습니다. ALBEF의 방식도 그렇고, GRIT-VLP처럼 유사한 image-text pair를 먼저 grouping해서 mini-batch를 구성하는 개선된 hard negative sampling도 마찬가지입니다. 이상적으로는 semantic하게 가까운 pair들이 정확히 라벨링되어 있어야 hard negative mining이 제대로 작동합니다. 하지만 실제 VLP 데이터셋은 그런 정보가 없기 때문에, hard negative가 informative negative가 아니라 false negative가 되어버리는 경우가 많고, 이게 결국 성능 저하로 이어질 수 있다는 주장입니다.
이 문제를 해결하기 위해 저자들은 MAFA(MAnaging FAlse negatives)라는 방법을 제안합니다. 핵심은 false negative를 그냥 운에 맡기지 않고, 학습 과정 안에서 보다 체계적으로 다루겠다는 것입니다. 구체적으로는 두 가지 장치를 넣습니다.
첫 번째는 Efficient Connection Mining(ECM)입니다. 이 모듈은 짝지어지지 않았지만 의미적으로 가까운 image-text 사이의 missing positive connection을 찾기 위한 과정입니다. 중요한 점은 모든 조합을 전수조사하지 않는다는 것입니다. 대신 hard negative로 이미 선택된 후보들 중에서 plausible한 샘플만 전략적으로 추려내고, 이를 pre-trained discriminator로 다시 검사합니다. 그리고 이 discriminator가 positive 가능성이 높다고 판단한 샘플들은 더 이상 negative로 두지 않고, 추가적인 positive로 학습에 반영합니다. 즉, false negative를 단순히 제거하는 수준을 넘어서, 실제 positive supervision으로 다시 활용하겠다는 아이디어입니다.
두 번째는 Smoothed ITC(S-ITC)입니다. 이 방식은 label smoothing 원리를 가져와 grouped mini-batch 안에서 false negative에 대해 모델이 지나치게 강한 penalty를 주는 문제를 완화합니다. ECM이 missing positive를 직접 발굴하는 쪽이라면, S-ITC는 아직 완전히 확인되지 않은 false negative 가능성에 대해 loss를 좀 더 부드럽게 주는 장치라고 이해하면 됩니다. 저자는 이 과정이 추가적인 memory나 computational overhead 없이 적용 가능하다는 점도 함께 강조합니다.
결국 이 논문의 메시지는 명확합니다. 기존 VLP는 noisy caption으로 인한 false positive 문제를 많이 다뤄왔지만, 실제 학습을 더 크게 흔드는 건 false negative일 수도 있다는 것입니다. 그리고 저자들은 이를 해결하기 위해 하나는 missing positive를 직접 찾아내는 ECM, 다른 하나는 penalty를 완화하는 S-ITC를 함께 사용합니다. 이 둘은 서로 보완적으로 작동하면서, false negative가 많은 환경에서도 보다 안정적인 VLP 학습을 가능하게 하겠다는 방향입니다.
실험 결과에서는 MAFA를 적용한 모델은 4M 규모의 noisy dataset만으로도, 훨씬 큰 14M dataset으로 학습한 baseline에 가까운 성능을 달성합니다. 또한 ablation study를 통해 성능 향상의 주된 원인이 실제로 false negative 완화에 있다는 점을 보이며, 단순히 false negative를 제거하는 것보다 이를 additional positive로 전환하는 편이 더 효과적이라는 것도 함께 보여줍니다. 더 나아가 BLIP과 결합해 false positive와 false negative를 동시에 다뤘을 때의 효과도 분석하고, BLIP-2와도 호환됨을 보여주면서 방법의 일반성까지 주장합니다.
각 모듈의 세부 동작과 왜 이런 설계가 필요한지는 방법론 파트에서 더 자세히 보면 될 것 같습니다.
2. Motivation
여기서는 저자들이 앞서 Introduction에서 제기한 false negative 문제가 실제로 얼마나 심각한지 정량적으로 보여주려는 부분입니다.
이를 위해 저자들은 한 epoch 동안 ITM 학습에서 발생하는 false negative pair의 수를 추정합니다. 비교 대상은 두 가지 mini-batch sampling 방식입니다. 하나는 일반적인 random sampling이고, 다른 하나는 GRIT sampling입니다. 그리고 이 비교를 원본 4M 데이터셋인 4M-Noisy와, BLIP으로 정제한 4M-Clean 양쪽에서 모두 수행합니다.
물론 여기에는 현실적인 문제가 있습니다. 모든 negative pair를 사람이 하나하나 보면서 “이게 진짜 false negative인가?”를 판별하는 건 불가능합니다. 그래서 저자들은 BLIP의 129M 데이터셋으로 사전학습된 ITM 모델을 일종의 판별기로 사용합니다. 즉, 원래는 negative로 들어간 image-text pair에 대해 이 ITM 모델이 “matched”라고 예측하면, 이를 false negative로 간주하는 방식입니다.

