오늘도 Video-Text Retrieval 논문에 대해 리뷰해보겠습니다.
- Conference: CVPR 2025
- Authors: Arun Reddy, Alexander Martin, Eugene Yang, Andrew Yates, Kate Sanders, Kenton Murray, Reno Kriz, Celso M. de Melo, Benjamin Van Durme, Rama Chellappa
- Affiliation: Johns Hopkins Applied Physics Laboratory, Johns Hopkins University, Human Language Technology Center of Excellence, DEVCOM Army Research Laboratory
- Title: Video-ColBERT: Contextualized Late Interaction for Text-to-Video Retrieval
1. Introduction
많은 비디오 데이터가 존재하는 요즘, 사람이 자연어로 “사람이 자전거를 타고 있다” 같은 쿼리를 입력하면, 거기에 맞는 영상을 빠르게 찾아주는 기술이 필요합니다. 이 때 활용되는 기술이 Text-to-Video Retrieval (T2VR) 입니다.
기존에는 쿼리와 영상을 각각 따로 인코딩하여 벡터로 만든 다음, 그 두 벡터의 유사도를 계산하는 bi-encoder 방식이 널리 사용됐습니다. 이 방식은 빠르고 효율적이지만, 복잡한 비디오와 쿼리를 하나의 벡터로 인코딩할 때 중요한 정보가 손실될 수 있다는 단점이 존재한다고 합니다. 이를 보완하기 위해 최근에는 쿼리의 단어별 임베딩과 비디오의 프레임별 표현을 정교하게 비교하는 방식이 등장했지만, 대부분 구조가 복잡하거나 여전히 표현력에 제한이 있기도 했죠
