안녕하세요. 박성준입니다.
오늘 제가 리뷰할 논문은 ICCV2023에 개제된 UniVTG입니다. 해당 논문은 3가지 task를 통합한 Unified 프레임워크를 제시하며 Moment Retrieval, Highlight Detection, Video Summarization에서 좋은 성능을 내는 모델을 제안합니다.
Introduction
일상 공유에 대한 사람들의 관심이 많아짐에 따라 동영상은 소셜 미디어에서 가장 유익하면서도 다양한 시각적 형태로 등장하게 됩니다. 이러한 영상들은 다양한 상황에서 수집되며 untrimmed 영상부터 잘 짜여진 영상까지 다양한 형태로 존재합니다. 다양한 크기와 종류의 영상들이 생성되며 사용자의 쿼리에 맞게 동영상을 브라우징하는 것은 업계에서 중요한 기능으로 떠오르고 있습니다. 이러한 수요들로 인해 Moment Retrieval, Highlight Detection, Video Summarization 등과 같은 연구들이 관심을 받게 되었습니다.
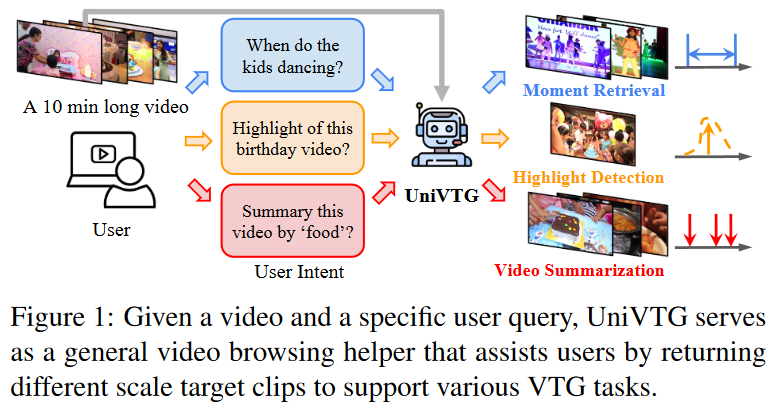
Figure 1에서 묘사되듯이 Moment Retrieval은 자연어 쿼리에 해당하는 구간을 비디오에서 찾아서 반환하는 task입니다. input으로 untrimmed video(편집되지 않은 영상)와 text query(Figure 1에서는 “When do the kids dancing?”이 자연어 쿼리에 해당합니다.)가 주어지고, input으로 주어진 untrimmed video 내에서 쿼리의 내용에 해당하는 구간을 반환하여 사용자로 하여금 원하는 사건이 있는 위치를 찾을 수 있게 도와주는 task입니다.
Highlight Detection은 영상 내 중요한 정도을 나타내는 worthiness score를 구해 영상의 핵심 세그먼트를 선택하는 task입니다. 말 그대로 Untrimmed video가 주어졌을 때에 영상의 하이라이트를 만드는 task라고 이해하시면 됩니다.
Video Summarization은 영상을 요약하기 위해 서로 다른 장면(point-level)을 수집하여 일반적인 요약 혹은 사용자의 쿼리에 일치하는 요약을 반환하는 task입니다. 영상 전체의 요약을 하는 task와 사용자의 쿼리에 맞는 요약을 하는 task로 크게 두가지 갈래로 나뉘며 해당 논문에서의 Video Summarization은 사용자의 쿼리에 해당하는 요약을 반환하는 task입니다. Figure 1에서 “Summay this video by ‘food'”라고 쿼리가 주어졌을 때, 영상 전체의 요약이 아닌 food라는 사용자의 니즈에 맞는 요약을 하는 것을 목표로 합니다.
위의 3가지 task들은 맞춤형 사용자의 쿼리를 기반으로 다양한 크기의 클립을 grounding하는 공통된 목표를 가집니다. 따라서 저자는 위의 3가지 task들을 통틀어 Video Temporal Grounding(이하 VTG)라 부릅니다. 일반적으로 video temporal grounding이라고 하면 moment retrieval을 칭하는 경우가 많지만 저자는 Moment Retreival을 포함하는 개념으로 VTG를 설명하고 있습니다. 따라서 앞으로 리뷰에서 나오는 VTG는 위의 3가지 task들을 모두 말하는 개념으로 이해해주시면 될 것 같습니다.
