

이미지 사이의 H-matrix를 구하는 방법론 중 Unsupervised 방법을 제안한 논문입니다. 해당 논문에서 제안하는 아키텍처는 생각보다 엄청나게 간단합니다.
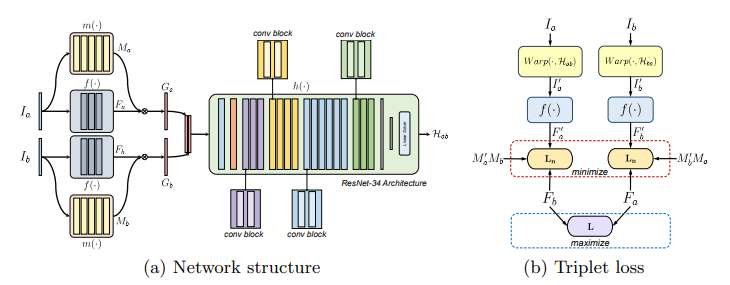
아키텍처는 Feature를 추출하는 Feature extractor, RANSAC과 같은 역할을 수행하며 inlier probability map을 예측하는 Mask predictor, 그리고 마지막으로 이렇게 구한 feature를 이용하여 최종적으로 Homography를 예측하는 Homography estimator 총 3개로 구성되며 각각에 디테일은 아래와 같으며 굉장히 심플합니다.

Feature Extractor

먼저 본 논문에서는 딥러닝을 이용하여 H-matrix를 계산하기 때문에 이미지에서 feature map을 추출합니다. 그리고 이러한 feature map은 기존에 제안된 pixel level에서 intensity를 계산하는 방법보다 더욱 강인한 특징을 갖는다고 합니다. (위에 그림에서 비교하고 있습니다.) 본 논문에서는 VGG, ResNet, ShuffleNet등으로 비교실험을 했는데, 최종적으로 ResNet-34를 사용했다고 합니다.
Mask predictor
실제 이미지 스티칭을 해보면 RANSAC은 필수적입니다. 그 이유는 실제 피처들의 매칭 관계를 통해서 inlier만 추출해야 정확한 H-matrix를 구할 수 있기 때문입니다. 본 논문에서도 이러한 아이디어에서 출발하여 Mask predictor를 제안합니다. (근데 방법은 그냥 inlier predictor를 예측하는 sub network를 설계하는것입니다.) 그리고 이러한 Mask predictor를 이용하여 feature 맵과 mask를 곱해서 Homography estimation의 입력으로 사용하게 됩니다. (아래 수식과 같이 F와 M을 곱하여 G를 만듬)
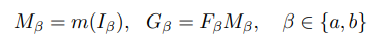
Homography estimator
위에서 구한 Mask와 Feature를 곱하여 Masked Feature map(G)를 만들었따면 이를 이용하여 H-matrix를 예측합니다. 이때 두 이미지 모두에서 G가 나오므로 그 둘을 concat하여 Homography estimator에 입력합니다.
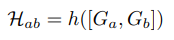
Training – Triplet Loss
이제 모델을 학습해야하는데, 모델 학습에는 Triplet Loss를 사용합니다.
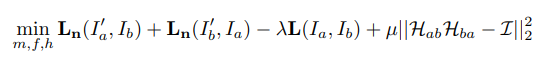
제가 지난주에 작성한 리뷰를 참고하시면 되는데, 일단 앞에서 마지막 H가 포함된 부분은 H-matrix의 역함수 관계가 I라는 것을 이용하여 설계한 loss입니다. 다음으로 앞에 있는 Loss term을 살펴보면 다음과 같습니다.
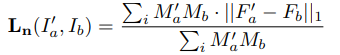
먼저 앞에 두 텀은 실제 Feature level에서 Loss를 계산하는 텀이며, M은 Mask 이며 ‘는 예측된 H-matrix를 이용하여 Warping 한 결과입니다.
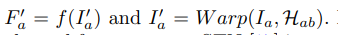
즉, H를 통해서 Warping한 Feature의 차이를 계산하는데, 이때 계산되는 Feature간의 차이는 Mask를 이용하여 두 영역 모두 활성화된 즉 inliner 들만 계산하게 됩니다. 그리고 여기서 이제 warping하지 않은 두 이미지의 차이도 계산하면서 triplet loss와 같은 효과를 나타냅니다.
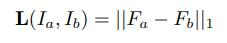
(추가로 위에 수식은 Lossterm에서 한번만 작성됐는데, 앞에 L_n은 두개이므로 람다를 2로 설정합니다. )
Experiments
본 논문에서는 자신들의 방법론을 테스트하기 위해서 데이터셋을 제작하는데, 데이터셋은 연속으로 촬영된 비디오에서 추출된 이미지들이며, 여러 상황에 강인함을 담기위해 다양한 신을 포함하고 있습니다. 또한 평가를 위해서 수동으로 6~8개의 매칭 포인트를 추가했다고 합니다. (이전에 식물 평가하는 방법론에서도 해당 방법을 이용하였습니다.)

