오늘은 흔히 SelaVPR(Seamless Adaptation)로 불리는 VPR 방법론을 들고 왔습니다. DINOv2를 VPR에 쓰기 시작한 시기에 나와서 효과적으로 Foundation model을 VPR에 활용하는법을 제시한 논문입니다. 저자는 역시 Lu Feng입니다.
Introduction
언제나 그렇듯 VPR의 전반적인 특징을 이야기하고 있습니다.
1stage로 VLAD와 같은 aggregation 알고리즘으로 local feature들을 하나의 global descriptor로 풀링합니다.
그리고 일부 방법론들은 위 global descriptor가 공간정보를 날려버리기 때문에 2stage로 reranking을 진행합니다.
더불어 VPR 모델 학습은 pretrained된 foundation을 finetuning하는 패러다임을 따릅니다.
최근 foundation을 모델이 엄청난 일반화 성능을 가지고 있기 때문에 이를 최대한으로 활용하기 위함입니다. foundation model들은 VPR에 해로운 동적 객체(e.g. 보행자, 차량)에 민감하고 정적인 배경(e.g. 건물 나무)에 상대적으로 덜 집중하는 경향을 보입니다. 그렇기에 finetuning의 과정을 통해, 동적인 물체를 무시하고, VPR에 중요한 부분에 집중하도록 학습시킵니다.
이러한 상황에서 SelaVPR은 두가지 새로운 방법을 제안합니다.
1. local-global adapter를 통하여 foundation model이 local한 특징과 global한 특징 모두 잡아내도록 학습시킵니다.
2. Mutual Nearest Neightbor(MNN) feature loss를 제안하여, local adapter module을 학습시킵니다. 이렇게 학습되어 얻어진 local feature는 후에 reranking에 사용됩니다.
정리하면 새로운 adapter(global-local)를 통해 DINOv2를 tuning하는 것이 VPR에 유리하다는 것과 Cosine 유사도 기반 reranking과 학습할 수 있는 loss를 제안했습니다.
Proposed Method
– Global Adaptation
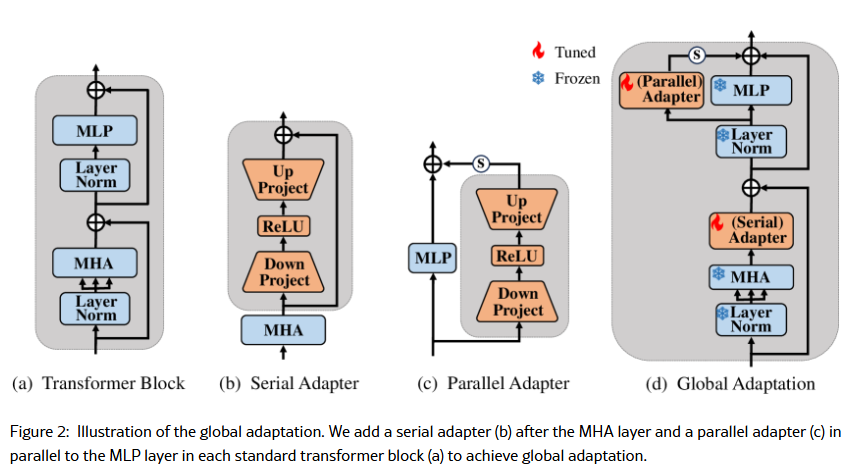
DINOv2의 능력을 더 VPR에 맞게 활용하기 위해서는 tuning이 필요합니다. 저자는 adapter, VPT, LoRA중 adapter를 사용한 방법을 택했습니다.
먼저 Global Adapter는 총 두개로 bottleneck module을 이용하여 설계하였습니다. Bottleneck은 down projection하는 FC layer를 먼저 태우고, 이후 ReLU, 그리고 다시 up projection하는 FC layer를 태웁니다.
첫번째 global adapter는 DINOv2의 MHA이후에 추가됩니다.
두번쨰 global adapter는 DINOv2의 MLP layer와 평행하게 추가됩니다. 이때 scaling factor s가 곱해집니다.
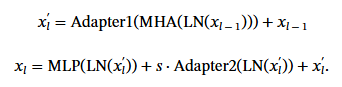
이렇게 Global adapted된 DINOv2를 통과한 feature map은 마지막 layernorm된 이후 GeM pooling을 이용하여 global descriptor로 표현됩니다. 이러한 방식은 feature들이 discriminative한 landmark들에 집중하고 동적인 방해물들을 무시하게 만들어줍니다.
