안녕하세요 손우진입니다.
오늘은 그동안 주로 다루었던 6D Pose Estimation 방법론이나 데이터셋 구축 논문보다는 로봇 매니퓰레이션 이라는 새로운 태스크의 논문을 리뷰해보려 합니다.
최근 멀티스펙트럴 데이터를 활용한 인식 모델을 구상하고 있습니다. 저의 궁극적인 목표는 이러한 다중 모달리티를 바탕으로 극한 환경에서도 로봇 팔이 객체를 안정적으로 파지하고 제어하는것 을 목표로 하고있습니다. 이를 위해서는 센서 간의 정보를 어떻게 fusion하여 학습할 것인지 물체 파지는 어떻게 할 것인지 등 해결해야 할 과제가 많습니다. 따라서 이번 리뷰는, 어두운 환경에서 적외선 및 RGB 데이터의 교차 학습 방식을 활용해 비정형 객체 파지를 성공시킨 논문을 리뷰해보려고 합니다. 가볍게 한번 읽어주시면 감사하겠슴다
Introduction
우선 해당 논문에서 고려하는 것은 물체에대해 인식하고 grasping Point를 찾는 것입니다. 물체 중에서도 grasping이 다소 까다로운 비정형 물체를 grasping하는데 집중합니다. 우선 비정형 Manipulation 분야에 대해 간단히 설명드리겠습니다. 천은 대표적인 비정형 물체로, 형태가 고정되어 있지 않고 잡는 위치와 방식에 따라 형상이 달라집니다. 그래서 rigid 물체에 비해 Grasping 난이도가 훨씬 높습니다. 기존 연구들은 주로 RGB 카메라를 사용하여 천의 영역을 인식하고 잡을 위치를 결정하는 방식으로 진행되어 왔다고 하는데요, 저자들은 이러한 방법이 조명이나 환경에 따라 한계가있다고 합니다. 뭐 저조도 환경이나 이런상황을 얘기하는 것 같습니다.
하지만 실제 산업 현장이나 real 환경에서는 조명이 부족하거나 완전히 어두운 상황이 종종 발생하곤 합니다. 이때 RGB 카메라로는 인식하기에는 어려움이 있게죠. 기존에 이와 같은 연구가 저조도 환경에서 RGB 이미지를 enhancement하여 파지를 시도했지만, 완전한 암흑 환경에서는 enhancement할 원본 정보 자체가 없기 때문에 한계가 명확합니다. 또한 멀티스펙트랄 즉 RGB와 적외선이 동시에 들어갔을때 RGB 상황이 완전 어둡거나 이러한 상화에서는 성능하락이 있을 수 밖에 없습니다. 이 논문은 바로 이러한 문제를 열화상(Infrared) 카메라로 해결하고자 합니다. 열화상 카메라는 물체가 방출하는 적외선 복사를 감지하기 때문에 조명 조건에 독립적입니다. 완전한 암흑에서도 천의 영역을 인식할 수 있다는 것이죠. 하지만 열화상만으로 segmentation을 하기에는 RGB에 비해 텍스처 정보가 부족하고, 무엇보다 학습 데이터가 거의 없다는 문제가 있습니다.
그래서 저자들은 꽤 재밌는 전략을 씁니다. 학습 단계에서는 RGB 이미지의 풍부한 특징을 활용하여 적외선 모델의 feature extraction을 가이드하고, 추론 단계에서는 오직 적외선 이미지만으로 segmentation을 수행하는 구조를 제안합니다(DIstillation 을 사용한다고 이해하면 될 것 같습니다). 이 부분이 AnyThermal에서 봤던 Knowledge Distillation과 방향성이 비슷하면서도, 여기서는 segmentation이라는 더 구체적인 태스크에 맞춰 feature fusion 구조로 해결 하였습니다. 이를 통해 적외선 카메라를 통해서 물체영역을 잘 인식하게 만들었다고 합니다. 또한 segmentation 이후의 Grasping Position Selection도 제안합니다. 천은 아무 곳이나 잡으면 안 되고, 옷의 주름이 돌출된 부분을 잡아야 안정적으로 파지할 수 있습니다. 저자들은 depth 이미지를 분석하여 주름의 형태를 모델링하고, 가장 돌출된 주름 위치를 자동으로 선정하는 알고리즘을 제안했습니다.
