안녕하세요. 최근 MER2026 Challenge의 Track 1, MER-Cross: Interlocutor Emotion을 살펴보다가 흥미로운 문제를 발견했습니다.
기존 multimodal emotion recognition은 보통 영상 속 사람이 “어떤 감정을 표현하고 있는가”를 맞히는 문제로 다뤄졌습니다. 즉, 말하고 있는 사람의 얼굴, 목소리, 발화 내용을 보고 그 사람의 감정을 예측하는 방식이죠. 그런데 MER-Cross는 조금 다릅니다. 이 track에서는 말하는 사람(speaker)의 감정이 아니라, 그 말을 듣고 있는 상대방(interlocutor)의 감정을 예측해야 합니다.
이 차이가 생각보다 중요합니다.
speaker의 감정은 audio, text, facial expression처럼 직접적인 단서가 비교적 많습니다. 반면 listener의 감정은 훨씬 간접적입니다. listener는 말을 하지 않을 수도 있고, audio나 text 정보가 없을 수도 있으며, 감정이 얼굴에 강하게 드러나지 않을 수도 있습니다. 결국 모델은 speaker의 발화와 상황 맥락, 그리고 listener의 미묘한 visual reaction을 함께 보고 “상대방이 지금 어떤 감정을 느끼고 있을까?”를 추론해야 합니다.
이 관점에서 MER-Cross는 단순한 multimodal fusion 문제가 아닌 다음과 같은 질문에 가깝습니다.
대화 속에서 한 사람의 발화와 행동은 상대방의 감정 상태에 어떤 영향을 주는가?
그리고 일부 modality가 빠져 있거나 비대칭적으로 주어진 상황에서도, 모델은 그 상호작용을 복원할 수 있는가?
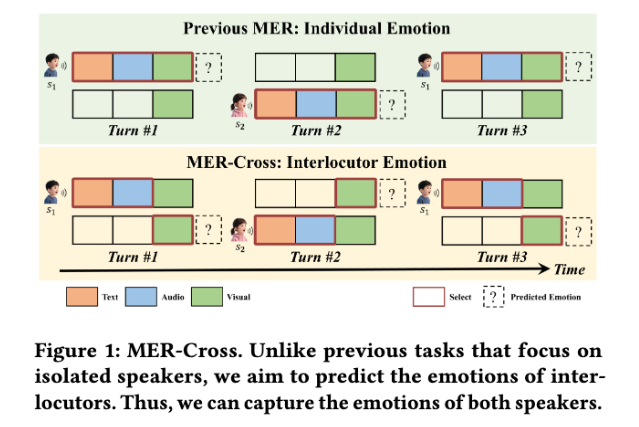
Figur 1이 MER-Cross의 challenge를 잘 보여주는데요. 이 질문을 가지고 challenge baseline 논문의 저자인 Zheng Lian 연구자의 이전 논문들을 살펴보면, GCNet이 특히 눈에 들어옵니다. GCNet은 conversation setting에서 발생하는 incomplete multimodal learning 문제를 다루는데요. 실제 대화 데이터에서는 모든 발화에 audio, visual, text modality가 완벽하게 존재하지 않을 수 있고, 기존 방법들은 이러한 불완전성을 충분히 다루지 못한다는 문제의식에서 출발합니다.
흥미로운 점은 이 문제가 MER-Cross와 꽤 닮아 있다는 것입니다. MER-Cross에서도 입력은 대칭적이지 않습니다. speaker 쪽에는 audio/text가 있지만, listener 쪽에서는 visual cue가 핵심 단서가 됩니다. 다시 말해, 모델이 다뤄야 하는 것은 “완전한 multimodal sample 하나”가 아니라, 서로 다른 역할을 가진 두 사람 사이에 부분적으로만 관측된 multimodal interaction입니다.
그래서 이번 리뷰에서는 GCNet을 단순히 “incomplete modality를 복원하는 논문”으로만 읽지 않고, 다음 질문을 중심으로 살펴보려고 합니다.
GCNet의 graph completion 관점은 MER-Cross의 interlocutor emotion recognition 문제를 푸는 데 어떤 힌트를 줄 수 있을까?
특히 GCNet이 제안하는 Speaker GNN과 Temporal GNN이 대화 속 speaker dependency와 temporal dependency를 어떻게 모델링하는지, 그리고 classification과 reconstruction을 함께 학습하는 방식이 MER-Cross의 비대칭 입력 구조에 어떻게 응용될 수 있을지에 집중해서 읽어보도록 하겠습니다. 그러면 리뷰 시작하도록 하겠습니다.