결과는 Table 1에 나와있습니다. Introduction에서 말한 것처럼, GRIT sampling은 random sampling보다 false negative를 훨씬 더 많이 만들어냅니다. GRIT sampling은 미니배치 안에 semantic하게 유사한 샘플들을 더 많이 모아 hard negative를 만들기 때문입니다. 원래는 이게 fine-grained representation을 학습하는 데 도움이 되어야 하지만, 실제 데이터셋에는 빠져 있는 positive connection이 많다 보니 이 hard negative들이 꽤 자주 false negative로 바뀌는 것이죠. 이 현상은 4M-Clean에서 더 심해지는데 이는 캡션을 정제했다고 해서 false negative 문제가 줄어드는 게 아니라, 경우에 따라서는 더 도드라질 수도 있다는 것을 알 수 있습니다.

Figure 2에서는 false negative 수가 downstream 성능에 어떤 영향을 주는지도 함께 봅니다. 먼저 batch size B는 고정한 채, GRIT-VLP의 search space, 즉 queue size M를 늘려가며 평균 IRTR score를 측정합니다. 여기서 먼저 확인되는 건 M이 커질수록 false negative 수가 증가한다는 점입니다. GRIT sampling의 탐색 공간이 넓어질수록 더 유사한 샘플들이 미니배치 안에 함께 들어오게 되고, 그만큼 false negative가 생길 가능성도 커지는 구조이기 때문입니다.
그런데 더 중요한 건 성능 추이입니다. 저자에 따르면 GRIT-VLP의 downstream 성능은 M=960을 넘기기 시작하면 오히려 하락합니다. 즉, hard negative를 더 세게 쓰면 무조건 좋은 것이 아니라, 어느 시점부터는 false negative가 너무 많아져서 오히려 “noise”처럼 작동하게 되는 것입니다. 원래는 informative hard negative를 통해 모델을 더 정교하게 학습시키려 했는데, 정작 그 negative 중 상당수가 사실상 positive였다면 학습이 꼬일 수밖에 없습니다.
저자들은 Supplementary Material에서 random sampling 환경에서도 batch size를 키우면 false negative 문제가 무시할 수 없게 된다는 점을 추가로 분석합니다. 즉, 이 문제가 꼭 GRIT 같은 특수한 sampling에서만 생기는 게 아니라, 일반적인 VLP 세팅에서도 batch가 커지면 충분히 중요해질 수 있다는 이야기입니다.
이러한 분석을 바탕으로 저자들은 MAFA를 제안합니다. 이 방법론은 hard negative의 장점은 살리되, 그 안에 있는 false negative는 제대로 관리하자는 것입니다. Figure 2에서 미리 보여주듯, MAFA는 false negative 수가 증가하는 환경에서도 IRTR score가 계속 좋아지는 경향을 보입니다.
3. Main Method: MAFA