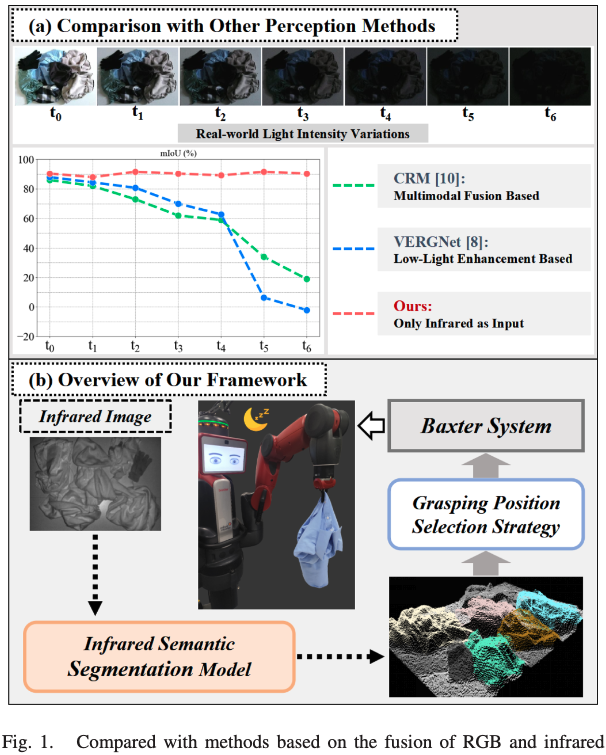
해당 figure는 저자들이 제안한 파이프라인의 전체적인 흐름이고 (a)에 보시면 기존 적외선과 RGB를 이용한 방식인데요 다른 모델들은 적외선 센서를 강조해서 사용하거나 RGB와 동시에 사용하여 완전한 저조도 환경에서는 물체를 거의 인식 못하는 것을 보실 수 있습니다. 저자들은 학습전략을 RGB로 부터 학습되었기때문에 완전한 어둠속에서도 적외선 이미지만을 가지고 물체를 인식하고 segmentation 할 수 있었다고 합니다.
정리하면 이 논문의 Contribution은 아래와 같습니다.
- 완전한 암흑 환경에서 적외선 이미지만을 사용하여 cloth를 perception하고 grasping하는 최초의 프레임워크를 제안합니다. 학습 시에는 RGB의 가이드를 받지만, 추론 시에는 적외선만으로 동작하여 조명에 완전히 독립적입니다.
- RGB 특징을 활용하여 적외선 특징 추출을 강화하는 cross-modal feature fusion 기반의 semantic segmentation 모델을 제안합니다.
- Depth 이미지 기반의 주름 분석을 통해 잡기 쉬운 grasping position을 자동으로 선정하는 전략을 제안하며, 실제 로봇 실험을 통해 90%의 grasping 성공률을 달성합니다.
Method
이 논문의 전체 파이프라인은 크게 두 파트로 나뉩니다. 먼저 적외선 이미지로부터 천의 영역을 분할하는 Infrared Semantic Segmentation, 그리고 분할된 영역에서 실제로 잡을 위치를 결정하는 Grasping Position Selection입니다. 하나씩 살펴보겠습니다.
