Introduction
우리가 익히 알고 있듯, 사람은 시각, 청각, 촉각 등 여러 감각 기관을 사용하여 세상을 인지합니다. 이러한 방식에 영감을 받아 머신 러닝 분야에서는 다양한 센서로부터 수집된 정보를 복합적으로 수집하여 상황을 인지하는 멀티모달 연구가 등장하였습니다. 멀티모달 데이터는 일반적으로 하나의 모달리티보다 더 다양한 view를 보여줍니다. 여기서 view라는 것은 보다 데이터를 다양한 관점에서 볼 수 있다는 의미로 이해하였는데요, 직관적으로 생각해 보았을 때 고려할 수 있는 데이터가 증가하였으므로 멀티모달은 단일모달 보다는 좀 더 많은 퍼포먼스 향상을 보일 것이라고 생각을 하고 있습니다.
그러나 최근 연구에 따르면 joint training 전략을 사용하는 멀티모달 모델의 경우, 즉, 모든 모달리티를 균일한 학습 목표로 최적화하는 모델의 경우 단일 모달보다 낮은 성능을 보이는 경우가 있습니다. 이러한 현상은 각 모달리티에 대응하는 파라미터의 convergence rate가 다르기 때문에 발생한다고 합니다.
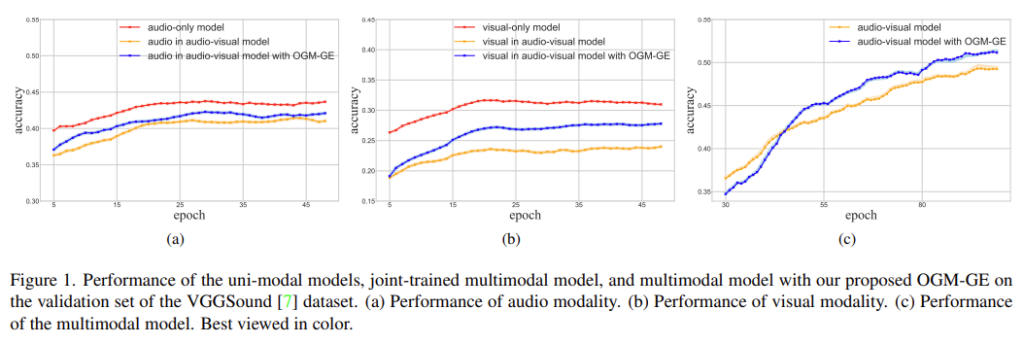
[그림 1]은 VGGSound 데이터의 audio-video classification 성능을 모달리티 별로 나타낸 것으로 각각 단일 모달 모델, 멀티모달 모델의 성능을 의미합니다. [그림 1(a)]은 audio 데이터만을 사용한 분류 성능으로 빨간색은 audio-only 모델, 노란색은 audio-video로 학습한 멀티모달 모델에 audio를 입력하였을 때의 classification acc입니다. (c)의 성능을 보면 audio-video를 둘 다 사용하여 best 단일 모달 모델에 비해 성능을 향상시킨 것을 확인할 수 있는데요, 그러나 이 모델에 단일 모달리티 데이터를 입력하면 단일 모달리티 모델보다는 안 좋은 성능을 발휘하게 됩니다. 즉, 멀티모달 학습은 전체적인 성능 향상을 가져올 지 몰라도 이를 분해하여 단일 모달리티의 관점으로 보자면 오히려 기존의 단일 모달 모델보다 결과가 좋지 않을 수 있다는 것입니다.
또한 멀티모달 학습에서는 여러 개의 모달리티를 한꺼번에 학습하기 때문에, 최적화의 불균형이 발생하여 특정 모달리티에 편향되는 문제가 발생합니다. [그림 1]을 보면 video를 사용했을 때 보다 audio를 사용했을 때의 성능이 더 좋은 것을 확인할 수 있는데요, 저자들은 이를 멀티모달 학습 시 video 보다 audio에 집중하기 때문이라고 분석하였고, optimization imbalance phenomenon이라 하였습니다.
이를 해결하기 위해 논문에서는 OGM-GE라는 방법론을 제안하였으며 자세한 설명은 method 부분에서 진행하도록 하겠습니다. [그림 1]에서 결과만 놓고 보자면 기존 멀티모달 모델에 비해 각 단일 모달리티의 성능을 끌어올린 것을 확인할 수 있습니다.