위의 task들은 서로 연관되어 있지만 최근까지 그 관계가 명확하게 정리되지 않고 있었습니다. NIPS 2021에서 Moment Retrieval과 Highlight Detection을 통합한 벤치마킹 데이터셋인 QVHighlights가 제공되고 Moment-DETR 모델이 두 task에 대해 다루기 시작하며 위 task들을 통합하여 학습할 수 있는 모델들이 제안되고 있습니다(QVHighlights와 Moment-DETR에 대한 자세한 리뷰는 지오님의 x-review를 참고하시기 바랍니다). 이에 따라 저자는 하나의 통합된 VTG 프레임워크의 필요성을 느꼈고, 다음의 3가지 방향성을 가지고 UniVTG를 구성했다고 밝힙니다.
- label과 task의 관점에서 VTG를 위한 formulation을 정의합니다. 비디오는 클립 시퀀스로 분해되며 각 클립은 세개의 query-conditional 요소가 할당됩니다. 이러한 formulation은 같은 프레임워크 안에서 다양한 VTG 라벨과 task를 같은 프레임워크에서 활용할 수 있게 합니다.
- model의 관점에서 위의 formulation에 부합하는 UniVTG는 모달리티 fusion과 모달리티 alignment를 위해 single-stream, dual-stream pathways를 고안합니다. 3개의 요소들을 decode하기 위해 3개의 헤드를 제안합니다.
- 통합된 프레임워크과 수도 라벨링의 가능성으로 인해 large-scale temporal grounding pretrain이 가능합니다. 이를 통해 zero-shot 추론을 포함한 다양한 VTG 다운스크림 작업을 해결할 수 있습니다.
위의 방향성을 가지고 구성된 UniVTG의 contribution은 다음과 같습니다.
- UniVTG는 다양한 domains과 tasks에 활용될 수 있는 VTG 사전학습 모델입니다.
- UniVTG는 point-level, interval-level, curve-level 라벨과 같은 다양한 temporal annotations를 통해 open source의 rich supervision을 다룰 수 있습니다.
- 사전 훈련 corpus의 한계를 해결하기 위해, CLIP을 teacher로 사용하여 확장 가능한 수도 temporal 라벨링을 생성하는 효율적인 annotation 방법을 구상했습니다.
- 제안된 프레임워크의 효과와 유연성을 네 가지 설정과 일곱 개의 데이터셋을 통해 검증합니다.
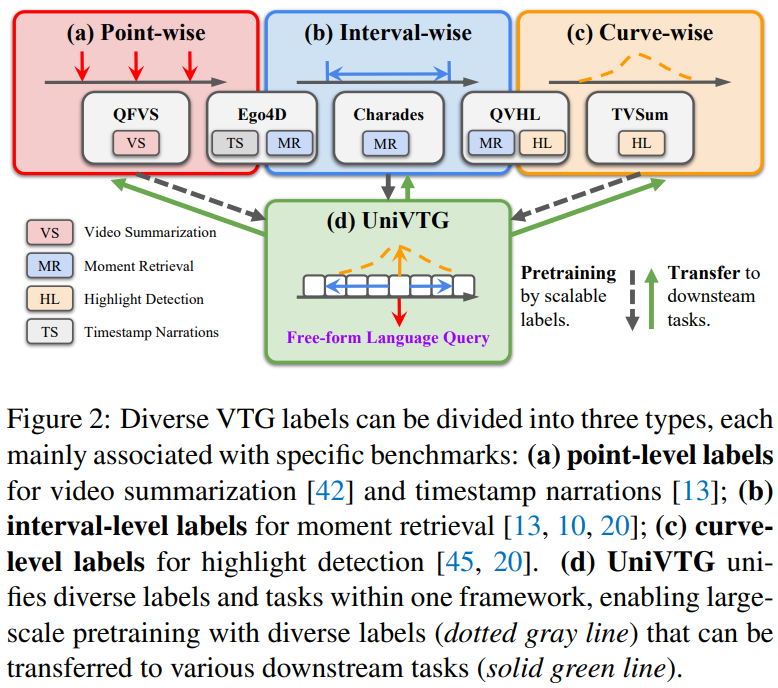
Figure 2에서 확인할 수 있듯이 point-level 라벨은 video summarization, timestamp narration에서 사용되고, interval-level 라벨은 moment retrieval에, 그리고 curve-level 라벨은 highlight detection에 사용됩니다. UniVTG는 위 라벨들은 통합하여 여러 downstream task에서 활용할 수 있습니다.