저자는 원래 텍스트 검색 분야에서 높은 성능을 보인 ColBERT라는 모델에서 착안해, 이를 영상 검색에 맞게 확장한 Video-ColBERT를 제안하였습니다. 제안하는 Video-ColBERT에서는 쿼리 단어 하나하나가 영상 프레임을 직접 비교할 수 있고, 시간 정보가 반영된 특징과 정적인 프레임 feature를 동시에 활용한다고 합니다. 그리고 학습할 때도 기존처럼 전체 확률을 계산하는 게 아니라, 각 쌍이 맞는지 아닌지를 따로 판단하는 이진 분류 방식을 써서 학습 안정성을 높였다고 합니다.
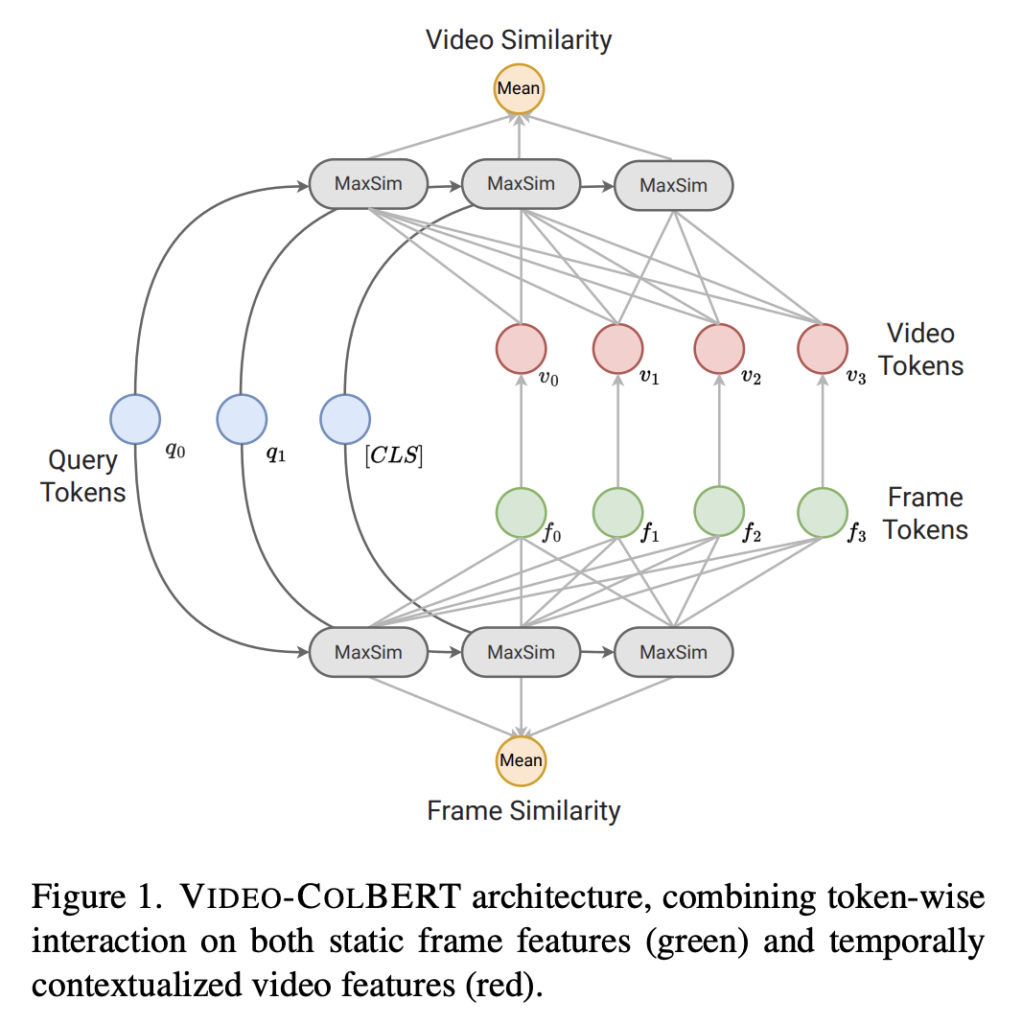
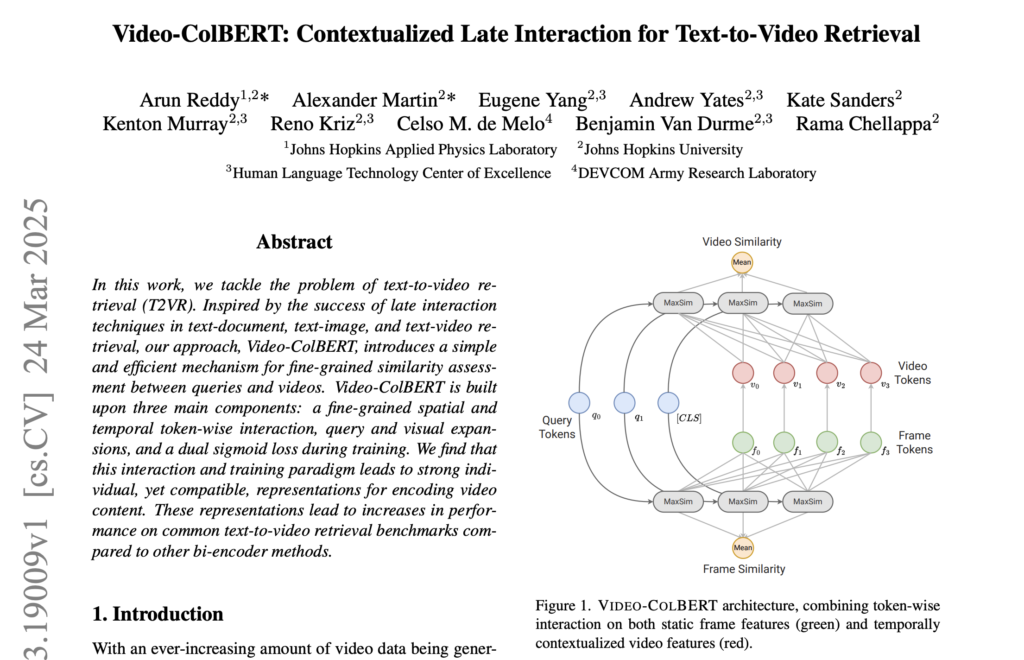
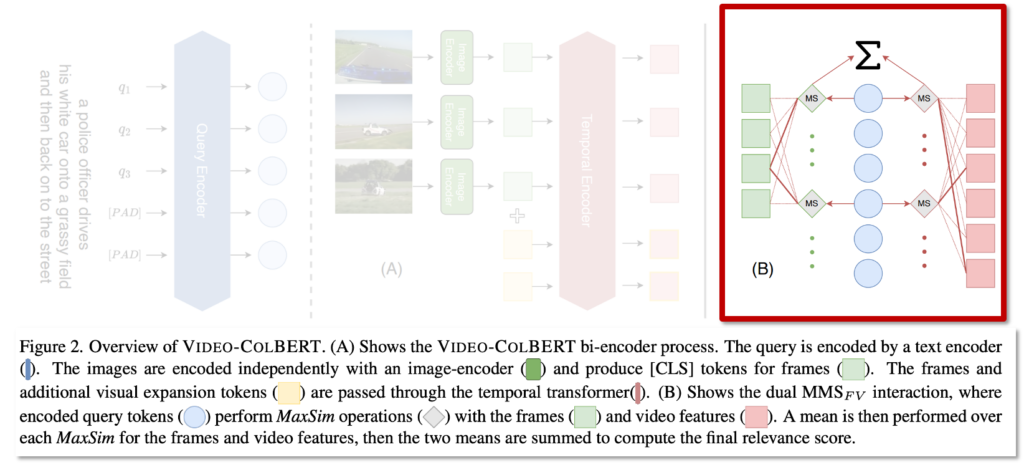
상단 그림 1이 Video-ColBERT의 간략한 구조를 파악할 수 잇습니다. 기존의 평균 기반 방식은 영상 내용을 하나의 벡터로 뭉뚱(?)그려 표현하지만, Video-ColBERT는 쿼리의 각 단어가 영상 내의 다양한 시점과 내용에 개별적으로 대응될 수 있도록 하여 훨씬 더 정밀한 매칭이 가능하다는 점을 강조하는 그림이라고 할 수 있겠네요. 자세한 내용은 다음 단원에서 설명드리겠습니다.
2. Preliminaries
2.1 Interaction Mechanisms
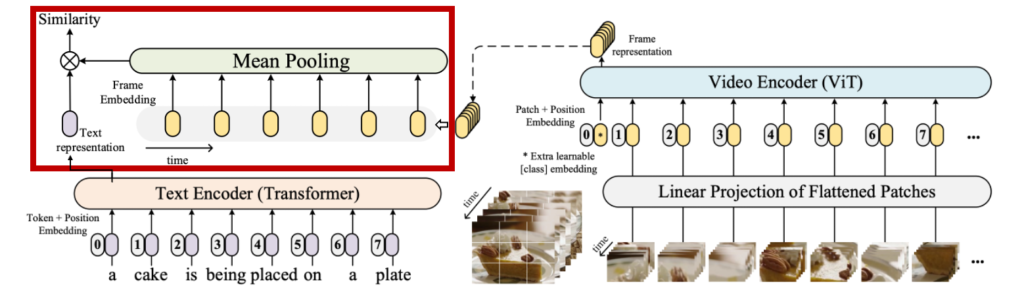
쿼리의 단어들이 비디오 프레임과 어떻게 상호작용해야 쿼리-비디오 간 유사도를 잘 계산할 수 있을지에 대해서는 여러 방식이 존재합니다. 가장 간단한 방식 중 하나는 상단 그림의 CLIP4Clip처럼 비디오 프레임 feature들을 mean pooling하여 하나의 벡터로 만들고, 쿼리도 마찬가지로 단일 벡터로 표현한 뒤 두 벡터 간 내적을 계산하는 방식입니다.
