Abstract
Cross-view object correspondence는 서로 다른 뷰에서 대응되는 물체를 인식하는 연구로, 시점 및 외관 변화가 심하여 단순히 SAM2와 같은 foundation 모델을 적용하는 것으로는 해결이 어렵습니다. 해당 논문은 단일 시점의 segmentation에 2가지 Prompt Generator를 통합하여 cross-view correspondence로 확장한 V2-SAM를 제안합니다. 먼저 Cross-View Anchor Prompt Generator(V2-Anchor)는 DINOv3 feature로 기하학적 정보를 고려한 대응관계를 구축하고 cross-view 시나리오에서 SAM2를 위한 좌표 기반 프롬프팅을 처음으로 구현합니다. 두번째로 Cross-View Visual Prompt Generator(V2-Visual)는 ego-exo 시점(관찰자시점과 제3자 시점)의 representation을 특징과 구조 관점에서 정렬하는 새로운 visual prompt로 와관 단서를 강화합니다. 이러한 두가지 Prompt Generator를 multi-expert 구조에 적용하고, Post-hoc Cyclic Consistency Selector(PCCS)를 제안하여 가장 신뢰할 수 있는 expert를 선택합니다. 저자들은 다양한 실험을 통해 V2-SAM의 효과를 입증하였며 다양한 벤치마크에서 SOTA를 달성하였습니다.
Introduction
Cross-view object correspondence는 서로 다른 시점에도 동일 물체를 인식하는 것으로, 쿼리 시점에 마스킹된 물체를 target 시점에서도 인식할 수 있어야 합니다. 여러 cross-view 시나리오 중에 exo-ego object correspondence는 첫번째 사람의 시점(ego-centric)의 카메라와 제 3자 시점(exo-centric)의 카메라 시점으로, 시점과 외관이 극단적으로 변하는 어려운 케이스입니다.
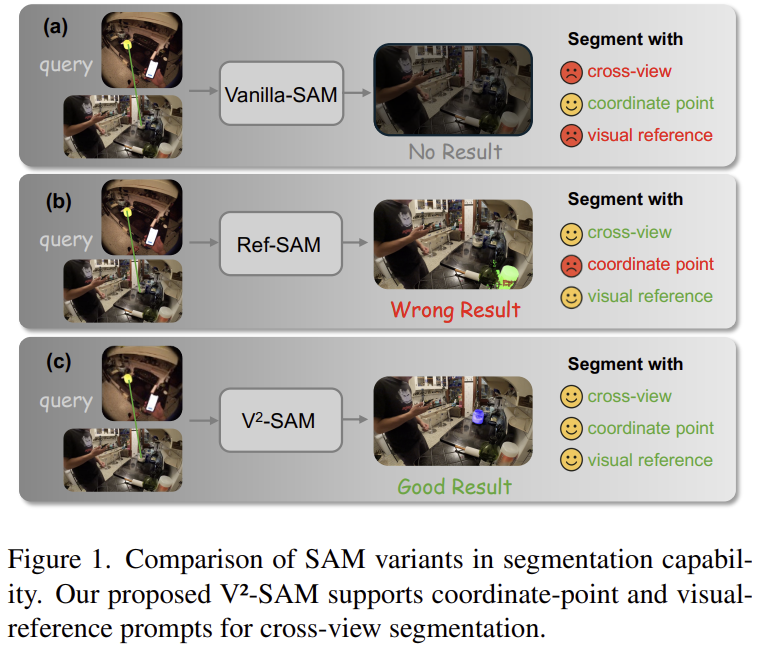
SAM2는 마스크 좌표나 bounding box와 같은 spatial grounded 프롬프트에 의존하므로, target 의 위치가 크게 변화는 cross-view 시나리오에서 잘 작동하지 못합니다.(Figure 1-(a)) 반면 Ref-SAM과 같은 referring 기반의 방식은 명시적인 positional 프롬프트를 visual guided prompt generator로 대체하며, 여전히 극단적인 시점 변화로 인한 외관정보 변화에 취약합니다.(Figure 1-(b)) 또한, 공간적 프롬프트를 제거함으로써 SAM2의 고유한 localization 능력이 약화된다고합니다. 저자들은 이러한 문제점으로부터 2가지 질문을 도출합니다.
