안녕하세요 손우진 입니다.
이번에 제가 리뷰할 논문은 RGB 이미지로 부터 열화상을 생성하는 논문입니다. 저는 지금 껏 RGB이미지로 열화상을 만드는건 현실적으로 불가능하다고 생각했습니다. 열화상 이미지는 동일한 장면을 찍더라도 온도분포를 고려하기 때문에 매번 달라지기 때문이죠. 그래서 지금 껏 RGB – TIR 변환 논문을 보더라도 그럴 듯 하게 생성했구나 정도로 넘겼습니다. 하지만 이번에 소개드릴 논문은 새로운 길을 개척했습니다. 물리적으로 현상을 이해하면서 생성하는 방향으로 지금 까지의 방향과는 다른 올바른 방향으로 말이죠. 제가 리뷰한 논문중에서도 물리적 현상을 고려한 Thermal3dgs라는 논문이 있는데요 점점 열화상 관련 연구에서도 이런 물리적인것을 고려하면서 이미지에 대해 접근하다보니 성능들이 많이 좋아지는 것 같습니다. 이 논문은 참고로 정민님께서도 Slack에 공유해주신적 있는데요 서울대 김아영교수님 연구실에서 작성한 논문입니다. 재밌게 읽어주세요~
Introduction
저희 연구실 사람들이라면 열화상의 필요성과 장점에대해 충분히 알 것 같습니다. 하지만 연구를 할때 가장 큰 문제는 대규모 데이터셋 구축이 쉽지 않은 도메인입니다. 물리 기반의 TIR 시뮬레이터를 활용하는 방법도 있지만 한정된 장면만 만들 수 있다는 게 한계가 있습니다. 그래서 한편에서는 RGB로부터 TIR을 직접 합성해내는 RGB-to-TIR translation 연구가 되고있습니다. 근데 여기서부터 문제가 생기는데요. 도입부에서도 말씀드렸지만, RGB와 TIR은 완전히 다른 modality입니다. TIR 이미지가 표현하는 픽셀 값은 색이나 텍스처가 아니라 객체 표면의 상대 온도이고 열의 유무, 시간대/날씨/계절 같은 환경 조건에 따라 결정됩니다. 즉 같은 RGB 한 장이 주어지더라도 그 장면이 어떤 thermal 상태에 놓여있는지에 따라 TIR이 여러 개가 될 수 있다는 것입니다. 저자들은 이를 RGB-to-TIR translation의 본질적 ill-posedness 라고 정의하며, 기존 방법들이 이 부분을 외면해왔다고 지적합니다.
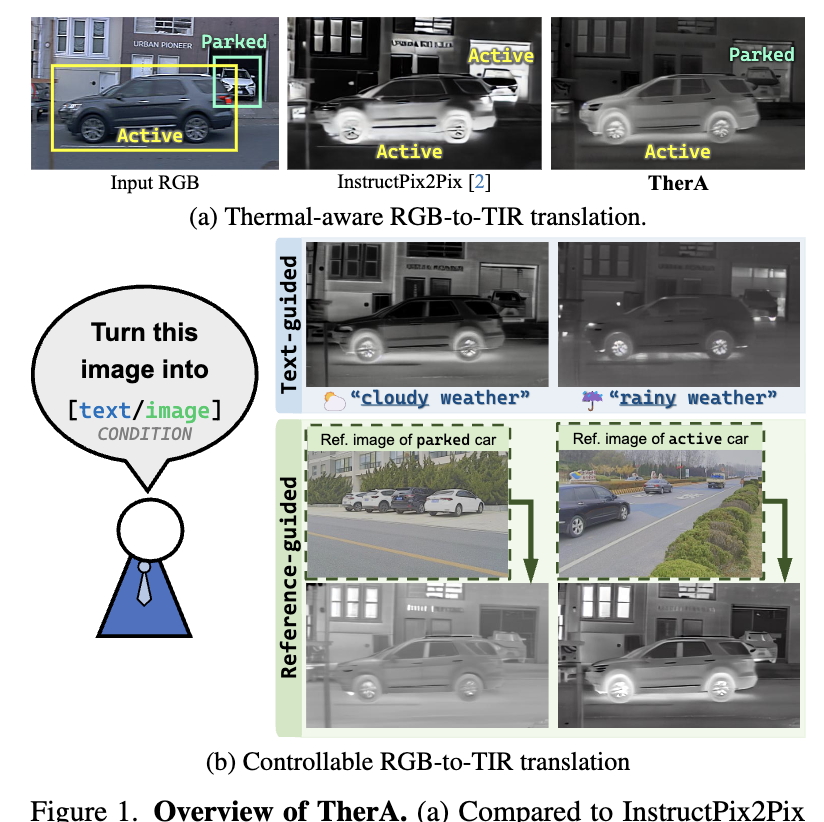
실제로 Figure 1을 보시면, InstructPix2Pix와 같은 기존 모델은 동일 장면 내에서도 주차된 차와 주행 중인 차를 구분하지 못하고 둘 다 자동차라면 뜨겁게 그려버립니다. 한 대는 식어있어야 하는데 말이죠..ㅎ 즉 RGB-to-TIR을 픽셀 단위의 style transfer로 풀어버린 결과, thermal의 물리적 현상들을 무시하는 출력이 나오게 됩니다. 찾아보니 후속 연구들은 이를 보완하기 위해 segmentation map이나 scene-index 같은 보조 prior를 추가하기도 했지만, 이런 prior는 어디에 어떤 객체가 있는지 같은 카테고리·레이아웃 정보일 뿐이라 열 방출과 전달의 physics 자체를 인코딩하진 못합니다.