이는 빠르고 구현이 간단하다는 장점이 있지만, 쿼리와 비디오를 하나의 벡터로만 표현하는 것이 충분한 표현력을 가질 수 있을지에 대해서는 의문이 있을 수밖에 없습니다. 특히 쿼리의 문장이 길어지고, 비디오의 내용이 복잡해질수록 이러한 단일 벡터 방식은 정보 손실의 가능성이 커지게 되죠.
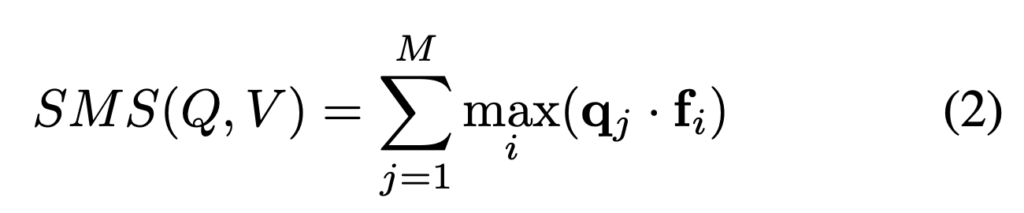
이를 보완하기 위해 저자는 ColBERT에서 제안된 방식처럼, 쿼리의 각 단어 임베딩이 비디오 프레임별 feature를 직접 비교하며 가장 유사한 프레임을 선택하는 MaxSim 기반의 fine-grained matching을 도입하였습니다. 이는 쿼리 단어 각각이 비디오 내에서 가장 유사한 프레임을 선택한 후, 해당 유사도를 모두 합산하는 구조로 되어 있습니다. 상단 수식 (2)처럼 표현되는 이 방식은 SMS(Sum of Max Similarities)라고 부르며, 각 단어가 비디오 전체를 스캔하여 가장 잘 맞는 프레임을 찾고, 그 유사도만을 모아서 최종 점수를 계산합니다.
즉, 단일 벡터 방식이 전체 내용을 하나의 평균으로 뭉뚱그려 비교한다면, SMS 방식은 훨씬 정밀하게 쿼리 단어마다 가장 관련 있는 비디오 프레임을 선택해 비교하는 방식이라고 볼 수 있습니다. 본 논문에서 제안하는 Video-ColBERT는 이 SMS 방식의 아이디어를 기반으로 비디오 검색에 특화된 정교한 상호작용 구조를 구성하였다고 합니다.
3. Method
이제 저자가 제안하는 VIDEO-COLBERT에 대해 설명드리겠습니다.
3.1 Fine-Grained Spatial & Temporal Interaction
앞서 소개된 SMS 방식은 쿼리의 각 단어가 비디오 프레임들과 유사도를 비교한 후, 가장 유사한 프레임의 값을 선택하고 이를 모두 더해 최종 유사도를 구하는 방식이었습니다. 하지만 이 방식은 쿼리의 길이에 따라 결과가 과도하게 영향을 받을 수 있습니다.
이를 보완하기 위해 저자는 mean 연산을 사용해 쿼리 길이의 영향을 줄이기 위한 MMS(MeanMaxSim) 방식을 제안하였고, 이를 spatial 특성과 temporal 특성에 각각 적용하였습니다.
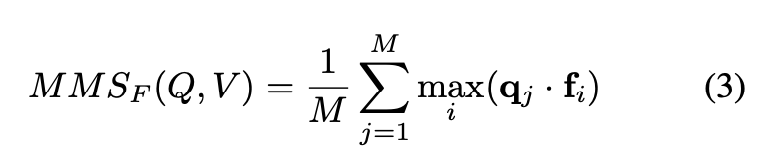
먼저, MMS_F는 비디오의 정적인 프레임 feature들에 대해 쿼리 단어와 1:1로 유사도를 계산하고, 그 중 가장 높은 값을 뽑아낸 뒤 쿼리 단어 전체에 대해 평균을 취하는 방식입니다. 여기서 비디오 feature는 vision transformer로부터 추출한 [CLS] 토큰을 사용하였다고 합니다.
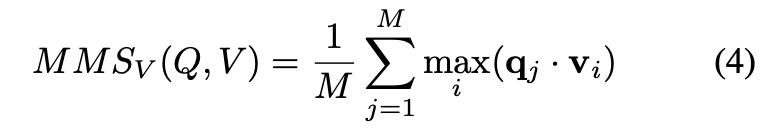
하지만 단일 프레임 feature만으로는 시간 흐름에 따라 등장하는 이벤트나 관계를 포착하기 어렵기 때문에, 저자는 temporal transformer layer를 통해 시간적 맥락이 반영된 비디오 feature를 추가로 구하였습니다. 이때 생성된 feature들을 대상으로 동일한 방식의 MMS 연산을 적용한 것이 MMS_V입니다.
