안녕하세요. 저는 케어 로봇에 대해서 흥미도 많고 이쪽으로도 연구를 해보고 싶다는 마음이 매우매우매우 큰데요. 케어와 관련해서는 벤치마크가 없나? 싶어 찾아보니 데이터셋을 정말 잘 구축한 논문이 있었습니다. 이쪽 분야도 많이 연구가 되고 있는거 같아 본격적으로 팔로업해보고 싶다는 마음이 드네요. 그럼 시작하겠습니다.
1. Introduction
전 세계적으로 신체적 한계를 가지고 계신 분이 얼마나 될까요? 무려 13억이나 됩니다. 이들 중에 많은 사람들이 ADL(Activities of Daily Living), 즉 일상생활 동작을 수행할 때 다른 사람의 도움을 필요로 한다고 합니다. 그런데 자격을 갖춘 간병인과 치료사의 수요는 이용 가능한 전문가 수를 크게 초과하죠. 이 상황에서 assitive robot(보조 로봇)을 보급하면 어떻게 될까요? 간병인과 치료사와 같은 human caregiver(돌봄 제공자)를 완전히 대체하기 보다는, 반복적이고 신체적 부담이 큰 caregiving process를 보조할 가능성을 가집니다.
그런데 robot caregiving은 일반적인 robot manipulation 보다는 훨씬 어려운데요. 예를 들어서, bed bathing task(침대 위에서 목욕 보조하는 task)를 생각해볼까요? 생각보다 고려할 부분이 많은 데요.
- occlusion
- safety constraints
- long-horizon planning under uncertainty
- user의 pysical function, preference에 맞는 개인화
- human feedback에 대한 적응
위와 같이 고려할 점들이 있습니다. physical human-robot interaction을 하기 위해서는 고려해야할 점들인 것이죠.
그리고 기존의 roboot caregiving 연구는 식사, 드레싱, 목욕 보조과 같이 개별 ADDL에서 성과를 보이고 많은 연구가 task-specific dataset이나 simulation에 의존하는 모습을 보이는데요. 제조 분야에서 보이는 일반적인 로봇 학습은 large scale datasets에 사용해서 foundation model을 학습시키는 것과 비해서 대조되는 모습을 보입니다., 즉, caregiving robot이 다양한 real world caregiving 루틴을 배우려면 특정 task 하나에 맞춘 작은 데이터세만으로는 부족합니다. 이것 뿐만이 아닙니다. 기존 caregiving 데이터셋은 modality가 제한적이고, 전문 human caregier나 치료사로부터 수집한 시범 자료가 부족합니다.
