안녕하세요. 이번에는 MLLM의 Token Pruning에 대한 분석을 담은 논문을 들고 왔습니다. 본 논문을 읽게 된 계기가 참 긴데, 현재 제가 진행 중인 실험과 연관되어 있습니다. 스토리가 있다 보니, 다음 세미나에서 간단히 소개해드리겠습니다. 본 논문의 리뷰를 읽다 보면 무릎을 치고 “아,” 하는 부분이 하나 있습니다. 여태 연구해오고 CVPR/ICCV/ECCV 등, 유명 학회에 실리던 방법론들이 사실은 랜덤 보다도 못하다는 점인데, 저 또한 이 논문을 읽기 전 랜덤 Token Pruning을 진행해보았었고, 그 성능이 제가 비교하려던 방법론 보다도 높단 점에서 충격을 받고 해매던 도중, 이 논문을 발견해 얼른 읽어보게 되었습니다. 우선 리뷰 진행하며 중간 중간 사견을 첨가하겠습니다.
Introduction
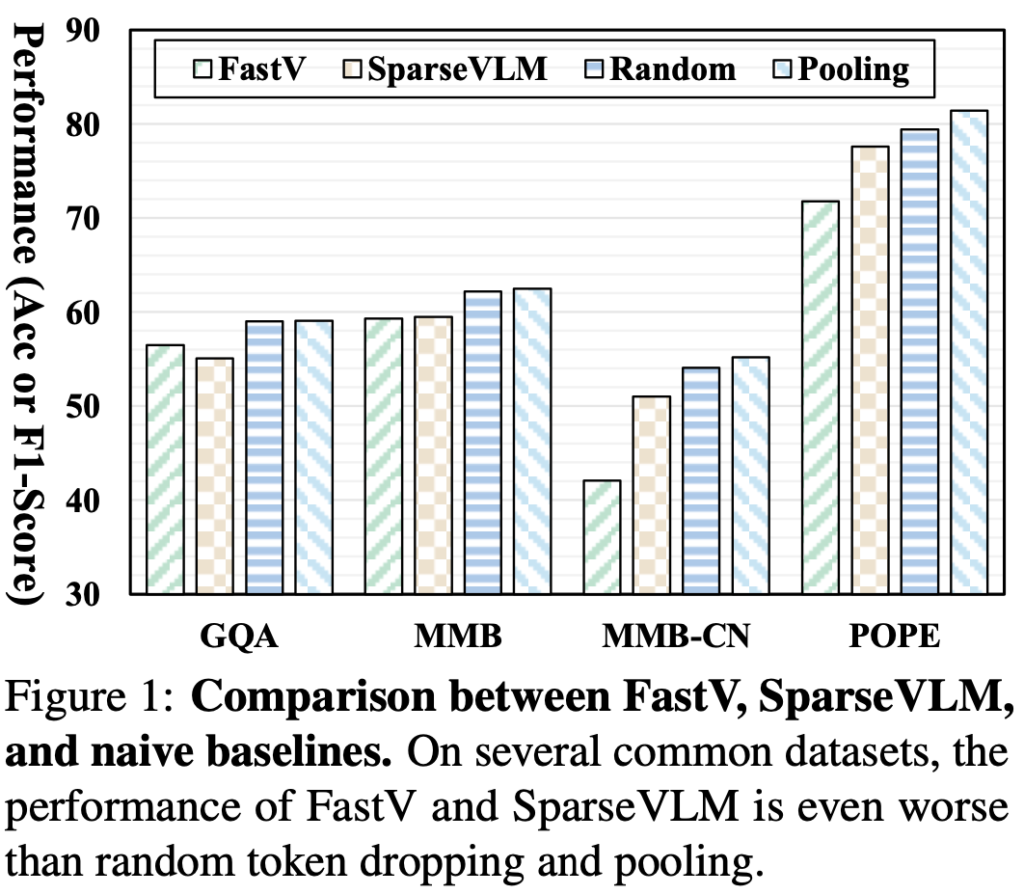
위 Figure 1이 본 논문의 전반을 담은 핵심입니다. MLLM에 대한 뛰어난 능력과 그에 반하는 계산 비용/자원의 부담은 당연한 전제로, Token pruning은 계산양을 줄이기 위해 흥미로운 연구 주제입니다. 실제로 24년 이후 현재까지, 일 년에만 CVPR 등의 주류 학회나 저널에만 50편 이상의 논문이 나오는 등 여전히 MLLM의 성능을 향상하기 위한 연구가 진행되는 반면, 한 측면에서는 그들의 활용성을 위한 연구도 활발히 진행되고 있습니다. MLLM에서 Token Pruning이 가능한 이유 중 하나는 LLM이 서로 다른 길이의 토큰을 처리할 수 있기 때문이며, 이들의 연구는 크게 두 갈래로 진행되고 있습니다. 하나는 CLIP 비젼 인코더의 출력으로 나오는 비젼 토큰의 개수를 줄이는 방법 (LLavA-PruMerge / TRIM), 또 다른 하나는 LLM의 트랜스포머 레이어의 연산 중에 비젼 토큰을 줄여나가는 방법 (FastV / SparseVLM)입니다.