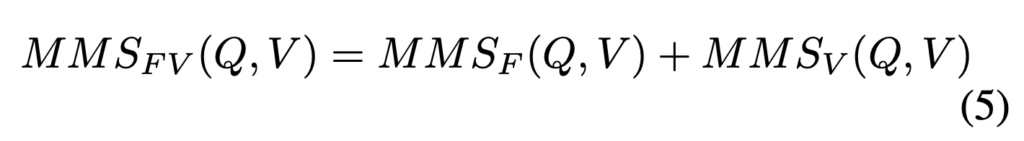
이렇게 얻은 MMS_F (spatial)와 MMS_V (temporal)를 더한 MMS_FV가 Video-ColBERT의 최종 유사도 점수가 됩니다. 이 때 재밌는게, MMS_FV 계산 시 오직 쿼리→비디오 방향으로만 비교를 수행하고, 반대 방향은 고려하지 않는다는 점입니다. 이는 쿼리와 비디오 사이의 비대칭성을 인정하고, 비디오에 등장하지 않는 쿼리 단어가 결과에 영향을 주지 않도록 하기 위함이라고 합니다.
즉, MMS_F는 정적인 배경이나 물체와의 연관성을 잘 포착하고, MMS_V는 동적인 이벤트나 시퀀스 개념을 포착하는 데 유리합니다. 이 둘을 결합함으로써 Video-ColBERT는 다양한 시간적・공간적 수준에서의 정밀한 매칭이 가능해졌다고 정리할 수 있겠습니다.
3.2 Query & Visual Expansion
뿐만아니라, 저자들은 ColBERT에서 제안된 soft query augmentation 기법을 참고하여 쿼리 확장(query expansion)을 도입하였습니다. ColBERT에서는 쿼리 토큰 뒤에 padding 토큰을 추가하면 토큰 간 상호작용에서 검색 성능이 개선된다고 실험으로 보였었다고 합니다. 이러한 padding 토큰은 단순한 빈칸이 아니라, 학습 가능한 “확장된 쿼리 표현”으로 활용되며, 본래 쿼리가 암시하고 있는 추가적인 의미(예: 관련된 단어)를 학습을 통해 반영할 수 있도록 도와준다고 합니다.
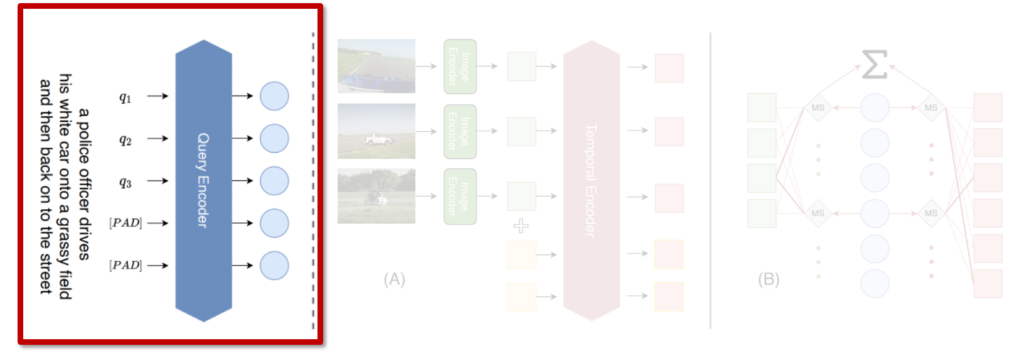
Video-ColBERT에서도 이러한 아이디어를 따라, 쿼리 입력에 pad 토큰을 추가하여 MMS_F와 MMS_V 두 연산에서 모두 활용하였습니다. 이로 인해 모델은 쿼리의 정보만으로는 잡히지 않는 의미까지 포착할 수 있는 여지(?)가 생기게 되죠
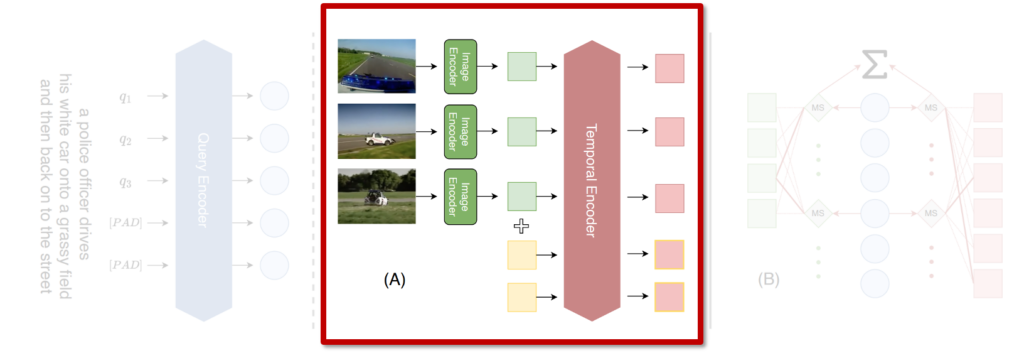
또한 이러한 확장 개념은 비디오에도 동일하게 적용됩니다. 기존 연구를 참고해서, temporal transformer에 입력으로 넣는 프레임 [CLS] 토큰 외에도 visual expansion tokens(노란색박스)을 함께 입력하도록 하였습니다. 이로써 transformer는 기존에 없던 시각적 개념도 학습을 통해 확장할 수 있게 되고, 더 풍부한 표현으로 비디오를 이해할 수 있게 된다고 합니다
3.3 Dual Sigmoid Loss
기존의 bi-encoder 기반 Text-to-Video Retrieval 모델에서는 일반적으로 InfoNCE 기반의 softmax loss를 사용해 학습을 진행했습니다. 이 방식은 텍스트-비디오 간 유사도를 계산하고, 정답 쌍은 높은 점수를, 나머지 쌍은 낮은 점수를 갖도록 softmax 정규화를 통해 학습을 유도합니다. 하지만 이 방식은 전체 배치 단위의 정규화를 필요로 하고, negative 샘플의 선택에 매우 민감하다는 단점이 있습니다. 실제로 좋은 negative 샘플을 선정하기 위해서는 별도의 hard negative mining 모델이 필요할 수 있는데, 저자가 정의한 문제 상황은 그런 모델을 처음부터 학습하려는 상황이기 때문에 이러한 방식은 적합하지 않을 수 있습니다.