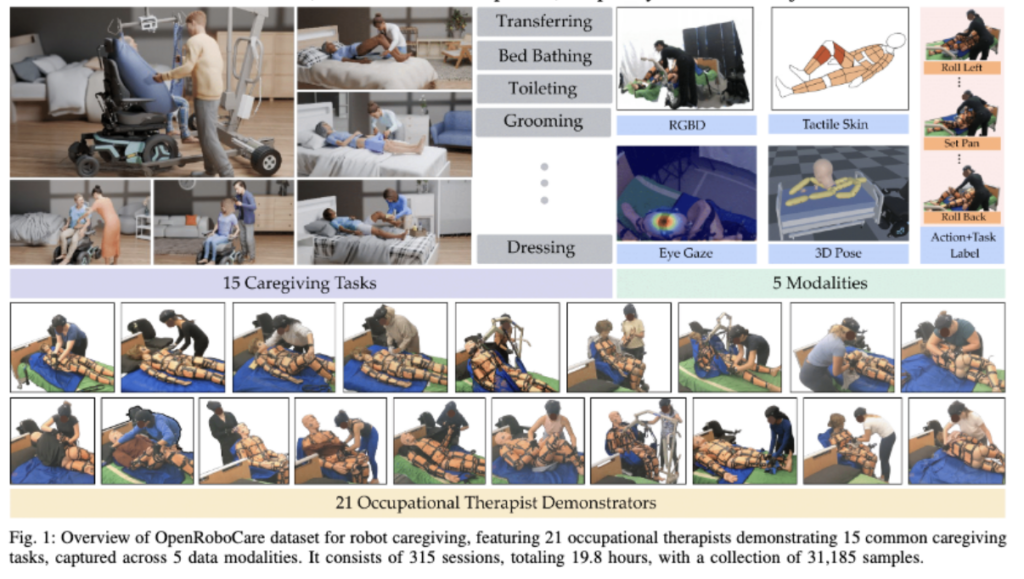
그래서 본 논문의 저자는 OpenRoboCare 데이터셋을 제안하였는데요 . Fig 1을 통해 데이터셋 수집과정과 구성을 확인할 수 있습니다. OpenRoboCare는 multimodal, multi-task로 구성된 전문가가 수집한 데이터셋입니다. 대략적으로 구성을 말씀드리면, 21명의 치료사가 두 종류의 마네킹을 대상으로 15개의 ADL task를 수행한 시범 자료로 구성됩니다. 수집 모달리티는 RGB-D video, tactile sensing, pose tracking, eye-gaze tracking, action annotation으로 구성됩니다. 구체적으로 말씀드리면, 맞춤형 전신 piezo-resistive tactile을 사용해서 caregiver와 마네킹 사이의 힘이랑 접속된 것을 기록하고, 모션 캡쳐로 pose 추정, Pupil Labs galsses를 통해서 eye-gaze를 수집합니다. 여기에 추가로 caregiver가 task 중 자신의 action을 자연어로 설명하고 이를 기반으로 action labeling을 수행합니다. “무엇을 했는가” 뿐아니라, 어디를 보았는지, 어디를 만졌는지, 얼마나 힘을 주었는지, 어떤 순서로 수행했는지를 담기 위해서 위와 같이 데이터셋을 수집했다고 보시면 됩니다.
마지막으로 해당 데이터셋을 공개 데이터셋으로 제공하는 것 뿐만 아니라, 전문 간병 원칙과 특정 기법을 분석하여 로봇 설계에 필요한 통할력을 도출하였으며, OpenRoboCare를 로봇 인지와 인간 행동 인식의 벤치마크를 구축하였다는 것이 본 논문의 contribution이라 말할 수 있습니다. 또한 기존 SOTA 방법론의 경우 해당 데이터셋으로 바로 좋은 성능을 내지 못하지만, OpenRoboCare의 일부 라벨링된 데이터로 fine-tuning하면 성능이 크게 향상되는 것을 볼 수 있습니다.
2. Task Selection and Caregiving Protocol
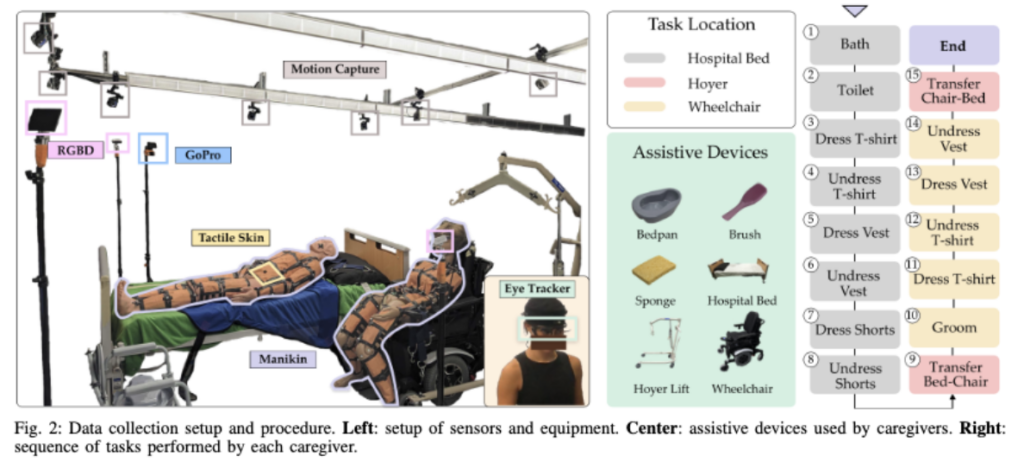
저자는 OT-in-the-loop protocol design(즉, 치료사가 설계 과정에 직접 참영하는 프로토콜)을 사용합니다. 여기서 중요한 점은 연구자가 임의로 돌봄 동작을 만든 것이 아니라, 치료 교육 경험이 있는 전문 치료사와 협업하여 task와 실험 환경을 설계했다는 것입니다. 특히 사지마비 처럼, 상지, 몸통, 하지, 골반 장기 및 골반 주변 기능의 조절 능력이 부족하여 전면적 도움이 필요한 사람을 주요 돌봄 시나리오로 고려합니다.