하지만, Figure 1을 보면 저자는 FastV (2024 ECCV Oral)과 SparseVLM (ICML 2025)가 LLaVA의 몇몇 벤치마크 (GQA/MMB/MMB-CN/POPE)에서 사실은 random/pooling의 나이브한 접근에 비해 오히려 성능이 낮다는 점을 확인했습니다. “Surprisingly, the two base- lines outperform the two well-designed token pruning methods in most benchmarks by a clear margin.” 이 결과는 곧 이전 방법들의 중요한 토큰에 대한 (pruning을 진행하기 위해 구분하는) 이해가 사실과는 다르다는 점을 증명하며 저자는 현재 이전 방법에 비해 본인들의 성능을 향상시키는 데에만 초점이 맞춰져 있는 것이 (사실은 랜덤 보다도 낮은 성능을 보이는) Token pruning의 장기적인 발전을 저해한다고 봅니다. 이에 대해 본 논문은 Token pruning에 대한 근본적인 질문을 던지고 실험적으로 증명하여 앞으로 나아가야 할 방향성을 제시합니다.
Benchmarking
비교 실험을 위해 모델/데이터셋/Token pruning 방법을 잘 선정해야 합니다. 저자는 LLaVA-1.5-7B, LLaVA-Next-7B, Qwen-VL을 선택합니다. 실험을 보면 대부분 LLaVA-1.5-7B에서 이루어지는데, 정작 제가 원하는 실험 (Visual Grounding)에선 어떤 모델을 사용한지 명확히 나와있지 않아 아쉽습니다 (메일은 보냈지만, 요즘엔 답변을 못 받는게 당연해보이네요). 이 모델들은 GQA, MMBench, MME , POPE, Science QA, VQA(v2/text), VizWiz의 LLaVA 벤치마크와 RefCOCO의 Grounding, 마지막으로 최근 소개된 Object retrieval 중 하나인 Visual Haystack을 수행합니다. Token pruning은 FasV, SparseVLM, MustDrop으로 앞의 두 방법은 LLM에서 토큰을 줄여나가는 방법 (Training-free), 뒤의 MustDrop은 KV Cache (이 논문을 읽어보지 않아 확실히 알지 못합니다)를 통해 LLM에서 줄이고 그 앞의 CLIP 비전 인코더의 출력 토큰도 줄이는 방법에 해당합니다. 이제 저자가 생각하는 Token pruning에 대한 근본적 질문과, 그에 대한 실험 비교를 살펴봅니다.