이러한 이유로 최근 이미지-텍스트 retrieval 분야에서는 softmax 대신 sigmoid 기반의 binary classification loss를 활용하는 방식이 좀 인기를 끌고 잇고, 저자 역시 이를 반영해 Video-ColBERT 학습 시 sigmoid loss를 사용하였다고 합니다. sigmoid loss는 각 텍스트-비디오 쌍에 대해 일일이 맞는지(+1), 틀린지(-1)를 판단하는 이진 분류 문제로 바꾸어 학습을 진행합니다. 이 방식은 softmax에 비해 전역 정규화가 필요 없어 계산이 간단하고, 노이즈에 더 강인하다는 장점이 있습니다.
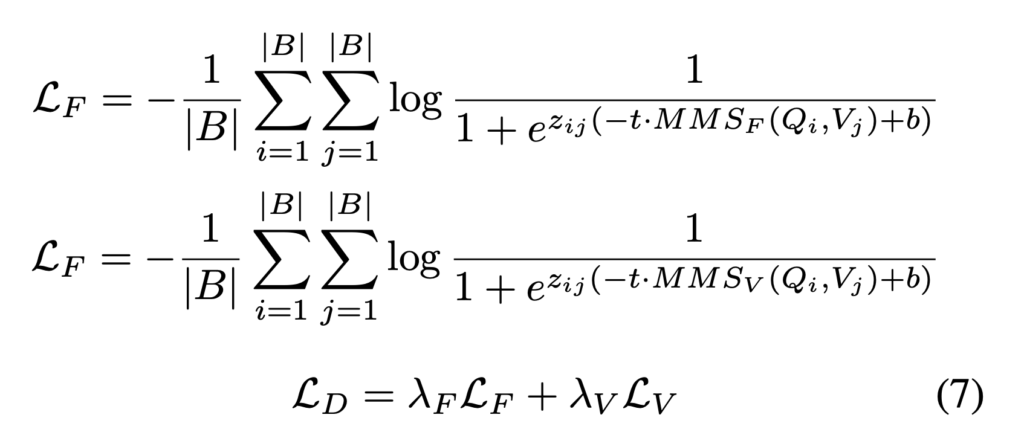
이렇게 sigmoid loss를 기반으로 하되, Video-ColBERT에서는 정적인 feature(MMS_F)와 시간적 feature(MMS_V)의 중요도가 서로 다르고 크기도 다르다는 점을 고려해, 이 두 유사도 행렬에 대해 각각 독립적인 sigmoid loss를 적용하였습니다. 즉, MMS_F[latex/]와 [latex]MMS_V 각각에 대해 별도로 sigmoid loss를 계산한 후, 두 손실을 합쳐 최종 loss로 사용하는 dual loss 구조를 제안한 것입니다. 상단 수식(7)로 보면 각각의 loss를 L_F, L_V로 정의하고, 이를 λ_F, λ_V라는 하이퍼파라미터 가중치로 조절해 전체 loss를 구성합니다.
이러한 설계는 두 가지 측면에서 효과적인데, 첫째는 multi-loss scaling 문제를 피할 수 있다는 점이고, 둘째는 프레임 단위 feature와 비디오 전체 feature가 더 독립적으로 학습될 수 있도록 유도한다는 점입니다.
4. Experiments
4.1 Dataset
- MSR-VTT
- MSVD
- VATEX
- DiDeMo
- ActivityNet
4.2 Benchmark Results
논문에서는 다양한 sentence-to-video 및 paragraph-to-video retrieval 벤치마크에서 Video-ColBERT의 성능을 평가하였습니다.