논문의 contribution을 정리하자면 아래와 같습니다.
- under-optimized representation으로 인한 joint multimodal model의 성능이 제한되는 optimization imbalance phenomenon을 발견하고, 이를 최적화 관점에서 분석
- 각 모달리티의 최적화 과정을 동적으로 제어하고 일반화 능력을 향상시켜 최적화 imbalance 문제를 해결하기 위한 OGM-GE 제안
Method
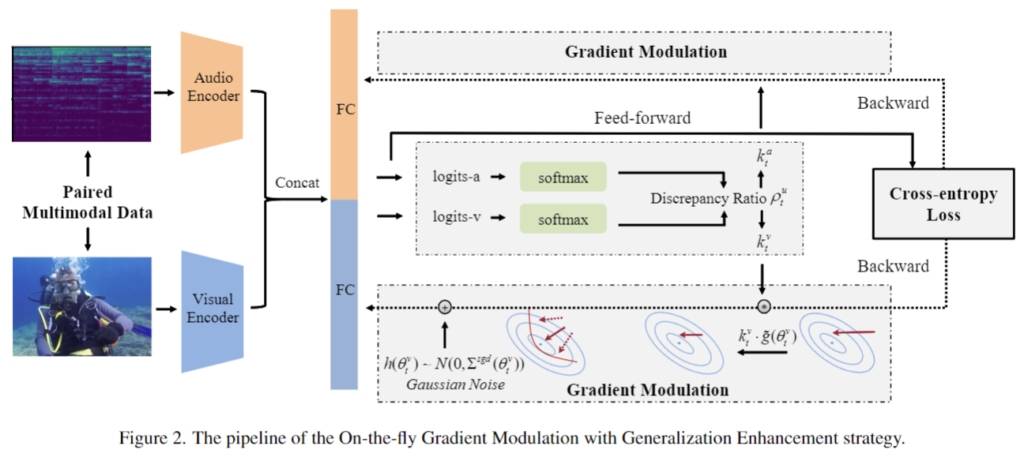
[그림 2]는 논문에서 주장하는 멀티모달 모델의 구조입니다. visual 과 audio 모달리티를 사용하였으며 각각 encoder를 통과하여 concat하여 fc레이어를 통화하는 방식으로 fusion을 진행하여 classification task를 수행합니다. 여기까지는 기존 모델과 같지만 추가적으로 모달리티 별 logit으로 discrepancy ratio를 구하여 gradient modulation을 수행하고 gaussian noise를 구하게 됩니다.
여기서 discrepancy ratio가 핵심적인 요소라고 할 수 있는데, 논문에서는 이를 멀티모달 task에서 모달리티 간 imbalance한 정도를 나타내기 위해 사용하였습니다.
Optimization imbalance analysis
멀티모달 모델에서 모달리티가 imbalance하다는 것은 특정 modality가 dominant한 것이라고도 할 수 있습니다. 이를 증명하기 위해서는 두 모달리티 간의 상관 관계를 파악할 필요가 있는데요, 저자들은 이를 수식적으로 분석하고자 하였습니다.
예를 들어 어떤 visual-audio 데이터 셋 D = \{ (x_i, y_i) \}_{i=1}^{N}가 있고, D에서 추출한 feature x_i = (x^{a_i}, x^{v_i})와 x에 대응하는 gt Y가 있을 때, x를 통해 y를 예측하는 classification은 아래의 그림과 [수식1]과 같이 나타낼 수 있습니다.
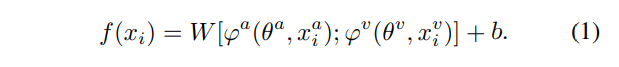
이때 [수식 1]에서 W는 FC레이어의 파라미터, \phi는 audio, visual encoder를 나타내고, \theta는 각 encoder의 파라미터를 나타냅니다. 본 논문에서 auidio, visual feature의 fusion은 단순 concat을 통해 진행하였다고 합니다. [수식 1]의 f(x_i)는 모델을 통해 예측된 logit이 되는데요, 이때 저자들은 모델을 optimize할 때 서로 다른 모달리티가 어떻게 상호 작용하는지 관찰하고자 하였습니다. 즉, audio에 관련된 부분과 video에 관련된 부분을 각각 고려하고자 하였고, 이를 위해 W를 [W^a, W^v]와 같이 두 모달리티에 대응되는 가중치의 결합으로도 표현하였으며, [수식 1]을 아래의 [수식 2]와 같이 변형하였습니다.
