안녕하세요, 이번주 X-review에는 tactile 관련 연구를 가져왔습니다. 최근 제안서 작업한 과제 내용에 기존 pretrained VLA에 tactile 센싱 모듈을 추가하겠다는 내용을 적었는데, 이거 어떻게 하면 효과적으로 하는걸까.. 고민하던 중 정민님이 하나 쓱 놓고 가신 연구입니다. 어댑터만 어떻게 잘 구성하면 될 것 같긴 했는데 논문이 마침 나온게 운이 좋은 것 같습니다.
Introduction
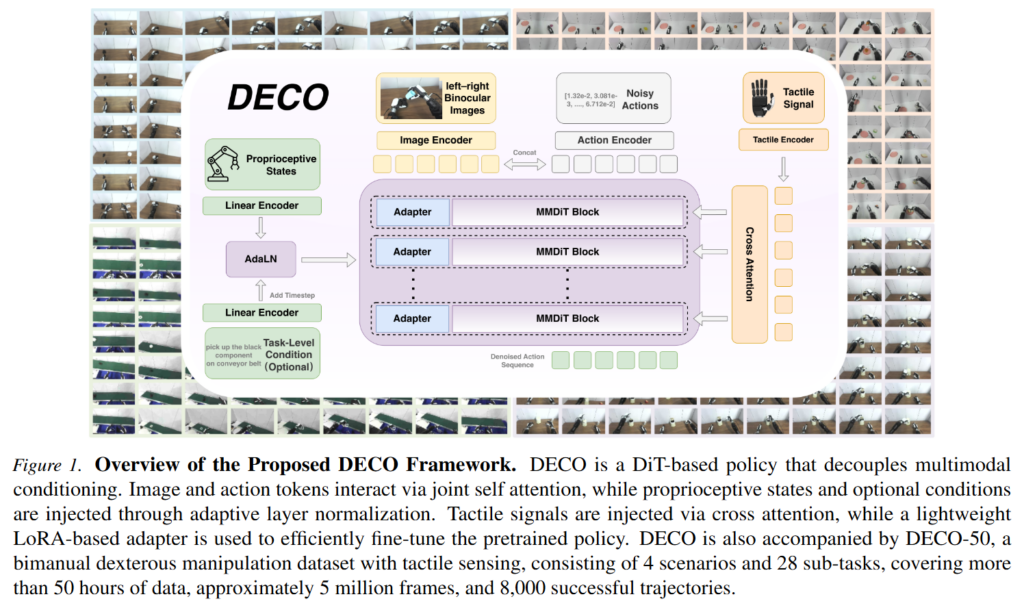
저자들의 DECO 또한 문제정의를 이 지점에서 했습니다. 저자들은 bimanual dexterous manipulation에서 시각, proprioception, tactile signal이 모두 중요하지만, 이 세 감각이 행동 생성에 기여하는 방식은 동일하지 않다고 합니다. 하지만 기존 visuo-tactile policy들은 여러 모달리티를 하나의 feature로 단순 결합하거나 동일한 중요도를 갖는 조건으로 취급하는 경우가 많았다고 합니다. 저자들은 이러한 coupled fusion이 각 모달리티의 역할 차이를 제대로 살리지 못하게 한다고 합니다. 특히 active camera처럼 시각 정보는 매 순간 크게 변할 수 있지만, tactile signal은 접촉이 발생하는 짧은 구간에만 sparse하게 나타납니다. 따라서 모든 모달리티를 같은 방식으로 섞는 것보다, 각 모달리티가 행동 생성에 개입하는 경로를 분리해야 한다는 것이 저자들의 핵심 철학입니다.
저자들은 각 모달리티가 행동 생성에 개입하는 경로를 분리시키는 아키텍쳐로 Decoupled Multimodal Diffusion Transformer를 제안했습니다. DECO는 image token과 action token은 joint self-attention으로 처리하고 proprioceptive state와 task condition은 AdaLN을 통해 조건으로 주입하며, tactile signal은 별도의 cross-attention adapter를 통해 주입한다고 합니다. 따라서 첫 번째 단계에서는 vision-action policy를 학습하고, 두 번째 단계에서는 pretrained policy를 freeze한 상태에서 tactile adapter만 추가 학습하여 tactile-aware policy로 확장하는 구조입니다. 저자들은 해당 연구에서 DECO (decoupled multimodal DiT)외에도 plugin 형식의 tactile adapter와 4개의 시나리오에서 28개의 subtask를 teleoperation한 8천개 에피소드 분량의 contact-rich tactile 데이터셋인 DECO-50을 제안했습니다.