Table 1 – Sentence-to-Video Retrieval (MSRVTT, MSVD, VATEX)
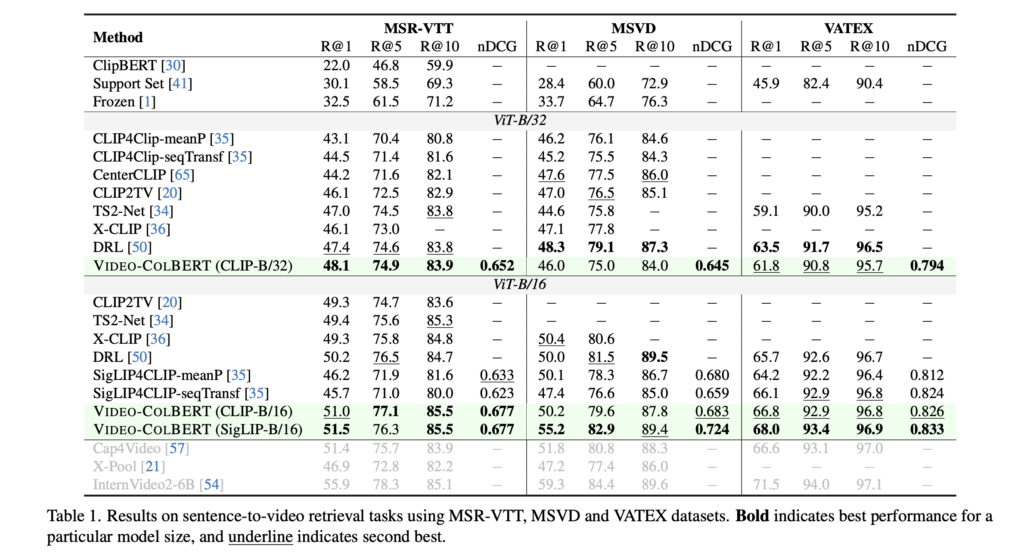
CLIP-B/32를 backbone으로 사용했을 때, Video-ColBERT는 기존 방법들보다 전반적으로 높은 성능을 보였습니다. 특히, token-level interaction을 사용하는 다른 방법들과 비교해도 더 간단한 구조에서 뛰어난 성능을 보였고, patch-level 정보를 활용하는 정교한 방식들보다도 앞서는 성능을 보였습니다. 다만 MSVD와 VATEX에서는 DRL이 더 높은 성능을 보였는데, 이는 DRL이 decorrelation regularization과 학습 가능한 token weighting을 사용했기 때문이라고 합니다.
한편, ViT-B/16을 backbone으로 교체한 경우 Video-ColBERT의 성능은 더욱 향상되어, SigLIP-B/16과 결합했을 때 MSRVTT, MSVD, VATEX 세 데이터셋 모두에서 새로운 SOTA를 달성했습니다. 이처럼 backbone의 성능 개선뿐 아니라, 두 단계의 tokenwise interaction 방식 자체가 중요한 성능 기여 요소였다는 점이 강조될 수 있습니다.
Table 2 Paragraph-to-Video Retrieval (DiDeMo, ActivityNet)
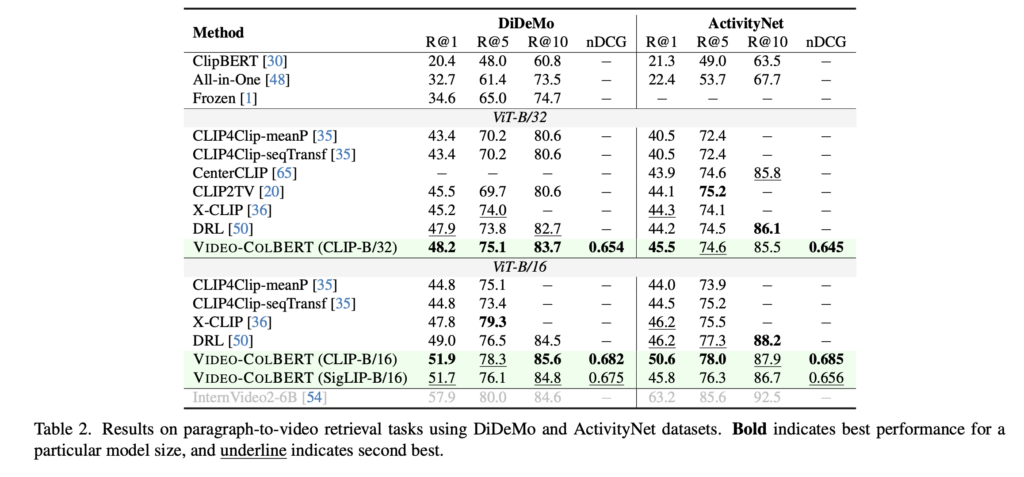
긴 문장인 Paragraph 수준의 쿼리를 사용하는 DiDeMo와 ActivityNet 실험에서도 Video-ColBERT는 좋은 성능을 보여주었습니다. DiDeMo에서는 세 가지 backbone을 모두 사용할 때 고르게 우수한 성능을 기록했습니다. ActivityNet에서는 CLIP-B/16 기반의 모델이 기존 방법들에 비해 월등한 성능 향상을 보였지만, SigLIP 기반 Video-ColBERT는 상대적으로 낮은 성능을 보였습니다.
저자는 그 이유로, SigLIP이 최대 16개 토큰 길이의 짧은 텍스트로 pretraining 되어 있기 때문에, 긴 자막이 자주 등장하는 ActivityNet과의 부적합이 성능 저하로 이어졌을 가능성을 말했습니다. 전반적으로 Video-ColBERT는 다양한 쿼리 길이와 시나리오에서 강력한 성능을 보이며, 특히 fine-grained interaction 구조가 길고 복잡한 표현에서도 효과적임을 보여주었습니다.