1. Introduction
대화 이해는 dialogue system, recommender system 등에서 중요합니다. 또한, 대화 이해에서 multimodal learning은 한 발화의 텍스트, 음성, 얼굴 영상 등을 함께 사용해 감정이나 의미를 더 정확히 파악하는 방법을 의미하는데요. 예를 들어 “괜찮아”라는 말도 목소리와 표정에 따라 실제 감정이 달라질 수 있습니다.
incomplete multimodal learning은 이 모달리티 중 일부가 없는 상황에서 학습하거나 예측하는 문제를 뜻합니다. 예를 들어서, 실증 상황에서는 음성 누락, 텍스트 오류, 얼굴 검출 실패 같은 현실적 이유로 모달리티 누락이 자주 발생할 수 있는데요. 이는 대화 이해에서 심각한 문제로 이어집니다. 왜냐하면 대화 감정이나 의미는 여러 모달리티가 서로 보완하면서 드러나는 경우가 많기 때문입니다.
그런데, 기존 연구들은 주로 개별 발화나 의료 영상에서의 모달리티 누락 문제를 다루었다고 합니다. 그러나 대화 데이터에는 개별 발화와 다른 두 가지 정보가 있는데요. 첫째, 인접 발화는 의미적으로 연결되는 경우가 많다는 것. 둘째, 같은 화자는 한 대화 안에서 비교적 일관된 표현 방식을 보일 수 있다는 것 입니다. GCNet은 바로 이 두 정보를 활용합니다.
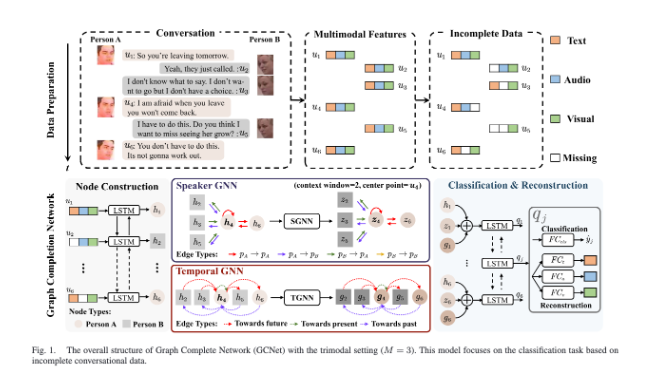
Figure 1을 통해 GCNet의 전체 구조를 파악할 수 있습니다. 세 모달리티 상황에서 대회 발화를 입력으로 받아, 누락된 모달리티를 포함한 특징을 만든 뒤, node construction, SGNN, TGNN, classification, reconstrction을 거치는 구조를 확인할 수 있습니다.최종적으로 논문의 contribution은 다음과 같이 정리할 수 있습니다.
- 의료 영상이나 개별 발화가 아니라 대화 데이터의 불완전 모달리티 문제를 연구함.
- GCN이라는 그래프 기반의 프레임워크를 제안해 화자 정보와 시간 정보를 사용함
- 3개의 벤치마크 대화 이터셋에서 SOTA 보다 좋은 성능을 보임.
2. Methodology
논문에서는 누락 모달리티가 있는 대화 데이터의 classification task를 다루는데요. 각 대화는 여러 발화로 구성되고, 각 발화에는 accoustric, lexical, visual feature로 구성되어 있습니다.
2.1 Data Preparation
대화는 $C=\{(u_i,y_i)\}_{i=1}^{L}$로 정의됩니다. 여기서 $L$은 발화 수, $u_i$는 $i$번째 발화, $y_i$는 정답 레이블을 의미합니다. 각 발화 $u_i$는 특정 화자 $p_{s(u_i)}$가 말하게 되는데요. 발화 특징은 $x_i=\{x_i^m\}_{m\in\{a,l,v\}}$로 나타내며, 여기서 $a$는 음향, $l$은 어휘, $v$는 시각 모달리티를 의미합니다.