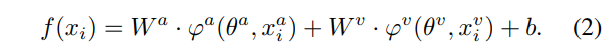
어떤 class c 에 대한 logit을 f(x_i)_c라고 할 때, Gradient Descent 방식으로 optimization을 진행하면 모델의 가중치 W^a, \theta^a는 각각 아래의 [수식 3], [수식 4]와 같이 업데이트됩니다.
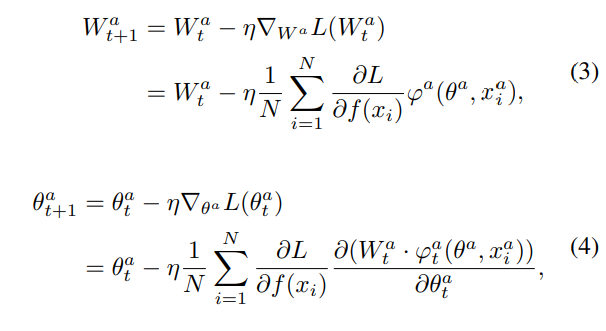
위 수식에서 \eta 은 learning rate를 나타냅니다. 그리고 위 수식에서는 audio 모달리티만 표현하였으나 W^v, \theta^v 또한 동일한 방식으로 업데이트가 진행됩니다.
저자들은 [수식 3], [수식 4]를 통해 각 모달리티 별 가중치를 최적화할 때 을 제외한 나머지 부분에서는 모달리티 간 연관성이 없다는 것을 발견하였습니다. 즉, encoder 부분을 최적화 할 때 다른 모달리티에 의해 영향을 받는 부분은 \partial L \over \partial f(x_i) 밖에 없다는 것인데요, [수식 2]와 [수식 4]를 통해 해당 부분을 정리하면 [수식 5]와 같이 나타낼 수 있습니다.
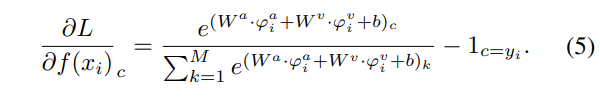
만약에, 정답 class가 y_i이고 모든 c \neq y_i에 대하여 e^{W^v \cdot \phi^v}_{y_i} \gg e^{W^v \cdot \phi^v}_c 이고, 모든 c에 대해 e^{W^v\cdot \phi^v}_{y_i} \gg e^{W^a \cdot \phi^a}_c이면 \partial L \over \partial f(x_i)_c은 거의 0에 가까워집니다. 풀어서 설명드리자면 위의 수식은 visual 모달리티에 의해 충분히 학습이 이루어져 정답 class를 높은 score로 예측하고, 모든 class score가 audio 모달리티보다 높아지는 경우, loss의 미분값이 거의 0에 가까워져 audio모달리티는 추가적인 학습이 이루어질 수 있음에도 더 이상의 update가 진행되지 않음을 의미합니다.
On-the-fly gradient modulation
앞서 멀티모달 모델의 학습에는 모달리티 간의 불균형으로 인해 한 모달리티가 다른 모달리티의 학습을 억제하는 현상이 발생한다고 분석하였습니다. 이를 해결하기 위해 저자들은 On-the-fly Gradient Modulation(OGM)이라는 학습 전략을 제안하였습니다. OGM은 Discrepancy ratio를 통해 모달리티의 학습 기여도를 측정하고, 기여도가 더 높은, 즉, 더 우세한 모달리티의 gradient에 penalty를 가함으로써 모달리티 간의 균형적인 학습을 진행할 수 있도록 하였습니다.
Discrepancy ratio \rho^u_t는 [수식 8], [수식 9]와 같이 모델이 정답을 예측했을 때 어떤 모달리티와 다른 모달리티의 confidence score의 비율로 설계되었습니다.
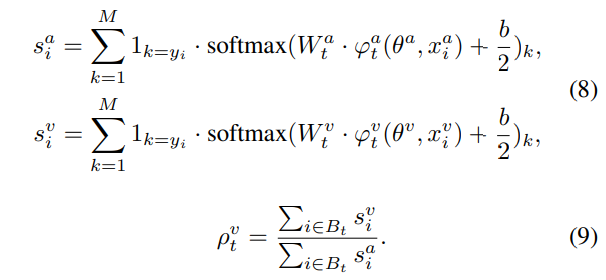
[수식 9]는 visual 모달리티의 discrepancy ratio의 예시로 이때 \rho^v_t가 1보다 큰 경우 전체 모델에서 visual 모달리티가 dominant 함을 의미합니다.