UniVTG: Tasks, Labels
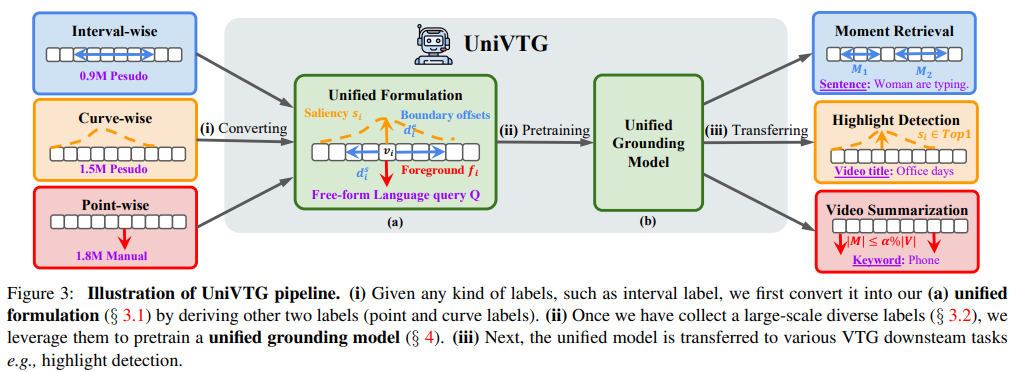
Figure 3는 UniVTG의 기본적인 파이프라인을 보여줍니다. 어느 형태의 라벨이 인풋으로 들어오게 된다면 unified formulation의 형태로 변환합니다. 그런 다음 unified grounding model을 사전학습하는 데에 활용합니다.
Unified Formulation
비디오 $V$와 자연어 쿼리 $Q$가 주어지면, 먼저 $V$를 $L_v$ 시퀀스의 고정된 길이를 갖는 클립$\{v_1,\cdots,v_{L_v}\}$으로 전환합니다. 모든 클립 $v_i$는 길이 $l$을 갖고 중간 timestamp $t_i$를 갖습니다. 쿼리 $Q$는 $L_q$토큰을 갖고, $Q=\{q_1,\cdots,q_{L_q}\}$로 표현됩니다. 그리고 나서 저자는 모든 클립을 3가지 요소로 정의합니다. $v_i=(f_i,d_i,s_i)$
Foreground indicator $f_i∈\{0,1\}$ 는 $i$번째 클립이 foreground인지 아닌지를 구분합니다. 0, 1로 표현되며 foreground인 경우에는 1, 그렇지 않은 경우에는 0으로 표현합니다.
Boundary Offset $d_i=[d^s_i,d^e_i]∈R^2$는 클립의 시작과 끝 간격을 결정합니다. 시작 timestamp $d^s_i$와 끝 timestamp $d^e_i$를 사용해 클립의 전체 범위 $b_i$를 정의합니다. 이를 이용하여 클립의 정확한 시간적 위치와 범위를 표현할 수 있습니다. $b_i=[t_i-d^s_i,t_i+d^e_i]$로 나타낼 수 있습니다.
Saliency score $s_i∈[0,1]$ 는 클립과 쿼리 사이의 관련성을 나타내는 점수입니다. 0과 1 사이의 값을 가지며 1에 가까울수록 관련성이 높다는 것을 의미합니다. 클립의 내용과 쿼리가 전혀 관련이 없다면 0으로 나타냅니다. 0보다 큰 값이라면 조금이라도 연관성이 있다는 것을 의미합니다. 이 점수를 통해 클립의 시각적 특징이 쿼리의 내용과 얼마나 관련이 있는 지를 확인해 클립의 중요성, 관련성을 평가할 수 있습니다.
사실 saliency score가 0보다 크다면 foreground라는 것을 의미하니 foreground indicator과 왜 필요한가 싶은 생각이 들긴 하지만 이에 대한 저자의 언급이 없어 연산의 효율성과 같은 점에서 foreground indicator를 사용하는 게 아닌가 싶은 생각이 듭니다.
Moment Retrieval and Interval-wise Label
Moment Retrieval은 쿼리 $Q$에 해당하는 하나 혹은 여러 개의 구간을 반환하는 것을 목표로 하기 때문에 interval-wise 라벨을 사용합니다. 하지만, moment retrieval을 위해 모든 구간을 annotate하는 것은 모든 영상을 전부 확인해야 하기에 굉장히 비효율적입니다. 저자는 video caption이 descriptive한 성격을 가지기에 grouning query로 적합하다고 말하며 이 정보를 활용하여 pseudo intervals를 만들 수 있다고 합니다. 이렇게 생성한 interval을 위의 unified formulation의 형태로 변환하여 사용했습니다. interval이 아닌 경우에는 $f_i=0, s_i=0$으로 설정하고 interval인 경우에는 $f_i=1, s_i>0$으로 설정합니다.
