안녕하세요, 스물 네 번째 x-review 입니다. 이번 논문은 2019년도 CVPR에 게재된 PointConv: Deep Convolutional Networks on 3D Point Clouds 입니다. 원래 읽으려했던 논문이 따로 있었는데, 그 논문이 해당 PointConv의 후속 논문이라 이번주는 PointConv를 먼저 읽게 되었습니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
2D 이미지에서는 CNN이 동일한 컨볼루션 필터가 이미지의 모든 영역에 적용되어 translation invariance를 가능하게 하면서 파라미터의 수를 줄이고 genralization을 향상시키며 지배적으로 사용되고 있습니다. 3D 데이터에서도 이러한 CNN이 동일한 영향력을 가지고 사용되길 바라지만 3D 데이터라고 함은 보통 포인트 클라우드의 형태를 가지고 있는데, 이는 순서가 없는 하나의 집합으로 구성되고 각각의 포인트에 RGB와 같은 특성 정보가 포함되기도 하고 아니기도 합니다. 그래서 포인트 클라우드는 2D 이미지와 같이 규칙적인 그리드 격자를 따를 수 없기 때문에 이러한 정렬되지 않은 형태의 입력에 기존 CNN을 적용하기는 어렵습니다. 대안으로 3차원 공간에서 포인트 클라우드를 복셀 볼륨 형태로 변형하여 다룰 순 있지만 이는 볼륨 공간에 비해 포인트 클라우드가 차지하는 공간이 적어 데이터 형태가 더욱 sparse해지고 볼륨이 고해상도로 갈 수록 일반 CNN으로 계산하기 힘들어집니다.
그래서 본 논문에서는 포인트 클라우드를 입력으로 컨볼루션을 수행할 수 있는 새로운 방법론을 제안하고 있습니다. 저자는 컨볼루션 연산은 연속적인 컨볼루션 연산을 이산적인 근사치로 볼 수 있고 3차원 공간에서 이러한 컨볼루션 연산의 가중치는 기준이 되는 3차원 포인트에 대해 로컬한 3차원 포인트의 연속 함수로 취급할 수 있으며 연속 함수는MLP로 근사화할 수 있다고 주장합니다. 그러한 이러한 알고리즘은 비균일한 샘플링 형태의 입력을 고려하지 않기 때문에 inver density scale을 사용하여 MLP로 학습한 연속 함수에 가중치를 다시 부여하는 방식의 PointConv를 제안합니다. PointConv는 포인트 클라우드를 입력으로 MLP를 학습하여 가중치 함수를 근사화하여 학습된 가중치에 inverse density scale을 적용하여 불균일한 샘플링의 입력을 CNN에 사용할 수 있도록 합니다. 이러한 구조를 통해 이미지의 2D CNN과 유사하게 포인트 클라우드를 입력으로 하는 컨볼루션 네트워크를 구성할 수 있으며 2D CNN과 동일하게 translation invariance와 포인트 클라우드의 포인트 순서에 대한 permtation invariance를 보장할 수 있습니다.
본 논문에서의 실험에서는 segmentation을 중점적으로 다루었는데 segmentation의 경우 저도 잘 알지는 못하지만 논문에서 말하기를 corae layer에서 finer layer로 정보가 점진적으로 옮겨가는 능력이 매우 중요하다고 합니다. 그래서 coarse layer에서 finer layer로 feature을 충분히 활용할 수 있는 디컨볼루션 연산이 필수적으로 사용되는데, 대부분의 당시 연구는 디컨볼루션을 수행할 수 없어서 segmentation task에서 성능이 제한되었다고 합니다. PointConv는 PointDeconv로 모델을 확장하여 다른 포인트 클라우드 기반의 모델에 비해 part segmentation과 indoor sementic segmentation 벤치마크에서 SOTA를 달성하였습니다. 또한 PointConv가 포인트 클라우드를 입력으로 실제 컨볼루션 연산을 진행하고 있음을 증명하기 위해서 2D 이미지의 모든 픽셀을 각 포인트의 RGB feature와 함께 2D 좌표를 가진 포인트 클라우드로 변환하여 CIFAR-10에서 PointConv에 대한 평가까지 진행하였습니다. 여기서 본 논문의 main contribution을 정리하면 다음과 같습니다.
