이번에 소개드릴 논문은 CVPR2018에서 발표된 An Analysis of Scale Invariance in Object Detection 이라는 논문입니다.
해당 논문에서는 Object Detection에 있어서 성능을 감소시키는 scale imbalance 문제에 대해 다루고자 합니다.
Introduction
Compute vision 분야들 중 Classification task는 AlexNet을 기점으로 성능이
매우 빠르게 향상되었습니다. ImageNet Classification에서 error가 15%에서 2%대로 확 떨어짐으로써, 분류에 대해서는 사람보다 더 정확할 정도가 되버린 것이죠.
하지만 Computer vision에 또 다른 task인 object detection 분야는 위에서 말한 classification 분야와는 다르게 성능에 대한 발전속도가 매우 느린편입니다. 그렇다면 어떤 이유로 인하여 object detection이 image classification만큼 발전하지 못하는 것일까요?
Relation between object scale and accuracy
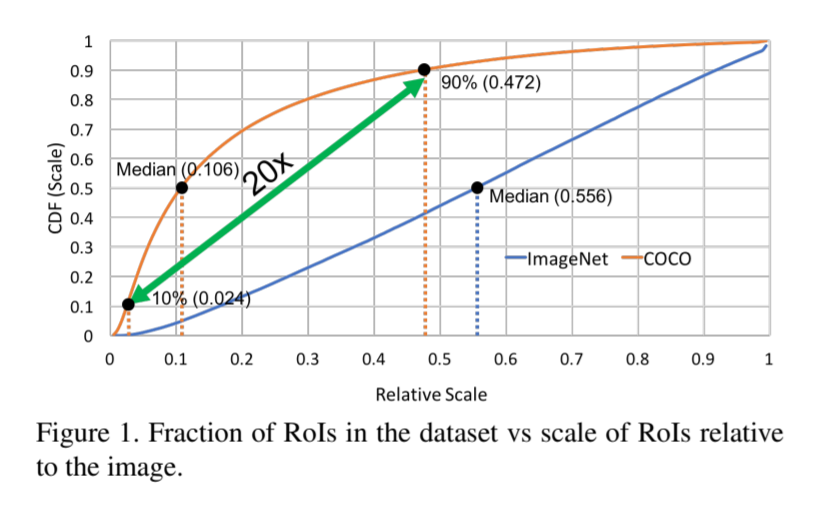
위에 그래프는 Classification에서 많이 사용하는 dataset인 ImageNet과 Detection에서 많이 사용하는 COCO dataset의 특징을 분석한 표입니다.
표의 x축은 Relative Scale로 Relative Scale은 (영상 속 물체의 크기 / 영상 전체의 해상도)를 통하여 나타낼 수 있습니다. 즉 1에 가까울수록 영상 속 물체가 크다는 의미이고, 0에 가까울수록 작은 물체라는 뜻입니다.
표를 분석해보면 ImageNet(남색)의 경우 scale 변화량(variation)이 선형적인 반면에 COCO는 매우 급격한 것을 볼 수 있습니다. 또한 COCO 데이터셋에서 제공되는 object의 전반적인 scale이 small object인 것을 확인하실 수 있습니다.(Median값이 0.106) 마지막으로 ImageNet과 COCO dataset이 scale에 대하여 domain-shift가 크다는 점입니다.
마지막 요인이 Detection 성능과 무슨 관계가 있느냐면, 대부분의 Object Detection 모델들은 pre-trained 모델을 가져올 때 주로 ImageNet 학습된 backborn을 사용하게 되는데, 해당 ImageNet과 COCO 데이터셋의 scale 경향성이 크게 차이가 있기에, 성능에 문제가 생길 수 있다는 점입니다.
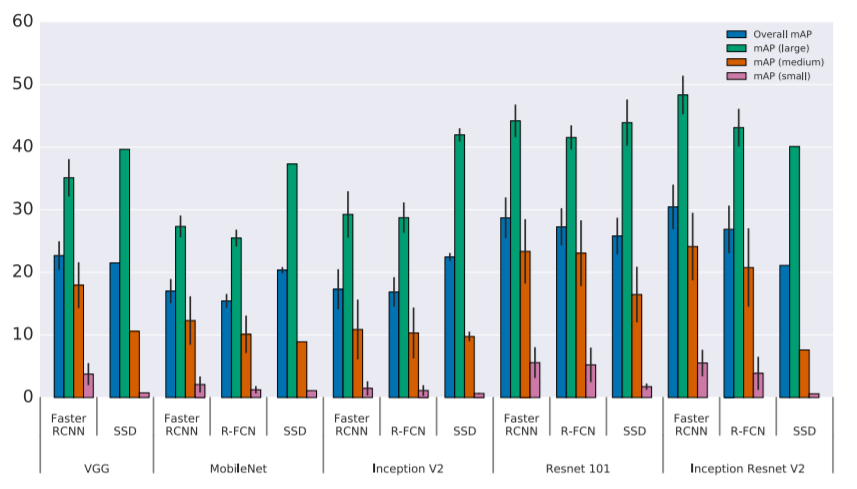
위에 표는 유명한 Object detection 모델들에 대해서 다양한 backborn을 가지고 Detection 성능을 비교한 지표입니다. 해당 지표를 보시면 아시다시피, 서로 다른 backborn을 통해 학습시켰음에도 불구하고, small object에 대해서 매우 낮은 map를 가지는 것을 확인할 수 있습니다.