Highlight Detection and Curve-wise Label
Highlight Detection은 모든 클립에 중요도 점수를 계산하는 것을 목표로 합니다. 중요도 점수를 토대로 하이라이트를 검출하기 때문입니다. 쿼리는 비디오의 제목 혹은 비디오의 도메인과 같은 형태로 주어지고, saliency score를 기준으로 top-K개의 후보군을 선정합니다. 그리고 CLIP을 teacher로 사용하여 clip-level 코사인 유사도를 얻고, 수도 curve label로 사용합니다.
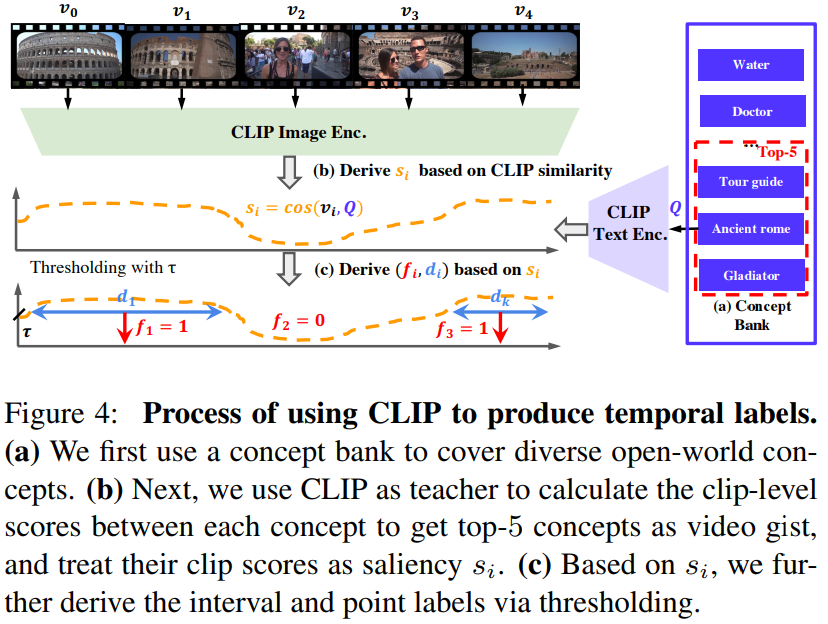
Figure 4은 CLIP을 사용하여 라벨을 생성하는 과정을 보여줍니다. 클립을 통해 영상과 쿼리 간의 코사인 유사도를 측정하고 이를 표현한 curve-level 라벨에서 임계치를 넘기는 부분을 사용합니다.
Video Summarization and Point-wise Label
Query-focused video summarization은 영상을 쿼리에 맞게 요약하는 것을 목표로 합니다. keyword를 $Q$, 클립 셋을 $M=\{v_i|f_i=1\}$으로 정의하는 task로 저자는 $M$의 size는 $V$의 길이의 2%로 설정했습니다.
UniVTG: Model
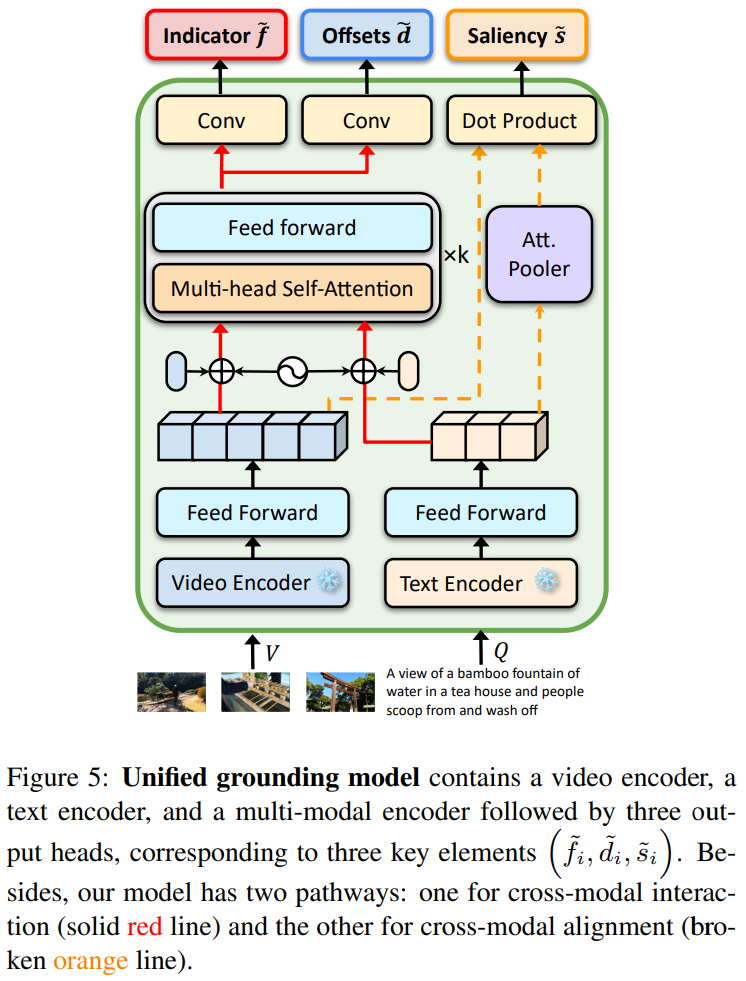
Figure 5는 UniVTG의 모델의 구조를 보여줍니다. frozen video encoder, frozen text encoder와 multi-modal encoder를 사용합니다. Moment-DETR의 video encoder, text encoder 즉, CLIP과 SlowFast를 video representation으로, CLIP text encoder로 token level features를 사용합니다.