MAFA는 크게 두 개의 축으로 구성됩니다. 첫 번째는 Efficient Connection Mining(ECM)이고, 두 번째는 Smoothed ITC(S-ITC)입니다. 전자가 false negative일 가능성이 높은 샘플을 실제 positive로 다시 복구하는 역할이라면, 후자는 아직 완전히 복구되지 못한 false negative들에 대해 loss를 좀 더 부드럽게 주는 장치라고 보면 됩니다.
3.1 Efficient Connection Mining (ECM)
ECM은 Introduction에서 말했던 “missing positive connection” 문제를 실제 학습 과정 안에서 다루기 위한 모듈입니다. paired dataset에서는 원래 짝지어진 image-text만 positive로 기록되어 있고, 그 외의 semantically close한 조합은 데이터셋에 드러나 있지 않습니다. 그래서 본래 positive일 수도 있는 샘플이 negative로 들어가 false negative가 되는 것이죠. 문제는 이걸 brute-force로 다 찾는 게 계산적으로 불가능하다는 점입니다. ECM은 바로 이 지점을 우회하려는 방법입니다.
핵심 아이디어는 모든 조합을 보지 말고, 이미 hard negative로 뽑힌 샘플만 보자는 것입니다. 어차피 false negative는 semantic하게 가까운 조합에서 나올 가능성이 높기 때문에, ITC similarity 기준으로 가장 어려운 negative들만 검사하면 훨씬 효율적으로 missing positive를 찾을 수 있다는 논리입니다.
구체적으로는 GRIT sampling으로 구성된 mini-batch 안에서, 학습 중인 모델이 각 anchor에 대해 가장 hard한 negative를 먼저 고릅니다. 그 다음에는 별도로 사전학습된 ITM 모델인 Connection Discriminator(Con-D)가 이 샘플이 진짜 hard negative인지, 아니면 false negative인지 판별합니다. 만약 Con-D가 어떤 image-text pair를 positive일 확률이 threshold τ보다 높다고 판단하면, 이 pair는 새로운 positive로 채택됩니다. 논문에서는 τ=0.8로 설정했습니다.
이제 저자들은 ECM이 실제 loss에 어떻게 반영되는지 ITC, ITM, MLM 순서로 설명합니다. 큰 방향만 먼저 말하면 ITC와 ITM에서는 label을 수정하고, MLM에서는 새로 찾은 positive pair를 추가 입력으로 활용합니다.
(a) ITC with ECM
ITC는 image와 text의 [CLS] 토큰 사이 유사도를 기준으로 positive는 가깝게, negative는 멀게 만드는 loss입니다. 기본적인 형태는 기존 contrastive learning과 같고, image-to-text와 text-to-image 양방향 cross-entropy를 평균내는 구조입니다.

ECM이 들어오면 여기서 바뀌는 건 target label입니다. 원래 ITC는 one-hot label을 사용하므로, anchor image i에 대해 정답 text 하나만 1이고 나머지는 모두 0입니다. 그런데 hard negative sampling으로 뽑힌 text tk가 Con-D에 의해 새로운 positive로 인정되면, 더 이상 기존처럼 one-hot을 유지하면 안 됩니다. 그래서 원래 정답이던 위치의 1을 0.5로 낮추고, 새롭게 positive로 판정된 k-번째 위치에도 0.5를 줍니다. 즉, 합은 여전히 1이지만, positive mass를 두 개의 샘플에 나눠주는 형태가 됩니다.
(b) ITM with ECM
ITM은 주어진 image-text pair가 matched인지 아닌지를 분류하는 task입니다. 여기서도 기본 방향은 ITC와 같습니다. Con-D가 false negative라고 판단한 샘플의 label을 negative에서 positive로 수정합니다.
다만 ITM에서는 한 가지 추가 처리가 들어갑니다. positive일 확률이 0.5와 0.8 사이인 애매한 샘플들에 대해서는 곧바로 negative라고 확정하지 않고, 아예 버린 뒤 두 번째로 hard한 negative를 다시 샘플링합니다. 저자가 보기엔 이 구간의 샘플은 진짜 negative인지 false negative인지 확신하기 어렵기 때문입니다. 그래서 애매한 샘플을 억지로 negative로 넣기보다는, 조금 더 확실한 negative를 다시 가져오는 쪽을 택한 것입니다.
이후 이러한 과정을 ITM loss에 직접 반영합니다.

여기서 pITM(i,t)는 해당 image-text pair가 matched인지 unmatched인지에 대한 모델의 예측값이고, y~ITM는 Con-D의 판단을 반영해 수정된 one-hot label입니다. 즉, ITM with ECM의 핵심은 기존 ITM의 cross-entropy 구조는 유지한 채 false negative일 가능성이 있는 hard negative의 라벨을 교정해서 학습한다는 점에 있습니다.
(c) MLM with ECM
MLM에서는 모델이 캡션의 일부 토큰을 가린 뒤, 남아 있는 텍스트 정보와 이미지 정보를 함께 이용해 이 가려진 단어를 맞히도록 학습합니다. 원래는 데이터셋에 주어진 positive image-text pair만 사용하지만, ECM이 들어가면 여기에도 변화가 생깁니다. Con-D가 새롭게 positive라고 판단한 image-text pair들을 기존 positive pair에 추가해, MLM 학습에 함께 사용합니다.