- ① cross-view 시나리오에서 SAM2의 spatial prompting 능력을 활용할 수 있을 지?
- ② 가능하다면, 공간적 시각적 프롬프트가 상호보완적으로 동작하여 corss-view segmentation 성능을 높일 수 있는 지?
①번 질문을 다루기 위해 저자들은 Cross-View Anchor Prompt Generator (V2-Anchor)를 제안합니다. V2-Anchor는 DINOv3의 geometry-aware feature를 이용하여 ego와 exo 시점의 물체 사이의 대응을 식별합니다. 노이즈가 많은 대응 관계를 억제하고 복잡한 장면에서 주변 방해물과의 혼동을 피하기 위해, 이상치는 제거하고 매칭시 중심점을 선택하여 신뢰도 높은 좌표를 target view로 전달하여 SAM2의 좌표기반 프롬프트를 활용할 수 있도록 합니다. ②번 질문을 위해 저자들은 visual-referring segmentation 모델들로부터 영감을 받아 Cross-View Visual Prompt Generator (V2-Visual)를 제안합니다. 이는 서로 다른 뷰에서 feature와 구조적 관점에서 물체의 representation을 정렬하기 위해 새로운 Visual Prompt Matcher를 제시합니다. 즉, V2-Anchor는 어디에 있는 지 인식하기 위해, V2-Visual는 어떻게 보이는지를 식별하기 위해 설계된 것 입니다.
또한, 저자들은 이 두가지 프롬프트를 모두 활용하기 위해 Mixture-of-Expert 방식을 적용합니다. 두 프롬프트 Expert와 두 프로프트를 융합하는 Fusion Expert를 학습하고, 예측된 view의 일관성을 기반으로 각 객체에 대한 최적의 전문가를 선택하는 Post-hoc Cyclic Consistency Selector(PCCS)를 제안합니다. 저자들은 다양한 cross-view correspondence 벤치마크에서 V2-SAM이 뛰어난 성능을 보인다는 것을 입증하였으며, 해당 논문의 contribution을 정리하면 다음과같습니다.
- 처음으로 SAM2에 cross-view correspondence를 위한 프레임워크 V2-SAM 제안
- V2-Anchor를 통해 처음으로 cross-view 시나리오에서 SAM2에 좌표기반 프롬프팅을 가능하도록 하며, V2-Visual을 통해 외형 기반의 정보를 개선
- PCCS 모듈을 제안하여 다중 프롬프트 전문가 프레임워크에서 가장 신뢰할 수 있는 전문가를 적응적으로 선택
- Ego-Exo4D, DAVIS-2017, HANDAL-X에서 V2-SAM의 성능을 입증하였으며 SOTA 달성
Methodology
Task Formulation
쿼리 시점의 영상 I_q/V_q과 target 시점의 I_t/V_t가 구분된 시점에서 주어졌을 때, 쿼리 이미지에서의 물체의 마스킹M_q에 대응되는 target 시점의 마스크 \hat{M}_t를 찾는 것을 목표로 합니다. ego-exo object correspondence는 1인칭과 3인칭 시점에서 촬영된 두 영상으로, Ego2Exo와 Exo2Ego 2가지 subtask로 구성되며 카메라 파라미터는 주어지지 않고 시각적 정보만을 활용하여 대응되는 물체를 찾아야 합니다.