1. Token Pruning Revisited: Are Simple Methods Better?
Figure 1의 FastV/SparseVLM과 Random이나 Pooling 방법을 비교합니다. Random은 말 그대로 랜덤하게 x%의 토큰을 제거하는 방식이며 Pooling은 CLIP의 특정 개수의 토큰을 묶어 평균으로 풀링하는 방식입니다. 이들은 새로운 방법론이라고 하기는 어렵습니다. 하지만, LLaVA 벤치마크에서의 성능은 오히려 세심하게 설계한 방법론들 (Vanilla FastV/SparseVLM)에 비해 성능이 높습니다. 아래 Table 1에서 LLaVA-1.5-7B를 Vanilla 성능 (100%)로 두고 성능 저하 차이를 비교할 때, Random과 Pooling은 (Retain 144 Tokens, 75% Pruning 기준) 각각 95.0%, 96.4%인 반면 Vanilla FastV와 SparseVLM은 89.8%, 93.5%로 더 낮은 성능을 보입니다. 이 결과는 Retain 64 Tokens, 87.5% Pruning 기준에서도 마찬가지이며 전체적으로 볼 때도 Random과 Pooling이 약 2/3의 벤치마크에서 더 높은 성능을 보입니다.
1.1 Token Distribution: Spatial Uniformity Outperforms Position Bias

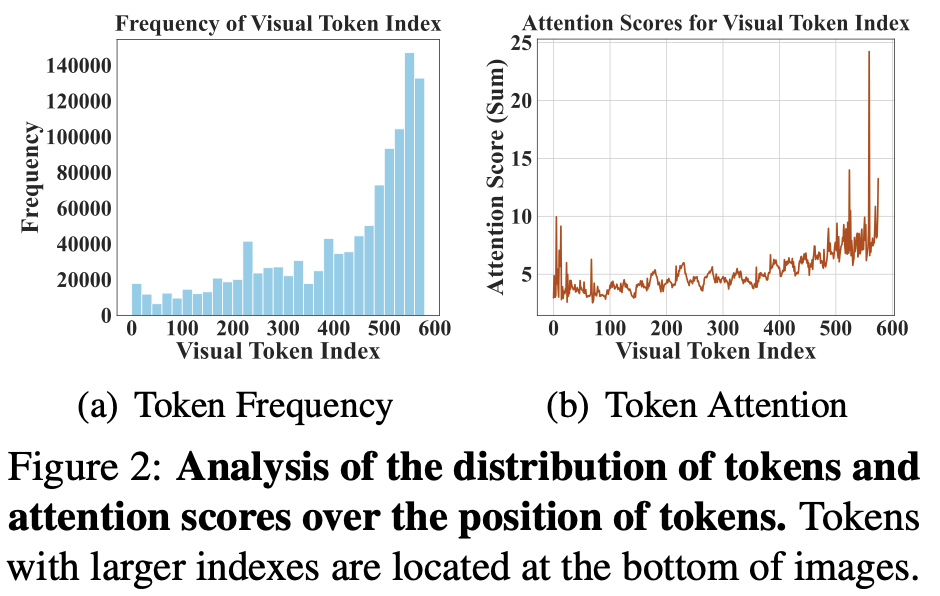
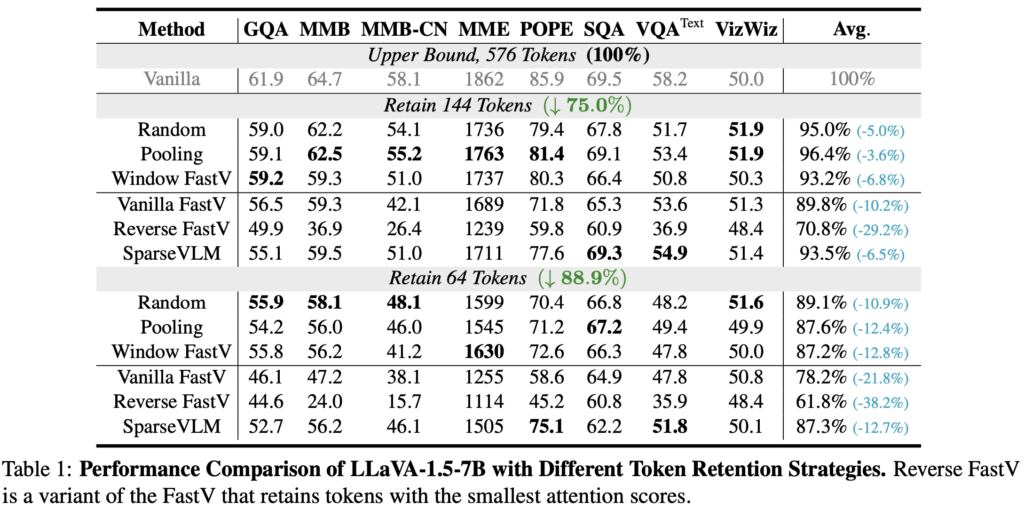
저자는 위 결과가 왜 나온지에 대해 분석하고자 합니다. FastV를 예시로 볼 때, 이 방법은 비젼 토큰에 주어지는 Attention score를 기준으로 중요 토큰을 선별하고, 기준 점수에 비해 낮은 특정 토큰을 선택해 제거합니다. POPE 데이터셋의 8,910개의 샘플로 분석해 보았을 때, Figure 2와 Figure 3에 보이는 바와 같이 Token이 남은 비율 (Figure 2-(a))과 Token에 대한 Attention score (Figure 2-(b))는 곧 비젼 토큰의 마지막 시퀀스 (즉, 이미지로 따지면 하단 부분)가 주로 살아남는 것을 발견했습니다. 