task 선정은 ADL의 여섯 기본 범주 중 Feeding(식사 보조)를 제외한 다섯 범주를 다룹니다. Feeding은 다른 돌봄 기술을 요구하고 기존 연구에서 이미 많이 다루었기 때문에 제외한다고 하네요. 포함된 task는 Bathing(목욕 보조), Toileting(배변 보조), Dressing(옷 입히기 및 벗기기), Transferring(침대와 휠체어 사이 이송), Grooming(머리 빗기와 같은 몸단장 보조)입니다. 각 task를 침대, 휠체어 환경에서 수행한 것을 또 task로 나눠서 총 15개 task(Bath, Toilet, Dress T-shirt (Bed), Undress T-shirt (Bed), Dress Vest (Bed), Undress Vest (Bed), Dress Shorts (Bed), Undress Shorts (Bed), Transfer (Bed-Wheelchair), Groom, Dress T-shirt (Wheelchair), Undress T-shirt (Wheelchair), Dress Vest (Wheelchair), Undress Vest (Wheelchair), Transfer (Wheelchair-Bed))로 구성됩니다. 그러면 각 task에 대해서 설명해보겠습니다. 각 보조기구가 어떻게 생겼는지, 해당 데이터셋의 마네킹과 침상, 휠체어는 Fig 2에서 확인할 수 있습니다.
Bathing
bathing은 목욕 보조를 의미하는데요. 병원 침대에 누운 마네킹에 스펀지를 이용한 전신 목욕을 수행하는 task입니다. caregiver는 피부를 세게 문지르기보다는 부드럽게 두드리도록 요청받았고, 힘의 크기나 손이 닿기 어려운 신체 부위 청소 등을 씻기기 위한 body repositioning을 보여줍니다.
Toileting
toileting은 배변 보조를 의미하는데, 침상용 변기를 이용해서 task를 수행합니다. caregiver는 마네킹의 엉덩이의 골반 부위를 들어 침상용 변기를 넣고 뻅니다. 해당 task는 골반 부위를 어떻게 안정화하고 무거운 몸음 어떻게 적은 노력으로 들어 올리는지를 보여는 것을 통해 contact-aware planning에 중요합니다.
Dressing
Dressing은 옷 입히고 벗기기를 의미하는데, 가장 많은 변형을 가집니다. 상체와 하체, 의복 종류, 침대 또는 휠체어, 누운 자세 또는 앉은 자세에 따라서 수행 전략이 달라지는데, 옷이 신체 부위를 가리고 팔과 다리를 옷 구멍에 맞추서 통과싴켜야 하기 때문에 occlusion과 fine-grained lim manipulation이 동시에 발생하게 됩니다.
Transferring
transferring은 이송 보조를 의미하는데요. 환자 이송 리프트와 몸을 받쳐 들어 올리는 천 형태의 보조 장치를 이용해서 침대와 휠체어 사이를 이동시키는 task 입니다. sling을 바르게 고정하고, 이송장치를 조작하고, 마네킹의 자세를 가이드하고, 이송 후 안전하게 내려놓는 절차가 필요한데요. 그래서 long-horizon task 중 하나이고, 보조기기들을 순서와 상황에 맞게 함께 다루는 능력이 중요합니다.
Grooming
Grooming은 휠쳉어에 앉은 마네킹의 머리를 빗는 task인데요. 겉보이게는 단순하지만, caregiver가 양손으로 돌보는 것을 고려하고, 자세를 조정하고, 움직임을 안정적으로 제어해야하는 것이 고려되어야 합니다.
마지막으로 21명의 caregiver가 2주 동안 참여했고, 각 참가자는 남자 또는 여자 마네킹 하나에 대해 15개의 task를 한번씩 수행하여 수집하였다고 합니다. 각 세션은 약 1시간이 걸렸고, IRB consent라는 기관생명윤리위원회 동의 절차와 설문을 통해서 motion capture 장값, motion caption 모자, eye-tracking 안경을 착용ㅇ했습니다.
3. Sensing modalities and Synchronization
RGB-D 비디오는 세 대의 카메라로 수집되었는데요. 두 카메라는 병원 침대를 서로 다른 각도에서 보고, 세 번째 카메라는 침대 뒤에서 휘체어를 향하게 방향을 설정하였다고 합니다. 해당 모달리티는 caregiver motion, manikin motion, assistive device interaction, scene geometry를 함께 기록하는데요. 로봇 입장에서는 “어디에 사람이 있고, 어떤 body part가 가려졌으며, 어떤 device와 상호작용 중인지”를 추론하는 데 비디오를 사용할 수 있습니다.