Overview
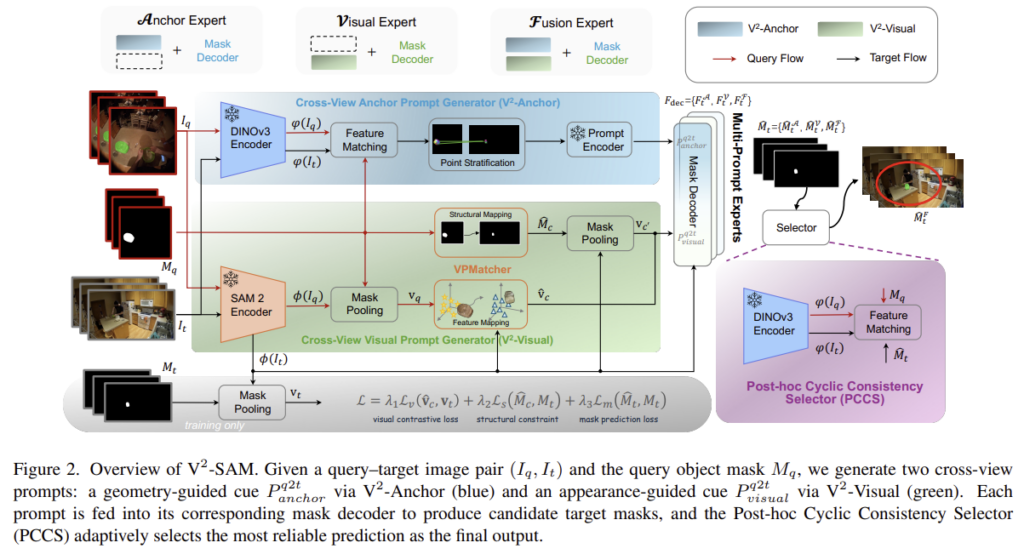
우선 V2-SAM는 SAM을 기반으로 구성되었으며, SAM2의 encoder \phi(.)와 Prompt Encodr, Mask Decoder를 그대로 사용합니다. 전체적인 개요는 위의 Figure 2에서 확인할 수 있으며, query-target 이미지 쌍 (I_q,I_t)과 query object mask M_q가 주어졌을 때, 모델은 2가지 prompt generator(V2-Anchor와 V2-Visual)를 사용하여 쿼리 시점의 객체 정보를 target 시점으로 변환합니다. 각 prompt generator로 생성된 cross-view prompt는 P^{q2t}_{anchor}와 P^{q2t}_{visual}로 표기되며, 각각 기하학적 단서와 외관 단서를 인코딩합니다. 이러한 두가지 상호보완전 prompt를 이용하여 Anchor Expert, Visual Expert, Fusion Expert 3가지가 구성되고 학습되며, 각 expert는 특정 prompt와 동일한 구조의 mask decoder를 결합한 구조(파라미터는 다름)입니다. 추론시에는 모든 expert가 target-view에 대한 마스크를 예측하며, 이후 Post-hoc Cyclic Consistency Selector(PCCS)가 일관성을 평가하여 가장 신뢰할 수 있는 결과를 적응적으로 선택합니다.
Cross-View Anchor Prompt Generator(V2-Anchor)
V2-Anchor는 query와 target 시점의 이미지 사이의 기하학적 관계를 탐색하여 target 이미지 I_t에서 대응되는 물체를 찾는 역할을 합니다. 저자들은 해당 과정에 DINOv3를 이용합니다. patch-level feature \varphi(I_q)와 \varphi(I_t)를 추출한 뒤, cross-view segmentation을 위한 기하학 기반의 anchor prompt를 생성하기 위해 순차적으로 feature matching, point stratification, coordinate transformation, prompt encoding 과정을 거칩니다.
[Feature Matching]
각 query 패치 \varphi(I_q)를 모든 target 패치 \varphi(I_t)에 대하여 코사인 유사도를 계산하여 correspondence heatmap \mathbf{H}를 구합니다.
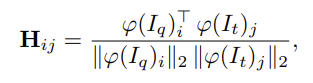
각 query 패치에 대해 가장 유사도가 높은 target 패치의 인덱스j* = arg \ max_j \mathbf{H}_{ij}를 찾은 뒤, 해당하는 패치 인덱스를 각각 query와 target 이미지 위치로 매핑하여 대응되는 2D 좌표를 복원합니다.