- 모든 3차원 포인트에 에서 3차원의 연속적인 컨볼루션을 완전히 근사화할 수 있는 density reweighted convolution인 PointConv 제안
- 현재 2D CNN과 동일한 수준까지 확장할 수 있도록 메모리 효율적인 방식을 설계
- segmentation 성능 향상을 위해 PointConv를 디컨볼루션 버전인 PointDeconv로 확장
2. Method
2.1. Convolution on 3D Point Clouds
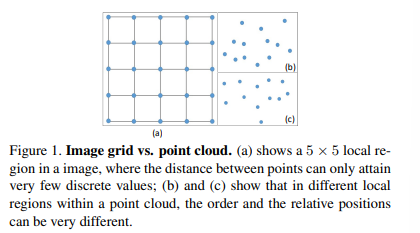
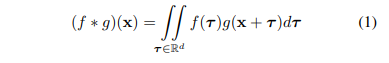
컨볼루션은 공식적으로 보았을 때 d차원 벡터 x의 함수 f(x) 및 g(x)에 대해 식(1)과 같이 정의합니다. 이미지는 일반적으로 격자형으로 표현되는 2차원 이상 함수로 해석할 수 있습니다. CNN에서 각 필터는 3×3이나 5×5와 같이 일정한 로컬 영역으로 제한되는데, 이러한 로컬 영역 내에서 서로 다른 픽셀 간의 상대적인 위치는 Figure1.(a)와 같이 항상 고정되어 있습니다. 그리고 필터는 로컬 영역 내의 각 위치에 대해 실수 형태의 가중치를 사용하여 쉽게 이산화될 수 있습니다. 포인트 클라우드는 \{p_i | i = 1, …, n\}의 집합으로 표현되며 각 포인트에는 위치를 나타내는 (x, y, z)와 색상 혹은 surface normal의 특징이 추가적으로 포함될 수 있습니다. 이미지와 다르게 포인트 클라우드는 보다 felxible한 형태를 가지고 있죠. 포인트 클라우드에서 한 점의 좌표 p = (x, y, z) \in \mathbb{R}^3는 고정된 그리드에 위치하지 않고 임의의 연속적인 값을 가질 수 있기 때문에 각 로컬 영역에서 서로 다른 포인트들 간의 상대적인 위치가 다양합니다. Figure1이 이미지와 포인트 클라우드의 로컬 영역에 대한 직관적인 차이를 보여주고 있는데, 이러한 차이로 인해 이미지의 기존 이산화된 컨볼루션 필터는 포인트 클라우드에 직접 적용할 수 없습니다. 컨볼루션이 포인트 집합에 활용되기 위해서 PointConv라는 permutation invariant한 컨볼루션 연산을 제안하게 된 것이죠.
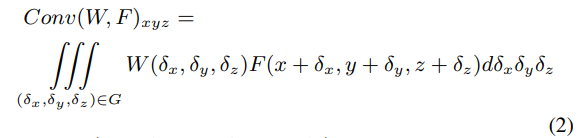
- F(x + \delta_x, y + \delta_y, z + \delta_z) : 포인트 p = (x, y, z)를 중심으로 한 로컬 영역 G에 포함된 포인트의 feature
가장 먼저 식(2)와 같이 3차원 컨볼루션의 연속적인 버전을 살펴보도록 하겠습니다. 포인트 클라우드는 연속적인 \mathbb{R}^3 공간에서 균일하지 않은 샘플로 취급할 수 잇씁니다. 각 로컬 영역에서 (\delta_x, \delta_y, \delta_z)는 로컬 영역에서 가능한 모든 위치를 표현할 수 있습니다.