Discrepancy ratio를 통해 dominant한 모달리티를 알아내었다면, dominant한 모달리티에 [수식 10]의 k라는 계수를 곱하여 gradient를 줄여주게 됩니다.
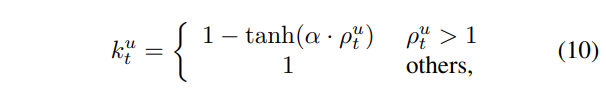
\rho^u_t가 1보다 큰 경우, 즉 모달리티 u가 dominant하면 k^u_t 은 [0, 1]범위의 값을 가지게 되어 gradient에 곱해주게 되겠죠. 두 모달리티 간의 격차가 크면 \rho^u_t의 값이 증가하여 k의 값이 감소하여 penalty가 증가합니다.
파라미터 업데이트를 수식으로 나타내면 [수식 11]과 같이 나타낼 수 있으며, \tilde{g}는 gradient를 의미합니다.
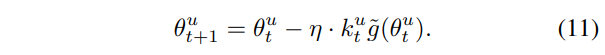
k^u_t를 통해, dominant한 모달리티의 optimization이 완화되며, 이때 다른 모달리티는 k의 영향을 받지 않고 충분한 학습을 통해 imbalance 문제를 해결할 수 있었다고 합니다.
Generalization enhancement
저자들은 추가적으로 generalization능력을 향상시키기 위해 gradient에 무작위로 샘플링된 가우시안 노이즈를 추가하였습니다. 이때 노이즈가 추가된 방법론은 OGM-GE로 명명하였습니다.
SGD 최적화를 수식으로 나타내면 아래의 [수식 7]과 같습니다.
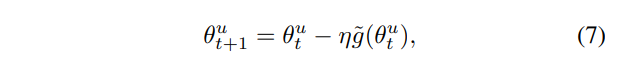
이때 중심극한정리에 의해 batch size가 충분히 큰 경우 \tilde{g}(\theta^u_t) 는 정규분포를 따르게 됩니다. [27]논문에 따르면 gradient는 [수식 12]와 같이 평균이 \nabla _{\theta ^{u}} L(\theta _{t}^{u}), 분산이 \Sigma ^{sgd}(\theta _{t}^{u})인 정규분포이며, \Sigma ^{sgd}(\theta _{t}^{u})는 [수식 13]과 같이 나타낼 수 있다고 합니다.
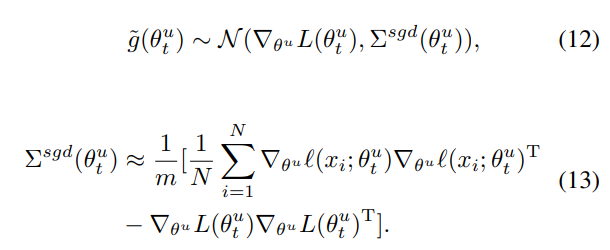
[수식 12], [수식 13]을 [수식 7]에 대입하면 아래의 [수식 14]와 같이 정리할 수 있으며, \xi 는 noise를 나타냅니다.
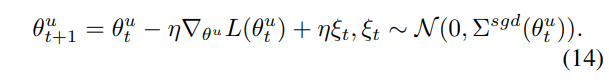
[21]에 따르면 SGD에서 noise는 model의 일반화 성능과 관련이 있는데, noise가 클수록 새로운 데이터에 대한 모델의 generalization 성능이 향상될 확률이 높다고 합니다. 저자들은 이를 바탕으로 SGD의 nosie를 강화하는 방법론인 Generalization Enhancement(GE)를 제안하였습니다.
해당 방법론은 gradient에 동일한 공분산을 가지며, iteration에 따라 무작위로 샘플링된 gaussian noise h(θ^u_t ) ∼ N (0, \sum^{sgd}(θ^u_t))를 추가하는 것으로 OGM에 적용하였을 때 [수식 16]과 같이 나타낼 수 있습니다.