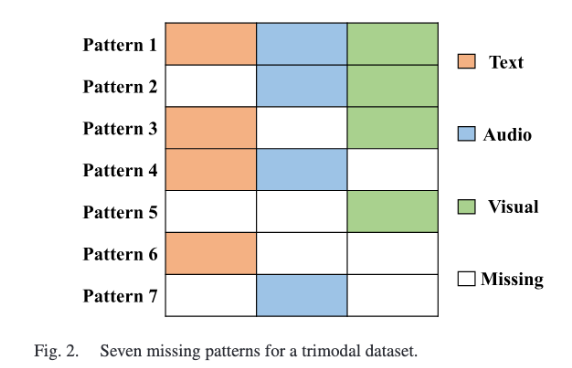
논문에서는 현실의 누락 상황을 흉내 내기 위해 각 샘플에서 일부 모달리티를 무작위로 버리되, 최소 하나의 모달리티는 남기기로 하였는데요. 이는 Figure 2를 통해서 확인할 수 있습니다. $M$개 양식이 있을 때 가능한 누락 패턴은 $2^M-1$개로, 세 모달리티이면 가능한 패턴은 7개입니다. $\sigma_i$는 발화의 누락 패턴이고 $\phi(\sigma_i)$는 그 패턴에서 사용 가능한 모달리티 집합을 의미합니다. 발화의 불완전 표현은 $\tilde{x}_i = \{\lambda_m^i x_m^i\}_{m \in \{a,l,v\}}$ 라고 하며, $\lambda_m^i$ 는 다음과 같이 정의됩니다.
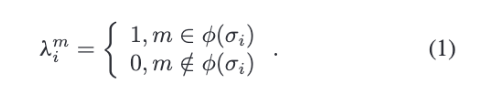
발화에서 모달리티 $m$이 존재하면 1, 없으면 0을 표시하는 수식으로, 스위치처럼 동작한다고 이해하시면 좋을 것 같습니다.
2.2 Graph Completion Network
GCNet은 세 부분으로 구성되는데요. 첫째는 node construction, 둘째는 SGNN과 TGNN, 셋째는 classification & Reconstrction입니다.
2.2.1 Node Construction
먼저, 각 발화는 하나의 노드 $v_i$가 됩니다. 불완전한 멀티모달 특징 $\tilde{x}_i = \{\lambda_m^i x_m^i\}_{m \in \{a,l,v\}}$ 는 Bi-LSTM을 사용해 context 정보를 반영한 초기 노드 표현 $h_i$를 만듭니다.
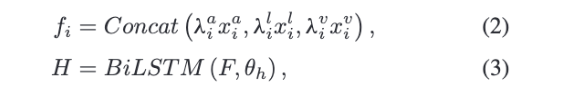
여기서 $F=\{f_i\}_{i=1}^{L}$이고, $H=\{h_i\}_{i=1}^{L}$이며, 각각 Bi-LSTM의 입력과 출력입니다. $\theta_h$는 학습되는 매개변수이고, 마지막으로 $H=\{h_i\}_{i=1}^{L}$는 초기 노드 표현으로 사용됩니다.
2.2.2 Speaker GNN and Temporal GNN
GCNet은 같은 엣지를 공유하지만 엣지 유형은 다르게 정의하는 두 그래프 신경망을 사용하는데요. SGNN은 화자 유형을 쓰고, TGNN은 시간 유형을 씁니다.
엣지는 전체 대화의 모든 발화를 다 연결하지 않습니다. 논문에서는 저장과 최적화 부담을 줄이고 local context를 반영하기 위해 context window 크기 $w$를 사용하였습니다. 노드 $v_i$는 $[i-w,i+w]$ 범위 안의 노드와만 상호작용하도록 설정하였습니다.
SGNN은 speaker type을 사용해 대화 안의 화자 의존성을 포착하는데요. 논문에서는 각 엣지 $e_{ij}$에 화자 유형 식별자 $\alpha_{ij}\in\alpha$를 부여합니다. 여기서 $\alpha$는 가능한 화자 유형들의 집합을 의미합니다. 엣지 $e_{ij}$의 화자 유형은 $p_{s(u_i)}\rightarrow p_{s(u_j)}$과 같이 정해집니다.
여기서 $p_{s(u_i)}$는 발화 $u_i$를 말한 화자이고, $p_{s(u_j)}$는 발화 $u_j$를 말한 화자를 의미합니다. 만약 대화에 서로 다른 화자가 $S$명 있다면, 가능한 화자 유형의 최대 개수는 $|\alpha|=S^2$를 뜻합니다.