이렇게 CNN기반 모델들이 small object에 대해서 성능이 낮은 이유는, CNN 과정 중에 stride나 pooling으로 인하여 영상의 해상도가 줄어들게 되는데, 이로인하여 small object를 표현하는 high level feature들이 잘 표현되지 않기 때문입니다.
이러한 문제들을 해결하기 위해서 다양한 방법론들이 예전부터 제안되어 왔습니다. 예를들면 input과 가까이 있는 layer(ex Conv3)들은 해상도 역시 input과 유사하기에, 이러한 shallow layer들을 기존의 deep layer(ex Conv5)와 combine하는 방식과, 각 layer별로 feature map을 가져와 prediction을 하는 방법이 존재합니다.
하지만 이러한 방법들도 문제점이 존재하여 크게 성능향상을 시키지는 못했습니다. 예를 들어 위에 shallow layer에 경우에는 결국에 input에 가까운 feature map을 사용하는 것이므로, object를 잘 표현하는 high level feature를 추출하기에 어려움이 존재하기 때문입니다.
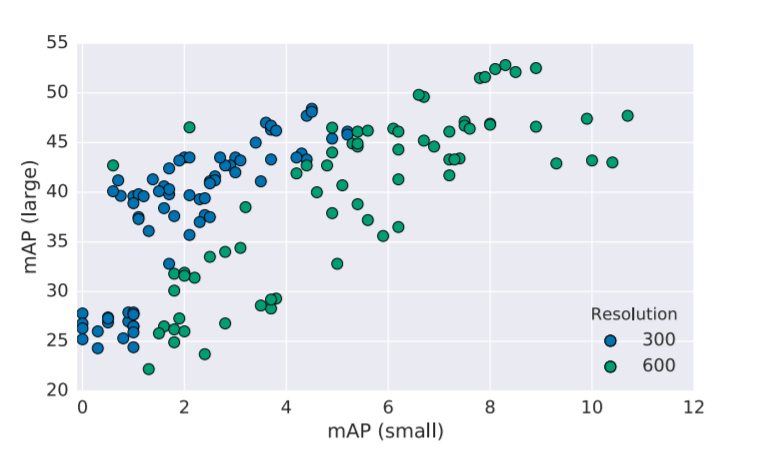
그래서 가장 일반적으로 Detection의 성능을 올리기 위해서는, input 영상의 해상도를 높여서 small object의 크기도 상대적으로 크게 만드는 것입니다.
위에 지표에서도 볼 수 있듯이, 영상의 해상도가 300보다는 600일 때 large obejct과 small object에 대한 map 성능이 일반적으로 향상되는 것을 확인할 수 있습니다. (좌측 상단에 input resolution이 600임에도 map(small)가 작은 detector는 SSD입니다.)
Image Classification at Multiple Scale
그렇다면 단순히 test 영상을 up-sampling 하면 성능이 향상될까요? 해당 논문에서는 CNN 기반 모델들이 up-sampling에 대하여 robust한지를 실험합니다.