저자들은 이 한계를 극복하기 위해 TherA라는 RGB-to-TIR translation framework를 제안합니다. 핵심 아이디어는 Thermal-aware Vision-Language Model(TherA-VLM)을 도입하여, 단순한 텍스트 캡션이 아니라 객체의 재료, 활동(?)상태, 장면의 환경 맥락 같은 thermal-relevant 정보가 인코딩된 embedding을 diffusion-based translator의 condition으로 활용한다는 것입니다. 추가적으로 TherA-VLM을 학습시키기 위해 R2T2라는 대규모 RGB-TIR-text 데이터셋을 구축했고, condition으로 사용되는 텍스트는 정해진 vocabulary로 형식화 시켰습니다(아래에 더 자세히 말씀드리겟습니다.). 이를 통해서 supervision signal을 깔끔하게 만들었다고 합니다. 더불어 사용자가 자연어 prompt나 reference 이미지를 통해 thermal appearance를 직접 조절할 수 있는 control 기능까지 한 framework 안에 녹여냈습니다. 도입부에서 언급드린 Thermal3DGS도 그렇고, 결국 thermal 분야는 단순히 픽셀을 흉내내는 방식이 아니라 physics 자체를 이해하고 모델링하는 방향으로 빠르게 옮겨가는 흐름인 것 같습니다.
저자들의 Contribution은 다음과 같이 세 가지로 요약됩니다.
Thermal-aware VLM Conditioning을 제안했습니다. 일반적인 CLIP text embedding이 아닌, 물리적으로 의미 있는 thermal embedding을 diffusion-based translator의 condition으로 사용하는 새로운 conditioning 방식을 도입했습니다.
Controllable Thermal Modulation을 구현했습니다. 텍스트 또는 reference 이미지를 통해 thermal appearance를 능동적으로 조절할 수 있으며, 이 과정에서 장면의 geometry는 변형되지 않고 유지됩니다.
SOTA 성능 및 데이터셋 공개를 입증했습니다. FLIR, M3FD 데이터셋에서 SOTA 성능을 달성했을 뿐 아니라 zero-shot 환경에서도 강건한 일반화 성능을 보였고, 추후 R2T2 데이터셋과 TherA-VLM 가중치, translation 모듈을 모두 공개하여 후속 연구를 지원한다고 합니다.