또한, 객체에 해당하는 영역만 사용하기 위해 query mask M_q를 DINOv3로 투영하여 유효한 패치는 point set \mathcal{P}_q = \{i|(x_i,y_i) \in M_q\}를 구성하여 이후 feature matcing을 통해 가장 잘 대응되는 target point set \mathcal{P}_t를 구성합니다. 이를 통해 노이즈 및 배경을 억제하여 이후의 stratification 과정에서 기하학적 정밀도를 개선하고자 하였다고 합니다.
[Point Stratification]
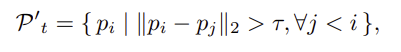
해당 과정은 \mathcal{P}_q와 \mathcal{P}_t 사이에서 최소한의 distance \tau를 보정하는 것으로, 이를 통해 컴팩트하면서도 다양한 고품질의 correspondence set \mathcal{P}'_t을 구합니다.
[Corrdinate Transformation and Prompt Encoding]
\mathcal{P}'_t는 원본 이미지 좌표계에 정의되지만, SAM2의 내부 표현과 맞추기 위해 canonical coordinate space로 선형변환합니다. 이렇게 구해진 좌표 \tilde{\mathcal{P}}_t는 prompt encoder에 입력하여 target 뷰를 위한 coordinate-based anchor prompt P^{q2t}_{anchor}를 생성합니다.
Cross-View Visual Prompt Generator(V2-Visual)
V2-Visual은 서로 다른 view 사이에서 시각적으로 유사한 객체를 식별하기 위해 외관 단서를 포착하는 역할을 합니다. 먼저, SAM2 encoder를 적용하여 query와 target 시점의 이미지에 대하여 visual feature \phi(I_q)와 \phi(I_t)를 추출하고, 학습 과정에 이 feature map들에 대하여 각각의 object mask M_q와 M_t를 사용하여 mask pooling을 수행하고, region-level feature를 구합니다.
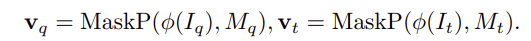
[Visual Prompt Matcher(VPMatcher)]
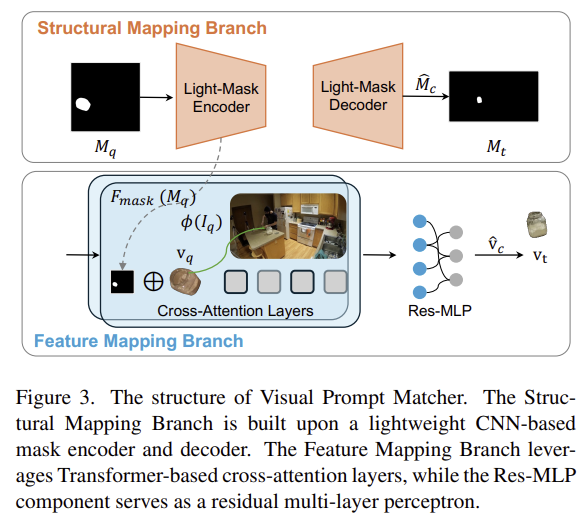
VPMatcher 구조는 Figure 3에서 확인할 수 있으며, 2개의 브랜치로 구성되어있습니다. 하나는 Feature Mapping Branch로 서로 다른 뷰에서 의미론적으로 일관된 representation을 학습하며, 다른 하나는 Structural Mapping Branch로 객체 mask를 재구성하여 구조적 일관성을 유지하도록 합니다.
[Feature Mapping Branch]
먼저, Feature Mapping Branch는 query에서 얻은 region feature \mathbf{v}_q와 경량 CNN 기반 mask encoder F_{mask}를 적용하여 얻은 mask feature F_{mask}(M_q)를 더하여 fused prompt embedding \mathbf{p}_f를 생성합니다. 이후, linear projection을 적용하여 query, key, value \mathbf{q,k,v}를 형성하며, attention weight는 아래의 식으로 계산됩니다.