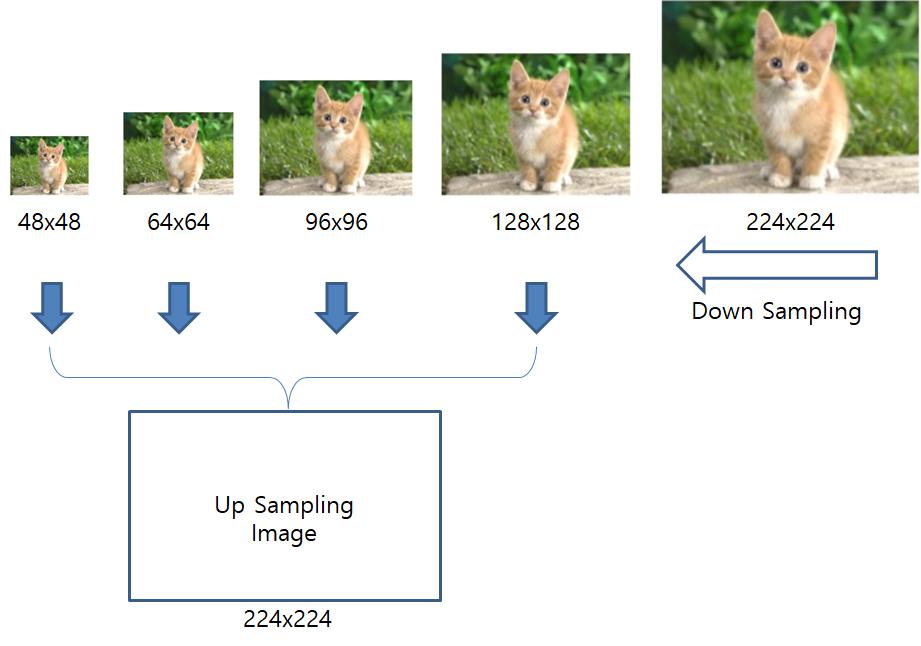
먼저 ImageNet database 영상을 각각 48, 64, 96, 128로 down sampling 합니다. 그 후 down sampling된 영상을 다시 원본 영상 크기인 224×224로 up sampling하여 test 영상을 단순히 up sampling하여 모델의 성능을 내어보는 상황을 만들었습니다.
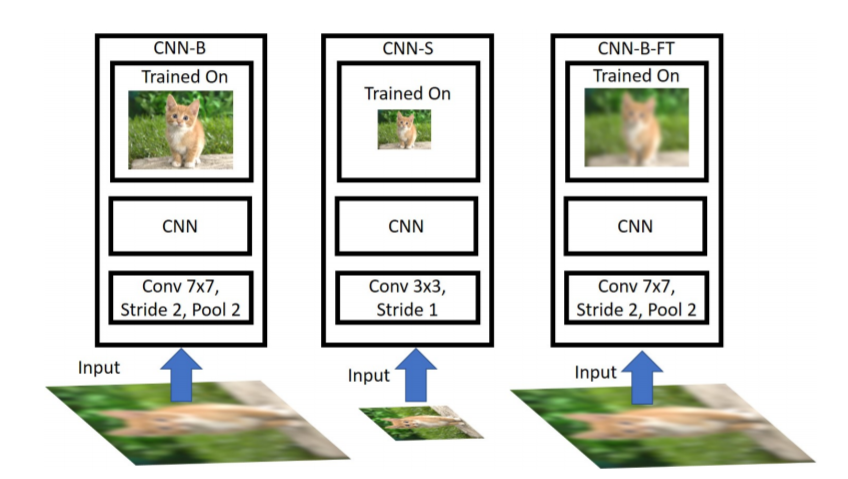
위에 그림에서 CNN-B의 경우가 원본 224×224 영상으로 학습하고, Figure 2에서 만들어놓은 영상(down sampling된 영상을 다시 원본 영상의 크기(224×224)로 up-sampling한 것)으로 학습시킨 모델입니다.
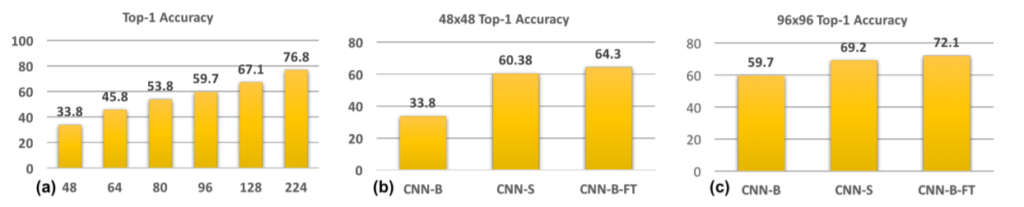
이를 통하여 나온 성능은 Figure 4. (a)에서 확인하실 수 있는데, train에서 사용했던 해상도와 test에서 up-sampling이전의 해상도 차이가 클수록 성능이 많이 차이나는 것을 확인할 수 있습니다. 이를 통해 CNN은 up-sampling에 관하여 robust하지 않다는 것을 확인할 수 있습니다.