Tacktill Skin
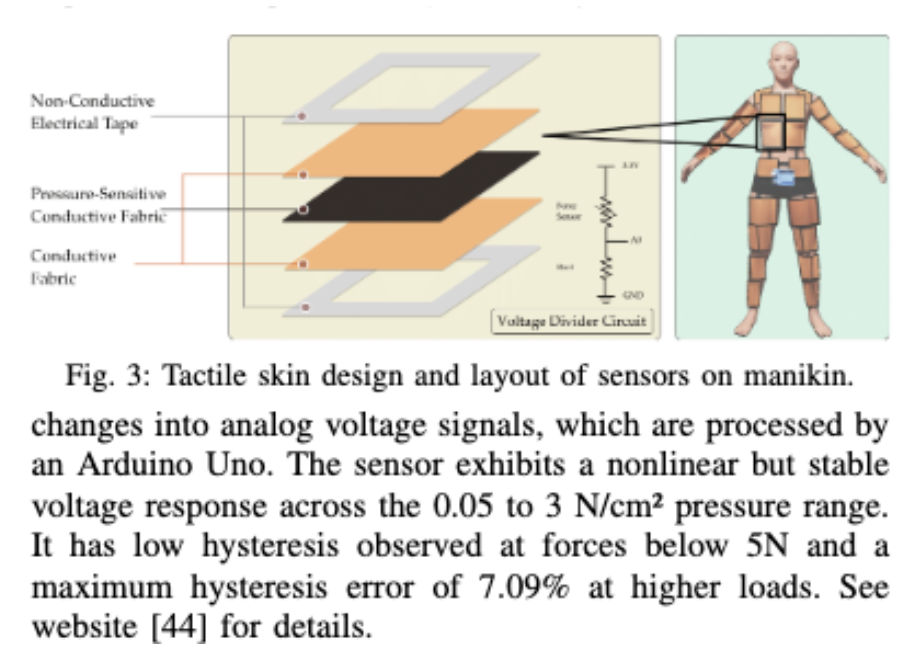
tacktill senser는 caregiver와 마네킹 사이의 물리적 접촉과 힘의 크기를 기록합니다. 커스텀한 전신 piezo-resistive skin은 마네킹 몸 형태에 맞게 부착 가능해야 하고, 곡면에 붙을 만큼 유연해야 하며, 마넼킹 무게로 눌려도 견딜 수 있어야 합니다. Fig3를 통해 skin이 어떤 식으로 구성되는지 확인할 수 있습니다.
Pose tracking은 12대의 카메라로 caregiver와 마네킹의 움직임을 추적합니다. caregiver는 hand와 head tracking을 위해 marker 장갑과 모자를 착용하고, 마네킹은 몸의 부위마다 body marker set을 사용합니다. 하지만 dressing의 clothing, transferring의 sling 때문에 마커가 가려져 tracking 실패가 발생하는 경우도 있는데요. 이를 보완하기 위해 저자는 세 RGB-D camera의 RGB image에 2D keypoints를 일부 수동으로 라벨링하고, YOLOv11 pose detector를 학습시켜 나머지 data를 자동 라벨링 한 뒤 3D position을 추정하였다고 합니다.
Eye-gaze tracking은 Pupil Labs eye-tracking 안경을 이용해 기록하였으며, 비디오와 2D gaze data를 기록합니다. eye-gaze tracking이 왜 필요할까 생각했는데, 논문의 저자가 이에 대해서 직접 밝히기를, caregiver가 task 중 어느 body part나 object를 먼저 보는지 알려줄 수 있다고 합니다. 이러한 것이 robot learning 관점에서는 gaze가 다음 action의 attention cue가 될 수 있기 때문에 해당 모달리티를 고려하는 것 또한 중요합니다.
Task and Action Labeling은 비디오와 caregiver의 설명을 기반으로 라벨링하였습니다. 치료사가 레코딩 된 것을 보고 task를 sub-task로 나눕니다.