왜 그런지에 대한 분석은 없지만 (모델 내부 학습 중의 과정이므로 설명력은 어려움) 이는 곧 Attention score에 의존해서 살아남을 토큰을 선택하는 것이 곧 심각한 Position bias (이미지 하단 부의 토큰만 살아남게 되는)를 보인다고 주장합니다. 반면, Random이나 Pooling은 당연히도 그런 Position bias를 가지지 않습니다. 이 결과를 시각적으로 비교해 보면 Figure 3의 (a) Vanilla FastV를 보면 이해에 좋습니다. 이에 대해 저자는 토큰이 공간적으로 균일한 (Spatial Uniformity) 것이 중요하며, 그 이유가 기존 방법론들의 성능이 저하되는 이유로 분석합니다.
1.2 Validating the Hypothesis: From Position Bias to Spatial Uniformity
위 분석을 증명하고자, 저자는 FastV에 공간적 균일성을 부여하고 (Window FastV) 이를 실험합니다. 간단히 Sliding Window 메커니즘을 FastV에 적용해서 각 윈도우 마다 사전에 정의한 특정 비율만큼만 토큰을 제거하게 만듭니다. 이렇게 하면 전체 토큰에 대한 특정 비율을 제거할 때보다 윈도우로 그 범위를 제한하기에 이미지 상단부의 토큰이 많이 살아남을 것입니다. 이에 대한 시각적 예시는 Figure 3-(b)에 해당합니다. 이 결과는 다시 Table 1로 돌아가보면 Vanilla FastV와 Window FastV를 비교 시 동일한 75% Pruning 시 3.4%의 성능 향상, 87.5% Pruning 시에는 9%의 성능 향상을 보입니다. 이 실험적 결과는 결국 Token pruning 시 공간적으로 균일하게끔 토큰을 남겨두어야 함을 증명합니다. 하지만 여전히 Random/Pooling이 더 좋습니다만, 적어도 이들을 저자의 전제를 증명하기엔 충분해보입니다.