이 설정이 중요한 이유는 같은 문장이라도 누가 말했고 누구의 발화와 연결되는지에 따라 의미가 달라질 수 있기 때문인데요. 논문에서는 각 화자가 대화 안에서 자기만의 표현 방식을 가질 수 있고, 이 표현 방식이 대체로 일관될 수 있다고 봅니다. 따라서 화자 유형은 누락된 양식을 보완하고 발화를 분류하는 데 중요한 단서가 됩니다.
TGNN은 temporal type을 사용해 대화 안의 시간 의존성을 포착합니다. 논문에서는 각 엣지 $e_{ij}$에 시간 유형 식별자 $\beta_{ij}\in\beta$를 부여하는데요. 여기서 $\beta$는 가능한 시간 유형들의 집합을 의미합니다. 시간 유형은 노드 $v_i$와 $v_j$가 대화 안에서 어떤 상대적 위치에 있는지에 따라 정해집니다. 논문에서는 세 가지 시간 유형을 사용하는데, {past, present, future}를 사용합니다. 따라서 시간 유형의 개수는 $|\beta|=3$을 가지게 됩니다.
쉽게 말하면, 현재 발화 $u_i$를 이해할 때 이전 발화가 주는 정보와 이후 발화가 주는 정보는 다릅니다. 이전 발화는 현재 발화의 원인이나 배경일 수 있고, 이후 발화는 현재 발화의 의미를 확인해 주는 반응일 수 있습니다. TGNN은 이런 시간 방향의 차이를 구분해서 정보를 모으는 역할을 합니다.
논문에서는 R-GCN(Relation Graph Convolutional Network)이 관계 모델링 문제에서 효과적이었다고 말하는데요. 그래서 GCNet은 이 아이디어를 이용해 SGNN과 TGNN에서 이웃 노드 정보를 모으게 됩니다. 계산 공식은 다음과 같습니다.
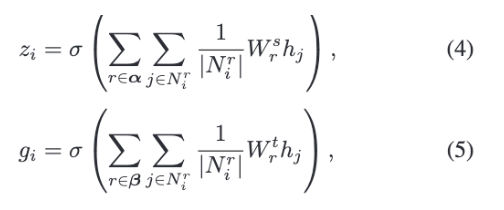
$z_i$는 SGNN의 출력, $g_i$는 TGNN의 출력을 의미합니다. $N_i^r$은 노드 $v_i$와 관계 유형 $r$로 연결된 이웃 노드들의 인덱스 집합을 나타내고, $|N_i^r|$은 그 이웃 노드의 개수를 뜻합니다. $\sigma(\cdot)$는 activation function을 의미하는데, 논문에서는 ReLU를 사용했다고 합니다.
2.2.3 Classification and Reconstruction
논문에서는 각 발화 노드 $v_i$에 대해 세 종류의 표현을 얻는다고 설명하는데요. 첫째는 노드 구성 단계에서 얻은 초기 표현 $h_i$, 둘째는 SGNN을 통해 얻은 화자 정보 기반 표현 $z_i$, 셋째는 TGNN을 통해 얻은 시간 정보 기반 표현 $g_i$을 말합니다.
GCNet은 이 세 표현을 따로 사용하지 않고 하나로 이어 붙입니다. 그다음 다시 Bi-LSTM을 사용해 context-sensitive representation을 만드는데요. 즉, 그래프에서 모은 화자 정보와 시간 정보를 다시 대화 순서 안에서 정리하는 단계라고 볼 수 있습니다.
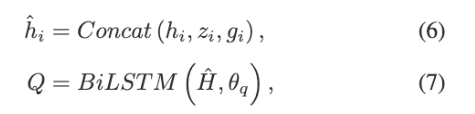
여기서 $\hat{H}={\hat{h}_i}_{i=1}^{L}\in\mathbb{R}^{L\times(3h)}$는 Bi-LSTM의 입력, $Q={q_i}_{i=1}^{L}\in\mathbb{R}^{L\times h}$는 Bi-LSTM의 출력을 의미합니다. $\theta_q$는 학습 가능한 매개변수를 의미합니다.
Classification
논문에서는 대화 이해를 위해 discriminative feature를 학습해야 한다고 하는데요. 이를 위해 $Q={q_i}_{i=1}^{L}$를 완FC-layer에 넣고, 그 뒤 softmax를 사용해 각 클래스의 확률을 계산합니다.