Method
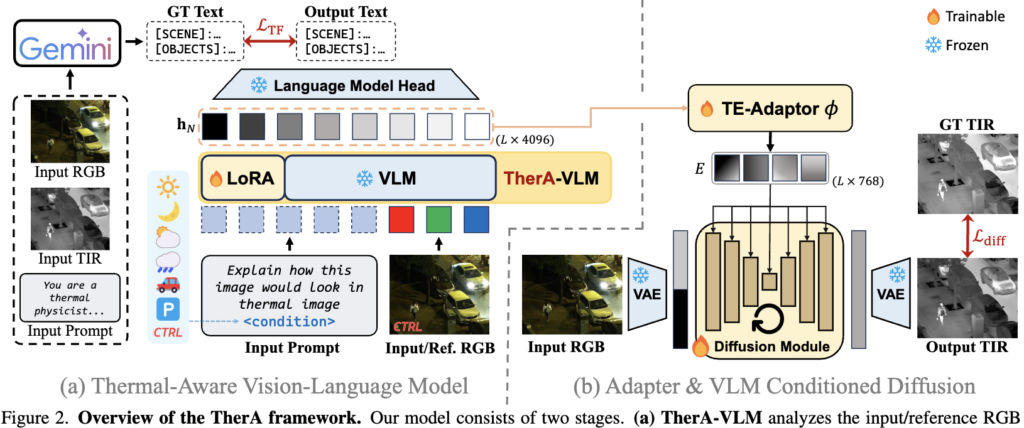
방법론에 대해 설명드리겠습니다. 우선 프레임워크의 전체 구조는 Figure 2와 같습니다. TherA는 크게 두 단계로 구성되어 있습니다. (a) 입력 RGB와 사용자 prompt를 받아 thermal-aware embedding을 추출하는 TherA-VLM, 그리고 (b) 이 embedding을 condition으로 받아 실제 TIR 이미지를 생성하는 VLM-conditioned Diffusion Module입니다. 핵심 아이디어는 단순합니다. 기존 diffusion 기반 translation 모델들은 condition으로 CLIP text embedding을 사용했는데, 저자들은 그 자리에 thermal physics를 이해하도록 학습된 VLM의 hidden state를 끼워 넣었다는 것입니다. 그럼 각 모듈에 대해 자세히 살펴보겠습니다.
R2T2 Dataset
TherA-VLM과 Diffusion Module을 학습시키기 위해서는 RGB, TIR, 그리고 thermal context를 묘사하는 텍스트가 함께 있는 데이터셋이 필요합니다. 저자들은 이를 위해 R2T2라는 100k 크기의 RGB-TIR-text triplet 데이터셋을 새로 구축했습니다. 각 요소로는 RGB 이미지, 정렬된 TIR 이미지, 그리고 장면과 객체의 thermal 특성을 묘사하는 canonical text로 구성됩니다.
데이터셋의 텍스트 부분을 먼저 살펴보면, 저자들은 multimodal reasoning 모델인 Gemini 2.5 Pro에 정렬된 RGB-TIR pair를 함께 입력으로 넣고, 해당 RGB 장면이 thermal domain에서 어떻게 나타나는지 keyword 단위의 structured output을 생성하도록 합니다. 이때 단순히 캡션을 뽑으면 vocabulary가 노이즈하고 중복이 많아 supervision signal로 쓰기에 부적절하기 때문에, 저자들은 결과 텍스트를 정해진 vocabulary로 맞춰주는 맞춰주는 과정을 거칩니다. 예를 들어, “sedan”/”SUV” → car 객체 속성(material, color, position, state)을 표준 토큰으로 통일하는 작업입니다. 개인적으로 흥미로웠던 점은 RGB만 보고 캡션을 뽑는 게 아니라 정답 TIR을 함께 보여주며 reasoning시킨다는 부분이었는데, 모델이 “이 RGB가 thermal에서는 어떻게 보일지”를 추측하는 게 아니라 실제 TIR을 참조한 신뢰할 수 있는 reasoning 결과를 supervision으로 사용할 수 있게 되는 셈입니다.