Related Works
DECO가 다루는 문제는 단순히 tactile sensor를 붙이는 문제가 아니라고 합니다. 저자들이 보는 핵심 문제는 pretrained visuomotor policy에 tactile signal을 어떻게 안정적으로, 효율적으로, 그리고 기존 policy를 망가뜨리지 않으면서 통합할 것인가입니다. VLA 계열 연구들은 RT-1, RDT-1B, OpenVLA, π0와 같이 language instruction과 visual observation을 기반으로 action 생성을 보여주었습니다. 그러나 contact-rich manipulation에서는 vision alone으로 세밀한 물리 상호작용 상태를 포착하기 어렵습니다. 조립, 삽입, 미끄러짐 방지 같은 작업에서는 힘과 접촉 상태가 행동 성공 여부를 직접적으로 결정하기 때문에 VLA에는 tactile 센싱이 필요하다고 합니다.
이에 따라 tactile 기반 policy 연구들도 빠르게 늘고 있지만, 저자들은 기존 연구들이 tactile signal을 통합하는 방식이 아직 충분히 구조화되어 있지 않다고 합니다. 일부 연구는 tactile representation을 self-supervised learning으로 학습하거나, visual-tactile feature alignment를 수행하거나, tactile과 action을 함께 예측합니다. 하지만 실제 행동 생성 모델 안에서 tactile signal이 어떤 경로로 action generation에 영향을 주어야 하는지가 여전히 문제이고, 저자들은 이 문제에 대해 “촉각을 추가하는 것”보다 “촉각을 어디에, 어떤 방식으로 주입할 것인가”가 더 중요하다고 합니다.
데이터셋 관점에서도 기존 대규모 로봇 조작 데이터셋은 single-arm manipulation이나 gripper 기반 조작에 치우쳐 있거나, bimanual dexterous manipulation을 다루더라도 tactile sensing을 함께 제공하지 않는 경우가 많았습니다. 저자들은 이러한 공백을 보완하기 위해 DECO-50이라는 데이터셋 또한 공개했다고 합니다.
Method
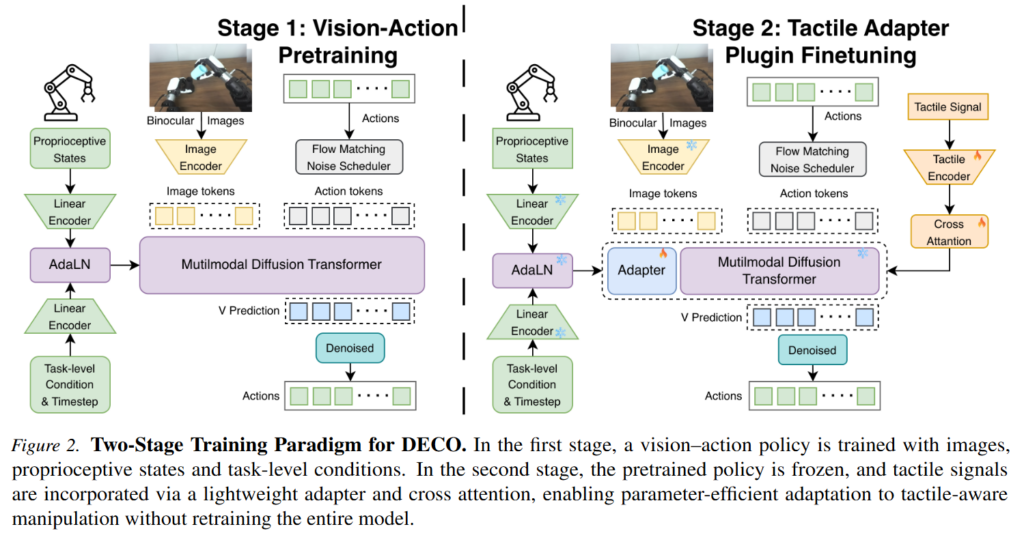
DECO는 크게 두가지 특징이 있습니다. 먼저 vision-action policy 자체를 Multimodal Diffusion Transformer, 즉 MMDiT로 구성하는 것입니다. 두 번째는 이미 학습된 vision-based policy에 tactile adapter를 plugin 형태로 추가하는 것입니다.