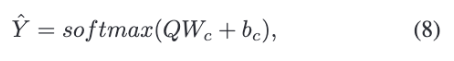
Reconstruction
저자는 latent space에서 완전한 데이터를 재구성하는 것이 모델이 누락된 부분의 의미를 학습하도록 도울 수 있다고 말하는데요. 이에 GCNet은 modality-specific reconstruction module을 사용합니다.
여기서 중요한 점은 하나의 공통 출력층으로 모든 모달리티를 복원하는 것이 아니라, 음향, 어휘, 시각 모달리티마다 별도의 linear transformation을 사용한다는 것이다. 각 모달리티는 차원과 정보 성격이 다르기 때문에, 모달리티 별로 input space에 다시 매핑합니다.
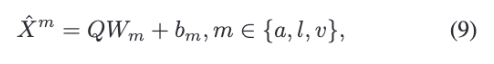
2.2.4 Joint Optimization
GCNet에서는 modality-complete data와 modality-incomplete data를 모두 활용하기 위해, classification와 대reconstruction을 하나의 end-to-end 방식으로 함께 최적화하는데요. GCNet의 loss function은 classification loss $L_{cls}$와 reconstruction loss $L_{rec}$로 구성됩니다.
classification loss를 최소화하면 discriminative feature을 학습할 수 있습니다. 즉, 서로 다른 클래스 사이의 경계가 더 분명해집니다. 이에, GCNet은 학습 과정에서는 cross-entropy loss을 classification loss로 사용합니다.
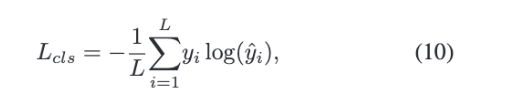
논문에서는 부분적으로 관측된 입력에서 누락된 데이터를 더 잘 추정하기 위해, 원래 특징과 채워진 특징 사이의 reconstruction loss를 계산한다고 설명하는데요.
여기서 중요한 점은 모든 위치에서 reconstruction loss을 계산하는 것이 아니라, missing position에서만 계산한다는 것입니다. 이미 관측된 모달리티는 입력으로 주어져 있으므로, GCNet이 정말 배워야 하는 부분은 빠진 모달리티의 원래 값을 맞히는 것이기 때문입니다.
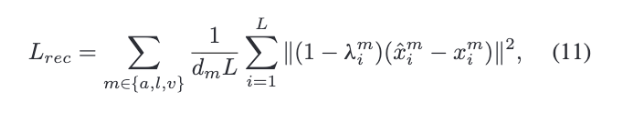
마지막으로 classification loss와 reconstruction los를 하나의 joint objective function으로 합칩니다. 이 전체 loss를 사용해 GCNet의 모든 학습 가능한 매개변수를 end-to-end 방식으로 최적화합니다.

추가로 말씀드릴 점은, 학습 중에는 모달리티가 완전하게 사용될 수 있다고 가정합니다. 학습 과정에서는 완전한 데이터에서 일부 모달리티를 가려 불완전 입력을 만들고, 모델이 정답 레이블을 맞히는 동시에 가려진 모달리티를 복원하도록 학습합니다.
3. Experimental Databases and Setup
해당 논문에서는 세개의 대화 데이터셋을 사용하였습니다. IEMOCAP은 감정 표현을 유도한 배우들의 대화 데이터이고, CMU-MOSI와 CMU-MOSEI는 온라인 영화 리뷰 영상 기반 정서 데이터셋입니다.
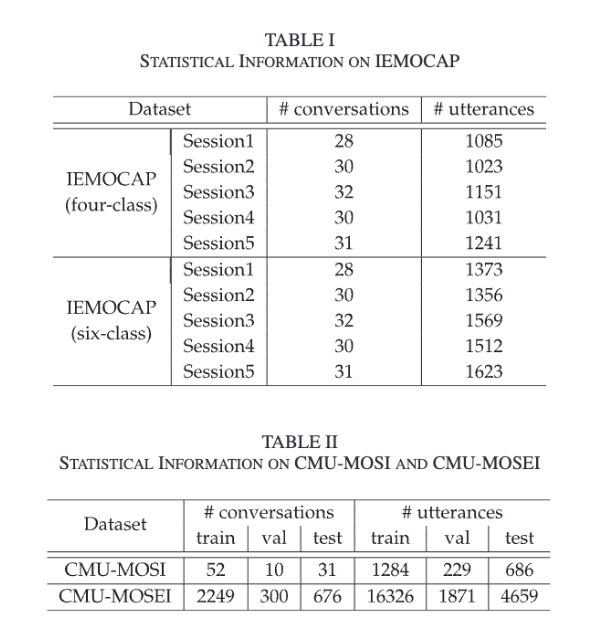
Table 1을 통해서 IEMOCAP의 통계를 확인할 수 있습니다. 이를 통해 IEMOCAP이 4개, 6개로 분류된 class를 가짐을 알 수 있습니다. Table 2를 통해서 CMU-MOSI와 MOSEI의 발화 수와 대화 수를 확인할 수 있는데요. MOSI에 비해서 MOSEI가 데이터셋의 크기가 매우 큰 것을 확인할 수 있습니다.