다음으로 RGB-TIR pair 구축 방식을 살펴보겠습니다. 우선 저자들은 기존에 공개된 9개의 정렬된 RGB-TIR 데이터셋을 그대로 통합해서 사용했고, 이 중 M3FD와 FLIR은 평가용으로 따로 남겨두었습니다. 다만 정렬된 데이터셋으로는 학습에는 부족합니다. RGB-TIR을 같은 시점에서 한 번에 촬영하려면 듀얼 카메라 시스템과 정밀한 캘리브레이션이 필요하기 때문에, 공개된 정렬 데이터셋의 수와 시나리오는 상당히 제한적입니다. 그래서 저자들은 시간 동기화는 되어 있지만 공간 정렬은 안 되어 있는 3개의 데이터셋으로부터 pseudo-aligned pair를 추가로 가공하였습니다. 두 카메라가 서로 떨어져 있어 viewpoint 차이가 존재하는 데이터셋들이라 pixel-level supervision이 불가능하기 때문에, 별도의 정렬 파이프라인이 필요합니다. 여기서 저자들이 명확히 짚고 가는 부분은 목표가 완벽한 pixel-wise registration이 아니라는 점입니다. 저자들은 어차피 정밀 정렬은 불가능하기 때문에, 학습에 쓸 만큼만 misalignment가 작은 frame을 골라내는 것이 현실적 목표라고 합니다.
(궁금하신분들만 읽어주셔도 무방한 부분입니다 -> 파이프라인은 MINIMA라는 cross-modal correspondence 추출기로 RGB-TIR 대응점을 찾고, 이를 바탕으로 RGB를 TIR view로 매핑하는 global warp를 fit하는 방식입니다. 카메라 extrinsic과 LiDAR scan이 제공되는 데이터셋의 경우 calibration으로 coarse rectification을 먼저 한 뒤 correspondence 기반 refinement를 적용했다고 합니다. 자동 정렬된 결과 중에서도 저자들은 검증 단계를 추가했습니다. 각 후보군들 중 RGB와 TIR을 0.5/0.5 비율로 겹친 겹쳐서 이미지를 생성하고 accept/reject 투표를 진행한 뒤 최종 채택하는 방식입니다. 이렇게 50,013개의 추가 pseudo-aligned pair를 확보하였다고 합니다. )
3.2 Thermal-Aware Vision-Language Model
이 절은 이 논문의 핵심인 TherA-VLM에 대한 설명입니다. 기존 RGB-to-TIR 모델들은 텍스트 condition으로 “turn this into a thermal infrared image” 같은 매우 일반적인 prompt를 사용하거나 BLIP 같은 일반 캡션으로 추출한 짧은 캡션을 사용해 왔습니다. 이런 RGB-centric description은 thermal physics를 전혀 담지 못하기 때문에 conditioning이 없고, 결과적으로 thermal 측면에서 부정확한 출력이 나오게 됩니다. 저자들은 이를 해결하기 위해 thermal-aware한 VLM fθ를 도입합니다. 이 모델은 RGB 입력과 사용자 prompt를 받아 계획된 프롬프트를 출력합니다.
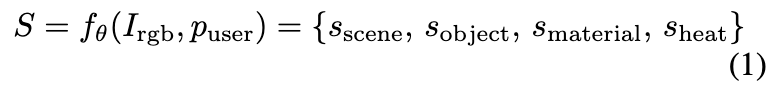
각 요소는 장면, 객체, 그리고 열 상태에 대한 정보를 인코딩합니다. figure3을 참고해주세용

저자들은 LLaVA 1.5를 base model로 사용하고, language 모듈과 image projection 모듈의 LoRA layer만 fine-tune했습니다. 학습은 앞서 만든 R2T2의 canonical schema를 pseudo-label로 활용한 teacher forcing 방식으로 진행됩니다. 각 학습 샘플은 RGB 입력과 sequence y = {y<em>n}</em>{n=1}^N 으로 구성되며, 다음 loss로 학습됩니다. (teacher forcing -> autoregressive에서 GT를 넣어서 안정적 수렴 달성을 위한겁니다.)