Observation에는 여러 camera image, robot joint state, tactile information, task-level condition이 포함됩니다. Action chunk는 rectified flow-matching loss로 학습한다고 합니다. 학습 시에는 원래 action chunk와 Gaussian noise 사이의 interpolation point를 만들고, 모델이 해당 지점에서 원래 action으로 향하는 velocity를 예측하도록 학습한다고 합니다. 추론 시에는 Gaussian noise에서 시작해 여러 flow-matching timestep을 거치면서 action chunk를 생성합니다. 핵심은 diffusion policy 계열의 장점을 따르지만, 단순 U-Net 기반 diffusion policy가 아니라 Transformer block을 중심으로 multimodal conditioning을 설계하는 것이라고 하네요.
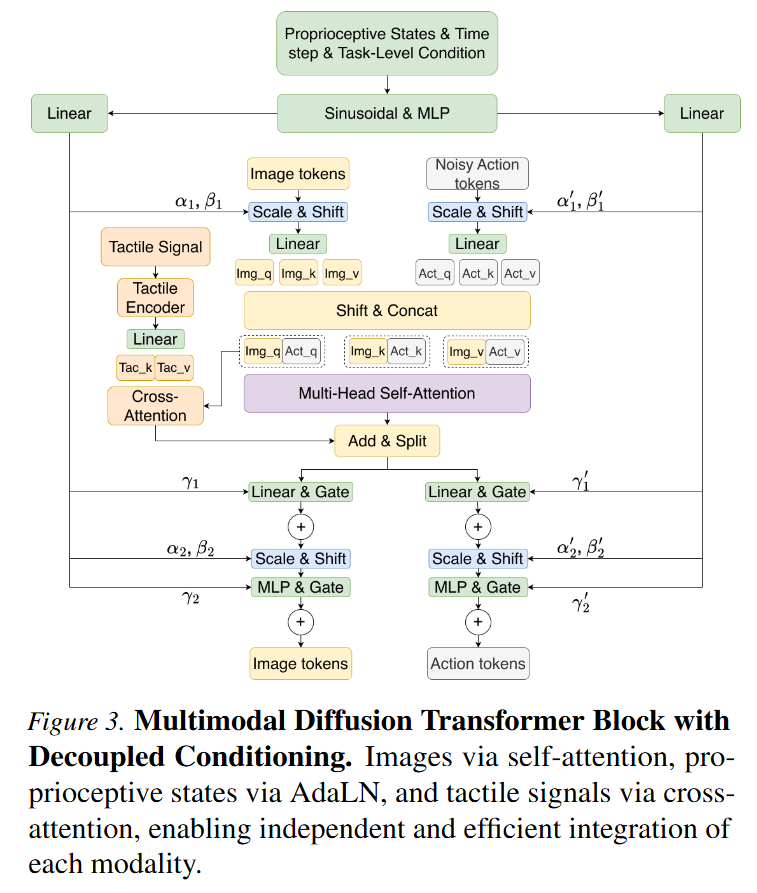
핵심이 되는 MMDiT block의 구조입니다. 저자들은 서로 다른 감각 모달리티가 action generation에 동일한 방식으로 기여하지 않는다고 가정하고 문제 정의를 했ㄱ ㅣ때문에 vision, proprioception, tactile을 하나의 conditioning vector로 합치는 대신, 각기 다른 주입 경로를 설계해주었습니다. Vision은 행동 생성에서 가장 주된 역할을 한다고 보고, image token과 noisy action token을 joint self-attention 안에서 직접 상호작용하도록 만듭니다. Binocular image는 shared ResNet-34 encoder를 통해 feature map으로 변환되고, 이를 token sequence로 펼친 뒤 rotary positional embedding을 각각 적용합니다. Noisy action sequence 역시 action token으로 embedding되고, learnable positional embedding이 더해집니다. 이후 image token과 action token은 각각 Q, K, V로 projection된 뒤 하나의 attention space에서 self-attention을 수행합니다. 이렇게 하면 action token은 시각 token을 단순한 외부 조건으로 받는 것이 아니라, 동일한 attention 공간 안에서 직접 참조하며 행동을 생성할 수 있다고 합니다.