비디오 $V$를 $L_v$의 클립들로, 쿼리 $Q$를 $L_q$ 토큰들로 주어지면 먼저 video text encoder를 거쳐 encode하여 두 FFN(Feed-Forward Networks)을 거쳐 같은 차원 $D$에 투영합니다. 그런 다음, cross-modal alignment와 cross-modal interaction을 위한 두 pathway를 거칩니다.
- cross-modal alignment를 위해서 저자는 attentive pooling operator를 사용해 쿼리 토큰 $Q∈R^{L_q*D}$를 sentence representation $S∈R^{1*D}$의 형태로 바꿉니다. 이것은 문장 표현이 D차원의 벡터 하나로 표현되는 것을 의미합니다. $S=AQ$, 여기서 가중치 $A$는 $S=Softmax(WQ)∈R^{1*L_q}$이고 $W^{1*L_q}$는 학습 가능한 임베딩입니다. 그런 후에 $V$와 $S$는 contrastive learning을 수행합니다.
- cross-modal interaction은 위치 임베딩 $E^{pos}$와 모달리티의 type 임베딩인 $E^{type}$가 추가됩니다. $\tilde{V}=V+E^{pos}_V+E^{type}_V$, $\tilde{Q}=Q+E^{pos}_T+E^{type}_T$ 그런 다음 text와 video token들은 concat되어 input $Z^0=[\tilde{V}, \tilde{Q}]∈R^{L*D}$로 바뀌어 multi-modal encoder에 들어가고, 여기서 $L$은 $L=L_v+L_q$를 뜻합니다. multi-modal encoder는 $k$개의 트랜스포머의 Multi-head Self-Attention과 FFN블록으로 구성된 레이어로 구성되어있습니다.
이전의 unified formulation $(f_i, d_i, s_i)$에 맞추기 위해 세가지 head를 사용하여 각 head는 하나씩 담당합니다.
Foreground head for Matching
multi-modal encoder에서 나온 출력 $\tilde{V_k}$를 $D$개의 필터를 가진 1X3 컨볼루션 레이어 3개를 적용하고 ReLU를 적요앟비낟. 그 후 sigmoid 함수를 통해 각 클립별 예측 $\tilde{f_i}$를 출력하고 BCE를 적용합니다.
$L_f = -\lambda(f_i\log(\tilde{f_i})+(1-f_i)\log(1-\tilde{f_i}))$
여기서 $\lambda$는 손실 함수의 가중치를 나타내며, $f_i$는 ground truth, $\tilde{f_i}$는 모델의 예측값을 의미합니다.
Boundary head for Localization
foreground head와 비슷한 구조를 가지지만 마지막 레이어에 왼쪽, 오른쪽 offset을 위한 2개의 출력 채널이 존재합니다. multi-modal encoder에서의 출력 $\tilde{V_k}$를 통해 클립별 offset $\{\tilde{d^l_i, \tilde{d^u_i}}\}$을 출력합니다. 그 후 예측된 boundary $\tilde{b_i}$를 고안하여 smooth L1 loss와 IoU loss을 활용하여 학습합니다.