Infrared Semantic Segmentation
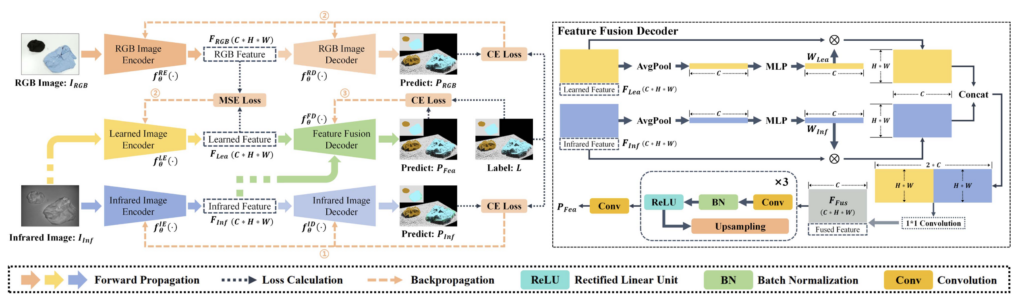
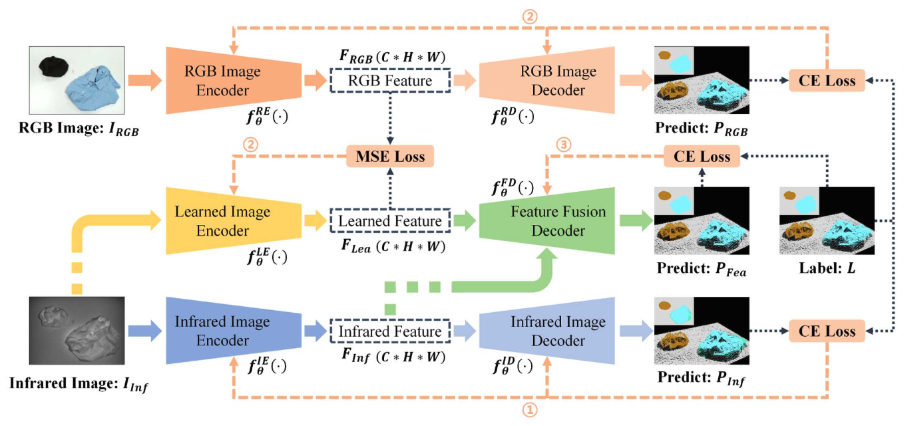
segmentation 모델의 전체 구조는 위 그림과 같습니다. 저자들은 SegFormer라는 모델을 기반으로 하였고, 적외선과 RGB 두 개의 브랜치를 갖는 구조를 설계했습니다. 여기서 핵심은 RGB 브랜치가 학습 시에만 사용된다는 점입니다. 추론 시에는 적외선 브랜치만으로 동작하기 때문에, 어두운 환경에서 RGB 카메라 없이도 segmentation이 가능합니다. 물론 여기서 사용하는 학습 이미지는 RGB 와 align이 맞춰져있습니다.
구체적으로 보면, Infrared Image Encoder-Decoder가 메인이 되는 브랜치이고, RGB Image Encoder-Decoder는 학습을 보조하는 역할입니다. 두 encoder는 각각 동일한 SegFormer 구조를 사용하며, 4개의 stage에서 multi-scale feature를 추출합니다. 학습은 3단계로 나뉘어 진행됩니다.
Stage 1에서는 적외선 Encoder-Decoder만 단독으로 학습합니다. 적외선 이미지 와 그에 대응하는 segmentation label을 사용하여 Cross-Entropy Loss로 기본적인 적외선 feature extraction 능력을 갖추게 됩니다. Loss는 다음과 같습니다.
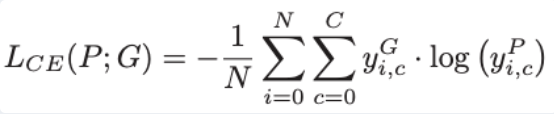
그리하여 1 단계는 기존에 적외선 이미지에서 Segmentation 능력을 학습하게됩니다. 데이터셋에 GT 같은경우는 SAM을 통해서 추출했다고 합니다(RGB).
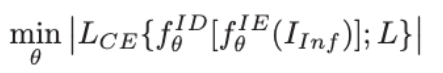
Stage 2에서는 두 개의 encoder가 새로 도입됩니다. 여기가 이 논문의 핵심인데요, RGB Image Encoder 와 Learned Image Encoder가 동시에 학습됩니다. RGB Encoder는 RGB 이미지를, Learned Encoder는 적외선 이미지를 각각 입력으로 받습니다.
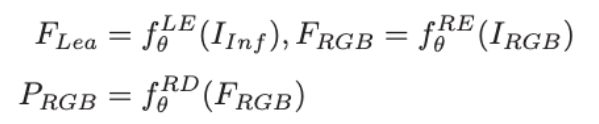
즉, Learned Encoder는 적외선 이미지를 넣었을 때 RGB Encoder가 RGB 이미지에서 뽑아내는 feature와 유사한 feature를 추출하도록 학습되는 것입니다. 이를 위해 두 가지 loss가 사용됩니다.