Proprioceptive state와 task-level condition은 diffusion timestep과 함께 embedding된 뒤 AdaLN을 통해 scale, shift, gate 형태로 image token과 action token을 조절합니다. 이 설계는 robot joint state와 task condition이 장면을 직접 설명하는 정보라기보다, 현재 로봇의 상태와 수행해야 할 세부 작업을 알려주는 조건이라그렇다고 합니다. 즉, proprioception은 vision처럼 action token과 동일 공간에서 경쟁하는 정보가 아니라, policy의 내부 feature 처리 방식을 조절하는 conditioning signal로 사용됩니다.
Tactile signal은 cross-attention module을 통해 주입됩니다. 촉각은 항상 유효한 dense signal이 아니라, 접촉이 발생하는 특정 순간과 특정 손가락 영역에서만 의미 있게 나타나는 sparse signal이기 때문에 tactile을 proprioception이나 task condition과 함께 AdaLN에 섞어버리면, 모델이 sparse하고 noisy한 tactile pattern을 분리해서 활용하기 어려울 수 있다고 합니다. 따라서 저자들은 tactile encoder가 만든 tactile embedding을 별도 cross-attention 경로로 action/vision backbone에 주입함으로써, pretrained vision-action policy의 self-attention 구조를 크게 건드리지 않고 tactile cue를 필요한 순간에 참조할 수 있도록 만들었습니다.
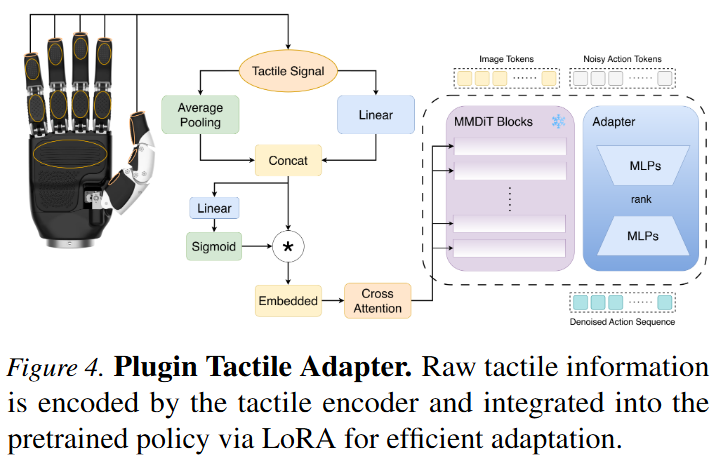
Tactile adapter를 보면 위 figure4와 같스빈다. Tactile encoder는 tactile pad의 raw value를 두 방식으로 처리합니다. 하나는 finger tip, pulp, end, palm 등 region별 tactile pad 값을 평균내어 region-level feature를 만드는 방식이고, 다른 하나는 raw tactile value를 learnable linear layer로 projection하는 방식입니다. 두 feature는 concat되고, gating mechanism을 통해 상대적 영향력이 조절된 뒤 최종 tactile embedding으로 변환된다고 합니다. 이 tactile embedding은 cross-attention을 통해 vision-based MMDiT에 주입되고, adapter는 LoRA방식입니다. 중요한 점은 이 tactile adapter를 두번째 stage에서 학습하는데, pretrained policy 전체를 다시 학습하는 것이 아니라 기존 policy는 freeze하고 adapter parameter만 학습합니다. 이 설계 덕분에 tactile integration을 할때도 pretrained vision-action policy를 유지하고, tactile adapter만 추가 학습할 수 있고, 기존 foundation policy나 대규모 vision-action policy를 촉각 기반 조작으로 확장할 수 있다고 합니다.
Experiments
저자들은 세 가지 질문을 중심으로 실험을 설계했다고 합니다. 모든 작업에 tactile이 필요한가, tactile adapter가 vision-based policy를 실제로 개선하는가, 그리고 tactile data를 multimodal policy에 어떻게 통합하는 것이 좋은가입니다. 저자들은 tactile이 필요한 작업과 그렇지 않은 작업을 구분하고, 필요한 작업에서 어떤 통합 방식이 효과적인지를 중심으로 실험을 설계했다고 하빈다.