평가 지표는 weighted average F1-score를 사용하였는데, 특히나 IEMOCAP은 클래스 불균형이 있어서 WAF를 사용하였다고 합니다. CMU-MOSI와 CMU-MOSEI는 원래 $[-3,3]$ score를 갖지만, 논문에서는 0보다 작은 점수와 큰 점수를 나누어 부정과 긍정의 binary 평가로 진행하였다고 합니다.
missing rate은 $\eta=1-\frac{\sum_{i=1}^{L}m_i}{L\times M}$으로 정의하였고, 여기서 $m_i$는 $i$번째 샘플에서 사용 가능한 모달리티 수, $M$은 전체 모달리티 수를 의미합니다. 세 모달리티 설정에서는 $\eta$를 0.0부터 0.7까지 사하였으며, 학습, 검증, 테스트에서 같은 missing rate를 유지하였다고 합니다.
4. Results and Discussion
4.1 Classification Performance
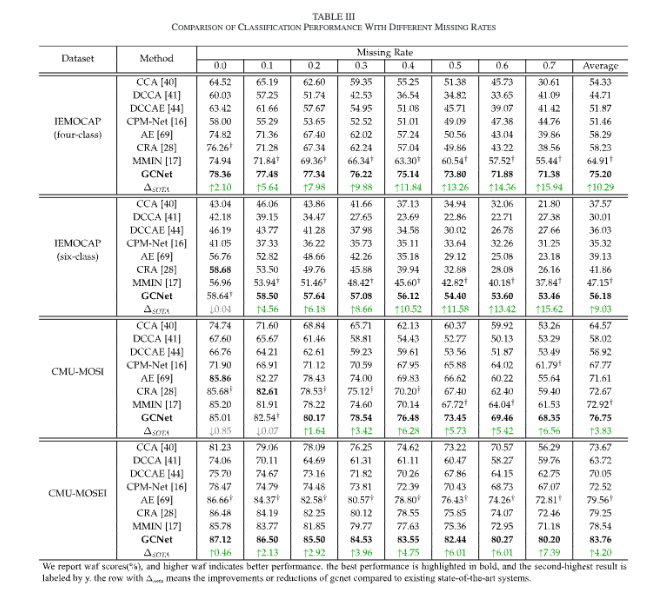
Table 3를 통해 성능을 확인할 수 있는데, IEMOCAP four-class에서 missing rate가 0.0에서 0.7로 증가할 때 기존 방법은 13.24%에서 37.70%까지 성능이 감소하지만, GCNet은 6.98%만 감소함을 볼 수 있습니다. 이를 통해 GCNet이 심한 누락 상황에서 더 안정적이라고 해석할 수 있습니다.
4.2 Imputation Performance
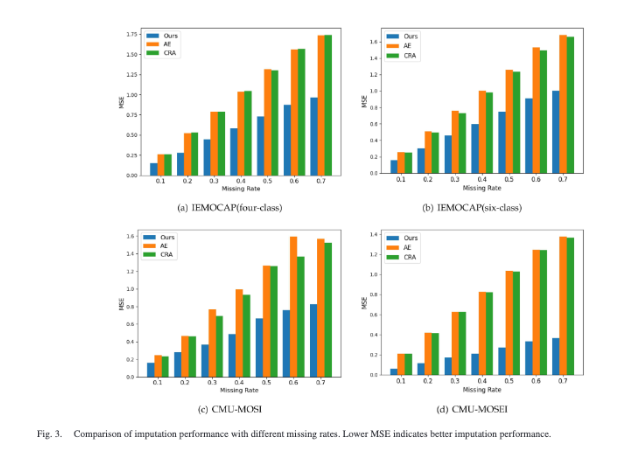
Figure 3은 여러 모델의 MSE를 missing rate별로 비교한 것을 볼 수 있습니다. 모든 데이터셋과 missing rate에서 GCNet의 MSE가 다른 모델들에 비해서 낮은 것을 볼 수 있습니다. 이는 SGNN과 TGNN이 단순한 모달리티 간 대치보다 더 많은 구조 정보를 제공한다고 해석할 수 있습니다.
