안녕하세요, 스물다섯 번째 X-Review입니다. 이번 논문은 2022년도 CVPR에게재된 Attention Concatenation Volume for Accurate and Efficient 논문입니다. 그럼 바로 리뷰 시작하겠습니다. ?
1. Introduction
Stereo matching은 rectified된 스테레오 영상 쌍에서 pixel 별로 disparity를 추정하는 task입니다. 최근 cnn을 이용한 stereo matching 방법론들은 크게 4 단계로 구성되어 있습니다. 1) feature extraction 2) cost volume 구성 3) cost aggregation 4) disparity regression 순으로 말이죠.
cost volume은 왼쪽 영상 픽셀과 오른쪽 영상 픽셀에 대한 유사도를 나타낸다고 보면 되는데, 이 cost volume을 이용해 그 다음 단계인 cost aggregation, disparity 추정까지 하게되니 cost volume을 잘 생성하는 것이 꽤나 중요합니다. 정보를 잘 담고 있고, 간결한 cost volume 표현이 최종 성능과 계산 복잡도를 결정하게 되는 것입니다.
그래서 이 cost volume을 어떻게 생성할 것인지에 대한 다양한 방법이 대두되었습니다. 먼저, 좌 우 feature map 간의 상관관계를 계산한 correlation volume을 사용했습니다. 이렇게 생성한 볼륨같은 경우 유사도를 측정하는데 꽤나 효율적인 방식일 수는 있지만, 컨텐츠 정보의 손실이 생길 수 있습니다. 다음으로는 풍부한 컨텐츠 정보를 담기 위해 좌 우 feature map을 disparity 축으로 concat함으로써 4D volume을 생성하는 방식이 있었는데, 이렇게 concat하여 생성한 volume은 두 feature map간의 similarity는 고려하지 않는다는 단점과 함께, aggregation과정에서 similarity를 측정하기 위해서는 많은 수의 3D convolution이 필요하다는 단점이 존재했습니다. 앞선 두 방식의 문제점들을 해결하기 위해 GwcNet같은 경우는 correlation volume을 그룹으로 나눈 후 이 그룹별로 concat하는 방식을 취함으로써 컨텐츠 정보와 matching(similarity) 정보 둘 다 인코딩된 최종 4D cost volume을 생성하는 방식을 제안하였습니다. 본 논문의 저자는 이 GwcNet의 아이디어를 착안하는 듯 하지만, 상관관계 volume과 concat volume의 데이터 분산이나 특성이 꽤 다르다고 지적합니다. correlation volume같은 경우는 내적을 통해 similarity를 측정함으로써 생성되는 것이고 concat volume은 각 feature를 concat함으로써 생성되는 것이니깐요. 그래서 단순히 이 두 volume을 concat한 후 3D convolution을 통해 정규화하는 것은 이 두 볼륨의 장점을 완전히 사용하는 것이 아니라고 합니다.
무튼.. 이런 연구들은 지금까지 더 효율적이고 효과적인 cost volume을 생성하는 것에 집중해왔습니다. cost aggregation과정에서의 짐을 좀 줄이고 좋은 성능을 내는 cost volume을 생성하는 것에 집중해왔던 것이죠. 저자는 두가지 관찰을 한 것을 기반으로 한 모델을 제안하게 됩니다. 두가지 관찰은 다음에 대한 것입니다. 1) concatenation 볼륨은 풍부한 컨텐츠 정보를 갖고 있지만, 정보의 상당수가 중복된다. 2) 좌우 영상 feature의 유사도를 측정함으로써 생성된 correlation 볼륨은 이웃 픽셀과의 관계 정보도 암시적으로 담고있어서 주위에 있는 픽셀이 같은 class나 카테고리에 속한다면 유사한 similairty를 갖는다.
이런 관찰을 통해 저자들은 픽셀들간의 관계를 미리 인코딩하는 correlation volume을 사용한다면 concatenation volume에서의 중복된 정보를 억제하는 동시에 matching을 위한 어느정도의 정보는 유지할 수 있다는 결론을 내립니다.
앞선 직관을 염두에 두고, 저자들은 attention concatenation volume(이하 ACV)를 제안합니다. 이 ACV는 correlation volume을 통해 어텐션 가중치를 생성하도록 한 후 이 가중치를 이용해 concat 볼륨을 필터링하는 식으로 생성됩니다. 이에 대해서는 메소드 부분에서 자세히 설명하도록 하겠습니다. 추가적으로 저자는 더 정확한 유사도 측정을 위해서 새로운 multi-level의 adaptive patch matching 방식을 제안하였습니다.
제안된 ACV를 통해 정확도를 높인 술 있었으며, cost aggregation 과정도 가볍게 할 수 있었다고 합니다. 실험 결과로 GwcNet에서의 cost 볼륨을 ACV로 대체한 결과 기존에 28개의 3D convolution을 사용하여 cost aggregation 과정을 수행해야 했던 것에 비해 오직 4개의 3D convolution만을 사용하여 cost aggregation 할 수 있었고 정확도도 더 높았다고 합니다. 이렇게 ACV는 다양한 3D CNN 기반 스테레오 모델에 붙일 수 있는 모듈로, PSMNet과 GwcNet에 붙인 결과 각각 42%와 39%의 정확도 향상의 결과를 보았습니다.