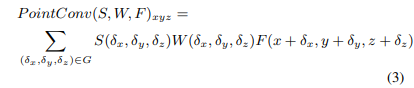
- S(\delta_x, \delta_y, \delta_z) : (\delta_x, \delta_y, \delta_z) 포인트에서의 inverse density
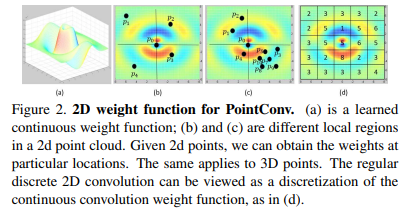
기존의 3차원 컨볼루션 형태를 기반으로 PointConv를 정의한 식(3)을 보면 포인트 클라우드는 매우 불균일하기 때문에 S(\delta_x, \delta_y, \delta_z)를 필요로 하는데 직관적으로 Figure2. (b)와 (c)에서와 같이 로컬 영역의 포인트 수는 전체 포인트 클라우드에 걸쳐서 매우 다양하게 나눠질 수 있습니다. 게다가 Figure2. (c)에서 포인트 p_3, p_5, p_6, p_7, p_8, p_9, p_{10}은 서로 매우 가깝기 때문에 각각의 영향력이 더 작아야 합니다. 본 논문의 주요 아이디어는 3차원 좌표 (\delta_x, \delta_y, \delta_z)(을 MLP로 가중치 함수 W(\delta_x, \delta_y, \delta_z)를 근사화하고 MLP로 구현된 nonlinear transform으로 inverse density (\delta_x, \delta_y, \delta_z)를 근사화하는 것 입니다. PointConv 이전에 유사한 방식으로 포인트 클라우드를 입력으로 CNN 연산을 수행하려는 시도들이 있었는데, 저자는 이전의 방법론들은 가중치 함수의 근사치는 고려하였지만 density scale의 근사치를 고려하지 않았기 때문에 연속적인 컨볼루션 연산의 완전한 근사화가 아니었으며 density를 고려하였더라도 nonlinear transform 연산에 차이가 존재한다고 이야기합니다.
- C_{in}, C_{out} : 입력 feature와 출력 feature에 대한 채널 수
- k : 한 로컬 영역 내의 k번째 이웃에 대한 인덱스
- c_{in}, c_{out} : 한 로컬 영역 내의 k번째 이웃에 대한 입력 feature와 출력 feature의 채널 수
- S : S \in \mathbb{R}^K, density scale
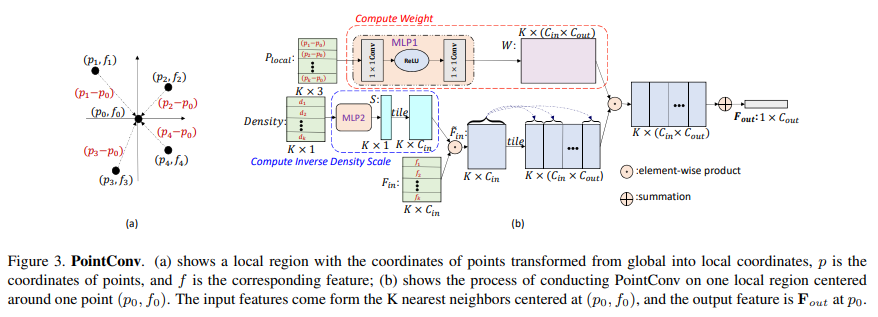
permutation invarianct를 보장하기 위해서 PointConv는 MLP 가중치를 모든 포인트에서 공유하게 됩니다. inverse density의 scale [S(\delta_x, \delta_y, \delta_z)을 계산하려면 먼저 커널 밀도 추정(KDE)를 사용하여 포인트 클라우드의 각 포인트의 density를 추정하고 추정한 density를 MLP에 입력으로 사용하여 1차원 nonlinear transform을 수행합니다. 이렇게 nonlinear transform을 사용하는 이유는 네트워크가 density 추정치를 사용할지의 여부를 adaptive하게 결정하기 위해서라고 합니다. Figure3은 포인트로 이루어진 K개의 이웃 포인트를 가진 로컬 영역에 대한 PointConv 연산 과정을 보여주고 있습니다. 입력은 로컬 영역에서의 위치 좌표인 P_{local} \in \mathbb{R}^{K \times 3}인데, 이러한 입력값은 로컬 영역의 중심 좌표와 로컬 영역의 feature F_{in} \in \mathbb{R}^{K \times 3}과 reference 포인트 값을 빼서 구할 수 있습니다. 1×1 컨볼루션을 사용하여 MLP를 구현하였으며, 가중치 함수의 출력값은 W \in \mathbb{R}^{K \times (C_{in} \times C_{out})}로 각각의 W(k, c_{in}) \in \mathbb{R}^{C_{out}}은 벡터 형태로 이루어져 있습니다.
