- Image Retrieval 이란
Image Retrieval을 정말 간단히 말하자면, 이름 그대로 영상 검색이라 할 수 있습니다. 자세히 이야기 하자면 기 구축된 영상 집단( DataBase:DB) 에서 사용자가 원하는 영상 (Query:QR)과 가장 유사한 영상(들)을 찾는 작업을 의미합니다.
이러한 DB에서 QR와 유사한 영상을 찾는 작업에서 영상을 그대로 사용하게 된다면 여러 문제 점이 있습니다. 첫번쨰는 많은 연산량으로 인해 굉장히 느린 속도를 보여 원하는 서비스를 할 수 없다는 것 이고 , 두번 째는 단순히 영상의 픽셀 값만으로 비교하는 것은 새로운 환경에서 촬영된 영상들에 대해 맞지 않은 결과 찾게 된다다는 것입니다.. 위 문제점들을 막기 위해서 영상을 표현할 수 있는 하나의 Vector로 영상을 대체하여 Retrieval을 합니다. 이 하나의 Vector를 Global Descriptor라 정의하여 사용합니다.
Global Descriptor를 영상을 표현하는 하나의 Vector로써, 이 Global Descriptor를 영상으로부터 변환해서 만들어내는 방식이 지금부터 제가 설명할 방법론들의 중심 포인트가 될 것 입니다.
2. DNN(Deep Neural Network)이전 방법론
DNN이전에 Global Descriptor를 표현하는 방식으로는 크게 BoVW와 VLAD가 았습니다. 각각 방법론들은 영상의 local descriptor의 k-means cluster를 기반으로 영상을 표현합니다. 좀 더 자세히 각 방법론을 아래에서 하겠습니다. 각 방법론의 큼직큼직한 흐름을 전달하고 정확한 이론은 가볍게 넘어갈 것 입니다.
2.1 K-means clustering
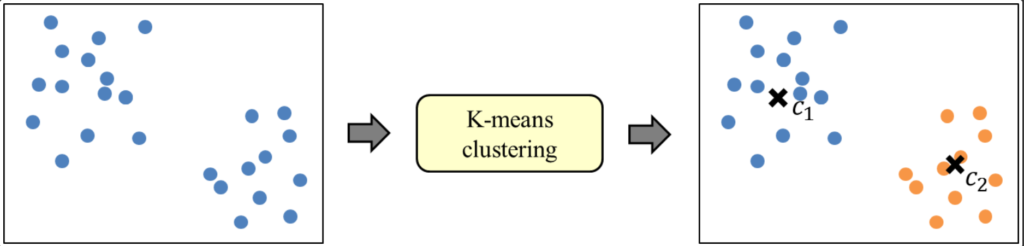
각 방법론은 k-means cluster를 기반으로 동작하기 때문에 공통적을 설명하도록 하겠습니다. k-means cluster은 그림 1 처럼 데이터를 소수의 그룹으로 묶는 알고리즘입니다. 그림 1 속 c1,c2를 Cluster center라 하는데, 이 center를 군집과 거리가 최소가 되도록 최적화 하는 알고리즘을 k-means알고리즘의 토대가 됩니다. center를 어떠한 방식으로 찾아가는 냐에 따라서 여러 방법론이 있지만 그건 넘어가도록하겠습니다.
데이터의 중심을 찾는 k-means cluster은 BoVW와 VLAD에서 Database 영상들을 표현하기 위한 수단으로 사용한다.
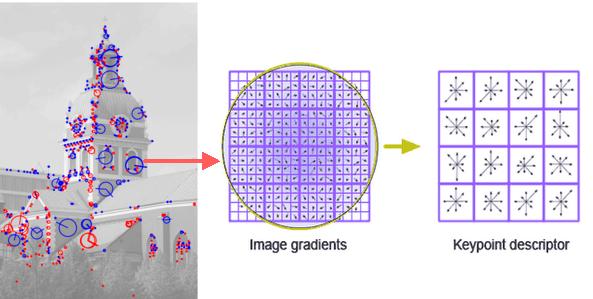
Database 속 모든 영상들의 그림 2와 같은 Local descriptor를 추출한 후, 모든 local descriptors의 cluster center를 알아내면 k-means의 역할은 끝이 난다. 이과정을 통해 Database 영상들의 특징을 1차적으로 알아내는 것을 완료했다.