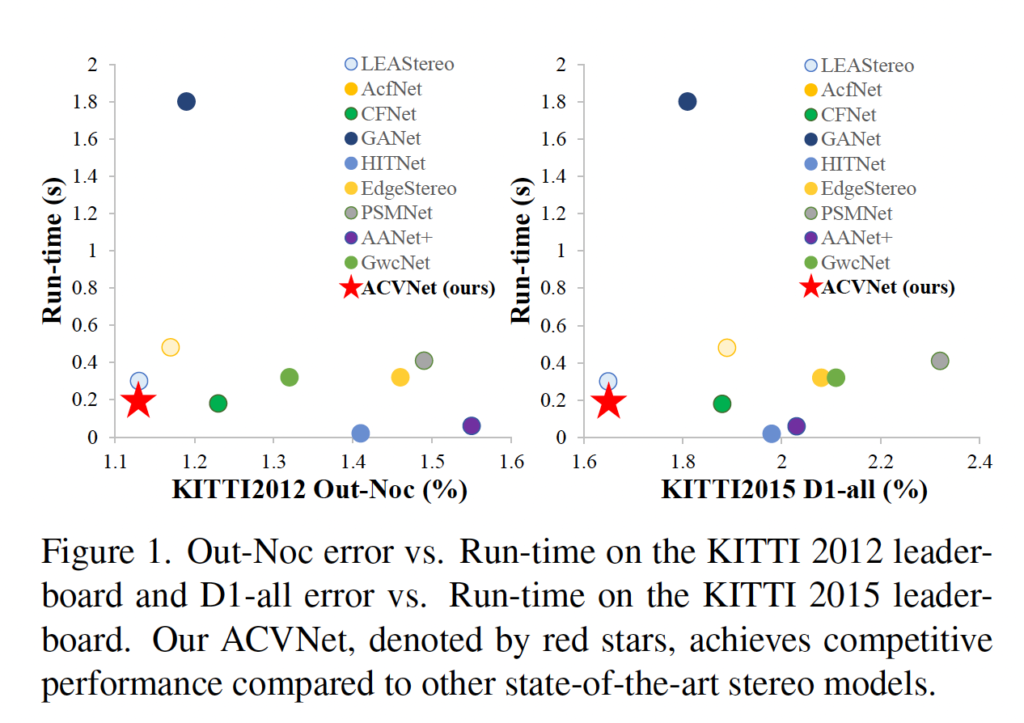
KITTI2012와 2015에서 error율과 runtime을 비교한 figure입니다. 빨간색 별이 ACVNet에 해당하는데 다른 방법론들에 비해 상대적으로 runtime 속도도 빠르고 error율도 낮은 것을 확인할 수 있습니다.
2. Method
2.1. Attention concatenation volume
attention concatenation volume (이하 ACV) 생성 방식은 3가지 단계로 이뤄집니다. 1) initial concatenation volume construction 2) attention weights 생성 3) 어텐션 필터링
순서대로 알아보도록 하겠습니다.
Initial concatenation volume construction
H x W x 3 크기를 갖는 스테레오 입력 영상 쌍이 주어질 때, 각 영상에 대해 feature extraction 과정을 통해 f_l, f_r feature map을 각각 얻을 수 있습니다. 이 feature map 사이즈는 N_c x H/4 x W/4 (N_c는 32)입니다. 초기 concat 볼륨은 식 1과 같이 disparity 레벨로 concat함으로써 생성할 수 있습니다.
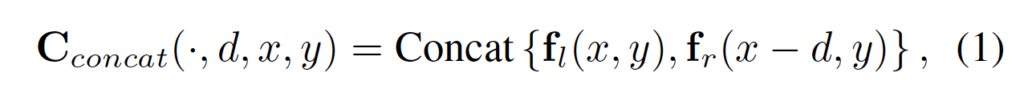
이렇게 생성된 cost volume C_{concat}은 2N_c x D/4 x H/4 x W/4의 크기를 갖게 되겠죠. 여기서 D는 disparity의 최대값입니다.
Attention weights generation
다음으로는 어텐션 가중치 생성 방식입니다. 이 어텐션 가중치는 방금 전 생성한 초기 concat 볼륨을 필터링할 때 사용되는 것으로 유용한 정보는 강조하고, 관련 없는 정보는 억제하는 효과를 갖습니다. 이를 위해 저자들은 두 스테레오 영상 쌍에 대한 상관관계에서 기하학적인 정보를 추출함으로써 어텐션 가중치를 생성하고자 하였습니다. 기존의 상관관계 볼륨같은 경우 pixel-to-pixel로 유사도를 계산하게 되는데, 이럴 경우 텍스철가 없는 경우에서는 충분한 매칭 단서가 부족해서 신뢰할 수 없는 유사도가 측정됩니다. 본 논문에서는 이런 문제를 해결하기 위해 multi-level adaptive patch matching(이하 MAPM)을 제안합니다.