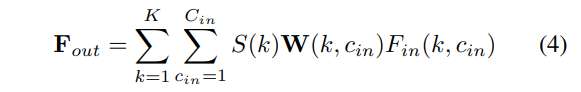
컨볼루션 연산 후에 식(4)와 같이 K개의 이웃 포인트를 가진 로컬 영역의 feature F_{in}이 F_{out} \in \mathbb{R}^{C_{out}}으로 인코딩됩니다. PointConv는 컨볼루션의 연속적인 가중치를 근사화 하는 방향으로 학습하게 되는데, 각 입력 포인트에 대한 상대적인 좌표를 사용하여 MLP의 가중치를 계산할 수 있습니다. Figure2.(a)는 컨볼루션을 위한 연속적인 가중치 함수의 예시를 보여주는데요, 연속적인 입력의 이산화로 포인트 클라우드 입력을 사용하면 Figure2.(b)와 같이 이산적인 컨볼루션을 계산하여 로컬 feature을 추출할 수 있습니다. 이는 Figure2.(d)와 같은 그리드 형태 뿐만 아니라 Figure2. (b), (c)와 같은 다양한 포인트 클라우드 샘플에 대해서 작동할 수 있습니다.
추출한 feature을 합칠 수 있도록 여러개의 feauture encoding 모듈로 이루어진 계층적인 구조를 사용하였는데, 이는 PointNet++과 유사한 구조로 이루어져 있따고 합니다. 각 모듈은 CNN에서 대략적으로 하나의 layer에 해당하며 각 feature encoding 모듈의 핵심적인 layer는 샘플링 layer, 그룹화 layer, 그리고 PointConv 입니다. 즉 각 로컬 영역에 대한 계층적인 feature encoding module을 통과한 후에 모든 포인트 집합에 대해서 합칠 수 있게 되는 것이죠.
2.2. Feature Propagation Using Deconvolution
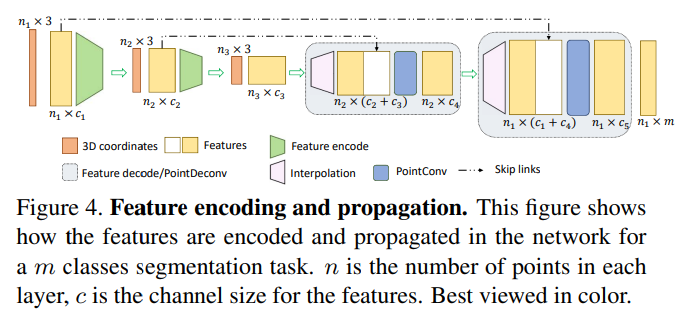
앞서 introduction에서도 이야기하였 듯 segmentation task에서는 포인트 단위의 예측이 필요한데, 모든 입력 포인트에 대한 feature을 얻으려면 샘플링된 포인트 클라우드에서 더 density가 높은 포인트 클라우드로 feature을 propagation할 수 있어야 합니다. PointNet++은 포인트 간의 distance를 기반으로 interpolation하여 feature을 propagation하는 방식을 제안하는데, 이는 로컬 영역 내에서의 correlation을 생각해보았을 때 합리적인 방식이긴 하나 deconvolution의 역할이 존재하지 않아 coarse한 수준에서 propagation된 정보의 로컬한 corrleation을 충분히 활용하지 못한다는 한계점이 존재합니다. 이를 해결하기 위해 본 논문에서 PointConv를 기반으로 한 PointDeconv layer을 추가적으로 제안하게 된 것이죠.