– Local Adaptation
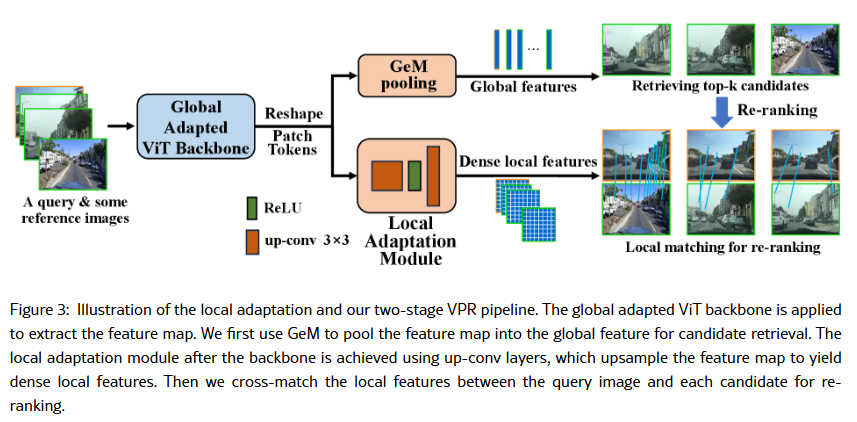
Adapted DINOv2를 통해 나온 feature map 자체가 coarse-grained patch-level feature로 볼 수 있습니다. 하지만 reranking의 관점에서는 더욱 dense한 feature가 필요합니다. 그렇기에 저자들은 upsampling하는 모듈을 제시합니다. 두번의 transpose convolution(사이의 ReLU)를 통해 16x16x1024의 feature map을 61x61x128로 공간축을 거의 4배로 upsampling해줍니다.
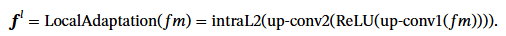
차원을 낮추고 token 개수를 늘려 matching을 더 수월하게 하기 위함이라고 생각하면 될 것 같습니다.
– Local Matching for Re-ranking
Re-ranking을 하기 위해서는 먼저 global descriptor로 candidate를 찾아야합니다.
Query와 Db의 global descriptor 사이의 L2 거리를 순서대로 정렬하여 나열합니다.
이때 top-K에 대해서만 re-ranking을 진행합니다.
query와 candidate의 feature map을 곱하여 cosine 유사도를 구합니다(이미 L2 되어있기에 곱하기만 합니다).
그리고 Query의 i번째 patch가 Candidate의 j번째 patch와 가장 유사할 때, Candidate의 j번째 patch도 Query의 i번째 patch가 가장 유사하다면(MNN이라면) match되었다고 판단합니다.
이러한 match의 개수를 counting하여 image similarity score로 사용합니다.
즉, query와 k개의 candidate중에 image similarity score가 가장 높은 것을 top1으로 판단합니다.
– Loss
저자가 추가한 local adapt module(transpose convolution moduel)은 기존 loss가 흐르지 않아 학습하지 못합니다. 그렇기에 추가적인 loss를 설계해 주어야합니다.
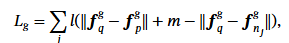
기존의 triplet loss는 위 수식과 같습니다. m은 마진이고 , f_q^g, f_p^g, f_n^g는 query, positive, negative에 대한 global feature입니다.
그러나 지금은 image similarity score를 사용하고, 이는 counting을 기반으로 판단하기 때문에 미분이 불가능합니다. 그래서 저자는 MNN local feature loss를 제안합니다.
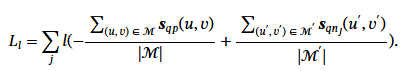
위 local loss는 query-negative의 MNN matching보다 query-positive의 MNN matching이 더 많이지도록 학습합니다.
Experiments
– SOTA와의 비교
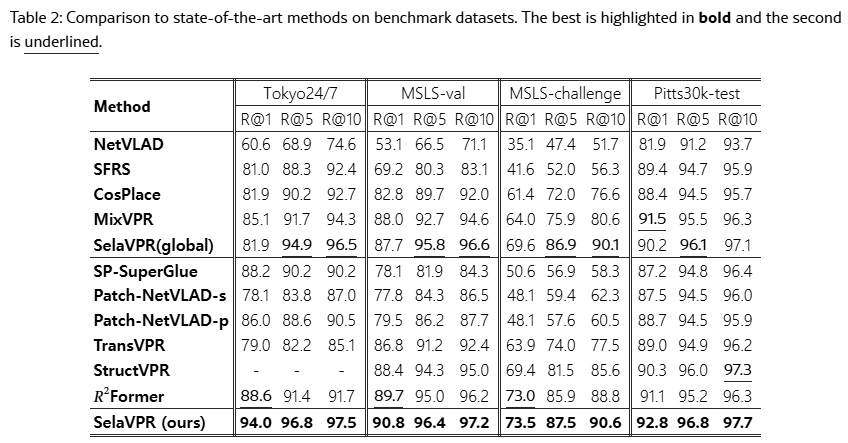
위 Table 2의 윗부분은 1stage 방법론이고, 아랫부분은 reranking을 하는 2stage 방법론들입니다.
성능을 보면, SelaVPR은 reranking을 하지 않는 SelaVPR(global)에서는 MixVPR에 약간 밀리는 모습을 보입니다. 저자들은 SelaVPR(global)이 R@1에서는 아쉽지만, R@5와 R@10에서는 우월하다는 것을 얘기하고 있습니다. 그리고 이것이 foundation model을 adapt하는 것이 강력한 feature 표현력을 지니기 때문이라고 설명합니다.
그리고 reranking을 했을때는 압도적인 모습을 보여줍니다.