저자들은 먼저 어떤 작업에서 tactile이 필요한지를 보기 위해 공개한 DECO-50 데이터셋의 네 가지 task를 설계했다고 합니다. Pick and Place는 왼손으로 plate를 들고 오른손으로 table 위 object를 집어 plate 위에 놓는 작업, material sorting은 컨베이어 벨트 위에서 움직이는 물체를 잡아 컨테이너에 넣는 작업입니다. 세 번째 waste disposal은 한 손으로 쓰레기를 집어 bin에 넣고, 다른 손으로 bin lid를 열고 닫는 작업입니다. 네 번째 assembly는 socket과 plug를 양손으로 동시에 제어해 조립하는 작업입니다. Contact-rich bimanual coordination과 force control이 다양하게 요구되는 세팅과 더불어 비전과 속도가 중요한 작업들로 구성한 것 같습니다.
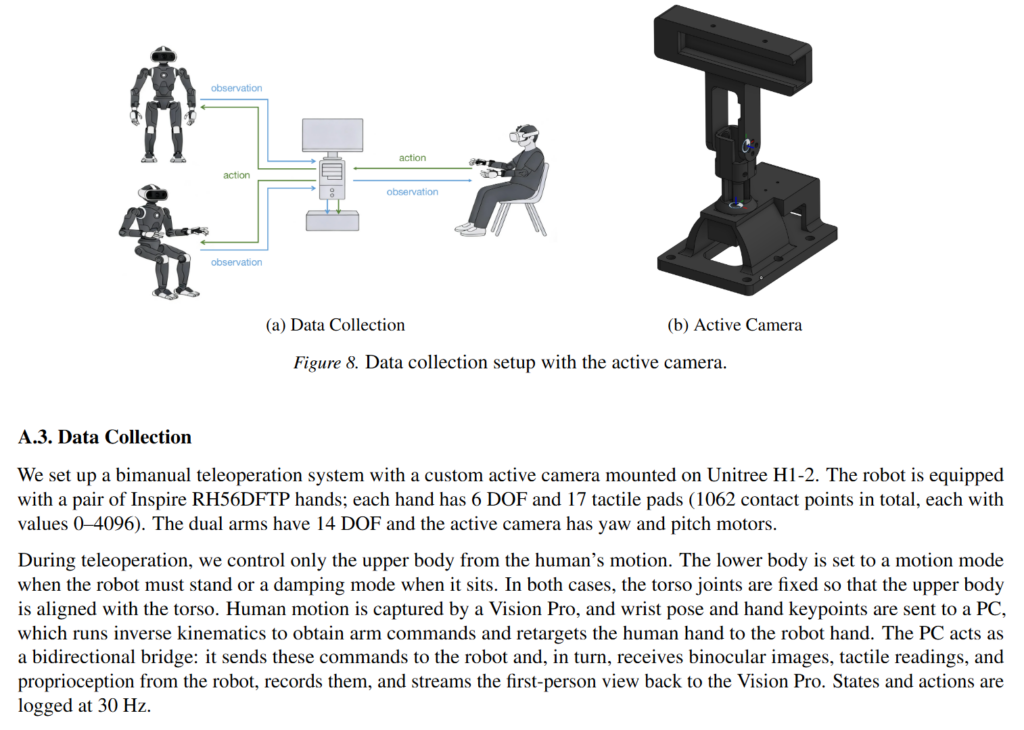
데이터는 Vision Pro를 통해 사람의 wrist, hand를 포함한 pose를 취득해 하체는 고정시킨 뒤 retargeting 해서 teleoperation을 하며 데이터를 취득했다고 합니다. Active 카메라도 부착돼있는데, 이 pose또한 vision pro를 통해 취득하는 것 같습니다. yaw, pitch 모터가 달려있습니다.
Baseline은 ACT와 Diffusion Policy입니다. ACT, DP, DECO는 먼저 tactile 없이 학습됩니다. 이후 tactile의 효과를 비교하기 위해 두 가지 tactile variant가 추가됩니다. DP.t는 tactile 정보를 input에 단순 concat하고 처음부터 학습한 모델입니다. DECO.p는 vision-based DECO에 tactile adapter를 추가하고 fine-tuning한 모델입니다. SR1은 전체 task, SR2는 contact rich task (waste dispoal, assembly)에 대한 결과입니다.