Figure4에서 볼 수 있듯이 PointDeconv는 interpolation과 PointConv, 이렇게 두 부분으로 구성되어 있습니다. 가장 먼저 interpolation을 사용하여 이전 레이어로부터 coarse한 feature을 propagation합니다. 가장 가까운 3개의 포인트로부터 feature을 선형적으로 interpolation하는 방식으로 진행되었으며 이렇게 interpolation된 feature을 skip connection을 사용하여 동일한 해상도를 가진 컨볼루션 레이어의 feature와 합쳐지게 됩니다. 두 feautre을 합치고 나면 2D 이미지 deconvolution과 유사하게 출력을 얻기 위해서 feature에 PointConv를 적용합니다. 이러한 과정을 모든 입력 포인트의 feature가 원래 해상도로 다시 propagation까지 반복하여 진행하게 됩니다.
3. Experiments
PointConv 네트워크의 성능을 검증하기 위해서 ModelNet40, ShapeNet, ScanNet 데이터셋을 사용하였으며 추가적으로 완전히 보편적인 컨볼루션으로 근사화되고 있음을 증명하기 위해 CIFAR-10 데이터셋에서까지 추가적으로 실험을 진행하였습니다.
3.1. Classifictaion on ModelNet40
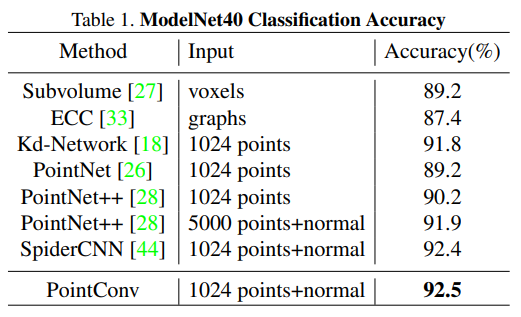
PointNet, PointNet++과 동일한 비교를 위해 동일한 data augmentation 기법을 사용하여 포인트 클라우드를 z축을 따라 랜덤 rotation을 적용하고, 가우시안 노이즈로 jittering을 적용하였습니다. Table1인 ModelNet40에서의 실험 결과로, PointConv는 3차원 입력에 기반한 방법론들 중 SOTA를 달성하였습니다. 비교 모델 중 가장 PointConv와 유사한 접근 방식을 가진 ECC가 PointConv에 비해 성능이 낮은 이유는 large scale의 네트워크로 확장할 수 없어 성능이 제한적이었기 때문이라고 합니다.
3.2. ShapeNet Part Segmentation
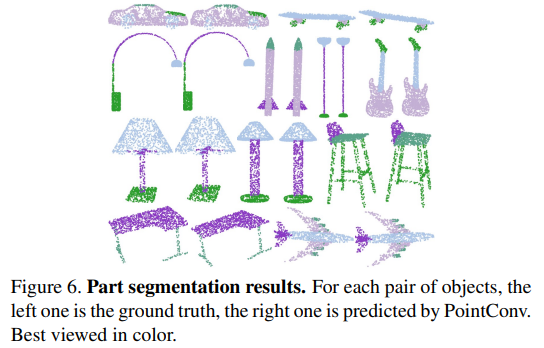
다음은 ShapeNet에서의 Part segmentation 실험을 진행하였는데, part segmentation은 3차원 인지 task 중에서도 어려운 task에 속한다고 합니다. 본 task의 입력으로는 포인트 클라우드로 표현된 object의 shape으로 목적은 포인트 클라우드의 각 포인트에 카테고리 라벨을 할당하는 것 입니다. 한 object에 대한 클래스 라벨은 주어지기에, 원래 일반적으로 가능한 part 라벨을 주어진 입력의 클래스 라벨에 맞게 좁히는 것이 일반적이며 주어진 shape을 더 잘 표현하기 위해 각 포인트의 normal vector의 방향을 입력 feature로 계산한다고 합니다. Figure6이 ShapeNet의 일부를 시각화한 결과로 하나의 object에 대한 shape 내에서 각각의 포인트에 대한 라벨이 할당된 것을 다른 색깔로 표현하였습니다.