D는 원래 데이터셋에 있던 positive image-text pair 집합입니다. DECM은 Con-D가 새롭게 찾아낸 additional positive pair 집합입니다. 따라서 D∪DECM 는, 원래 positive pair와 새로 발굴한 positive pair를 모두 합친 학습 집합이라고 보면 됩니다.
3.2 Smoothed ITC (S-ITC)
저자들은 GRIT sampling에서 ITC가 자주 false negative를 만나게 된다는 점을 보고 앞서 본 것처럼 GRIT sampling은 semantic하게 비슷한 샘플들을 미니배치 안에 모아 hard negative를 구성합니다. 원래 의도는 더 어려운 negative를 통해 표현을 정교하게 학습하자는 것이지만, 실제로는 이 hard negative들 중 일부가 진짜 negative가 아니라 false negative일 가능성이 높습니다. 즉, 모델 입장에서는 positive에 가까운 샘플을 지나치게 강하게 밀어내는 문제가 생깁니다. 이를 완화하기 위해 저자들은 S-ITC(Smoothed ITC)라는 간단한 방법을 추가로 도입합니다. 핵심 아이디어는 contrastive loss에 label smoothing을 적용하는 것입니다.

여기서 yI2T(i)와 yT2I(t)는 원래의 one-hot target입니다. pI2T(i), pT2I(t)는 각각 image-to-text, text-to-image 방향에서 모델이 예측한 확률 분포입니다. 따라서 최종 타깃은 원래 one-hot label에 약간의 uniform distribution을 섞은 soft target이 됩니다
S-ITC는 정답만 절대적으로 맞고 나머지는 전부 0이라고 두지 않고 negative들에도 아주 작은 양의 확률을 나눠줌으로써, 모델이 일부 negative를 과도하게 밀어내지 않도록 만듭니다.
4. Experimental Results
이제 실험 파트입니다.
Data and Experimental Settings
먼저 실험 세팅부터 보면, MS-COCO, Visual Genome, Conceptual Captions, SBU Captions를 합쳐 총 4M개의 unique image와 5M개의 image-text pair를 사용합니다. 저자들은 이 데이터를 4M-Noisy라고 부르는데, 이유는 이 안에는 이미지 내용을 불완전하게 설명하거나 아예 틀리게 설명하는 noisy caption이 적지 않기 때문입니다. 즉, false positive 문제가 꽤 많이 섞여 있는 데이터라는 뜻입니다. 여기서 저자들은 비교를 위해 하나의 데이터를 더 만듭니다. 바로 4M-Clean입니다. 이건 BLIP captioner로 정제한 clean pair들로 구성된 같은 크기의 데이터셋입니다.
모델 구조는 이미지 인코더는 12-layer ViT, 텍스트와 멀티모달 인코더는 각각 6-layer Transformer를 사용하고, BERT-base에서 초기화합니다.
Downstream Vision-Language Tasks
사전학습이 끝난 뒤에는 세 가지 대표 downstream task에서 성능을 평가합니다. image-text retrieval(IRTR), visual question answering(VQA), 그리고 NLVR2입니다. Retrieval은 MS-COCO와 Flickr30K를 쓰고, 나머지 task 구성도 대체로 GRIT-VLP를 따릅니다.
5.3 Comparison with Baselines