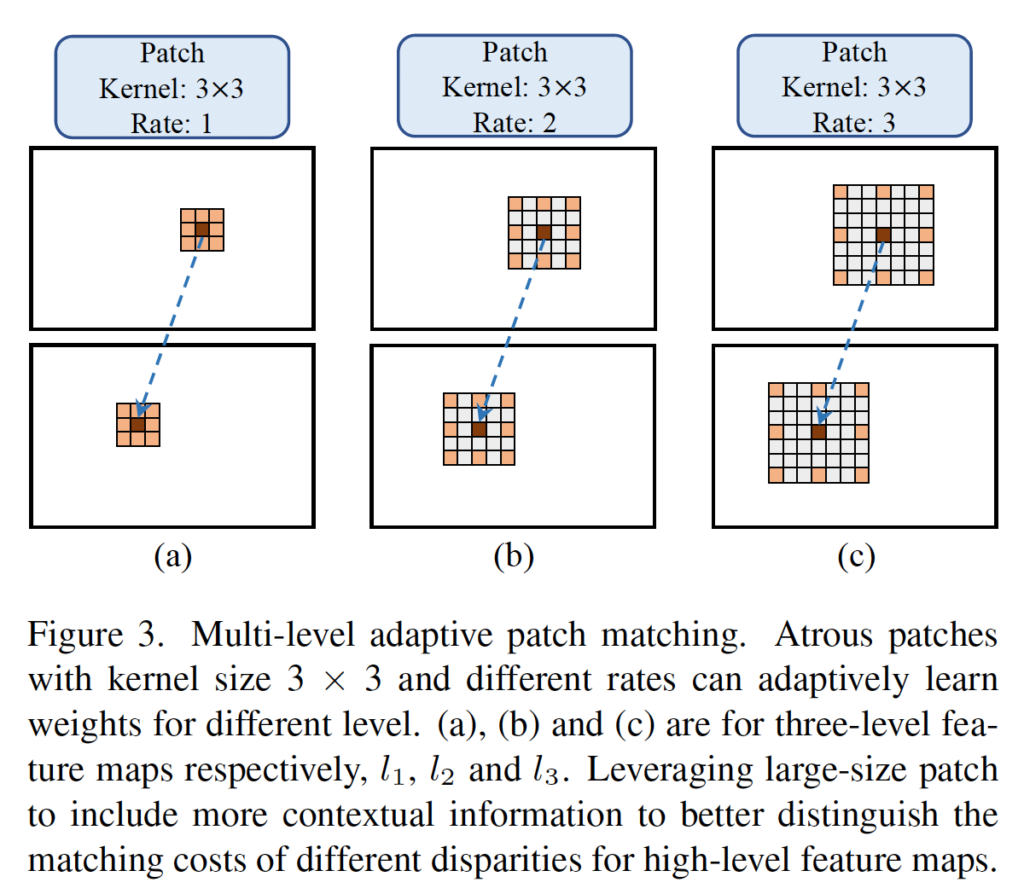
Figure 3이 MAPM에 대한 주요 아이디어를 보여줍니다. 우선 특징 추출 단계에서 각각 다른 수의 channel(각각 64, 128, 128)을 갖는 3 level의 feature map(l_1, l_2, l_3을 생성합니다. 이후 특정 레벨에서 각 픽셀에 대해 미리 사전에 정의한 크기의 atrous patch와 adaptive하게 학습된 가중치를 사용해 matching cost를 계산합니다. 구체적으로 fig3에서 (a)는 low-level의 feature map에 적용되는 patch이며, (b), (c)는 각각 그 다음 high-level feature map에 적용되는 patch입니다. 미리 사전에 (a), (b), (c)에 대한 각각의 dilation rate를 1, 2, 3으로 정의해두었다는 의미입니다.
Dialtaiton rate를 사전에 정의함으로써 feature map level에 따른 patch의 범위를 제어할 수 있었으며 이는 결국 한 중심 픽셀에 대해 similarity를 계산할 때 동일한 수의 픽셀을 유지할 수 있게 됨을 의미합니다. 결론적으로, 두 픽셀간의 유사도는 patch 내의 대응되는 pixel들간에 correlation을 가중합함으로써 계산됩니다.
저자는 GwcNet의 group-wise 아이디어를 채택해왔는데, 이 group-wise 아이디어란 feature를 여러 그룹으로 나눈 다음 각 그룹별로 correlation map을 계산해내는 방식을 의미합니다. 본 논문의 경우에는 3 level의 feature map (l_1, l_2, l_3)이 존재했고 각각의 channel 수는 64, 128, 128이었습니다. 우선 이들을 concat하여 N_f 채널 수를 갖는 단일 feature map을 생성합니다. (N_f의 경우에는 64+128+128로 320입니다) 이후 이 N_f 채널을 N_g 그룹으로 나누게 되는데 여기서 N_g는 40입니다. 그럼 한 그룹은 8channel을 갖는 feature map이겠죠. 그럼 앞에서 8개의 그룹이 l_1, 중간의 16개의 그룹이 l_2, 마지막 16개의 그룹이 l_3로부터 나오게 된 것입니다.