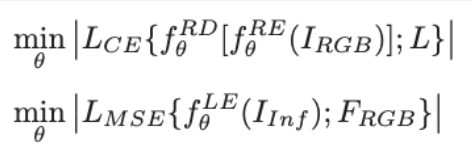
첫 번째 CE loss는 RGB Encoder-Decoder가 segmentation을 학습시키고, 두 번째 MSE loss는 Learned Encoder의 출력 F<em>{Lea} 가 RGB Encoder의 출력F{RGB} 와 가까워지도록 학습합니다. 결과적으로 RGB Encoder는 RGB 이미지에서 좋은 segmentation feature를 뽑는 teacher 역할을 하고, Learned Encoder는 적외선 이미지만으로 RGB에 대응하는 feature를 추출할 수 있는 능력을 갖추게 됩니다. 이 과정을 통해서 추론때는 Learned Encoder가 적외선 이미지로부터 RGB 수준의 정보를 추출할 수 있기를 기대하게 됩니다.
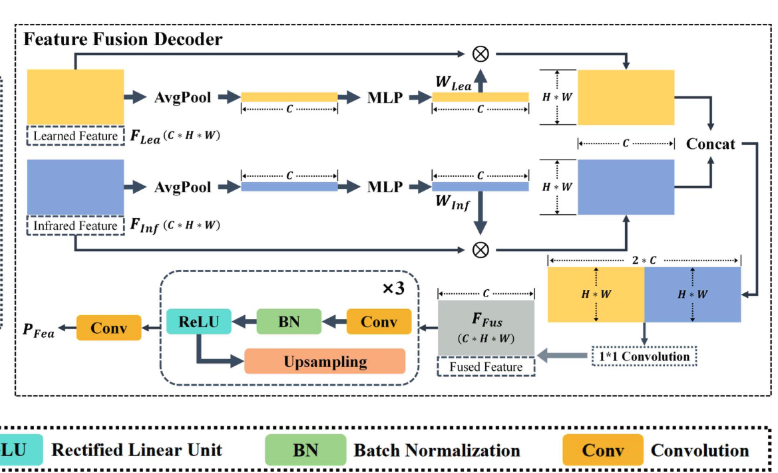
stage 3에서는 Feature Fusion Decoder를 학습합니다. 이 단계에서는 Stage 1의 Infrared Encoder와 Stage 2의 Learned Encoder를 모두 고정(freeze)시킨 상태에서, 두 encoder의 feature를 결합하는 fusion decoder만 학습시킵니다. 학습과정은 figure 오른쪽을 보시면 될 것 같습니다. 해당 순전파와 loss는 아래와같이 CE loss를 통해서 Decoder를 학습시킵니다
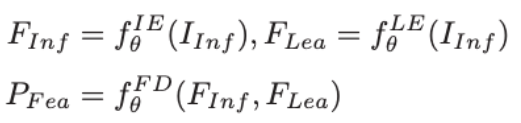
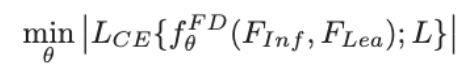
여기서 주목할 점은, 적외선 이미지 하나가 두 encoder에 동시에 들어간다는 것입니다. Infrared Encoder는 적외선 고유의 feature를 추출하고, Learned Encoder는 같은 적외선 이미지로부터 RGB에 대응하는 feature 를 추출합니다. Fusion Decoder는 이 두 feature를 결합하여 최종 segmentation prediction을 만들어냅니다.
정리하면, 추론 시 전체 흐름은 이렇습니다. 적외선 이미지 하나가 들어오면 Infrared Encoder가 적외선 특성의 feature를, Learned Encoder가 RGB에 대응하는 feature를 각각 추출하고, Fusion Decoder가 이 둘을 합쳐서 최종 segmentation mask를 출력합니다. RGB 카메라는 학습 때만 필요하고, 추론 시에는 불필요합니다.