비교 결과는 Table 3에 나와있습니다. 결론부터 말하면, MAFA는 여러 downstream task에서 기존 baseline보다 일관되게 더 좋은 성능을 보입니다. 특히 더 작은 데이터로 학습했는데도 ALBEF(14M)를 넘거나 BLIP(14M)에 근접하는 지표가 나온다는 점입니다. 이건 단순히 데이터를 더 많이 쓰지 않아도, 학습 과정에서 false negative를 제대로 다루면 상당한 이득을 볼 수 있다는 것을 알 수 있는 부분입니다.
GRIT-VLP와 비교했을 때도, MS-COCO에서는 IR/R@1이 +1.4%, TR/R@1이 +1.6% 오르고, NLVR2 dev에서도 +1.1% 향상됩니다. 숫자 자체가 큰 건 아니지만, 이미 강한 baseline 위에서 얻은 개선이라는 점을 생각하면 꽤 의미 있는 상승이라고 볼 수 있습니다.
또 하나 저자가 강조하는 비교는 BLIP(4M-Clean) vs. MAFA입니다. 여기서 저자들은 false positive를 줄이는 것보다 false negative를 다루는 효과가 더 클 수도 있다고 해석합니다. 또한 MAFA(4M-Clean)가 MAFA보다 더 좋은 성능을 보인다는 점을 통해, false positive와 false negative를 둘 다 잡으면 시너지 효과가 있다고도 주장합니다.
Ablation Studies

다음은 Ablation 결과입니다. Table 4를 보면, GRIT-VLP에 ECM만 추가해도 성능이 좋아지고, S-ITC만 추가해도 성능이 좋아집니다. 그리고 두 요소를 함께 넣었을 때 가장 높은 성능이 나타납니다. 즉, 두 구성요소가 각각 의미 있는 효과를 가지며, 함께 사용될 때 더 큰 성능 향상으로 이어진다는 것을 보여줍니다.
이러한 경향은 4M-Noisy뿐 아니라 4M-Clean에서도 동일하게 확인됩니다. 즉, 제안한 방법의 효과가 특정 데이터 조건에만 한정되지 않는다는 점을 보여줍니다. 특히 저자들은 MAFA on noisy dataset과 GRIT-VLP on clean dataset을 비교하면서, false positive를 줄이는 것만큼이나 false negative를 다루는 것이 중요하다는 점을 다시 강조합니다.

Table 5는 sampling 방식과 ECM의 효과를 함께 분석한 결과입니다. MAFA는 random sampling과 GRIT sampling 모두에서 성능을 향상시키지만, 그 효과는 GRIT sampling에서 더 크게 나타납니다. 이는 hard negative mining이 강하게 작동할수록 false negative를 제대로 관리하는 것이 더욱 중요해진다는 점을 보여줍니다.
또한 이 실험에서 눈여겨볼 부분은, false negative를 단순히 제거하는 것보다 이를 새로운 positive로 활용하는 방식이 더 효과적이라는 점입니다. 즉, ECM은 잘못된 negative를 걸러내는 데 그치지 않고, 기존 데이터셋에 명시되지 않았던 positive correspondence를 추가적인 supervision으로 활용합니다. 결국 저자들이 말하고 싶은 것은, 빠져 있던 positive 관계를 다시 학습에 복원하는 것이 더 효과적일 수 있다는 점입니다.