RE는 Regular, LR는 low-texture, LL은 low-light, SF는 small-foregrounds, LF는 large-forgrounds를 이야기하며, 이미지는 총 16000장의 페어가 있다고 합니다.

정성적 결과이며 정략적인 결과는 아래와 같습니다. 해당 정량적 결과는 앞서 설명드린것처럼 수동으로 잡은 이미지의 6개 정답이 있기 때문에 이를 이용하여 오차를 계산하였다고 합니다. (수동포인트간의 오차거리 계산)
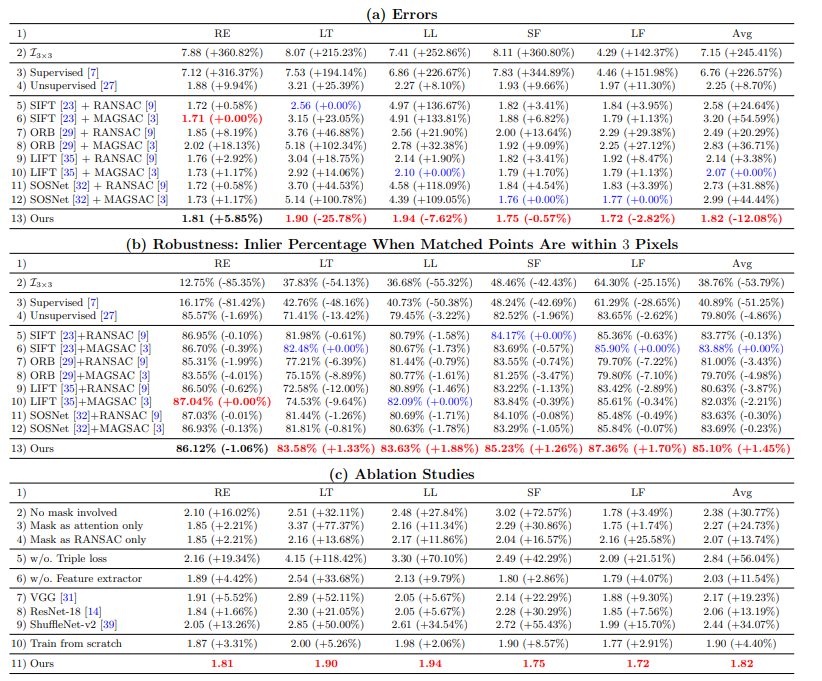
자신들의 방법이 전통적인 방법론보다 좋았음을 나타내고 있습니다. (중간에 퍼센트는 Inliner의 비율입니다.) 또한 해당 논문에서는 다양한 Ablation study도 자세하게 포함하고 있어 Oral paper로 선정된게 아닌가 생각합니다.
이러한 방법으로 멀티스펙트럴 영상의 Registration을 수행하는 것을 시도하는 중이며, 좋은 결과가 나오길 기대하고 있습니다. 해당 방법론에서 사용하는 그리고 논문이 작성된 방식들을 참고하면 좋은 논문을 작성하는데 많은 도움이 될 것 같습니다. 마지막으로 해당 방법론의 한계는 아직까지 학습이 잘 안될 수 있다는 단점이 있어 이 부분은 해결해야할 부분으로 남는 것 같습니다.
평가에서 임의로 찍은 포인트가 제가 보기에는 너무 적어보이는데 실제로 몇개의 포이트를 정량적으로 사용했다는 언급이 있나요?
위에서 언급하긴했는데 6-8개의 포인트를 수동으로 찍고, 이를 평가에 이용했다고 합니다.