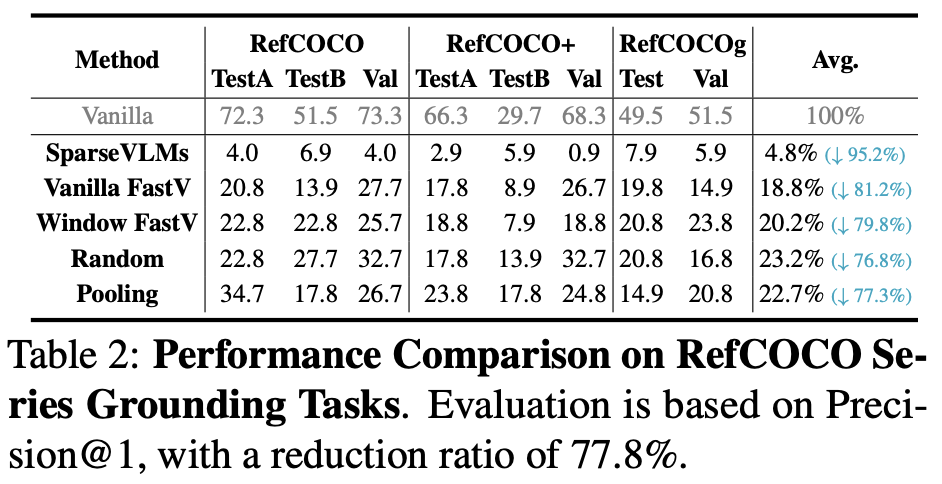
공간적 균일성을 증명하기 위해 즉, 토큰이 공간적 위치에 대한 이해의 중요성을 조사하고자 Referring Expression Comprehension (Reference 문장에 대해 Bounding Box/Segmentation Mask를 생성해내는) 태스크에 적용합니다. 바로 이 때 제가 궁금한 점이 Table 2에서 Vanilla가 과연 Table 1과 같이 LLaVA-1.5-7B일까 입니다. 왜냐하면 원래 LLaVA는 Visual Grounding 결과가 잘 나오지 않습니다. 무슨 말이냐면 저도 직접 LLaVA 데모로 Bounding Box로 대답을 요청해도, 대답은 0~1의 절대좌표와 같은 방식으로 나옵니다. 하지만 이 좌표도 어떤 형식인지 이해하기 힘듭니다. 그래서 저자에게 메일로 LLaVA를 활용했는지, 활용했다면 어떤 방식으로 입력 프롬프트를 넣은지에 대해 여쭤보았습니다. 우선 Table 2의 결과를 보면, Vanilla FastV 대비 1.4%의 성능 향상을 보입니다. 큰 성능 향상으로 볼 수는 없지만 제 생각에서 이 또한 저자의 주장을 증명하기엔 충분하며, 더욱이도 Random/Pooling이 공간적 균일성을 가진다는 전제에서 두 부류 (SparseVLMs, Vanilla FastV / 그 이외)의 성능을 비교할 때 분명한 성능 차이를 보입니다. 다음은 위 저자의 전제와 실험에 대한 요약입니다.

2. Language in Visual Token Pruning: When and Why Does Language Matter?
다음은 Visual Token Pruning 시에 Language (텍스트) 정보가 필요한지 또는 필요하지 않은지에 대해 질문을 던집니다. FastV, SparseVLM, MustDrop은 텍스트 정보를 활용하는 반면, FasterVLM은 비젼 정보에만 의존합니다. 저자는 다음의 가설을 질문합니다: 언어 정보가 특히 중요한 작업이 부족해서 그 중요성이 드러나지 않은 것일까? 이 가설을 증명하기 위해 저자는 Visual Haystack 태스크를 선정합니다. 해당 태스크는 수 많은 이미지가 포함된 셋에서 복잡한 질문에 대해 특정 이미지를 찾아내는 Retriveal 태스크입니다. 해당 태스크에서는 복잡한 질문에 대해, 그 질문에 대한 이해가 필요한지가 중요합니다.