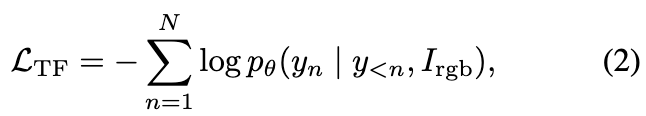
사실 TherA-VLM의 진짜 output은 텍스트 토큰 자체는 아닙니다. 저자들은 LM head를 통해 나오는 텍스트 토큰은 학습 단계에서 보조 출력으로만 사용하고, downstream의 diffusion model에 condition으로 전달하는 것은 LLaVA의 마지막 hidden state입니다. 즉 캡션 생성은 proxy 같은 역활이고, 실제로 활용하는 결과물은 그 reasoning 과정에서 형성된 내부 feature입니다. 다만 large VLM에서 나온 hidden state를 그대로 diffusion UNet의 attention layer에 바로 꽂아 넣을 수는 없습니다. 저자들은 이를 해결하기 위해 별도의 adapter 모듈을 도입했습니다. 이 TE-Adapter는 두 층짜리 feed-forward network로, TherA-VLM이 출력한 thermal embedding 을 UNet의 attention width에 맞게 projection합니다.
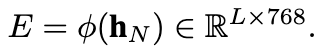
이렇게 projection된 E가 diffusion UNet의 cross-attention layer에 condition으로 주입되어, 기존 CLIP text embedding이 차지하던 자리를 대체하게 됩니다.
overview를 보시면 stage가 분리되어 있는데요. TherA-VLM은 먼저 학습되고, 그 다음 diffusion training 단계에서는 TherA-VLM을 freeze한 채로 UNet과 TE-Adapter만 학습됩니다. 즉 TherA-VLM은 thermal-aware representation을 나타내는 역할만 담당하고, 그 representation을 어떻게 UNet의 attention에 흘려보낼지는 adapter가 따로 학습하는 방식입니다.
3.3 VLM-Conditioned Diffusion
diffusion model을 활용하는 부분에 대해 설명드리겠습니다. 우선 저자들은 Stable Diffusion를 backbone으로 활용하여 latent diffusion 구조를 따릅니다.
학습 단계에서는 RGB와 GT TIR을 각각 frozen VAE encoder에 통과시켜 4채널 + 4 채널로 8채널latent로 변환합니다.
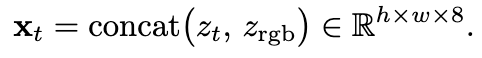
여기서 두 latent의 처리가 비대칭인데, RGB latent는 깨끗한 상태로 유지되고 TIR latent에는 timestep 에 Gaussian noise가 추가되어 zt가 만들어집니다. 그 다음 두 latent를 채널 방향으로 concat하여 8채널로 UNet의 입력으로 들어갑니다. RGB는 inference 때도 알고 있는 조건이라 굳이 노이즈를 더할 이유가 없고, TIR은 생성 대상이라 다양한 노이즈 레벨에서 denoising을 학습시켜야 하기에 thermal에 노이즈를 추가하였습니다.
UNet은 추가된 noise를 예측하도록 표준 MSE loss로 학습되고, 이 과정에서 thermal embedding E는 cross-attention을 통해 condition으로 주입됩니다. 그러면 모델은 두가지를 수행해야하는데요 RGB 를 열화상으로 또 context embedding에 맞게 학습을 시켜야합니다.
(저도 diffusion을 디테일 하게는 알지못했지만 이번기회에 찾아보게되면서 알게됐습니다.) 두 condition의 영향력을 조절하기 위해 dual classifier-free guidance를 사용합니다.<- 생성방향을 알려주면서 학습시키는 것입니다 분포에서 생성되고자 하는 방향을 빼줌으로써 이 효과를 볼수있다고 합니다. 아시는 분들은 이미 아실거같은데 모르신다면 한번 찾아보시는것도 추천드립니다..)