$L_b = 1_{\{f_i=1\}}[\lambda_1L_{SmoothL1}(d_i, \hat{d}_i) + \lambda_{iou}L_{iou}(b_i, \hat{b}_i)]$
여기서 $1_{\{f_i=1\}}$는 $f_i=1$일때만 loss를 계산한다는 뜻으로 foreground일때에만 loss를 계산하는 것을 의미합니다.
Salinecy head for Contrasting
저자는 saliency를 visual context와 text query간의 관련성으로 정의했기 때문에, video와 text 모달리티 간의 코사인 유사성을 통해 점수를 계산합니다.
$\tilde{s_i}=\cos(v_i,S):=\frac{v^T_iS}{||v_i||_2||S||_2}$, $||\cdot||_2$는 벡터의 L2-norm을 의미합니다.
각 비디오 $V$에 대해 랜덤하게 foreground sample $v_p$를 $f_p=1$, $s_p>0$으로 positive sample로 샘플링합니다. saliency $s_j$가 $s_p$보다 낮은 클립의 경우 negative sample이라 샘플링합니다. 그 후 intra-video contrastive learning을 진행합니다.
$L_s^{intra} = -\log\frac{\exp(\tilde{s}_p / \tau)}{\exp(\tilde{s}_p / \tau) + \sum_{j \in \Omega} \exp(\tilde{s}_j / \tau)}$, $\tau$는 temperture parameter로 0.07로 설정했습니다. $\Omega$는 positive sample의 집합입니다.
또한, cross-sample supervision을 위해 inter-video contrastive learning을 진행합니다.
$L^{inter}_s = \log \frac{\exp(\tilde{s}_p/\tau)}{\sum_{k\in B \exp(\tilde{s}^k_p/\tau)}}$, $B$는 학습 배치 사이즈이고 $\tilde{s^k_p}=\cos(v_i,S_k)$입니다.
최종 Saliency score는 inter-, intrea-video contrastive loss를 모두 고려합니다.
$L_s = \lambda_{inter}L^{inter}_s+\lambda_{intra}L^{intra}_s$
그리고 모든 헤드의 loss를 합한 최종 loss를 다음과 같습니다.
$L=\frac{1}{N}\sum^N_{i=1}(L_f+L_b+L_s)$, $N$은 학습 셋의 클립의 개수입니다.
Experiments
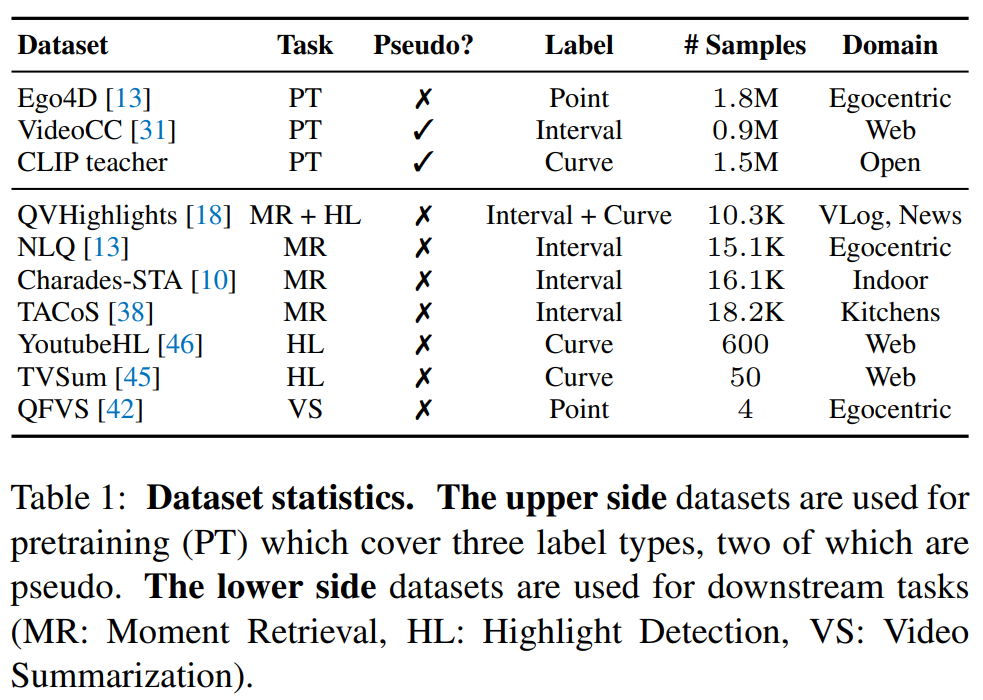
Table 1의 위의 데이터셋은 사전학습에 사용된 데이터셋들이고 밑의 데이터셋은 downstram task에 활용된 데이터셋입니다.