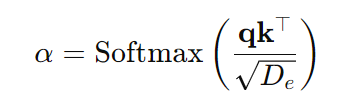
이때 D_e는 임베딩의 차원을 의미하며, attention weight은 배경의 노이즈를 억제하기 위해 spatial gating function에 의해 조절된다고 합니다. 이후 여러 Transformer 기반 cross-attention encoder layer와 residual multi-layer 구조를 통해 점진적으로 정제되어 최종적으로 predicted cross-view embedding \hat{\mathbf{v}}_c가 생성됩니다.
[Structural Mapping Branch]
두번째 브랜치는 query mask의 구조 정보를 이용해 target view에서의 객체 mask를 예측합니다. 단순히 appearance feature만 맞추는 것이 아니라, 객체의 대략적인 형태나 공간적 구조도 유지하도록 합니다. 이를 위해 query mask를 down-sampling하여 prior representation \mathbf{m}_{prior}를 만들고, query feature로 modulation을 수행하여 mask space로 semantic conditioning이 이루어집니다.
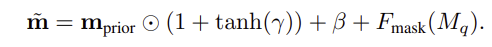
최종적으로, decoder F_{mask}가 \tilde{\mathbf{m}}를 점진적으로 up-sampling하여 predicted cross-view mask \hat{M}_c를 생성합니다.
마지막으로, 예측된 mask \hat{M}_c를 기반으로 다시 region feature \mathbf{v}_{c'}를 추출하고, Feature Mapping Branch에서 얻은 cross-view embedding \hat{\mathbf{v}}_c과 결합한 뒤, MLP를 통과시켜 최종 appearance-guided prompt P^{q2t}_{visual}를 생성합니다.
Multi-Expert Training
V2-Anchor는 기하학적 구조에 기반하고, V2-Visual은 시각적 외관에 초점을 둔 프롬프트로, 상호보완적인 장점을 활용하고, 다양한 cross-view 상황을 처리하기 위해 저자들은 장면에 따라 적합한 expert를 적응적으로 선택할 수 있는 multi-expert training 방식을 설계하였습니다.
총 anchor expert, visual expert, fusion expert 3가지로 구성되며, 서로 다른 prompt를 입력으로 사용하여 동일한 mask decoder에 조건으로 활용됩니다. anchor expert는 P^{q2t}_{anchor}, visual expert는 P^{q2t}_{visual}이 입력으로 들어가며, fusion expert는 P^{q2t}_{anchor}와 P^{q2t}_{visual}가 함께 입력으로 들어가 통합 프롬프트 embedding으로 결합됩니다.
학습의 경우, anchor expert는 SAM2의 mask decoder를 그대로 사용하는 training-free 방식이며, visual expert와 fusion expert는 새로 학습이 필요한 VPMathcer가 포함되므로, SAM2 encoder는 freeze하고, VPMatcher와 mask decoder를 학습하게 됩니다.
[Loss Function]
학습에 사용되는 Loss는 크게 3가지로, visual constraint loss \mathcal{L}_{v}, structural constraint loss \mathcal{L}_{s}, mask prediction loss \mathcal{L}_{m} 의 가중합으로 정의됩니다. 실험에서는 1:1:10의 가중치를 사용하였다고 합니다.
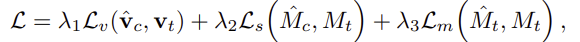
먼저, visual constraint loss \mathcal{L}_{v}는 서로 다른 view의 region-level feature mapping을 강제하기 위해 positive 쌍은 가까워지고, negative 쌍은 멀어지도록 하는 아래의 식으로 정의됩니다.