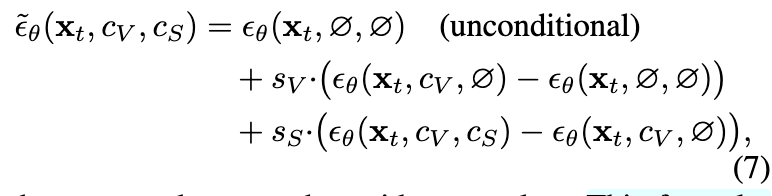
쉽게 얘기하면 RGB의 영향력은 Cv가, thermal embedding의 영향력은 Cs가 담당하게 되며, 사용자가 “RGB에 충실히 따르되 thermal context만 강하게 반영” 같은 미세한 조절이 가능해집니다. TherA-VLM의 입력에 사용자 prompt가 들어가기 때문에 prompt를 바꾸면 thermal embedding이 달라지고, RGB가 그대로 유지되므로 장면의 geometry는 변하지 않은 채 thermal 분포만 나타낼 수 있는 효과가 나옵니다. 저자들은 이를 통해서 control할 수있는 프레임워크를 만들게 된것입니다.
Experiments
실험 설명드리도록 하겠습니다.우선 데이터셋은 M3FD와 FLIR에서 TherA의 정량적 성능을 평가했으며, 비교 대상으로는 일반 image-to-image translation 모델들과 RGB-to-TIR 특화 모델(prior 사용)을 포함한 SOTA 방법들을 사용했습니다.
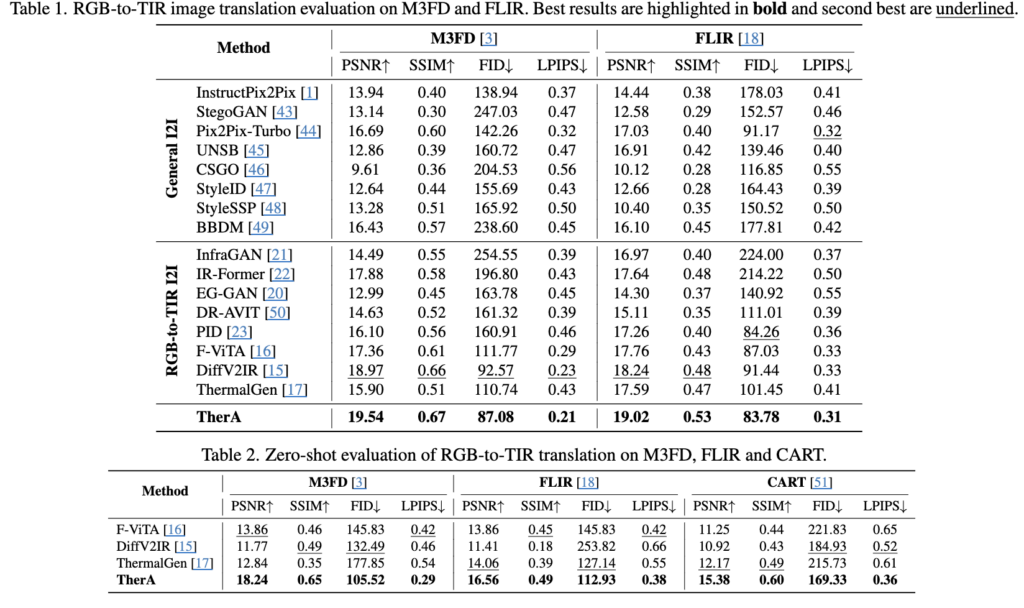
Table 1을 보시면 TherA가 PSNR, SSIM, FID, LPIPS 등 모든 지표에서 baseline들을 많이 능가합니다. baseline들 사이에서도 segmentation map이나 scene-description 같은 prior를 활용하는구조가 일반적인 translation 모델들보다 더 좋은 성능을 보입니다. 저자들이 이를 통해서 순수 픽셀 단위 end-to-end 학습으로는 RGB-to-TIR 변환이 한계가 있고 prior를 주입할수록 thermal translation 품질이 향상된다는 주장합니다.