수식으로 살펴보자면, 다른 level의 feature map은 서로 연관되지 않으며, g번째 feature group을 f_l^g, f_l^g라고 명시한다고 할 때 multi-level의 패치 매칭 볼륨 C_{patch}는 아래 식 2를 통해 계산됩니다.
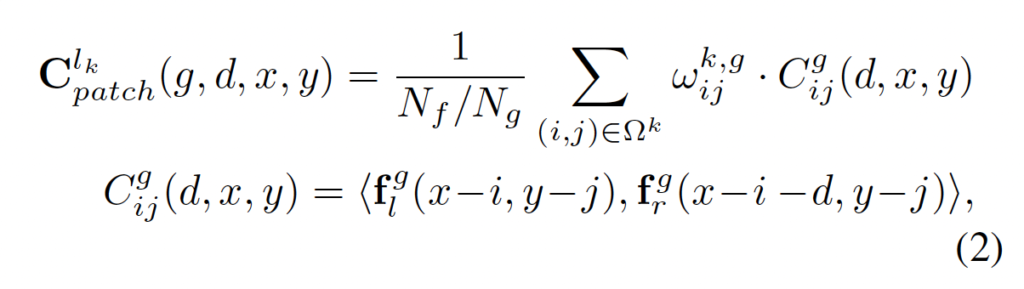
C^{l_k}_{patch}(k∈(1, 2, 3))은 각 다른 feature level k에서의 matching cost를 나타냅니다.
<.,.>는 내적 기호이며, (x, y)는 matching cost를 계산하는 현재 픽셀의 위치, d는 disparity를 의미합니다.
Ω^k = (i, j) (i, j ∈ (-k, 0, k))으로 fig3에서 보았듯이 한 픽셀에 대해서 k만큼 떨어져 있는 주위 9개의 pixel 좌표에 해당합니다. 예를 들어 l_1은 fig3의 (a)에 해당한다고 하였으니, 주위 픽셀은 (-1, -1) ~ (1, 1)의 좌표를 갖는 픽셀에 해당하겠죠. 이때 (0, 0)일 때가 빨간색 픽셀, 나머지가 주황색 픽셀에 해당합니다.
x^k_{ij}는 k-level 특징맵에서 patch에 존재하는 (i, j) 픽셀의 weight에 해당하며, training 동안 adaptive하게 학습됩니다.
최종 multi-level 패치 매칭 볼륨은 아래 식3에서 볼 수 있듯이, 각 level에서의 C^{l_k}_{patch}(k∈(1, 2, 3))를 concat하여 얻어집니다.

최종적으로 얻어지는 multi-level 패치 매칭 볼륨 C_{patch}는 N_g x D/4 x H/4 x W/4의 크기를 가지고, 이후 2개의 3D conv와 3D hourglass 네트워크를 통과하며 정규화 과정을 거치게 됩니다. 이후 또다른 합성곱층을 통과함으로써 1의 channel을 갖는 output이 나오게 되고 이는 곧 어텐션 가중치(이하 A)로 사용됩니다. 이때 어텐션 가중치 A는 1 x D/4 x H/4 x W/4크기를 갖게 됩니다.
이때 보다 정확한 attention weight를 얻기 위해서 A를 gt disparity를 사용하여 지도학습하였다고 합니다. 구체적으로는 A를 가지고 추정한 disparity d_{att}를 gt disparity 사이의 smooth L1 loss를 사용하여 네트워크를 학습해 정확한 A를 얻도록 하였습니다.
Attention filtering
이렇게 어텐션 가중치 A를 얻었다면 이를 초기 concat volume에서 중복된 정보는 제거하고, 표현력을 향상하는데 사용할 수 있습니다. 최종적으로 channel i에서의 attention concatenation volume C_{ACV}은 아래와 식 4를 통해 계산됩니다.
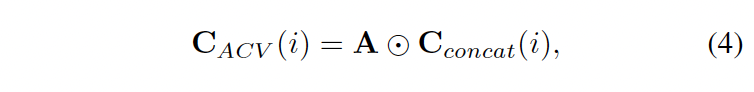
⊙ 는 element-wise product를 의미합니다. 어텐션 가중치 A는 initial concat volume의 모든 채널에 적용됩니다.