4.3 Additional Analysis & Discussion
Table 3 – Interaction Mechanisms
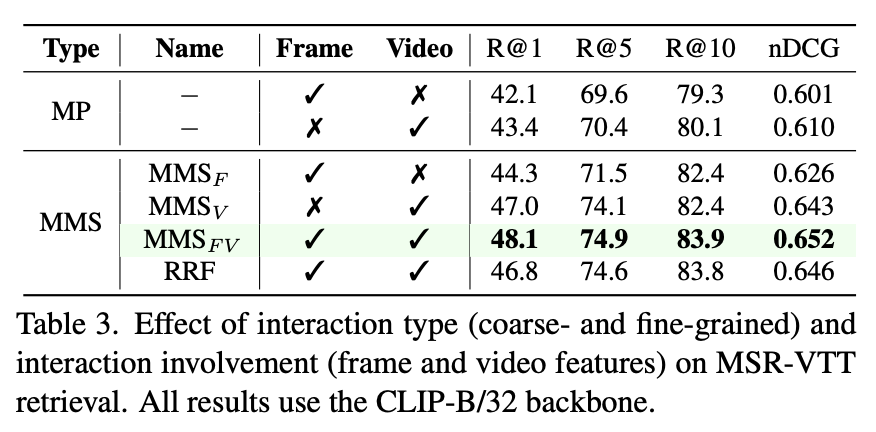
세 가지 interaction 방식에 대한 성능 비교 실험에서는, coarse한 방식인 mean pooling(MP)보다 fine-grained tokenwise similarity 방식이 훨씬 더 뛰어난 성능을 보였습니다. 특히 MMS_F(정적 프레임 기반 similarity)는 MP보다 높은 성능을 보였고, temporal transformer를 활용한 MMS_V(시간 정보 반영)는 MMS_F보다도 더 큰 성능 향상을 이끌어냈습니다. 두 방식의 장점을 결합한 MMS_FV는 가장 우수한 결과를 보였고, 이는 정적 개체 정보와 시간적 변화 정보가 상호보완적인 관계라는 점을 확인하는 부분이라고 하네요.
또한 두 유사도 점수를 단순히 합산하는 것이 reciprocal rank fusion(RRF) 방식보다도 더 나은 성능을 보였는데, 이는 MMS_F와 MMS_V 각각의 점수가 실제로 의미 있는 차이를 담고 있음을 시사한다고 합니다. 결과적으로, frame-level과 video-level의 두 관점이 독립적이면서도 상호보완적으로 작용하며 retrieval 성능을 극대화시킨다는 점을 실험적으로 입증했다고 볼 수 있습니다.
Table 4 – Choice of Loss Function
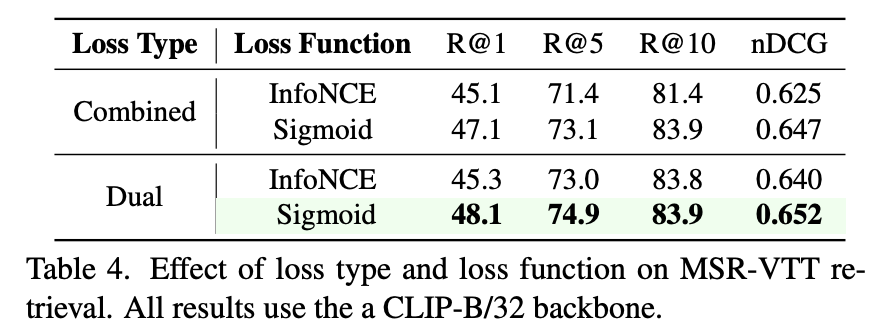
기존에 사용되던 InfoNCE loss와 비교하여 sigmoid 기반의 binary loss가 얼마나 효과적인지를 비교한 실험도 있습니다. 결론적으로, sigmoid loss가 InfoNCE 보다 검색 성능에서 더 뛰어난 결과를 보였으며, 이는 특히 노이즈가 많은 데이터셋에 대해 더 강인하게 작동함을 보였습니다. 여기서 중요한건 CLIP-B/32 백본이 sigmoid 기반으로 사전학습된 것이 아님에도 불구하고, sigmoid loss를 활용해 파인튜닝만으로도 성능 향상을 이끌어냈다는 점입니다.
또한 frame-level과 video-level similarity를 따로 학습하는 dual loss 방식이, 두 유사도를 단순히 합산해 하나의 similarity matrix로 학습하는 combined 방식보다 더 우수한 성능을 보였습니다. 이는 각 수준의 특징이 독립적으로 학습될 때 더 강한 표현력을 만들고, 개별 interaction에 대한 loss function이 모델 성능을 높이는데 의미한다고 볼 수 있다고 하네요
Table 5 – Query Augmentation
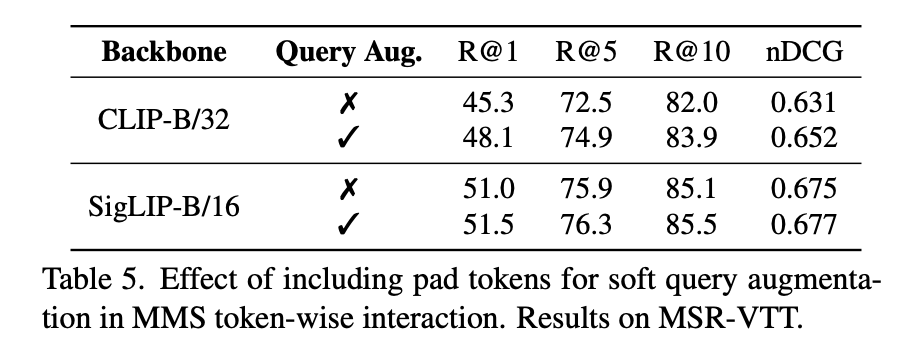
Table 5에서는 ColBERT에서 제안된 soft query augmentation 기법을 Video Retrieval에 적용했을 때의 결과입니다. CLIP과 SigLIP 백본 모두에서 쿼리에 padding 토큰을 추가했을 때 token 단위 MMS에서 성능이 향상되는 결과를 보였습니다. 특히 CLIP의 경우, 그 향상폭이 더 두드러졌는데, 이는 CLIP의 텍스트 인코더가 causal attention 구조를 사용해 문장 앞쪽 토큰이 뒤쪽 정보를 참조할 수 없는 구조이기 때문입니다. 이런 구조에서는 토큰의 문맥화가 제한되어 상호작용 효과가 떨어지지만, padding 토큰을 통해 전체 쿼리 내용을 참고할 수 있는 새로운 soft query를 만들면서 이 한계를 보완할 수 있었다고 합니다. 반면 SigLIP은 양방향 self-attention을 사용하기 때문에 이미 쿼리 토큰이 문맥화되어 있어 padding의 효과가 제한적이었지만, 여전히 성능이 약소하게 증가함을 보였죠
5. Conclusion