일반적인 cross-modal fusion이 두 모달리티의 원본 이미지를 모두 요구하는 것과 다르게, 추론 시에는 적외선 이미지 단일 입력으로 두 종류의 feature(적외선 고유 + RGB 대응)를 모두 얻을 수 있도록 설계한게 신박한 설계가 아닌가 싶습니다. 이전에 리뷰했던 AnyThermal이 CLS 토큰 레벨의 Knowledge Distillation이었다면, 이 논문은 multi-scale feature 레벨에서 적외선 이미지로부터 RGB에 대응하는 feature를 직접 추출하는 encoder를 학습시켰다는 점에서 접근이 다릅니다.
Grasping Position Selection
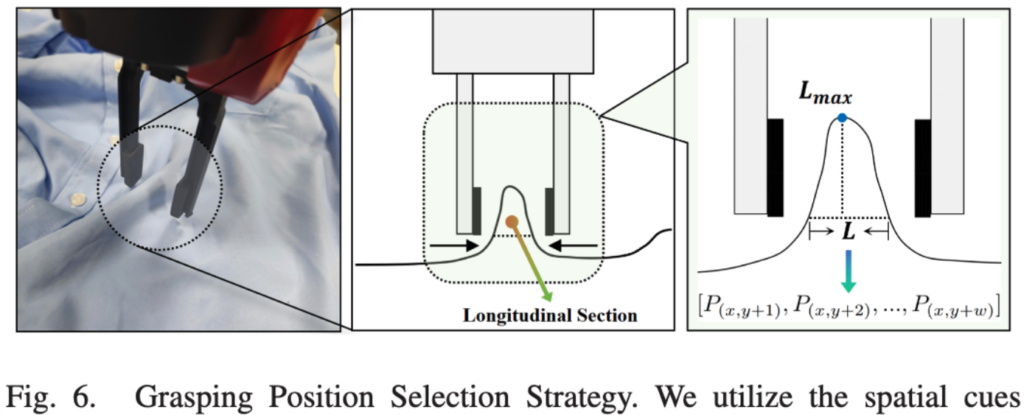
segmentation으로 물체인식 이 후, 실제로 로봇이 잡을 위치를 결정하여야 합니다. 물체가 deformable하기 때문에 단순히 segmentation mask를 통해서 파지하려고하면 실패할 가능성이 높습니다.
저자들의 핵심 아이디어는 주름을 이용하는 것인데요 돌출된 부분이 gripper가 잡기에 가장 쉽기에 약간 구겨진 지점을 찾으려고 합니다. 우선 segmentation mask를 depth 이미지에 적용하여 천 영역의 depth 값만 추출합니다. 이후 저자들이 1D Searcher라고 알고리즘을 적용하는데, 이 알고리즘은 세 가지 파라미터 (w, m, T)로 정의됩니다. w는 searcher의 너비, m은 탐색 범위, T는 높이 임계값입니다.
1D Searcher는 cloth 영역의 depth 데이터를 row 단위로 스캔하면서 주름 패턴을 탐지합니다. 주름이 있는 부분은 카메라에 더 가까워 depth 값이 작아지는데, searcher는 이러한 depth의 가장 튀어 나온 지점 과 약간 언덕 진 부분을 찾습니다. 구체적으로, 특정 위치 x에서 너비 w 범위 내의 depth 평균값과 그 양쪽 m 범위의 depth 평균값을 비교합니다. 중심의 depth가 양쪽보다 임계값 T 이상 작으면(즉, 카메라에 더 가까우면) 해당 위치를 주름의 peak로 판정합니다.
최종적으로 검출된 모든 peak 후보 중에서 가장 돌출도가 높은 위치를 grasping point로 선정합니다. 이 2D 좌표를 depth 정보와 결합하여 3D 공간의 grasping pose로 변환하고, 로봇에 전달하여 실제 파지 동작을 수행하게 됩니다.
이 방식은 학습 기반이 아니라 그냥 Depth를 이용해서 기하학적으로 접근하였습니다. 별도의 grasping point detection 모델을 학습시킬 필요 없이, depth 정보만으로 적용하여 하이퍼파라미터를 수동으로 설정했다고합니다. 하지만 주름이 거의 없는 평평한 옷같은경우네느 후보 자체가 나오지 않을 수 있다는 한계가 있습니다.