2.2. ACVNet architecture
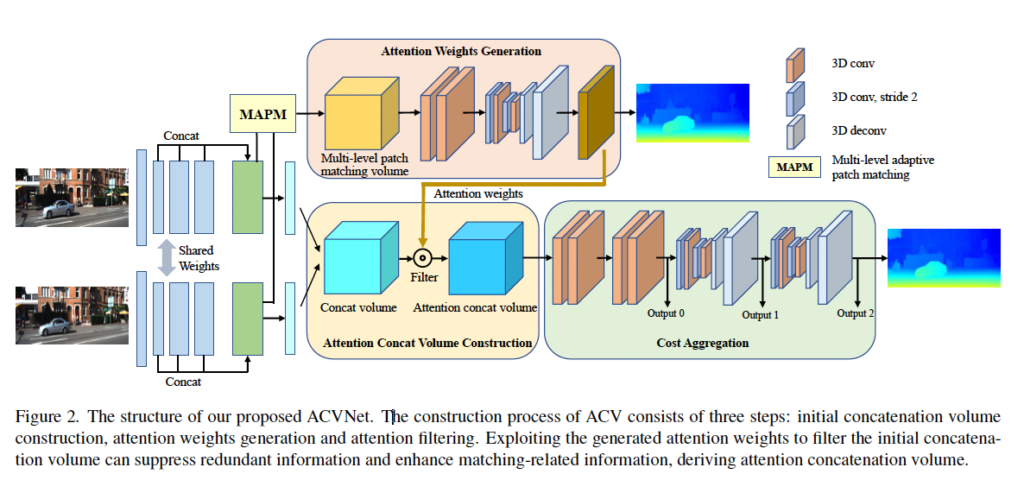
앞서 제안한 ACV에 기반하여 정확하고 효율적인 end-to-end 스테레오 매칭 네트워크 ACVNet을 제압합니다. Figure2에서 ACVNet의 아키텍처를 살펴볼 수 있습니다. feature extraction, attention concatenation volume 구축, cost aggregation, disparity 예측으로 크게 이 네 모듈로 구성되어 있습니다. 아래에서 각 모듈에 대해 자세히 서술하도록 하겠습니다.
Feature extraction
feature extractor로는 3 level의 resnet과 유사한 아키텍처를 사용하였습니다. 특징 추출기를 통해 얻게되는 feature map들 l_1, l_2, l_3들은 입력 영상에 대해 1/4 크기를 갖고 세 특징맵을 concat했을 때 320 채널을 갖게 됩니다. 이 320 채널을 갖는 concat한 feature map에 대해서는 앞서 2.1에서 설명했듯이 attention weight를 생성하게 됩니다. 또 이 320 채널을 갖는 특징맵은 fig2에서 확인할 수 있듯이 2개의 convolution을 더 타고 나와 32채널을 갖는 feature map(f_l, f_r이 되어 초기 concat volume을 구축하는데 사용됩니다.
Attention concatenation volume construction
이 모듈은 320 채널을 갖는 특징맵을 가지고 어텐션 가중치를 생성하고, f_l, f_4를 이용해 초기 concat volume을 구축합니다. 그 다음 어텐션 가중치를 이용해 초기 concat volume을 필터링하여 최종적으로 4D cost volume을 생성해내게 됩니다. 이 부분 역시 앞선 2.1에서 설명드렸으니 디테일한 설명은 넘어가도록 하겠습니다.
Cost aggregation
다음 단계는 ACV(Attention concatenation volume)을 가공하는 cost aggregation 단계입니다. fig2에서 보시다시피 단순히 4개의 3D convolution을 통과하고 2개의 3D hourglass network를 통과하는 것이 끝입니다.
Disparity prediction
그림 2에서 보시면 cost aggregation 과정에서 중간 중간마다 output이 나오게 되어 총 3개의 output이 나옵니다. 각각의 output마다 2개의 3D conv를 통과시켜 1 채널의 4D 볼륨을 생성해 내었고 upsampling 과정을 거친 후 disparity 차원에 대해 softmax를 적용시켜 probability volume으로 변환하였습니다. 이때 upsampling한 이유로는 원본영상의 각 pixel에 대해서 disparity를 추정하기 위해 그에 맞춰 원본 영상 크기로 맞춰준 것입니다.
최종적으로 아래 식5를 통해 disparity 값을 예측하게 됩니다.
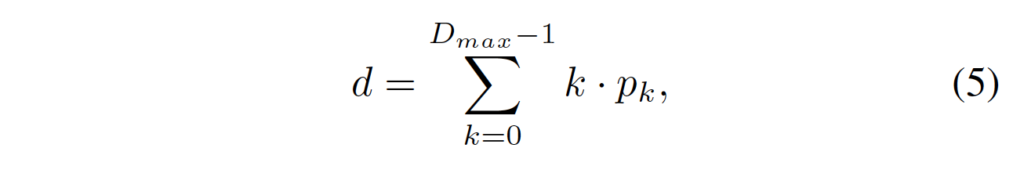
식5는 단순한 soft argmin 함수로 보이며, k는 disparity level을 의미하고 p_k는 그 disparity에 해당하는 확률값을 의미합니다.