LLaVA-1.5-7B를 베이스로 타 방법론의 비교를 위해 저자는 FastV에서 비젼 토큰만 활용하는 (텍스트의 영향력을 제거한) FastV_VIS를 실험했습니다. 실험 결과, FastV와 FastV_VIS 비교 시 성능이 하락한 모습을 보인다고 합니다. 다만 궁금한 점은 위 표에서 Input Images가 많을 수록 더 어려운 태스크인데, Input Images 10에 대해선 FastV_VIS가 미약하지만 더 높은 성능을 보이는데 말이죠. 저자의 말로는 SparseVLM이 텍스트의 영향을 받는데, 이들이 77.8%의 토큰을 줄이는 데에도 불구하고 베이스라인 (LLaVA)와 거의 유사한 성능을 보인다는 점에서 텍스트의 영향이 중요하다고 합니다. 하지만 본 표에는 나와있지 않지만 VQA 벤치마크에서는 FastV와 SparseVLM보다 텍스쳐 정보의 안내를 받지 않는 (비젼 토큰만 활용하는) 방법들이 훨씬 더 좋은 성능을 보이는데, 그러므로 저자는 태스크에 따라 텍스트의 정보의 필요성이 좌지우지된다고 주장합니다. 즉, Pruning은 태스크의 필요성에 따라 달리 쓰여야 한다는 점입니다. 다음은 해당 전제에 대한 저자의 요약입니다.

3. The α Dilemma: Importance vs. Redundancy in Token Pruning
다음은 Task-agnostic한 관점에서, 입력 패턴에만 초점을 둡니다. 다시 말하자면 Pruning 시 입력의 구조적인 무결성을 보존한 채 정보 손실을 최소화하면서 중복 토큰을 제거하는 것입니다. Mutual Information의 관점에서 저자는 본래의 토큰 X 와 Pruning 이후 남은 토큰 X^{'} 에 대해 정보량을 최대화하도록 보존함을 목표하며, 다음과 같이 공식화합니다.
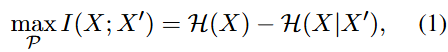
\mathcal{P} 는 Pruning 전략으로, Mutual Information이 최대가 되는 전략을 찾음에 있습니다. 이때는 Task-specific을 고려하지 않고 구조적 패턴만 보존합니다.
3.1 Importance Criteria
그에 반면, Task-oriented 기준에서는 target의 출력 Y를 고려합니다. 이 때의 토큰 중요성은 태스크의 예측 정확도를 보존함에 있습니다. 이 때 공식은 아래와 같습니다. 결국, Task-agnostic에서는 토큰의 입력 패턴만 고려한 반면, Task-oriented에서는 target prediction을 고려합니다.
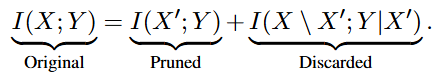
3.2 Empirical Validation of Adaptive Criteria Balancing
저자는 최종적으로 위의 두 Task-agnostic인 패턴의 유니크함과 Task-oriented인 target prediction을 고려하는 이 둘을 가중치로 두어 중요 토큰을 선정할 필요가 있음을 언급합니다. 그 이유는 결국 태스크에 따라 이 둘 중 어느 것이 좋을지는 실험적으로 나오기 때문인데, 제 사견에서 이 점은 일반화성을 해칩니다. 다음 식의 알파를 태스크마다 선정해야 한다는 의미는 곧 데이터마다 그 특성이 다른데, 이는 해당 섹션의 제목의 Adaptive보다는 Empirical로 봐야한다는 의견입니다. 다시 본문으로 돌아와 저자는 FastV에서 Attention score를 활용한 부분을 수정하여 아래 식의 Score를 활용하며, 이 결과는 다음의 Table 4에서 확인할 수 있습니다.