이는 해당 알고리즘입니다.
Experiments
실험은 크게 Segmentation 성능 평가와 Grasping 실험 두가지로 진행 되었습니다.(로봇은 양팔로봇을 사용했지만 한팔만 사용했다고 합니다)
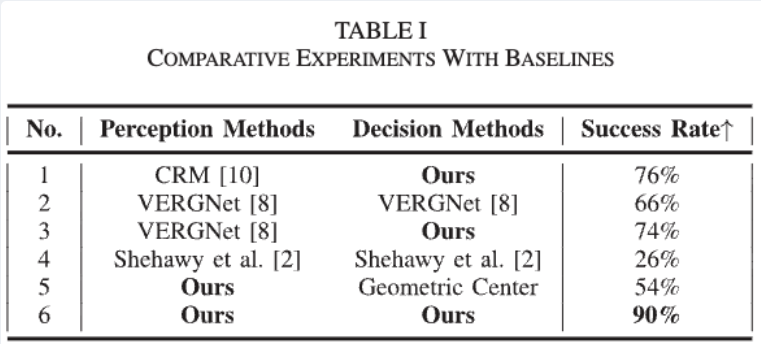

우선 Table I은 어두운 환경에서의 grasping 성공률을 기존 방법들과 비교한 결과입니다. 실험은 Baxter 로봇을 사용하여 암흑 환경에서 수행되었고, 각 method별로 10종류의 옷에 대해 각 10회씩 총 100회의 grasping 시도를 진행했습니다.
결과를 보면 제안된 방법이 90%의 성공률을 보여줍니다. 기존 방법들의 결과를 하나씩 살펴보면, CRM은 RGB 기반이라 암흑 환경에서 segmentation 자체가 실패하면서 낮은 성공률을 기록했고, VERGNet은 low-light enhancement를 적용했지만 완전 저조도에서는 enhancement할 정보가 없어 역시 한계를 보였습니다. Shehawy et al. 방법도 RGB에 의존하기 때문에 비슷한 문제를 겪었고, Geometric Center방식은 segmentation mask의 중심점을 잡는 단순한 방법인데 주름이 없는 평평한 부분을 잡게 되어 gripper가 미끄러지는 경우가 많았다고 합니다. 반면 제안된 방법은 적외선 기반 segmentation으로 어둠속에서 물체의 영역을 인식하고, 1D Searcher를 통해 주름의 돌출 지점을 찾아 잡기 때문에 높은 성공률을 달성할 수 있었습니다. 실패 케이스를 분석해보면, 저자는 주로 천이 매우 얇거나 배경과의 온도 차이가 적어 segmentation이 부정확한 경우, 또는 주름이 거의 없는 flat한 상태에서 돌출 지점을 찾기 어려운 경우에 발생했다고 합니다.
Segmentation 성능에 대해서는 별도의 비교 테이블은 없고, 저자들이 각 학습 단계별로 ablation한 결과를 본문에 기술했습니다. 제안된 모델은 validation set에서 mIoU 90.89%, test set에서 mIoU 88.01%를 달성하여 저자들의 제안한 방법론이 RGB(91.96% and 96.72)와 유사하게 나타났다고 합니다.