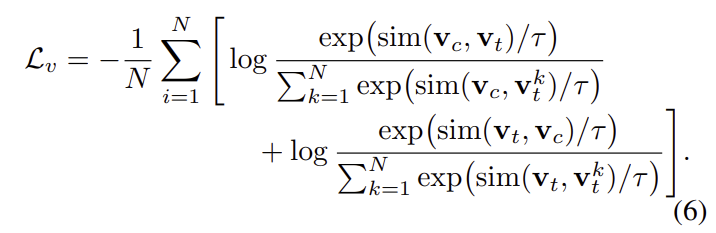
- sim(.): 코사인 유사도
- \tau: temperature 파라미터
다음으로, mask prediction loss \mathcal{L}_{m}는 mask-level loss로, structural constraint loss \mathcal{L}_{s}도 이를 기반으로 합니다. pixel-wise cross-entropy loss와 region-level Dice loss를 결합한 형태로, \mathcal{L}_{CE}는 픽셀에 대한 classification error, \mathcal{L}_{Dice}는 GT와 예측 마스크 사이의 overlap을 측정하게 됩니다.
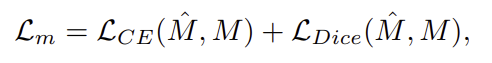
마지막으로, structural constraint loss \mathcal{L}_{s}는의 경우에도 mask loss를 적용하여 VPMatcher 내부의 cross-view structural mapping 과정에 제약을 부여합니다.
Post-hoc Cyclic Consistency Selector(PCCS)
마지막으로 저자들은 query와 target 마스크 사이의 일관성을 기반으로 가장 신뢰할 수 있는 expert를 적응적으로 선택하기 위해 PCCS를 제안하였습니다. target view에서 예측한 mask를 다시 query view로 되돌려 봤을 때, 원래 query mask와 얼마나 잘 맞는지 확인하는 것으로, V2-Anchor를 통해 target의 마스크를 query로 되돌립니다.
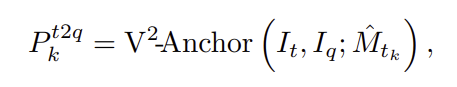
cyclic consistency 검증을 위해, 저자들은 back-projected point P^{t2q}_k와 query mask에서 샘플링한 reference point 사이의 평균 거리를 계산합니다. 이를 proxy score로 사용하여 어떤 expert의 결과가 가장 신뢰할 수 있는지를 선택하게 됩니다. 이러한 방식은 mask를 복원하는 기존의 cyclic consistency방식과 다르게 point level에서 동작하므로, decoding 과정도 피할 수 있어 더욱 효율적인 방식임을 이야기합니다.
Experitments
실험은 다음 3가지 벤치마크에 대하여 이루어졌습니다. Ego-Exo4D, DAVIS-17(video object tracking), HANDAL-X(robotic cross-view segmentation)
[Results on Ego-Exo4D]
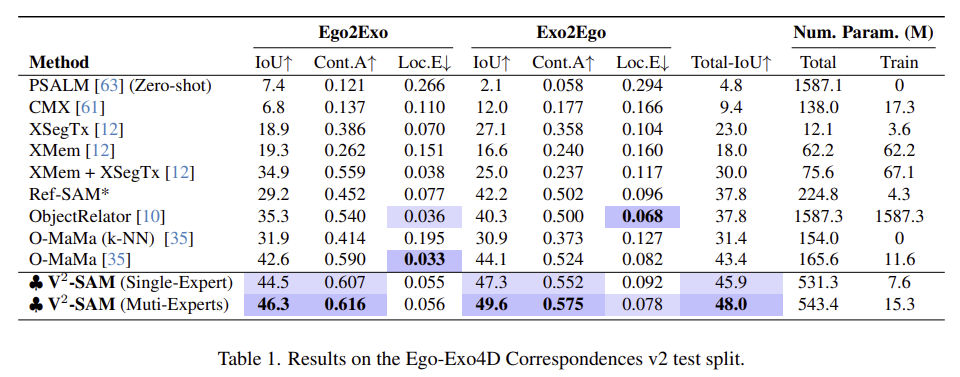
Table 1은 Ego-Exo4D에 대한 실험 결과로, 대부분의 지표에서 V2-SAM이 우수한 성능을 달성하였으며, 기존의 SOTA 방법론인 O-MaMa보다 IoU가 각각 3.7, 5.5 개선되었습니다. 단일 expert로도 우수한 성능을 보였으며, ObjectRelator보다 훨씬 적은 학습 파라미터만으로도 성능 개선이 이루어졌다는 것을 강조합니다.