2.3. ACVNet-Fast
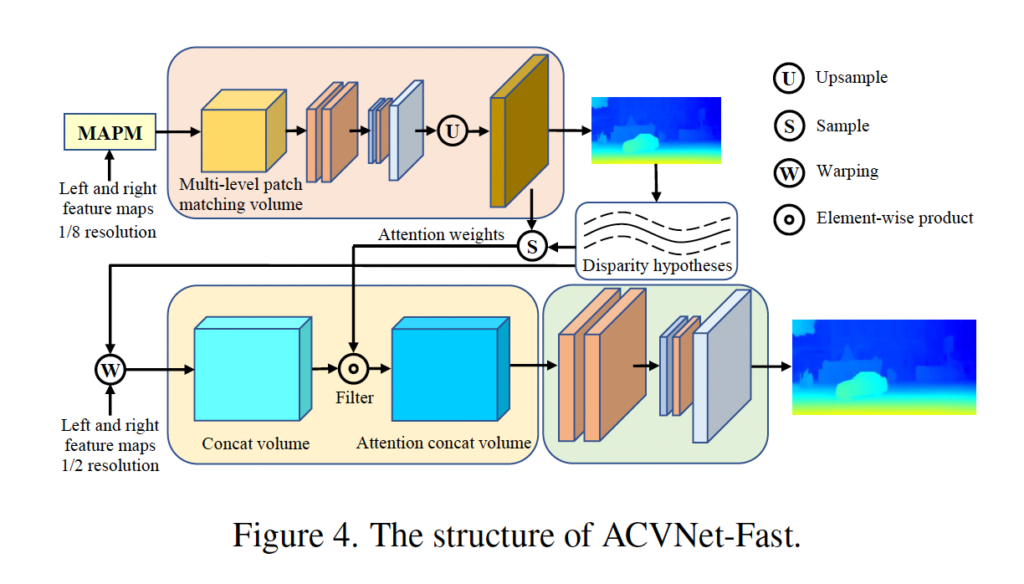
앞서 소개드린 ACVNet 외에 추가적으로 real-time으로 동작할 수 있는 ACVNet-Fast 버전도 존재합니다. ACVNet과 feature extractor는 동일하지만, 이후 단계에서 ACVNet보다 적은 개수의 layer를 사용한 버전입니다. 그림 4에서 ACVNet-Fast의 아키텍처를 살펴볼 수 있는데, 두 네트워크의 가장 큰 차이점은 ACV 구조와 aggregation 모듈에 있습니다.
2.4. Loss function
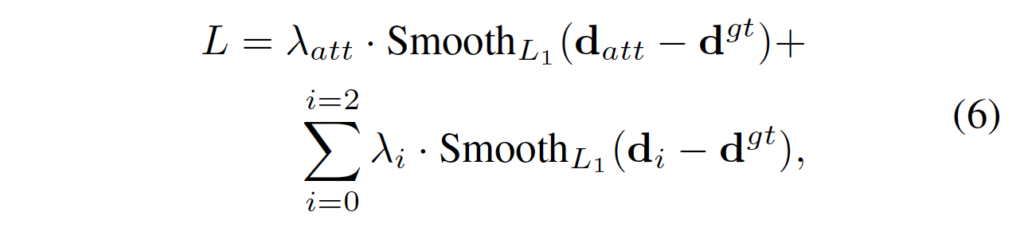
ACVNet의 Loss는 식6과 같습니다. d_{att}는 2.1 섹션에서 다뤘던 attention weight A로부터 추정한 disparity이며, d^{gt}는 gt disparity, λ_{att}는 d_{att}의 계수, λ_i는 i번째 예측한 disparity의 계수입니다. (cost aggregation 과정에서 총 3개의 output이 나왔으니 i의 범위는 0에서 2에 해당) 정리하자면, 어텐션 가중치로부터 예측한 disparity와 gt disparity 사이의 smooth L1 loss와 최종 output들에 대해 예측한 disparity와 gt disparity 사이의 smooth L1 loss 값들을 가중합한것이라고 보면 되겠습니다.
아래 식7은 ACVNet-Fast에 대한 최종 손실함수입니다.
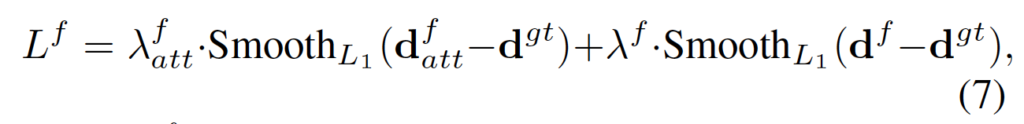
이때는 output이 한개만 나오고 이 한 개의 output에 대한 dispairty 예측만 수행하기 때문에 위와 같은 식이 되겠습니다.
3. Experiment
실험은 SceneFlow 합성 데이터셋, KITTI 2012, 2015, ETH3D에서 수행되었습니다.
3.1. Ablation study
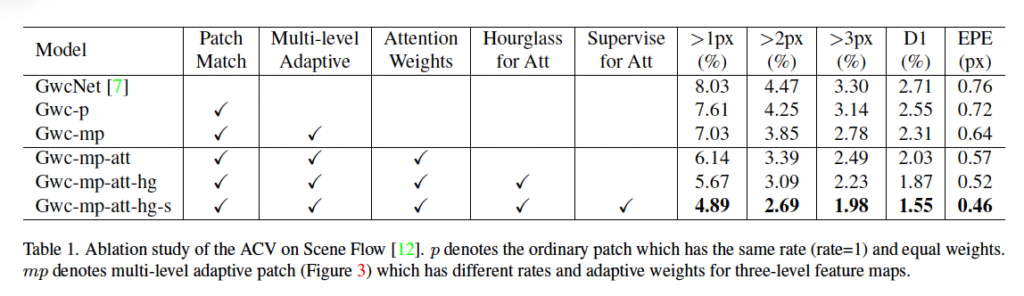
먼저 ablation study부터 보겠습니다. ablation study에서는 GwcNet을 베이스라인으로 삼아 모듈을 하나씩 붙여보며 성능을 비교하였습니다. 최종적으로 모든 모듈을 다 붙인것이 성능이 가장 좋습니다.