Table 2는 학습에 사용되지 않은 데이터셋에서의 zero-shot 평가 결과입니다. TherA는 다른 SOTA 모델들 대비 모든 지표에서 엄청난 성능 향상을 보였습니다. zero-shot임에도 불구하고 학습기반들과 비비는 성능인데요 이 부분에대해서 thermal 물리적 특성을 프롬프트를 주게되면서 강력한 일반화를 준다고합니다. 아래는 정성적 자료인데 DiffV2IR이 prior로 segmentation 등 prior사용했는데 이는 segmentation 을 활용하면 물체들간의 부자연스러운 이미지가 생성된다고 합니다. 반면에 저자들의 이미지는 열에 대한 프롬프트를 줬기 때문에 주차되어있는 차에도 열이 크게발생하지않는 능력을 만들 수 있다고합니다. 대단하네요 ..

다음으로는 프롬프트로 control하는 능력을 보여주는데요, 동일한 RGB 입력에 대해 “cloudy weather”, “rainy weather” 같은 text prompt만 바꾸거나 reference TIR 이미지를 다르게 제공했을 때, 장면 구조적인 것은 유지되면서 thermal 표혀만 자연스럽게 변경됩니다. 프롬프트를 임베딩해서 diffusion으로 함께학습한 덕분이며 또한 프롬프트에 날씨 정보와 차들의 상태들이나 이런걸 주면서 가능하게 된다고 합니다.

마지막으로 ablation인데요
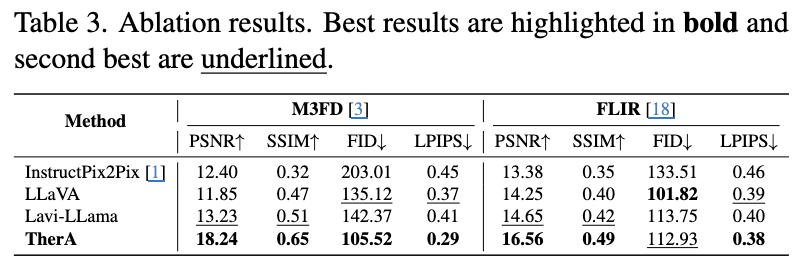
저자들은 conditioning 방식을 실험했습니다. (i) InstructPix2Pix를 R2T2로 학습시킨 baseline, (ii) generic LLaVA의 hidden state를 condition으로 사용한 실험, (iii) TherA-VLM이 생성한 표준화된 텍스트를 LLaMA encoder로 다시 embedding하여 condition으로 사용한 실험, (iv)통합한 성능입니다
hidden state를 직접 condition으로 활용하는 순간(iv) M3FD 기준 PSNR이 13.23에서 18.24로 점프합니다(+4.66 dB). (iii)과 (iv)는 둘 다 thermal-aware한 정보를 사용하지만, 텍스트로 전달하느냐 hidden state로 전달하느냐의 차이밖에 없는데도 차이가 발생합니다. 이는 TherA-VLM이 학습한 thermal reasoning은 텍스트로 변환해서 넣어주면 정보가 손실되고, hidden state를 직접 사용하게 되면 더 좋다고 합니다.
Conclusion
음 도입에서 얘기했듯이 사실 저는 그 동안 RGB로부터 TIR을 생성하는게 어려울거 같은 생각이 들었는데 그런데 해당 논문은 부족한 정보를 VLM의 reasoning으로 채워 넣는다는 방향으로 풀어냈다는 점이 해결방향이라고 제안하니 인상 깊었습니다…. 이전에 리뷰한 Thermal3DGS도 그렇고, thermal imaging 분야가 물리적 현상 자체를 모델링하는 방향으로 옮겨가고 있다는 흐름이 점점 명확해지는 것 같습니다. 감사합니다
안녕하세요, 우진님. 좋은 리뷰 감사합니다.