그래서 위에 결과를 토대로 논문에서는 또 새로운 실험을 합니다. 바로 low resolution에 대한 성능을 높이기 위해 단순히 train data의 크기도 low resolution으로 학습하는 것입니다. 즉 low resolution 영상으로 학습하고, low resolution 영상으로 test를 하는 것이죠.(Figure 3참조)
그리고 그것에 대한 결과는 Figure 4 (b)와 (c)를 통해서 볼 수 있듯이, up-sampling 했을 때 보다 더 좋은 성능을 보여줍니다.
위의 결과들을 종합적으로 봤을 때, CNN-B의 성능이 낮게 나온 것은, up-sampling 시킨 영상에 대해서는 학습 때 한번도 보지 못하였기 때문이라고 판단하여, train 시에 up-sampling시킨 영상도 같이 학습한 fine-tune한 CNN-B를 실험하였습니다. 그리고 이를 통한 결과를 보면 CNN-B-FT가 CNN-S보다 더 좋은 것을 확인하실 수 있습니다.
이를 통하여 해당 논문은 small object 검출에 좀 더 목적을 둔 새로운 네트워크를 사용하는 것 보다는, 영상을 up sampling하여 high resolution image로 pre-trained 된 네트워크를 사용하는 것이 성능면에서 더 우수하다고 말합니다.
Data Variation or Correct Scale
우리는 CNN이 scale에 따라서 성능의 차이가 발생하는 것을 확인할 수 있었습니다. 그래서 이러한 scale variation을 줄이고자, 작은 scale instance와 large scale instance를 나누어서 학습할 수도 있는데, 이러한 방법은 scale variation은 줄일 수 있을지 몰라도, Data Variation(데이터의 다양성이라고 보시면 될 것 같습니다.) 역시 줄어들게 되어, 성능이 낮아질 수 있습니다. 이러한 Data Variation과 Scale Variation에 대한 trade off 관계를 명확히 확인하고자 해당 논문에서 실험을 하였습니다.


먼저 800×1400 해상도 영상으로 학습한 detector( 800_{all} )와 1400×2000 해상도 영상으로 학습한 detector( 1400_{all})에 대한 성능은 당연하게도 더 큰 해상도를 가진 1400_{all} 이 상대적으로 더 좋은 성능을 보여주고 있습니다(Table 1).
하지만 엄청 극적인 성능 향상을 보여주지는 못하였는데, 그 이유로는 medium-to-large scale의 물체들이 너무 커지다보니깐 small object는 잘 찾지만, 그 이상의 크기는 잘 찾지 못하는 문제가 발생한 것입니다.
그래서 이러한 문제를 해결하고자, 두번째 실험으로는 1400_{all} 에서 80픽셀 이상의 크기를 가진 object들은 제외하고 학습하였습니다,Figure 5.2. 해당 방식에 대한 성능은 Table 1에 1400_{<80px}로 나타나 있는데, 성능이 오히려 800_{all}보다 더 떨어진 것을 볼 수 있습니다.
그 이유로는 scale만을 고려하여 80픽셀 이상의 object들은 다 제외시켜버리는 바람에, (Data variation이 줄어들어서) 오히려 object의 appearance 또는 pose 등 특징에 대한 학습이 이루어지지 않았다고 예측합니다.
그래서 마지막으로 다양한 해상도를 통해 영상을 랜덤하게 샘플링하여 학습하는 Multi Scale Training(MST) 기법을 추가해 실험하였습니다, Fig 5.3. 하지만 이 역시 small object과 large object에 대하여 검출이 잘 되지 않아 1400_{all}보다 성능이 좋게 나오지는 못하였습니다.
이러한 실험을 토대로 해당 논문에서는, 가능한 object들의 variation은 많이 챙겨가면서, 동시에 object에 대한 scale을 적절하게 키워야만이 성능 향상을 할 수 있을 것이라고 판단하였고 이러한 방법론을 적용시킨 SNIP를 제안합니다.
Scale Normalization for Image Pyramids(SNIP)
우리는 Data Variation or Correct Scale 세션에서 object가 너무 크거나 작으면 문제가 생기고, 이를 해결하고자 scale을 맞춰주려고 하면, Data variation이 줄어들어 또 성능이 낮아지는 골치아픈 상황을 보게 되었습니다.
즉 적절한 scale로 맞추어 주면서 동시에 Data variation은 유지하는 방법을 찾아야만 하는데, 이를 위해서 해당 논문에서는 Image pyramid 상에 scale normalization을 하자고 제안합니다.
쉽게 말하자면 Image pyramid에서 가장 작은 크기의 영상 속에는 large object를 뽑아오고, 중간 크기의 영상 속에는 median object를, 가장 작은 크기의 영상 속에는 small obejct만을 가져와 학습하자는 것입니다.(Fig 5.4)
이러한 scale normalization은 모든 데이터를 활용하면서 scale variance는 줄여나갈 수 있게 됩니다.