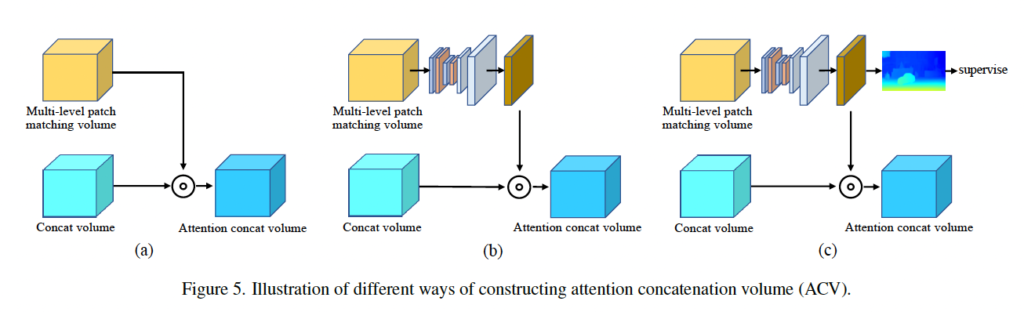
위 fig5는 ablation study 도중의 ACV 구조를 모사한 그림입니다. 가장 왼쪽에 (a)가 table1에서 Gwc-mp-att이며, (b)는 hourglass를 추가한 Gwc-mp-att-hg가 되겠고 (c)는 att를 지도학습하도록 추가한 Gwc-mp-all-hs-s에 해당하겠습니다.
3.2. Universality and superiority of ACV
다음으로 저자가 제안한 ACV(Attention Concatenation Volume)의 범용성을 평가하는 부분입니다. 본 실험에서는 GwcNet, PSMNet, CFNet에 ACV 모듈을 붙인 다음, 붙이기 전과 후의 성능을 비교하였습니다.
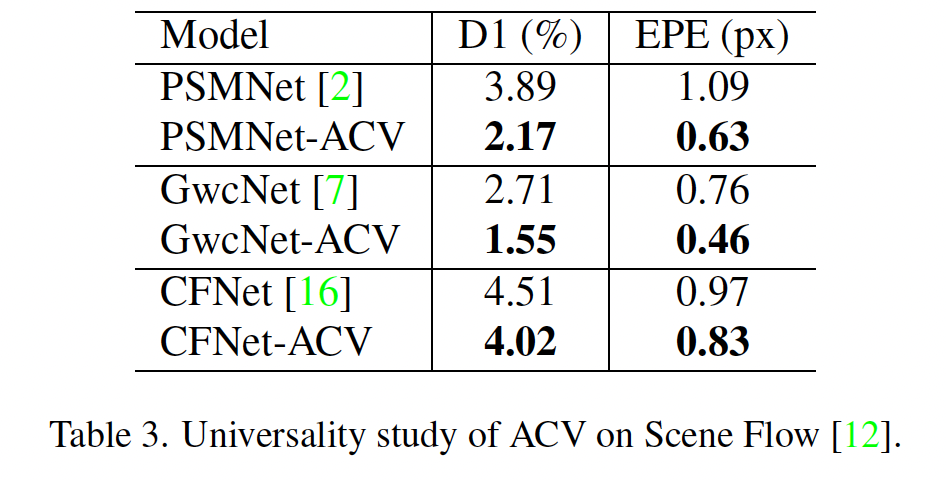
ACV 모듈을 붙인 경과 D1과 EPE가 감소하였고, 이는 곧 성능 향상을 의미합니다.