리뷰를 읽으면서 궁금한 점은, TherA가 실험실처럼 통제된 환경뿐만 아니라 우진님께서 실제로 실험하시는 외부 환경에서도 안정적으로 적용될 수 있는지입니다. 외부 환경에서는 날씨, 계절, 시간대, 태양광, 지면 온도, 객체의 사용 상태처럼 thermal appearance에 영향을 주는 요소가 매우 다양할 것 같습니다. 이런 변화가 큰 상황에서도 TherA-VLM이 학습한 thermal-aware representation을 통해 충분히 일반화될 수 있는지 궁금합니다. 또한 이러한 환경 변화가 큰 상황에서 해당 방법론이 오히려 더 큰 이점을 발휘할 수 있는지도 궁금합니다.
좋은 리뷰 감사합니다.
댓글 감사합니다. 기현님
지금 해당논문은 데이터셋 전체가 외부에서 진행된거라고 보실 수 있습니다. kaist 데이터셋이나 ms2 데이터셋과 같이 TIR과 RGB가 같이 있는 데이터셋을 활용했는데 이 데이터셋들 자체가 주행 데이터셋에서 거의 학습이 되었기 때문에 제가 하는 실험실에서는 일반화가 되지않을수도있습니다. 이 또한 실내 데이터셋이 제한적이여서 그럴거라 생각이듭니다. 추가적으로 여러 appearance 같은 경우 현재는 저자들이 설정한 정도로 만 가능 하고 추가적인것은 추후연구방향으로 이어진다고 합니다. 감사합니다
우진님 좋은 리뷰 감사합니다.
VLM으로 열에 대한 상태를 추출하여 활용하는 컨셉으로 이해하였습니다.
결국은 VLM 모델이 열화상 도메인에 대한 지식이 있어야 가능하다고 생각하는데, 이에 대해서는 기존 연구에서 열화상에 대한 이해 능력이 있다고 밝혀진 것일지도 궁금합니다.
전반적으로 열이 있다고 만드는 것이 아니라, 특정 영역만 밝아지도록(열이 있다고) 나타낸 것도 신기하네요..
Figure 3를 참고하면, 객체들의 상태가 active인지 passive인지가 중요한 것 같습니다. 사람과 같이 기본적으로 열을 가지고 있느 경우에는 움직이는지 아닌지가 중요한 정보가 아닐 것 같은데, 이러한 형태는 고정적인것일지도 궁금합니다.
좋은 댓글 감사합니다. 승현님
동적인 객체 그중에서도 보행자를를 말씀주시는 것으로 이해하였습니다. 우선적으로 보행자 같은경우에는 움직인든 움직이지 않던 열을 가지고 있어 고려대상이 아닌것으로 저는 이해하였습니다. 사람이 차가워져있으면 위험하지않을까요 ,,? 하하 따로 저자의 언급은 해당부분에 찾지는 못하였고 동적인 자동차에 대해서 고려만 한것으로 알고있습니다. 감사합니다
안녕하세요 우진님 리뷰 감사합니다.
TherA-VLM의 마지막 hidden state가 thermal representation으로 사용되는데, 이 representation에 semantic한 요소들을 고려하더라도 rgb 이미지 만으로는 RGB to TIR이 좀 모호할 것 같습니다. 로봇 작업 high level planning이나 액션 수행 쪽에서 uncertainty를 다루듯 해당 연구에도 VLM을 통한 representation 생성에서 uncertainty를 다루는 흐름들이 있을까요?
댓글 감사합니다. 영규님
저 또한 그렇게 생각이듭니다. 하지만 학습때는 열화상이미지를 노이즈로 변환해서 학습하게 되고 dual classifier-free guidance 학습방식으로 통해서 정확하게 가이드를 줄수있다고 저자들은 언급을 합니다. 다만 우려하신 내용 Uncerainty를 다루는 연구가 분명 존재할 것 같습니다. 저도 이쪽 Domain이 아직은 익숙치않아서 VLM representation 까지는 아직 찾아보지못했습니다 . 찾으면 직접 말씀드리겠습니다..ㅎㅎ
감사합니다