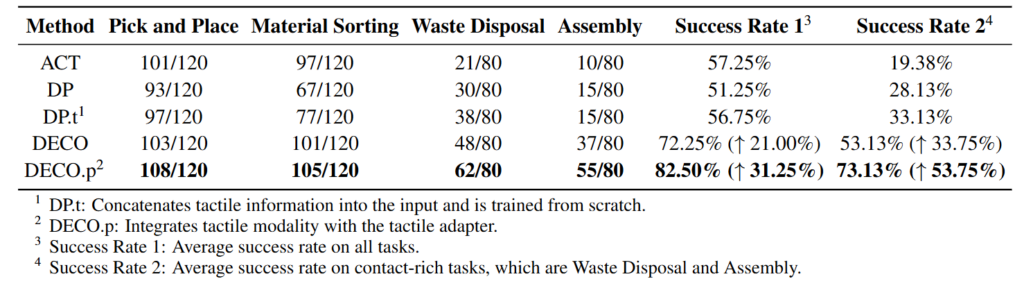
Table1에서 볼 수 있는것은 DP에 tactile을 붙여주더라도 DECO보다 성공률이 낮다는 점입니다. DECO에 tactile adapter 까지 붙였을 때 특히 SR2에서 차이가 나는 것을 볼 수 있습니다. 당연한 결과일수도 있지만 tactile 센싱이 필요한 task가 어떤 task인지를 잘 나타내고, 또 쉬운 task일지라도 tactile정보가 중요한 것 같습니다. 휴머노이드 세팅의 경우 머리쪽 cam 정보에 의존하는 경향이 있어 더 의미가 있지 않나 싶습니다.
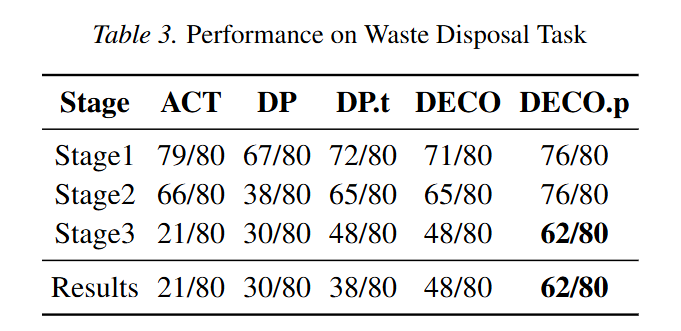
Waste Disposal은 tactile의 필요성이 훨씬 명확하게 드러나는 작업입니다. 이 작업은 lid를 열고, trash를 집어 넣고, lid를 닫는 세 단계로 나뉩니다. Lid를 열고 닫는 과정은 적절한 torque가 필요하며, torque는 접촉 위치와 가해지는 힘에 의해 결정된다고 합니다. Vision과 proprioception은 손을 대략적인 접촉 위치까지 보낼 수 있지만, lid가 실제로 닫혔는지, 충분히 눌렸는지, 다시 튀어 오를지 여부를 안정적으로 알려주지 못합니다. 아래 Figure 7은 vision-only policy가 lid가 닫혔다고 잘못 판단하고 손을 빼면서 실패하는 경우와, tactile adapter를 사용한 모델이 contact와 force 상태를 활용해 성공하는 경우를 비교합니다. Table 3에서도 DECO.p의 성능을 볼 수 있습니다.