3.3. ACVNet performance
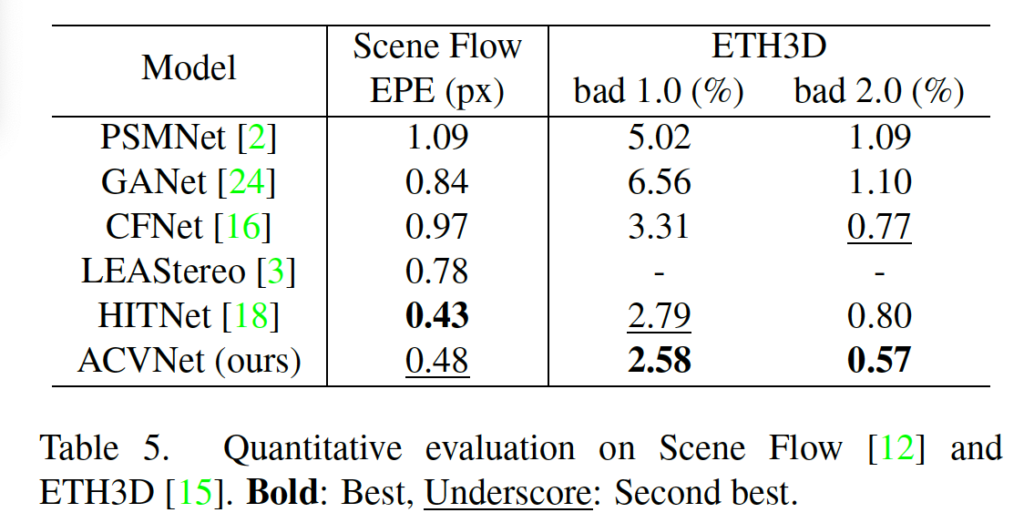
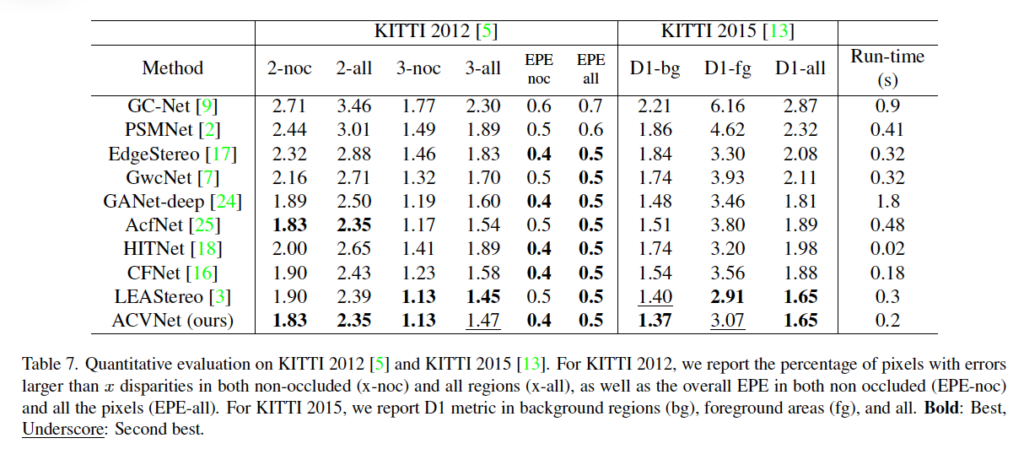
마지막으로 SceneFlow, ETH3D, KITTI 데이터셋에 대한 실험 결과를 보고 마무리하도록 하겠습니다.
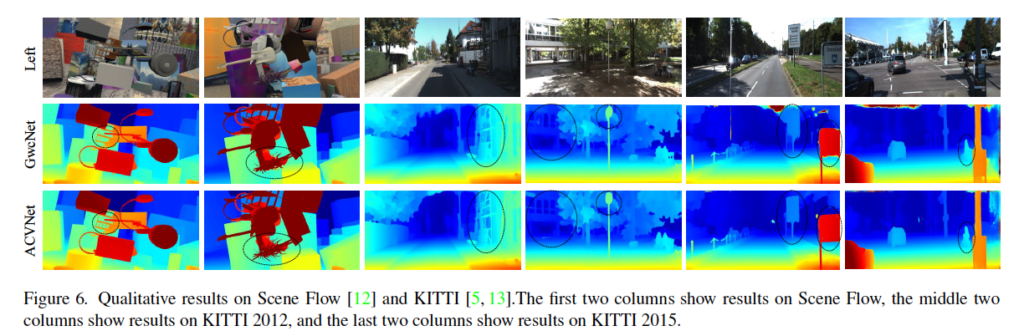
정성적 결과는 fig6에서 확인할 수 있습니다. baseline으로 삼은 GwcNet과 ACVNet을 비교하고 있으며, 잘 안보이시겠지만 동그라미 쳐진 부분을 보면 ACVNet이 더 disparity를 잘 예측하는 것을 확인할 수 있습니다.
리뷰 잘 읽었습니다.
Intro, Method만큼이나, 혹은 이들 보다도 더 중요하고 저자들의 insight를 많이 얻을 수 있는 부분이 Experiment 파트라고 생각하는데 해당 파트에 대한 설명이 조금 부족한 거 같습니다. 주관적인 실험 해석이 어렵다면, 논문에서 각 실험 요소에 대해 저자들이 언급한 부분을 함께 작성해 주시면 해당 연구를 수행할 동료, 선후배에게 많은 도움이 될 거 같습니다.
그리고 매번은 어렵겠지만, 리뷰 작성 후 본 논문에 대한 윤서님의 견해나 얻은 아이디어 등을 적는 연습을 하는것도 좋아보입니다. 사실 논문을 읽는 이유가 이걸 어떻게 하면 내 연구에 써먹을지 고민하면서 읽는 거잖아요??
감사합니다.
넵 좋은 피드백 감사합니다 !
다음 리뷰부터는 제 아이디어를 적는 연습을 해보도록 하겠습니다. . . ?
감사합니다 .