본 논문에서 제안한 데이터셋은 여러 모달리티로 구성되어 있기 때문에 synchronization 과정, 즉, sensor별 sampling rate 차이를 맞추는 과정이 반드시 필요한데요. 각 모달리티 별로 하드웨어 장비로 인해 다른 sampling rate로 수집되었다고 합니다. 그래서 모든 컴퓨터를 NIST Internet Time Server에 맞춰 chrony와 w32tm으로 동기화되고, RGB-D stream의 15 Hz timeline을 기준으로 다른 모달리티의 가장 가까운 timestamp sample을 매칭했다고 합니다.
3. Dataset Characteristics and Analysis
해당 섹션은 단순 통계보다는 돌봄 전문가가 어떻게 몸을 움직이고, 어디를 만지고, 얼마만큼 힘을 쓰고, 어떤 전략을 쓰는지를 보여주는게 핵심인데요. 전체 규모는 315 session, 19.8 Hours, 5 모달리티, 21명의 전문가, 15 task, 31,185 Expert demonstration samples을 가집니다.
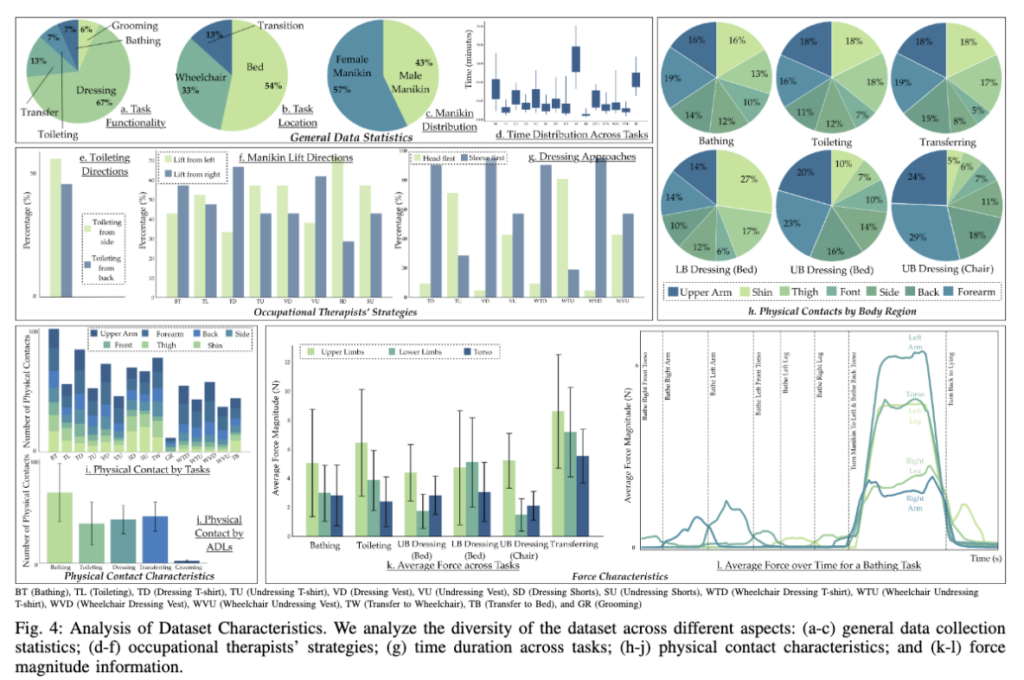
돌봄 전문가는 21명 중에 19명이 졸업을 앞둔 작업치료 전공 학생이고, 2명이 면허를 가진 전문가였는데요. 모두 여성이었고 나이는 22-75세로 가장 경험이 많은 전문가는 40년 이상의 임상 경험을 가졌다고 합니다.
본 논문의 핵심은 바로 “인간 돌봄 원칙”을 따로 정리했다는 것인데요. 전문가들의 수행 방식을 분석해 돌봄 원칙을 3가지로 정의하였습니다. 첫 번째로, pre-positioning인데요. task 시작전에 자세나 안정성, 관절 각도를 안전하게 준비하는 원칙입니다. 예를 들어서 몸을 옆으로 굴리기 전에 몸통 정렬을 맞춰 팔이나 다리가 끼이는 상황이나 예상치 못한 무게 중심 이동을 줄입니다.
두 번째로, Anticipation 인데요. 최종 자세와 움직임의 경로를 미리 생각하고 caregiver의 몸 사용 방식을 배치하는 원칙입니다. 이게 저는 주목해야할 점이라고 생각한게, 이런 과정에서 인간이 힘을 주기 어려운 동작이나 관절을 불편하게 꺽어야 하는 동작을 수행하게 되는데, 로봇은 이러한 제약이 없으니 정말 본 데이터셋이 필요한 목적이 이것이 아닐까 생각하게 되었습니다.