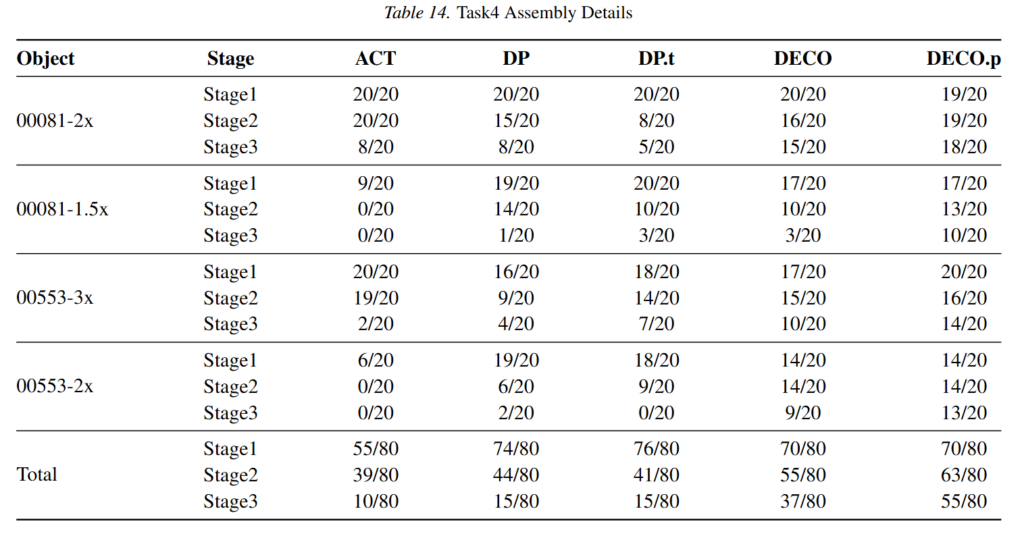
아래 Table을 통해 Assembly의 결과도 볼 수 있습니다. Assembly의 경우 아래 부품들을 조합하는 것이라고 합니다. Assembly 과정에서 많은 부분이 손에 의해 occlusion 되고, 끼우는 동안 힘을 유지하고 떨어트리지 않거나 균형을 맞추며 삽입하는 과정에서 tactile의 기여도를 볼 수 있고, 2x, 1.5x는 크기를 말합니다. 원래 부품을 해당 배율만큼 키워서 제작한 것이라고 하네요. 작은 객체들일수록 진가가 드러납니다.
Conclusion
해당 연구를 통해서 tactile이 항상 필요한 것은 아니지만, 필요한 작업에서는 vision을 대체할 수 없는 정보를 제공한다는 점을 확인할 수 있었고 multimodal fusion의 방식, tactile adapter 구조또한 확인해볼 수 있었습니다 . Pick and Place나 대부분의 Material Sorting처럼 object의 위치와 손의 움직임이 시각적으로 충분히 관측되는 작업에서는 tactile의 이득이 제한적이지만 접촉 여부, 미끄러짐, occlusion이 핵심 실패 요인이 되는 작업에서는 tactile이 성공률을 크게 끌어올리는 것을 확인할 수 있었습니다.
안녕하세요, 영규님. 좋은 리뷰 감사합니다.
평소에도 tactile 정보를 학습할 때 신경망이 tactile signal이 의미하는 접촉 상태나 물리적 의미를 명확히 이해할 수 있는지, 또 vision/action과의 연관성을 제대로 학습할 수 있는지 궁금했는데, 이번 리뷰를 보면서 그 부분을 이해하는 데 도움이 되었습니다.
한 가지 궁금한 점은, 리뷰에서 tactile signal이 sparse하고 noisy한 pattern을 가질 수 있다고 설명된 부분에서 noisy하다는 표현이 센서 측정값 자체에 포함된 noise를 의미하는 것인지, 아니면 task 수행 중 접촉이 순간적이고 불규칙하게 발생하기 때문에 학습 관점에서 noisy하게 보인다는 의미인지 궁금합니다.
좋은 리뷰 감사합니다.
안녕하세요 기현님 댓글 감사합니다.
시간 축으로 봤을 때는 각 센서가 작업하는 중에 short contact로만 나타날 수 있고, tactile 센서의 전체 센서 대비 접촉 면적의 해석에서는 많은 센서들 중 일부 pad만 활성화되며 이런 tactile 센싱 특성상 학습 관점에는 noisy하게 보일 수 있다는 의미입니다.
안녕하세요, 영규님. 리뷰 잘 읽었습니다. 읽다가 궁금한 부분이 있어서 질문 남겨놓습니다.
DECO.p의 성능이 경로를 분리한다는 아키텍처 자체의 효과인지, 혹은 adapter 기반 tactile fine-tuning의 효과인지 분리해서 보기 위해 ACT나 DP도 동일한 adapter fine-tuning 실험이 가능했을 것 같은데 이에 대한 논의가 있었는지 궁금합니다.
감사합니다.
안녕하세요 성민님 댓글 감사합니다.
논문에서는 ACT나 DP에 동일한 tactile adapter fine-tuning을 적용한 baseline은 제시하지 않았습니다. 현재 실험은 DECO 내부에서 tactile을 coupled하게 넣는 경우와 decoupled하게 넣는 경우를 비교해 decoupled injection의 유효성은 보이지만, 말씀하신 것 처럼 동일한 adapter를 ACT/DP에 적용한 추가 baseline이 있었다면 해석이 더 명확했을 것 같습니다.