4.3 Importance of Incomplete Data
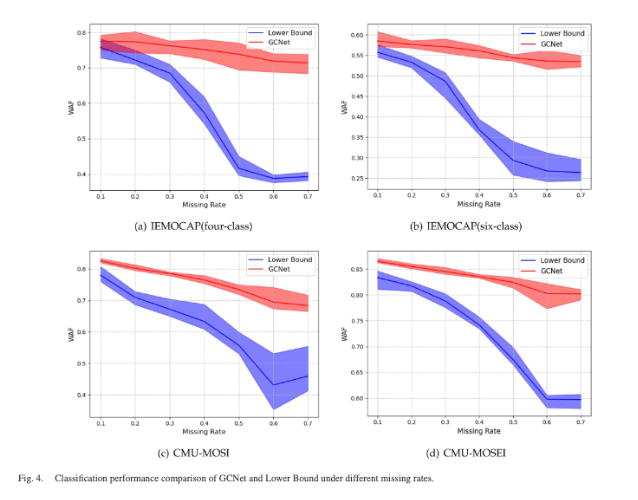
Figure 4를 통해 불완전 데이터를 학습에 사용하는 GCNet과 완전한 데이터만 사용하는 Lower Bound를 missing rate별로 비교함을 볼 수 있습니다. GCNet은 모든 데이터셋과 missing rate에서 Lower Bound보다 높은 성능을 보이는 것을 확인할 수 있는데요. 누락된 샘플도 남아 있는 모달리티 정보를 갖기 때문에, 이를 버리면 특히 missing rate가 높을 때 학습 데이터가 크게 줄어든다고 해석할 수 있습니다.
4.4 Role of SGNN and TGNN
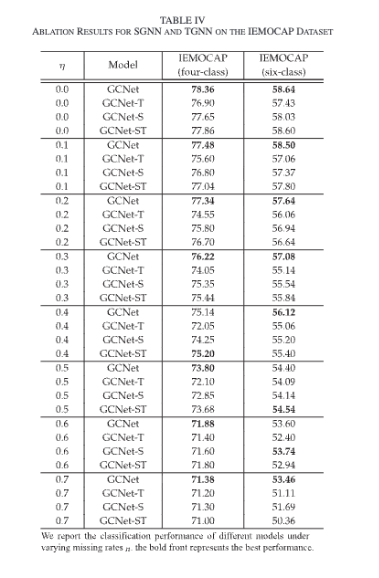
Table 4를 통해 GCNet, SGNN을 제거한 GCNet-T, TGNN을 제거한 GCNet-S, 화자와 시간 관계를 하나의 그래프에 결합한 GCNet-ST를 IEMOCAP에서 비교한 결과를 볼 수 있는데요. GCNet은 대부분 missin rate에서 변형 모델보다 좋은 성능을 보임을 알 수 있습니다. SGNN과 TGNN분리해 쓰는 설계가 화자 정보와 시간 벙보를 효과적을 학습한다는 것을 볼 수 있는 점인 것 같습니다.
이렇게 논문 리뷰를 마쳐보겠습니다. 결국 GCNet이 주는 가장 큰 힌트는 missing modality를 “없는 정보”로만 보지 말고, 대화 구조 안에서 복원 가능한 정보로 보자는 점입니다. MER-Cross에서도 listener의 감정은 직접 드러나지 않을 수 있지만, speaker의 발화, 시간적 맥락, listener의 visual reaction 사이에는 감정 추론에 필요한 관계가 남아 있습니다.
그래서 MER-Cross의 다음 과제는 단순한 multimodal fusion이 아니라, speaker와 interlocutor 사이의 비대칭적이고 부분적으로 관측된 interaction을 어떻게 graph로 모델링할 것인가라고 볼 수 있습니다. GCNet은 이 문제를 향해 가는 좋은 출발점이 될 것 같습니다.