정리하자면, 본 논문에서는 정교한 토큰 단위의 상호작용 방식을 통해 공간적, 시공간적 정보 모두를 활용하는 Text-to-Video Retrieval 기법인 Video-ColBERT를 제안하였습니다. 특히, T2VR 분야에서 처음으로 sigmoid 기반 loss를 사용한 dual sigmoid loss formulation을 도입하였다는 점이 큰 novelty 입니다. 이는 공간과 시간 정보를 잘 인코딩하면서도 retrieval 단계에서 두 정보를 효과적으로 통합할 수 있게 해줍니다. 또한, 짧은 쿼리에 대해 padding 토큰을 통한 쿼리 확장이 retrieval 성능 향상에 기여한다는 것도 실험으로 확인하였습니다. 다양한 실험으로 저자가 주장하는 바를 차근차근 증명해서 제안하는 방법론의 설득력을 높인 것 같네요
안녕하세요. 리뷰 잘 읽었습니다.
초반부에 설명해주신 MMS(MeanMaxSim) 방법에 대해 질문이 있습니다.
쿼리의 길이에 따른 영향을 줄이기 위한 방법론으로 소개되었는데, 정작 가장 높은 값은 쿼리에 평균내버리면, 본 목적의 Retrieval을 위해 핵심이 되는 정보를 오히려 억누르게하는 방법이 아닌지싶어 질문 남깁니다.
우선 MMS는 쿼리 길이에 따라 유사도가 과도하게 커지는 걸 방지하려고 MaxSim 결과를 평균내는 방식입니다. 따라서 상인님이 말씀하신대로 중요한 토큰이 덜 중요한 토큰에 의해 희석될 수 있다는 단점이 분명한 것 같습니다.
다만 논문에서는 이걸 보완하기 위해 frame-level(MMSF)과 video-level(MMSV)을 분리해서 각각 따로 학습하고, dual sigmoid loss를 써서 표현력을 유지하고자 하였습니다
안녕하세요. 리뷰 잘 읽었습니다.
단어가 내용에 개별적 대응되도록 설계하였다고 소개해주신것이 흥미롭습니다. 이는 video retrieval 수행에 있어 해석가능성을 갖게될 여지가 생긴것으로 보이는데, 이러한 부가적 이점에 대한 언급이나, 해당 분야에서 해석 가능성을 어떻게 다루고 있는지 궁금합니다.
둘째로는 텍스트와 비전 도메인의 불균형이 있다고 말씀해주셨는데, 본 논문은 특히 텍스트 쿼리에 노이즈나 생략된 것이 많음을 가정한다고 이해했습니다. 그러나 이는 연구실 래벨의 video datasets에만 한정된다고 생각합니다. 즉, real world video 에는 텍스트 쿼리 못지 않게 중복과 생략이 많을 것 같은데, 혹시 이러한 가정이 real world와의 괴리성이 있을 수 있다고 생각하시는지 궁금합니다.
감사합니다.
굉장히 좋은 댓글이네요. 차근차근 답변 드리겠습니다
A1. 말씀하신대로 Video-ColBERT는 쿼리의 각 단어가 비디오 내 특정 시점과 직접 대응하도록 설계되어, 어떤 단어가 어떤 장면과 대응되는지 추적할 수 있어 해석 가능성이 높다고 할 수 있을 것 같습니다. 실제로 temporal transformer를 통과한 후 word-scene 대응이 정적 개념에서 동적 맥락으로 바뀌는 모습이 시각화한 결과를 보이기도 했죠.
A2. 본 논문은 텍스트 쿼리가 종종 생략되기도 하고 추상적이라는 가정 하에 query augmentation과 sigmoid loss를 도입했는데, 현실에서는 비디오 쪽도 중복이나 노이즈가 많기 때문에 이 가정이 다소 일방적일 수 있다는 생각도 들었습니다.
안녕하세요 주영님 리뷰 감사합니다.
본문에서 temporal transformer layer를 통해 시간적 맥락이 반영된 비디오 feature를 추가한다고 하셨는데, 이 동작 방식이 어떻게 되는지 궁금합니다. 각 프레임에 단순히 position encoding을 적용한 후 self-attention만 수행하는 것인지, 아니면 그 외에 추가적으로 사용되는 기법이 있나요?
감사합니다.
댓글 감사합니다.
아쉽게도 말씀하신 대로 Video-ColBERT의 temporal transformer는 포지셔널 인코딩 외에 별도의 시간적 기법은 사용하지 않는 듯 합니다.