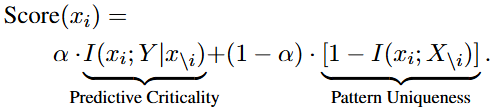
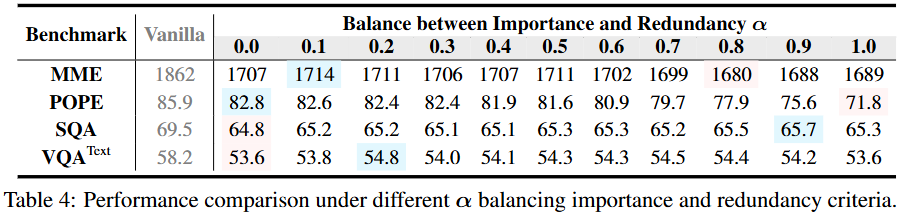
Table 4의 결과에서 MME와 POPE는 Perception이 중요한 태스크이며, 반면 SQA와 VQA(Text)는 Knowledge가 중요한 태스크입니다. 그 점에 따라 Perception이 중요한 태스크에서는 패턴의 유니크함 (알파가 0에 가까울 때 성능이 높음)이, 반면 Knowledge가 중요한 태스크에서는 Target prediction이 (알파가 1에 가까울 때 성능이 높음) 중요하단 점을 알 수 있습니다.

4. The Overlooked Role of Training-Aware Compression in MLLMs
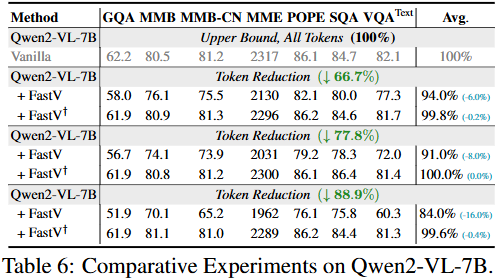
마지막은 최근 Qwen2-VL, MiniCPM-V-2.6 등의 최근 MLLM은 학습 과정에서 토큰 압축 전략을 수행합니다. 예를 들어 Qwen2-VL은 학습 시 인접한 4개의 토큰을 하나로 압축하는데, 이 때 저자는 다음의 직관적 의문점을 제기합니다: MLLM이 이미 훈련 도중 압축 기술을 수행했으면, 우리가 Inference 시에 Pruning 방식을 디자인하고 평가할 때 이를 고려해야할까요? 이들 모델에서 인코딩된 토큰들이 고압축된 정보를 가지고 있기 때문에, 동일한 수의 비젼 토큰을 지운다면 비교적으로 더 큰 정보 손실을 가져올 것입니다. 이를 위해 훈련 시 압축을 사용하는 Qwen2-VL-7B-Instruct4를 선정하고 FastV의 Pruning 방식을 적용해보았습니다. 구체적으로 하나는 학습 단계에서 수행된 토큰 압축을 무시하고, 다른 하나는 이를 고려했습니다. 위 Table 6의 결과를 보면, 훈련 시의 압축을 고려할 때 동일한 Pruning 방식이 다양한 감소율에서 Vanila와 거의 동등한 성능을 보이는 것을 확인할 수 있습니다. 이는 곧 MLLM에게 던지는 메시지로, 학습 시 토큰 압축 기술에 더 많은 관심을 기울여야 할 것을 시사합니다.
오랜만에 분석 논문을 읽었습니다. 제 실험에 막히는 부분이 있어 이 간지러운 부분을 긁어주길 기대했으며, 분명 그 점은 아쉬웠지만 그럼에도 저도 Pruning을 위한 새로운 시각을 지녀야할 것을 염두해둘 수 있는 좋은 기회였습니다.
안녕하세요. 리뷰 잘 읽었습니다.
입력에 pruning을 적용하여 효율성을 높이는 방법으로 attetion score 기반 pruning과 information 보존을 위한 방법에 대한 분석을 소개해주신 것으로 이해했습니다. 조금 단순한 질문이지만, 위 방법 모두 attention score와 데이터의 정보량을 예측하려면 이미 학습 된 모델이 필요로 할 것 같습니다. 그렇다면 해당 pruning은 어느 단계에서 활용되는 것 인지 알 수 있을까요?