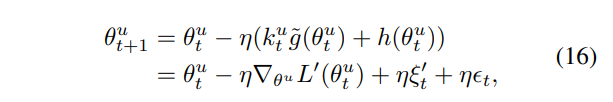
이때 ϵ_t ∼ N (0, Σ_{sgd}(θ^u_t ))이며, ϵ_t, ξ_t가 독립이기 때문에, [수식 16]은 [수식 17]과 같이 표현할 수 있습니다.
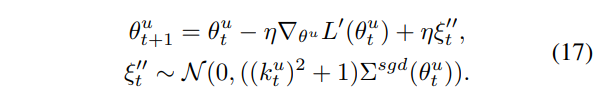
Experiments
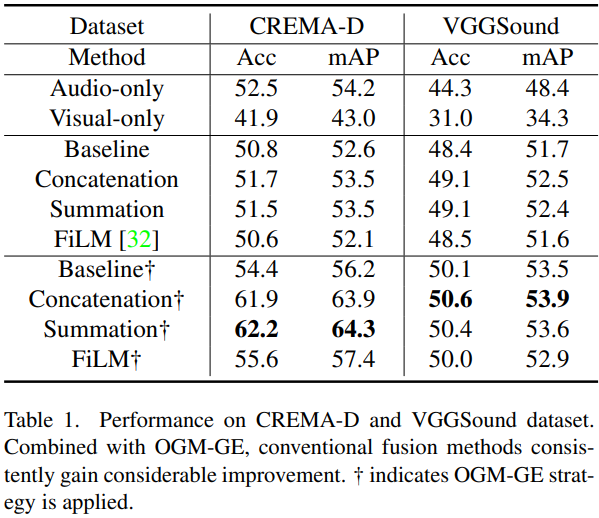
[표 1]에서 두 번째 구역은 baseline이고 아래의 3번째 구역은 OGM-GE를 적용한 결과로, OGM-GE를 적용했을 때 성능이 향상되는 것을 볼 수 있습니다. 이 실험에서 주목할 점은 기존 방법론들의 실험 결과에서 audio-only가 visual-only보다 더 높은 성능을 달성하여 각 uni-modal의 performance가 imbalance하다는 것이며, fusion method를 활용했을 때보다도 좋은 성능을 달성한 것을 확인할 수 있습니다.
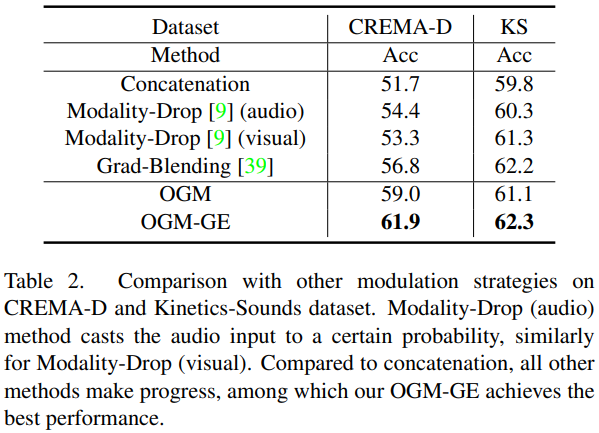
[표 2]는 OGM-GE와 OGM의 성능을 비교한 것으로, OGM-ME가 더 좋은 성능을 보이는 것을 확인할 수 있습니다.
[21] Stanislaw Jastrzebski, Zachary Kenton, Devansh Arpit, Nicolas Ballas, Asja Fischer, Yoshua Bengio, and Amos Storkey. Three factors influencing minima in sgd. arXiv preprint arXiv:1711.04623, 2017.
[27] Stephan Mandt, Matthew D Hoffman, and David M Blei. Stochastic gradient descent as approximate bayesian inference. arXiv preprint arXiv:1704.04289, 2017.
안녕하세요 혜원님 좋은 리뷰 감사합니다.
본문에서 encoder 부분을 최적화 할 때 다른 모달리티에 의해 영향을 받는 부분은 ∂L/∂f(xi) 밖에 없다고 하셨는데 Method 부분에서 visual 과 audio 모달리티를 사용하여 각각 encoder를 통과하여 concat하여 fc레이어를 통과하는 방식으로 fusion을 진행하는 구조를 보입니다. 그렇다면 각 모달리티에 대한 W , θ 모두 최적화할때 영향이 있을 것 같은데 이에 대해서 추가 설명해주실 수 있나요??
감사합니다.