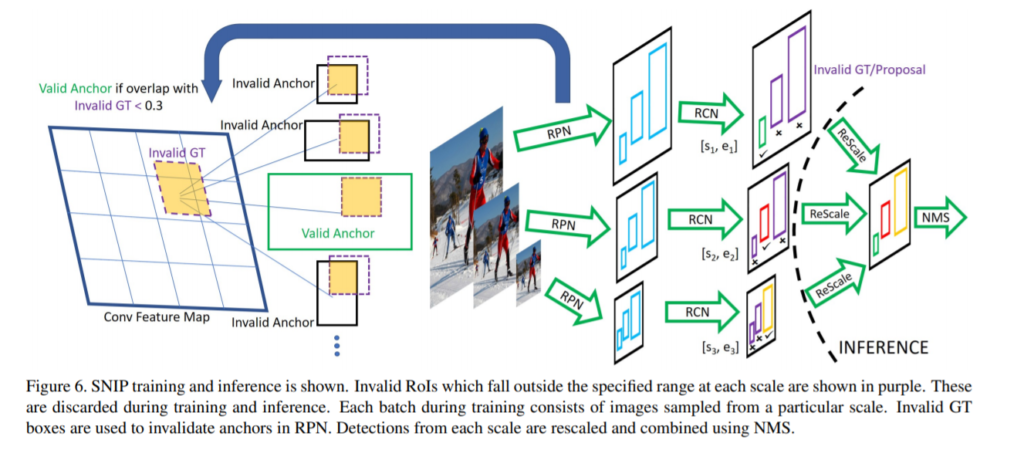
SNIP 학습 방법은 간단합니다. 각각의 서로 다른 해상도를 가진 영상들(1400×2000, 800×1200, 480×800)에 대하여 각각 RPN을 통해 region proposal을 뽑아냅니다. 그렇게 나온 region proposal에 대해서 미리 각각의 해상도에 따라 설정해놓은 특정 range (Figure 6에서 [s_{n}, e_{n}] 부분) 범위를 벗어난 proposal은 제외시킵니다. 그리하여 유효한 proposal만을 가지고 training 단계에서는 back propagtaion도 하고, test할때는 해당 proposal들을 rescale하여 기존 Detection 모델처럼 NMS 과정을 걸치면서 detect를 하게 됩니다.
RPN을 학습하는 과정도 위와 유사하게, 특정 범위를 벗어난 anchor들은 제거하고 유효한 anchor들 만으로 학습하는데, 이때 anchor가 유효한지 제외시켜야하는지는 바로 invalid GT box를 통해 지정됩니다.
invalid GT box란, 아까 말한 특정 range부분을 벗어난 GT box들을 말하는데, RPN에서는 해당 박스들과 anchor들을 비교해서 IoU가 0.3 이하인 애들을 유효한 anchor라고 합니다. 쉽게 생각하면 invalid한 GT box에 대해서 0.3의 overlap을 가지는 negative anchor들은 다른말로 하면 valid한 GT box에 대해서 positive anchor라고 볼 수 있는 것이죠!
결론을 내보자면, Detection에서 총 세가지의 문제점(
1.너무 작은 물체에 대해서 검출 성능이 매우 낮음,
2. COCO dataset에서 scale variation이 매우 큼,
3. pre-trained시킨 Dataset(Image Net)과 실제 평가 Dataset (COCO)이 scale과 관련하여 domain shift가 큼)
이 존재하였고, 이를 해결하고자 Image pyramid 속에서 큰 resolution 영상에서는 작은 물체를, 중간 resolution 영상에서는 중간 크기의 물체를, 작은 resolution 영상에서는 큰 물체를 뽑아서 학습하는 scale normalization 방식을 사용하였습니다. 그리고 이때 scale normalization의 기준을 Image Net으로 맞추었기 때문에, COCO와 Image Net에 따른 domain shift 문제도 해결하였습니다.
마지막으로 여러 detector들에 대한 비교 결과를 보여주고 글을 마무리 짓겠습니다.

질문에 앞서 좋은 발표와 좋은 리뷰 감사합니다. 고생한 것이 확 보이네요ㅋㅋㅋㅋ
데이터 셋에 대해 분석한 내용들은 다른 데이터 셋들에서도 고려를 해봐야하는 부분이라고 생각합니다.
해당 페이퍼에서는 물체 검출의 맟춰서 이야기를 했는데요. 해당 방법론을 만약에 다른 태스크에 적용한다면 어떤 태스크에 가능 할까요?