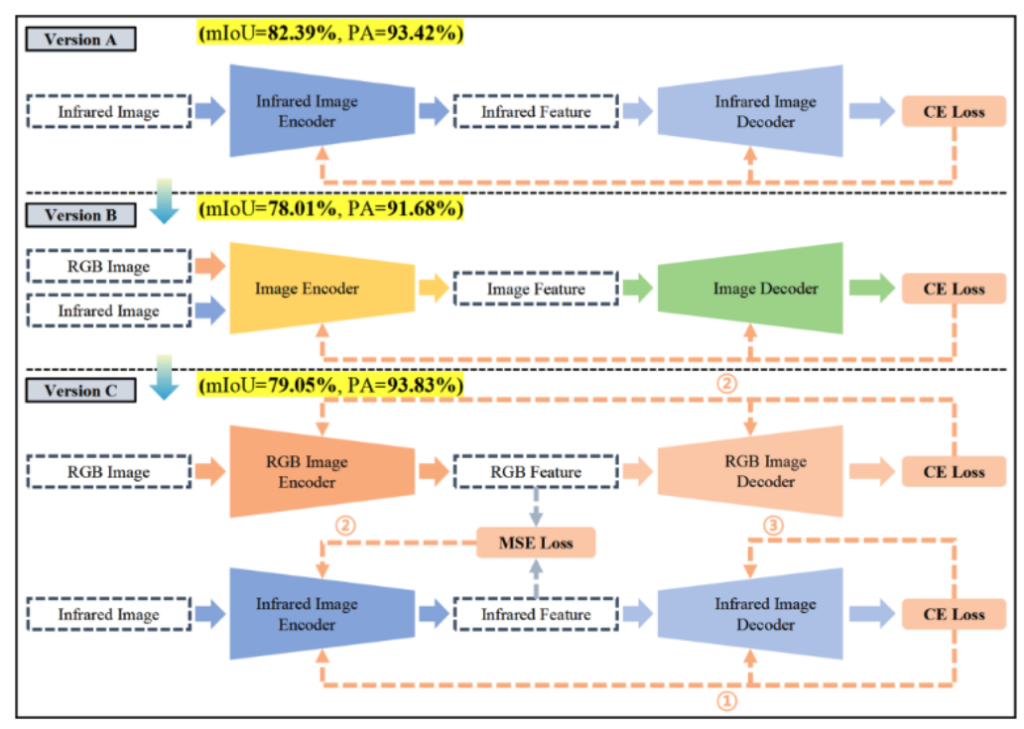
이는 학습 전략에 대한 ablation인데요, Version A는 적외선 Encoder-Decoder만 사용한 가장 기본적인 구성이고, Version B는 RGB 와 적외선을 동시에 입력하여 넣는 구조, Version C는 RGB 와 적외선 두 모델의 출력을 통해 실험 한 것입니다(RGB,T 각각 입력으로 들어가는 구조). 우선 적외선만 넣은경우에는 RGB 의 feature들의 정보를 포함하지못하므로 물체 구분을 제대로 하기 어려웠다고 합니다. B 와 C같은 경우 RGB를 입력을 받으므로 RGB 가 완전히 무너지는 상황에서 성능하락이 더욱 심하였다고 합니다. 그래서 저자들은 RGB 를 Distillation 받은 구조를 사용하여 적외선 센서만을 통해서 RGB , IR 의 특징 모두를 살렸습니다.
Conclusion
음 우선 이 논문을 통해서 학습전략을 좀 알게되었는데요 하지만 저자들은 Table top scene 내에서 배경을 바꿔가면서 학습을 하였다고 하지만 아무래도 일반화성이 많이 떨어질 것으로 예상됩니다. 이전에 리뷰했던 AnyThermal 과 이를 합쳐서 Dino같은 모델에 적용하여 indoor와 Outdoor를 모두 포함한 데이터셋으로 위 학습전략과 동일하게 적용하면 적외선에 강력한 dino 모델이 나타날수도있지않을까 싶습니다. 물론 저자들이 제안한 방법으로 domain specific한 환경에서의 Deploy라면 해당 방법론의 전략은 흥미로운 방법 같습니다 RGB가 심하게 노이즈 되는순간 학습된 Encoder가 RGB feature까지 내뱉게 된다라는 점..얼만큼 정확할지는 모르겠습니다만 열화상 도메인을 연구하는 사람들의 가장 이루고싶은 바램이 아닐까 싶습니다..ㅋㅋㅋ 감사합니다.
안녕하세요 우진님 좋은 글 감사합니다.
논문을 RGB 와 Thermal 데이터를 동일한 feature 상으로 align 시켜 열화상데이터만으로도 RGB feature space로 특징들을 추출할 수 있게한 논문으로 이해했습니다.
제가 궁금한 점은 옷을 grasping 한다는 내용이 주름이 아니어도 grasp 할 수 있을텐데 이런경우도 성공한 케이스로 해석하는지 궁금합니다.
감사합니다.
질문 감사합니다 인택님!