위의 Figure 5와 6은 Ego2Exo와 Exo2Ego의 정성적 결과입니다. 복잡한 배경에서는 Visual Expert가 시각적으로 유사한 객체를 잘못 고르는 경우가 있는 반면, Anchor Expert는 기하학적 단서를 통해 조금 더 잘 동작하였다고 합니다. 또한, Visual Expert의 경우 basketball이나 music처럼 움직임이 크거나 외관 변화가 심한 경우에 더 강인하게 동작하였다고합니다. Fusion expert는 occlusion이 심한 물체 조작 장면이나 다양한 장면에서 안정적으로 동작하고있으며, 최종적으로 PCCS를 통해 신뢰도가 높은 마스크가 잘 선정된 것을 확인할 수 있습니다.
[Results on DAVIS-17]
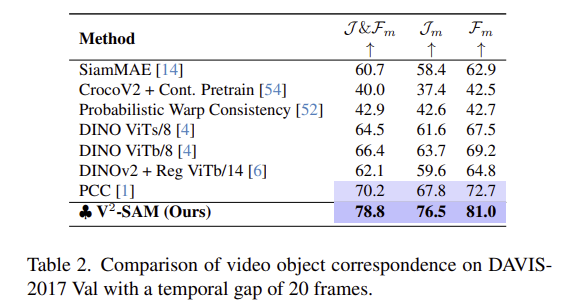
DAVIS-17은 video object tracking에서 많이 사용되는 벤치마크로, 모든ㄷ 프레임 사이의 대응 관계를 20개 간격으로 평가한 결과입니다. Table 2를 통해 저자들이 제안한 방식이 우수한 성능을 달성하였음을 보였습니다. 특히, 기존의 self-supervised 방법론들보다 두드러지는 성능 개선이 이루어졌으며, viewpoint 변화가 큰 상황에도 강인하게 작동함을 실험적으로 입증하였습니다.
[Results on HANDAL-X]
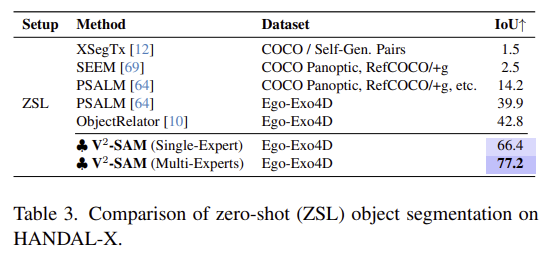
HANDAL-X는 로봇 조작이 가능한 객체를 포함한 데이터셋으로, Ego-Exo4D에서 학습된 모델을 zero-shot으로 적용한 결과입니다. 두드러진 성능 개선이 이루어진 것을 확인할 수 있습니다.
[Ablation on Individual Expert]
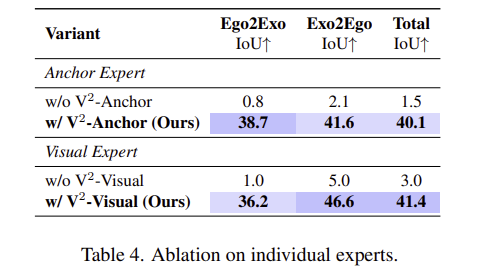
V2-Anchor와 V2-Visual의 유무에 따른 실험 결과입니다. Anchor Expert는 V2-Anchor를 제거하고 query mask의 중심점을 target view를 위한 프롬프트로 사용한 방식이며, Visual Expert는 Visual Prompt Matcher를 제거하고 mask polling으로 얻은 query feature를 그대로 cross-view segmentation의 프롬프트로 사용한 방식 입니다. 실험 결과, 두 요소가 모두 중요한 역할을 하고 있다는 것을 실험적으로 보였습니다.