Evaluation Metrics
QVHighlights의 경우에는 논문에서 제공된 official 방식을 따라합니다. Recall@1을 IoU threshold 0.5와 0.7을 사용합니다. 그리고 mAP 0.5, 0.75를 IoU threshold [0.5:0.05:0.95]를 moment retrieval로 사용하고, highlight detection은 mAP와 HIT@1가 사용됩니다. Charades-STA, NLQ, TACoS의 moment retrieval 데이터셋은 Recall@1을 IoU threshold 0.3, 0.5, 0.7 그리고 mIoU가 사용됩니다. Youtube Highlights와 TVSum의 경우에는 mAP와 Top-5 mAP가 사용되고, QFVS는 F1-score를 사용합니다.
Moment Retrieval
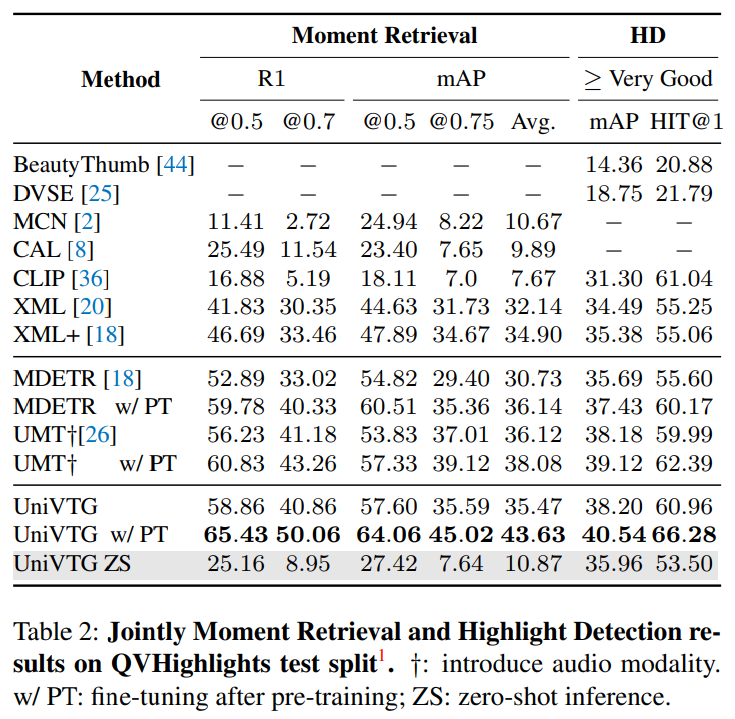
위의 Table 2는 QVHighlights 데이터셋에 대한 Moment Retreival과 Highlights Detection 결과입니다. 사전학습한 UniVTG가 SOTA를 달성한 것을 확인할 수 있습니다.
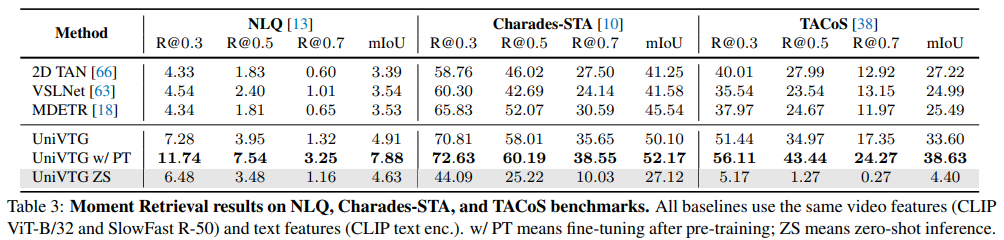
그 외의 moment retrieval을 다루는 NLQ, Charades-STA 그리고 TACoS 데이터셋에서도 모두 SOTA를 달성한 모습을 볼 수 있습니다.