만약 inference 단계에서 활용되기 위함이라면, 학습때 활용되지 않은 데이터셋에 학습 데이터로 구축된 pruning 방식이 효과적인 것으로 이해하면 될지 궁금합니다.
감사합니다.
안녕하세요. 좋은 질문 감사합니다.
우선 비젼 분야에서 pruning의 목적은 “모든 비젼 토큰을 다 쓰지 않으면 연산량이 작아 속도가 빠르며, 이 때 성능을 최대한 보존함”에 있습니다. 이 과정에서, 이미 학습 된 모델은 일반적으로 LLaVA를 생각해주시면 됩니다. 이 pruning은 LLaVA의 LLM 단계 연산에서 활용되며, 말씀해주신 것 처럼 inference를 위해 활용합니다. 위 목적에 따라 학습 때 활용되지 않은 데이터 셋과 학습 데이터 간의 차이는 있고 그럼에도 이들의 방식이 어느정도 효과적이지만 (우리가 LMM에 기대하는 것이 그렇기에) pruning이 그 관점에서 바라보지는 않습니다.
리뷰 잘 읽었습니다. 질문이 있어 댓글 남기겠습니다.
1. Spatial Uniformity가 성능 향상에 효과적이라는 주장을 실험적으로 잘 뒷받침하고 있는 것 같지만, 해당 분석이 특정 벤치마크나 모델(LLaVA-1.5)에만 국한된 것은 아닌가 하는 생각이 드는데.. 다른 모델 구조나 벤치마크 실험은 없었을까요?
2. 그리고 테이블1 Window FastV의 성능 향상이 Spatial Uniformity 때문인지, 아니면 단순히 특정 영역의 중요성이 반영된 것인지 구분이 잘 안되는데, 이 둘을 분리해서 결과를 본건 없었나요?
안녕하세요. 질문 감사합니다.
1. 음, 물론 말씀하신 바 처럼 다양한 모델에 적용해봄이 더 좋을 듯 합니다. 다만, 아직 그런 다양한 모델에 적용해봐야한다는 단계까지가 아닌 것으로 확인됩니다. MLLM하나를 잡고, 대표적으로 LLaVA로, 그 모델에서 다양한 Pruning 기법을 적용해보는 수준의 기술 성숙도로 확인됩니다. 이 때 벤치마크 또한 마찬가지입니다.
2. Window FastV의 방식이 곧 Spatial Uniformity이자 특정 영역의 중요성이 좀 더 반영될 수 있다고 생각 (그 둘 모두)합니다. 아무래도, Window 방식 자체가 결국 꼼꼼히 볼 수 밖에 없기 때문이죠.
안녕하세요 상인님, 흥미로운 분석 논문 리뷰 감사합니다!
1절에서, 기존 방법론의 attention 이후 비주얼 토큰에서는 모델이 암묵적으로 하단부의 정보가 중요하다는 spatial한 bias를 학습했다는 뜻으로 이해했습니다. 모델 내부 학습 중의 과정이므로 설명하기엔 분석이 어려울 수 있다는 의견 남겨주셨지만, 그 부분에서 순수한 궁금증이 생겼는데요.
해당 bias는 마치 CNN 계열의 locality inductive bias처럼, VLM 모델구조 속 cross-attention 혹은 self-attention만의 간접적인 inductive bias인 셈으로도 이해해도 될까요? 아니면 단순 internet scale 학습 데이터 자체가 position bias를 가져 생긴 data-inductive bias 라고 이해해야 될까요?
감사합니다.
안녕하세요. 리뷰 읽어주셔서 감사합니다.
질문에 있어 제 생각에 이는 attention에서 생기는 inductive bias로 보여집니다.
data-inductive가 아닌 model-inductive로 보는 것이 옳을 텐데, 이 때 attention 연산에서 발생하기 때문에 설명적인 분석은 어렵다는 의미입니다.