2.2 BoVW 와 VLAD
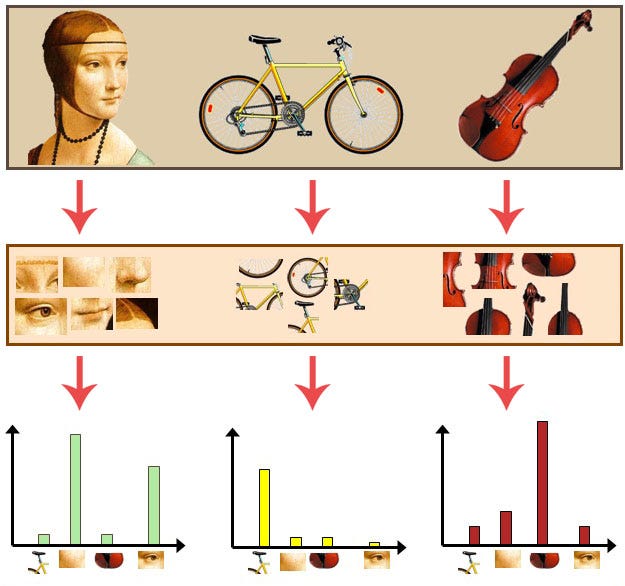
k-means cluster center를 알아낸 후 BoVW 와 VLAD가 어떻게 영상의 Global descriprtor를 표현하는지 설명하도록하겠다.
먼저 BoVW을 간단히 이해하자면 그림 3과 같이 특징들로 histogram을 만들어 그것을 Global descriptor로 만드는 것이다. 위 설명에서 특징은 k-means cluster center가 된다 . 따라서 모든 영상의 local descirptor를 k-means clusters로 histogram을 만들면 그것이 Global descriptor가 된다.
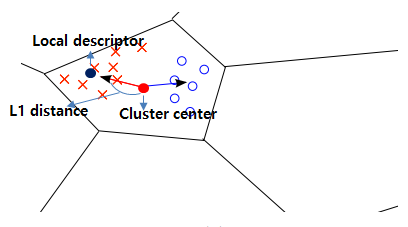
VLAD는 k-means cluster와 local descritor 간의 거리를 이용한다. local destriptor를 추출했을떄 N개의 point가 나왔다하면 , 모든 N개 에 대해 각각 가장 가까운 K-means cluster center와 L1 distance를 측정하고 concat한 후 L2 Normalize 하면 VLAD 방식의 Global Descriptor를 만들 수 있다.
Global Descriptor는 이미지에서 location에 대한 정보는 담고있지 않나요? 아니면 해당 정보도 담고있는 Global Descriptor가 존재하나요??? 좀 더 풀어서 질문하면 예를들면 좌우반전이나 상하반전을 하여도 구성이 같으면 같게 기술되나요??? (SIFT의 경우 회전에 강인해서 같을수도 있겠다는 생각이 들기도 하는데 다른 것들은 어떤지 궁금합니다)
말씀해주신 것처럼 Global Descriptor를 기술하는 Local Descriptor 에 따라서 달라질 것 같습니다
김지원 연구원님과 유사한 질문 내용입니다. 카메라의 위치가 물체의 정면과 뒤쪽에서 촬영한 영상(충분한 matching local point가 있다고 가정을 하고)을 global descriptor로 찾거나 구분이 가능할까요?
그건 데이터셋이 어떻게 구성 되어 있는지에 따라 달라질 것 같습니다
튜토리얼 (1) 이라고 하셨는데, 후속도 있나요?
아마 있지않을까 …합니다