세 번째로, efficiency 입니다. 정확하는 것은 당연하고, 제때 끝내는 것을 중시하는 원칙인데요. 예를 들어서 심한 이동성 제한이 있는 사람의 경우, 조치가 지연이 되면 느린 부정맥이 오거나 저혈압, 어지러움 같은 위험을 겪을 수 있고, 옷이 잘못 놓이면 압박 궤양 위험도 생긴다고 합니다.
추가적으로 task 수행 시간에 대해서 좀더 분석을 하면 침대에서 휠체어로 이송하는 것이 가장 오래 걸리고, 휠체어에서 침대로 이송하는 것이 가장 오래걸렸다고 합니다. 전문가에게도 최대 9분까지 걸린 task라고 하네요. 9분 정도 걸린다는 것은 transferring이 여러 보조기기, 슬링, 사람의 팔 다리를 함께 다루는 long-horizon task임을 보여주기도 합니다.
toileting에는 두 가지 방식이 있는데요. 하나는 마네킹을 옆쪽으로 굴린뒤 침상용 변기를 넣는 방식이고 하나는 무릎을 굽혀 엉덩이와 골반을 들어 넣는 방식이 있습니다. 무거운 마네킹을 맡은 사람은 신체적 노력이 적은 옆으로 굴리기를 선호했다고 합니다.
dressing에서는 티셔츠를 입힐 때 90% 이상이 소매부터 끼우는 방식을 선호했고, 티셔츠를 벗길때는 75% 이상이 머리부터 벗기는 방식을 선호했는데, 팔다리를 정확히 유도하는 동작을 필요로 하지만 옷 벗기기는 제약이 상대적으로 적어 빠른 방법을 선택했음을 볼 수 있습니다.
4. Evaluation and Open Challenges
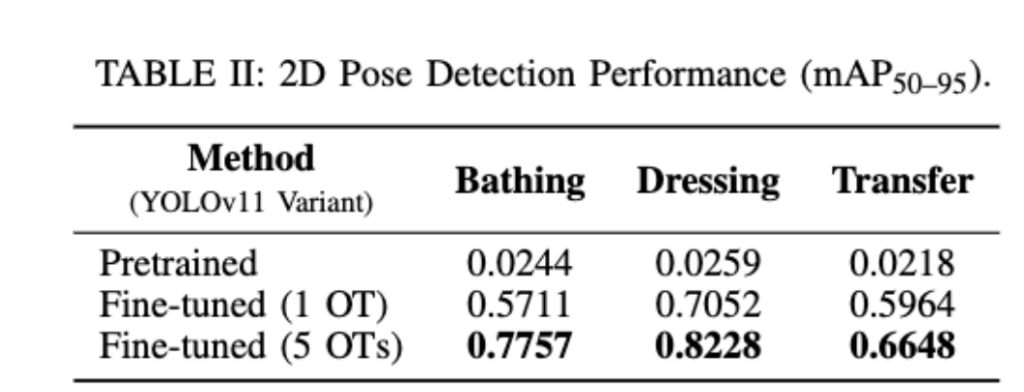
Table 2는 pose estimation에 대해서 SOTA 방법론의 성능을 보여주는 데요. YOLOv11 pretrained model을 보시면, Bathing 0.0244, Dressing 0.0259, Transfer 0.0218로 매우 낮은 mAP를 보이는 것을 알 수 있습니다. OpenRoboCare의 Labeled subset으로 Fine-tuning하면 1 OT 기준 Bathing 0.5711, Dressing 0.7052, Transfer 0.5964까지 오르는 것을 볼 수 있는데, 해당 결과는 Caregiving domain이 일반 Pose dataset과 Distribution shift가 크지만, Domain-specific data가 있으면 성능을 크게 개선할 수 있음을 보여줍니다.

3D pose estimation 성능은 Table 3를 통해 확인할 수 있습니다. RTMOPose3D가 119.9 mm, MixSTE가 122.9 mm, HoT가 142.2 mm, MHFormer가 162.7 mm MPJPE를 보이는 데요. 수치가 낮을수록 좋으므로 RTMOPose3D가 가장 낮은 오차를 보이지만, caregiving에서 요구되는 안전한 physical contact를 고려하면 여전히 큰 오차일 수 있다고 저자는 말합니다. 기존 모델이 어려운 이유가, 심한 occlusion, Close physical interaction, Multi-body pose estimation, Non-standard caregiving posture을 고려해야하기 때문입니다.