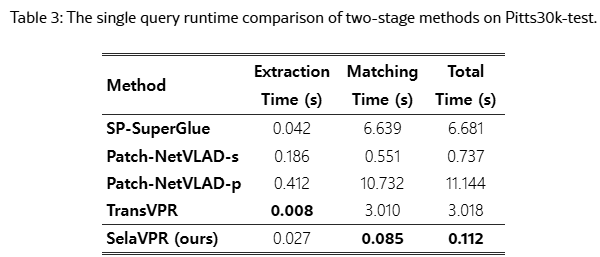
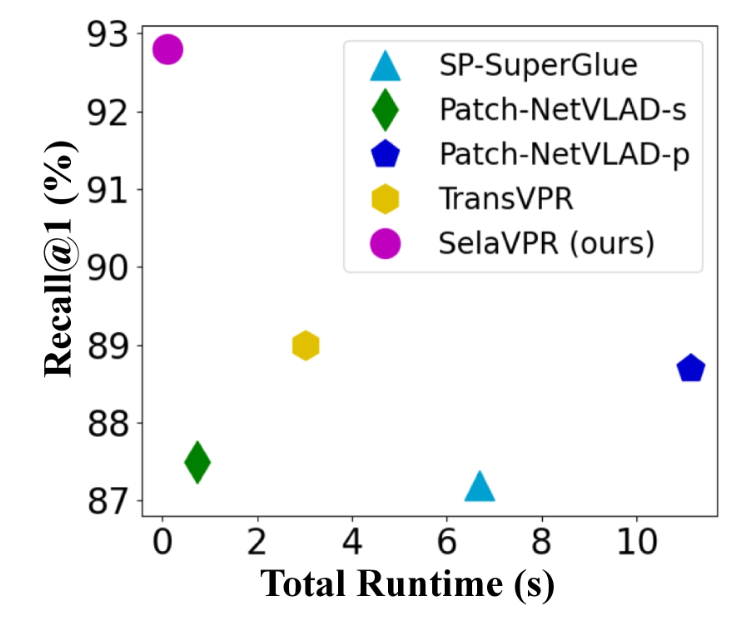
속도면에서도 SelaVPR은 큰 강점을 가집니다. 먼저 RANSAC을 하는 Patch-NetVLAD-p와 TransVPR와는 비교할 수 없을 정도로 빠릅니다. 하지만 TransVPR은 extraction time이 SelaVPR보다 빠릅니다. 왜냐하면 SelaVPR은 Vit/L backbone을 쓰기 때문입니다. 하지만 SelaVPR은 Matching Time에서 빠르기에 전체 속도는 SelaVPR이 압도하고 있습니다.
– Ablation Study
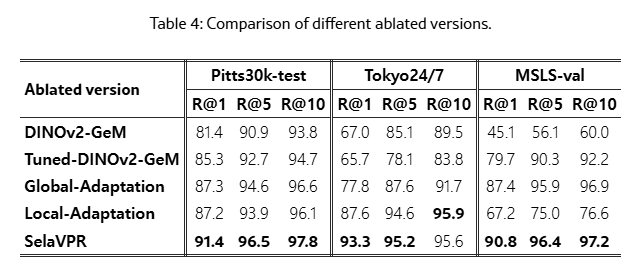
Table 4는 Adaptation 방법에 대해 다룹니다. 첫번째로 봐야할 것은 tuning이 안된 DINOv2(DINOv2-GeM)은 다른 tuning된 방법론에 비해 성능이 많이 낮습니다. 그리고 Global/Local-Adapation은 모두 전반적인 성능을 올려주지만, 둘이 같이 쓰였을 때 가장 높은 성능을 보입니다.
Visulization

위 Figure 1은 adaption module이 실제로 동적인 객체를 무시하고 정적 객체(VPR에 도움이 되는 객체)에 집중한다는 것을 시각적으로 보여줍니다.

Figure 4는 여러가지 상황에서 SelaVPR이 강건성을 가진다는 것을 다른 방법론과의 비교를 통해 보여주고 있습니다.
안녕하세요 정우님 좋은 리뷰 감사합니다.
이 분야에 대해서 익숙한게 아니라 읽으면서 궁금한 점이 생겼는데요!
VPR task에서 동적인 개체는 해로운 영향을 준다는 것은 이해했습니다. 근데 foundation model은 왜 동적인 객체에 민감한지 조금 더 풀어서 설명해주실 수 있나요?
감사합니다
안녕하세요 인하님 질문 감사합니다.
일반적인 Foundation model은 모든 객체에 민감합니다.
그러나 도로주행 상황의 특성상, 나무 건물들은 배경이나 사이드에 존재하고
사람, 자전거, 차량 등은 가운데에 많이 분포합니다.
Visualization의 Figure 1에서도 자전거를 탄 사람은 중앙에 있는 반면 건물이나 나무는 먼 배경에 존재합니다.
그렇기에 정리하자만 Foundation model이 동적인 객체에만 민감한 것이 아닌 모든 객체에 민감하며, VPR은 동적인 객체가 중심에 위치하는 경우가 많기 때문에 이를 제거하는 것이 중요합니다.
감사합니다.