Table 6은 S-ITC의 효과를 조금 더 구체적으로 보여줍니다. 앞서 설명한 것처럼, S-ITC는 random sampling에서는 성능 향상으로 이어지지 않고 오히려 성능을 떨어뜨립니다. 이는 random sampling 환경에서는 대부분의 negative가 실제 negative이기 때문에, 이들에게 soft label을 넓게 주는 것이 도움이 되기 어렵기 때문입니다.
반면 GRIT sampling에서는 다르게 나타납니다. 이 경우 batch 안에 semantic하게 유사한 샘플이 많이 포함되기 때문에 false negative가 발생할 가능성도 함께 커집니다. 따라서 더 많은 negative에 일정 수준의 nonzero label을 주는 방식이 성능 향상에 도움이 됩니다. consistency loss가 momentum distillation보다 더 좋은 결과를 보이고, S-ITC가 그보다도 더 높은 성능을 보이는 것도 같은 흐름에서 이해할 수 있습니다. 즉, 핵심은 소수의 샘플에만 soft label을 주는 것이 아니라, 더 많은 negative에 완화 신호를 분산하는 것에 있다고 볼 수 있습니다.
이상으로 리뷰 마치겠습니다. 감사합니다.
안녕하세요 의철님 좋은 리뷰 감사합니다.
대조학습 기반에서 필연적으로 생기는 문제점을 저자가 어느정도 해결해낸 것 같네요.
어느정도 휴리스틱한 설계도 있는 것 같지만 충분히 납득할 수 있게 분석하고 해결한 것 같습니다.
혹시 해당 soft labeling 방법이나 False negative, False positive인 데이터셋들을 활용하는 방법을 연구하고 싶어서 읽으신건지 궁금합니다.
감사합니다.
안녕하세요 인택님 좋은 질문 감사합니다.
네 맞습니다. 현재 진행하는 실험에서 Contrastive Learning을 적용할때 배치 내의 네거티브 샘플을 다루는 방법에 대해 설계한 것이 있는데, 이를 어떻게 분석하면 좋을지 참고하기 위해 이번 논문 리뷰하게 되었네요.
감사합니다.
리뷰 잘 읽었습니다. 몇 가지 궁금한 점이 잇어 댓글 남깁니다
ECM에서 기존 positive와 새로 발견된 positive에 각각 0.5씩 확률을 나눠주는 방식이 재밌는거 같은데, 이 비율은 고정값인지, 아니면 상황에 따라 조정되는지도 궁금합니다. (예를 들자면 multiple positives가 있을 때?)
그리고 두번째는 ITM에서 확률이 애매한 샘플(0.5~0.8)은 버리고 다시 샘플링하는 것 같은데, 이런 샘플이 많아지면 오히려 hard negative 다양성이 줄어드는 문제는 없을까요?
안녕하세요 주영님 좋은 질문 감사합니다.
1. 논문에서는 고정값처럼 사용합니다. multiple positives일 때 어떻게 하는지는 논문에 안 나와있네요.
2. 맞습니다. 이런 샘플이 많아지면 hard negative 다양성은 줄어들 수 있습니다. 하지만 저자들은 다양성보다 false negative를 negative로 잘못 쓰는 문제를 줄이는 것을 더 중요하게 본 것 같습니다.
감사합니다.
안녕하세요 의철님, 좋은 리뷰 감사합니다.
VLP에서 false negative 문제를 정의할 때, 기존 in-batch hard negative sampling 방식의 문제점을 언급해주셨는데 해당 방식이 왜 positive를 hard negative로 판단할 위험성이 있는지에 대한 간단한 추가 설명 부탁드립니다.
그리고, con-d가 새로운 positive를 판단할 때 사용되는 threshold가 0.8이라고 언급되어 있는데, 본 threshold관련 ablation 실험이 있는지 궁금합니다.
안녕하세요 재윤님 좋은 질문 감사합니다.
기존 in-batch hard negative sampling이 위험한 이유는, negative를 고를 때 similarity가 높은 샘플을 hard negative로 뽑기 때문입니다. 그런데 VLP 데이터는 본질적으로 many-to-many 대응이라서, 현재 pair로 묶여 있지 않더라도 의미적으로는 충분히 positive일 수 있는 조합이 존재합니다. 문제는 데이터셋에는 이런 연결이 라벨로 없어서, 모델은 “정답 pair 하나만 positive, 나머지는 전부 negative”로 취급하게 됩니다. 그러면 semantic similarity가 높아서 hard negative로 뽑힌 샘플이 사실은 숨겨진 positive, 즉 false negative일 수 있는 것입니다.
그리고 threshold 관련 ablation 실험은 없습니다.
감사합니다.
안녕하세요 의철님
many to many 컨셉을 해결하는 연구가 흥미롭습니다. 물론 논문에서는 false negative로 인한 성능 하락에 대한 개선책으로 본 연구를 소개하였지만, noise 제거로 부터 오는 것인지, 특정 클래스에 대한 주변적 표현(메인 컨텍스트는 아니나 many to many 컨셉에서 이어질 수 있는 서브 컨텍스트로의 임베딩 학습)을 활용한 데이터 어그멘테이션을 통한 성능 개선인지 실험적 분석 결과가 궁금하네요.
GRIT sampling 방법에 대해 간단히 설명을 부탁드릴 수 있을까요? 혹시 놓쳤다면 죄송합니다 semantic 하게 유사한 샘플을 hard negative로 구성했을때 false positive가 많이 발생하는 이유는 무엇일까요? “배에서 물고기를 잡는 영상”에는 “헤엄치는 돌고래”(false positive)가 있으나 무시될 확률이 높다 정도로 이해하면 될까요? 그렇다면 단순 스무딩이 아니라 context 별 유사도를 고려한 metric learning 전략을 취하는 것으로 확장하는 것에 대해 어떻게 생각하시는지 궁금합니다.
좋은 리뷰 감사합니다!