마지막으로 “Planning: Long-horizon task recognition”파트 입니다. 저자들은 VidChapters-7M을 21개 Video subset에 적용시켜 결과를 만들었다고 합니다.
기존 method는 일부 subtask를 인식하지만, Fine-grained detail이 부족하고 Domain-specific terminology에 약한 모습을 보였다고 합니다. 해당 사례를 통해 model이 일반 video captioning 지식만으로는 Caregiving terminology와 Procedure를 충분히 이해하지 못한다는 점을 보여줍니다.
이상으로 리뷰 작성을 마쳐보고자 합니다. 돌봄 로봇을 만들겠다는 의지가 보이는 논문이었던 것 같습니다. 돌봄 로봇에 굉장히 관심이 많기 때문에 계속해서 팔로업 해보고자 합니다. 읽어주셔서 감사합니다.
안녕하세요 주연님 좋은리뷰 감사합니다.
엄청 새로운 주제의 논문이라 읽게되었습니다.. 돌봄로봇이라 꼭 필요한 연구같다는 생각이들고 한편으로는 데이터셋 구축 비용만 하더라도 엄청난거같아요, 또한 환자를 대상으로하니 정밀도도 엄청 요구할거같고요.
궁금한것이 돌봄로봇이라해서 휴머노이드나 또는 로봇 팔을 통해서 action을 할거라는 예상을 했는데 예상한것과는 다르게 뭔가 비디오로 모니터링 하는 것처럼 detection하고 pose 추정만 실험에 담겨있네요 아무래도 아직 이쪽 분야에서는 로봇이 실제로 action하는 흐름은 아니라서 perception한거를 토대로 로봇의 투입시 action할수있는 기대정도로 연구가 진행이 되고있나요?
안녕하세요, 우진님 좋은 댓글 감사합니다.
저도 action을 기대하고 데이터셋 논문을 읽은 건데, 해당 논문은 action까지 이어지는 파이프라인의 베이스라인을 구축했다기 보다는 정말로 돌봄 연구를 수행할 수 있는 데이터셋을 제안한 것에 컨트리부션이 있는것 같습니다. 그래서 action 부분은 아직 없는거 같구요. 제가 이 분야를 지금 팔로업하고 있는데, 현재 care와 유사한 preference-aware한 로봇의 경우 action까지 진행한 것 정도까지 파악했습니다. OpenRoboCare와 유사한 데이터셋인 Assitive gym의 경우 2020년에 나와서 인용된 논문이 제법 있는데, 리스트를 대략적으로 보면 아직까지 현실단계에서의 action까지로 연구가 진행되고 있지는 않는 것 같습니다. 발전단계라고 보여집니다.
감사합니다.
주연님 좋은 리뷰 감사합니다.
해당 논문이 잘 구축된 벤치마크라고 판단하셨는데, 간병 전문지식이 포함되었기 때문일까요? 추가로 어떤 요인들이 긍정적으로 평하게 되었는 지 정리 부탁드립니다. 혹은 이런 정보도 필요하지 않을까 하는 아쉬운 점은 없었는 지 궁금합니다.
또한, 간병 원칙도 함께 포함되는 벤치마크인 지 궁금합니다.
마지막으로, 해당 벤치마크를 이용하여 연구들이 활발히 이루어지고 있는 지 궁금합니다.
안녕하세요, 승현님 좋은 댓글 감사합니다.
제가 예전에 감정인식 과제를 수행하면서 얼추 데이터셋을 구축해보기도하고, 여러 데이터셋 논문도 많이 있었었는데요. 그때 전문지식이 포함된 논문이라는 것이 굉장히 신뢰성 있는 데이터셋이라고 생각했습니다. 그래서 OpenRoboCare의 경우, 간병 전문지식을 가진 전문가가 수행한 것을 기록한 데이터셋이라는 것에 잘 구축되었다고 1차적으로 생각하였고, 많은 모달리티, tactile skin부터 eye-gaze 까지 고려한 것을 보면서 많은 모달리티를 한번에 많이 구축했다는 점에서 잘 구축되었다고 생각했습니다.