로봇 파지 작업의 성공 기준은 테이블 위의 옷을 차례로 집어 보관함에 넣고 테이블에 옷이 남지 않게 하는 것입니다. 제안된 파지 위치 선정은 옷 표면의 돌출된 주름을 찾는 것에 맞춰져 있습니다. 주름이 아닌 부분을 잡아 성공적으로 옮겼을 때의 예외 처리를 구체적으로 명시하지는 않았으나 center point 실험 (세그멘테이션 중앙 부분)을 잡았을때 성공률이 낮은것으로 보아 주름이 아니면 잡기 쉽지않다고 해석되지않을까 싶습니다.
우진님 좋은 리뷰 감사합니다.
1단계에서 적외선 encoder를 학습시키고, 2단계에서 rgb image encoder와 적외선 feature를 rgb와 비슷해지도록 하는 learning image encoder, 3단계에서 두 인코더를 fusion하는 feature fusion decoder를 학습하는 방식으로 이해하였습니다.
이 3 단계는 모두 동일 데이터로 이루어지는 것 인가요?
segmentation 성능에 대하여, ablation study에 해당하는 성능은 test set의 성능으로 보면 될 것 샅은데, 성능 개선이 굉장히 많이 된 것 같습니다. 그런데 2단계에서 learning image encoder가 아니라 rgb image encoder 도 다시 학습시키는 데, 이미 잘 학습된 모델을 freeze 하지 않고, 처음부터 학습시키면서 learning image encoder를 학습시키는 이유가 있을까요?
질문 감사합니다 승현님!
세 단계의 학습은 모두 사전에 수집된 1018쌍의 동일한 RGB-적외선 학습 데이터셋을 기반으로 진행됩니다. 2단계 학습 시 RGB Image Encoder를 완전히 freeze하지 않는 이유에 대해 논문은 학습률을 0.00001로 매우 낮게 설정하여 안정적인 특징을 제공하기 위함이라고 명시하고있습니다. 아무래도 Task specific하게 학습하다보니 rgb도 같이 학습하지않을까 생각이듭니다.
감사합니다.
안녕하세요 우진님 좋은 리뷰 감사합니다.
제가 이 분야에 대해서 잘 아는게 아니라서 간단한 질문 남기겠습니다!
주름진 부분에서 pick가 가장 높은 부분을 찾고 그 부분을 grasp 한다고 하는데 perception 후 grasp 까지의 과정은 어떻게 이루어 지는지 알 수 있을까요? 단순 위치로의 제어 방식인지 궁금합니다!
질문감사합니다 인하님
파지 위치 선정은 Depth 이미지를 활용해 옷 표면에서 가장 잡기 쉬운, 돌출된 주름을 찾는 과정입니다. 먼저 인식된 옷 영역의 깊이 정보만 남긴 채 나머지는 마스킹해. 그 후 로봇 그리퍼 너비에 맞춘 1차원으로 이미지를 전체적으로 훑으면서, 픽셀 값이 솟아올랐다가 내려가는 전형적인 주름 단면 형태를 찾게 됩니다. 이렇게 찾은 후보들 중에서 양끝점 대비 가장 높게 솟아오른 주름 중심점을 최종 파지 위치로 결정하고, 로봇 시스템은 이 지점의 3차원 공간 좌표로 단순 이동하여 옷을 집어 올리도록 제어돼. 휴리스틱하게 파지위치는 접근했다고 이해하시면 될 것 같습니다. 하이퍼파라미터 튜닝으로 task에 맞춰줘야한다고 저자는 얘기합니다
감사합니다!
안녕하세요 우진님 리뷰 감사합니다. 먼가 흥미롭고 재밌는 연구주제인 것 같습니다 ㅋㅋㅋ.
질문이 두개 있는데요,
Q1. Stage 2에서는 Learned Encoder가 적외선 입력만으로 RGB encoder의 feature를 모사하도록 학습되는것 같은데, 이때 실제로 semantic한 정보 얼마나 복원되었는지에 대한 정량 평가나 feature space visualization 같은 추가 분석도 있었나요?
Q2. SR의 병목은 무조건 perception 쪽인가요? 파라미터 튜닝 하니까 인지가 되면 grasping은 실패 안하는건가 싶긴 한데 1D searcher 방식이 실패하지는 않을까 궁금해서 여쭤봅니다