Highlights Detection
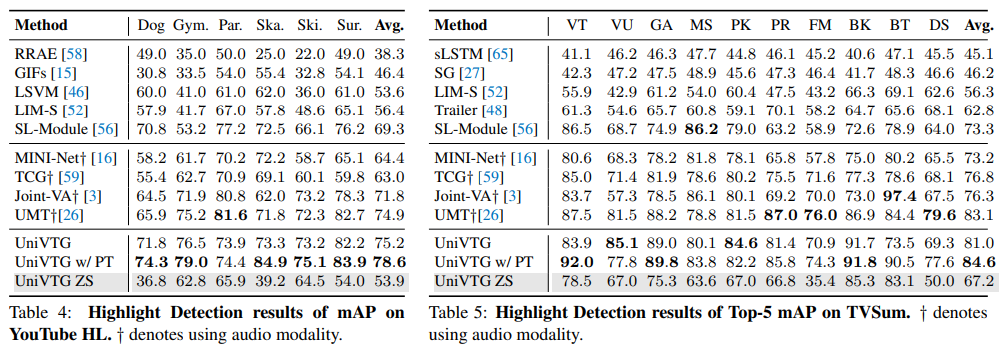
Highlight Detection의 경우, 오디오를 포함한 모델에 비해서도 전혀 밀리지 않는 성능을 보여주고 있습니다.
Video Summarization
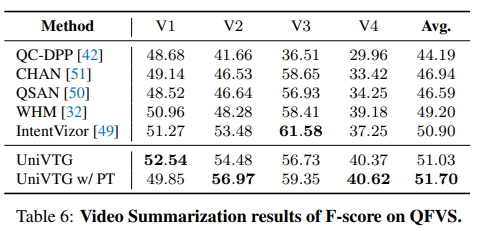
Video Summarization에서도 UniVTG의 성능이 좋은 모습을 보입니다.
Conclusion
논문에서 제안하는 UniVTG는 3가지 주요 challenges를 해결합니다. i) 우리는 VTG에 대한 통합된 formulation을 제안하여 단일 프레임워크 내에서 다양한 label과 task를 전환할 수 있습니다. ii) 다양한 VTG task와 훈련 라벨을 다루는 모델을 개발합니다. iii) 통합된 프레임워크로 확장 가능한 라벨 덕분에 사전학습이 가능해집니다.
감사합니다.
안녕하세요. 박성준 연구원님.
좋은 리뷰 감사합니다.
제안서 작업을 하면서 Moment Retrieval이 정확히 어떤 task인지도 잘 모르고 UniVTG를 읽느라 고생했던 기억이 나기도 하고, 오랜만에 보니까 조금 기억이 나지 않는 부분도 있고 하네요.
이전에 논문을 읽으면서도 약간 헷갈렸던 부분인데, UniVTG가 point/interval/curve 세 가지 종류의 라벨을 가지고 학습을 하는 과정에서 unified formulation이라는 하나의 형태로 라벨을 변환해 준다면, 데이터의 원래 라벨이 어떤 형태이든 변환된 라벨의 형태에 전혀 차이가 없는 것인가요? 그렇다면 사전학습 시에 사용되었다는 세 가지 데이터셋을 모두 섞어서 학습을 진행한 것인지도 궁굼합니다.
감사합니다.
안녕하세요 지오님 좋은 답글 감사합니다.
저도 unified formulation이라는 형태의 라벨을 처음 보는터라 이해하기 어려웠던 기억이 나네요. 제가 이해한 바로는 (f_i, d_i, s_i)의 형태로 라벨이 존재하는 것으로 보아 프레임마다 3가지의 point/interval/curve 라벨이 모두 존재하고 각각의 task별로 필요한 라벨을 활용하는 것으로 파악했습니다. 즉, unified formulation이 point/interval/curve 형태의 라벨을 모두 포함하는 라벨이라고 이해했습니다.
사전학습시에는 Ego4D 데이터셋을 통해 point를 VideoCC 데이터셋을 통해 interval을 그리고 CLIP을 활용하여 curve를 학습합니다. 따라서 사전학습 모델은 3가지 데이터셋을 모두 학습을 진행했습니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다.
본문의 Moment Retrieval and Interval-wise Label 부분에서 video의 모든 구간을 annotate하는 것은 비효율적이라video caption에 대해 언급을 해주셨는데 이는 특정 구간에 대해 설명하는 텍스트를 생성하는 작업을 뜻하나요? 그렇다면 video caption은 어떤 방법으로 생성이 되는지 논문에서 특별히 언급된 부분이 있을까요??
안녕하세요 의철님 좋은 답변 감사합니다.
caption을 활용해 비디오의 프레임에 대한 설명을 자연어로 얻을 수 있습니다. 저자는 이를 grounding tasks에 대해 strong region-level를 이해하는 데에 도움이 된다고 설명하고 있습니다.
논문의 Appendix에 VideoCC를 활용하여 caption을 추출한다는 언급이 있긴하지만 구체적으로 어떻게 생성하는지에 대해서는 언급이 없어 파악하기가 어렵네요. caption을 생성해 비디오의 이해를 돕는 것으로 이해했습니다.
감사합니다.