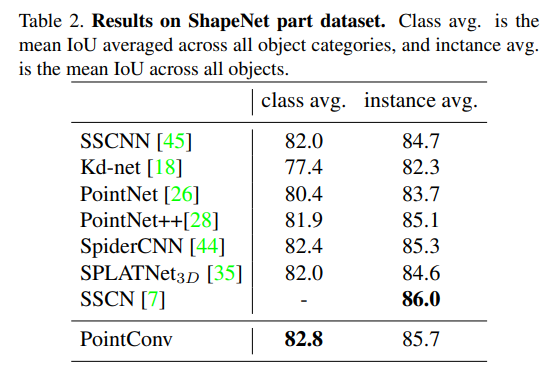
Table2는 PointNet++과 일부 part segmentation 알고리즘과 마찬가지로 포인트 IoU를 사용하여 PointConv 네트워크의 성능을 평가한 결과로 PointConv는 SOTA 방법론과 거의 동등한 수준의 성능을 달성한 것을 확인할 수 있습니다.
PointConv는 3D 포인트 클라우드만 입력으로 사용하기 때문에 공정한 비교를 위해 [35]의 SPLATNet3D와 결과만 비교합니다.
3.3. Classification on CIFAR-10
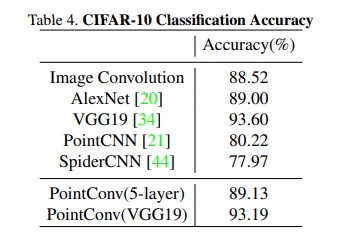
본 논문에서는 PointConv가 2D CNN가 동등한 역할을 할 수 있다고 주장합니다. 실제로 그렇다면 PointConv 기반의 네트워크가 이미지 CNN의 성능과 유사해야 한다고 저자는 생각했고, 이를 증명하기 위해 CIFAR-10 데이터셋을 이용하여 실험을 진행하였습니다. CIFAR-10 이미지의 각 픽셀을 xy 좌표와 RGB feature을 가진 2D 포인트로 정의하였다고 합니다. Table4로 실험 결과를 확인해보면, 이미지 CNN과 PointConv는 실제로 동등한 수준의 성능을 달성한 것을 확인할 수 있습니다. PointCNN은 이미지 CNN에 비해 월등히 정확도가 낮지만, 5개의 encoding layer을 사용하는 PointConv 네트워크의 경우 이미지 컨볼루션을 사용한 네트워크와 유사한 89.13%의 정확도를 보입니다. 또한 VGG19 구조의 PointConv는 VGG19와 비교하여 거의 차이가 나지 않는 정확도를 보이고 있네요. 이를 통해 PointConv가 포인트 클라우드를 입력으로 하면서 CNN과 동등한 역할을 수행할 수 있음을 증명할 수 있습니다.
4. Ablation Study
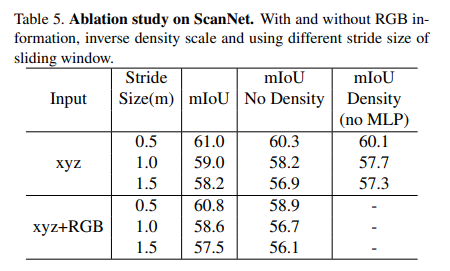
ablation study에서는 inverse density scale S의 효과에 대해서 ScanNet 데이터셋을 통해 실험을 진행하였습니다. inverse density scale은 adaptive하게 적용될 수 있도록 구현되었기에 inverse density scale이 포함된 네트워크와 그렇지 않은 네트워크를 각각 학습하였다고 합니다. Table5에서 확인할 수 있듯이 포함된 네트워크(mIOU)가 포함되지 않은 네트워크(mIOU No Density) 대비 약 1% 더 높은 성능을 보이며 inverse density scale이 효과가 있음을 증명할 수 있었습니다. 추가적으로 더 깊은 레이어에서 MLP가 density scale의 효과를 감소시키는 경향이 있음을 확인하였다고 합니다. 이러한 경향성이 나타나는 이유를 생각해봤을 때, 샘플링 알고리즘으로 FPS 알고리즘을 사용하게 되면 더 깊은 층의 포인트 클라우드가 더 균일하게 분포되는 경향이 영향을 주었지 않았을까 생각이 듭니다. 또한 nonlinear transform을 사용하지 않고 density를 직접 적용하게 되면 density를 사용하지 않는 경우와 비교하여 더 좋지 않은 성능을 보이는데, 이는 nonlinear transform이 데이터셋의 inverse density scale을 학습할 수 있음을 보여줍니다.