[Ablation on Experts Combinations]
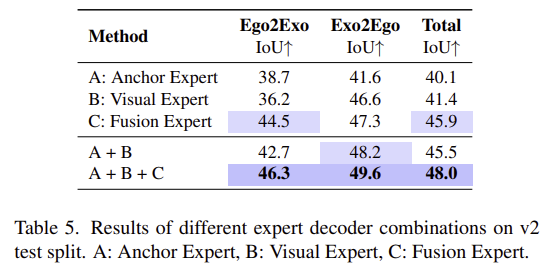
다음으로 3가지 Expert의 조합에 대한 실험 결과입니다. Anchor Expert와 Visual Expert가 각각 단독으로는 제한적이지만, 함께 사용할 때 성능이 향상되며, 이에 대해 저자들은 기하학적 단서와 외관적 단서가 상호보완적이기 때문이라고 분석하였습니다. 또한, Fusion Expert가 두 프롬프트와 함께 사용될 때 다양한 시나리오에서 안정적으로 작동한다는 것을 확인할 수 있습니다.
[Expert Performance Analysis]
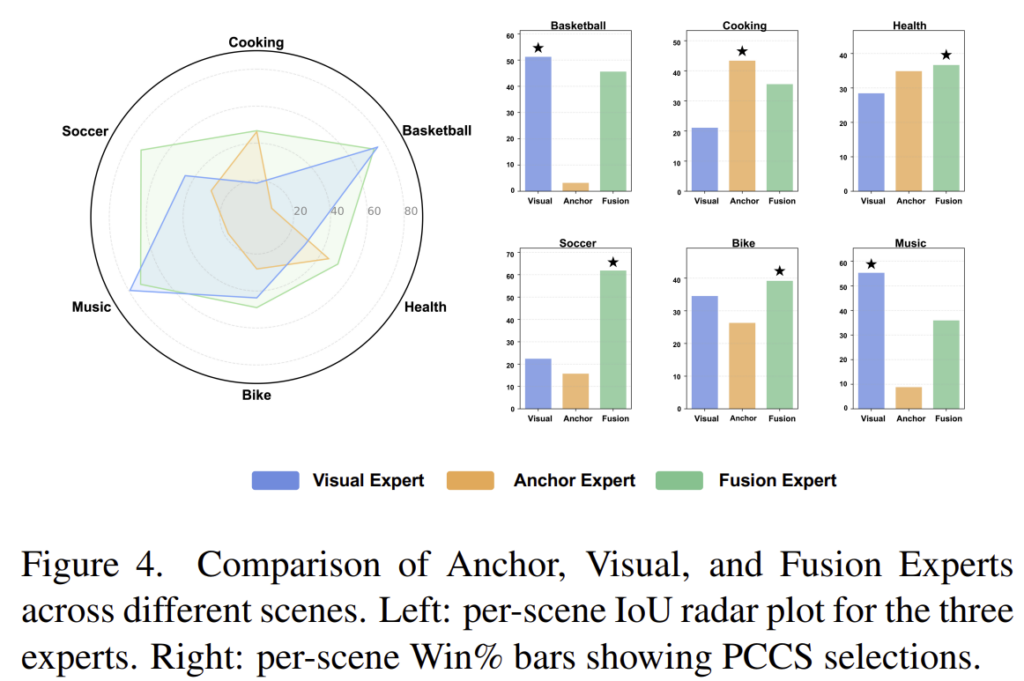
Figure 4는 각 expert가 서로 다른 장면에서 어떻게 동작하는 지 실험한 결과를 나타낸 그래프입니다. 실험 결과, Anchor Expert는 cooking이나 health와 같이 구조적이고 비교적 정적인 장면에서 좋은 성능을 보이지만, 큰 움직임이나 외관 변화가 큰 경우 성능이 감소하였다고 합니다. 또한, Visual Expert는 basketball이나 music과 같이 동적이고 사람 중심적인 경우에 강인하게 동작하였다고 합니다. 마지막으로, Fusion Expert의 경우 왼쪽 radar plot과 같이 다양한 장면에서 모두 안정적인 성능을 보였습니다.