아쉬운점은 구축 과정에서 전문가가 모두 여성인 점이었습니다. 여성과 남성의 몸짓이 다를 수 있는데(키나 근력의 차이로 인해서), 여성의 케어 행동만을 추후에 학습하게 되는 것이 아닌가 아쉬웠습니다.
마지막으로, 해당 벤치마크는 아직 나온지 얼마 되지 않아서인지 인용이 3개밖에 없는데요. 적다고 생각이 들지만, 그럼에도 불구하고 Care관련하여 많은 연구자들이 최근들어 논문을 많이 내는 것 같아 점점 속도가 붙고 있는 연구가 아닐까 생각합니다.
안녕하세요 주연님 리뷰 감사합니다
사담이지만 캡스톤때 관련 주제를 하려다가 벤 당한 주제라서 흥미롭게 읽었습니다!
한가지 궁금한점이 있는데 OpenRoboCare는 전문가의 시선이나 접촉하는 힘, 자세와 순서까지 포함한 멀티모달 데이터셋인데 그럼 실제로 로봇학습시에 요 다양한 모달리티 중 어떤 게 가장 핵심적으로 기여하는지 궁금합니다.
예를 들어 RGB-D만 사용했을 때와 tactile, gaze, pose를 함께 사용했을 때 task별로 성능 차이가 크게 나타나는지, 또는 특정 task에서 특히 중요한 모달리티가 따로 있는지도 궁금합니다!
안녕하세요, 찬미님 좋은 댓글 감사합니다.
해당 논문의 경우, perception과 planning에 대한 평가만 본 논문에서 공개하여서 실제 로봇 학습시에 다양한 모달리티가 어떻게 기여하였는지는 확인할 수 없었습니다. 이 논문의 아쉬운 점인 것 같습니다.
그래도 제 생각을 말씀드려보면… 시각 정보가 주이기 때문에 RGB-D가 제일 성능을 많이 기여할 것이라 생각되며, planning에 gaze가 기여를, tactile은 수행 성공률에 대한 힌트가 될것이라 생각듭니다.
감사합니다.
안녕하세요 주연님 리뷰 감사합니다.
로봇 케어라는 부분이 제가 접했던 내용들과 달라서 좀 신기해서 읽게된 것 같습니다. Caregiving에 대한 요소들을 정리해서 벤치마킹 한 논문이 있을만큼 연구가 진행되고 있다는 사실에 놀랐습니다. 한가지 질문이 있는데, 기존에 연구하시던 감정 인식에 대한 요소는 로봇 케어 쪽에서 다루고 있을까요? 해당 벤치마크에는 내용이 없는 것 같아 질문 드립니다!
안녕하세요, 영규님 좋은 댓글 감사합니다.
저도 아직은 팔로업 중이지만 Caregiving에 대해서 연관되어 나오는 주제가 preference-aware 분야인데요. 사람의 선호를 인지하고 이를 기반으로 planning하는 로봇이라고 보시면 됩니다. 이 분야에서는 찾아보지는 않았지만 감정인식에 대한 요소가 충분히 들어갈 수 있다고 생각이들고, caregiving에서도 환자에게 맞는 조치를 취할때 행동에 적절한 감정을 담아 행동하면 더욱 좋지 않을까 하는 생각을 하였습니다.
감사합니다.
안녕하세요, 주연님. 좋은 리뷰 잘 읽었습니다.
케어 로봇이라는 분야를 처음 접하게 되어 흥미롭게 읽었습니다. 도움이 필요한 사람과 로봇이 직접 상호작용하는 만큼 안전이나 물리적인 상호작용 측면에서 굉장히 민감한 분야라는 생각이 들었습니다. 해당 논문에서는 마네킹을 활용한 것으로 보이는데, 실제 caregiving 상황에서는 돌봄을 받는 사람의 움직임도 중요한 변수일 것 같습니다. 이러한 대상자의 움직임도 고려한다는 내용이 있었는지 궁금합니다.
감사합니다.
안녕하세요, 성민님 좋은 댓글 감사합니다.
본 논문에서는 사지마비 환자를 가정한 마네킹으로만 연구를 진행하였습니다. 돌봄을 받는 사람의 움직인은 아직 고려하지 않은 것 같습니다. 다만 제가 생각해도 추후에는 돌봄을 받는 사람의 움직임도 고려하는 방법론이 나와야하지 않을까 생각합니다. 아직 이 분야의 성숙도가 올라오지 않아서 고려되지 않은 것 같습니다.
감사합니다.