안녕하세요, 손건화 연구원님, 좋은 리뷰 감사합니다.
결국 기존에는 연속적인 pointcloud를 CNN에 제대로 넣지 못하는게 한계였는데, MLP로 이를 근사시켜 convolutional 연산으로 풀어낸 것으로 이해했습니다. 제가 3D 및 segmentation에 익숙지 않다보니, 리뷰 읽으면서 몇가지 궁금한 점이 있었습니다.
1. coarse layer와 finer layer가 무엇인가요? figure를 보니 3D segmentation은 정보를 압축하는 encoding 및 다시 원래 크기로 되돌리는 deconvolution으로 구성되는것 같은데, encoding쪽 부분을 지칭하는 것이라 이해하면 될까요?
2. 논문이 permutation invariant 및 density scale의 고려에 대한 부분이 나오던데, 각각이 무엇을 뜻하는 것인지 궁금합니다.
감사합니다.
안녕하세요. 리뷰 잘 읽었습니다.
PointCloud에 대해 CNN의 컨볼루션 연산을 적용하는 방향이 당연해보였는데, 해당 방법이 좋은 contribution이란 점에서 놀랐습니다.
첫 번째로, Point Cloud에 픽셀과 같은 색상 등의 기준 정보가 없다면, 컨볼루션 연산이 어떻게 구별 가능한 Feature를 추출할 수 있나요? 어떠한 Inductive Bias로부터 얻는지 궁금합니다.
글을 쭉 읽다보니 제가 이해를 못했는지 또는 나오지 않았는지 궁금한데, 글에서 말씀해주신 ” 저자는 컨볼루션 연산은 연속적인 컨볼루션 연산을 이산적인 근사치로 볼 수 있고 3차원 공간에서 이러한 컨볼루션 연산의 가중치는 기준이 되는 3차원 포인트에 대해 로컬한 3차원 포인트의 연속 함수로 취급할 수 있으며 연속 함수는MLP로 근사화할 수 있다고 주장합니다.”는 내용이 도저히 이해되지 않습니다. 예시를 들어 조금 풀어 설명해주실 수 있을까요?
마지막으로 Inverse diversity에 관한 내용 중, Point 들이 가까워 영향력이 작아야한다는 점이 이해하기 어렵네요. 이미지와 같이 모든 지점에서 Convolution 연산이 되지 않는다면 포인트들이 뭉친 지점이 더 중요하게 여겨져야 하지 않나요?
리뷰 잘 읽었습니다!
안녕하세요. 건화님! 좋은 리뷰 감사합니다.
리뷰를 읽던 중 궁금한 점에 대해서 질문드리겠습니다.
Figure 3.의 (b)에서 P_{local} 정보들을 MLP1을 태워서 나온 결과인 W의 차원이 K x (C_{in} x C_{out})이라고 되어있는데, 어떤 방식으로 column차원의 정보가 3->(C_{in} x C_{out})으로 늘어나는 것인지 궁금합니다.
또한 같은 그림에서 Compute inverse Density Scale과정을 거치는 부분에서, Density vector(K x 1)가 MLP2를 통과한 결과로 나온 S 벡터(K x 1)를 tile하는 과정을 가쳐서 column차원의 확장하는 데, tile과정이 무엇인지 궁금합니다.
감사합니다!